Nous nous sommes déjà familiarisés avec le périphérique de
cache de tampon , l'un des principaux objets de la mémoire partagée, et nous avons réalisé que pour récupérer d'une défaillance lorsque le contenu de la RAM était perdu, vous devez conserver un
journal de pré-enregistrement .
Le problème non résolu que nous avons arrêté la dernière fois est que l'on ne sait pas à quel moment vous pouvez commencer à lire les journaux pendant la récupération. Commencer depuis le début, comme le conseillait le roi d'
Alice , ne fonctionnera pas: il est impossible de stocker toutes les entrées de journal depuis le début du serveur - c'est potentiellement une quantité énorme et le même temps de récupération énorme. Nous avons besoin d'un point qui progresse progressivement à partir duquel nous pouvons commencer la récupération (et, par conséquent, nous pouvons supprimer en toute sécurité toutes les entrées de journal précédentes). C'est le
point de contrôle qui sera discuté aujourd'hui.
Point de contrôle
Quelle propriété doit avoir un point de contrôle? Nous devons être sûrs que toutes les entrées de journal, à partir du point de contrôle, seront appliquées aux pages écrites sur le disque. Si ce n'était pas le cas, lors de la restauration, nous pouvions lire sur le disque une version trop ancienne de la page et lui appliquer une entrée de journal, et ainsi endommager définitivement les données.
Comment obtenir un point d'arrêt? L'option la plus simple consiste à suspendre périodiquement le système et à vider toutes les pages sales du tampon et des autres caches sur le disque. (Notez que les pages sont uniquement écrites, mais pas éjectées du cache.) De tels points satisferont la condition, mais, bien sûr, personne ne voudra travailler avec un système qui se bloque constamment pendant une durée indéfinie, mais très significative.
Par conséquent, dans la pratique, tout est un peu plus compliqué: un point de contrôle à partir d'un point se transforme en segment. Nous
commençons d'abord le point d'arrêt. Après cela, sans interrompre le travail et, si possible, sans créer de charges de pointe, nous vidons lentement les tampons sales sur le disque.

Lorsque tous les tampons qui étaient sales
au début du point de contrôle ont été écrits, le point de contrôle est considéré comme
terminé . Maintenant (mais pas plus tôt), nous pouvons utiliser le point de départ comme point à partir duquel vous pouvez démarrer la récupération. Et les écritures de journal dont nous n'avons plus besoin jusqu'ici.

Le point de contrôle est géré par un processus spécial de pointeur de fond.
La durée des tampons sales est déterminée par la valeur du paramètre
checkpoint_completion_target . Il montre combien de temps entre deux points de contrôle adjacents l'enregistrement aura lieu. La valeur par défaut est 0,5 (comme dans les figures ci-dessus), c'est-à-dire que l'enregistrement prend la moitié du temps entre les points de contrôle. En règle générale, la valeur est augmentée jusqu'à 1,0 pour une plus grande uniformité.
Examinons plus en détail ce qui se passe lorsqu'un point de contrôle est exécuté.
Le processus de point de contrôle vide d'abord les tampons d'état des transactions (XACT) sur le disque. Puisqu'ils sont peu nombreux (128 au total), ils sont enregistrés immédiatement.
Ensuite, le travail principal commence - écrire des pages sales à partir du cache de tampon. Comme nous l'avons déjà dit, il est impossible de réinitialiser toutes les pages à la fois, car la taille du cache de tampon peut être importante. Par conséquent, tout d'abord, toutes les pages actuellement sales sont marquées dans le cache de tampon dans les en-têtes avec un indicateur spécial.
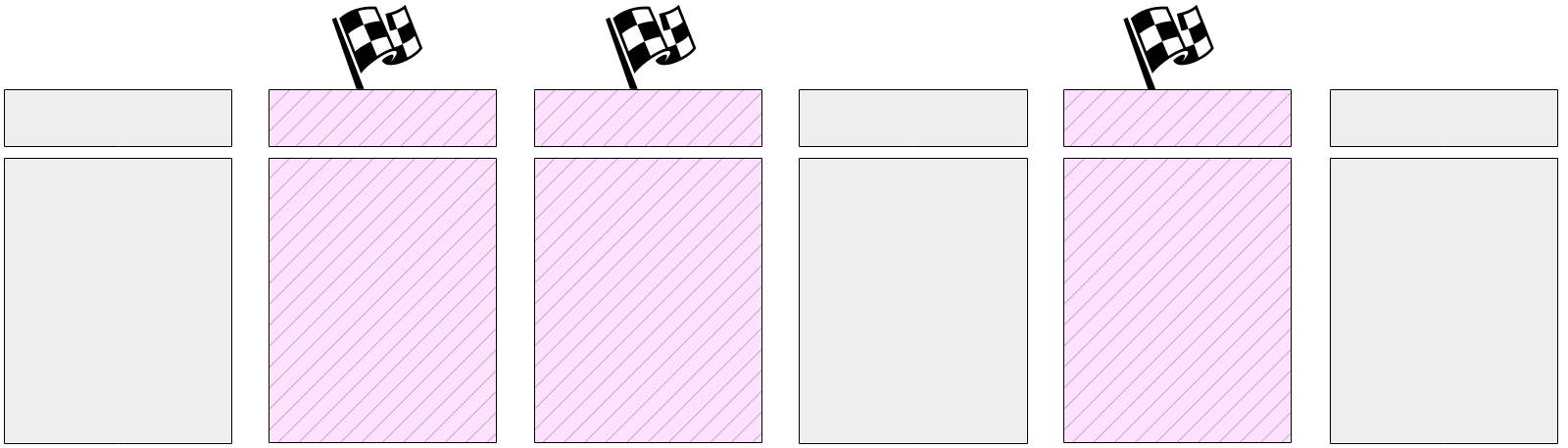
Et puis le processus de point de contrôle passe progressivement par tous les tampons et vide ceux marqués sur le disque. Rappelez-vous que les pages ne sont pas éjectées du cache, mais uniquement écrites sur le disque, vous n'avez donc pas besoin de faire attention au nombre d'appels au tampon ou à sa correction.
Les tampons étiquetés peuvent également être écrits par les processus serveur - selon qui accède au tampon en premier. Dans tous les cas, le drapeau précédemment défini est supprimé lors de l'enregistrement, donc (aux fins du point de contrôle) le tampon ne sera écrit qu'une seule fois.
Naturellement, lors de l'exécution du point de contrôle, les pages continuent de changer dans le cache tampon. Mais les nouveaux tampons sales ne sont pas marqués et le processus de point de contrôle ne doit pas les écrire.
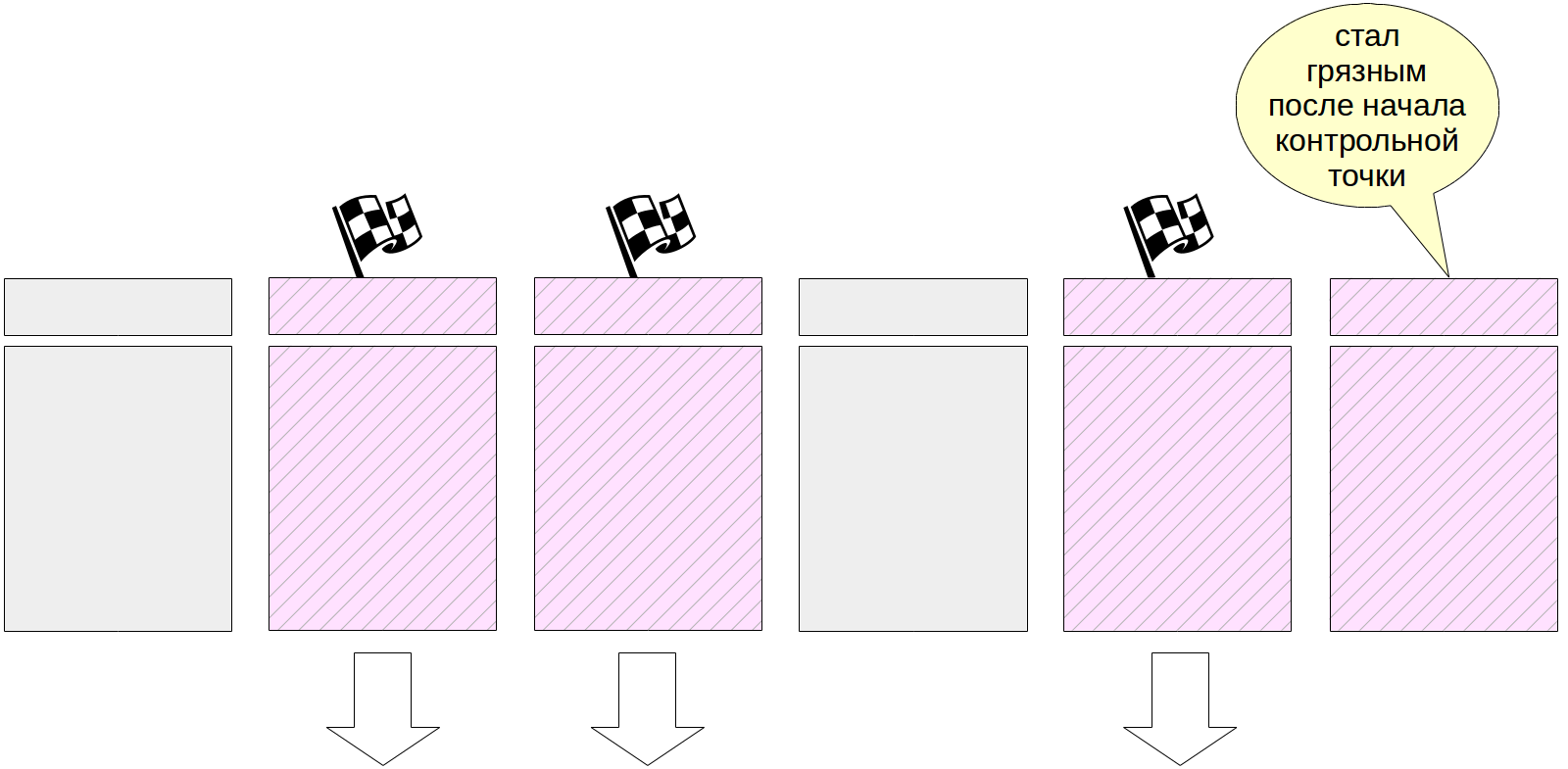
À la fin de son travail, le processus crée une entrée de journal pour la fin du point de contrôle. Cet enregistrement contient le LSN du début des travaux du point de contrôle. Comme le point de contrôle n'écrit rien dans le journal au début de son travail, ce LSN peut contenir n'importe quel enregistrement de journal.
De plus, le fichier $ PGDATA / global / pg_control met à jour l'indication du dernier point de contrôle
passé . Avant la fin du point de contrôle, pg_control pointe vers le point de contrôle précédent.

Pour regarder le travail du point de contrôle, créez une table - ses pages iront dans le cache tampon et seront sales:
=> CREATE TABLE chkpt AS SELECT * FROM generate_series(1,10000) AS g(n); => CREATE EXTENSION pg_buffercache; => SELECT count(*) FROM pg_buffercache WHERE isdirty;
count ------- 78 (1 row)
Rappelez-vous la position actuelle dans le journal:
=> SELECT pg_current_wal_insert_lsn();
pg_current_wal_insert_lsn --------------------------- 0/3514A048 (1 row)
Maintenant, nous allons exécuter le point de contrôle manuellement et nous assurer qu'il n'y a pas de pages sales dans le cache (comme nous l'avons dit, de nouvelles pages sales peuvent apparaître, mais dans notre cas, il n'y a eu aucun changement dans le processus d'exécution du point de contrôle):
=> CHECKPOINT; => SELECT count(*) FROM pg_buffercache WHERE isdirty;
count ------- 0 (1 row)
Voyons comment le point de contrôle a été reflété dans le journal:
=> SELECT pg_current_wal_insert_lsn();
pg_current_wal_insert_lsn --------------------------- 0/3514A0E4 (1 row)
postgres$ /usr/lib/postgresql/11/bin/pg_waldump -p /var/lib/postgresql/11/main/pg_wal -s 0/3514A048 -e 0/3514A0E4
rmgr: Standby len (rec/tot): 50/ 50, tx: 0, lsn: 0/3514A048, prev 0/35149CEC, desc: RUNNING_XACTS nextXid 101105 latestCompletedXid 101104 oldestRunningXid 101105
rmgr: XLOG len (rec/tot): 102/ 102, tx: 0, lsn: 0/3514A07C, prev 0/3514A048, desc: CHECKPOINT_ONLINE redo 0/3514A048; tli 1; prev tli 1; fpw true; xid 0:101105; oid 74081; multi 1; offset 0; oldest xid 561 in DB 1; oldest multi 1 in DB 1; oldest/newest commit timestamp xid: 0/0; oldest running xid 101105; online
Ici, nous voyons deux entrées. Le dernier est un enregistrement du passage du point de contrôle (CHECKPOINT_ONLINE). Le LSN du début du point de contrôle est indiqué après le mot refaire, et cette position correspond à l'entrée de journal, qui était la dernière au début du point de contrôle.
On retrouvera les mêmes informations dans le fichier de contrôle:
postgres$ /usr/lib/postgresql/11/bin/pg_controldata -D /var/lib/postgresql/11/main | egrep 'Latest.*location'
Latest checkpoint location: 0/3514A07C Latest checkpoint's REDO location: 0/3514A048
Récupération
Nous sommes maintenant prêts à clarifier l'algorithme de récupération décrit dans l'article précédent.
Si le serveur tombe en panne, la prochaine fois qu'il démarre, le processus de démarrage le détecte en consultant le fichier pg_control et en voyant un état autre que «arrêté». Dans ce cas, une récupération automatique est effectuée.
Tout d'abord, le processus de récupération lira du même pg_control la position du début du point de contrôle. (Pour compléter l'image, nous notons que si le fichier backup_label est présent, alors l'enregistrement du point de contrôle est lu à partir de celui-ci - cela est nécessaire pour la restauration à partir de sauvegardes, mais c'est un sujet pour un cycle séparé.)
Ensuite, il lira le magazine, à partir de la position trouvée, en appliquant séquentiellement des entrées de journal aux pages (si nécessaire, comme nous l'avons vu la
dernière fois ).
En conclusion, toutes les tables non journalisées sont écrasées à l'aide d'images dans les fichiers init.
À ce stade, le processus de démarrage se termine et le processus de pointeur de vérification exécute immédiatement un point de contrôle pour corriger l'état restauré sur le disque.
Vous pouvez simuler un échec en arrêtant de force le serveur en mode immédiat.
student$ sudo pg_ctlcluster 11 main stop -m immediate --skip-systemctl-redirect
(La clé
--skip-systemctl-redirect est nécessaire ici car PostgreSQL est installé dans Ubuntu à partir du package. Elle est contrôlée par la commande pg_ctlcluster, qui appelle en fait systemctl, et elle appelle déjà pg_ctl. Avec tous ces wrappers, le nom du mode est perdu en cours de route, et le
--skip-systemctl-redirect vous permet de vous passer de systemctl et d'enregistrer des informations importantes.)
Vérifiez l'état du cluster:
postgres$ /usr/lib/postgresql/11/bin/pg_controldata -D /var/lib/postgresql/11/main | grep state
Database cluster state: in production
Au démarrage, PostgreSQL comprend qu'un échec s'est produit et qu'une récupération est nécessaire.
student$ sudo pg_ctlcluster 11 main start
postgres$ tail -n 7 /var/log/postgresql/postgresql-11-main.log
2019-07-17 15:27:49.441 MSK [8865] LOG: database system was interrupted; last known up at 2019-07-17 15:27:48 MSK 2019-07-17 15:27:49.801 MSK [8865] LOG: database system was not properly shut down; automatic recovery in progress 2019-07-17 15:27:49.804 MSK [8865] LOG: redo starts at 0/3514A048 2019-07-17 15:27:49.804 MSK [8865] LOG: invalid record length at 0/3514A0E4: wanted 24, got 0 2019-07-17 15:27:49.804 MSK [8865] LOG: redo done at 0/3514A07C 2019-07-17 15:27:49.824 MSK [8864] LOG: database system is ready to accept connections 2019-07-17 15:27:50.409 MSK [8872] [unknown]@[unknown] LOG: incomplete startup packet
Le besoin de récupération est noté dans le journal des messages: le
système de base de données n'a pas été correctement arrêté; récupération automatique en cours . Ensuite, les entrées de journal commencent à jouer à partir de la position marquée «recommencer à» et continuent jusqu'à ce que les entrées de journal suivantes puissent être récupérées. Ceci termine la récupération dans la position «refaire à» et le SGBD commence à travailler avec les clients (le
système de base de données est prêt à accepter les connexions ).
Et que se passe-t-il lors d'un arrêt normal du serveur? Pour vider les pages sales sur le disque, PostgreSQL déconnecte tous les clients, puis exécute le point de contrôle final.
Rappelez-vous la position actuelle dans le journal:
=> SELECT pg_current_wal_insert_lsn();
pg_current_wal_insert_lsn --------------------------- 0/3514A14C (1 row)
Arrêtez maintenant doucement le serveur:
student$ sudo pg_ctlcluster 11 main stop
Vérifiez l'état du cluster:
postgres$ /usr/lib/postgresql/11/bin/pg_controldata -D /var/lib/postgresql/11/main | grep state
Database cluster state: shut down
Et dans le journal, nous trouvons le seul enregistrement sur le point de contrôle final (CHECKPOINT_SHUTDOWN):
postgres$ /usr/lib/postgresql/11/bin/pg_waldump -p /var/lib/postgresql/11/main/pg_wal -s 0/3514A14C
rmgr: XLOG len (rec/tot): 102/ 102, tx: 0, lsn: 0/3514A14C, prev 0/3514A0E4, desc: CHECKPOINT_SHUTDOWN redo 0/3514A14C; tli 1; prev tli 1; fpw true; xid 0:101105; oid 74081; multi 1; offset 0; oldest xid 561 in DB 1; oldest multi 1 in DB 1; oldest/newest commit timestamp xid: 0/0; oldest running xid 0; shutdown
pg_waldump: FATAL: error in WAL record at 0/3514A14C: invalid record length at 0/3514A1B4: wanted 24, got 0
(Dans un terrible message fatal, pg_waldump veut juste dire qu'il a lu jusqu'à la fin du magazine.)
Exécutez à nouveau l'instance.
student$ sudo pg_ctlcluster 11 main start
Enregistrement en arrière-plan
Comme nous l'avons découvert, le point de contrôle est l'un des processus qui écrit les pages sales du cache tampon sur le disque. Mais pas le seul.
Si le backend doit pousser la page hors du tampon et que la page est sale, il devra l'écrire sur le disque de son propre chef. C'est une mauvaise situation, ce qui conduit à des attentes - c'est beaucoup mieux lorsque l'enregistrement se produit de manière asynchrone en arrière-plan.
Par conséquent, en plus du
processus de point de contrôle
, il existe également
un processus d'enregistrement en arrière-plan (écrivain en arrière-plan, bgwriter ou simplement écrivain). Ce processus utilise le même algorithme de recherche de tampon que le mécanisme de préemption. Il existe essentiellement deux différences.
- Il n'utilise pas de pointeur sur la "prochaine victime", mais le sien. Il peut être en avance sur le pointeur de la «victime», mais ne traîne jamais derrière lui.
- Lors de la traversée de tampons, le compteur de coups ne diminue pas.
Des tampons sont écrits simultanément:
- contenir des données modifiées (sales),
- non fixe (nombre de broches = 0),
- avoir zéro accès (nombre d'utilisation = 0).
Ainsi, le processus d'enregistrement en arrière-plan, pour ainsi dire, précède l'éviction et trouve les tampons qui seront probablement évincés bientôt. Idéalement, pour cette raison, les processus de service devraient trouver que les tampons qu'ils sélectionnent peuvent être utilisés sans s'arrêter pour écrire.
Personnalisation
Le processus de point de contrôle est généralement configuré pour les raisons suivantes.
Vous devez d'abord décider de la quantité de fichiers journaux que nous pouvons nous permettre d'économiser (et du temps de récupération qui nous convient). Plus c'est grand, mieux c'est, mais pour des raisons évidentes, cette valeur sera limitée.
Ensuite, nous pouvons calculer combien de temps ce volume sera généré sous une charge normale. Nous avons déjà réfléchi à la façon de procéder (nous devons nous souvenir des positions dans le journal et soustraire les uns des autres).
Ce temps sera notre intervalle habituel entre les points de contrôle. Nous l'écrivons dans le paramètre
checkpoint_timeout . La valeur par défaut de 5 minutes est évidemment trop petite, généralement le temps est augmenté, disons, à une demi-heure. Je le répète: moins vous pouvez vous permettre des jalons, mieux c'est - cela réduit les frais généraux.
Cependant, il est possible (et même probable) que parfois la charge soit plus élevée que la normale et que trop d'entrées de journal soient générées dans le temps spécifié dans le paramètre. Dans ce cas, je voudrais effectuer le point de contrôle plus souvent. Pour ce faire, dans le paramètre
max_wal_size , nous
spécifions le montant qui est valide au sein du même point de contrôle. Si le volume réel est obtenu davantage, le serveur lance un point de contrôle non planifié.
Ainsi, la plupart des points de contrôle se produisent sur une planification: une fois par unité de temps
checkpoint_timeout . Mais avec une charge accrue, le point de contrôle est appelé plus souvent lorsque le volume
max_wal_size est
atteint .
Il est important de comprendre que le paramètre
max_wal_size ne détermine pas du tout la quantité maximale que les fichiers journaux sur le disque peuvent occuper.
- Pour récupérer après une panne, vous devez stocker les fichiers à partir du moment où le dernier point de contrôle a été franchi, ainsi que les fichiers qui se sont accumulés pendant le fonctionnement du point de contrôle actuel. Par conséquent, le volume total peut être approximativement estimé à
(1 + checkpoint_completion_target ) × max_wal_size . - Avant la version 11, PostgreSQL stockait également des fichiers pour le point de contrôle de deux ans, donc jusqu'à la version 10 dans la formule ci-dessus, vous devez définir 2 au lieu de 1.
- Le paramètre max_wal_size n'est qu'un souhait, mais pas une limite stricte . Cela peut s'avérer plus.
- Le serveur n'a pas le droit d'effacer les fichiers journaux qui n'ont pas encore été transférés via les emplacements de réplication et qui n'ont pas encore été archivés lors de l'archivage continu. Si cette fonctionnalité est utilisée, une surveillance constante est nécessaire, car il est facile de déborder la mémoire du serveur.
Pour compléter l'image, vous pouvez définir non seulement le volume maximum, mais aussi le minimum: paramètre
min_wal_size . La signification de ce paramètre est que le serveur ne supprime pas les fichiers lorsqu'ils tiennent dans le volume dans
min_wal_size , mais les renomme simplement et les utilise à nouveau. Cela vous permet d'économiser un peu en créant et supprimant constamment des fichiers.
Il est judicieux de configurer le
processus d'enregistrement en arrière-plan une fois le point de contrôle configuré. Ensemble, ces processus doivent avoir le temps d'écrire des tampons sales avant d'être utilisés par les processus de maintenance.
Le processus d'enregistrement en arrière-plan s'exécute en cycles d'au plus
bgwriter_lru_maxpages pages, s'endormant entre les cycles sur
bgwriter_delay .
Le nombre de pages qui seront enregistrées dans un cycle de travail est déterminé par le nombre moyen de tampons qui ont été demandés par les processus de maintenance de la dernière exécution (en utilisant une moyenne mobile pour aplanir les inégalités entre les exécutions, mais ne dépend pas d'une longue histoire). Le nombre calculé de tampons est multiplié par le coefficient
bgwriter_lru_multiplier (mais en aucun cas il ne dépassera
bgwriter_lru_maxpages ).
Valeurs par défaut:
bgwriter_delay = 200
ms (probablement trop, il
fuit beaucoup d'eau en 1/5 de seconde),
bgwriter_lru_maxpages = 100,
bgwriter_lru_multiplier = 2.0 (nous essayons de répondre à la demande avant la date prévue).
Si le processus ne détecte pas du tout les tampons sales (c'est-à-dire qu'il ne se passe rien dans le système), il "hiberne", d'où il est déduit que le processus serveur accède au tampon. Après cela, le processus se réveille et fonctionne à nouveau de la manière habituelle.
Suivi
Les paramètres d'enregistrement du point de contrôle et de l'arrière-plan peuvent et doivent être ajustés, en recevant les commentaires de la surveillance.
Le paramètre
checkpoint_warning affiche un avertissement si les points de contrôle provoqués par des dépassements de taille du fichier journal s'exécutent trop souvent. Sa valeur par défaut est de 30 secondes et elle doit être alignée sur la valeur de
checkpoint_timeout .
Le paramètre
log_checkpoints (désactivé par défaut) permet de recevoir des informations sur les points de contrôle exécutés dans le journal des messages du serveur. Allumez-le.
=> ALTER SYSTEM SET log_checkpoints = on; => SELECT pg_reload_conf();
Maintenant, changez quelque chose dans les données et exécutez le point de contrôle.
=> UPDATE chkpt SET n = n + 1; => CHECKPOINT;
Dans le journal des messages, nous verrons quelque chose comme ceci:
postgres$ tail -n 2 /var/log/postgresql/postgresql-11-main.log
2019-07-17 15:27:55.248 MSK [8962] LOG: checkpoint starting: immediate force wait 2019-07-17 15:27:55.274 MSK [8962] LOG: checkpoint complete: wrote 79 buffers (0.5%); 0 WAL file(s) added, 0 removed, 0 recycled; write=0.001 s, sync=0.013 s, total=0.025 s; sync files=2, longest=0.011 s, average=0.006 s; distance=1645 kB, estimate=1645 kB
Vous pouvez voir ici combien de tampons ont été écrits, comment la composition des fichiers journaux a changé après le point de contrôle, combien de temps le point de contrôle a pris et la distance (en octets) entre les points de contrôle voisins.
Mais, probablement, les informations les plus utiles sont les statistiques du travail des processus d'enregistrement de point de contrôle et d'arrière-plan dans la vue pg_stat_bgwriter. La vue est une pour deux, car une fois que les deux tâches ont été effectuées par un seul processus; puis leurs fonctions ont été divisées, et la vue est restée.
=> SELECT * FROM pg_stat_bgwriter \gx
-[ RECORD 1 ]---------+------------------------------ checkpoints_timed | 0 checkpoints_req | 1 checkpoint_write_time | 1 checkpoint_sync_time | 13 buffers_checkpoint | 79 buffers_clean | 0 maxwritten_clean | 0 buffers_backend | 42 buffers_backend_fsync | 0 buffers_alloc | 363 stats_reset | 2019-07-17 15:27:49.826414+03
Ici, entre autres, nous voyons le nombre de points de contrôle terminés:
- checkpoints_timed - selon le calendrier (en atteignant checkpoint_timeout),
- checkpoints_req - à la demande (y compris en atteignant max_wal_size).
La grande valeur de checkpoint_req (par rapport à checkpoints_timed) indique que les points de contrôle se produisent plus souvent que prévu.
Informations importantes sur le nombre de pages enregistrées:
- buffers_checkpoint - processus de point de contrôle,
- buffers_backend - en servant des processus,
- buffers_clean - processus d'enregistrement en arrière-plan.
Sur un système bien réglé, la valeur de buffers_backend doit être sensiblement inférieure à la somme de buffers_checkpoint et buffers_clean.
De plus, maxwritten_clean est utile pour configurer l'enregistrement en arrière-plan - ce nombre indique combien de fois le processus d'enregistrement en arrière-plan a cessé de fonctionner en raison du dépassement de
bgwriter_lru_maxpages .
Vous pouvez réinitialiser les statistiques accumulées à l'aide de l'appel suivant:
=> SELECT pg_stat_reset_shared('bgwriter');
À suivre .