
La solution du problème de la reconnaissance d'image (OCR) se heurte à diverses difficultés. Cette image ne peut pas être reconnue en raison de la palette de couleurs non standard ou en raison de la distorsion. Que le client souhaite reconnaître toutes les images sans aucune restriction, et c'est loin d'être toujours possible. Les problèmes sont différents et il n'est pas toujours possible de les résoudre immédiatement. Dans cet article, nous donnerons quelques conseils utiles basés sur l'expérience de résolution de situations réelles avec des clients.
Mais d'abord, un peu d'histoire. Beaucoup de temps s'est écoulé depuis la publication de l'article sur la
façon dont nous avons réécrit le service de filtrage . Dans ce document, nous avons parlé un peu du filtrage et du traitement des messages, de la façon dont notre service de filtrage dans son ensemble est organisé. Cette fois, nous allons essayer de répondre à la question «Comment traitons-nous les images, comment les services interagissent-ils et qu'arrive-t-il au système sous charge?» Si nous opérons sur un article sur un service de filtrage, alors maintenant nous ne considérerons qu'une seule branche d'interaction de service - c'est l'interaction d'un service de filtrage et de l'OCR.
Qu'est-ce qu'un OCR?
Avant de parler de l'interaction des services et des problèmes d'utilisation de l'OCR, essayons de comprendre ce qu'est l'OCR. Prenez la définition
compliquée de Wikipedia.
Reconnaissance
optique de caractères (OCR) - la traduction mécanique ou électronique d'images textuelles manuscrites, dactylographiées ou dactylographiées en données textuelles utilisées pour représenter des caractères dans un ordinateur (par exemple, dans un éditeur de texte).
Autrement dit, ils ont pris une photo, l'ont envoyée pour reconnaissance, puis la
magie était à l'extérieur de Poudlard et a reçu le texte.

Vous pouvez également prendre la définition OCR sur le site Web d'ABBYY, qui semble plus simple.
La reconnaissance optique de caractères (OCR) est une technologie qui vous permet de convertir divers types de documents, tels que des documents numérisés, des fichiers PDF ou des photos à partir d'un appareil photo numérique, en formats modifiables interrogeables.
Et pourquoi avons-nous besoin de (reconnaissance d'image)?
Nous pouvons utiliser la reconnaissance d'image même sur un ordinateur personnel pour convertir des images numériques en données texte modifiables. Mais la tâche qui nous attend est beaucoup plus large (un système DLP après tout): nous devons contrôler le flux d'informations dans l'organisation.
Les systèmes DLP sont apparus depuis longtemps sur le marché et font maintenant partie de l'arsenal familier des systèmes de sécurité de l'information d'entreprise (outils de protection de l'information). DLP est confronté à la tâche de contrôler le mouvement des informations graphiques (documents numérisés, captures d'écran, photos). Et pas seulement contrôler le mouvement des fichiers graphiques, mais tout d'abord l'analyse de leur contenu. Le système doit être en mesure de comprendre exactement les informations qu'il a rencontrées, de les comparer avec des échantillons d'informations protégées et de fournir à l'utilisateur des possibilités de recherche supplémentaire de ces informations. L'utilisation d'autres outils d'analyse, tels que la comparaison avec les empreintes digitales numériques, le calcul du hachage, l'analyse par format de fichier, la taille et la structure, sont également de précieuses sources d'information, mais ils ne permettent pas de répondre à la question: «quel texte est transmis dans cette image?» Pendant ce temps, le texte reste le support le plus courant d'informations structurées, y compris dans les fichiers graphiques.
Traditionnellement, la technologie OCR est utilisée pour reconnaître les informations graphiques (ce que nous avons déjà déterminé). En fait, l'OCR est généralement la seule classe de technologies qui permet d'extraire des informations textuelles d'images. Par conséquent, il ne s'agit pas tant de l'approche traditionnelle, mais plutôt du manque de choix.
Combien d'images sont traitées par système DLP?
Vous ne pouvez pas vous passer de l'OCR? Y a-t-il vraiment tellement d'images dans DLP que vous devez appliquer l'OCR? La réponse à cette question est «Oui!». Plus d'un million d'images peuvent entrer dans le système par jour, et toutes ces images peuvent contenir du texte.
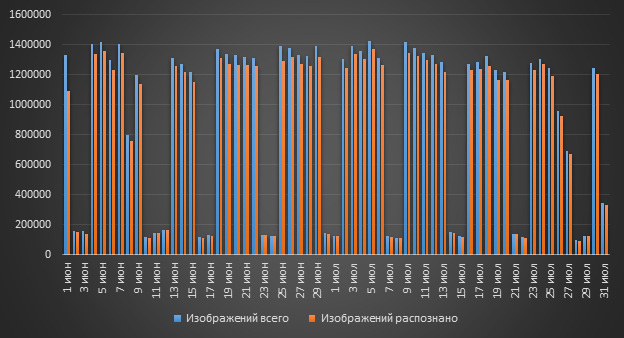
L'OCR dans le cadre du système Rostelecom-Solar DLP est utilisé par les sociétés pétrolières et gazières et les agences gouvernementales. Tous les clients utilisent l'OCR pour détecter les données sensibles dans les documents numérisés. Que peut contenir un tel «calendrier»? Oui, n'importe quoi. Il peut s'agir de numérisations de divers documents internes, par exemple, contenant PD. Ou des informations de la catégorie des secrets commerciaux, des panneaux de particules (à usage officiel), des états financiers, etc.
Comment l'OCR reconnaît-il les images?
Le processus est le suivant: DLP intercepte un message contenant une image (numérisation de document, photo, etc.), détermine que l'image se trouve réellement dans le message, l'extrait et l'envoie à l'OCR pour reconnaissance. En sortie, le DLP reçoit des informations sur le contenu de l'image (et le message dans son ensemble) sous la forme du TEXTE / PLAIN extrait.
Si nous parlons de l'interaction des services directement dans notre système Solar Dozor, le service de filtrage envoie les images (le cas échéant) du message au service d'extraction de texte d'image (OCR). Ce dernier, une fois la reconnaissance terminée, envoie le texte reçu à mailfilter. Cela ressemble à jongler avec des images et du texte.

Examinons plus en profondeur le mécanisme de reconnaissance par l'exemple des technologies OCR ABBYY, que nous utilisons dans notre propre DLP.
Le problème principal de l'OCR lors de la reconnaissance de texte est peut-être l'orthographe d'un caractère. Si nous prenons n'importe quelle lettre de l'alphabet (par exemple, russe ou anglais), alors pour chacune, nous trouverons plusieurs options d'orthographe. Les moteurs OCR résolvent ce problème de plusieurs manières:
- Trouver un personnage par motif. Par exemple, utiliser une variété de polices d'orthographe.
- Identification des signes d'écriture d'un personnage.
Si vous donnez un exemple de travail assez grossier, l'OCR divise le texte en caractères qu'il a précédemment identifié dans l'image et les impose sur des modèles prêts à l'emploi. Ensuite, il est vérifié si le symbole ressemble à une orthographe de modèle ou non. Lorsqu'un caractère est identifié, il est converti en code de caractère dans le codage utilisé. À la suite de ce processus, des symboles sont ajoutés dans des mots, des phrases dans le texte final.
Il existe de nombreux articles différents sur le travail de l'OCR. Vous pouvez en savoir plus sur le travail de l'OCR, par exemple, ici
https://sysblok.ru/knowhow/iz-pikselej-v-bukvy-kak-rabotaet-raspoznavanie-teksta/Comment préparer l'OCR dans son ensemble pour la reconnaissance?
Nous avons déjà découvert que plus d'un million d'images peuvent entrer dans DLP. Mais toutes les images de ce million nous sont-elles utiles?
La réponse à la question est plus qu'évidente - bien sûr que non. Mais pourquoi toutes les images ne nous seront-elles pas utiles? La réponse à cette question est également assez transparente: beaucoup de photos de signatures dans des messages «marchent» par la poste. Probablement 90% des messages (sinon plus) contiendront le logo de l'entreprise.
Ces images sont trop petites pour être reconnues; il se peut qu’elles ne contiennent aucun texte. Ici, nous pouvons conseiller (et même fortement recommander) de définir des restrictions sur la taille des images reconnues. Dans ce cas, les restrictions doivent être définies à la fois sur la limite inférieure et sur la limite supérieure. La probabilité d'envoyer des fichiers lourds pour le traitement est plus faible que pour les images d'une signature, mais reste assez élevée.Il convient de noter que les images numériques présentent souvent des défauts différents. Il est peu probable que DLP obtienne toujours des numérisations de documents en bonne résolution. Au contraire, les scans ne seront pas toujours de la meilleure qualité et avec beaucoup de défauts.
Par exemple, dans une photo numérique, la perspective peut être déformée, elle peut se révéler être mise en évidence ou inversée, et les lignes de balayage peuvent être courbes. Une telle distorsion peut compliquer la reconnaissance. Par conséquent, les moteurs OCR peuvent prétraiter les images pour les préparer à la reconnaissance. Par exemple, une image peut être tordue, convertie en noir et blanc, inverser les couleurs et corriger les asymétries de ligne.
Tout cela peut être défini dans les paramètres OCR et, par conséquent, ces outils peuvent aider à améliorer la reconnaissance de texte dans les images.En conséquence, nous sommes arrivés aux principes de base de la préparation de l'OCR pour la reconnaissance:
- Déterminez les tailles d'images que nous reconnaîtrons, à la fois en pixels et en Mo.
- Activez le prétraitement des images.
Pour augmenter l'efficacité de l'OCR, vous pouvez également mettre en cache les données reconnues afin de ne pas envoyer plusieurs fois les mêmes images pour la reconnaissance.
À quoi d'autre devez-vous faire attention lors de la préparation de l'OCR, nous décrirons ci-dessous des exemples d'utilisation de cette technologie dans la pratique du combat.
Quels défis sont possibles lors de l'utilisation de l'OCR dans DLP sous une charge élevée?
1. Limites trop larges sur la taille des images reconnuesCommençons par ce que nous avons déjà mentionné - avec des limites.
Sur la base de notre pratique, les clients définissent souvent des limites trop larges sur la taille des fichiers d'image reconnus. Oui, pour que l'OCR fonctionne correctement, vous devez limiter la taille des images. Mais les clients s'efforcent de tout contrôler, estimant que même dans une image de 100 x 100 pixels et de 5 Ko, des données précieuses peuvent fuir. En général, bien sûr, 100x100 pixels et 5 Ko sont également des limitations, mais ces seuils sont trop bas.
L'autre extrême est le désir de reconnaître des fichiers lourds de plusieurs centaines de Mo. Il est clair que de telles images ne seront pas analysées par courrier électronique en raison de restrictions sur la taille des messages envoyés. Mais ici, sur d'autres canaux d'interception (par exemple, à partir de la balle du réseau d'entreprise), les fichiers lourds cherchent constamment à reconnaître. Si le client souhaite ajouter à cela une grande quantité d'images haute résolution, vous devez pour cela disposer des capacités de serveur appropriées. Par conséquent, avec des seuils minimum et maximum aussi larges pour la taille des fichiers reconnus, une charge de processeur élevée est créée sur les serveurs, ce qui ralentit le fonctionnement de tous les sous-systèmes.
Que peut-on recommander ici? Tout d'abord, analysez quel «calendrier» utilisé par l'entreprise contient des données confidentielles, puis estimez les restrictions minimales et maximales raisonnables sur la taille des images surveillées. Nous recommandons généralement aux clients de fixer la limite inférieure de résolution d'image à partir de 200 pixels, idéalement à partir de 400 pixels (le long des axes X et Y), et des tailles de fichier d'au moins 20 Ko, mieux plus grandes. Il est également inutile d'envoyer des images lourdes à l'OCR - elles surchargeront simplement vos serveurs et non le fait qu'elles seront reconnues.2. Filtrage des files d'attente et des délais de traitement des demandesUne charge excessive sur les serveurs, résultant des raisons ci-dessus, conduit le long de la chaîne à augmenter le temps de reconnaissance d'image et de traitement des requêtes en général. En conséquence, la file d'attente de messages pour le filtrage commence à augmenter dans le système DLP. De plus, des fichiers graphiques qui ne peuvent pas être reconnus en principe (fichiers lourds, mauvaise qualité, etc.) peuvent arriver dans le module OCR, entraînant des délais d'attente de traitement d'image. S'il y a beaucoup de fichiers non reconnus et que le système a des délais d'expiration de reconnaissance élevés, le service de filtrage attend jusqu'à ce que ce délai se produise et procède ensuite uniquement au traitement de la demande suivante. L'ensemble du processus de traitement peut être sérieusement inhibé.
Que pouvons-nous conseiller? S'il y a une file d'attente pour le traitement des images graphiques, vous devez regarder les paramètres OCR dans le système DLP et essayer de trouver la cause du freinage. Cela peut se produire, par exemple, en raison de problèmes de communication interprocessus sur le serveur lui-même. En général, ces problèmes méritent une discussion séparée. Quelques détails sur les problèmes généraux peuvent être trouvés dans l'article «Présentation de la communication interprocessus sous Linux» .De plus, un point important lors de la configuration de l'OCR est de définir des délais d'attente adéquats pour la reconnaissance d'image. En général, 90 secondes suffisent pour que l'image soit reconnue avec précision. Si aucun texte n'a été extrait de l'image en 90 secondes, on peut supposer que l'OCR ne reconnaît pas l'image en principe. À ce stade, des problèmes de configuration OCR peuvent également se produire lorsqu'ils définissent des délais d'attente de reconnaissance élevés et tentent ainsi de reconnaître les éléments non reconnus.Quoi d'autre pourrait provoquer un délai d'attente? Nous revenons ici à la question de la configuration du système. Le service de filtrage, comme le service OCR, fonctionne avec des threads qui traitent les messages et les images. Le système peut ne pas être configuré correctement en termes de nombre de gestionnaires de service de filtrage et de nombre de gestionnaires OCR. Par exemple, un service de filtrage aura de nombreux gestionnaires de threads, tandis que l'OCR n'en aura qu'un. Dans une telle situation, à certains moments, l'OCR peut tout simplement ne pas avoir le temps de traiter toutes les demandes de reconnaissance, et ainsi des délais d'attente de traitement d'image apparaîtront.
Ce comportement du système suggère des réflexions sur les problèmes de conception et les bogues dans l'architecture, mais en fait ce n'est pas le cas. L'architecture de notre DLP offre la flexibilité de configurer le système et de le personnaliser selon les besoins des clients. Par exemple, nous pouvons simplement configurer un OCR pour fonctionner avec deux services de filtrage sans sacrifier les performances.
3. Images non reconnuesSi une image que l'OCR ne peut pas reconnaître entre dans le système DLP pour analyse, il existe plusieurs solutions au problème.
Pour quelles raisons les images peuvent-elles ne pas être reconnues? Par exemple, par ce qui suit:
1. Jeu de couleurs non standard de l'image.
2. Image basse résolution.
3. Orientation incorrecte de l'image et du texte qu'elle contient dans l'espace.
4. Inclinaison des lignes et distorsion des proportions du texte dans l'image, etc.
Voici un exemple: l'un des clients au cours du processus de surveillance a découvert que l'OCR ne reconnaît pas les documents pdf exécutés dans un schéma de couleurs non standard. Autrement dit, l'image a été extraite du document PDF en mode normal, mais en ce qui concerne le traitement du module OCR, il n'a pas compris le schéma de couleurs de l'image et a produit le «carré Malevitch» à la sortie. Dans notre interface, l'image ressemblait à ceci:
 Les moteurs OCR ont diverses fonctions pour la correction automatique de l'image, ce qui augmente considérablement les chances de réussite de la reconnaissance du texte qu'il contient. Cependant, dans la pratique, ces outils magiques ne fonctionnent pas toujours. Dans ce cas particulier, nous avons personnalisé le module OCR pour le client afin qu'il reconnaisse ce schéma de couleurs non standard.
Les moteurs OCR ont diverses fonctions pour la correction automatique de l'image, ce qui augmente considérablement les chances de réussite de la reconnaissance du texte qu'il contient. Cependant, dans la pratique, ces outils magiques ne fonctionnent pas toujours. Dans ce cas particulier, nous avons personnalisé le module OCR pour le client afin qu'il reconnaisse ce schéma de couleurs non standard.5. Incohérence de l'un des paramètres du document avec les tailles spécifiées reconnues
des images.
Par exemple, dans la configuration du système, les limites de taille des images reconnues sont définies sur 200x1000 pixels et un fichier de 500x1500 pixels est reçu en OCR (limite supérieure dépassée).
Dans ce cas, vous devez corriger les paramètres OCR pour reconnaître ces images.Il s'agit peut-être de l'un des scénarios de reconfiguration de système les plus populaires après que l'on nous a dit que l'OCR ne fonctionne pas.
Pourquoi l'OCR n'est pas sur les agents?
L'OCR dans les systèmes DLP est implémenté en deux versions - sur les agents et sur les serveurs. Nous sommes en faveur de la deuxième approche, car la reconnaissance d'image directement sur le poste de travail crée une charge élevée sur son processeur et, par conséquent, ralentit le travail d'autres applications. L'OCR lui-même est une technologie très vorace, même pour les serveurs, et son application nécessite une bonne planification des capacités du processeur et une surveillance des performances.
Cependant, de nombreuses entreprises nationales, en particulier dans le secteur public, possèdent toujours une flotte de PC assez ancienne. Que se passe-t-il dans ce cas? Les utilisateurs commencent à se plaindre au service informatique du «freinage» du PC, et les informaticiens découvrent enfin que la cause du freinage est le module OCR du système DLP. Cela les ennuie, ainsi que les utilisateurs qui ne peuvent pas résoudre rapidement les tâches de travail. En fin de compte, tout cela représente un casse-tête pour un agent de sécurité qui a de nombreuses autres tâches.
L'utilisation de l'OCR sur les agents n'est justifiée que lorsque le système DLP fonctionne «de manière isolée». Dans ce cas, la reconnaissance d'image doit se produire exactement au moment où l'utilisateur effectue des actions avec ce fichier graphique sur son poste de travail. Autrement dit, le système DLP devrait instantanément décider du sort du document contenant cette image - autoriser son envoi / sa copie ou son interdiction. Mais dans la pratique, seuls quelques clients utilisent le système DLP en mode de blocage actif, et cela ne s'applique pas seulement à notre propre DLP. Ici, le principe fonctionne: "tout ce qui peut être retiré pour des contrôles sur le serveur doit être effectué sur le serveur."
Total
Les technologies OCR offrent des capacités de reconnaissance graphique et, en outre, nous donnons toujours des recommandations générales pour la configuration du système. Cependant, dans un projet particulier, il peut être nécessaire de reconfigurer le module OCR pour répondre aux besoins spécifiques du client tant au stade de pilotage et de mise en œuvre de la solution, qu'au stade de son fonctionnement industriel. Ce n'est pas seulement normal - c'est la seule bonne manière qui donnera des résultats tangibles, rendra l'OCR aussi efficace que possible dans l'entreprise et minimisera la fuite d'informations confidentielles à travers des images graphiques.
Nikita Igonkin, ingénieur de service principal, Rostelecom Solar