Le 27 mai, dans le hall principal de la conférence DevOpsConf 2019, organisée dans le cadre du festival
RIT ++ 2019 , dans le cadre de la section Livraison continue, un rapport a été rédigé «werf est notre outil pour CI / CD à Kubernetes». Il parle des
problèmes et des défis auxquels tout le monde est confronté lors du déploiement sur Kubernetes , ainsi que des nuances qui peuvent ne pas être immédiatement perceptibles. En analysant les solutions possibles, nous montrons comment cela est mis en œuvre dans l'outil
werf Open Source.
Depuis le salon, notre utilitaire (anciennement connu sous le nom de dapp) a dépassé la limite historique de
1000 étoiles sur GitHub - nous espérons que la communauté croissante de ses utilisateurs simplifiera la vie de nombreux ingénieurs DevOps.

Nous présentons donc la
vidéo avec le rapport (~ 47 minutes, beaucoup plus informatif que l'article) et son extrait principal sous forme de texte. C'est parti!
Livraison de code dans Kubernetes
La discussion ne portera plus sur werf, mais sur CI / CD dans Kubernetes, ce qui implique que notre logiciel est emballé dans des conteneurs Docker
(j'en ai parlé dans le rapport 2016 ) , et des K8 seront utilisés pour le lancer en production
(à propos de ce - en 2017 ) .
À quoi ressemble la livraison de Kubernetes?
- Il existe un référentiel Git avec du code et des instructions pour le construire. L'application est compilée dans une image Docker et publiée dans le registre Docker.
- Dans le même référentiel, il y a des instructions sur la façon de déployer et d'exécuter l'application. Au stade du déploiement, ces instructions sont envoyées à Kubernetes, qui reçoit l'image souhaitée du registre et la démarre.
- De plus, il y a généralement des tests. Certains d'entre eux peuvent être effectués lors de la publication d'une image. Vous pouvez également (par les mêmes instructions) déployer une copie de l'application (dans un espace de noms K8 séparé ou dans un cluster séparé) et y exécuter des tests.
- Enfin, nous avons besoin d'un système CI qui reçoit les événements de Git (ou clics sur les boutons) et appelle toutes les étapes indiquées: construire, publier, déployer, tester.

Il y a quelques notes importantes ici:
- Comme nous avons une infrastructure immuable, l'image de l'application utilisée à toutes les étapes (mise en scène, production, etc.) doit être une . J'en ai parlé davantage et avec des exemples ici .
- Étant donné que nous suivons l'infrastructure en tant qu'approche de code (IaC) , le code de l'application et les instructions pour sa création et son exécution doivent se trouver dans un référentiel . Pour en savoir plus à ce sujet, voir le même rapport .
- Nous voyons généralement la chaîne de livraison (livraison) comme ceci: l'application a été assemblée, testée, publiée (étape de publication) et c'est tout - la livraison a eu lieu. Mais en réalité, l'utilisateur reçoit ce que vous avez déployé, non pas lorsque vous l'avez livré à la production, mais quand il a pu s'y rendre et que cette production a fonctionné. Par conséquent, je pense que la chaîne de livraison ne se termine qu'au stade opérationnel (run) , et plus précisément, même au moment où le code a été retiré de la production (en le remplaçant par un nouveau).
Revenons au schéma de livraison de Kubernetes décrit ci-dessus: il a été inventé non seulement par nous, mais littéralement par tous ceux qui ont traité ce problème. Essentiellement, ce modèle est maintenant appelé GitOps
(vous trouverez
plus d'informations sur le terme et les idées qui le sous-tendent ici ) . Regardons les étapes du schéma.
Étape de construction
Il semblerait qu'en 2019, vous pouvez parler de l'assemblage d'images Docker, quand tout le monde sait comment écrire des Dockerfiles et exécuter la
docker build de Docker? .. Voici les nuances auxquelles je voudrais faire attention:
- Le poids de l'image est important, utilisez donc plusieurs étapes pour ne laisser que l'application vraiment nécessaire à l'image.
- Le nombre de couches doit être minimisé en combinant les chaînes de commandes
RUN dans le sens. - Cependant, cela ajoute aux problèmes de débogage , car lorsque l'assembly se bloque, vous devez trouver la commande nécessaire dans la chaîne à l'origine du problème.
- La vitesse de construction est importante car nous voulons déployer rapidement les modifications et regarder le résultat. Par exemple, je ne veux pas réassembler les dépendances dans les bibliothèques de langues avec chaque build de l'application.
- Souvent, à partir d'un référentiel Git, de nombreuses images sont requises, qui peuvent être résolues par un ensemble de Dockerfiles (ou des étapes nommées dans un seul fichier) et un script Bash avec leur assemblage séquentiel.
Ce n'était que la pointe de l'iceberg à laquelle tout le monde fait face. Mais il y a d'autres problèmes, et en particulier:
- Souvent, au stade de l'assemblage, nous devons monter quelque chose (par exemple, mettre en cache le résultat d'une commande comme apt dans un répertoire tiers).
- Nous voulons Ansible au lieu d'écrire sur le shell.
- Nous voulons construire sans Docker (pourquoi avons-nous besoin d'une machine virtuelle supplémentaire dans laquelle vous devez tout configurer pour cela alors qu'il existe déjà un cluster Kubernetes dans lequel vous pouvez exécuter des conteneurs?).
- Assemblage parallèle , qui peut être compris de différentes manières: différentes commandes du Dockerfile (si plusieurs étapes sont utilisées), plusieurs validations d'un référentiel, plusieurs Dockerfiles.
- Assemblage distribué : nous voulons collecter quelque chose dans des pods qui sont «éphémères», car leur cache disparaît, ce qui signifie qu'il doit être stocké quelque part séparément.
- Enfin, j'ai appelé le summum de l'auto- magie des désirs: il serait idéal d'aller dans le référentiel, de taper une équipe et d'obtenir une image prête à l'emploi, assemblée avec une compréhension de comment et quoi faire correctement. Cependant, je ne suis personnellement pas sûr que toutes les nuances puissent être prévues de cette manière.
Et voici les projets:
- moby / buildkit - un constructeur de la société Docker Inc (déjà intégré dans les versions actuelles de Docker), qui essaie de résoudre tous ces problèmes;
- kaniko - un collectionneur de Google, qui vous permet de construire sans Docker;
- Buildpacks.io - une tentative de la CNCF de faire de l' automagie et, en particulier, une solution intéressante avec rebase pour les couches;
- et un tas d'autres utilitaires comme buildah , genuinetools / img ...
... et voyez combien d'étoiles ils ont sur GitHub. C'est-à-dire, d'une part, que la
docker build est et peut faire quelque chose, mais en réalité, le
problème n'a pas été complètement résolu - cela est démontré par le développement parallèle de constructeurs alternatifs, chacun résolvant certains des problèmes.
Construire en werf
Nous sommes donc arrivés à
werf (anciennement connu sous le nom de dapp) - l'utilitaire Open Source de Flant, ce que nous faisons depuis de nombreuses années. Tout a commencé il y a environ 5 ans avec des scripts Bash qui optimisent l'assemblage des Dockerfiles, et les 3 dernières années, le développement complet s'est poursuivi dans le cadre d'un projet avec son propre référentiel Git
(d'abord en Ruby, puis réécrit en Go, et en même temps renommé) . Quels problèmes de build sont résolus dans werf?

Les problèmes ombrés de bleu ont déjà été mis en œuvre, l'assemblage parallèle a été fait au sein du même hôte, et nous prévoyons de terminer les questions jaunes d'ici la fin de l'été.
Stade de publication dans le registre (publier)
Nous avons tapé
docker push ... - qu'est-ce qui peut être difficile à télécharger une image dans le registre? Et puis la question se pose: "Quelle balise pour mettre l'image?" Cela vient du fait que nous avons
Gitflow (ou une autre stratégie Git) et Kubernetes, et l'industrie est déterminée à s'assurer que ce qui se passe à Kubernetes suit ce qui se fait à Git. Git est notre seule source de vérité.
Qu'est-ce qui est si compliqué?
Assurer la reproductibilité : d'une validation dans Git, qui est intrinsèquement
immuable , à une image Docker qui doit rester la même.
Il est également important pour nous de
déterminer l'origine , car nous voulons comprendre à partir de quel commit l'application lancée dans Kubernetes a été construite (nous pouvons alors faire des différences et des choses similaires).
Stratégies de marquage
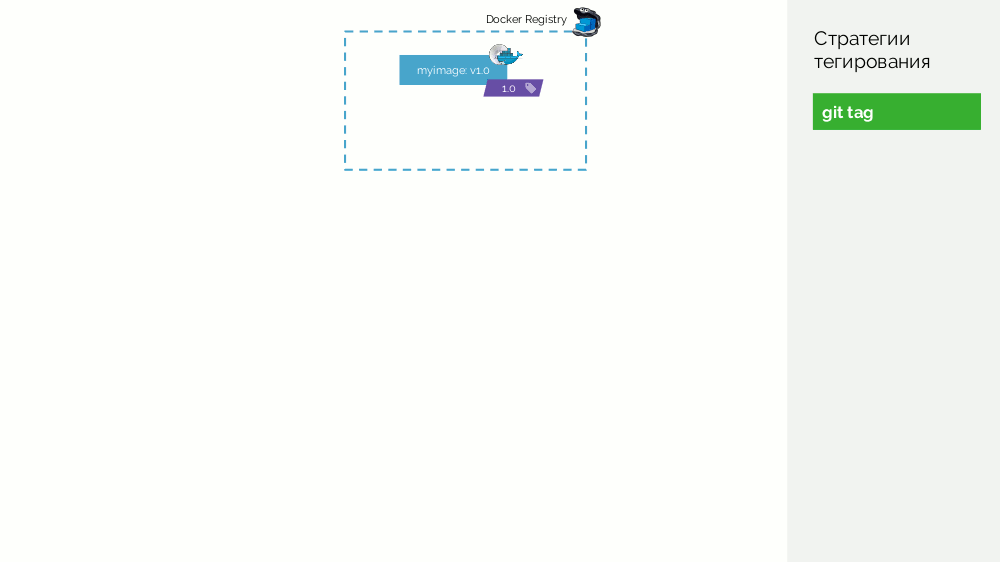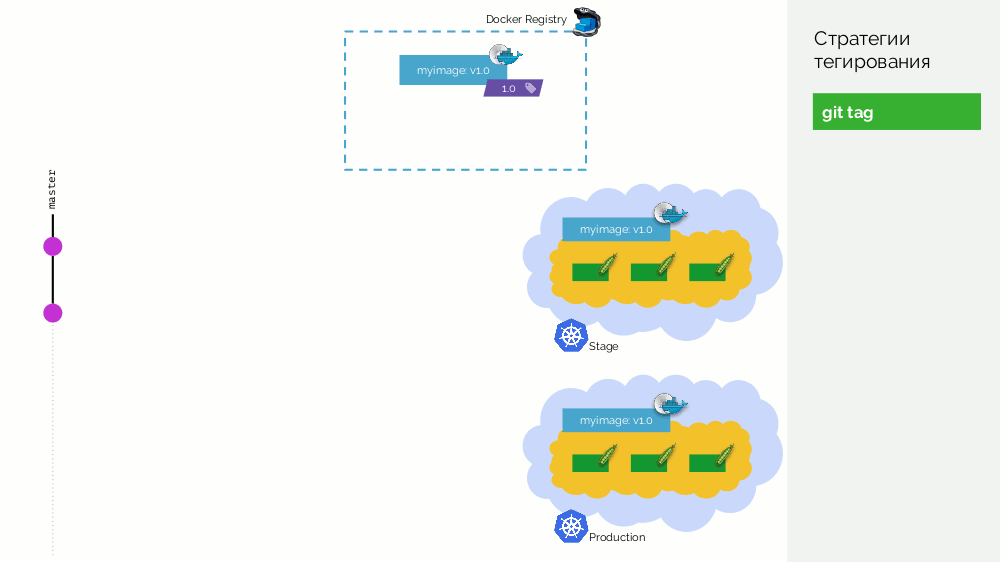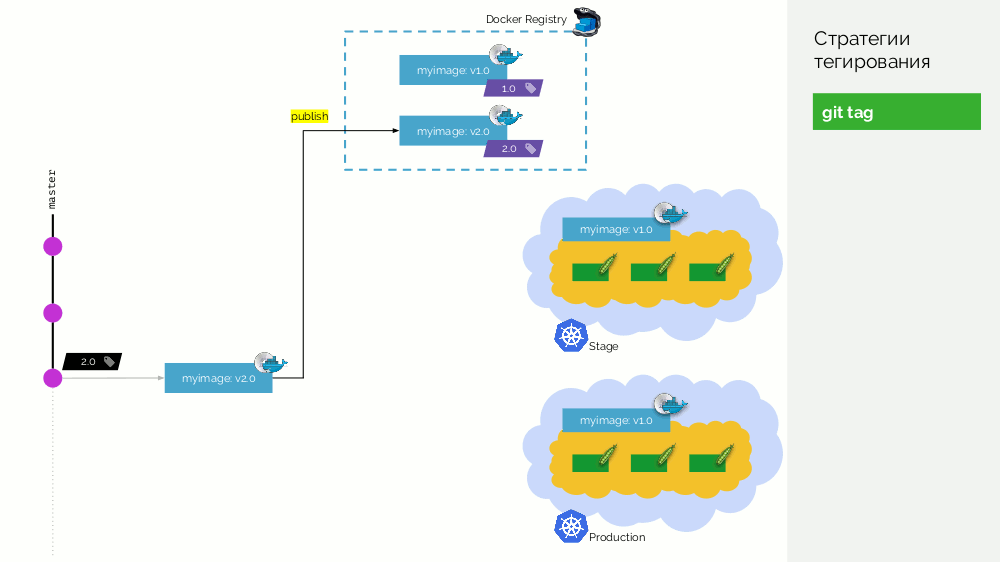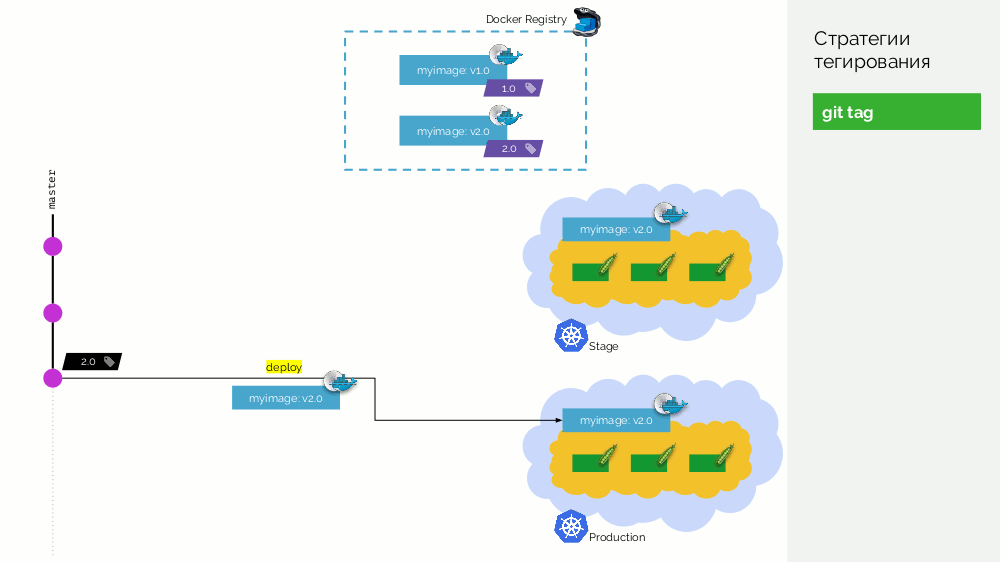
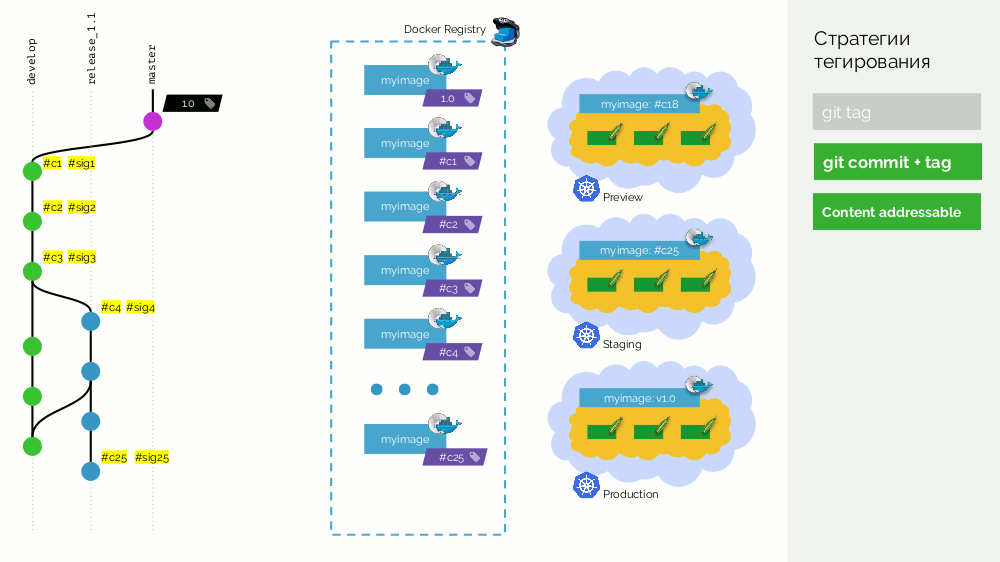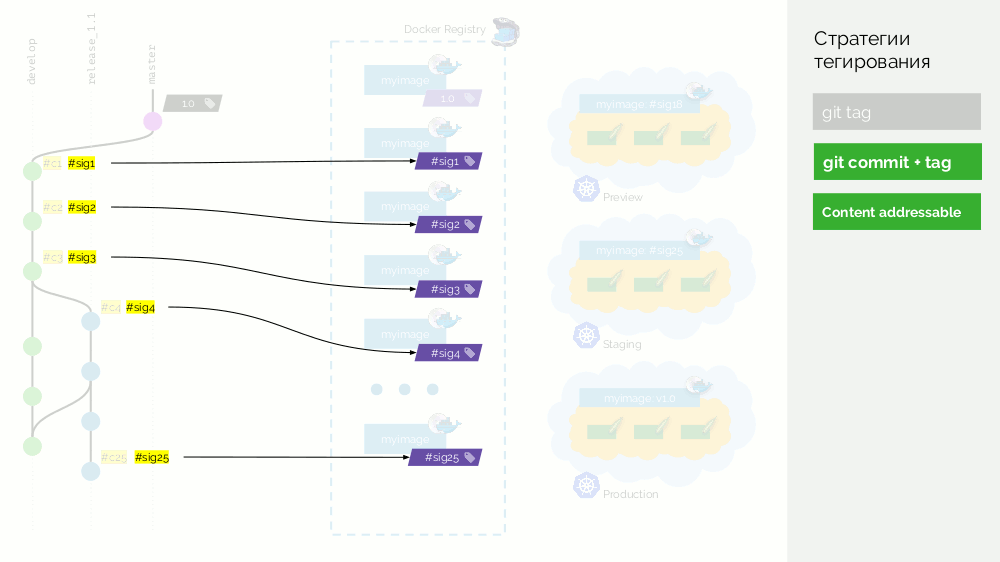
Le premier est une simple
balise git . Nous avons un registre avec une image étiquetée
1.0 . Kubernetes a une scène et une production où cette image est pompée. Dans Git, nous faisons des commits et à un moment donné nous mettons le tag
2.0 . Nous le collectons selon les instructions du référentiel et le mettons dans le registre avec la balise
2.0 . Nous le déployons sur scène et, si tout va bien, alors en production.
Le problème avec cette approche est que nous avons d'abord défini la balise, puis seulement testé et déployé. Pourquoi? Tout d'abord, c'est tout simplement illogique: nous distribuons une version de logiciel que nous n'avons même pas testée (nous ne pouvons pas faire autrement, car pour vérifier, vous devez mettre une balise). Deuxièmement, cette façon n'est pas compatible avec Gitflow.
La deuxième option est
git commit + tag . Il y a une balise
1.0 dans la branche principale; pour lui dans le registre - une image déployée en production. De plus, le cluster Kubernetes possède des boucles de prévisualisation et de transfert. Ensuite, nous suivons Gitflow: dans la branche principale pour le développement, nous
develop nouvelles fonctionnalités, à la suite desquelles il y a un commit avec l'identifiant
#c1 . Nous le collectons et le publions dans le registre en utilisant cet identifiant (
#c1 ). Nous déployons l'aperçu avec le même identifiant. Nous faisons de même avec les commits
#c2 et
#c3 .
Lorsque nous avons réalisé qu'il y avait suffisamment de fonctionnalités, nous commençons à tout stabiliser. Dans Git, créez la branche
release_1.1 (basée sur
#c3 de
develop ). La collecte de cette version n'est pas requise, car Cela a été fait à l'étape précédente. Par conséquent, nous pouvons simplement le déployer vers la mise en scène. Nous corrigeons les bogues dans
#c4 et
#c4 même manière sur la mise en scène. Dans le même temps, le développement est en cours à
develop , où des modifications par rapport à la
release_1.1 sont effectuées périodiquement. À un moment donné, nous obtenons un commit validé et pompé pour la mise en scène, ce dont nous sommes satisfaits (
#c25 ).
Ensuite, nous faisons une fusion (avec avance rapide) de la branche de publication (
release_1.1 ) dans master. Nous avons mis une balise avec la nouvelle version (
1.1 ) sur ce commit. Mais cette image est déjà assemblée dans le registre, donc afin de ne pas la collecter à nouveau, nous ajoutons juste une deuxième balise à l'image existante (maintenant elle a les balises
#c25 et
1.1 dans le registre). Après cela, nous le déployons en production.
Il y a un inconvénient qu'une image (
#c25 ) est
#c25 sur la mise en scène, et une autre (
1.1 ) est
#c25 sur la production, mais nous savons que «physiquement», c'est la même image du registre.
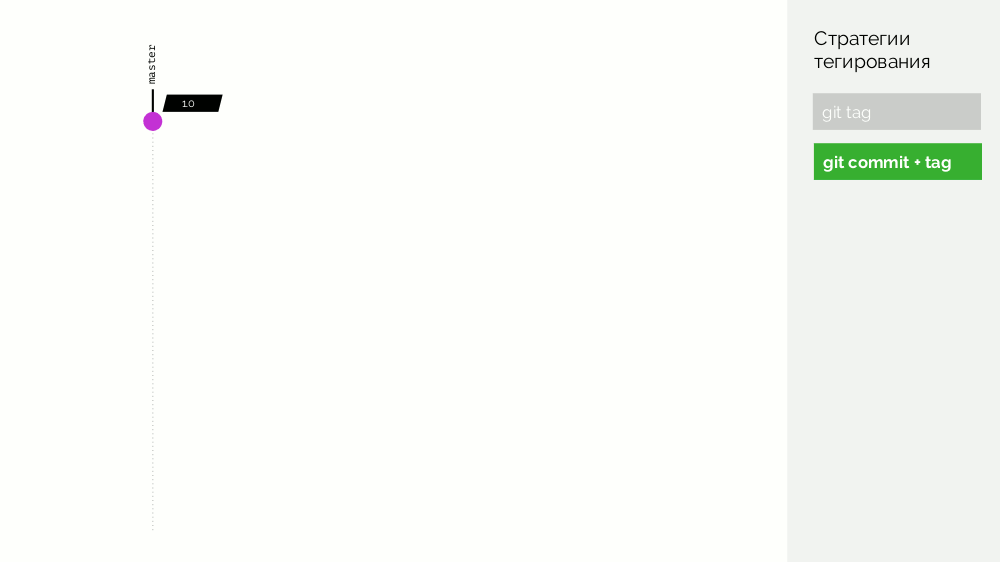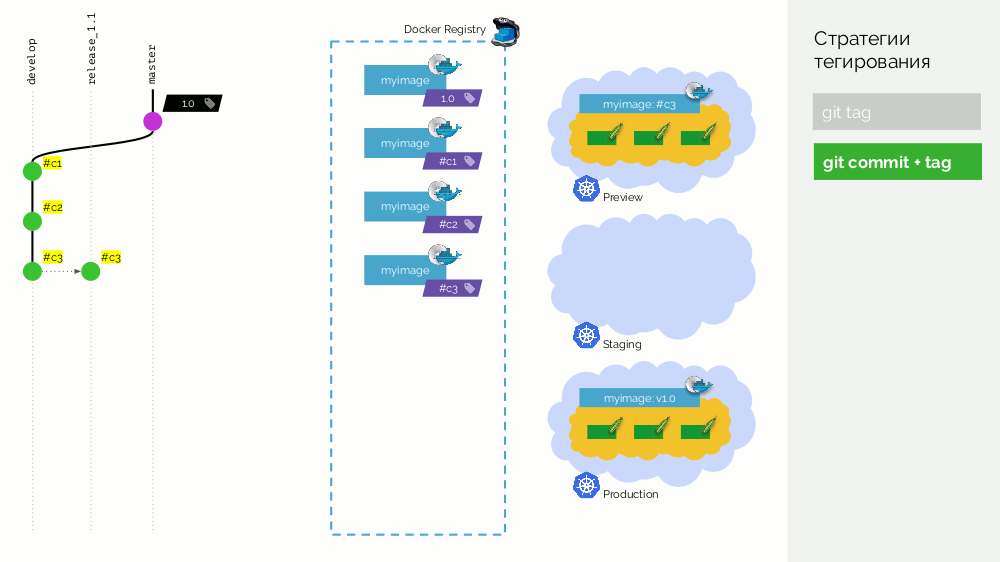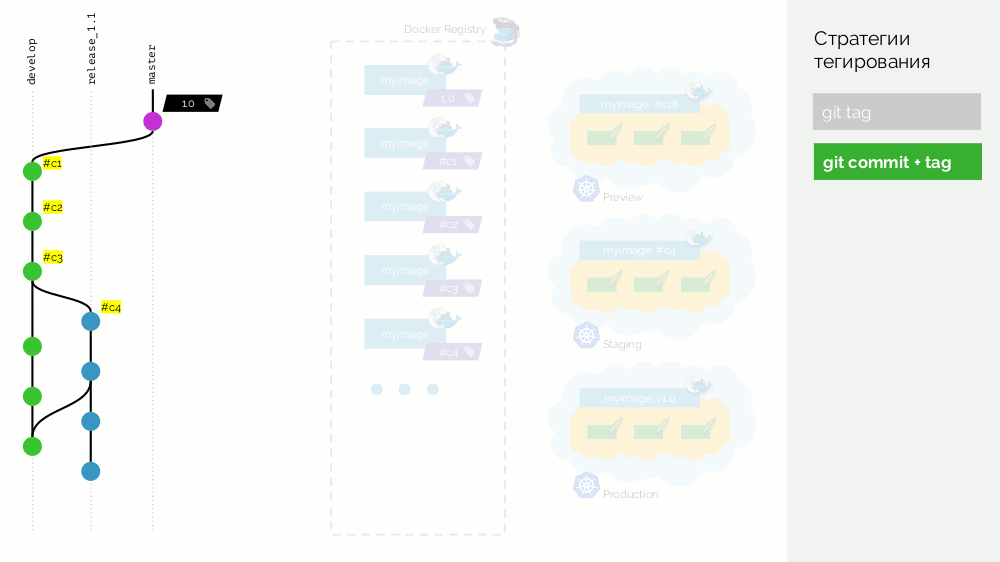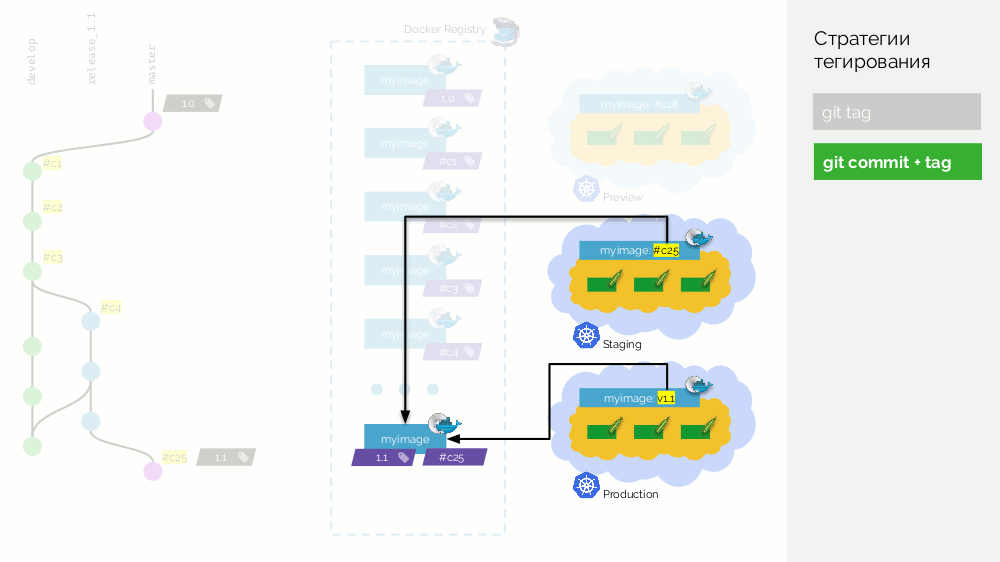
Le vrai inconvénient est qu'il n'y a pas de support pour merge commit'ov, vous devez faire une avance rapide.
Vous pouvez aller plus loin et faire l'affaire ... Prenons un exemple de Dockerfile simple:
FROM ruby:2.3 as assets RUN mkdir -p /app WORKDIR /app COPY . ./ RUN gem install bundler && bundle install RUN bundle exec rake assets:precompile CMD bundle exec puma -C config/puma.rb FROM nginx:alpine COPY --from=assets /app/public /usr/share/nginx/www/public
Nous en construisons un fichier selon ce principe, que nous prenons:
- SHA256 à partir des identifiants des images utilisées (
ruby:2.3 et nginx:alpine ), qui sont des sommes de contrôle de leur contenu; - toutes les équipes (
RUN , CMD , etc.); - SHA256 à partir de fichiers ajoutés.
... et prenez la somme de contrôle (à nouveau SHA256) d'un tel fichier. Il s'agit de la
signature de tout ce qui définit le contenu d'une image Docker.

Revenons au schéma et
au lieu des validations, nous utiliserons de telles signatures , c'est-à-dire étiqueter les images avec des signatures.
Maintenant, lorsque vous avez besoin, par exemple, de fusionner des modifications de la version au master, nous pouvons faire un vrai commit de fusion: il aura un identifiant différent, mais la même signature. Avec le même identifiant, nous déploierons également l'image en production.
L'inconvénient est qu'il ne sera désormais plus possible de déterminer quel type d'engagement a été injecté dans la production - les sommes de contrôle ne fonctionnent que dans un sens. Ce problème est résolu par une couche supplémentaire avec des métadonnées - je vous en dirai plus plus tard.
Marquage dans werf
Dans werf, nous sommes allés encore plus loin et nous nous préparons à faire un assemblage distribué avec un cache qui n'est pas stocké sur la même machine ... Donc, nous avons deux types d'images Docker, nous les appelons
stage et
image .
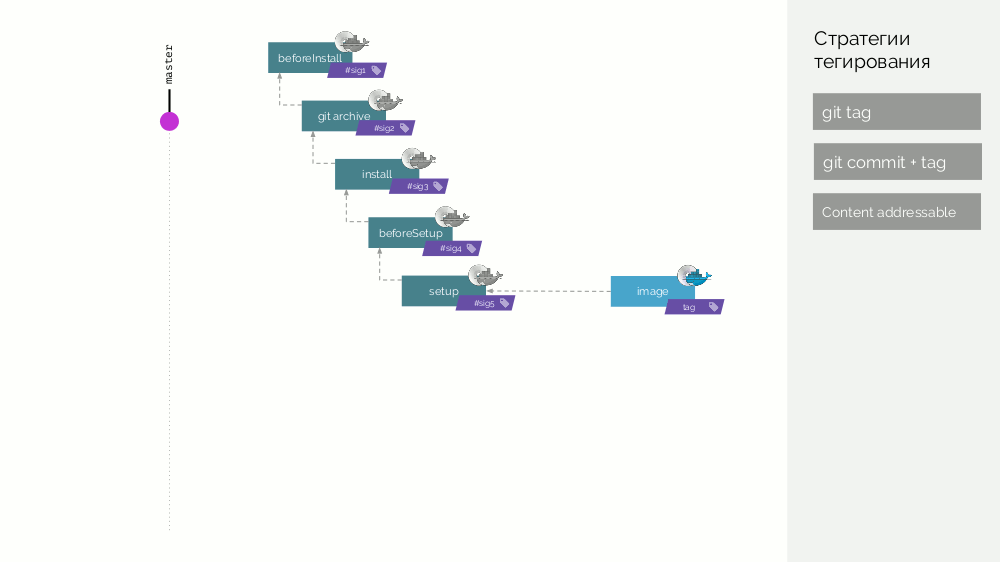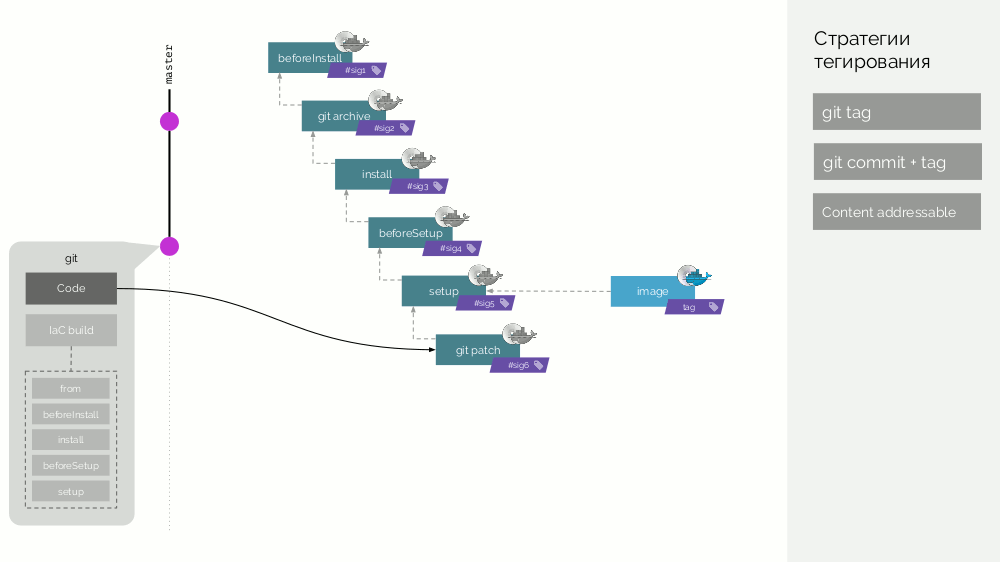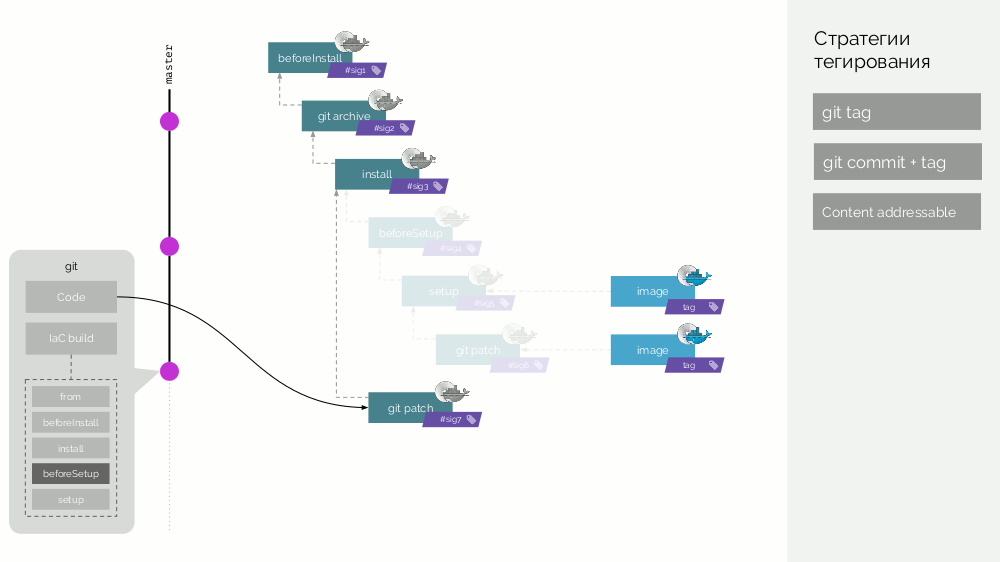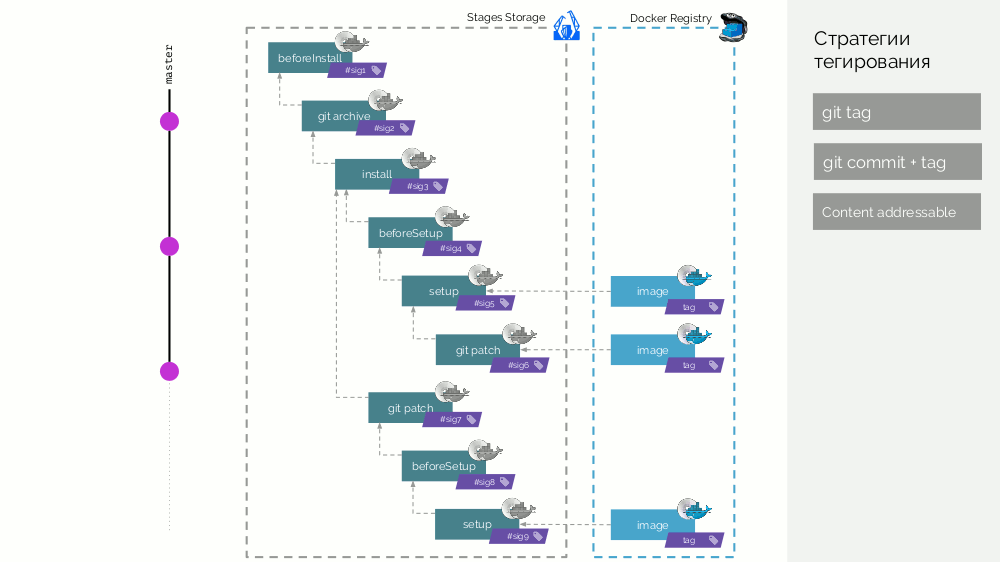
Le référentiel werf Git stocke des instructions de build spécifiques qui décrivent les différentes étapes de la build (
beforeInstall ,
install ,
beforeSetup ,
setup ). Nous collectons l'image de la première étape avec une signature définie comme la somme de contrôle des premières étapes. Ensuite, nous ajoutons le code source, pour la nouvelle image de scène, nous considérons sa somme de contrôle ... Ces opérations sont répétées pour toutes les étapes, à la suite de quoi nous obtenons un ensemble d'images de scène. Ensuite, nous faisons l'image-image finale contenant également des métadonnées sur son origine. Et nous marquons cette image de différentes manières (détails plus tard).

Après cela, un nouveau commit apparaît, dans lequel seul le code d'application est modifié. Que va-t-il se passer? Un patch sera créé pour les changements de code, une nouvelle image de stage sera préparée. Sa signature sera définie comme la somme de contrôle de l'ancienne image de la scène et du nouveau patch. A partir de cette image, une nouvelle image-image finale sera formée. Un comportement similaire se produira avec des changements à d'autres étapes.
Ainsi, les images de scène sont un cache qui peut être distribué distribué, et les images d'image déjà créées à partir de celui-ci sont chargées dans le Docker Registry.
Nettoyage du registre
Il ne s'agit pas de supprimer des couches qui restent suspendues après la suppression de balises - c'est une fonctionnalité standard du Docker Registry lui-même. Il s'agit d'une situation où de nombreuses balises Docker s'accumulent et nous comprenons que nous n'en avons plus besoin et qu'elles prennent de la place (et / ou nous la payons).
Quelles sont les stratégies de nettoyage?
- Vous ne pouvez rien nettoyer . Parfois, il est vraiment plus facile de payer un peu pour l'espace supplémentaire que de démêler une énorme boule de balises. Mais cela ne fonctionne que jusqu'à un certain point.
- Réinitialisation complète . Si vous supprimez toutes les images et reconstruisez uniquement les images pertinentes dans le système CI, un problème peut survenir. Si le conteneur redémarre en production, une nouvelle image sera chargée pour celui-ci - celle qui n'a encore été testée par personne. Cela tue l'idée d'une infrastructure immuable.
- Bleu-vert . Un registre a commencé à déborder - chargeant des images dans un autre. Le même problème que dans la méthode précédente: à quel moment pouvez-vous nettoyer le registre qui a commencé à déborder?
- Par le temps . Supprimer toutes les images de plus d'un mois? Mais il y a sûrement un service qui n'a pas été mis à jour depuis un mois ...
- Déterminez manuellement ce qui peut déjà être supprimé.
Il existe deux options vraiment viables: ne pas nettoyer ou une combinaison de bleu-vert + manuellement. Dans ce dernier cas, nous parlons de ce qui suit: lorsque vous comprenez qu'il est temps de nettoyer le registre, créez-en un nouveau et ajoutez-y toutes les nouvelles images pendant, par exemple, un mois. Un mois plus tard, voyez quels pods dans Kubernetes utilisent toujours l'ancien registre et transférez-les également dans le nouveau registre.
Où sommes-nous
allés à
werf ? Nous collectons:
- Git head: toutes les balises, toutes les branches, - en supposant que tout ce qui est testé dans Git, nous en avons besoin dans les images (et sinon, nous devons les supprimer dans le Git lui-même);
- tous les pods qui sont maintenant téléchargés dans Kubernetes;
- anciens ReplicaSets (quelque chose qui a été récemment pompé), ainsi que nous prévoyons de numériser les versions de Helm et de sélectionner les dernières images là-bas.
... et nous faisons une liste blanche à partir de cet ensemble - une liste d'images que nous ne supprimerons pas. Nous nettoyons tout le reste, après quoi nous trouvons les images de scène orphelines et les supprimons aussi.
Étape de déploiement (déploiement)
Déclaration forte
Le premier point sur lequel je voudrais attirer l'attention dans le déploiement est de déployer la configuration de ressource mise à jour, déclarée de manière déclarative. Le document YAML d'origine décrivant les ressources Kubernetes est toujours très différent du résultat qui fonctionne réellement dans le cluster. Parce que Kubernetes ajoute à la configuration:
- identifiants
- informations de service;
- de nombreuses valeurs par défaut;
- section avec l'état actuel;
- les modifications apportées dans le cadre du webhook d'admission;
- le résultat du travail de différents contrôleurs (et ordonnanceur).
Par conséquent, lorsqu'une nouvelle configuration d'une ressource (
nouvelle ) apparaît, nous ne pouvons pas simplement prendre et écraser avec elle la configuration actuelle «en direct» (en
direct ). Pour ce faire, nous devons comparer
nouveau avec la dernière configuration appliquée (
dernière appliquée ) et lancer le patch résultant en
direct .
Cette approche est appelée
fusion bidirectionnelle . Il est utilisé, par exemple, dans Helm.
Il existe également une
fusion à 3 voies , qui diffère en ce que:
- en comparant la dernière application et la nouvelle , nous examinons ce qui a été supprimé;
- en comparant le nouveau et le vivant , nous voyons ce qui a été ajouté ou changé;
- appliquer le patch résumé pour vivre .
Nous déployons plus de 1000 applications avec Helm, nous vivons donc réellement avec une fusion bidirectionnelle. Cependant, il a un certain nombre de problèmes que nous avons résolus avec nos correctifs qui aident Helm à fonctionner normalement.
Statut de déploiement réel
Après le prochain événement, notre système CI a généré une nouvelle configuration pour Kubernetes, il l'envoie à
appliquer au cluster en utilisant Helm ou
kubectl apply . Ensuite, la fusion N-way déjà décrite a lieu, à laquelle l'API Kubernetes approuve le système CI, et ce dernier répond à son utilisateur.

Cependant, il y a un énorme problème: après tout, une
application réussie ne signifie pas un déploiement réussi . Si Kubernetes comprend les changements à appliquer, l'applique - nous ne savons toujours pas quel sera le résultat. Par exemple, la mise à jour et le redémarrage des pods dans le frontend peuvent réussir, mais pas dans le backend, et nous obtiendrons différentes versions des images d'application en cours d'exécution.
Pour tout faire correctement, un lien supplémentaire apparaît dans ce schéma - un tracker spécial qui recevra les informations d'état de l'API Kubernetes et les transmettra pour une analyse plus approfondie de l'état réel des choses. Nous avons créé une bibliothèque Open Source sur Go -
kubedog (voir son annonce ici ) - qui résout ce problème et est intégrée à werf.
Le comportement de ce tracker au niveau werf est configuré à l'aide d'annotations placées sur Deployments ou StatefulSets. L'annotation principale,
fail-mode , comprend les significations suivantes:
IgnoreAndContinueDeployProcess - ignore les problèmes de IgnoreAndContinueDeployProcess de ce composant et continue le déploiement;FailWholeDeployProcessImmediately - une erreur dans ce composant arrête le processus de déploiement;HopeUntilEndOfDeployProcess - nous espérons que ce composant fonctionnera d'ici la fin du déploiement.
Par exemple, une combinaison de ressources et de valeurs d'annotation en
fail-mode :

Lors du premier déploiement, la base de données (MongoDB) n'est peut-être pas encore prête - Les déploiements se bloqueront. Mais vous pouvez attendre le moment où il démarre et le déploiement se poursuivra.
Il y a deux annotations supplémentaires pour kubedog dans werf:
failures-allowed-per-replica - le nombre de suppressions autorisées par réplique;show-logs-until - ajuste le moment jusqu'à lequel werf affiche (dans stdout) les journaux de tous les pods en cours de déploiement. Par défaut, il s'agit de PodIsReady (pour ignorer les messages dont nous avons à peine besoin lorsque le trafic commence à arriver sur le pod), cependant, les valeurs ControllerIsReady et EndOfDeploy également EndOfDeploy .
Que voulons-nous d'autre du déploiement?
En plus des deux points déjà décrits, nous souhaitons:
- pour voir les journaux - et seulement nécessaire, mais pas tout;
- suivre les progrès , car si un travail se "suspend" en silence pendant plusieurs minutes, il est important de comprendre ce qui s'y passe;
- avoir une restauration automatique en cas de problème (et il est donc essentiel de connaître l'état réel du déploiement). Le déploiement doit être atomique: soit il se termine, soit tout revient à son état précédent.
Résumé
En tant qu'entreprise, pour nous, pour implémenter toutes les nuances décrites à différents stades de livraison (construire, publier, déployer), le système CI et l'utilitaire
werf suffisent .
Au lieu d'une conclusion:

Avec l'aide de werf, nous avons bien progressé dans la résolution d'un grand nombre de problèmes des ingénieurs DevOps et serons heureux si la communauté plus large essaie au moins cet utilitaire dans la pratique. Obtenir un bon résultat ensemble sera plus facile.
Vidéos et diapositives
Vidéo de la performance (~ 47 minutes):
Présentation du rapport:
PS
Autres rapports Kubernetes sur notre blog: