Il n'y a pas si longtemps, j'étais confronté à la tâche de passer à un nouveau système de BI pour notre entreprise. Comme je devais plonger assez profondément et complètement dans cette question, j'ai décidé de partager mes réflexions à ce sujet avec la communauté réputée.

Sur Internet, il existe de nombreux articles sur ce sujet, mais, à ma grande surprise, ils n'ont pas répondu à beaucoup de mes questions sur le choix du bon outil et étaient quelque peu superficiels. Dans les 3 semaines suivant les tests, nous avons testé 4 outils:
Tableau, Looker, Periscope / Sisense, analyse de mode . Ces outils seront principalement abordés dans cet article. Je dois dire tout de suite que l'article proposé est l'opinion personnelle de l'auteur, reflétant les besoins d'une petite entreprise informatique en pleine croissance :)
Quelques mots sur le marché
Maintenant, des changements assez intéressants se produisent sur le marché de la BI, la consolidation est en cours, les grands acteurs de la technologie cloud essaient de renforcer leurs positions en intégrant verticalement tous les aspects du travail avec les données (stockage, traitement, visualisation des données). Au cours des derniers mois, il y a eu 5 rachats majeurs: Google a acheté Looker, Salesforce a acheté Tableau, Sisense a acheté Periscope Data, Logi Analytics a acheté Zoomdata, Alteryx a acheté ClearStory Data. Nous ne plongerons pas davantage dans le monde des fusions et acquisitions, il convient de noter que de
nouveaux changements dans les prix et les politiques protectionnistes des nouveaux propriétaires d'outils de BI peuvent être attendus (comme l'outil Alooma nous a récemment plu, peu de temps après leur achat par Google, ils cesser de prendre en charge toutes les sources de données, sauf Google BigQuery :)).
Un peu de théorie
Donc, je voulais commencer par une petite partie théorique, car maintenant où sans théorie. Comme nous le dit Gartner, un système de BI est un terme qui combine des produits logiciels, des outils, une infrastructure et les meilleures pratiques, ce qui nous permet d'améliorer et d'optimiser les décisions [1]. Cette définition inclut également le stockage de données et ETL. Dans cet article, je propose de me concentrer sur un segment plus étroit, à savoir les produits logiciels pour la visualisation et l'analyse des données.
Dans la pyramide de création de valeur pour l'entreprise (j'ai eu le courage de proposer une autre présentation de cette structure évidente sur la figure 0), les outils BI se situent après les blocs de stockage des enregistrements et de traitement préliminaire des données (ETL).
Ceci est important à comprendre - la
meilleure pratique dans ce cas est la séparation des tâches ETL et BI . En plus d'un processus plus transparent de travail avec les données, vous ne serez pas non plus lié à une seule solution logicielle et pourrez choisir l'outil le plus approprié pour chacune des tâches ETL et BI. Avec un processus ETL bien structuré et une architecture optimale des tableaux de données, vous pouvez généralement fermer 80% de tous les problèmes commerciaux urgents sans utiliser de logiciel spécial. Cela, bien sûr, nécessitera une implication importante des analystes et de DS. Par conséquent, nous arrivons à la question principale: de quoi avons-nous réellement besoin en premier lieu d'un produit logiciel de BI?
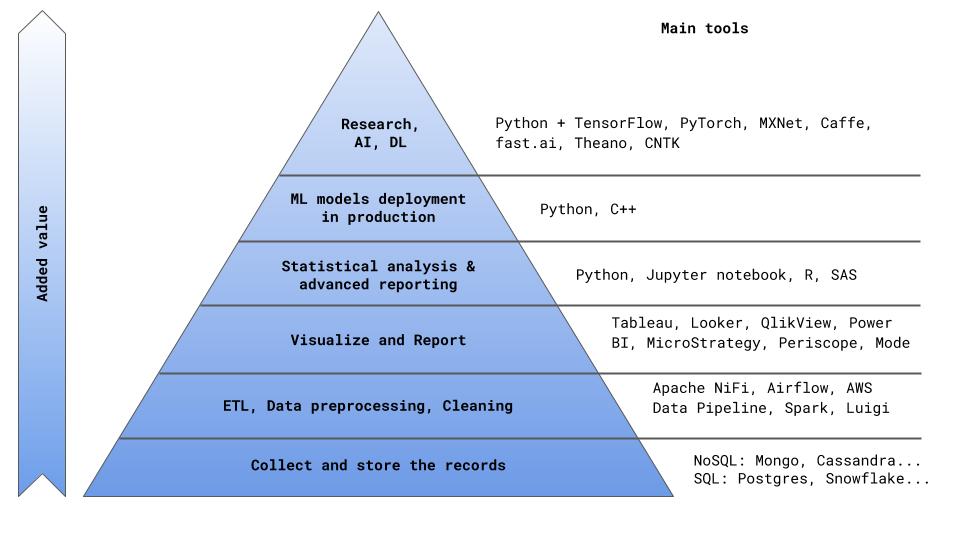
Fig. 0
Critères clés pour choisir un produit logiciel BI
Comme nous l'avons déjà compris, toutes les métriques clés et les indicateurs de performance de l'entreprise dans son ensemble peuvent être directement extraits des tableaux analytiques de la base de données préalablement préparés dans le cadre du processus ETL (je vais vous dire dans le prochain article comment construire de manière optimale un processus ETL En attendant, je vais vous expliquer pourquoi c'est si important: selon un sondage Kaggle, la principale difficulté que la moitié des visages de DS sont des données sales [2]). Le problème principal dans ce cas sera évidemment la complexité et l'inefficacité de l'utilisation du temps des analystes. Au lieu de créer un produit à part entière, les analystes / DS prépareront des indicateurs tout le temps, compteront les mesures, vérifieront les écarts de chiffres, rechercheront les erreurs dans le code SQL et effectueront d'autres activités inutiles. Ici, je suis convaincu que la principale chose que les analystes / DS devraient faire est de créer un produit qui apporte de la valeur à l'entreprise à long terme. Il peut s'agir soit d'un service de règlement / prévisionnel, dont le résultat fait partie du produit principal de l'entreprise (par exemple, un algorithme pour calculer le coût / le temps d'un voyage) ou, par exemple, un algorithme pour la distribution des commandes entre les clients, ou un rapport analytique à part entière qui identifie les raisons du départ des utilisateurs et une diminution de la MAU .
Par conséquent, le principal critère de choix d'un système analytique devrait être la
capacité de décharger autant que possible les analystes des problèmes ponctuels et de la fluidité. Comment y parvenir? En fait, il y a deux options: a) automatiser, b) déléguer. Par le deuxième paragraphe, je veux dire l'expression désormais populaire
Self Service - pour donner aux entreprises la possibilité de se plonger dans les données elles-mêmes.
Autrement dit, les analystes configurent un produit logiciel une fois: créez des cubes de données, configurez la mise à jour automatique des cubes (par exemple, tous les soirs), envoyez automatiquement des rapports, préparez plusieurs assistants de tableau de bord et apprenez aux utilisateurs comment utiliser le produit. En outre, l'entreprise fournit ses besoins supplémentaires de manière indépendante, en calculant les indicateurs nécessaires pour elle dans diverses agrégations et filtrages de données à l'aide de l'option
glisser-déposer simple et compréhensible.
Outre la simplicité du processus de génération de rapports, la
vitesse d'exécution des requêtes est également importante . Personne n'attendra 15 minutes pour le mois précédent pour charger des données ou des métriques pour une autre ville. Pour résoudre ce problème, il existe plusieurs approches généralement acceptées. L'un d'eux est la création de cubes de données
OLAP (traitement analytique en ligne). Dans les cubes OLAP, les types de données sont divisés en dimensions (dimensions) - ce sont des champs par lesquels des agrégations peuvent être effectuées (par exemple, ville, pays, produit, intervalles de temps, type de paiement ...), et les mesures sont des mesures calculées pour les mesures (par exemple nombre de voyages, revenus, nombre de nouveaux utilisateurs, chèque moyen, ...). Les cubes de données sont un outil assez puissant qui vous permet de produire très rapidement des résultats à l'aide de données pré-agrégées et de mesures calculées. Le revers des cubes OLAP est le fait que toutes les données sont pré-collectées et ne changent pas jusqu'à la prochaine génération de cube. Si vous avez besoin d'une agrégation de données ou d'une métrique qui n'a pas été calculée à l'origine, ou si vous avez besoin de données plus récentes, vous devez
recréer le cube de données.
Les solutions
en mémoire constituent une autre solution pour augmenter la vitesse de travail avec les données. La base de données en mémoire (IMDB) est conçue pour fournir des performances maximales lorsqu'il y a suffisamment de RAM pour stocker les données. Alors que les bases de données relationnelles sont conçues pour fournir des performances maximales lorsque les données ne sont pas complètement placées dans la RAM, les E / S de disque lentes doivent être effectuées en temps réel. De nombreux outils modernes combinent ces deux solutions (par exemple, Sisense, Tableau, IBM Cognos, MicroStrategy, etc.).
Avant cela, nous avons parlé de la simplicité et de la commodité de l'utilisation des outils de BI pour les utilisateurs professionnels. Il est important de mettre en place un
processus de développement et de publication de tableau de bord pratique pour les analystes / DS. Ici, la situation est similaire à tout autre produit informatique - vous avez besoin d'un processus de déploiement rapide et pratique (
temps de déploiement rapide ), ainsi que d'un processus de développement réfléchi, de tests, de révision de code, de publication, de contrôle de version, de collaboration d'équipe. Tout cela est combiné par le concept de workflow.
Ainsi, nous arrivons aux
exigences clés du produit logiciel BI . Les mêmes exigences ont constitué la base de la carte de vitesse, sur la base de laquelle nous avons finalement choisi un fournisseur de produits.
Tableau 1. Critères de sélection de l'outil BI.
Le tableau final des résultats de vote au sein de notre équipe est le suivant:
Tableau 2. Résultats du vote pour le choix d'un outil BI.
De la part des utilisateurs professionnels (ils ont également participé à la sélection du produit), les votes ont été répartis à peu près également entre Tableau et Looker. En conséquence, le choix a été fait en faveur de Looker. Pourquoi Looker et quelles sont les différences fondamentales entre les outils, nous allons maintenant discuter.
Description détaillée de l'outil
Commençons donc par la description des outils de BI.
Tableau
(ici nous parlerons d'un package de service étendu: Tableau Online)
- UX + glisser-déposer.
Tableau est un outil assez ancien sur le marché depuis 2003, et on a le sentiment que l'interface n'a pas beaucoup changé depuis lors. Vous pouvez avoir peur des fenêtres contextuelles et des options déroulantes dans le style de Windows XP (Fig. 1, Fig. 2). Mais assez rapidement, vous pouvez vous habituer et maîtriser les fonctionnalités de base de l'outil. Tableau rappelle beaucoup de la version avancée d'Excel, il a des onglets (feuilles de calcul) et des tableaux de bord (Tableaux de bord) - une combinaison de visualisations obtenues sur des feuilles de calcul. L'option glisser-déposer est assez facile à utiliser, les filtres sur les graphiques sont facilement configurables et changent (Fig. 3, Fig. 4). Tableau propose deux versions du service: Desktop et Desktop + Online. Le bureau est plus démodé - il s'agit en fait d'Excel avancé. La version en ligne pour la période de test était souvent réfléchie et finissait parfois par mettre à jour la page sans enregistrer votre travail.
Fig. 1
Fig. 2
Fig. 3
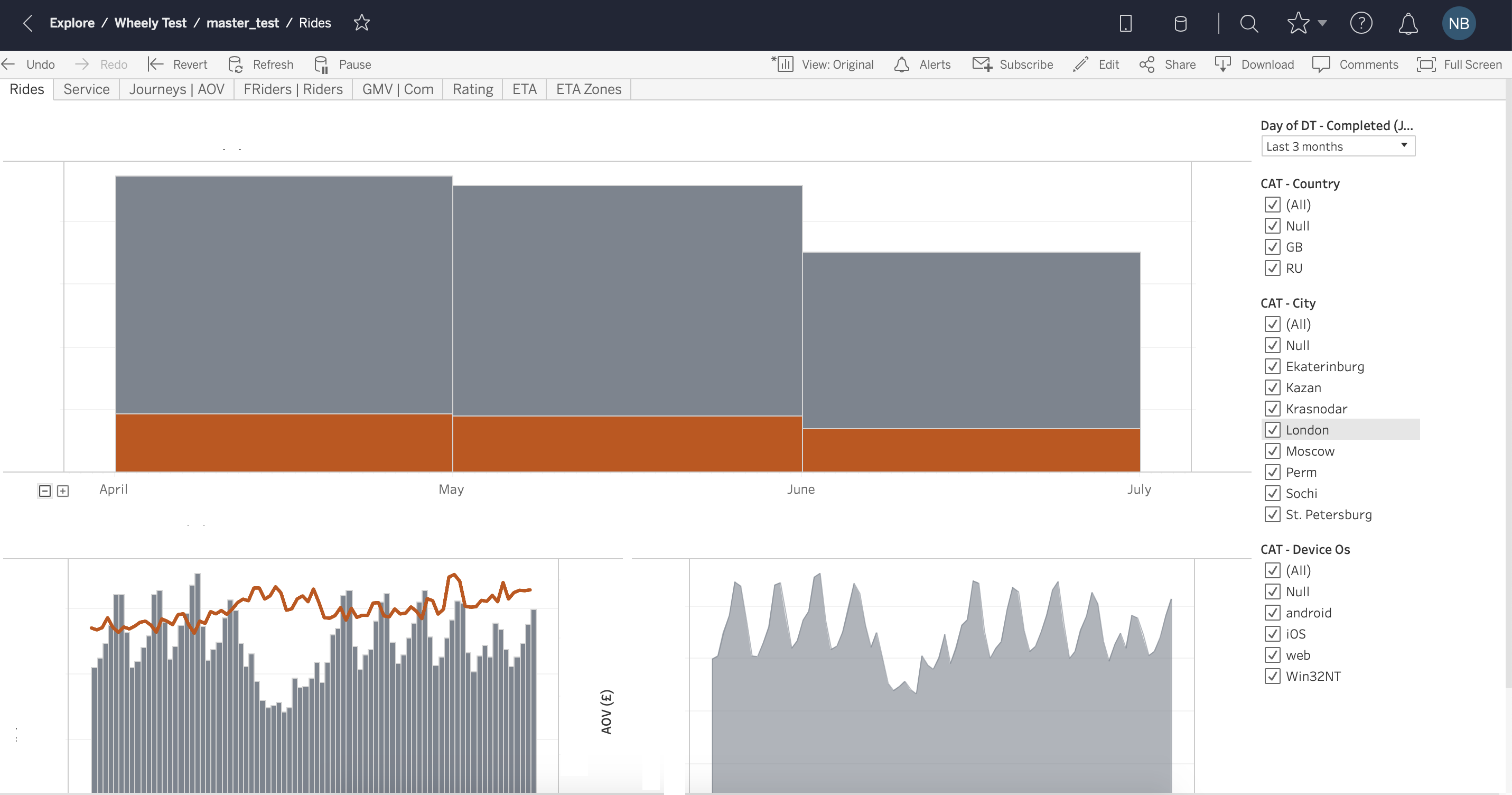
Fig. 4
- Traitement des données.
Tableau gère les données très rapidement, le changement de filtre temporel ou d'agrégation se produit en quelques secondes, même sur de gros volumes de données (plus de 20 millions d'enregistrements). Comme nous l'avons déjà dit, pour cela, Tableau utilise à la fois des cubes de données OLAP et un moteur de données en mémoire. Tableau affirme que grâce à leur solution interne en mémoire Hyper, la vitesse d'exécution des requêtes a été multipliée par 5 .
Les cubes de données peuvent être configurés sur la version locale de Tableau Desktop et téléchargés ou mis à jour sur un serveur réseau, dans ce cas, tous les tableaux de bord construits sur la version précédente de l'assemblage de cube seront automatiquement mis à jour. Les cubes de mise à jour peuvent être configurés automatiquement, par exemple la nuit. Toutes les mesures et mesures (dimensions et mesures) sont définies à l'avance lors de l'assemblage du cube et ne changent pas avant la prochaine version de l'assemblage. Avec l'utilisation de cubes de données dans Tableau, il est possible d'accéder directement à la base de données, c'est ce qu'on appelle la connexion en direct, auquel cas la vitesse sera beaucoup plus faible, mais les données seront plus pertinentes. Le processus d'assemblage d'un cube de données est assez simple, l'essentiel est de sélectionner les champs corrects pour assembler plusieurs tables (jointures) (Fig. 5).
Fig. 5
- Workflow
C'est à cause de ce point que nous n'avons pas choisi Tableau à l'avenir. Selon ce paramètre, Tableau était loin derrière l'industrie et ne pouvait pas proposer d'outils pour simplifier le développement et la publication des tableaux de bord. Tableau ne fournit pas de contrôle de version, de révision de code, de collaboration d'équipe, pas plus qu'il n'y a un environnement de développement et de test bien pensé. C'est précisément pour cette raison que les entreprises abandonnent souvent Tableau au profit d'outils plus avancés. Déjà avec plusieurs employés impliqués dans la création de cubes de données et de tableaux de bord, une confusion peut survenir - où trouver la dernière version des données, quelles mesures peuvent être utilisées et lesquelles ne le peuvent pas. Il y a un manque d'intégrité des données, ce qui conduit à une méfiance de l'entreprise dans les mesures qu'elle voit dans le système.
- Visualisation
En termes de visualisation des données, Tableau est un outil très puissant. Vous pouvez trouver des tableaux et des graphiques pour tous les goûts et couleurs (Fig. 6). Visualisation des données - page, comme dans Excel, vous pouvez basculer entre les onglets.
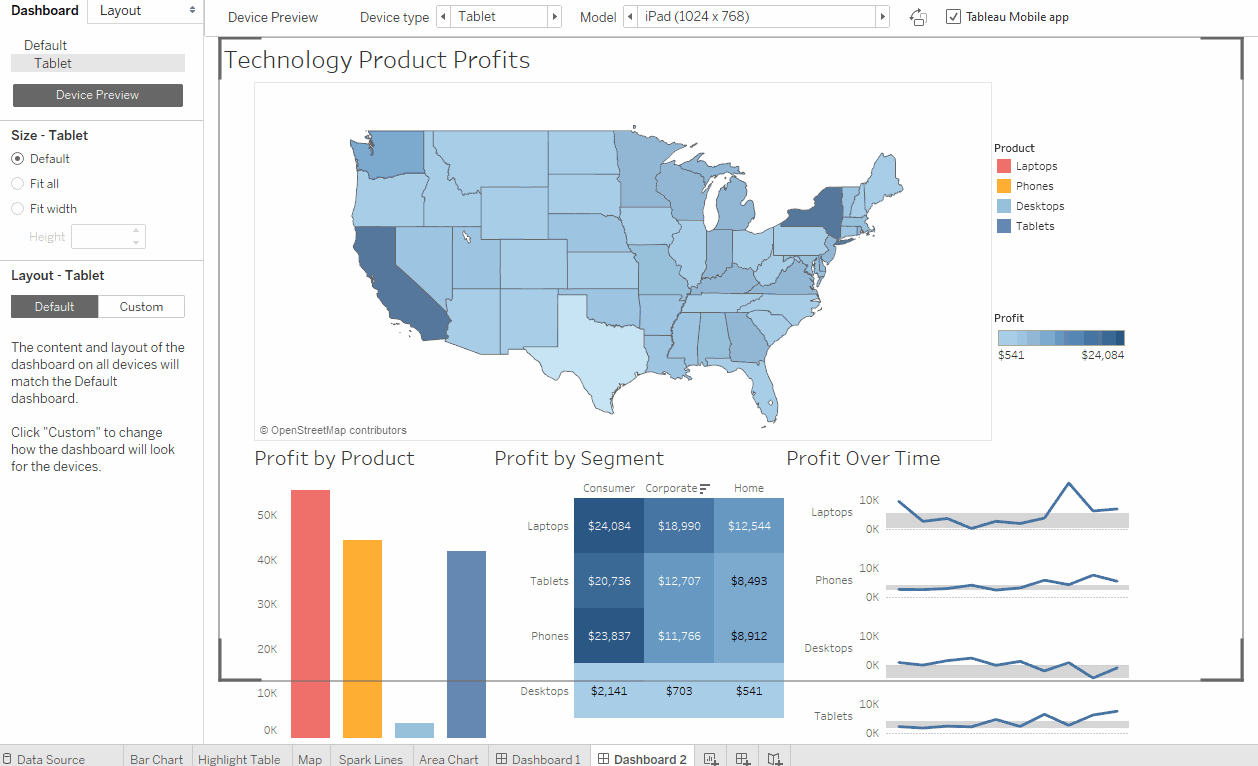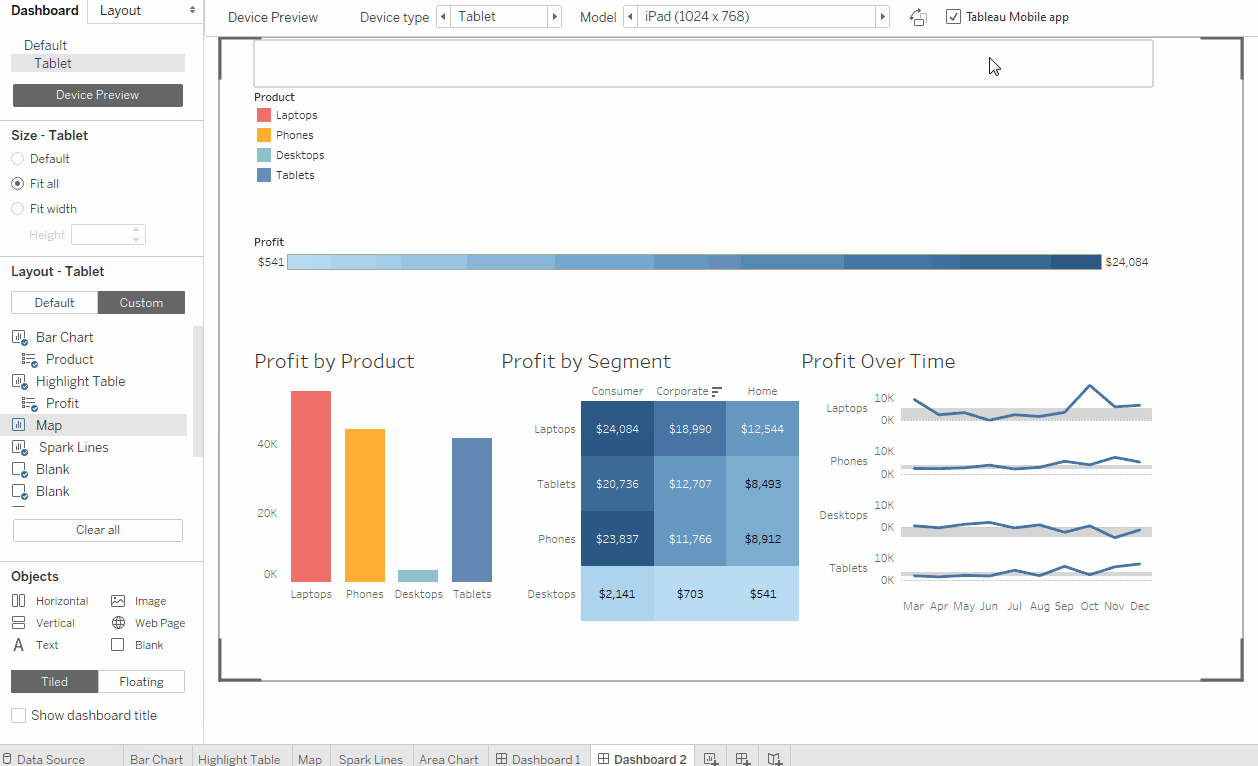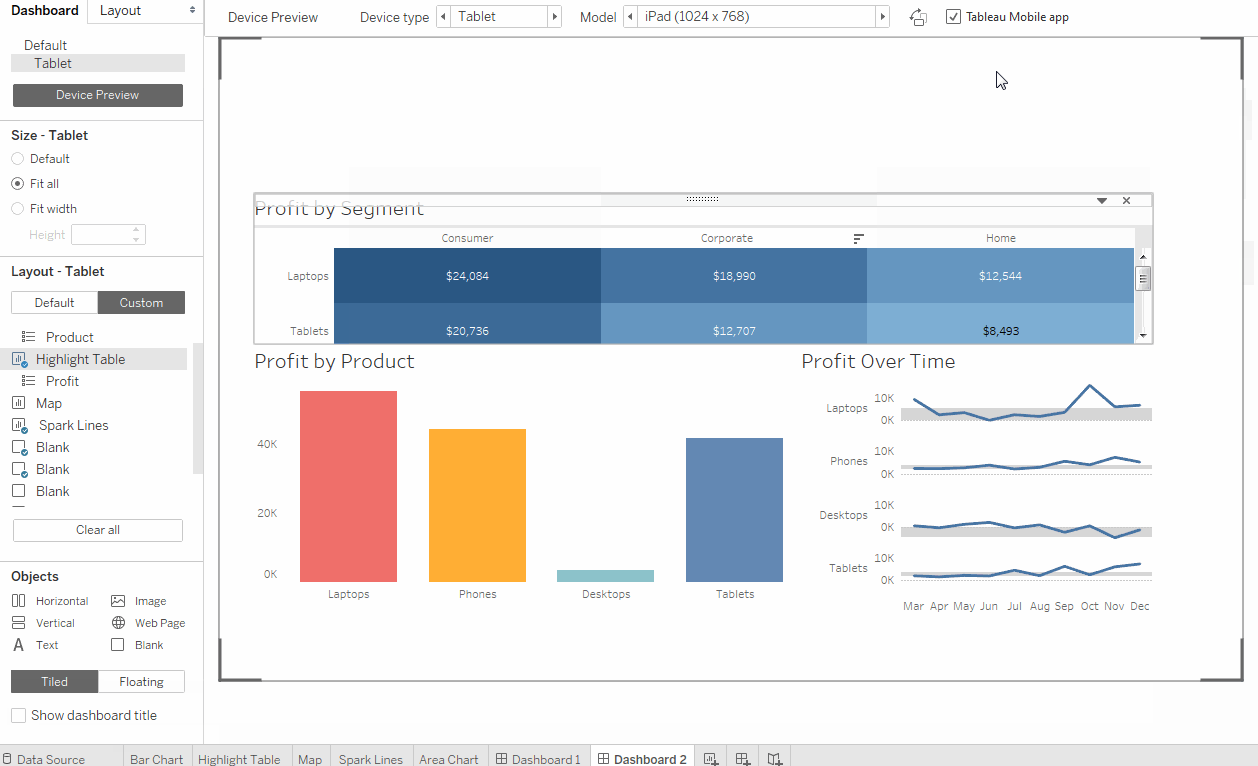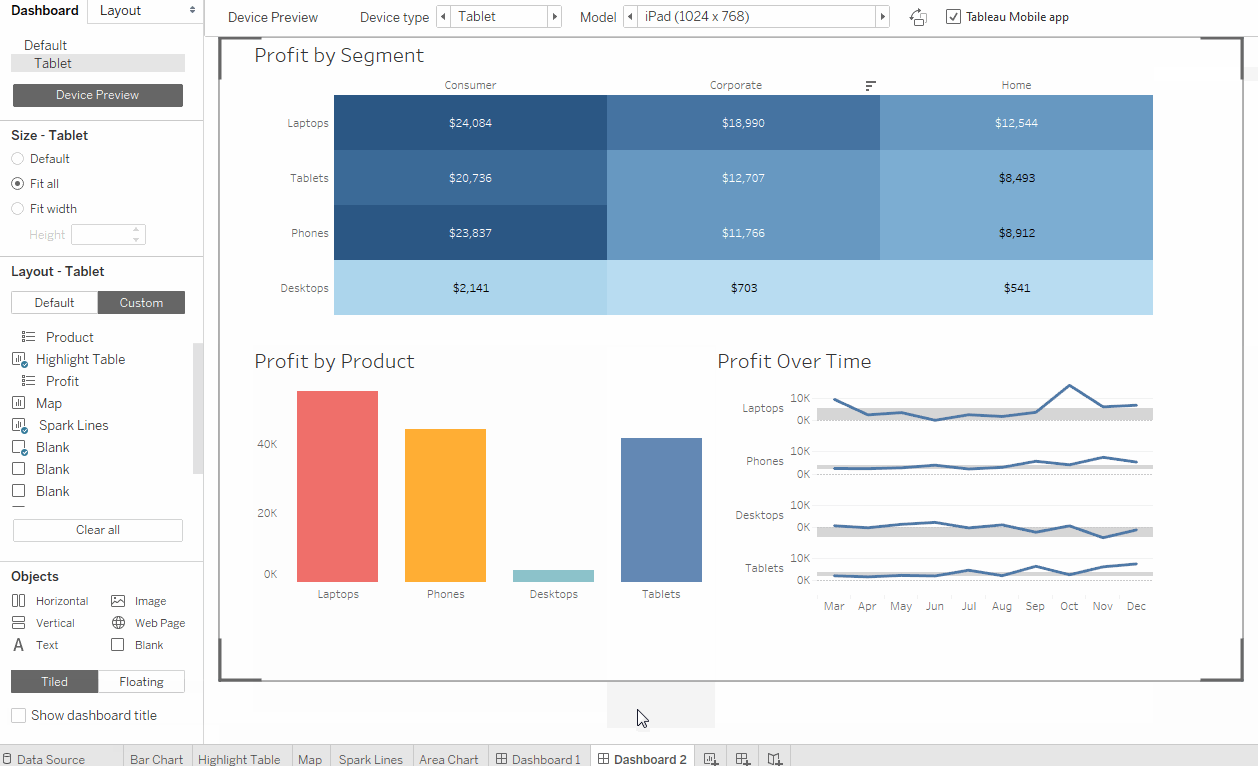
Fig. 6
- Support.
Du point de vue du support Tableau, il me semblait peu orienté client , je devais trouver moi-même la réponse à la plupart des questions. Heureusement, Tableau possède une communauté assez large où vous pouvez trouver des réponses à la plupart des questions.
- Statistiques
Tableau a la capacité de s'intégrer à Python, plus de détails peuvent être trouvés.
- Prix
Les prix sont assez standard pour le marché, peuvent être trouvés sur le site officiel. Le prix dépend du niveau d'utilisateur (développeur, explorateur, visionneuse), la description peut être trouvée ici . Lors du calcul de 10 développeurs, 25 explorateurs et 100 téléspectateurs, 39 000 $ / an sortent par an.
Looker
- UX + glisser-déposer.
Looker est une entreprise relativement jeune, fondée en 2012. UX est nativement clair et simple pour l'utilisateur, le glisser-déposer est commodément implémenté (Fig.7).
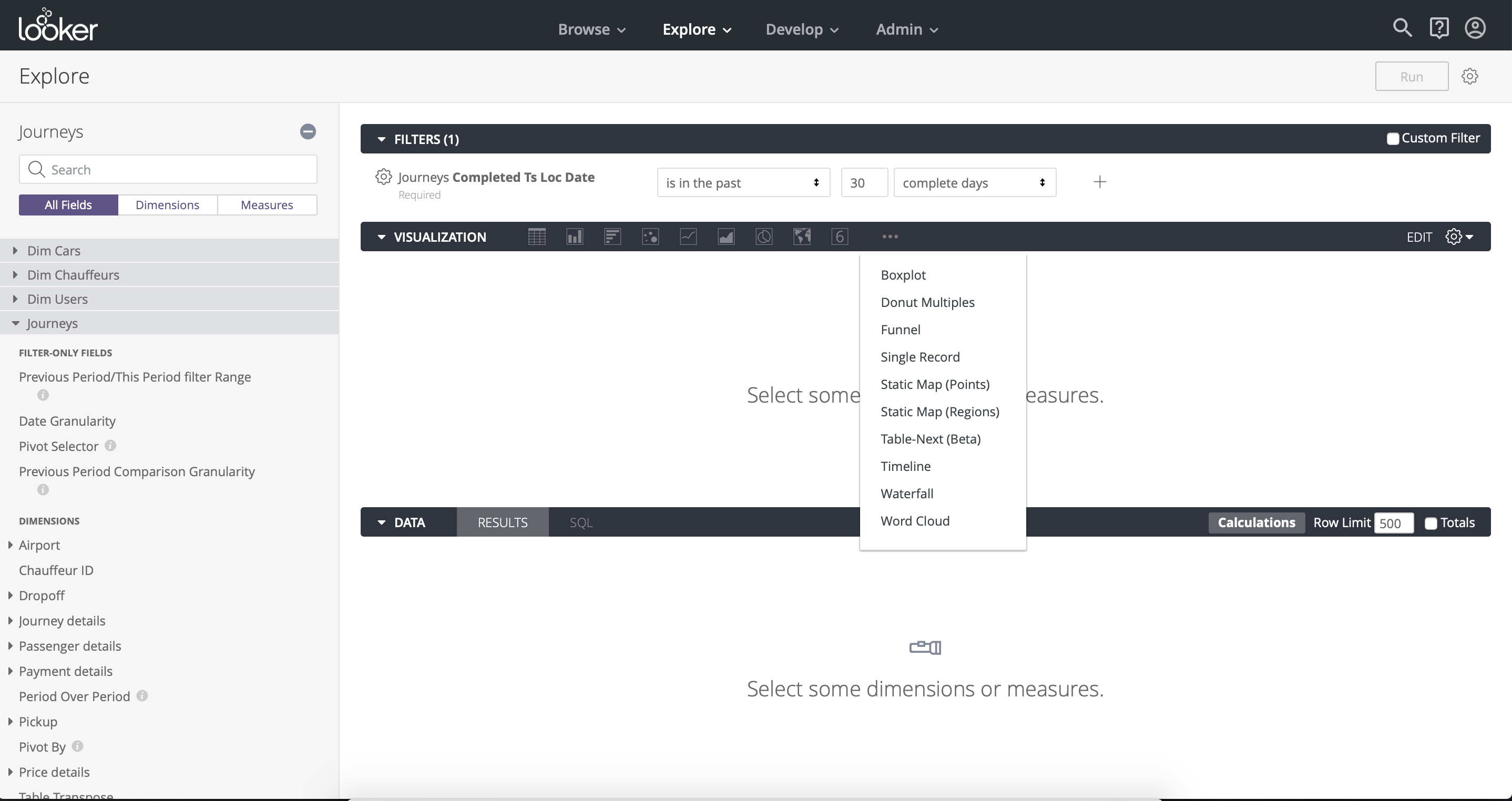
Fig. 7
- Traitement des données.
Travailler avec des données dans Looker est sensiblement plus lent que dans Tableau . La raison principale est que Looker effectue des requêtes directement dans la base de données sans créer de cubes OLAP. Comme nous l'avons vu, cette approche a ses avantages - le fait que les données sont toujours fraîches et que toute agrégation de données peut être effectuée. Looker fournit également un outil pour accélérer les requêtes complexes - les requêtes mises en cache , c'est-à-dire la possibilité de mettre en cache les requêtes.
- Workflow
Le principal avantage de Looker par rapport à tous les outils de BI que nous avons testés est son processus de développement et de publication de tableau de bord bien pensé . Looker intègre le contrôle de version à l' aide de github . L'environnement de développement ( mode Production) et l'environnement productif (Fig. 8) sont également bien séparés. Un autre avantage de Looker est que l'accès à la modélisation des données reste entre les mêmes mains - il n'y a qu'une seule version principale du modèle de données, ce qui garantit l'intégrité.
Il est logique ici de mentionner également que Looker a son propre analogue du langage SQL avec des fonctionnalités supplémentaires pour la modélisation des données - LookML. Il s'agit d'un outil assez simple et flexible qui vous permet de personnaliser la fonctionnalité glisser-déposer et ajoute de nombreuses nouvelles options (Fig. 9).
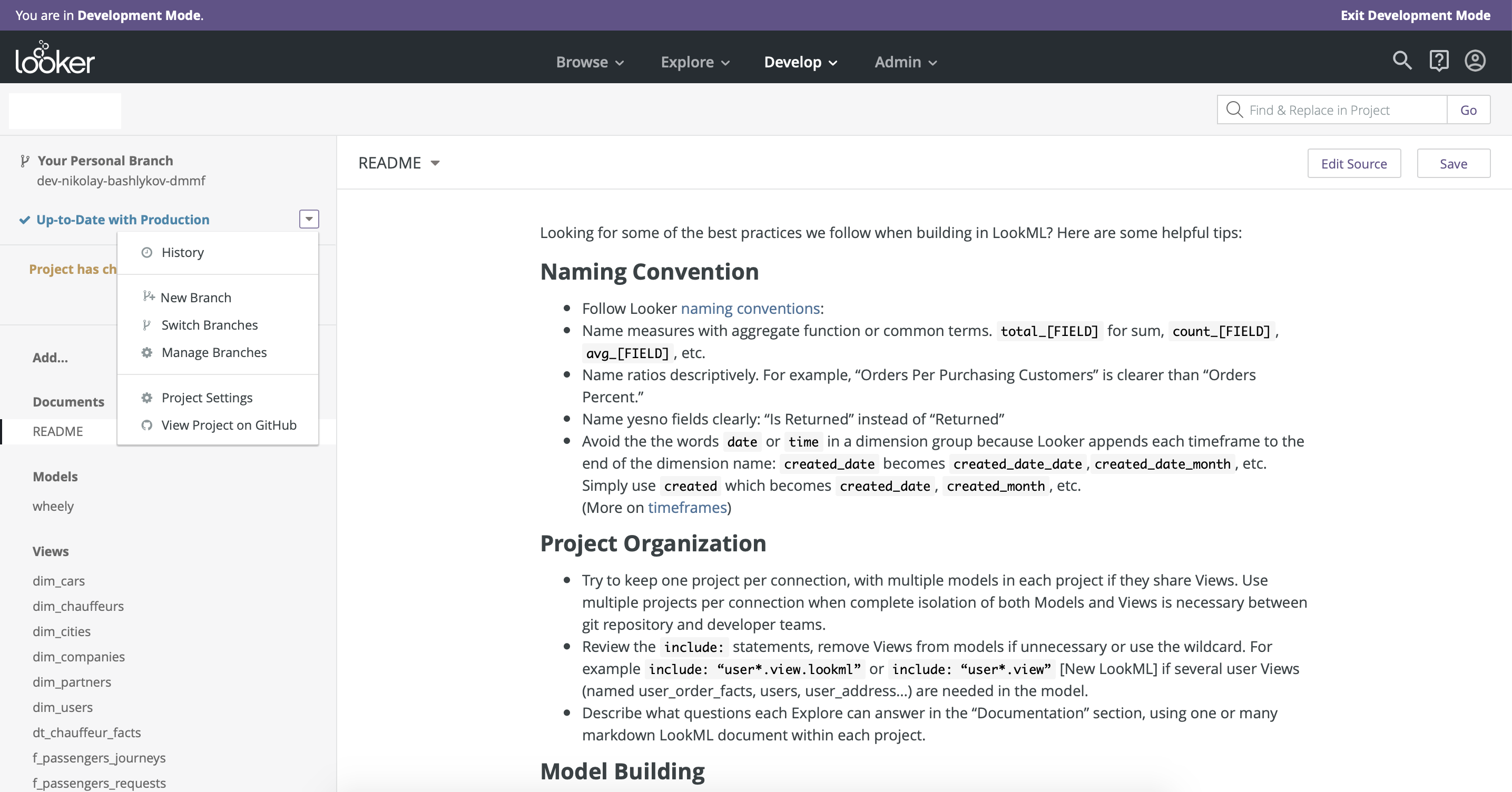
Fig. 8
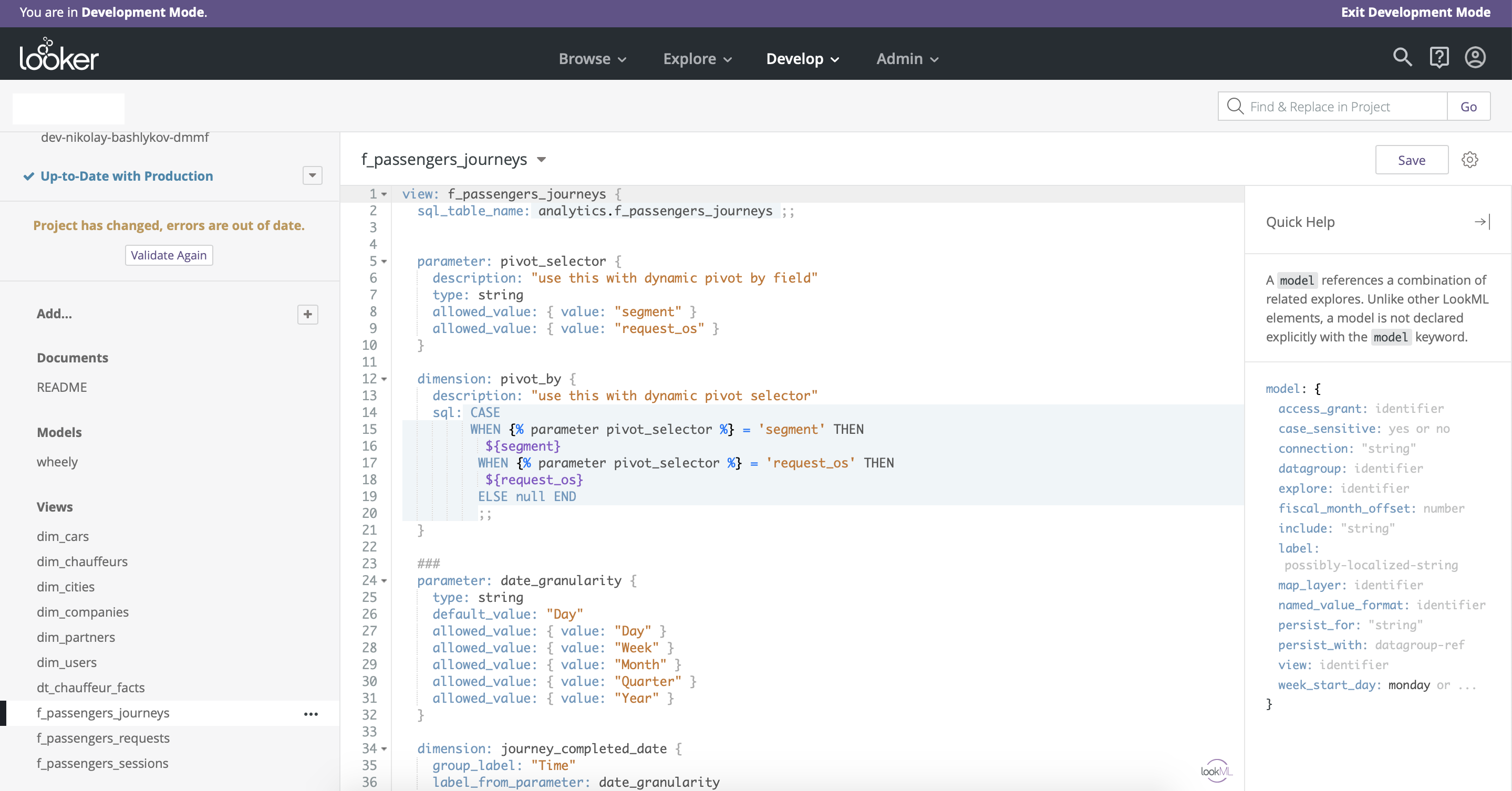
Fig. 9
- Visualisation
Du point de vue de la visualisation, Looker n'est pas très inférieur à Tableau, vous y trouverez des graphiques et des graphiques à votre goût. L'organisation des graphiques est verticale, contrairement à Tableau, où l'organisation est paginée (Fig.10, Fig.11). Une fonctionnalité utile pour les utilisateurs professionnels est l'exploration - la possibilité de segmenter les données sélectionnées dans des dimensions prédéfinies.
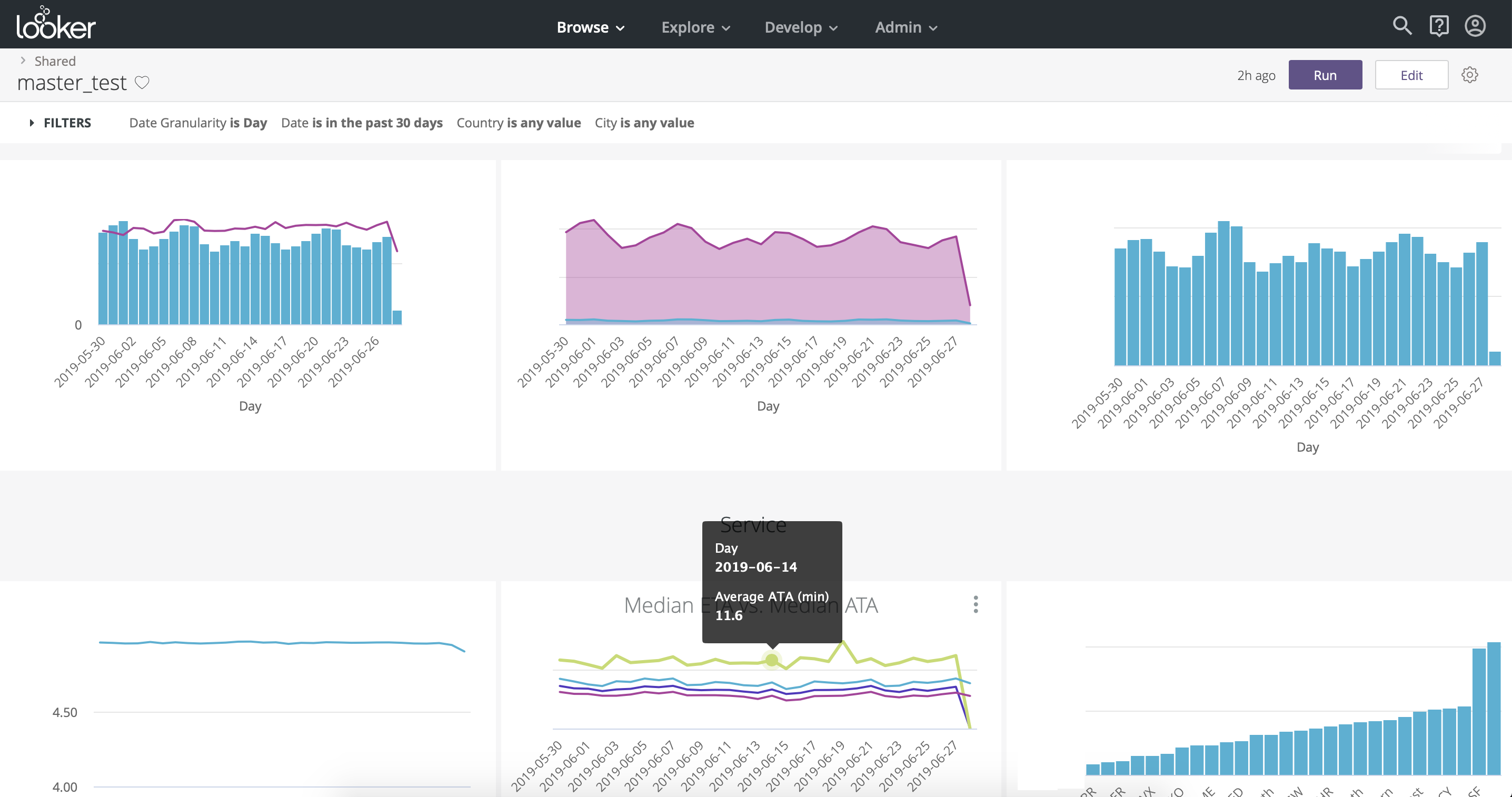
Fig. 10
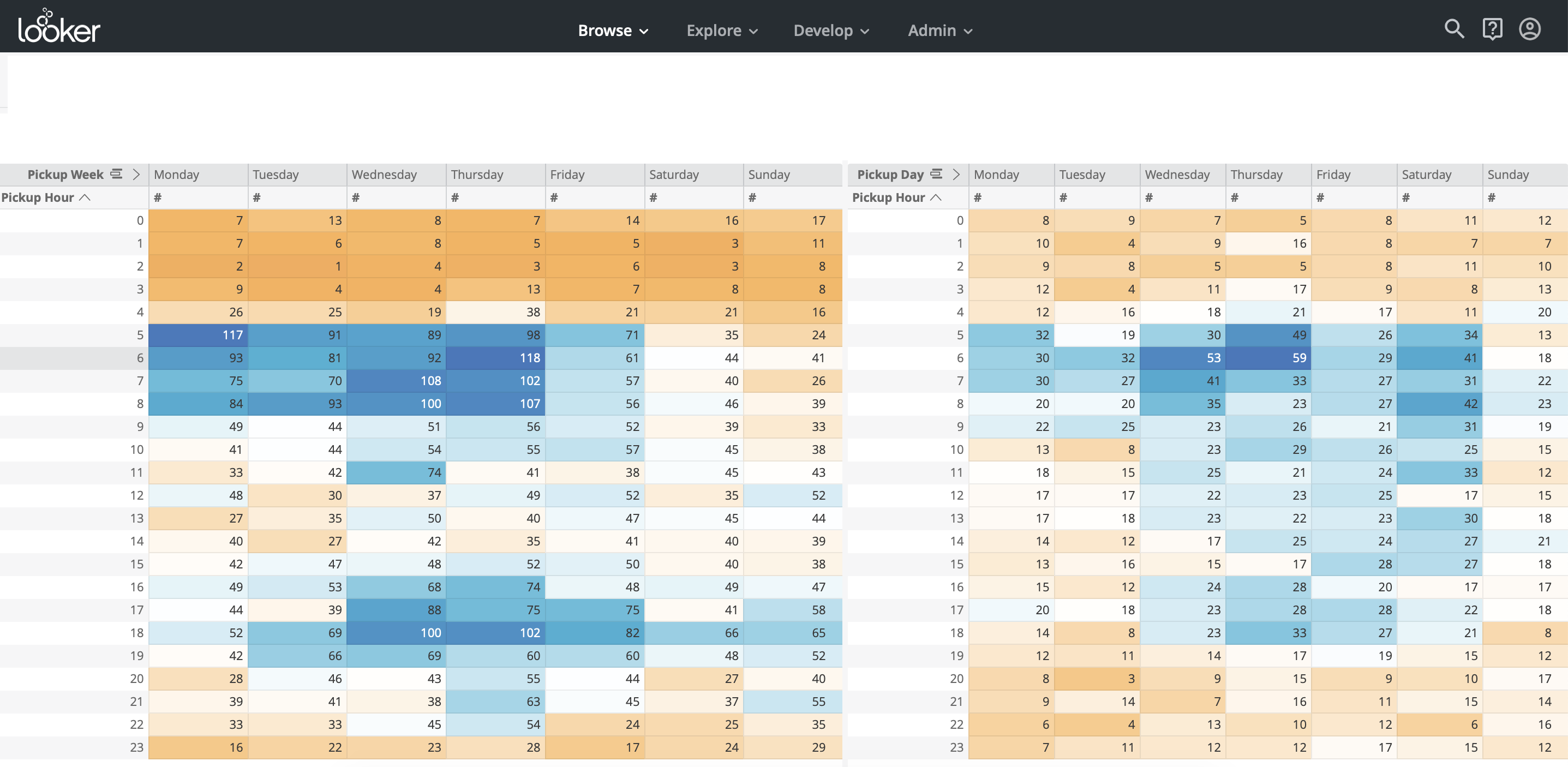
Fig. 11
- Support.
Le soutien des consultants commerciaux et des experts techniques de Looker, je dois dire, était surprenant - nous pouvions planifier un appel vidéo en une demi-heure sur n'importe quel problème et obtenir une réponse complète. Il semble que Looker apprécie vraiment ses clients et essaie de simplifier leur vie.
- Statistiques
Looker a une API - Look API et SDK for Python, avec leur aide, vous pouvez vous connecter à Looker depuis Python et télécharger les informations nécessaires, puis effectuer les transformations et analyses statistiques nécessaires en Python et charger les résultats dans la base de données avec une sortie ultérieure pour les utilisateurs dans les tableaux de bord.
- Prix
Looker coûte beaucoup plus cher que Tableau , pour un ensemble d'utilisateurs similaire, Looker est sorti presque 2 fois plus cher que Tableau - environ 60 000 $ / an.
Périscope
- UX + glisser-déposer.
Periscope est un outil assez facile à utiliser avec des fonctionnalités limitées . Il existe également une fonction de glisser-déposer, mais les filtres pour différents graphiques devront être créés séparément, ce qui n'est pas pratique (Fig.12). Vous ne pouvez pas vous passer de SQL pour créer des requêtes légèrement plus complexes.
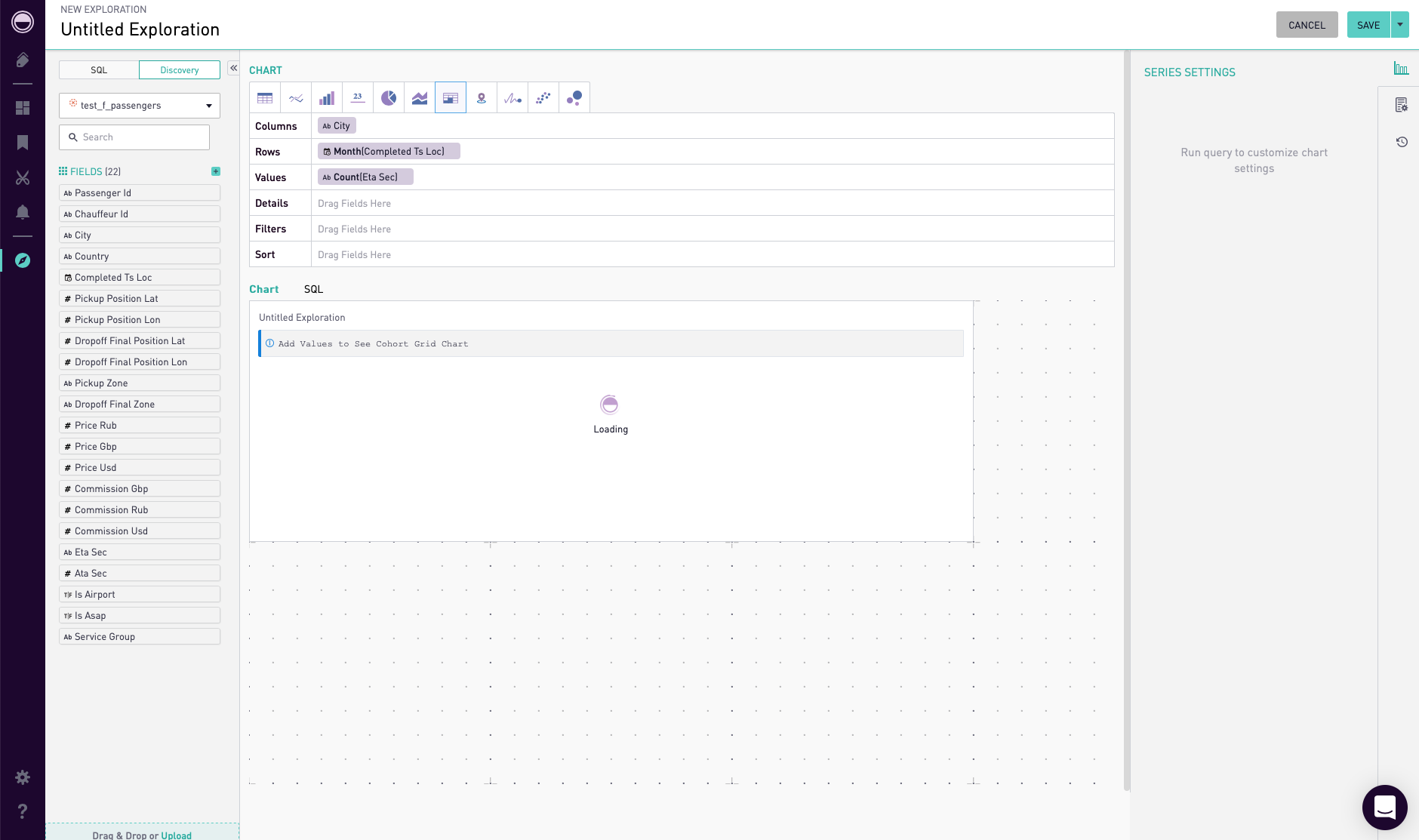
Fig. 12
- Traitement des données.
Periscope a un croisement entre les cubes OLAP et la mise en cache des requêtes. Dans celui-ci, vous pouvez créer des vues et les mettre en cache. La vue est une requête SQL, pour sa mise en cache, il est nécessaire de cliquer sur le bouton «matérialiser» dans les paramètres de cette vue (Fig. 13). Vous pouvez également publier une vue de «publication» afin de pouvoir l'utiliser pour le glisser-déposer.
Fig. 13
- Workflow
Periscope Pro intègre le contrôle de version à l' aide de git. Il est également possible de voir l'historique des modifications apportées à n'importe quel tableau de bord et de revenir à la version précédente.
- Visualisation
L'ensemble des graphiques et des graphiques est très limité; vous ne pouvez pas trouver la variété ici comme dans Tableau ou Looker.
- Support.
Le support est assez opérationnel, si vous apportez la modification que le centre de support fonctionne à l'heure normale du Pacifique. Dans les 24 heures, vous recevrez certainement une réponse.
- Statistiques
Periscope a une intégration avec Python. Plus de détails peuvent être trouvés ici .
- Prix
Periscope Pro coûtera à peu près comme Tableau: 35 000 $.
Analyse des modes
- UX + glisser-déposer.
Le mode est le plus simple de ces outils. Sa principale différence est l'intégration avec Python et la possibilité de créer des rapports analytiques basés sur le bloc-notes Jupyter (Fig. 14). Si vous n'avez pas mis en place le processus de création de rapports analytiques à l'aide du bloc-notes Jupyter, cet outil peut vous être utile. Le mode est plutôt un ajout à un système de BI à part entière, sa fonctionnalité est très limitée, dans le but de créer des tableaux de bord, vous pouvez utiliser des tableaux ne dépassant pas 27000 lignes, ce qui limite considérablement les capacités de l'outil (Fig.15). Sinon, vous devez écrire des requêtes SQL distinctes pour chaque graphique afin d'agréger les données et d'obtenir une table de dimension plus petite pour la visualisation (Fig. 16).
Fig. 14
Fig. 15
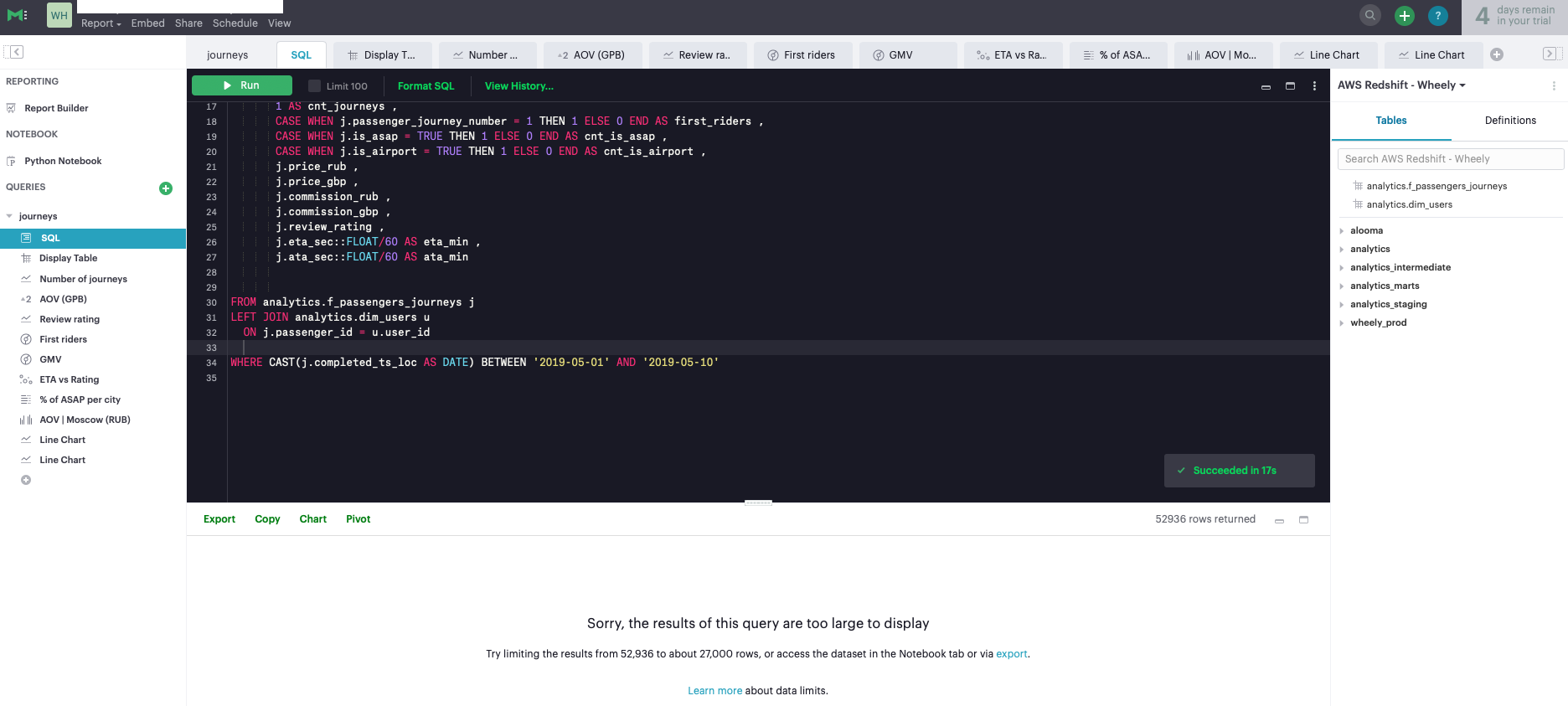
Fig. 16
- Traitement des données.
En mode en tant que tel, la gestion des données est manquante. Toutes les requêtes sont effectuées directement dans la base de données, il n'y a aucun moyen de mettre en cache les tables principales.
- Workflow
Le mode a une intégration avec Github, plus de détails peuvent être trouvés ici .
- Visualisation
L'ensemble des visualisations de données est très limité; il existe 6-7 types de graphiques.
- Support.
Pendant la période d'essai, le soutien a été assez opérationnel.
- Statistiques
Comme déjà mentionné, le mode est bien intégré à Python, ce qui vous permet de créer des rapports analytiques conviviaux à l'aide du bloc-notes Jupyter.
- Prix
Le mode, assez curieusement, est assez cher pour ses capacités - environ 50 000 $ / an.
Conclusions
BI , (, ). , , .
Les sources
- Gartner, Business Intelligence — BI — Gartner IT Glossary
- Kaggle
- Tableau — Hyper
- ZDNet — Salesforce-Tableau, other BI deals flow
- Tableau website
- Looker website
- Periscope website
- Mode analytics website