Remarque perev. : L'auteur de ce document est Cindy Sridharan, une ingénieure d'imgix impliquée dans le développement d'API et, en particulier, dans le test de microservices. Dans cet article, elle partage sa vision détaillée des problèmes réels dans le domaine du traçage distribué, où, à son avis, il y a un manque d'outils vraiment efficaces pour résoudre les problèmes urgents. [L'illustration est empruntée à un autre document sur le traçage distribué.]
[L'illustration est empruntée à un autre document sur le traçage distribué.]On pense que le
traçage distribué est difficile à mettre en œuvre et son retour
est au mieux douteux . Le «problème» de la trace s'explique par de nombreuses raisons, faisant souvent référence à la complexité de la configuration de chaque composant du système pour transmettre les en-têtes correspondants avec chaque requête. Bien que ce problème se produise, il ne peut pas du tout être qualifié d'insurmontable. Soit dit en passant, cela n'explique pas pourquoi les développeurs n'aiment pas vraiment le traçage (même déjà fonctionnel).
La principale difficulté du suivi distribué n'est pas de collecter des données, de ne pas normaliser les formats de distribution et de présentation des résultats, et de ne pas déterminer quand, où et comment échantillonner. Je n'essaie pas du tout de présenter ces «problèmes de digestibilité» comme
triviaux - en fait, il y a des défis techniques et politiques (si nous examinons vraiment les
normes et protocoles Open Source) politiques qui doivent être surmontés pour que ces problèmes puissent être considérés résolus.
Cependant, si vous imaginez que tous ces problèmes ont été résolus, il est probable que rien ne changera considérablement en termes d'
expérience de l'utilisateur final . Le suivi n'est peut-être toujours pas pratique dans les scénarios de débogage les plus courants, même après son déploiement.
Une telle trace différente
Le traçage distribué comprend plusieurs composants disparates:
- équiper les applications et les middlewares de commandes;
- Transmission de contexte distribué
- collecte de traces;
- stockage des traces;
- leur extraction et visualisation.
Beaucoup de discussions sur le traçage distribué se résument à le considérer comme une sorte d'opération unaire, dont le seul but est d'aider au diagnostic complet du système. Cela est largement dû à la manière dont le concept de traçage distribué a été formé. Dans
un blog publié lors de l'ouverture des sources Zipkin, il a été mentionné
qu'il [Zipkin] rend Twitter plus rapide . Les premières offres commerciales de traçage ont également été promues comme
outils APM .
Remarque perev. : Afin de mieux comprendre le texte, nous définissons deux termes de base selon la documentation du projet OpenTracing :- Span - l'élément de base du traçage distribué. Il s'agit d'une description d'un certain flux de travail (par exemple, une requête de base de données) avec un nom, des heures de début et de fin, des balises, des journaux et un contexte.
- Les travées contiennent généralement des liens vers d'autres travées, ce qui vous permet de combiner plusieurs travées dans Trace - une visualisation de la durée de vie d'une demande lorsqu'elle se déplace à travers un système distribué.
Trace'y contient des données incroyablement précieuses qui peuvent vous aider dans des tâches telles que: tests en production, tests de reprise après sinistre, tests avec introduction d'erreurs, etc. En fait, certaines entreprises utilisent déjà le traçage à ces fins. Pour commencer,
le transfert de contexte universel a d'autres utilisations en plus du simple transfert de portées vers le système de stockage:
- Par exemple, Uber utilise les résultats de la trace pour faire la distinction entre le trafic de test et le trafic de production.
- Facebook utilise des données de trace pour analyser le chemin critique et pour basculer le trafic lors des tests de reprise après sinistre réguliers.
- Le réseau social utilise également des blocs-notes Jupyter, qui permettent aux développeurs d'exécuter des requêtes arbitraires sur les résultats du traçage.
- Les adhérents LDFI (Lineage Driven Failure Injection ) utilisent des traces distribuées pour les tests d'erreur.
Aucune des options ci-dessus ne se rapporte entièrement au scénario de
débogage , au cours duquel l'ingénieur essaie de résoudre le problème en examinant la trace.
En ce qui concerne le scénario de débogage, le diagramme
traceview reste l'interface principale (bien que certains l'appellent également le
"diagramme de Gantt" ou le
"diagramme en cascade" ). Par
traceview, je
veux dire toutes les
étendues et les métadonnées associées qui constituent ensemble la trace. Chaque système de trace open source, ainsi que chaque solution de trace commerciale, offre une interface utilisateur basée sur
traceview pour visualiser, détailler et filtrer les données de trace.
Le problème avec tous les systèmes de trace que je connais en ce moment est que la
visualisation finale
(traceview) reflète presque complètement les caractéristiques du processus de génération de trace. Même lorsque des visualisations alternatives sont proposées: cartes d'intensité (heatmap), topologies de service, histogrammes de latence - au final, elles se
résument toujours à
traceview .
Dans le passé, je me
plaignais que la plupart des «innovations» en matière de traçabilité en ce qui concerne l'interface utilisateur / l'expérience utilisateur semblent
se limiter à
inclure des métadonnées supplémentaires dans la trace, à incorporer des informations avec
une cardinalité élevée , ou à fournir la possibilité de parcourir des plages spécifiques ou exécuter des requêtes
inter- et intra-trace . Dans ce cas,
traceview reste le principal moyen de visualisation. Tant que cet état de choses persiste, le traçage distribué occupera (au mieux) la 4e place en tant qu'outil de débogage, suivi des métriques, des journaux et des traces de pile, et au pire, cela se révélera être une perte d'argent et de temps.
Problème avec traceview
Le but de
traceview est de fournir une image complète du mouvement d'une demande individuelle à travers tous les composants d'un système distribué auquel elle se rapporte. Certains systèmes de traçage plus avancés vous permettent d'explorer des plages individuelles et de visualiser la répartition du temps
au sein d'un même processus (lorsque les plages ont des limites fonctionnelles).
Le principe de base de l'architecture de microservices est l'idée que la structure organisationnelle croît avec les besoins de l'entreprise. Les partisans des microservices soutiennent que la distribution de diverses tâches commerciales sur des services distincts permet à de petites équipes de développement autonomes de contrôler l'ensemble du cycle de vie de ces services, leur permettant de créer, tester et déployer ces services de manière indépendante. Cependant, l'inconvénient de cette distribution est la perte d'informations sur la façon dont chaque service interagit avec les autres. Dans de telles circonstances, le traçage distribué prétend être un outil indispensable pour
déboguer les interactions complexes entre les services.
Si vous avez un
système distribué vraiment
incroyablement complexe , alors personne ne peut garder à l'esprit son image
complète . En fait, développer un outil basé sur l'hypothèse qu'il est généralement possible est un peu un contre-modèle (approche inefficace et improductive). Idéalement, le débogage nécessite un outil pour
affiner votre recherche afin que les ingénieurs puissent se concentrer sur un sous-ensemble des dimensions (services / utilisateurs / hôtes, etc.) qui sont pertinentes pour le scénario en question. Pour déterminer la cause de la panne, les ingénieurs ne sont pas tenus de comprendre ce qui s'est passé dans
tous les services à la fois , car une telle exigence contredirait l'idée même d'une architecture de microservice.
Cependant, traceview n'est
que cela. Oui, certains systèmes de trace offrent des vues de trace compressées lorsque le nombre de plages de trace est si important qu'elles ne peuvent pas être affichées dans une seule visualisation. Cependant, en raison de la grande quantité d'informations contenues même dans une visualisation aussi réduite, les ingénieurs sont toujours
obligés de les «filtrer», en limitant manuellement la sélection à un ensemble de sources de problèmes de service. Hélas, dans ce domaine, les machines sont beaucoup plus rapides que les humains, moins sujettes aux erreurs et leurs résultats sont plus reproductibles.
Une autre raison pour laquelle je pense que la méthode traceview est erronée est qu'elle ne convient pas au débogage hypothétique. À la base, le débogage est un processus
itératif commençant par une hypothèse, suivi de la vérification de diverses observations et faits reçus du système à l'aide de différents vecteurs, conclusions / généralisations et une évaluation plus approfondie de la vérité de l'hypothèse.
La capacité
de tester des hypothèses
rapidement et à moindre coût et d'améliorer le modèle mental en conséquence est la
pierre angulaire du débogage. Tout outil de débogage doit être
interactif et restreindre l'espace de recherche ou, dans le cas d'une fausse trace, permettre à l'utilisateur de revenir en arrière et de se concentrer sur une autre zone du système. Un outil idéal le fera de
manière proactive , attirant immédiatement l'attention de l'utilisateur sur les zones potentiellement problématiques.
Hélas,
traceview ne peut pas être appelé un outil d'interface interactive. Le mieux que vous puissiez espérer en l'utilisant est de détecter une certaine source de retards accrus et de visualiser toutes sortes de balises et de journaux qui lui sont associés. Cela n'aide pas l'ingénieur à identifier les
modèles de trafic, tels que les spécificités de la distribution des retards, ou à détecter les corrélations entre les différentes mesures.
L'analyse générique des traces peut contourner certains de ces problèmes. En effet,
il existe des exemples d' analyse réussie utilisant l'apprentissage automatique pour identifier des plages anormales et identifier un sous-ensemble de balises pouvant être associées à un comportement anormal. Néanmoins, je n'ai pas encore rencontré de visualisations convaincantes de découvertes faites à l'aide de l'apprentissage automatique ou de l'analyse de données appliquées à des étendues qui seraient significativement différentes de traceview ou DAG (graphique directionnel acyclique).
Les portées sont trop faibles
Le problème fondamental avec traceview est que les étendues sont des primitives de niveau trop bas pour l'analyse de latence et l'analyse des causes profondes. C'est comme analyser des commandes de processeur individuelles dans le but d'éliminer une exception, sachant qu'il existe des outils de niveau beaucoup plus élevé comme backtrace, qui sont beaucoup plus pratiques à utiliser.
De plus, je me permettrai d'affirmer ce qui suit: idéalement, nous n'avons pas besoin d'une
image complète de ce qui s'est passé pendant le cycle de vie de la demande, que représentent les outils modernes de traçage. Au lieu de cela, une forme d'abstraction de niveau supérieur est requise, contenant des informations sur ce qui
n'a pas fonctionné (similaire à la trace), ainsi qu'un certain contexte. Au lieu d'observer toute la trace, je préfère en voir une
partie où quelque chose d'intéressant ou d'inhabituel se produit. Actuellement, la recherche est effectuée manuellement: l'ingénieur reçoit une trace et analyse indépendamment les portées à la recherche de quelque chose d'intéressant. L'approche lorsque les gens regardent des travées sur des traces distinctes dans l'espoir de détecter une activité suspecte n'est pas du tout mise à l'échelle (en particulier lorsqu'ils doivent comprendre toutes les métadonnées encodées dans différentes travées, telles que l'ID de portée, le nom de la méthode RPC, la durée de la portée 'a, journaux, balises, etc.).
Alternatives à Traceview
Les résultats de traçage sont plus utiles lorsqu'ils peuvent être visualisés de manière à avoir une idée non triviale de ce qui se passe dans les parties interconnectées du système. Jusqu'à ce que ce soit le cas, le processus de débogage reste largement
inerte et dépend de la capacité de l'utilisateur à remarquer les corrélations correctes, à vérifier les bonnes parties du système ou à assembler des morceaux de la mosaïque ensemble - contrairement à l'
outil qui aide l'utilisateur à formuler ces hypothèses.
Je ne suis pas un concepteur visuel ou un spécialiste UX, mais dans la section suivante, je veux partager quelques idées sur l'apparence de telles visualisations.
Focus sur des services spécifiques
Dans un environnement où l'industrie se consolide autour des idées de
SLO (objectifs de niveau de service) et de SLI (indicateurs de niveau de service) , il semble raisonnable que les équipes individuelles surveillent d'abord la pertinence de leurs services par rapport à ces objectifs. Il s'ensuit que
la visualisation
orientée service est la mieux adaptée à de telles équipes.
Les traces, en particulier sans échantillonnage, sont un réservoir d'informations sur chaque composant d'un système distribué. Ces informations peuvent être transmises à un gestionnaire délicat qui fournira aux utilisateurs des découvertes orientées
service , qui peuvent être détectées à l'avance - avant même que l'utilisateur ne regarde les traces:
- Diagrammes de distribution des retards uniquement pour les demandes fortement distinguées (demandes aberrantes) ;
- Diagrammes de distribution des retards pour les cas où les objectifs de service SLO ne sont pas atteints;
- Les balises les plus «communes», «intéressantes» et «étranges» dans les requêtes, qui sont le plus souvent répétées ;
- Répartition des retards pour les cas où les dépendances de service n'atteignent pas les objectifs SLO définis;
- Répartition des retards pour divers services en aval.
Les métriques intégrées ne peuvent tout simplement pas répondre à certaines de ces questions, forçant les utilisateurs à étudier attentivement les portées. En conséquence, nous avons un mécanisme extrêmement hostile à l'utilisateur.
À cet égard, la question se pose: qu'en est-il des interactions complexes entre les différents services contrôlés par différentes équipes?
Traceview n'est-il pas considéré comme l'outil le plus approprié pour couvrir une telle situation?
Les développeurs mobiles, les propriétaires de services sans état, les propriétaires de services gérés avec état (comme les bases de données) et les propriétaires de plates-formes peuvent être intéressés par une autre
vision d'un système distribué;
traceview est une solution beaucoup trop universelle pour ces besoins fondamentalement différents. Même dans une architecture de microservices très complexe, les propriétaires de services n'ont pas besoin d'une connaissance approfondie de plus de deux ou trois services en amont et en aval. En substance, dans la plupart des scénarios, les utilisateurs n'ont qu'à répondre à des questions concernant un
ensemble limité de services .
C'est comme regarder un petit sous-ensemble de services à travers une loupe pour une étude minutieuse. Cela permettra à l'utilisateur de poser des questions plus pressantes concernant l'interaction complexe entre ces services et leurs dépendances immédiates. Ceci est similaire à la trame dans le monde des services, où l'ingénieur sait
ce qui ne va pas et a également une idée de ce qui se passe dans les services environnants pour comprendre
pourquoi .
L'approche que je préconise est l'exact opposé de l'approche descendante basée sur traceview, lorsque l'analyse commence par la trace entière, puis descend progressivement vers des travées individuelles. Au contraire, l'approche ascendante commence par l'analyse d'une petite zone proche de la cause potentielle de l'incident, puis l'espace de recherche est élargi si nécessaire (avec la participation éventuelle d'autres équipes pour analyser une gamme plus large de services). La seconde approche est mieux adaptée pour tester rapidement les hypothèses initiales. Après avoir obtenu des résultats spécifiques, il sera possible de passer à une analyse plus ciblée et détaillée.
Construction de la topologie
Les vues associées à un service particulier peuvent être incroyablement utiles si l'utilisateur sait
quel service ou groupe de services est responsable de l'augmentation des retards ou est une source d'erreurs. Cependant, dans un système complexe, l'identification d'un intrus peut ne pas être une tâche triviale lors d'une panne, surtout si aucun message d'erreur n'a été reçu des services.
La création d'une topologie de service peut être très utile pour déterminer quel service affiche une augmentation du taux d'erreur ou une augmentation de la latence, entraînant une détérioration notable des performances du service. Parlant de la construction d'une topologie, je ne parle pas d'
une carte de service qui affiche tous les services disponibles dans le système et connus pour leurs
cartes d'architecture sous la forme d'une étoile de la mort . Une telle représentation n'est pas meilleure qu'une trace vue basée sur un graphe acyclique dirigé. Au lieu de cela, j'aimerais voir une
topologie de service générée dynamiquement basée sur certains attributs, tels que le taux d'erreur, le temps de réponse ou tout paramètre spécifié par l'utilisateur qui aide à clarifier la situation avec des services suspects spécifiques.
Regardons un exemple. Imaginez un site de nouvelles hypothétique. Le service de
première page communique avec Redis, avec un service de recommandation, avec un service de publicité et un service vidéo. Le service vidéo prend des vidéos de S3 et les métadonnées de DynamoDB. Le service de recommandation reçoit les métadonnées de DynamoDB, télécharge les données de Redis et MySQL, écrit des messages dans Kafka. Le service de publicité reçoit des données de MySQL et écrit des messages à Kafka.
Ce qui suit est une représentation schématique de cette topologie (de nombreux programmes de routage commerciaux construisent la topologie). Cela peut être utile si vous avez besoin de comprendre les dépendances des services. Cependant, lors du
débogage , lorsqu'un certain service (par exemple, un service vidéo) affiche un temps de réponse accru, une telle topologie n'est pas très utile.
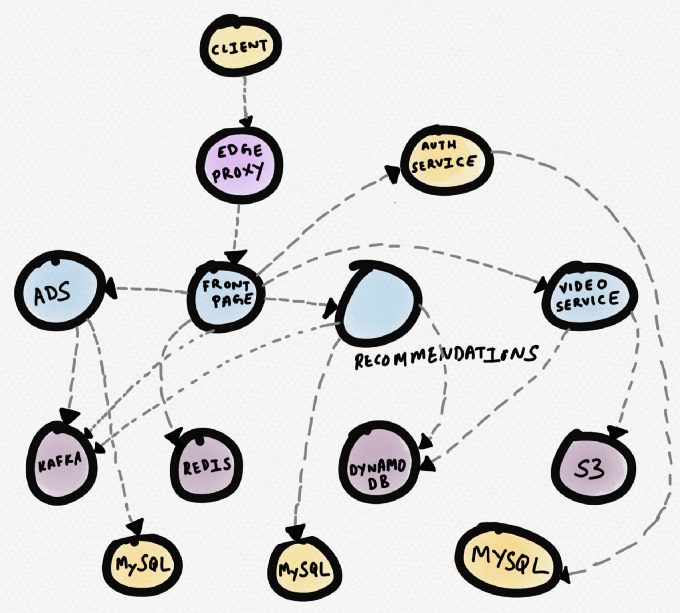 Système de services de site de nouvelles hypothétiques
Système de services de site de nouvelles hypothétiquesLe diagramme ci-dessous serait mieux. Un service problématique
(vidéo) y est représenté en plein centre. L'utilisateur le remarque immédiatement. De cette visualisation, il devient clair que le service vidéo fonctionne anormalement en raison de l'augmentation du temps de réponse de S3, ce qui affecte la vitesse de téléchargement d'une partie de la page principale.
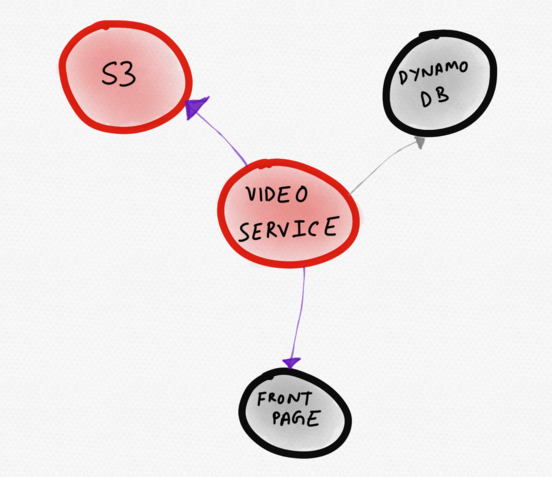 Topologie dynamique qui affiche uniquement les services «intéressants»
Topologie dynamique qui affiche uniquement les services «intéressants»Les schémas topologiques générés dynamiquement peuvent être plus efficaces que les cartes de service statiques, en particulier dans les infrastructures flexibles et évolutives. La possibilité de comparer et de contraster les topologies de services permet à l'utilisateur de poser des questions plus pertinentes. Des questions plus précises sur le système sont plus susceptibles de conduire à une meilleure compréhension du fonctionnement du système.
Affichage comparatif
Une autre visualisation utile serait un affichage comparatif. Les traces ne sont actuellement pas bien adaptées aux comparaisons côte à côte, de sorte que les
plages sont généralement comparées. Et l'idée principale de cet article est précisément que les intervalles sont trop bas pour extraire les informations les plus précieuses des résultats de la trace.
La comparaison de deux traces'ov ne nécessite pas de visualisations fondamentalement nouvelles. En fait, quelque chose comme un histogramme représentant les mêmes informations que traceview suffit. Étonnamment, même cette méthode simple peut apporter beaucoup plus de fruits qu'une simple étude de deux traces séparément. Encore plus puissant serait la possibilité de
visualiser la comparaison des traces
dans l'agrégat . Il serait extrêmement utile de voir comment un changement de configuration de base de données récemment déployé avec l'inclusion de GC (garbage collection) affecte le temps de réponse d'un service en aval en quelques heures. Si ce que je décris ici ressemble à une analyse A / B de l'impact des changements d'infrastructure
dans une variété de services en utilisant des résultats de trace, alors vous n'êtes pas trop loin de la vérité.
Conclusion
Je ne remets pas en question l'utilité de la trace elle-même. Je crois sincèrement qu'il n'y a pas d'autre moyen de collecter des données aussi riches, informelles et contextuelles que celles contenues dans la trace. , . , traceview-, , , trace'. , , .
, , . ,
, . , production , , , , .
, , , , , . , , , trace' span'.
( UI). , , . , . . .
PS du traducteur
Lisez aussi dans notre blog: