Nous voulons présenter notre nouvel outil de tokenisation de texte - YouTokenToMe. Il fonctionne 7 à 10 fois plus rapidement que les autres versions populaires dans des langues de structure similaire à l'européenne et 40 à 50 fois - dans les langues asiatiques. Nous parlons de YouTokenToMe et le partageons avec vous en open source sur GitHub. Lien à la fin de l'article!

Aujourd'hui, une proportion importante des tâches des algorithmes de réseau neuronal sont le traitement de texte. Mais, comme les réseaux de neurones fonctionnent avec des nombres, le texte doit être converti avant d'être transféré vers le modèle.
Nous listons les solutions populaires qui sont généralement utilisées pour cela:
- pause dans l'espace
- algorithmes basés sur des règles: spaCy, NLTK;
- stemming, lemmatisation.
Chacun d'eux a ses propres inconvénients:
- Vous ne pouvez pas contrôler la taille du dictionnaire de jetons. La taille de la couche d'intégration dans le modèle en dépend directement;
- les informations sur la parenté des mots qui diffèrent par des suffixes ou des préfixes ne sont pas utilisées, par exemple: poli - impoli;
- dépendent de la langue.
Récemment, l'approche de
codage par paire d'octets a été populaire. Initialement, cet algorithme était destiné à la compression de texte, mais il y a plusieurs années, il a commencé à être utilisé pour symboliser le texte dans la traduction automatique. Maintenant, il est utilisé pour un large éventail de tâches, y compris celles utilisées dans les modèles BERT et GPT-2.
Les implémentations BPE les plus efficaces étaient
SentencePiece , développé par les ingénieurs de Google, et
fastBPE , créé par Facebook AI Research. Mais nous avons réussi à prouver que la tokenisation peut être considérablement accélérée. Nous avons optimisé l'algorithme BPE et publié le code source, et également publié le package terminé dans le référentiel pip.
Ci-dessous, vous pouvez comparer les résultats de la mesure de la vitesse de notre algorithme et d'autres versions. Par exemple, nous avons pris les 100 premiers Mo
du corpus de données Wikipedia en russe, anglais, japonais et chinois.
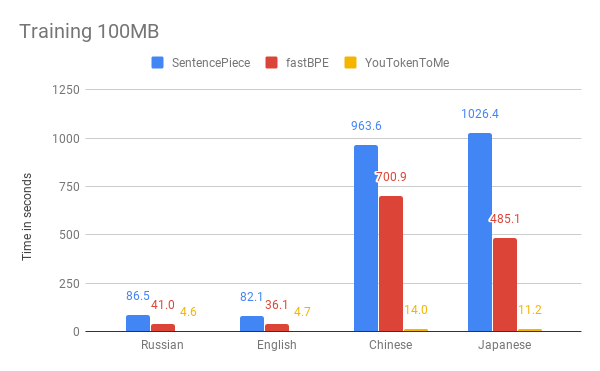

Les graphiques montrent que la durée de fonctionnement dépend considérablement de la langue. En effet, les langues asiatiques ont plus d'alphabets et les mots ne sont pas séparés par des espaces. YouTokenToMe fonctionne 7 à 10 fois plus rapidement dans des langues de structure similaire à l'européen, et 40 à 50 fois en asiatique. La tokenisation a été accélérée au moins deux fois, et dans certains tests plus de dix fois.
Nous avons atteint ces résultats grâce à deux idées clés:
- le nouvel algorithme a un temps d'exécution linéaire en fonction de la taille du boîtier pour la formation. SentencePiece et fastBPE ont un comportement asymptotique moins efficace;
- le nouvel algorithme peut utiliser efficacement plusieurs flux à la fois dans le processus d'apprentissage et dans le processus de tokenisation - cela vous permet d'obtenir une accélération plusieurs fois plus.
Vous pouvez utiliser YouTokenToMe via l'interface pour travailler à partir de la ligne de commande et directement à partir de Python.
Vous pouvez trouver plus d'informations dans le référentiel:
github.com/vkcom/YouTokenToMe