Bonjour à tous, nous avons récemment
écrit sur la façon dont nous avons appris à être pilotés par les données avec GoPractice Simulator! Dans ce numéro, nous continuerons le sujet de l'analyse des données et parlerons de la construction du processus de travail avec l'analyse dans l'équipe Plesk.
Plesk est un produit complexe avec une expérience de 20 ans et nous n'avons pas toujours été en mesure de collecter efficacement les statistiques nécessaires. Pendant longtemps, nous n'avons examiné les données que rétrospectivement, et les décisions ont été prises sur la base de sensations subjectives «comme il se doit». Dans le passé, nous avions déjà eu les tristes conséquences de cette approche - en 2012, nous avons changé la conception, voulant faire de notre mieux, mais nous avons reçu une vague de commentaires négatifs, le refus de mettre à jour vers la dernière version du produit et la sortie des clients.
Ayant compris cette triste expérience, nous avons tiré des conclusions et décidé d'aller vers la création d'une entreprise Data Driven. Sur ce chemin, des difficultés de nature différente nous attendaient. À grande échelle, ils peuvent être divisés en deux groupes principaux - système et processus, et dans cet article, je me concentrerai sur la tâche de construire le processus de travail avec l'analyse.
Les problèmes systémiques associés aux spécificités du produit en boîte méritent un article séparé, je ne m'attarderai donc pas là-dessus en détail, je ne citerai que les plus importants.
- Nombreux événements, volumes d'utilisation élevés. Si nous ne parlons que du suivi des actions des utilisateurs dans le panneau, selon nos estimations, cela représente 60 millions d'événements par mois, et il est dommage de donner 150 000 $ pour Advanced Google Analytics. Une autre difficulté est que pour travailler avec GA, vous devez traiter explicitement chaque action personnalisée, mais nous voulions obtenir un mécanisme unifié qui ne nécessite pas de baliser manuellement les événements ou les actions pour chaque nouvelle fonctionnalité.
- En raison du volume et du format de la boîte (le déploiement de toute modification prend du temps), l'analyse ne peut pas être effectuée en temps réel. Les utilisateurs sont assis sur 8 versions différentes du produit, dont 4 sont déjà en fin de vie. Même sur les dernières versions, seuls 60% des utilisateurs apportent de nouvelles modifications dans les deux premières semaines après leur sortie.
- Produit complexe. Plesk prend en charge 14 systèmes d'exploitation de la famille Linux, 4 OC Windows, un composant tiers 150, plusieurs serveurs Web, serveurs de messagerie, clients de messagerie Web, visualiseurs de statistiques, solutions antivirus, etc. Un grand nombre de configurations possibles affecte principalement la complexité et le volume des tests et rend presque impossible l'utilisation des tests A / B.
- Spécificités B2B2C. Le décideur n'est pas toujours égal au «véritable utilisateur du panel».
- RGPD - la nécessité de se conformer à la lettre de la loi nécessite des efforts supplémentaires pour anonymiser les données et complique les tâches de segmentation des utilisateurs, et nous prive également de la possibilité de contacter facilement et rapidement les clients en utilisant leurs coordonnées.
Nous parlerons des douleurs de processus plus en détail. Jusqu'à récemment, le processus de collecte des analyses avec nous était complètement dissocié du processus de développement - nous nous sommes souvenus du suivi et des mesures à la fin, avons foutu une solution unique, et ainsi de suite jusqu'à la prochaine fonctionnalité. De plus, au fil des ans, Plesk a accumulé un tas de sources de données - ce qui a entraîné des coûts pour maintenir la cohérence, la pertinence des données, la nécessité de garder à l'esprit d'où elles viennent, dans quelles conditions elles parviennent à la base de données et pourquoi les mêmes mesures à différents endroits. diffèrent (par exemple, le nombre de clés de licence et d'installations physiques). De nombreuses informations ont été écrites sur ces sources (coupes mensuelles d'une base de données de 270 000 clés et rapports arrivant deux fois plus souvent à partir de 300 000 serveurs), mais seules quelques personnes ont pu travailler avec ces données et ont trouvé du temps. Je suis arrivé à Plesk en 2015, et mes premières tâches consistaient simplement à obtenir des statistiques hétérogènes à partir du cube OLAP et de la base de données MongoDB. «Comment faire» pour cette base de données était une page avec un nom d'utilisateur et un mot de passe de l'hôte et un fichier texte avec un script js de la dernière demande populaire.
Un tas de sources signifiait un tas d'outils et de services, dont chaque gestionnaire de programme devrait être capable d'utiliser. Le sentiment au début du travail était quelque chose comme ceci:

Qu'avons-nous fait?
La solution était la suivante: il y a environ un an et demi, nous avons entamé une refonte complète du processus de collecte de données - nous développons maintenant des analyses de la même manière que la fonctionnalité elle-même, à chaque étape de toute l'équipe (équipe de fonctionnalités), du PM et du développement à l'ingénieur AQ.
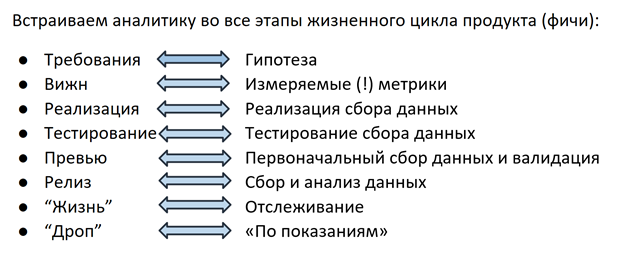
Hypothèse
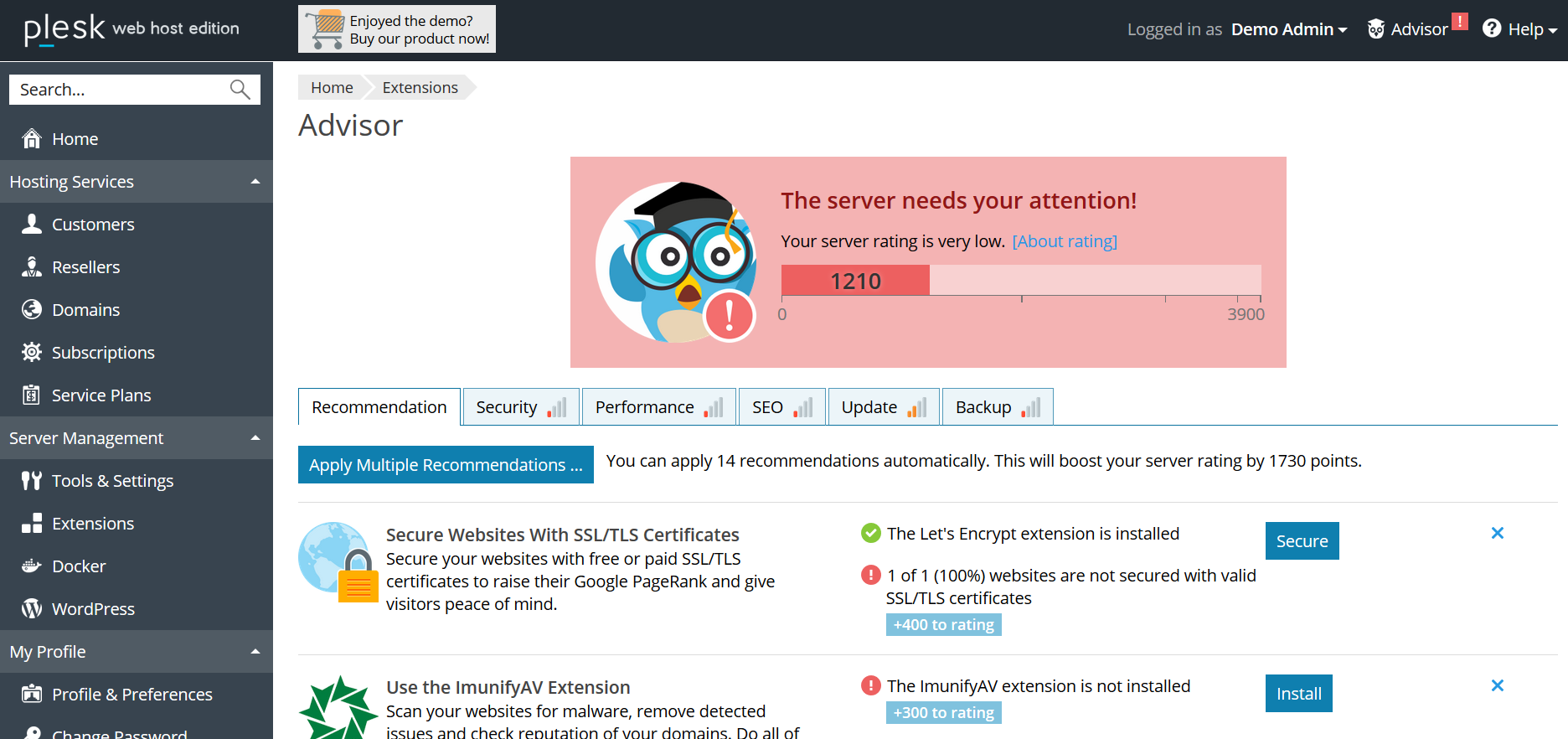
Tout commence au stade de la planification des fonctionnalités: PM formule une hypothèse sur la base de laquelle la métrique sera sélectionnée à l'étape suivante. Par exemple: Plesk dispose d'un système de recommandation Advisor qui aide l'utilisateur à améliorer l'état du serveur en suivant les étapes proposées (ajouter un certificat ssl, activer les mises à jour, mettre à jour la version PHP, etc.). En libérant Advisor, nous supposons que l'utilisateur suivra les recommandations, la cote de "santé" du serveur augmentera, et grâce aux "réalisations" gamifiées, l'utilisateur sera impliqué dans l'interaction avec le conseiller sur une base continue.
Métrique
À l'étape suivante, une métrique est sélectionnée pour chaque hypothèse: pour Advisor, il s'agit du nombre de clics dans les recommandations, du pourcentage de sites protégés par des certificats, du score de notation, etc. Toutes ces informations (hypothèse + métriques) sont saisies dans le document Vision - avec les exigences de fonctionnalités. À ce stade, les analystes de données sont impliqués dans le processus - leur tâche est d'aider à rendre la métrique mesurable, facile à collecter et sans ambiguïté. Même des détails tels que la structure du futur champ dans la base de données ou le rapport sont importants - puisque le PM responsable de la fonctionnalité accède le plus souvent à ces informations, il est dans son intérêt de déterminer comment il est plus pratique de le faire, jusqu'à la structure souhaitée de la demande de base de données. Grâce à cette approche, en passant, il est devenu plus facile pour tout le monde dans le sens où le besoin de grimper dans 100500 sources a considérablement diminué - maintenant vous décidez dans quel format les données seront collectées et comment vous préférez les obtenir. En fixant une logique de comptage dans une vue, le PM a également la possibilité à tout moment de revenir sur le document et de rappeler par quels critères la base de données entre / augmente le compteur / le fait d'envoyer, etc. Cela résout le problème de la compréhension de la logique des rapports.
Implémentation
Lorsqu'une hypothèse est formulée et qu'une métrique est sélectionnée, c'est le tour de la mise en œuvre. Les développeurs mettent en œuvre à la fois la fonctionnalité elle-même et le mécanisme de collecte de ses statistiques. Comme déjà mentionné, l'utilisation de solutions prêtes à l'emploi comme GA est difficile pour nous pour diverses raisons.Par conséquent, il y a 2 ans, nos ingénieurs ont mis en place leur propre mécanisme de suivi des actions des utilisateurs dans le panneau. En plus des actions de l'utilisateur, divers détails techniques, paramètres de configuration, etc. peuvent également être intéressants. - tout cela est envoyé à la base de données MongoDB déjà mentionnée.
Tests et aperçus
Comme tout produit, le mécanisme de collecte de données doit être testé - dans notre cas, l'ingénieur QA vérifie que les recommandations sont affichées et ouvertes, la notation est surveillée et des informations sur tous ces événements sont collectées dans la base de données. Souvent, les cas d'utilisation sélectionnés pour le suivi et l'analyse deviennent de nouveaux cas de test pour tester la fonctionnalité de la fonctionnalité elle-même.
Après que l'ingénieur QA ait vérifié tous les scénarios, le PM avec le développeur a examiné les premières données et s'est assuré que la fonctionnalité 1) n'a rien cassé et 2) qu'elle fonctionne comme prévu et que les statistiques collectent ce qui l'intéresse - tout est prêt pour la publication dans libération.
Durée de vie
Lorsqu'une fonctionnalité est lancée dans une version, la partie la plus intéressante commence - sa «vie» dans le produit. Plus besoin de lancer: «savez-vous quel champ de notre base de données stocke des informations sur l'affichage des recommandations? non? blin ... ". L'analyste de données ne reçoit pas de messages en retard: «pouvez-vous compter à nouveau le nombre d'impressions sur la dernière version? - pour cela, il y a des graphiques sur des tableaux de bord avec des alertes configurées qui envoient des lettres si la valeur surveillée a fortement chuté / augmenté / modifié / aucun enregistrement n'a été trouvé dans la base de données. Mais ce n'est pas tout. Comprendre que le compteur a augmenté ou baissé de n% n'est pas toujours suffisant pour dire avec certitude qu'il s'agit d'un changement significatif, et non d'un saut saisonnier ou d'une fluctuation dans la marge d'erreur. L'un des membres de notre équipe élabore un cadre pour mesurer la signification statistique des changements métriques. À l'aide de l'appareil de statistiques mathématiques, il calcule l'échantillon minimum (le nombre d'utilisateurs / installations / événements) nécessaire pour évaluer l'importance des changements, sélectionne les segments entre lesquels vous pouvez comparer et détermine l'intervalle de confiance qui contient le plus probablement la valeur réelle de la métrique qui nous intéresse. Ce cadre a déjà été testé et a donné des résultats intéressants la semaine dernière: nous avons découvert qu'après avoir commencé à afficher les prix dans le catalogue d'extension à l'intérieur du panneau Plesk, les gens ont commencé à acheter moins de clés de licence annuelles et plus souvent mensuelles pour ces produits. À l'heure actuelle, nos collègues calculent les prévisions de LTV, après quoi il deviendra clair que ces changements sont pour nous à long terme et quelle option nous devrions promouvoir dans la logique d'affichage des prix.
Résiliation du soutien
Le résultat de la vie de tout produit ou fonctionnalité est la fin de son support dans le cas où il est dû à un manque de demande ou à d'autres raisons (par exemple, des considérations de sécurité en cas de cessation du support pour un système d'exploitation ou une version de PHP obsolète). Ici, l'analyse vient également à notre aide: par exemple, lorsque nous avons décidé d'encourager les utilisateurs à passer à de nouvelles versions de PHP, la première chose que nous avons faite a été de collecter des statistiques d'utilisation des versions auprès des utilisateurs de Plesk. Nous avons appris que le pourcentage utilisant PHP 7 n'atteint que 20% des utilisateurs et nous avons réalisé que les coûts potentiels d'une commutation forcée sous la forme de millions de sites endommagés l'emportent sur les risques de vulnérabilités possibles des anciennes versions. En conséquence, nous avons décidé de mesures d'influence plus douces et avons commencé par une notification sur l'opportunité d'une mise à niveau dans le panel. Un autre exemple peut être de nombreuses histoires avec l'arrêt du support des systèmes d'exploitation - dans le cas où nous avons découvert que l'un des plus gros clients avec des dizaines de milliers d'installations Plesk utilise un certain système d'exploitation, nous communiquons de manière ciblée avec ce partenaire et, en cas d'impossibilité d'une transition rapide, nous lui proposons la soi-disant paresseuse - la fin de la prise en charge des nouvelles installations et la possibilité de continuer à travailler sur les installations existantes après la mise à niveau vers la dernière version de Plesk.
Conclusion
Pour résumer, je veux une fois de plus exprimer ce que nous considérons comme le plus important - travailler pour nous avec l'analyse fait maintenant partie intégrante du travail sur chaque fonctionnalité. Mais le processus construit n'est pas la fin. De notre propre expérience, nous étions convaincus que le contrôle de la qualité des données n'est pas moins important que le processus lui-même. Tout n'a aucun sens si, à n'importe quel stade de la collecte, les données sont perdues ou déformées. Pour éviter que cela ne se produise, à chaque étape, nous nous efforçons d'ajouter des vérifications de l'exhaustivité et de l'exactitude des données, ainsi que d'enregistrer chaque étape de traitement.

Et le dernier. Ne vous pesez pas avec des mesures simplement parce que vous pouvez :) énoncer clairement ce que ces informations sont pour vous, et lorsqu'elles sont reçues, demandez-vous si elles aboutissent à une conclusion menant à l'action. Après tout, comprendre ce qu'il faut faire est exactement ce pour quoi tout a commencé :)