À l'école, j'avais un camarade de classe qui pouvait écouter le fonctionnement de la voiture dans la cour et avec un visage sérieux rendre un verdict: tout est en ordre, ou quelque chose s'est cassé, et j'ai besoin de toute urgence de courir pour de nouvelles pièces / huile / outils! Comme une théière absolue dans le secteur automobile, j'ai toujours entendu le cliquetis habituel de la prochaine dvenashka, ne remarquant aucune différence et m'émerveillant silencieusement de son audition et de ses compétences.
Maintenant, je ne comprenais pas mieux l'intérieur de la voiture, mais j'ai commencé à travailler avec le traitement des signaux sonores et l'apprentissage automatique, et ici nous allons essayer de comprendre s'il est possible d'apprendre à un ordinateur à détecter les anomalies dans le bruit d'un moteur?
Au minimum, il est juste intéressant de vérifier, et à l'avenir, une telle technologie pourrait économiser beaucoup d'argent pour les propriétaires de voitures. Au moins à mon avis, les défaillances critiques se produisent progressivement sous le capot, et dans les premiers stades, beaucoup d'entre elles peuvent être entendues, rapidement et à moindre coût, économisant du temps, de l'argent et des nerfs déjà tremblants.
Eh bien, il est peut-être temps de passer des paroles aux actes. C'est parti!
Je veux dire tout de suite que dans tout ce qui concerne les mathématiques et les algorithmes, je mettrai davantage l'accent sur le sens et la compréhension, il n'y aura pas de formules et de calculs mathématiques ici. Je n'ai pas développé de nouveaux algorithmes ici; pour les formules, si vous le souhaitez, il vaut mieux google et Wikipedia, ainsi qu'utiliser les liens que je laisserai tout au long de l'article.
Je vais donner toutes les explications sur l'exemple du bruit d'un moteur cassé tiré de cette vidéo sur YouTube .
Le fichier téléchargé depuis YouTube (vous pouvez le télécharger en utilisant des extensions de navigateur ou simplement en changeant le lien youtube en ssyoutube) nous convertissons au format wav en utilisant ffmpeg:
ffmpeg -i input_video.mp4 -c:a pcm_s16le -ar 16000 -ac 1 engine_sound.wav
Avant de commencer le traitement de ce fichier, je vais dire quelques mots sur ce qu'est un spectrogramme et comment il nous sera utile pour résoudre ce problème. Beaucoup d'entre vous, à coup sûr, ont vu une image similaire - c'est la représentation amplitude-temporelle du son ou un oscillogramme.
Si, en termes simples, le son est une onde, et les valeurs d'amplitude de cette onde sont observées sur l'oscillogramme à des moments donnés.
Pour obtenir un spectrogramme à partir d'une telle représentation, nous avons besoin de la transformée de Fourier. Avec son aide, vous pouvez obtenir la représentation amplitude-fréquence du son ou le spectre d'amplitude. Un tel spectre montre à quelle fréquence et avec quelle amplitude le signal étudié est exprimé.
En fait, un spectrogramme est un ensemble de spectres de courts morceaux consécutifs d'un signal. Une telle "définition" suffira peut-être pour que nous ne soyons pas trop distraits de la tâche. Tout deviendra plus clair si vous regardez la visualisation du spectrogramme (l'image a été obtenue en utilisant WaveAssistant ). Le temps est tracé sur l'axe X, la fréquence sur l'axe Y, c'est-à-dire que chaque colonne de cette matrice est le module spectral à un moment donné.
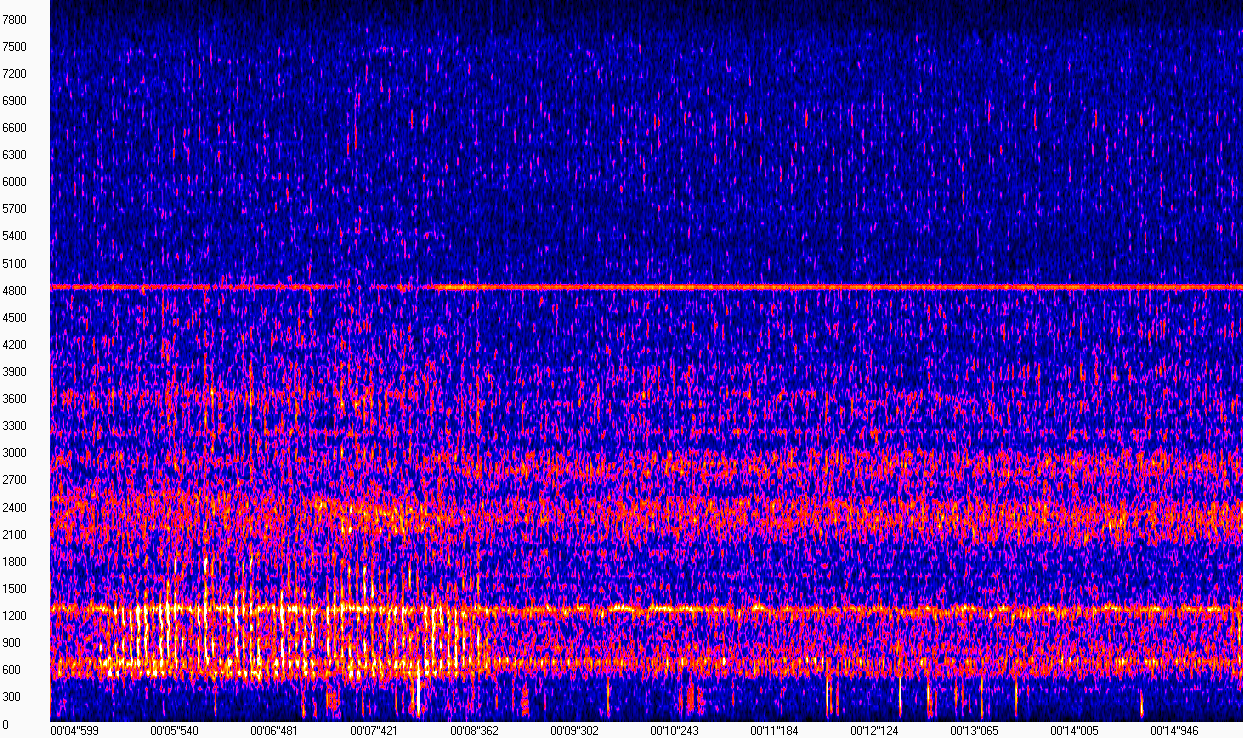
Ce spectrogramme montre que le son du moteur en l'absence de tapotement "ressemble" à peu près au même, et est exprimé à des fréquences voisines de 600, 1200, 2400 et 4800 Hz. Le son d'un coup qui dérange le propriétaire est très distinct dans la gamme de fréquences de 600-1200 Hz de 5 à 8 secondes. L'enregistrement ayant été réalisé dans des conditions plutôt bruyantes dans la rue, ces bruits sont également présents sur le spectrogramme, ce qui complique quelque peu notre tâche.
Néanmoins, en regardant un tel spectrogramme, nous pouvons dire avec certitude où le coup a été et où il ne l'a pas été. L'ordinateur n'a pas d'yeux, nous devons donc sélectionner un algorithme qui sera capable de distinguer une telle déviation (et de préférence pas seulement), sous réserve de la présence de bruit dans l'enregistrement.
Les spectrogrammes peuvent être calculés à l'aide de la bibliothèque librosa comme suit:
from librosa.util import buf_to_float from librosa.core import stft
Solution
À strictement parler, nous devons résoudre le problème de classification binaire, où nous devons déterminer si le moteur est cassé ou fonctionne normalement. Mon collègue et moi avons déjà décrit des tâches similaires dans notre article précédent , où nous avons utilisé un réseau neuronal convolutif pour classer les événements acoustiques. Ici, une telle solution n'est guère possible: les neurones aiment beaucoup quand on leur donne de grands ensembles de données. Nous avons affaire à une seule indentation qui dure un peu plus d'une minute, qui ne peut évidemment pas être appelée un grand ensemble de données.
Le choix a été arrêté sur le modèle de mélange gaussien (modèle de mélanges gaussiens). Un bon article détaillant le principe de fonctionnement et de formation de ce modèle peut être trouvé ici. L'idée générale de ce modèle est de décrire les données en utilisant une distribution complexe sous la forme d'une combinaison linéaire de plusieurs distributions normales multidimensionnelles (plus sur la distribution normale multidimensionnelle ici ).
Puisque le moteur pendant son fonctionnement sonne à peu près «le même», le son de son fonctionnement peut être considéré comme stationnaire, et l'idée de décrire ce son en utilisant une telle distribution semble tout à fait significative. Pour comprendre l'essence du GMM, je recommande fortement de regarder un exemple de formation et de choisir le nombre de gaussoïdes ici .
Notre cas diffère des exemples ci-dessus en ce qu'au lieu de points sur un plan bidimensionnel, les valeurs de spectre tirées du spectrogramme du signal seront utilisées. Vous pouvez sélectionner des paramètres de distribution, tels que le type de matrice de covariance en utilisant le critère BIC ( exemple , description ), cependant, dans mon cas, les paramètres optimaux du point de vue de ce critère se sont révélés pires que ceux qui sont indiqués dans le code ci-dessous:
from sklearn.mixture import GaussianMixture n_components = 3 gmm_clf = GaussianMixture(n_components) gmm_clf.fit(X_train)
En supposant que le son d'un fonctionnement normal est décrit par une distribution dont les paramètres ont été sélectionnés au cours du processus de formation, il est possible de mesurer la proximité d'un son avec cette distribution.
Pour ce faire, vous pouvez calculer la probabilité moyenne des colonnes du spectrogramme du signal étudié, puis choisir un seuil qui séparera la probabilité de sons de bon travail de toutes les autres. La crédibilité pour chaque seconde est la suivante:
n_seconds = len(full_wav_data) // sr gmm_scores = []
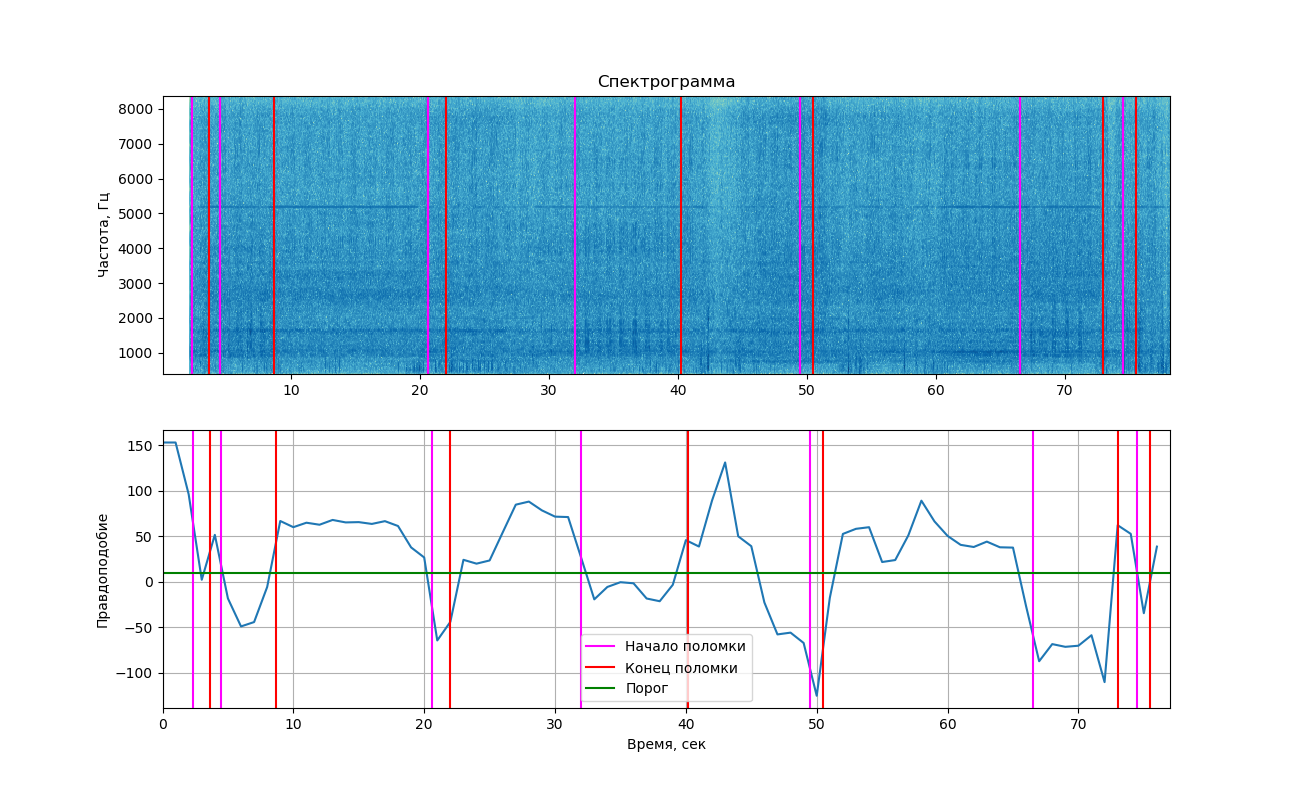
Si vous affichez la probabilité obtenue sur le graphique, nous obtenons l'image suivante.
La partie supérieure montre le spectrogramme du signal affiché à l'aide de la bibliothèque matplotlib. Les changements causés par les coups ne sont pas aussi visibles sur celui-ci que dans l'exemple ci-dessus (c'est pourquoi vous avez vu 2 images ici). Néanmoins, si vous regardez attentivement, ils peuvent encore être vus. Les lignes verticales marquent les heures de début et de fin de frappe.
Conclusions
Comme vous pouvez le voir sur le graphique, au moment du son d'un coup, la probabilité est vraiment tombée en dessous du seuil, ce qui signifie que nous pourrions séparer ces deux classes (travailler avec et sans frapper). Mais je dois dire que cette valeur est assez proche du seuil et dans les zones où le coup n'est pas entendu. Cela est dû au fait que du bruit étranger est souvent trouvé dans l'enregistrement, ce qui affecte également la probabilité.
Nous ajoutons ici une formation en seulement quelques secondes de son, de mauvaises conditions d'enregistrement, et vous pouvez déjà être surpris du tout que l'expérience ait été réussie!
Très probablement, afin de mettre cette méthode en pratique et d'être sûr de sa fiabilité, vous devrez enregistrer beaucoup plus de son et bien placer le microphone afin de minimiser le bruit entrant dans les enregistrements.
Cet article est juste une tentative de résoudre un problème similaire, ne revendiquant pas l'exactitude absolue, si vous avez des idées et des suggestions, ou peut-être des questions, discutons-en ensemble dans les commentaires ou en personne.
Le code Github complet est ici