Présentation
Dans cet article, nous avons supposé que nous parlerons de l'API de capture d'écran. Cette API est née en 2014, et il est difficile de l'appeler nouvelle, mais la prise en charge du navigateur est encore assez faible. Néanmoins, il peut être utilisé pour des projets personnels ou lorsque ce soutien n'est pas si important.
Quelques liens pour vous aider à démarrer:
Au cas où le lien avec la démo tomberait (ou si vous êtes trop paresseux pour y aller) - voici à quoi ressemble la démo terminée:
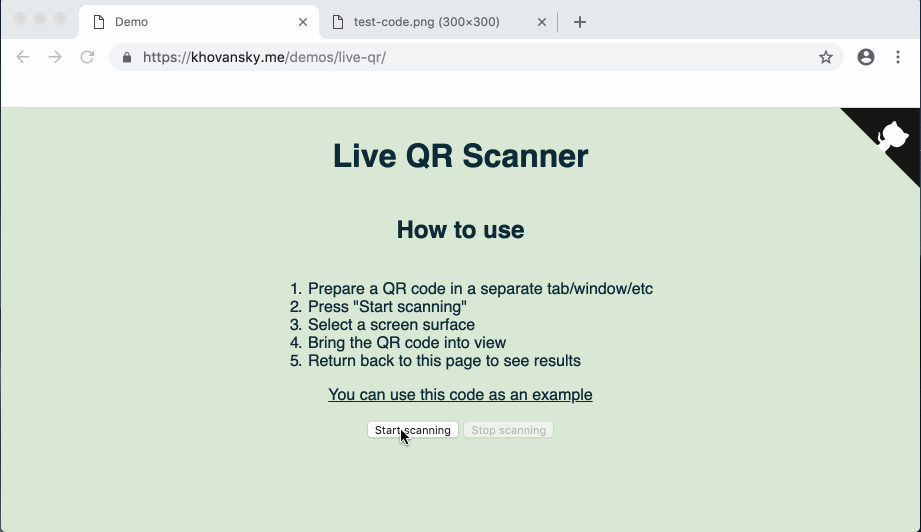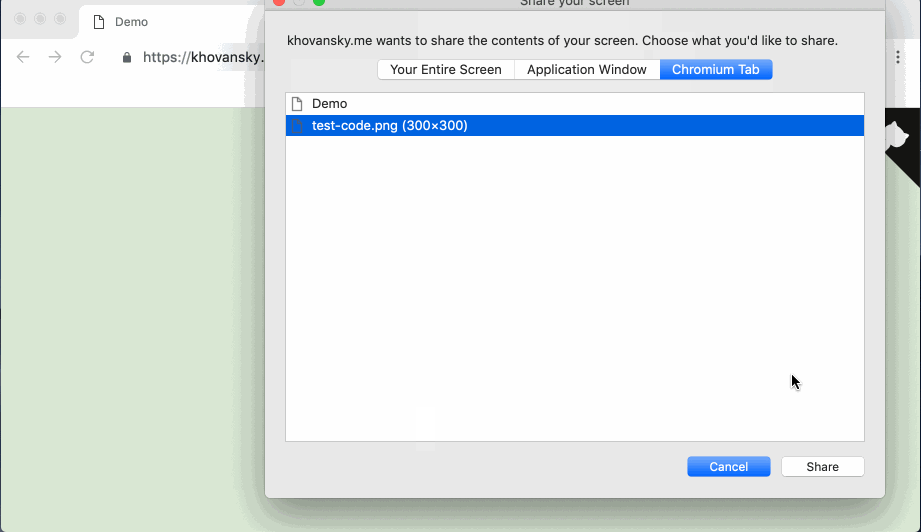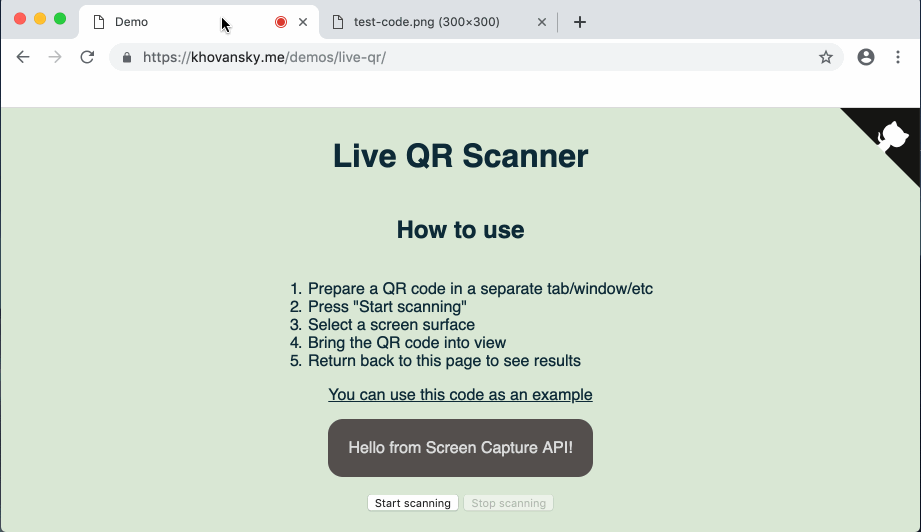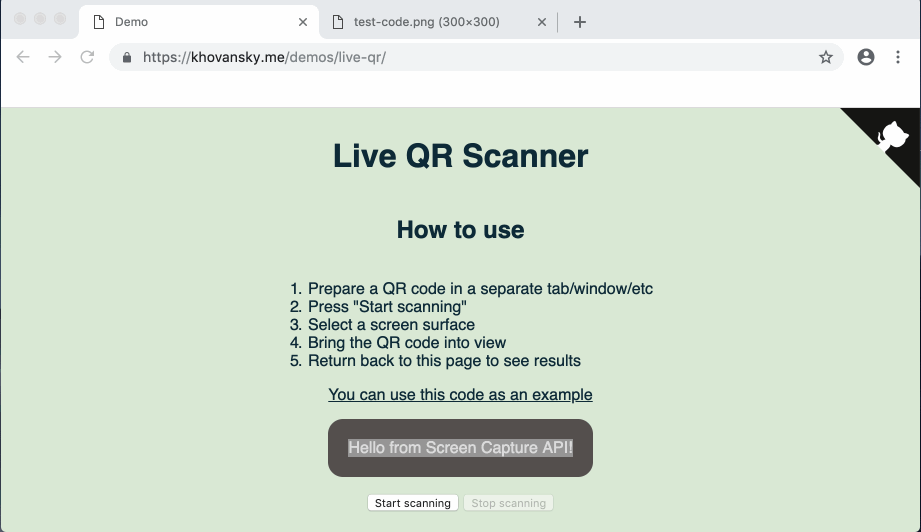
Commençons.
La motivation
Récemment, j'ai eu l'idée d'une application Web qui utilise des codes QR dans son travail. Et bien qu'ils soient généralement pratiques pour envoyer, par exemple, de longs liens dans le monde réel, où vous pouvez pointer le téléphone vers eux, sur le bureau, c'est un peu plus compliqué. Si le code QR est sur l'écran du même appareil sur lequel vous devez le lire, vous devez jouer avec les services pour la reconnaissance ou le reconnaître depuis le téléphone et retransférer les données sur le PC. Inopportunément.
Certains produits, tels que 1Password , incluent une solution intéressante pour cette situation. Si vous devez configurer un compte à partir d'un code QR, ils ouvrent une fenêtre translucide que vous pouvez faire glisser sur l'image avec le code, et il est automatiquement reconnu. Voici à quoi ça ressemble:
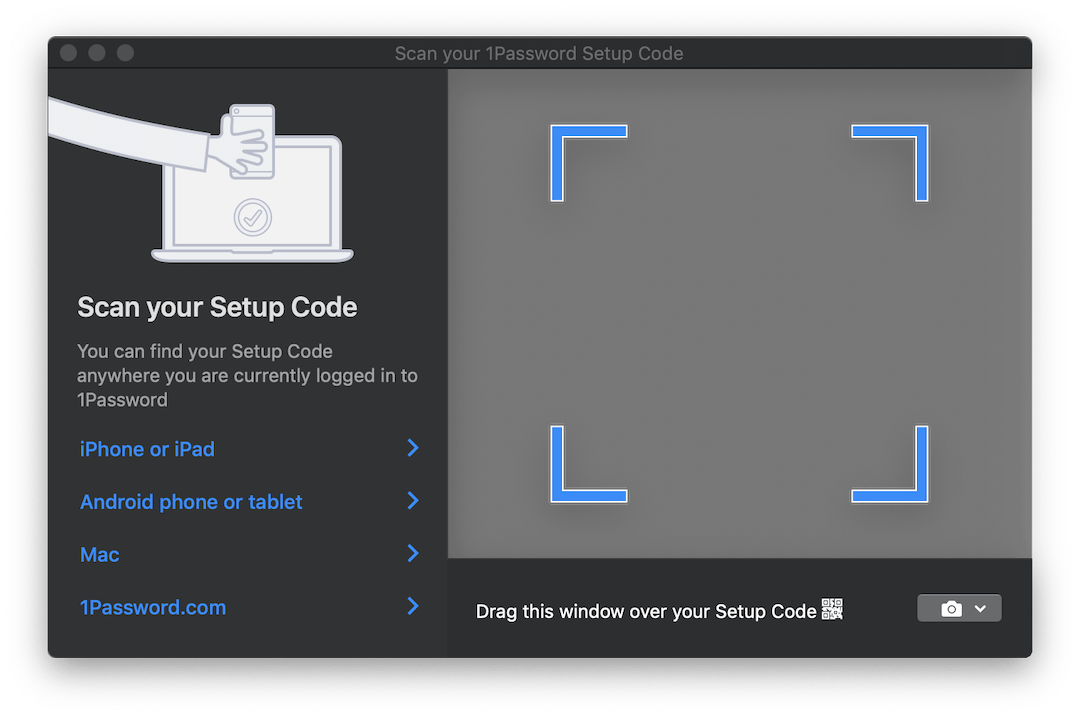
Ce serait idéal si nous pouvions implémenter quelque chose de similaire pour notre application. Mais cela ne fonctionnera probablement pas dans le navigateur ...
Enfin presque. Ici, l'API de capture d'écran avec sa seule méthode getDisplayMedia nous getDisplayMedia . getDisplayMedia est comme getUserMedia , uniquement pour l'écran de l'appareil, au lieu de sa caméra. Malheureusement, la prise en charge du navigateur, comme mentionné ci-dessus, est loin d'être aussi répandue que l'accès à la caméra. Selon MDN, vous pouvez l'utiliser dans Firefox, Chrome, Edge (bien qu'il soit au mauvais endroit - immédiatement dans le navigator , et non dans navigator.mediaDevices ) + Edge Mobile et ... Opera pour Android.
Une sélection assez curieuse de navigateurs mobiles à côté des Big Two attendus.
L'API elle-même est extrêmement simple. Il fonctionne de la même manière que getUserMedia , mais vous permet de capturer un flux vidéo à partir de l'une des surfaces d'affichage définies:
- depuis le moniteur (écran entier),
- à partir d'une fenêtre ou de toutes les fenêtres d'une certaine application,
- depuis un navigateur , ou plutôt depuis un document spécifique. Dans Chrome, ce document est un onglet séparé, mais dans FF il n'y a pas une telle option.
API du navigateur, qui vous permet de regarder au-delà du navigateur ... Cela semble familier et augure généralement de quelques problèmes, mais dans ce cas, cela peut être très pratique. Vous pouvez capturer une image à partir d'autres fenêtres et, par exemple, reconnaître et traduire du texte en temps réel, comme Google Translate Camera. Eh bien, et il y a probablement beaucoup d'autres utilisations intéressantes.
Nous collectons
Nous avons donc compris les capacités que l'API nous offre. Et ensuite?
Et puis nous devons dépasser ce flux vidéo en images sur lesquelles nous pouvons travailler. Pour ce faire, nous utilisons les éléments <video> , <canvas> et quelques autres JS.
Un gros plan du processus ressemble à ceci:
- Flux direct vers
<video> ; - Avec une certaine fréquence, dessinez le contenu de la
<video> dans <canvas> ; - Collectez un objet ImageData à partir de
<canvas> à l'aide de la méthode de contexte getImageData 2D.
Toute cette procédure peut sembler un peu étrange en raison d'un si long pipeline, mais cette méthode est assez populaire et a été utilisée pour capturer des données de webcams dans getUserMedia .
En omettant tout ce qui n'est pas pertinent, afin de démarrer le flux et d'en retirer le cadre, nous avons besoin du code suivant:
async function run() { const video = document.createElement('video'); const canvas = document.createElement('canvas'); const context = canvas.getContext('2d'); const displayMediaOptions = { video: { cursor: "never" }, audio: false } video.srcObject = await navigator.mediaDevices.getDisplayMedia(displayMediaOptions); const videoTrack = video.srcObject.getVideoTracks()[0]; const { height, width } = videoTrack.getSettings(); context.drawImage(video, 0, 0, width, height); return context.getImageData(0, 0, width, height); } await run();
Comme mentionné ci-dessus: nous créons d'abord les éléments <video> et <canvas> et demandons au canevas un contexte 2D ( CanvasRenderingContext2D ).
Ensuite, nous définissons les restrictions / conditions de flux. Contrairement aux flux de la caméra, il y en a peu. Nous disons que nous ne voulons pas voir le curseur et que nous n'avons pas besoin d'audio. Bien qu'au moment d'écrire ces lignes, la capture audio n'est toujours prise en charge par personne.
Après cela, nous accrochons le flux reçu de type MediaStream à l'élément <video> . Notez que getDisplayMedia renvoie une promesse.
Enfin, à partir des données reçues sur le flux, nous nous souvenons de la résolution de la vidéo afin de la dessiner correctement sur le canevas, dessiner le cadre et extraire l'objet ImageData du ImageData .
Pour une utilisation complète, vous souhaiterez probablement traiter les images en boucle plutôt qu'une fois. Par exemple, pendant que vous attendez lorsque l'image souhaitée apparaît dans le cadre. Et ici, il faut dire quelques mots.
Quand il s'agit de «gérer quelque chose dans le DOM dans une boucle constante», la première chose qui vient à l'esprit est très probablement requestAnimationFrame . Cependant, dans notre cas, son utilisation ne fonctionnera pas. Le fait est que lorsque l'onglet cesse d'être actif - les navigateurs suspendent le traitement de la boucle rAF. Dans notre cas, c'est à ce moment que nous voudrons traiter les images.
À cet égard, au lieu de rAF, nous utiliserons le bon vieux setInterval . Mais les choses ne vont pas si bien avec lui. Dans un onglet inactif, l'intervalle entre les opérations de rappel est d' au moins 1 seconde . Néanmoins, cela nous suffit.
Enfin, lorsque nous arrivons aux cadres, nous pouvons les traiter à notre guise. Pour les besoins de cette démo, nous utiliserons la bibliothèque jsQR . C'est extrêmement simple: l'entrée accepte ImageData , la largeur et la hauteur de l'image. Si l'image reçue a un code QR, vous obtiendrez un objet JS avec des données reconnues.
Complétons notre exemple précédent avec juste quelques lignes de code supplémentaires:
const imageData = await run(); const code = jsQR(imageData.data, streamWidth, streamHeight);
C'est fait!
NPM
Je pensais que le code principal derrière cet exemple pourrait être empaqueté dans une bibliothèque npm et gagner du temps lors de l'utilisation initiale pour une utilisation ultérieure. La bibliothèque est très simple, à ce stade, elle accepte simplement le rappel auquel ImageData sera envoyé, et un paramètre supplémentaire est la fréquence d'envoi des données. Tout le traitement dont vous avez besoin pour apporter le vôtre. Je vais réfléchir à l'opportunité d'étendre ses fonctionnalités.
La bibliothèque s'appelle stream-display : NPM | Github .
Son utilisation est réduite à trois lignes de code et à un rappel:
const callback = imageData => {...}
La démo peut être vue ici . Il existe également une version CodePen pour des expériences rapides. Les deux exemples utilisent le package NPM ci-dessus.
Un peu sur les tests
En emballant ce code dans la bibliothèque, j'ai dû réfléchir à la façon de le tester. Je ne voulais absolument pas faire glisser 50 Mo de Chrome sans tête pour y exécuter quelques petits tests. Et même si l'idée d'écrire des talons pour tous les composants semblait trop douloureuse, je l'ai finalement fait.
En tant que testeur, la tape été sélectionnée. Voici ce que j'ai finalement dû simuler:
document les éléments objet et DOM. Pour cela, j'ai pris jsdom ;- certaines méthodes jsdom qui manquent d'implémentation:
HTMLMediaElement#play , HTMLCanvasElement#getContext et navigator.mediaDevices#getDisplayMedia ; - le temps. Pour ce faire, j'ai utilisé les
useFakeTimers bibliothèque useFakeTimers , qui sous le capot appelle lolex . Il définit ses remplacements sur setInterval , requestAnimationFrame et de nombreuses autres fonctions qui fonctionnent avec le temps, et vous permet également de contrôler le flux de ce faux temps. Mais attention: jsdom utilise le passage du temps à un endroit de son processus d'initialisation, et si vous allumez sinon d'abord, tout se fige.
J'ai également utilisé sinon pour tous les stubs de fonction qui devaient être surveillés. Le reste a été implémenté par des fonctions JS vides.
Bien entendu, vous êtes libre de choisir les outils que vous connaissez déjà. Mais j'espère que cette liste vous permettra de la préparer à l'avance, puisque maintenant vous savez à quoi vous devez faire face.
Le résultat final peut être vu dans le référentiel de la bibliothèque. Ça n'a pas l'air trop joli, mais ça marche.
Conclusion
La solution ne s'est pas avérée aussi élégante que la fenêtre transparente mentionnée au début de l'article, mais peut-être que le Web y arrivera un jour. On ne peut qu'espérer que lorsque les navigateurs apprendront à voir à travers leurs fenêtres - ces capacités seront strictement contrôlées par nous. En attendant, rappelez-vous que lorsque vous fouillez l'écran dans Chrome - il peut être analysé, enregistré, etc. Alors ne fouillez pas plus que nécessaire!
J'espère que quelqu'un après cet article a appris une nouvelle astuce pour lui-même. Si vous avez des idées sur quoi d'autre cela peut être utilisé, écrivez dans les commentaires. Et à bientôt.