Vous voulez en savoir plus sur trois méthodes d'exploration de données pour votre prochain projet ML? Lisez ensuite la traduction de l'article de Rebecca Vickery publié sur le blog Towards Data Science sur Medium! Elle intéressera les débutants.
Obtenir des données de qualité est la première étape et la plus importante de tout projet d'apprentissage automatique. Les spécialistes de la science des données utilisent souvent diverses méthodes pour obtenir des ensembles de données. Ils peuvent utiliser des données accessibles au public, ainsi que des données disponibles via l'API ou obtenues à partir de diverses bases de données, mais combinent le plus souvent ces méthodes.
Le but de cet article est de fournir un bref aperçu de trois méthodes différentes pour récupérer des données à l'aide de Python. Je vais vous expliquer comment procéder avec le bloc-notes Jupyter. Dans mon
article précédent
, j'ai écrit sur l'application de certaines commandes qui s'exécutent dans le terminal.
SQL
Si vous avez besoin d'obtenir des données d'une base de données relationnelle, vous travaillerez très probablement avec le langage SQL. La bibliothèque SQLAlchemy vous permet d'associer le code de votre ordinateur portable aux types de bases de données les plus courants. Vous trouverez ici des informations sur les bases de données prises en charge et sur la façon de se lier à chaque type.
Vous pouvez utiliser la bibliothèque SQLAlchemy pour parcourir les tables et interroger les données, ou écrire des requêtes brutes. Pour vous lier à la base de données, vous aurez besoin d'une URL avec vos informations d'identification. Ensuite, vous devez initialiser la méthode
create_engine pour créer la connexion.
from sqlalchemy import create_engine engine = create_engine('dialect+driver://username:password@host:port/database')
Vous pouvez maintenant écrire des requêtes de base de données et obtenir des résultats.
connection = engine.connect() result = connection.execute("select * from my_table")
Grattage
Le scraping Web est utilisé pour télécharger des données à partir de sites Web et extraire les informations nécessaires de leurs pages. Il existe de nombreuses bibliothèques Python disponibles pour cela, mais la plus simple est
Beautiful Soup .
Vous pouvez installer le package via pip.
pip install BeautifulSoup4
Regardons un exemple simple comment l'utiliser. Nous allons utiliser Beautiful Soup et la bibliothèque
urllib pour gratter les noms et les prix des hôtels de
TripAdvisor .
Tout d'abord, nous importons toutes les bibliothèques avec lesquelles nous allons travailler.
from bs4 import BeautifulSoup import urllib.request
Chargez maintenant le contenu de la page que nous allons supprimer. Je souhaite collecter des données sur les prix des hôtels sur l'île grecque de Crète et prendre l'adresse URL contenant une liste d'hôtels à cet endroit.
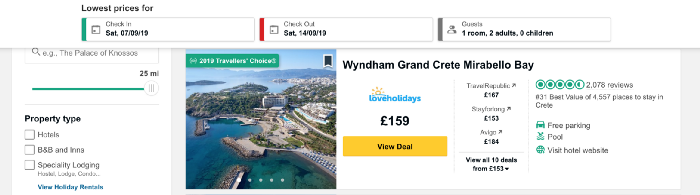
Le code ci-dessous définit l'URL comme une variable et utilise la bibliothèque urllib pour ouvrir la page et la bibliothèque Beautiful Soup pour la lire et renvoyer les résultats dans un format simple. Une partie des données de sortie est indiquée sous le code.
URL = 'https://www.tripadvisor.co.uk/Hotels-g189413-Crete-Hotels.html' page = urllib.request.urlopen(URL) soup = BeautifulSoup(page, 'html.parser') print(soup.prettify())

Maintenant, obtenons une liste avec les noms des hôtels sur la page. Nous présenterons la fonction
find_all , qui extraira des parties du document qui nous intéressent. Vous pouvez le filtrer différemment à l'aide de la fonction
find_all pour passer une seule ligne, une expression régulière ou une liste. Vous pouvez également filtrer l'un des attributs de la balise - c'est exactement la méthode que nous appliquerons. Si vous débutez avec les balises et les attributs HTML, consultez cet
article pour un aperçu rapide.
Afin de comprendre comment fournir au mieux l'accès aux données de la balise, nous devons vérifier le code de cet élément sur la page. Nous trouvons le code du nom de l'hôtel en cliquant avec le bouton droit sur le nom dans la liste, comme indiqué dans la figure ci-dessous.

Après avoir cliqué sur
inspect code de
inspect élément apparaîtra et la section avec le nom de l'hôtel sera mise en évidence.

Nous voyons que le nom de l'hôtel est le seul morceau de texte de la classe avec le nom
listing_title . Après la classe vient le code et le nom de cet attribut à la fonction
find_all , ainsi que la balise
div .
content_name = soup.find_all('div', attrs={'class': 'listing_title'}) print(content_name)
Chaque section du code avec le nom de l'hôtel est retournée sous forme de liste.

Pour extraire les noms d'hôtels du code, nous utilisons la fonction
getText de la bibliothèque Beautiful Soup.
content_name_list = [] for div in content_name: content_name_list.append(div.getText().split('\n')[0]) print(content_name_list)
Les noms des hôtels sont retournés sous forme de liste.

De la même manière, nous obtenons des données sur les prix. La structure de code pour le prix est indiquée ci-dessous.

Comme vous pouvez le voir, nous pouvons travailler avec un code très similaire à celui utilisé pour les hôtels.
content_price = soup.find_all('div', attrs={'class': 'price-wrap'}) print(content_price)
Dans le cas du prix, il n'y a pas de difficulté. Vous pouvez le voir en exécutant le code suivant:
content_price_list = [] for div in content_price: content_price_list.append(div.getText().split('\n')[0]) print(content_price_list)
Le résultat est illustré ci-dessous. Si une réduction de prix est indiquée dans la liste des hôtels, en plus du texte, le prix initial et le prix final sont retournés. Pour résoudre ce problème, nous renvoyons simplement le prix actuel d'aujourd'hui.

Nous pouvons utiliser une logique simple pour obtenir le dernier prix indiqué dans le texte.
content_price_list = [] for a in content_price: a_split = a.getText().split('\n')[0] if len(a_split) > 5: content_price_list.append(a_split[-4:]) else: content_price_list.append(a_split) print(content_price_list)
Cela nous donnera le résultat suivant:

API
API - interface de programmation d'application (à partir de l'interface de programmation d'application en anglais). Du point de vue de l'exploration de données, il s'agit d'un système Web qui fournit un point de terminaison de données que vous pouvez contacter via la programmation. Habituellement, les données sont renvoyées au format JSON ou XML.
Cette méthode sera probablement utile dans l'apprentissage automatique. Je vais donner un exemple simple de récupération de données météorologiques à partir de l'API publique
Dark Sky . Pour vous y connecter, vous devez vous inscrire et vous aurez 1000 appels gratuits par jour. Cela devrait être suffisant pour les tests.
Pour accéder aux données de Dark Sky, j'utiliserai la bibliothèque de
requests . Tout d'abord, je dois obtenir l'URL correcte pour la demande. En plus des prévisions, Dark Sky fournit des données météorologiques historiques. Dans cet exemple, je vais les prendre et obtenir l'URL correcte dans la
documentation .
La structure de cette URL est:
https://api.darksky.net/forecast/[key]/[latitude],[longitude],[time]
Nous utiliserons la bibliothèque de
requests pour obtenir
résultats pour une latitude et une longitude spécifiques, ainsi que la date et l'heure. Imaginez qu'après avoir extrait les données quotidiennes des prix des hôtels en Crète, nous avons décidé de savoir si la politique des prix est liée à la météo.
Par exemple, prenons les coordonnées de l'un des hôtels de la liste - Mitsis Laguna Resort & Spa.

Créez d'abord une URL avec les coordonnées correctes, ainsi que l'heure et la date demandées. En utilisant la bibliothèque de
requests , nous avons accès aux données au format JSON.
import requests request_url = 'https://api.darksky.net/forecast/fd82a22de40c6dca7d1ae392ad83eeb3/35.3378,-25.3741,2019-07-01T12:00:00' result = requests.get(request_url).json() result
Pour faciliter la lecture et l'analyse des résultats, nous pouvons convertir les données en un bloc de données.
import pandas as pd df = pd.DataFrame.from_dict(json_normalize(result), orient='columns') df.head()

Il existe de nombreuses autres options pour automatiser l'extraction de données à l'aide de ces méthodes. Dans le cas du Web scraping, vous pouvez écrire différentes fonctions pour automatiser le processus et faciliter l'extraction des données pour plus de jours et / ou de lieux. Dans cet article, je voulais revoir et fournir suffisamment d'exemples de code. Les documents suivants seront plus détaillés: je vais vous dire comment créer de grands ensembles de données et les analyser en utilisant les méthodes décrites ci-dessus.
Merci de votre attention!