Bonjour à tous! Une conférence sur le développement d'applications hautement chargées HighLoad ++ Siberia 2019 s'est tenue en juin à Novossibirsk. Plus tôt dans les articles sur Habré, nous avons mentionné que nous, à Plesk, conduisons une rétrospective des conférences et des rapports auxquels nous assistons afin de ne pas perdre les connaissances acquises et de les appliquer ensuite. Nous vous indiquerons les rapports que nous avons notés nous-mêmes et partagerons également avec vous une recette rétrospective. Les organisateurs publient progressivement la vidéo ici:
chaîne youtube . Une partie de ce que nous décrivons est déjà visible.
Présentation des rapports
Victor Eremchenko (Miro)Ceci est un rapport d'examen sur la migration réussie de Redis -> PostgreSQL -> Pgbouncer + PostgreSQL -> Patroni Consul + Pgbouncer + PostgreSQL. L'auteur donne des schémas, des pièges typiques de solutions évidentes, parle de solutions alternatives et pourquoi elles ne cadraient pas. De l'intéressant:
- Les ingénieurs de Miro ont mis au point leur solution afin de ne pas payer pour Amazon RDS, et cette solution leur convient jusqu'à présent.
- Likbez sur les gestionnaires de connexions pour PostgreSQL.
- Décrit le processus de mise à jour des nœuds de cluster sans arrêter l'application.
- Montre une astuce pour mettre à jour rapidement PostgreSQL.
Il est utile de voir ceux qui utilisent ou vont utiliser PostgreSQL, et qui ont une quantité croissante de données.
Vasily Bogonatov (Yandex)En tant que conférencier d'introduction, il a fait une brève comparaison de certaines fonctionnalités de Kafka et RabbitMQ. En bref: Kafka - une file d'attente simple, un destinataire complexe; RabbitMQ est une file d'attente complexe, un récepteur simple. L'auteur a également parlé des types de garanties pour délivrer un message de la file d'attente. Remarque importante: aucune file d'attente ne peut garantir la livraison d'un message exactement 1 fois sans prise en charge de l'expéditeur et du destinataire.
Le rapport est dédié à YandexMQ. YandexMQ (YMQ) est une API compatible avec la file d'attente Amazon SQS. La base de YandexMQ est la base de données Yandex (YDB). Vasily a montré l'avantage de YandexMQ, comment obtenir une cohérence et une fiabilité strictes, et a donné un aperçu de l'architecture de YMQ. YMQ met en œuvre le modèle des consommateurs concurrents - un message à un consommateur. Puce YMQ: lorsque le consommateur demande un message, il est caché dans la file d'attente afin que personne d'autre ne le prenne en traitement. S'il y a des problèmes pendant le traitement, après VisibilityTimeout, le message redevient visible dans la file d'attente. L'orateur affirme qu'Apache Kafka a un problème de perte de données lorsque le processus est soudainement tué, Yandex MessageQueue y résiste.

Le rapport est recommandé à tous ceux qui souhaitent comprendre les caractéristiques fondamentales des files d'attente.
Ivan Muratov (première société de surveillance)Rapport sur la façon de stocker et de traiter les données dans la série temporelle PostgreSQL.
TimescaleDB vous permet de stocker de gros volumes en raison d'un partitionnement astucieux, et PipelineDB fournit le travail avec les flux directement dans PostgreSQL (ainsi que l'intégration avec les files d'attente).
TimescaleDB:
- Il a une vitesse d'enregistrement très stable avec une augmentation du volume de la base de données sous de lourdes charges et avec une augmentation du nombre de partitions, mesurée en milliers.
- Vous permet d'utiliser des fonctionnalités PostgreSQL standard telles que SQL, la réplication, la sauvegarde, la restauration, etc.
- Un bon ensemble d'intégrations est annoncé, par exemple, avec Prometheus, Telegraf, Grafana, Zabbix, Kubernetes.
- Il existe une version open source gratuite.
L'idée principale: TimescaleDB est nécessaire principalement pour le stockage des données.
PipelineDB:
- Vous permet de traiter en continu les données entrantes à l'aide de SQL et d'ajouter le résultat à une table.
- Possède une interface SQL.
- Il y a une performance des procédures stockées dans les conditions.
- Des intégrations avec Apache Kafka et Amazon Kinesis sont possibles.
- Il existe une version open source gratuite.
- Le développement de PipelineDB est figé sur la version 1.0, et maintenant seules les corrections de bugs sont publiées.
L'idée principale: PipelineDB est nécessaire principalement pour le traitement des données.
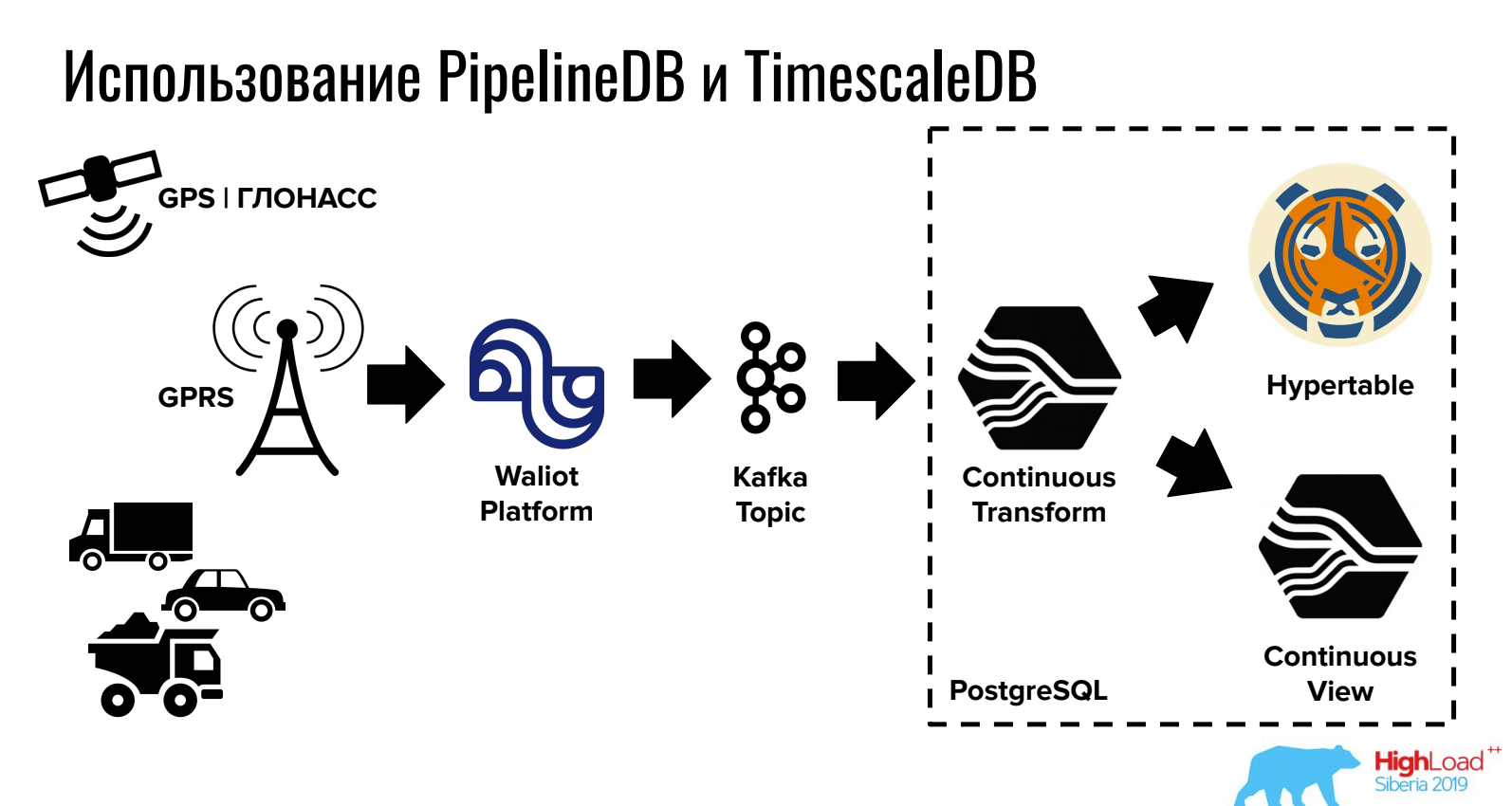
Pour les tâches où un SGBD relationnel, NoSQL et des séries temporelles sont nécessaires en même temps, cette option peut être très pratique.
Pavel Luzanov (Postgres Professional)Un bon rapport de présentation sur PostgreSQL, l'héritage des tables et les performances de Tips & Tricks de PostgreSQL 10, 11, 12+. Partitionnement par héritage, partitionnement. Il est utile de voir tous ceux qui utilisent PostgreSQL et veulent le rendre un peu plus rapide.
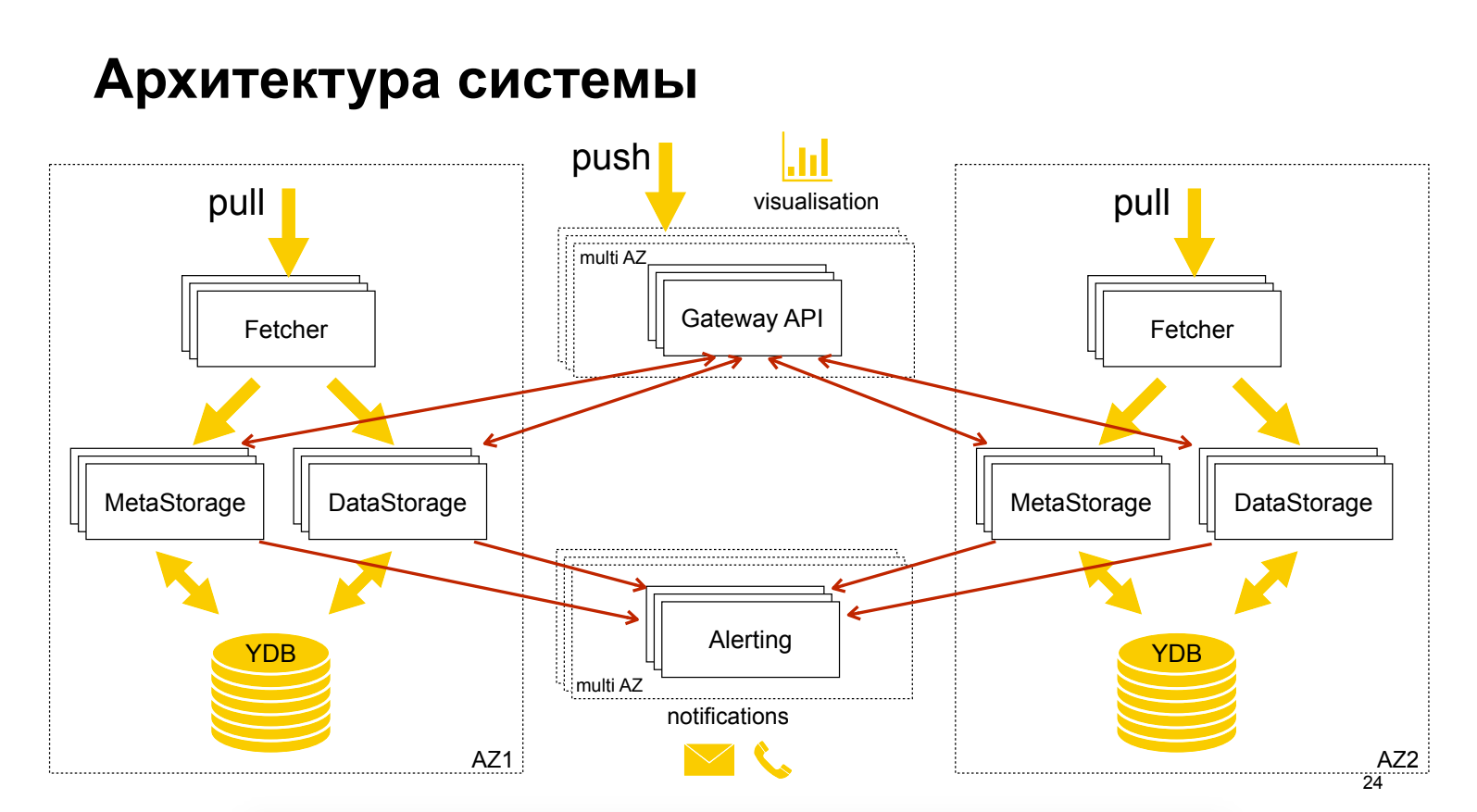
Sergey Polovko (Yandex)À propos du produit cloud Yandex Monitoring, qui est encore au stade «Aperçu», est gratuit. Un peu sur l'architecture. Une technique intéressante est présentée: la séparation des métadonnées des données, qui permet une mise à l'échelle et une optimisation indépendantes. Grafana est utilisé comme une interface graphique, tandis que ses alertes ne sont pas dans Grafana.
 Andrey Salnikov (Data Egret)
Andrey Salnikov (Data Egret)Expérience dans l'administration de systèmes commerciaux de nombreux serveurs PostgreSQL. Il indique quels paramètres de serveur sont automatiquement surveillés, comment les tâches sont hiérarchisées.
Data Egret utilise une expérience généralisée dans le Wiki avec des recettes, des listes de contrôle - c'est la base pour les futurs articles et rapports. Ils utilisent une base de données d'incidents avec une description des problèmes et des solutions - cela économise considérablement les ressources. A publié un certain nombre d'utilitaires pour travailler avec PostgreSQL, fournir des liens vers eux.
 Evgeny Sokolov (Yandex.Market)
Evgeny Sokolov (Yandex.Market)Rapport sur l'architecture d'une application Yandex.Market complexe, hautement accessible et distribuée et sur les processus et outils pour son développement, test, mise à jour, suivi. De l'intéressant:
- «Stop-crane» est sa solution pour une application rapide et un retour en arrière de la configuration, il permet de tester de nouvelles fonctionnalités.
- Le trafic est redirigé du centre de données actuel par l'équilibreur vers un autre centre de données en cas de problème.
- Le graphite et le Grafana sont utilisés pour la surveillance.
- Il existe une surveillance de base en double sur une autre pile technologique.
- Un cluster fantôme est utilisé pour les développeurs, ce qui duplique une partie du trafic utilisateur. Les utilisateurs ne voient pas les réponses du cluster Shadow.
- Un calcul de qualité automatique est effectué lors des tests A / B.
 Anton Alekseev (2GIS)
Anton Alekseev (2GIS)Rapportez ce que ClickHouse est bon et comment le cuisiner en collaboration avec Grafana. Le principal intéressant:
- S'il n'y a pas assez de vitesse, vous devez utiliser l'échantillonnage (on fait valoir que la précision des données après l'échantillonnage est suffisante). Échantillonnage dans ClickHouse - l'échantillonnage partiel des données avec agrégation tout en conservant le rapport des différentes valeurs dans la clé du tableau, vous permet d'accélérer l'agrégation à certains moments et en même temps d'obtenir un résultat très proche de la réalité.
- ClickHouse peut être utilisé pour enquêter rapidement sur les incidents (un exemple intéressant dans le rapport).
- ClickHouse dispose également d'une MaterializedView pour accélérer la récupération.
- L'interface HTTP ClickHouse pour l'interrogation et le chargement des données est décrite.
En conclusion de l'examen des rapports, je voudrais noter que nous avons également beaucoup aimé le rapport
«Appels vidéo: de millions par jour à 100 participants à une conférence» (
Alexander Tobol / Odnoklassniki), qui figurait dans la liste des meilleurs rapports de la conférence en fonction des résultats du vote. Voici un excellent aperçu du fonctionnement de la vidéoconférence pour un groupe de participants. Le rapport se distingue par une présentation systémique compréhensible. Si vous devez soudainement passer des appels vidéo, vous pouvez voir le rapport afin d'avoir rapidement un aperçu du sujet.
Structure du flashback de la conférence Plesk
Et maintenant, pour le dessert, sur la façon dont nous écrivons une rétrospective au sein de l'entreprise. Tout d'abord, nous essayons d'écrire rétro la première semaine après avoir assisté à la conférence, alors que nos souvenirs sont encore frais. Soit dit en passant, le matériel rétrospectif peut alors servir de base à l'article, comme vous pouvez le deviner;)
La rédaction d'une rétrospective n'a pas seulement pour but de consolider les connaissances, mais aussi de les partager avec ceux qui n'étaient pas présents à la conférence, mais qui souhaitent se tenir au courant des dernières tendances, des solutions intéressantes. Une liste prête à l'emploi permet de réduire le temps de recherche de rapports intéressants à afficher. Nous écrivons les leçons que nous avons apprises par nous-mêmes, marquons des personnes spécifiques avec une note, pourquoi vous devez voir le rapport et réfléchir aux idées et aux décisions des autres. Les leçons écrites aident à se concentrer et à ne pas perdre ce que nous voulions faire. En regardant les enregistrements dans 3-6 mois, nous comprendrons si nous avons oublié quelque chose d'important.
Nous stockons la documentation dans l'entreprise à Confluence, pour les conférences nous avons une arborescence de pages séparée, un morceau de bois:
Comme le montre la capture d'écran, nous organisons les documents par année pour faciliter la navigation.
À l'intérieur de la page dédiée à une conférence particulière, nous stockons les sections suivantes: aperçu avec des liens vers le site Web de l'événement, calendrier, vidéos et présentations, liste des participants (en personne et sur les émissions), impression générale (impression générale) et aperçu détaillé (aperçu détaillé) ) Soit dit en passant, nous générons une page pour rétro à partir d'un modèle dans lequel la structure entière existe déjà. Nous constituons également le contenu des rubriques afin que vous puissiez visualiser très rapidement la liste des rapports et passer à celle souhaitée.
La section Impression générale donne une brève évaluation de la conférence et donne les impressions des participants. Si les participants étaient à la conférence au cours des dernières années, ils peuvent comparer leurs niveaux et généralement comprendre l'utilité d'assister à l'événement.
La section Vue d'ensemble détaillée contient un tableau:

Un exemple de remplissage d'une table:

Nous serions intéressés de connaître les rapports que vous avez appréciés à Highload Siberia 2019, ainsi que votre expérience dans la conduite de rétrospectives.