
Il y a presque 9 ans, Cloudflare était une toute petite entreprise, mais je n'y travaillais pas, j'étais juste un client. Un mois après le lancement de Cloudflare, j'ai reçu une notification indiquant que DNS ne semble pas fonctionner sur mon site Web jgc.org. Cloudflare a modifié les tampons de protocole et il y a eu un DNS cassé.
J'ai immédiatement écrit à Matthew Prince, en tête de la lettre "Où est mon DNS?", Et il a envoyé une longue réponse, pleine de détails techniques ( lire toute la correspondance ici ), à laquelle j'ai répondu:
De: John Graham Cumming
Date: 7 octobre 2010 9:14
Objet: Re: Où est mon DNS?
À: Matthew Prince
Rapport sympa, merci. J'appellerai certainement s'il y a des problèmes. Cela vaut probablement la peine d'écrire un article à ce sujet lorsque vous collectez toutes les informations techniques. Je pense que les gens aimeront une histoire ouverte et honnête. Surtout si vous y joignez des graphiques pour montrer comment le trafic a augmenté après le lancement.
J'ai une bonne surveillance sur le site, et je reçois un SMS sur chaque panne. La surveillance montre que l'échec s'est produit entre 13 h 03 min 07 s et 14 h 04 min 12 s. Les tests sont effectués toutes les cinq minutes.
Je suis sûr que vous le comprendrez. Vous n'avez certainement pas besoin de votre propre personne en Europe? :-)
Et il a répondu:
De: Matthew Prince
Date: 7 octobre 2010, 9:57
Objet: Re: Où est mon DNS?
À: John Graham Cumming
Je vous remercie Nous avons répondu à tous ceux qui ont écrit. Je vais au bureau maintenant, et nous écrirons quelque chose sur le blog ou publierons un message officiel sur notre babillard. Je suis entièrement d'accord, l'honnêteté est notre tout.
Maintenant, Cloudflare est une très grande entreprise, j'y travaille, et maintenant je dois écrire ouvertement sur notre erreur, ses conséquences et nos actions.
Événements du 2 juillet
Le 2 juillet, nous avons déployé une nouvelle règle dans les règles gérées pour WAF, en raison des ressources processeur épuisées sur chaque cœur de processeur qui traite le trafic HTTP / HTTPS sur le réseau Cloudflare à travers le monde. Nous améliorons constamment les règles gérées pour WAF en réponse aux nouvelles vulnérabilités et menaces. En mai, par exemple, nous nous sommes précipités pour ajouter une règle pour nous protéger d'une grave vulnérabilité dans SharePoint. L'intérêt de notre WAF est la capacité de déployer rapidement et globalement des règles.
Malheureusement, la mise à jour de jeudi dernier contenait une expression régulière qui a dépensé pour revenir en arrière sur trop de ressources processeur allouées pour HTTP / HTTPS. Cela a affecté nos fonctionnalités principales de proxy, CDN et WAF. Le graphique montre que les ressources du processeur pour servir le trafic HTTP / HTTPS atteignent presque 100% sur les serveurs de notre réseau.
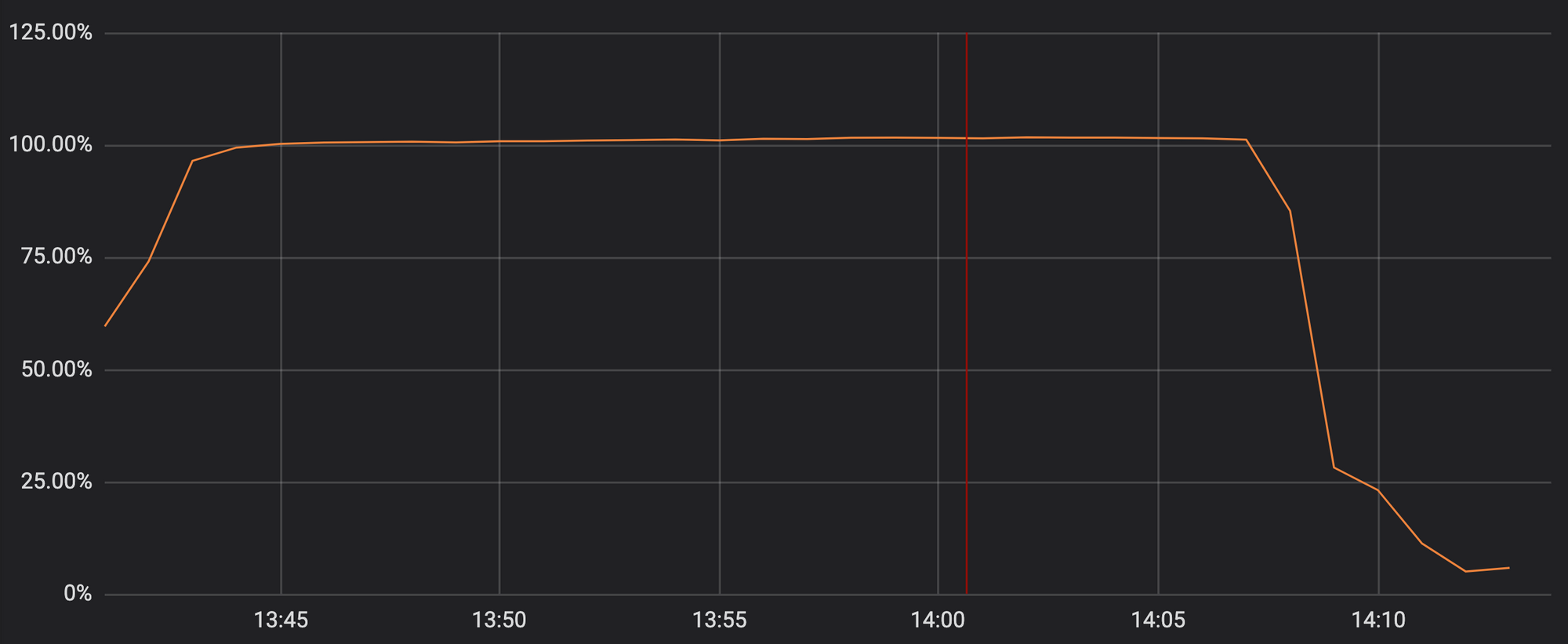
Utilisation des ressources du processeur à l'un des points de présence lors d'un incident
En conséquence, nos clients (et les clients de nos clients) sont tombés sur une page avec une erreur 502 dans les domaines Cloudflare. 502 erreurs ont été générées par les serveurs Web frontaux Cloudflare, qui avaient toujours des noyaux gratuits, mais ils n'ont pas pu contacter les processus qui traitent le trafic HTTP / HTTPS.
Nous savons combien d'inconvénients cela a causé à nos clients. Nous avons terriblement honte. Et cet échec nous a empêchés de traiter efficacement l'incident.
Si vous étiez l'un de ces clients, cela vous a probablement effrayé, irrité et bouleversé. De plus, nous n'avons pas connu d' échecs mondiaux depuis 6 ans. La consommation élevée de CPU était due à une règle WAF avec une expression régulière mal formulée, ce qui a conduit à un retour en arrière excessif. Voici l'expression coupable: (?:(?:\"|'|\]|\}|\\|\d|(?:nan|infinity|true|false|null|undefined|symbol|math)|\`|\-|\+)+[)]*;?((?:\s|-|~|!|{}|\|\||\+)*.*(?:.*=.*)))
Bien qu'il soit intéressant en soi (et je vais vous en dire plus ci-dessous), le service Cloudflare a été interrompu pendant 27 minutes, non seulement en raison d'une expression régulière impropre. Il nous a fallu un certain temps pour décrire la séquence des événements qui ont conduit à l'échec, nous n'avons donc pas réagi rapidement. À la fin de l'article, je décrirai le retour en arrière dans l'expression régulière et vous dirai quoi faire à ce sujet.
Qu'est-il arrivé?
Commençons dans l'ordre. Tout le temps est indiqué ici en UTC.
À 13h42, un ingénieur de l'équipe du pare-feu a apporté une petite modification aux règles de détection de XSS à l' aide d'un processus automatique. Par conséquent, un ticket de demande de changement a été créé. Nous gérons ces billets via Jira (capture d'écran ci-dessous).
Après 3 minutes, la première page PagerDuty est apparue, signalant un problème avec WAF. Il s'agissait d'un test synthétique qui vérifie la fonctionnalité de WAF (nous en avons des centaines) en dehors de Cloudflare afin de surveiller le fonctionnement normal. Puis, immédiatement, il y a eu des pages avec des notifications d'échecs d'autres tests de bout en bout des services Cloudflare, des problèmes de trafic mondial, des erreurs 502 généralisées et un tas de rapports de nos points de présence (PoP) dans des villes du monde entier qui indiquaient un manque de ressources processeur.


J'ai reçu plusieurs de ces notifications, je suis tombé de la réunion et marchais déjà vers la table lorsque le chef de notre service de développement de solutions a déclaré que nous avions perdu 80% du trafic. J'ai couru vers nos ingénieurs SRE qui travaillaient déjà sur le problème. Au début, nous pensions que c'était une sorte d'attaque inconnue.

Les ingénieurs Cloudflare SRE sont dispersés dans le monde et surveillent la situation 24h / 24. En règle générale, ces alertes vous informent de problèmes locaux spécifiques de portée limitée, sont suivies sur des tableaux de bord internes et sont résolues plusieurs fois par jour. Mais ces pages et notifications indiquaient quelque chose de vraiment sérieux, et les ingénieurs SRE ont immédiatement annoncé le niveau de gravité P0 et se sont tournés vers les ingénieurs de gestion et de système.
À ce moment-là, nos ingénieurs londoniens écoutaient une conférence dans le hall principal. La conférence a dû être interrompue, tout le monde s'est réuni dans une grande salle de conférence et d'autres experts ont été invités. Ce n'était pas un problème commun que SRE pouvait comprendre par lui-même. Il était urgent de mettre en relation les bons spécialistes.
À 14h00, nous avons déterminé qu'il y avait un problème avec WAF et qu'il n'y avait pas d'attaque. Le service des performances a récupéré les données du processeur et il est devenu évident que WAF était à blâmer. Un autre collaborateur a confirmé cette théorie avec force. Quelqu'un d'autre a vu dans les journaux que le problème avec WAF. À 14h02, toute l'équipe est venue vers moi quand il a été proposé d'utiliser la suppression globale - un mécanisme intégré à Cloudflare qui désactive un composant dans le monde.
La façon dont nous avons tué Global pour WAF est une autre histoire. Ce n'est pas si simple. Nous utilisons nos propres produits, et puisque notre service d' accès n'a pas fonctionné, nous n'avons pas pu authentifier et entrer dans le panneau de contrôle interne (lorsque tout a été réparé, nous avons appris que certains membres de l'équipe ont perdu l'accès en raison d'une fonction de sécurité qui désactive les informations d'identification si n'utilisez pas le panneau de commande interne pendant une longue période).
Et nous n'avons pas pu accéder à nos services internes, comme Jira ou le système de build. Nous avions besoin d'une solution de contournement, que nous utilisions rarement (cela devrait également être élaboré). Enfin, un ingénieur a pu couper le WAF à 14h07 et à 14h09, le niveau de trafic et le processeur partout sont revenus à la normale. Le reste des mécanismes de défense de Cloudflare a fonctionné comme prévu.
Ensuite, nous avons commencé à restaurer WAF. La situation sortait de l'ordinaire, nous avons donc effectué des tests négatifs (en nous demandant si le problème était vraiment ce changement) et positifs (en veillant à ce que le retour en arrière fonctionne) dans une ville en utilisant un trafic séparé, en transférant des clients payés à partir de là.
À 14 h 52, nous étions convaincus que nous avions compris la raison et apporté une correction, puis allumé à nouveau le WAF.
Comment fonctionne Cloudflare
Cloudflare dispose d'une équipe d'ingénieurs qui gère les règles gérées pour WAF. Ils essaient d'augmenter le taux de détection, de réduire le nombre de faux positifs et de répondre rapidement aux nouvelles menaces à mesure qu'elles surviennent. Au cours des 60 derniers jours, 476 demandes de modification des règles gérées WAF ont été traitées (en moyenne, une toutes les 3 heures).
Ce changement particulier devait être déployé en mode simulation, où le trafic client réel passe par la règle, mais rien n'est bloqué. Nous utilisons ce mode pour vérifier l'efficacité des règles et mesurer la proportion de faux positifs et de faux négatifs. Mais même en mode simulation, les règles doivent effectivement être exécutées, et dans ce cas, la règle contenait une expression régulière qui consommait trop de ressources processeur.
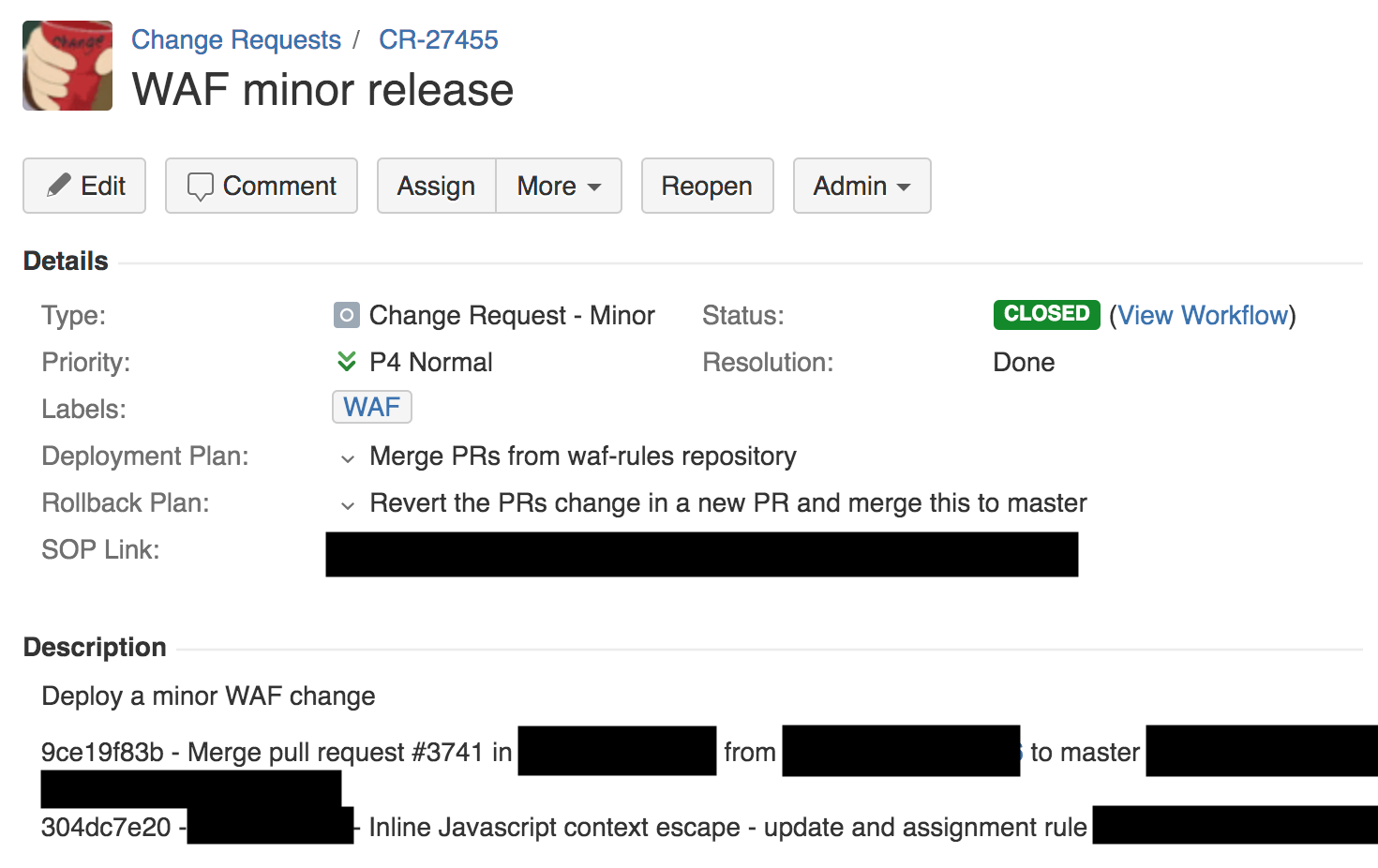
Comme vous pouvez le voir dans la demande de changement ci-dessus, nous avons un plan de déploiement, un plan de restauration et un lien vers la procédure d'exploitation standard interne (SOP) pour ce type de déploiement. SOP pour changer la règle vous permet de la publier globalement. En fait, dans Cloudflare, tout est organisé complètement différemment, et SOP exige d'abord d'envoyer le logiciel pour les tests et l'utilisation interne à un point de présence interne (PoP) (que nos employés utilisent), puis à un petit nombre de clients dans un endroit isolé, puis à un grand nombre de clients, et seulement ensuite au monde entier.
Voici à quoi ça ressemble. Nous utilisons git dans le système interne via BitBucket. Les ingénieurs du changement envoient le code qu'ils créent à TeamCity, et lorsque la construction réussit, des réviseurs sont affectés. Lorsque la demande de pool est approuvée, le code est collecté et une série de tests est effectuée (à nouveau).
Si l'assemblage et les tests réussissent, une demande de modification est créée dans Jira et la modification doit être approuvée par le superviseur ou le spécialiste principal approprié. Après approbation, il est déployé dans la soi-disant «ménagerie PoP»: DOG, PIG et Canary (chien, oreillons et canari).
DOG PoP est Cloudflare PoP (comme n'importe quelle autre de nos villes), qui est utilisé uniquement par les employés de Cloudflare. Le PoP à usage interne vous permet de détecter les problèmes avant même que la solution ne commence à recevoir du trafic client. Chose utile.
Si le test DOG réussit, le code passe au stade PIG (cobaye). Il s'agit de Cloudflare PoP, où une petite quantité de trafic client gratuit circule via le nouveau code.
Si tout va bien, le code va aux Canaries. Nous avons trois PoP Canaries dans différentes parties du monde. Le trafic des clients payants et gratuits passe par le nouveau code en eux, et c'est la dernière vérification d'erreur.

Processus de sortie du logiciel Cloudflare
Si le code est correct aux Canaries, nous le publions. Passer par toutes les étapes - CHIEN, PORC, Canaries, le monde entier - prend plusieurs heures ou jours, selon le changement de code. En raison de la diversité du réseau et des clients de Cloudflare, nous testons soigneusement le code avant une version mondiale pour tous les clients. Mais WAF ne suit pas spécifiquement ce processus car les menaces doivent être traitées rapidement.
Menaces WAF
Au cours des dernières années, il y a eu beaucoup plus de menaces dans les applications conventionnelles. Cela est dû à la plus grande disponibilité des outils de test logiciel. Par exemple, nous avons récemment écrit sur le fuzzing ).
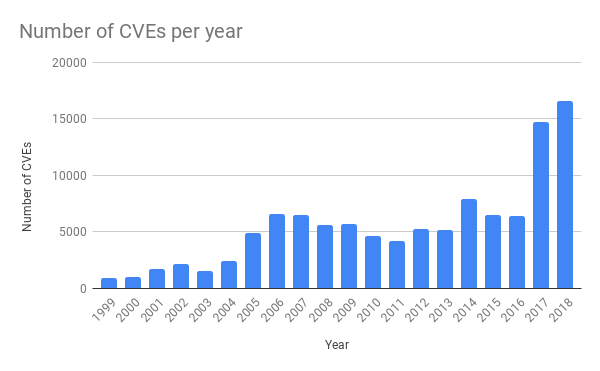
Source: https://cvedetails.com/
Très souvent, une confirmation du concept est créée et immédiatement publiée sur Github afin que les équipes au service de l'application puissent la tester rapidement et s'assurer qu'elle est bien protégée. Par conséquent, Cloudflare doit pouvoir répondre aux nouvelles attaques le plus rapidement possible afin que les clients aient la possibilité de réparer leur logiciel.
Un bon exemple de la réponse rapide de Cloudflare est le déploiement de la protection contre les vulnérabilités de SharePoint en mai ( lire ici ). Presque immédiatement après la publication des annonces, nous avons constaté un grand nombre de tentatives d'exploitation de la vulnérabilité dans les installations SharePoint de nos clients. Nos gars surveillent constamment les nouvelles menaces et écrivent des règles pour protéger nos clients.
La règle qui a provoqué le problème jeudi était de se protéger contre les scripts intersites (XSS). Il y a également eu beaucoup plus d'attaques de ce type ces dernières années.
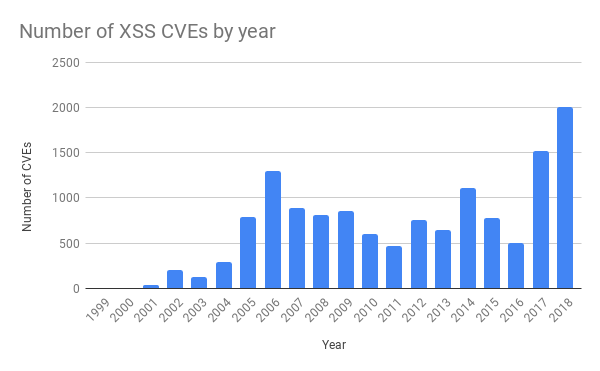
Source: https://cvedetails.com/
La procédure standard de modification d'une règle gérée pour WAF nécessite des tests d'intégration continue (CI) avant le déploiement global. Jeudi dernier, nous l'avons fait et avons élargi les règles. À 13 h 31, un ingénieur a envoyé une demande de pool approuvée avec une modification.
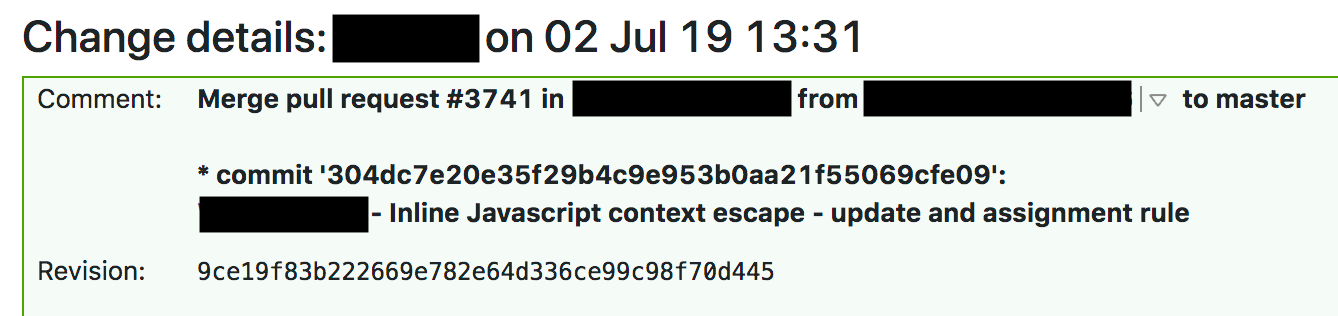
À 13:37, TeamCity a rassemblé les règles, a effectué les tests et a donné le feu vert. La suite de tests WAF teste la fonctionnalité de base WAF et se compose d'un grand nombre de tests unitaires pour des fonctions individuelles. Après des tests unitaires, nous avons vérifié les règles pour WAF avec un grand nombre de requêtes HTTP. Les requêtes HTTP vérifient quelles requêtes doivent être bloquées par WAF (afin d'intercepter l'attaque) et lesquelles peuvent être ignorées (afin de ne pas tout bloquer et d'éviter les faux positifs). Mais nous n'avons pas effectué de tests pour une utilisation excessive des ressources du processeur, et l'étude des journaux des assemblys WAF précédents montre que le temps d'exécution des tests avec la règle n'a pas augmenté, et il était difficile de soupçonner qu'il n'y avait pas suffisamment de ressources.
Les tests ont été réussis et TeamCity a commencé à déployer automatiquement le changement à 13h42.
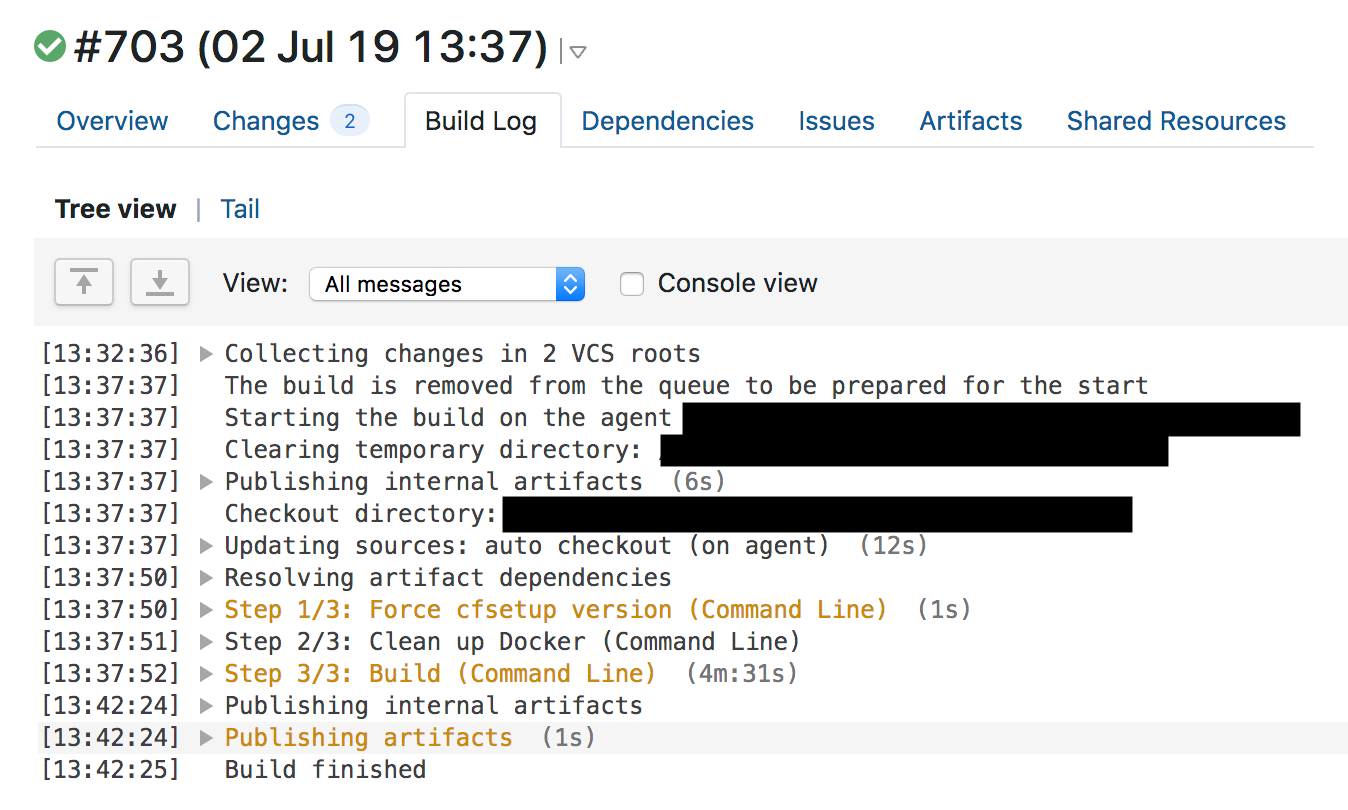
Quicksilver
Les règles WAF traitent de l'élimination urgente des menaces, nous les déployons donc à l'aide des paires clé-valeur distribuées Quicksilver, qui distribuent les modifications à l'échelle mondiale en quelques secondes. Tous nos clients utilisent cette technologie lorsqu'ils modifient la configuration sur le tableau de bord ou via l'API, et c'est grâce à elle que nous répondons aux changements avec une vitesse fulgurante.
Nous avons parlé un peu de Quicksilver. Nous avions l'habitude d'utiliser Kyoto Tycoon comme référentiel mondialement réparti de paires clé-valeur, mais il y avait des problèmes opérationnels et nous avons écrit notre référentiel répliqué dans plus de 180 villes. Désormais, avec Quicksilver, nous envoyons les modifications de configuration client, mettons à jour les règles WAF et distribuons le code JavaScript écrit par les clients dans Cloudflare Workers.
Il suffit de quelques secondes à une configuration pour faire le tour du monde, de la pression d'un bouton sur un tableau de bord ou de l'appel d'une API à la modification de la configuration. Les clients adorent ce réglage de vitesse. Et Workers leur offre un déploiement logiciel mondial presque instantané. En moyenne, Quicksilver distribue environ 350 changements par seconde.
Et Quicksilver est très rapide. En moyenne, nous avons atteint le 99e centile de 2,29 pour propager les modifications sur tous les ordinateurs du monde. La vitesse est généralement bonne. Après tout, lorsque vous activez une fonction ou videz le cache, cela se produit presque instantanément et partout. L'envoi de code via Cloudflare Workers s'effectue à la même vitesse. Cloudflare promet à ses clients des mises à jour rapides au bon moment.
Mais dans ce cas, la vitesse nous a joué un tour et les règles ont changé partout en quelques secondes. Vous avez probablement remarqué que le code WAF utilise Lua. Cloudflare utilise largement Lua dans l'environnement de production et nous avons déjà discuté des détails de Lua dans WAF . Lua WAF utilise PCRE en interne et applique un suivi arrière pour la correspondance. Il n'a aucun mécanisme de défense contre les expressions qui sont hors de contrôle. Ci-dessous, je vais en parler davantage et ce que nous en faisons.

Avant le déploiement des règles, tout s'est bien passé: la demande de pool a été créée et approuvée, le pipeline CI / CD a compilé et testé le code, la demande de modification a été envoyée conformément au SOP, qui régit le déploiement et la restauration, et le déploiement a été achevé.

Processus de déploiement CloudFare WAF
Qu'est-ce qui a mal tourné
Comme je l'ai déjà dit, nous déployons des dizaines de nouvelles règles WAF chaque semaine, et nous avons de nombreux systèmes de protection contre les conséquences négatives d'un tel déploiement. Et quand quelque chose se passe mal, c'est généralement une combinaison de plusieurs circonstances. Si vous ne trouvez qu'une seule raison, cela est bien sûr apaisant, mais pas toujours vrai. Voici les raisons qui, ensemble, ont conduit à l'échec de notre service HTTP / HTTPS.
- L'ingénieur a écrit une expression régulière qui pourrait entraîner un retour en arrière excessif.
- Un outil qui pouvait empêcher une utilisation excessive des ressources processeur utilisées par l'expression régulière a été supprimé par erreur lors du refactoring WAF quelques semaines auparavant - un refactoring était nécessaire pour que le WAF consomme moins de ressources.
- Le moteur regex n'avait aucune garantie de complexité.
- La suite de tests n'a pas pu révéler une consommation excessive de CPU.
- La procédure SOP permet le déploiement global de modifications de règles non urgentes sans processus en plusieurs étapes.
- Le plan de restauration a nécessité un assemblage WAF complet à deux reprises, ce qui a pris beaucoup de temps.
- La première alerte mondiale d'alerte de trafic a fonctionné trop tard.
- Nous avons retardé la mise à jour de la page d'état.
- Nous avons eu des problèmes d'accès aux systèmes en raison d'un crash, et la solution de contournement n'a pas été suffisamment bien résolue.
- Les ingénieurs SRE ont perdu l'accès à certains systèmes car leurs informations d'identification ont expiré pour des raisons de sécurité.
- Nos clients n'avaient pas accès au tableau de bord ou à l'API Cloudflare car ils traversent la région Cloudflare.
Ce qui a changé depuis jeudi dernier
Tout d'abord, nous avons complètement arrêté tout travail sur les versions de WAF et procédez comme suit:
- Réintroduction de la protection contre les ressources processeur excessives que nous avons supprimées. (Terminé)
- Vérifiez manuellement toutes les règles 3868 dans les règles gérées pour que WAF trouve et corrige d'autres cas potentiels de retour en arrière excessif. (Vérification terminée)
- Nous incluons le profilage des performances pour toutes les règles dans la suite de tests. (Prévu: 19 juillet)
- Nous passons au moteur re2 ou Rust regex - les deux offrent des garanties pendant l'exécution. (Prévu: 31 juillet)
- Nous réécrivons SOP afin de déployer les règles par étapes, comme les autres logiciels de Cloudflare, mais en même temps, nous avons la possibilité de déployer un déploiement global d'urgence si les attaques ont déjà commencé.
- Nous développons la possibilité d'un retrait urgent du tableau de bord et de l'API Cloudflare de la région Cloudflare.
- Nous automatisons la mise à jour de la page d' état de Cloudflare .
À long terme, nous abandonnons Lua WAF, que j'ai écrit il y a plusieurs années. Nous migrons WAF vers le nouveau système de pare-feu . Le WAF sera donc plus rapide et bénéficiera d'un niveau de protection supplémentaire.
Conclusion
Cet échec a causé des problèmes à nous et à nos clients. Nous avons rapidement réagi pour corriger la situation, et maintenant nous travaillons sur les failles dans les processus qui ont causé l'échec, et nous creusons encore plus pour nous protéger des problèmes potentiels avec les expressions régulières à l'avenir en passant à une nouvelle technologie.
Nous avons très honte de cet échec et nous nous excusons auprès de nos clients. Nous espérons que ces changements feront en sorte que cela ne se reproduise plus.
Application. Retour arrière d'expression régulière
Pour comprendre comment l'expression:
(?:(?:\"|'|\]|\}|\\|\d (?:nan|infinity|true|false|null|undefined|symbol|math)|\`|\- |\+)+[)]*;?((?:\s|-|~|!|{}|\|\||\+)*.*(?:.*=.*)))
mangé toutes les ressources du processeur, vous devez savoir un peu comment fonctionne le moteur regex standard. Le problème ici est le modèle .*(?:.*=.*) . (?: et celui correspondant ) n'est pas un groupe passionnant (c'est-à-dire que l'expression entre parenthèses est regroupée en une seule expression).
Dans le contexte d'une consommation excessive de ressources processeur, ce modèle peut être désigné par .*.*=.* . En tant que tel, le motif semble inutilement complexe. Mais plus important encore, dans le monde réel, de telles expressions (similaires à des expressions complexes dans les règles WAF) qui demandent au moteur de faire correspondre un fragment suivi d'un autre fragment peuvent entraîner un retour en arrière catastrophique. Et voici pourquoi.
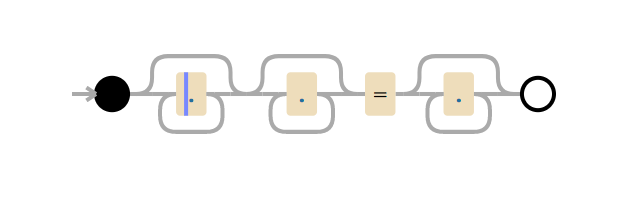
En expression régulière . signifie que vous devez faire correspondre un caractère,. .* - faire correspondre zéro ou plusieurs caractères "avec avidité", c'est-à-dire capturer un maximum de caractères, donc .*.*=.* signifie faire correspondre zéro ou plusieurs caractères, puis faire correspondre zéro ou plusieurs caractères, trouver caractère littéral =, correspond à zéro ou plusieurs caractères.
Prenez la ligne de test x=x . Il correspond à l'expression .*.*=.*. .*.* .*.*=.*. .*.* jusqu'au signe égal correspond au premier x (l'un des groupes .* correspond à x et le second à zéro). .* after = correspond au dernier x .
Pour une telle comparaison, 23 étapes sont nécessaires. Le premier groupe .* .*.*=.* Agit "avec avidité" et correspond à la ligne entière x=x . Le moteur passe au groupe suivant .* . Nous n'avons plus de caractères à faire correspondre, donc le deuxième groupe .* Correspond à zéro caractère (cela est autorisé). Ensuite, le moteur passe au signe = . Il n'y a plus de caractères (le premier groupe .* Utilisé l'expression entière x=x ), aucune correspondance ne se produit.
Et ici, le moteur d'expression régulière revient au début. Il va dans le premier groupe .* Et le compare x= (au lieu de x=x ), puis prend le deuxième groupe .* . Le deuxième groupe .* Mappe vers le deuxième x , et encore une fois, nous n'avons plus de caractères. Et lorsque le moteur atteint = v .*.*=.* Encore une fois, rien ne se passe. Et il revient en arrière.
Cette fois, le groupe .* Correspond toujours à x= , mais au deuxième groupe .* plus x , mais zéro caractère. Le moteur essaie de trouver le symbole littéral = dans le motif .*.*=.* , Mais ne sort pas (après tout, le premier groupe l'a déjà occupé .* ). Et il revient en arrière.
Cette fois, le premier groupe .* Ne prend que le premier x. Mais le deuxième groupe .* "Greedily" capture =x . Déjà deviné ce qui va se passer? Le moteur essaie de faire correspondre littéral = , échoue et effectue le retour en arrière suivant.
.* x . .* = . , = , .* . . !
.* x , .* — , = = . .* x .
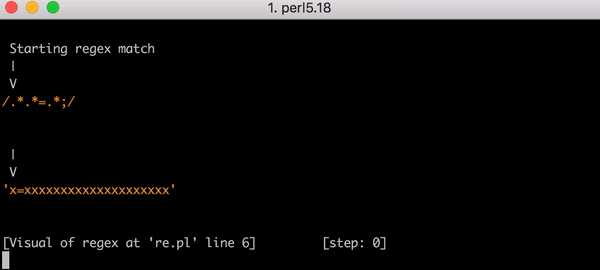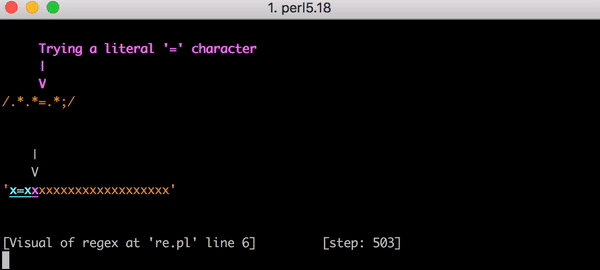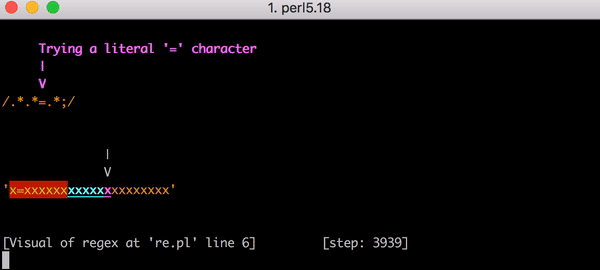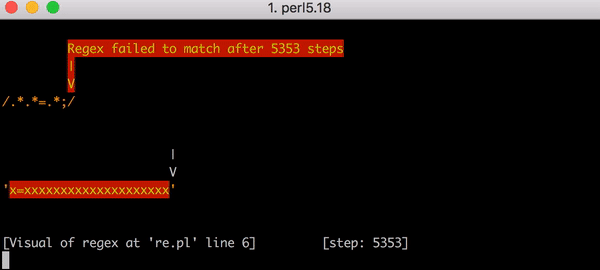
23 x=x . Perl Regexp::Debugger , , .
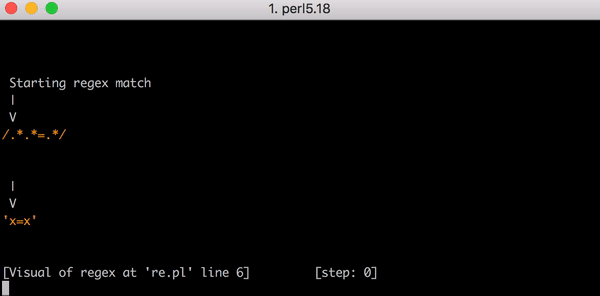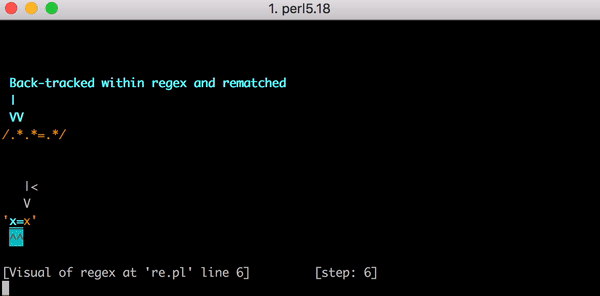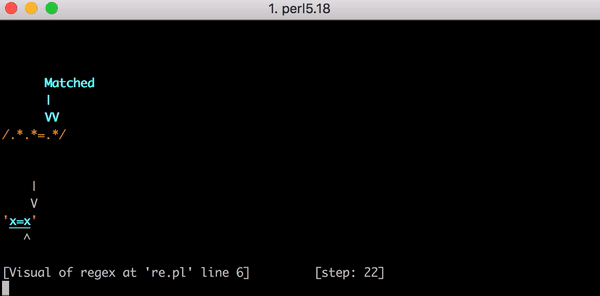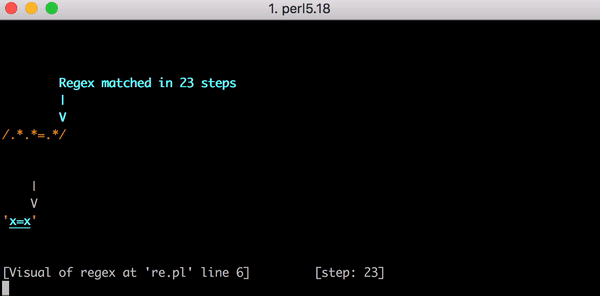
, x=x x=xx ? 33 . x=xxx ? 45. . x=x x=xxxxxxxxxxxxxxxxxxxx (20 x = ). 20 x = , 555 ! ( , x= 20 x , 4067 , , ).
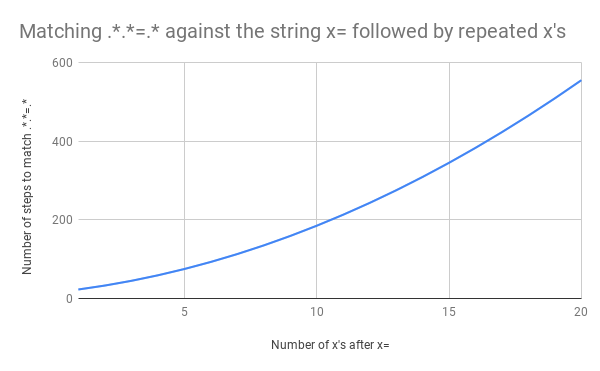
x=xxxxxxxxxxxxxxxxxxxx :
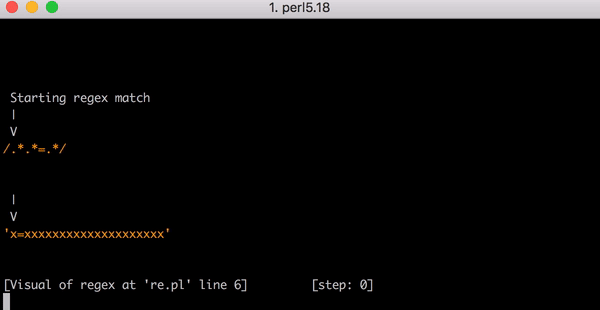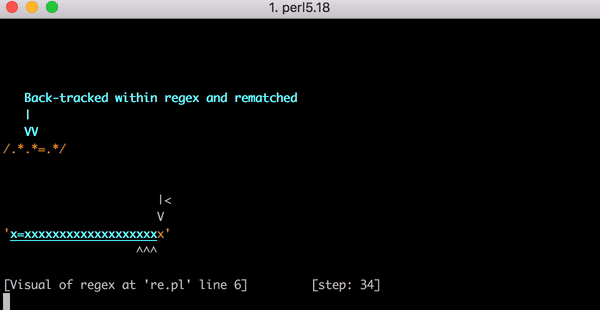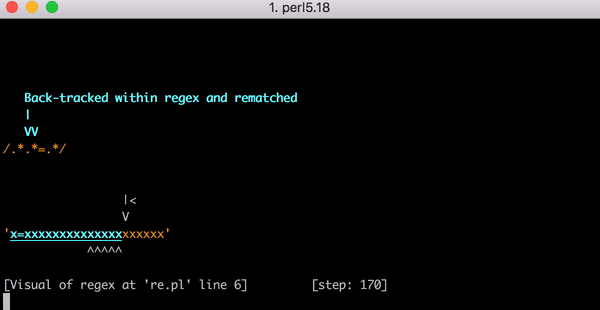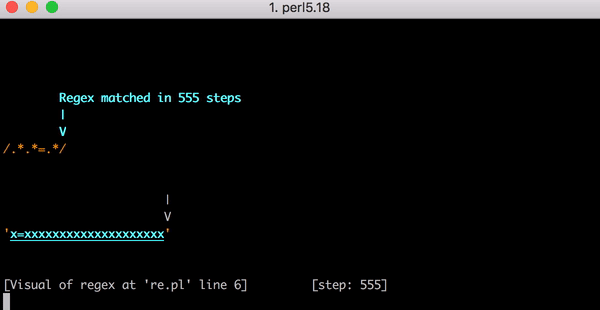
, . , . , .*.*=.* ; ( ). , , foo=bar; .
. x=x 90 , 23. . x= 20 x , 5353 . . Y .
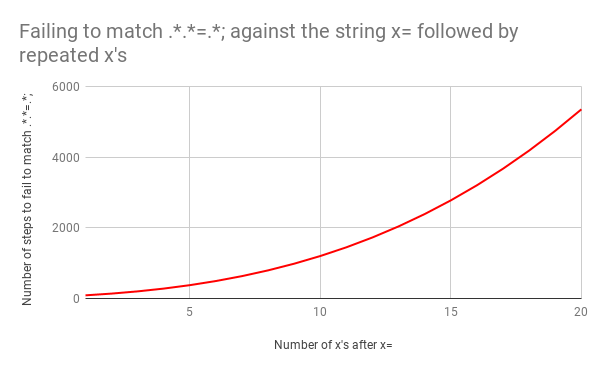
, 5353 x=xxxxxxxxxxxxxxxxxxxx .*.*=.*;
«», «» , . .*?.*?=.*? , x=x 11 ( 23). x=xxxxxxxxxxxxxxxxxxxx . , ? .* , .
«» . .*.*=.*; .*?.*?=.*?; , . x=x 555 , x= 20 x — 5353.
, ( ) — . .
1968 , Programming Techniques: Regular expression search algorithm (« : »). , , , .

(Ken Thompson)
Bell Telephone Laboratories, Inc., -, -
. IBM 7094 . , . , .
, .
. . — .
. , . , .
, IBM 7094.
. — , . «·» . . . 2 , .
, ALGOL-60, IBM 7094. , .
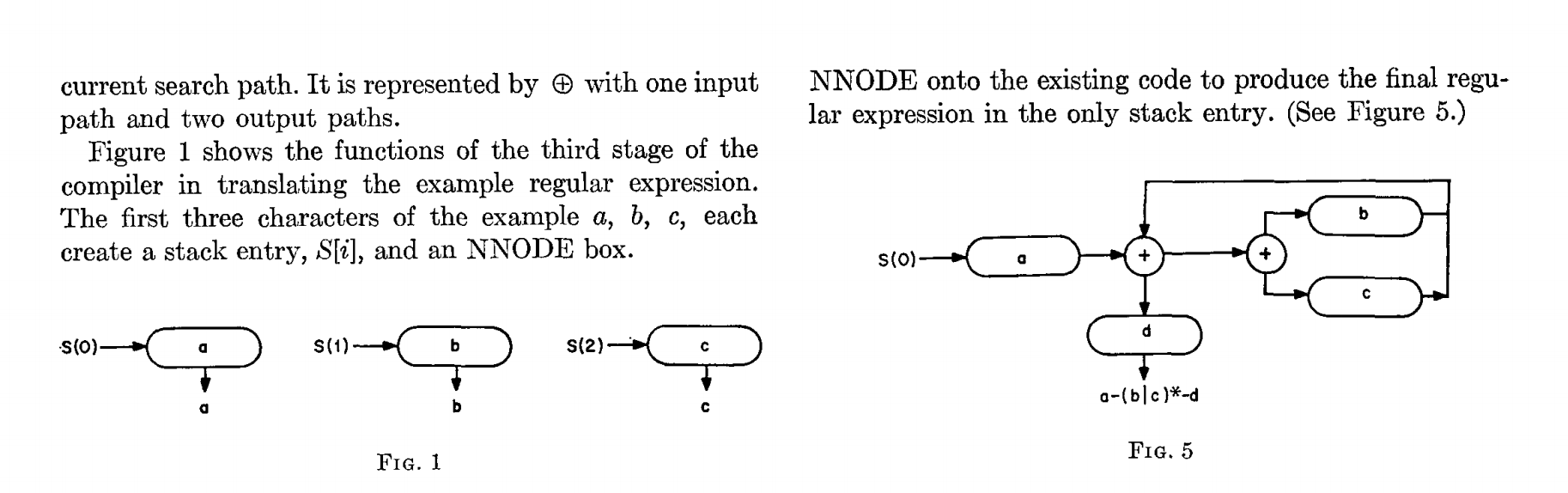
. ⊕ .
1 . — a, b, c, S[i] NNODE.
NNODE , (. . 5)
.*.*=.* , , .
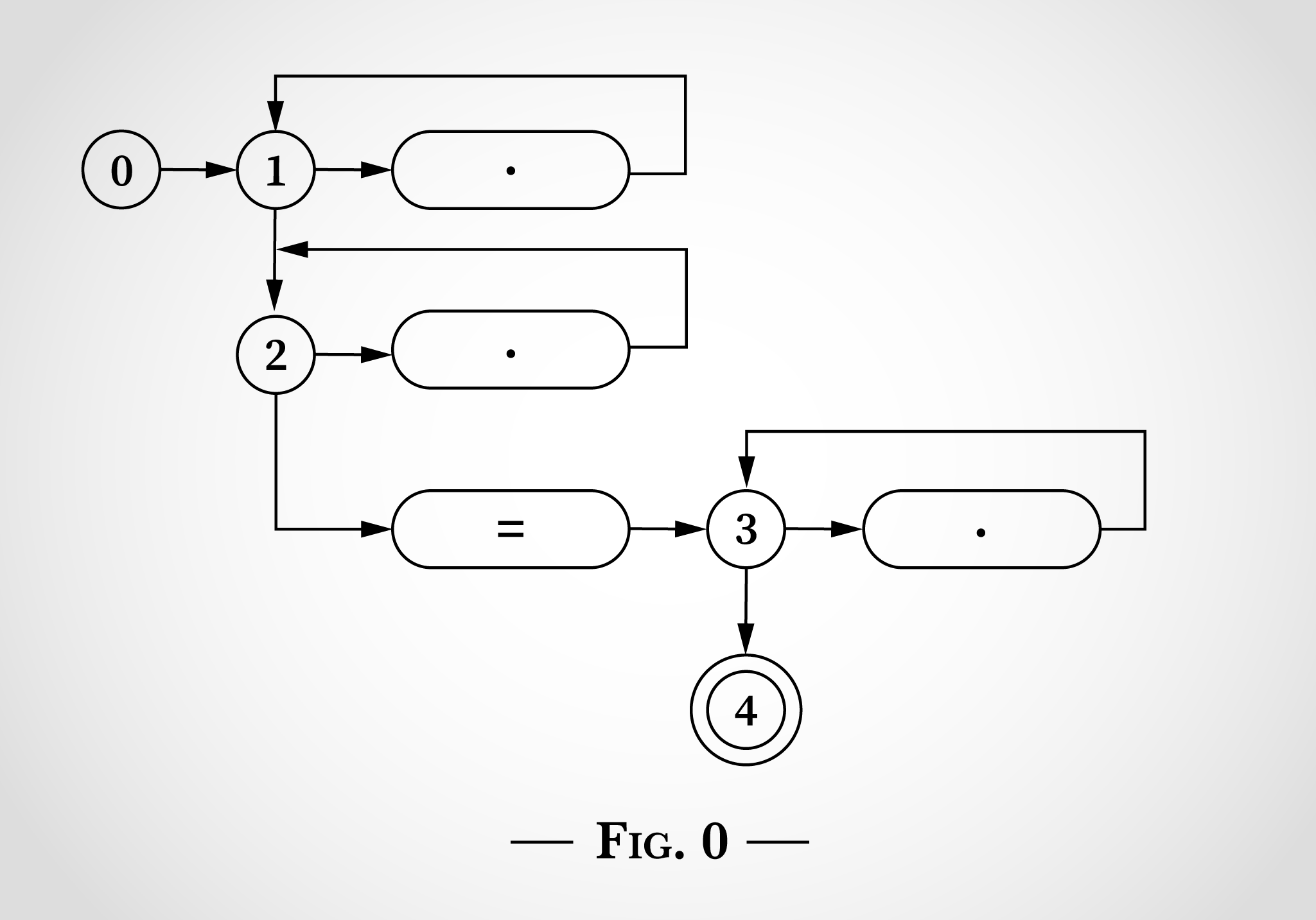
Dans la fig. 0 , 0, 3 , 1, 2 3. .* . 3 . = = . 4 . , .
, .*.*=.* , x=x . 0, . 1.
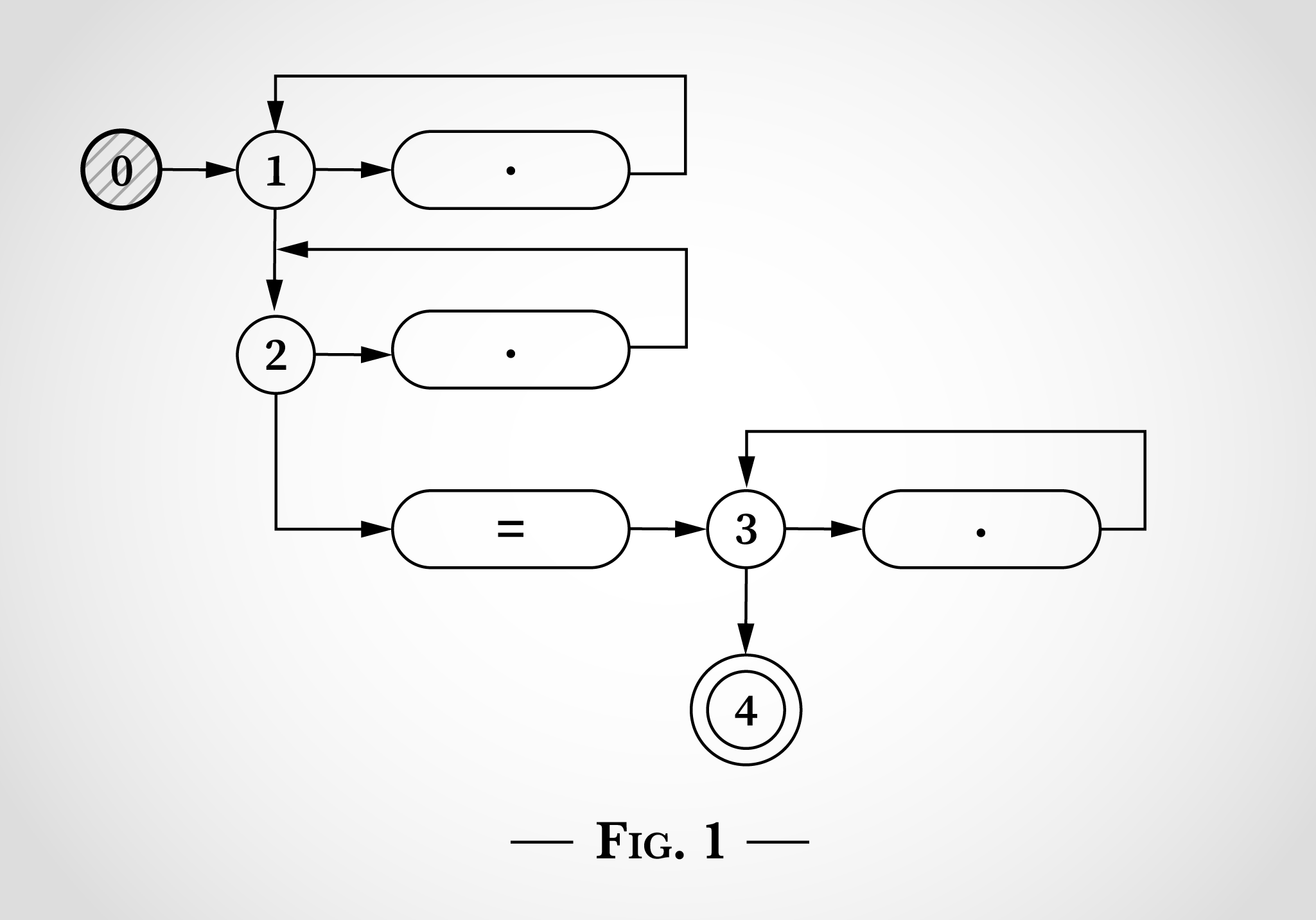
, . .
, (1 2), . 2.
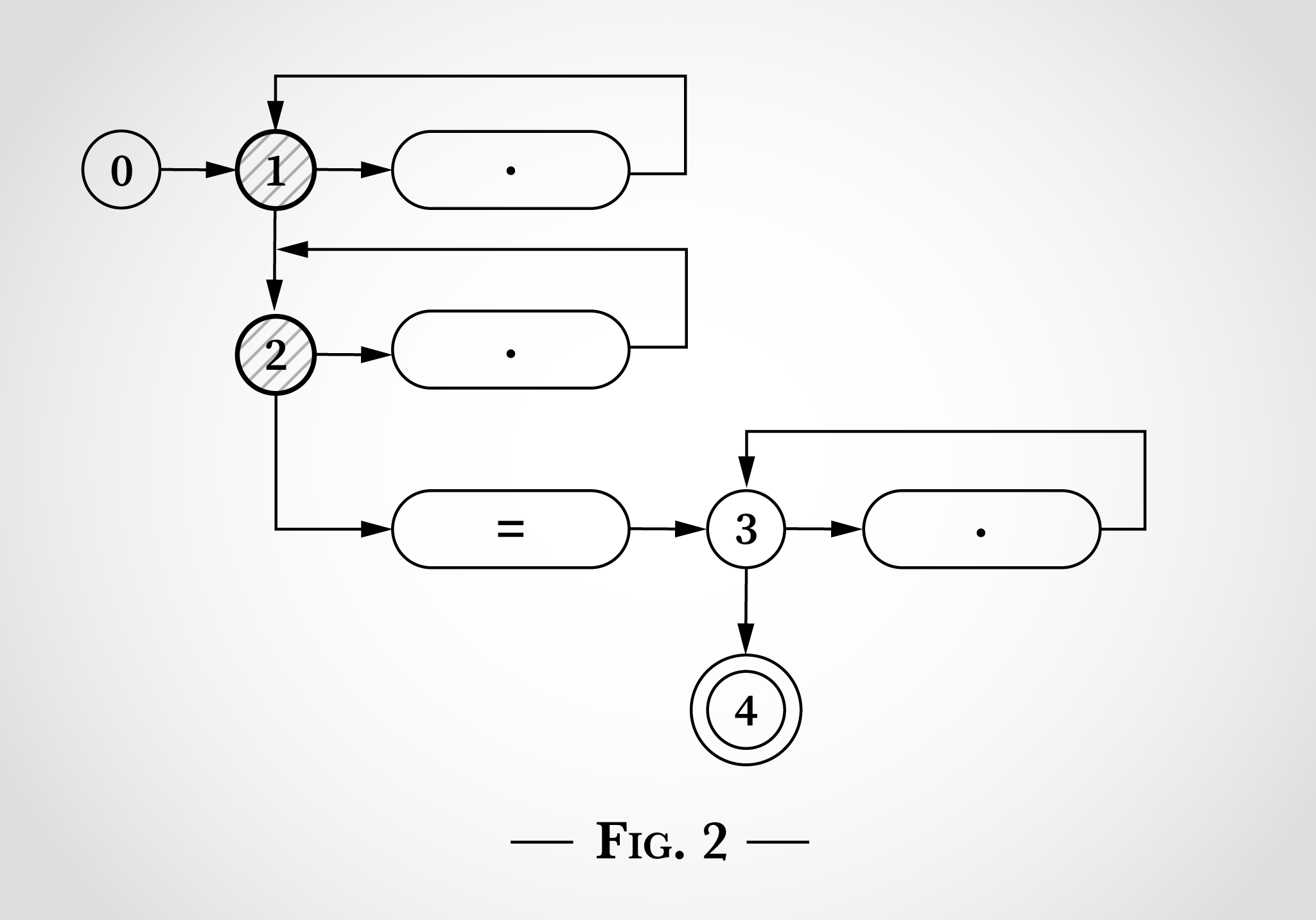
Dans la fig. 2 , , x x=x . x , 1 1. x , 2 2.
x x=x - 1 2. 3 4, = .
= x=x . x , 1 1 2 2, = 2 3 ( 4). . 3.
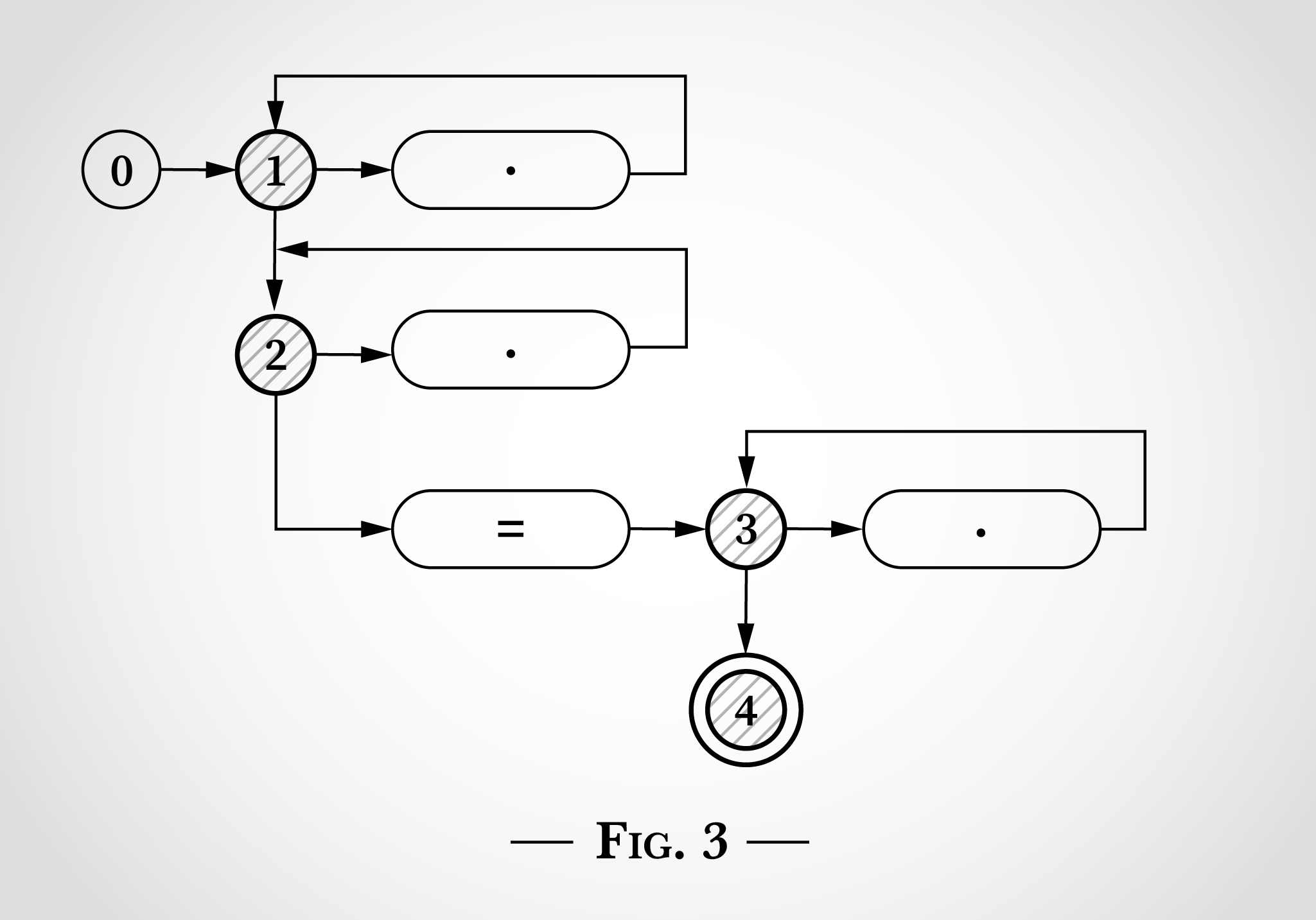
x x=x . 1 2 1 2. 3 x 3.
x=x , 4, . , . .
, 4 ( x= ) , , x .
.