Remarque perev. : Nous sommes heureux de partager la traduction du merveilleux matériel de l'évangéliste technologique senior d'AWS - Adrian Hornsby. En termes simples, il explique l'importance des expériences conçues pour atténuer les conséquences des défaillances des systèmes informatiques. Vous avez probablement déjà entendu parler de Chaos Monkey (ou même utilisé des solutions similaires)? Aujourd'hui, les démarches pour la création de tels outils et leur mise en œuvre dans un contexte plus large sont menées dans le cadre d'une activité appelée ingénierie du chaos. En savoir plus à ce sujet dans cet article.
"Mais derrière toute cette beauté se cache le chaos et la folie." - murs tanneurs
Les pompiers . Ces spécialistes hautement qualifiés risquent leur vie chaque jour en combattant le feu. Savez-vous qu'avant de devenir pompier, vous devez passer au moins 600 heures en formation? Et ce n'est qu'un début. Selon les rapports, les pompiers forment jusqu'à 80% de leur temps de travail.
Pourquoi?
Lorsqu'un pompier lutte contre un véritable incendie, il a besoin d'une
intuition appropriée. Pour le développer, il faut s'entraîner heure après heure, jour après jour. Comme on dit, la pratique fait des merveilles.
«Il semble qu'ils pénètrent l'essence même du feu; de tels analogues du Dr Phil pour la flamme. " - Lutter contre les incendies de forêt avec les ordinateurs et l'intuition
Remarque perev. : Phillip Calvin «Phil» McGraw est un psychologue américain, écrivain, présentateur de l'émission de télévision populaire «Doctor Phil», dans laquelle le présentateur propose à ses participants des solutions à leurs problèmes.Il était une fois à Seattle
Au début des années 2000,
Jesse Robbins , qui occupait un poste officiel en Amazonie sous le nom officiel de
Master of Disaster , a créé et dirigé le programme GameDay. Il était basé sur son expérience de pompier. GameDay a été conçu pour tester, éduquer et préparer divers systèmes, logiciels et personnes Amazon pour des situations de crise potentielles.
Tout comme les pompiers développent l'intuition pour combattre les incendies, Jesse était sur le point d'aider son équipe à développer l'intuition pour contrer les événements catastrophiques à grande échelle.
"GameDay: Créer de la résilience par la destruction" - Jesse RobbinsGameDay a été conçu pour augmenter la résilience du site de vente au détail d'Amazon en introduisant délibérément des erreurs dans les systèmes critiques.
GameDay a commencé par une série d'annonces pour toute l'entreprise qu'une alarme de formation était prévue - parfois à très grande échelle, par exemple, la désactivation d'un centre de données complet. Les détails sur la fermeture planifiée ont été minimes et l'équipe a eu plusieurs mois pour se préparer. L'objectif principal de l'exercice était de vérifier si le personnel peut faire face à la crise locale et éliminer rapidement ses conséquences.
Au cours de ces exercices, des outils et processus spéciaux, tels que la surveillance, les alertes et les appels urgents, ont été utilisés pour analyser et identifier les erreurs dans les procédures de réponse aux incidents. Il s'est avéré que GameDay révèle parfaitement les problèmes architecturaux classiques. Parfois, il était également possible de détecter les soi-disant «vices cachés» - des problèmes se manifestant en raison des spécificités de l'incident. Par exemple, les systèmes de gestion des incidents essentiels au processus de récupération ont échoué en raison d'effets secondaires inattendus causés par un problème d'origine humaine.
Au fur et à mesure que la société grandissait, le rayon théorique de la défaite de GameDay s'élargissait. Au final, ces exercices se sont arrêtés: les dommages potentiels à l'entreprise devenaient trop importants en cas de problème. Depuis lors, le programme a dégénéré en une série d'expériences commerciales disparates et sans impact pour la formation du personnel dans les situations de crise. Je n'entrerai pas dans les détails des expériences dans cet article, mais je le ferai à l'avenir. Cette fois, je veux discuter de l'idée importante qui sous-tend GameDay: l'
ingénierie de la résilience , également connue sous le nom d'
ingénierie du chaos .
Monkey Rise
Vous avez probablement entendu parler de Netflix, le fournisseur de contenu vidéo en ligne. Netflix a commencé à passer de son propre centre de données à AWS Cloud en août 2008. Cette étape a été causée par de graves dommages à la base de données, à cause desquels la livraison du DVD a été retardée de trois jours (oui, Netflix a commencé par envoyer des films par courrier ordinaire). La migration vers le cloud était associée à la nécessité de supporter des charges de streaming beaucoup plus élevées, ainsi qu'au désir d'abandonner l'architecture monolithique et de passer à des microservices faciles à mettre à l'échelle en fonction du nombre d'utilisateurs et de la taille de l'équipe d'ingénierie. La partie utilisateur du service de streaming est d'abord passée à AWS, entre 2010 et 2011, suivie par l'informatique d'entreprise et toutes les autres structures. Le centre de données de Netflix a fermé ses portes en 2016. La société mesure l'accessibilité comme un rapport entre le nombre de tentatives réussies de lancement d'un film et le nombre total, et non comme une simple comparaison du temps de disponibilité et des temps d'arrêt, et essaie d'atteindre un chiffre de 0,9999 dans chaque région sur une base trimestrielle (souvent cela réussit). L'architecture globale de Netflix s'étend sur trois régions AWS. Ainsi, en cas de problème dans l'une des régions, l'entreprise a la possibilité de rediriger les utilisateurs vers d'autres.
Je répète une de mes citations préférées:
«L'échec est inévitable; à terme, tout système tombera en panne avec le temps. » - Werner Vogels
En fait, les défaillances des systèmes distribués, en particulier ceux à grande échelle, sont inévitables même dans le cloud. Cependant, le cloud AWS et ses primitives de redondance - en particulier, le
principe des zones d'accès multiples sur lesquelles il est construit - permet à quiconque de concevoir des services hautement fiables.
En utilisant les principes de redondance et de
dégradation gracieuse , Netflix a
réussi à survivre aux défaillances sans affecter les utilisateurs finaux.
Dès le début, Netflix a adhéré aux principes architecturaux les plus stricts. L'une des premières applications qu'ils ont déployées sur AWS a été leur
Chaos Monkey - pour prendre en charge les microservices sans état à l'échelle automatique. En d'autres termes, toute instance peut être arrêtée et remplacée automatiquement sans aucune perte d'état. Chaos Monkey garantit que personne ne viole ce principe.
Remarque perev. : Soit dit en passant, pour Kubernetes, il existe un analogue appelé kube-singe , dont le développement semble s'être arrêté en mars de cette année.Netflix a une règle de plus, qui prévoit la distribution de chaque service dans trois zones de disponibilité. Il devrait continuer à fonctionner si seulement deux d'entre eux sont disponibles. Pour garantir le respect de cette règle,
Chaos Gorilla désactive les zones de disponibilité. Plus globalement,
Chaos Kong est capable de désactiver l'intégralité de la région AWS pour confirmer que tous les utilisateurs de Netflix peuvent être servis à partir de l'une des trois régions. Et ils font ces tests à grande échelle toutes les quelques semaines en production pour s'assurer que rien n'échappe à l'attention.
Enfin, Netflix a également développé des
outils de test du chaos plus ciblés pour aider à détecter les problèmes liés aux microservices et à l'architecture de stockage. Vous pouvez en savoir plus sur ces techniques dans le livre Chaos Engineering, que je recommande à toute personne intéressée par ce sujet.
«En effectuant régulièrement des expériences qui imitent les pannes régionales, nous avons pu identifier divers défauts systémiques et les éliminer à un stade précoce.» - Blog Netflix
Aujourd'hui, les principes de l'ingénierie du chaos sont
formalisés ; on leur donne la définition suivante:
«L'ingénierie du chaos est une approche qui consiste à mener des expériences sur un système de production pour garantir sa capacité à résister aux diverses interférences qui se produisent pendant le fonctionnement.» - Principlesofchaos.org
Cependant, dans un
discours à AWS re: Invent 2018 sur l'ingénierie du chaos,
Adrian Cockcroft , un ancien créateur de l'architecture cloud Netflix, qui a aidé l'entreprise à passer entièrement à l'infrastructure cloud, a introduit une définition alternative de l'ingénierie du chaos. À mon avis, il est plus précis et bien établi:
«L'ingénierie du chaos est une expérience conçue pour atténuer les conséquences des échecs.»
En fait, nous savons que les plantages se produisent tout le temps. Avec la bonne réponse, ils ne devraient pas affecter les utilisateurs finaux. L'objectif principal de l'ingénierie du chaos est de détecter les problèmes qui ne sont pas résolus correctement.
Prérequis pour créer le chaos
Avant de vous lancer dans l'ingénierie du chaos, assurez-vous de faire tout le travail nécessaire pour assurer la durabilité à tous les niveaux de l'organisation. La création de systèmes tolérants aux pannes ne concerne pas uniquement les logiciels. Il commence au niveau de l'
infrastructure , s'étend au
réseau et aux données , affecte la structure des
applications et englobe finalement les
personnes et la culture . Dans le passé, j'ai beaucoup écrit sur les modèles de stabilité et les échecs (
ici ,
ici ,
ici et
ici ) et je ne vais pas me concentrer là-dessus maintenant, mais je ne peux pas me passer d'un petit rappel.
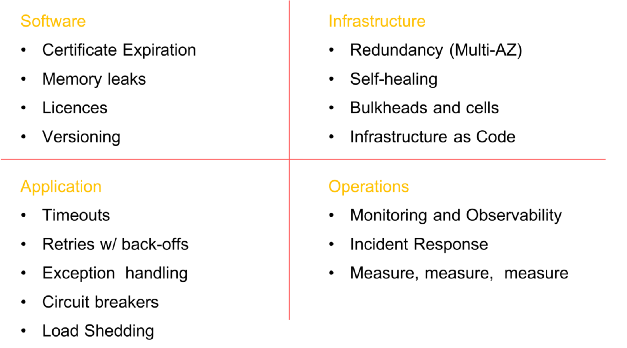 Quelques éléments obligatoires avant d'introduire le chaos dans le système (la liste n'est pas exhaustive)
Quelques éléments obligatoires avant d'introduire le chaos dans le système (la liste n'est pas exhaustive)Étapes de l'ingénierie du chaos
Il est important de comprendre que l'essence de l'ingénierie du chaos n'est
PAS de laisser les singes se déchaîner et de les laisser détruire tout de suite, sans but. Le but de cette discipline est de détruire certains éléments du système dans un environnement contrôlé grâce à des expériences bien planifiées pour vérifier si votre application peut résister à des conditions turbulentes.
Pour ce faire, vous devez suivre le processus formalisé clairement défini illustré dans la figure ci-dessous. Avec lui, vous pouvez passer de la compréhension de l'état stationnaire de votre système à la formulation d'une hypothèse, la tester et, enfin, analyser l'expérience acquise au cours de l'expérience et augmenter la stabilité du système lui-même.
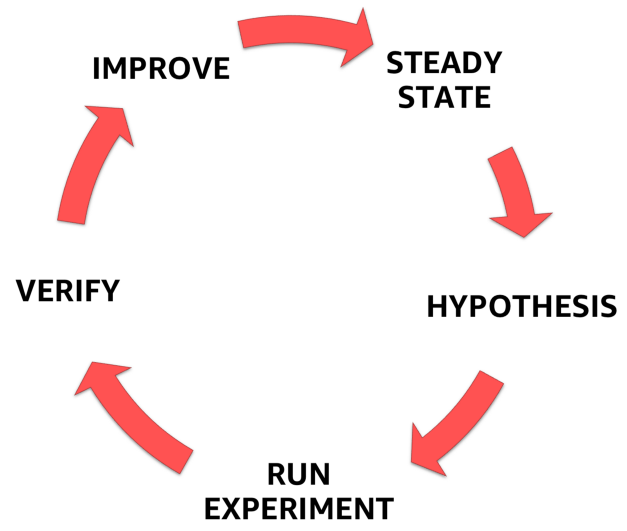 Étapes de l'ingénierie du chaos
Étapes de l'ingénierie du chaos1. État stable
L'un des éléments les plus importants de l'ingénierie du chaos est de comprendre le comportement d'un système dans des conditions normales.
Pourquoi? C'est simple: après l'introduction d'une défaillance artificielle, vous devez vous assurer que le système est revenu à un état stable bien étudié et que l'expérience n'interfère plus avec son comportement normal.
Le point clé ici est que vous devez vous concentrer non pas sur les attributs internes du système (processeur, mémoire, etc.), mais pour surveiller les signaux de sortie mesurables qui connectent les performances à l'expérience utilisateur. Pour que ces signaux de sortie soient dans un état stable, le comportement observé du système doit avoir un schéma prévisible, mais changer de manière significative lorsqu'un dysfonctionnement se produit dans le système.
Compte tenu de la
définition de l'ingénierie du chaos proposée ci-dessus par Adrian Cockcroft, cet état stable change lorsqu'une défaillance incontrôlée provoque un problème inattendu et signale que l'expérience du chaos doit être interrompue.
À titre d'exemple de conditions stables, citons l'expérience d'Amazon. La société utilise le nombre de commandes comme l'une des mesures d'un état stable, et pour une bonne raison. En 2007, Greg Linden, qui travaillait auparavant chez Amazon, a expliqué comment, dans le cadre d'une expérience utilisant la méthode de
test A / B, il a essayé de ralentir le temps de chargement des pages sur le site par incréments de 100 ms et a constaté que même de légers retards résultaient à une grave baisse des revenus. Avec une augmentation du temps de chargement de 100 ms, le nombre de commandes (et donc de ventes) a diminué de 1%. C'est pourquoi le nombre de commandes est un excellent candidat pour des mesures stables.
Netflix utilise une métrique côté serveur associée au début de la lecture - le nombre de clics sur le bouton de lecture. Ils ont constaté une régularité dans le comportement de l'indicateur SPS (démarrages par seconde) et ses fluctuations importantes en cas de défaillance du système. La métrique est appelée "Pulse of Netflix" (
Pulse of Netflix ).
Le nombre de commandes dans le cas d'Amazon et de Netflix Pulse sont d'excellents baromètres de stabilité, car ils combinent l'expérience utilisateur et les mesures opérationnelles en un seul indicateur mesurable et hautement prévisible.
Mesurer, mesurer et mesurer à nouveau
Il va sans dire que si vous n'êtes pas en mesure d'enregistrer correctement les performances du système, vous ne pourrez pas surveiller les changements dans un état stable (ni même les détecter). Portez une attention particulière à la suppression de tous les paramètres / indicateurs du réseau, du matériel et à la fin de l'application et des personnes. Tracez des graphiques de ces mesures, même si elles ne changent pas avec le temps. Vous serez surpris de découvrir des corrélations dont vous n'étiez pas au courant.
«Rendez le plus facile possible aux ingénieurs l'accès aux données qu'ils peuvent compter ou traduire sous forme graphique.» - Ian Malpass
2. Hypothèse
Après avoir traité d'un état stable, nous pouvons procéder à la formulation d'une hypothèse.

- Et si le mécanisme de recommandation s'arrête?
- Et si l'équilibreur de charge tombe?
- Et si la mise en cache tombe?
- Et si le retard augmente de 300 ms?
- Et si la base principale tombe en panne?
Bien entendu, une seule hypothèse doit être retenue et il n'est pas nécessaire de la compliquer inutilement. Commencez petit. J'aime commencer par l'hypothèse du personnel. Avez-vous entendu parler du
facteur bus ? Le facteur bus est une mesure de risque associée au fait que les connaissances ne sont pas réparties également entre les membres de l'équipe. Il vous permet de calculer le nombre minimum de participants, après une perte soudaine dont le projet s'arrêtera par manque de connaissances ou d'expérience.
De nombreuses entreprises disposent d'experts techniques dont la disparition soudaine («heurtée par un bus») aura un effet dévastateur sur le projet et l'équipe. Identifiez ces personnes et menez des expériences de chaos avec leur participation: par exemple, prenez-leur des ordinateurs et renvoyez-les chez eux pendant une journée, puis observez les résultats (souvent chaotiques).
Rendez le problème commun à tous!
Engager
toute l'équipe à développer une hypothèse. Laissez tout le monde participer au brainstorming: le propriétaire du produit, le responsable technique, les développeurs backend et frontend, les concepteurs, les architectes, etc. Toute personne connectée d'une manière ou d'une autre au produit.
Tout d'abord, demandez à chacun d'écrire sa propre réponse à la question "Et si ...?" sur un morceau de papier. Vous verrez que dans la plupart des cas, chacun aura sa propre réponse, et vous comprendrez qu'une partie de l'équipe n'a toujours pas pensé à un tel problème.
Arrêtez-vous à ce stade et discutez des raisons pour lesquelles les membres de l'équipe ont une vision différente du comportement du produit dans le cas de «Et si ...?». Revenez à ses spécifications et assurez-vous que tout le monde comprend correctement l'évolution possible des événements.
Prenons, par exemple, le site de vente au détail d'Amazon mentionné. Que se passe-t-il si le service Acheter par catégorie cesse de se charger sur la page principale?

Dois-je retourner une erreur 404? Vaut-il la peine de charger la page, en laissant un espace vide comme dans la capture d'écran ci-dessous?

Vaut-il la peine de sacrifier une partie de la fonctionnalité et, par exemple, de laisser la page se développer et masquer l'erreur?
Et ce n'est que du côté de l'interface utilisateur. Que doit-il se passer dans le backend? Faut-il envoyer des alertes? Un service défaillant doit-il continuer à recevoir des demandes à chaque fois que l'utilisateur charge la page d'accueil, ou le backend doit-il le couper complètement?
Et le dernier. Veuillez ne pas formuler d'hypothèse, qui est connue à l'avance qu'elle cassera le bois de chauffage! Expérimentez avec des parties du système qui, à votre avis, sont stables - en fin de compte, c'est tout l'intérêt de l'expérience.3. Concevez et exécutez une expérience
- Choisissez une hypothèse;
- Définir la portée de l'expérience;
- Définir les indicateurs associés à mesurer;
- Avertissez l'organisation.
Aujourd'hui, de nombreuses personnes, ainsi que le site Web Principlesofchaos, promeuvent l'idée de l'ingénierie du chaos dans la production. Bien que cela devrait être l'objectif ultime, la plupart des organisations ont peur de cette approche, vous ne devez donc pas commencer par elle.
Pour moi, l'ingénierie du chaos n'est pas seulement la destruction de divers éléments des systèmes de production. Ceci est un voyage. Un voyage dans le monde de la connaissance, inextricablement lié à des activités telles que la destruction de systèmes dans un environnement contrôlé - tout environnement, qu'il s'agisse d'un environnement de développement local, bêta, mise en scène ou prod. Destruction grâce à des expériences bien conçues pour renforcer la confiance dans la capacité de votre application à tolérer des conditions turbulentes. «
Bâtir la confiance » est un point clé dans ce cas, car il est un précurseur des changements culturels nécessaires à la mise en œuvre réussie de l'ingénierie du chaos et à la pratique d'améliorer la fiabilité dans votre entreprise.
Honnêtement, la plupart des équipes apprendront beaucoup en cassant les choses même dans un environnement non productif. Essayez simplement de créer une
docker stop database de
docker stop database dans votre environnement local et voyez si vous pouvez résoudre ce problème sans conséquences. Forte probabilité que non.
Arrêt de la base de données - ExempleCommencez petit et renforcez progressivement la confiance au sein de votre équipe et de votre organisation. On vous dira que «le trafic de production réel est le seul moyen de capturer de manière fiable le comportement du système». Écoutez, souriez et continuez lentement à faire ce que vous faites. La pire chose que vous puissiez faire est d'appliquer l'ingénierie du chaos à la production et d'échouer lamentablement. Après cela, personne ne vous fera confiance et vous serez obligé d'oublier les «singes du chaos» pour toujours.
Gagnez en crédibilité en premier. Montrez aux organisations et à vos collègues que vous savez ce que vous faites. Devenez pompier et apprenez-en le plus possible sur la flamme avant de vous entraîner avec le tir réel. Gagnez en crédibilité. Rappelez-vous l'
histoire de la tortue et du lièvre ? La course est toujours gagnée par une course lente et patiente.
L'un des points les plus importants de l'expérience est de comprendre le
rayon potentiel
des dommages causés par le dysfonctionnement que vous introduisez et de le minimiser. Posez-vous les questions suivantes:
- Combien de clients seront affectés par l'expérience?
- Quelle fonctionnalité en souffrira?
- Quels endroits seront touchés?
Pensez à un «bouton d'arrêt d'urgence» ou à un moyen de terminer immédiatement une expérience et de revenir à un état stable dès que possible. J'aime mener des expériences en utilisant ce qu'on appelle. Déploiements "Canaries". Cette technique réduit le risque d'échec lors du lancement de nouvelles versions d'une application en production en déployant progressivement les modifications sur un petit sous-ensemble d'utilisateurs, puis en les répartissant lentement sur l'ensemble de l'infrastructure et sur tous les utilisateurs. J'adore les déploiements canaris simplement parce qu'ils satisfont au principe d'une
infrastructure fixe , et l'expérience elle-même est assez facile à arrêter.
 Un exemple de déploiement d'un canari basé sur DNS pour des expériences de chaos
Un exemple de déploiement d'un canari basé sur DNS pour des expériences de chaosSoyez prudent avec les expériences qui modifient l'état de l'application (cache ou base de données) ou celles qui ne peuvent pas être annulées (facilement ou en principe).
Il est curieux qu'Adrian Cockcroft m'ait dit que l'une des raisons pour lesquelles Netflix a commencé à utiliser les bases de données NoSQL était le manque de schémas de modifications ou de restaurations, il est donc beaucoup plus facile de mettre à jour ou de corriger progressivement des enregistrements individuels avec des données (c'est-à-dire qu'ils amical à l'ingénierie du chaos).
4. Observer et apprendre
Afin d'apprendre quelque chose de nouveau et de suivre la progression de l'expérience, vous devez être en mesure de suivre les performances du système. Comme mentionné précédemment, portez une attention maximale à toutes sortes de mesures et de paramètres! Quantifiez ensuite les résultats et toujours - toujours! - Notez le temps jusqu'à l'apparition des premiers signes d'un problème. Dans mon histoire, il est arrivé à plusieurs reprises que les systèmes d'alerte refusent et le premier à signaler le problème aux clients sur Twitter ... croyez-moi, vous ne voudrez pas être dans cette situation, alors utilisez des expériences de chaos pour vérifier vos systèmes de surveillance et d'alerte.
- Il est temps de découvrir?
- Il est temps d'alerter et de commencer une action active?
- Il est temps de rendre public l'avis?
- Temps de perte partielle de fonctionnalité?
- La durée de la période d'auto-guérison?
- Temps de récupération complète ou partielle?
- Il est temps de mettre fin à la crise et de revenir à un état stable?
N'oubliez pas qu'il n'y a pas une seule cause de défaillance isolée. Les accidents majeurs sont toujours le résultat de plusieurs petites défaillances qui s'accumulent et conduisent à une crise de grande ampleur.
Effectuez une analyse post-mortem détaillée pour chaque expérience!Chez AWS, nous accordons une grande attention à l'analyse des défaillances détectées et à la compréhension des causes qui les ont amenées à éviter des problèmes similaires à l'avenir. Toutes les conclusions et les résultats de l'expérience sont résumés dans un document appelé Correction des erreurs (COE). COE nous permet d'apprendre de nos erreurs, qu'elles soient défectueuses en termes de technologie, de processus ou même d'organisation. Nous utilisons ce mécanisme pour éliminer les causes profondes des pannes et du développement continu.
La clé du succès dans ce processus est l'ouverture et la transparence concernant ce qui a mal tourné. L'un des principes les plus importants lors de la rédaction d'un bon COE est d'être impartial et d'éviter de mentionner des personnes spécifiques. Ceci est souvent difficile dans un environnement qui n'encourage pas un tel comportement et ne permet pas d'échec. Amazon utilise une collection de
principes de
leadership pour promouvoir ce comportement - par exemple,
l'autocritique, une approche analytique, l'engagement envers les normes les plus élevées et la responsabilité sont des éléments clés du processus COE et de l'excellence opérationnelle en général.
Le rapport du COE comprend cinq sections principales:
- Que s'est-il passé (ordre chronologique)?
- Quel a été l'impact sur les clients?
- Pourquoi l'erreur s'est-elle produite? ( Cinq «pourquoi?» )
- Qu'avons-nous appris?
- Comment éviter cela à l'avenir?
Il est plus difficile de répondre à ces questions qu'à première vue, car vous devez vous assurer que chaque moment incompréhensible / inconnu est soigneusement étudié.
Afin de faire du mécanisme COE un processus à part entière, nous effectuons en permanence des contrôles sous forme de réunions hebdomadaires avec une analyse obligatoire des métriques opérationnelles. De plus, des experts techniques de premier plan effectuent des revues métriques hebdomadaires avec tout le personnel AWS.
5. Corrigez et améliorez!
La leçon principale ici est
, tout d'abord, d'éliminer les problèmes identifiés lors des expériences de chaos, en leur accordant une priorité plus élevée que le développement de nouvelles fonctions . Engager la haute direction dans ce processus et lui présenter l'idée que la résolution des problèmes actuels est beaucoup plus importante que le développement de nouvelles fonctionnalités.
Une fois, à l'aide d'une expérience de chaos, j'ai aidé un client à identifier des problèmes de stabilité critiques, mais en raison de la pression du service des ventes, la priorité du correctif a été réduite et tous les efforts ont été dirigés vers l'introduction d'une nouvelle chose qui est «extrêmement importante» pour les clients. Deux semaines plus tard, un temps d'arrêt de 16 heures a forcé l'entreprise à s'attaquer aux mêmes problèmes que nous avions identifiés lors de l'expérience du chaos. Seules les pertes étaient beaucoup plus élevées.
Les avantages de l'ingénierie du chaos
Les avantages sont nombreux. Je vais en souligner deux, à mon avis, les plus importantes:
Premièrement, l'ingénierie du chaos permet de résoudre des problèmes inconnus dans le système et de les résoudre avant qu'ils n'entraînent une défaillance de la production, disons dimanche à 3 heures du matin. Autrement dit, il
augmente la résistance aux chocs et, en fait, la qualité du sommeil .
Deuxièmement, des expériences de chaos menées avec efficacité provoquent toujours des changements plus importants (principalement culturels) que prévu. Le plus important d'entre eux est peut-être l'évolution naturelle vers une
culture " sans reproche" , lorsque la question "Pourquoi avez-vous fait cela?" se transforme en "Comment pouvons-nous éviter cela à l'avenir?". En conséquence, l'équipe devient plus heureuse, plus efficace, plus intéressée et plus performante.
Et c'est magnifique!Sur ce point, la première partie prend fin. J'espère que ça vous a plu. Veuillez écrire des avis, partager des opinions ou simplement taper des mains chez
Medium . Dans la partie suivante, j'examinerai les outils et les techniques pour introduire les défaillances du système. Jusqu'à - au revoir!
Pour ceux qui sont désireux de se familiariser avec la deuxième partie, je propose ma présentation sur le thème de l'ingénierie du chaos au NDC à Oslo. J'y parle de plusieurs de mes outils préférés:
PS du traducteur
La deuxième partie de l'article en anglais est déjà parue et nous la traduirons également si nous voyons un intérêt suffisant des lecteurs du Habré pour ce matériel - les commentaires pertinents sur l'article sont les bienvenus! MISE À JOUR (3 septembre): Une traduction de la deuxième partie est également
publiée .
MISE À JOUR (19 décembre): La
traduction de la troisième partie est devenue disponible.
Lisez aussi dans notre blog: