Salut, Habr.
Dans la
première partie , NVIDIA Jetson Nano a été envisagée - une carte au format Raspberry Pi, axée sur le calcul des performances à l'aide du GPU. Il est temps de tester la carte dans laquelle elle a été créée - pour des calculs orientés IA.

Réfléchissez à la façon dont les différentes tâches se déroulent sur le tableau, comme classer des images ou reconnaître des piétons ou des phoques (où sans eux). Pour tous les tests, les codes sources pouvant être exécutés sur le bureau, Jetson Nano ou Raspberry Pi sont donnés. Pour ceux qui sont intéressés, continue sous la coupe.
Il existe deux façons d'utiliser cette carte. La première consiste à exécuter des cadres standard comme Keras et Tensorflow. Cela fonctionnera en principe, ce sera le cas, mais comme déjà vu dans la première partie, Jetson Nano, bien sûr, est inférieur à une carte vidéo de bureau ou d'ordinateur portable à part entière. L'utilisateur devra se charger d'optimiser le modèle. La deuxième façon consiste à suivre des cours prêts à l'emploi fournis avec la planche. C'est plus simple et fonctionne «prêt à l'emploi», le moins est que tous les détails de l'implémentation sont beaucoup plus cachés, en plus, vous devrez étudier et utiliser custom-sdk, qui, en plus de ces cartes, ne sera utile nulle part ailleurs. Cependant, nous examinerons les deux façons, en commençant par la première.
Classification d'image
Considérez le problème de la reconnaissance d'image. Pour ce faire, nous utiliserons le modèle ResNet50 fourni avec Keras (ce modèle a été lauréat du Défi ImageNet en 2015). Pour l'utiliser, quelques lignes de code suffisent.
import tensorflow as tf import numpy as np import time IMAGE_SIZE = 224 IMG_SHAPE = (IMAGE_SIZE, IMAGE_SIZE, 3) resnet = tf.keras.applications.ResNet50(input_shape=IMG_SHAPE) img = tf.contrib.keras.preprocessing.image.load_img('cat.png', target_size=(IMAGE_SIZE, IMAGE_SIZE)) t_start = time.time() img_data = tf.contrib.keras.preprocessing.image.img_to_array(img) x = tf.contrib.keras.applications.resnet50.preprocess_input(np.expand_dims(img_data, axis=0)) probabilities = resnet.predict(x) print(tf.contrib.keras.applications.resnet50.decode_predictions(probabilities, top=5)) print("dT", time.time() - t_start)
Je n'ai même pas commencé à supprimer le code sous le spoiler, car il est très petit. Comme vous pouvez le voir, l'image est d'abord redimensionnée à 224x224 (c'est le format réseau d'entrée), à la fin, la fonction de prédiction fait tout le travail.
Nous prenons une photo du chat et exécutons le programme.

Résultats:
[[('n02123045', 'tabby', 0.765179), ('n02123159', 'tiger_cat', 0.19059166), ('n02124075', 'Egyptian_cat', 0.013605555), ('n04493381', 'tub', 0.0025916891), ('n04553703', 'washbasin', 0.0021566998)]]
Encore une fois, bouleversé par sa connaissance de l'anglais (je me demande combien de non-natifs savent ce qu'est un «tabby»?), J'ai vérifié la sortie avec le dictionnaire, oui, tout fonctionne.
Le temps d'exécution du code PC était de
0,5 s pour les calculs sur le CPU et de 2 s (!) Pour les calculs sur le GPU. À en juger par le journal, le problème se situe dans le modèle ou dans Tensorflow, mais lorsqu'il démarre, le code essaie d'allouer beaucoup de mémoire, obtenant plusieurs avertissements du formulaire «Allocator (GPU_0_bfc) a manqué de mémoire en essayant d'allouer 2.13GiB avec freed_by_count = 0.» . Il s'agit d'un avertissement et non d'une erreur, le code fonctionne, mais beaucoup plus lentement qu'il ne devrait.
Sur Jetson Nano, il est toujours plus lent:
2,8 c sur le CPU et
18,8 c sur le GPU, la sortie ressemble à ceci:
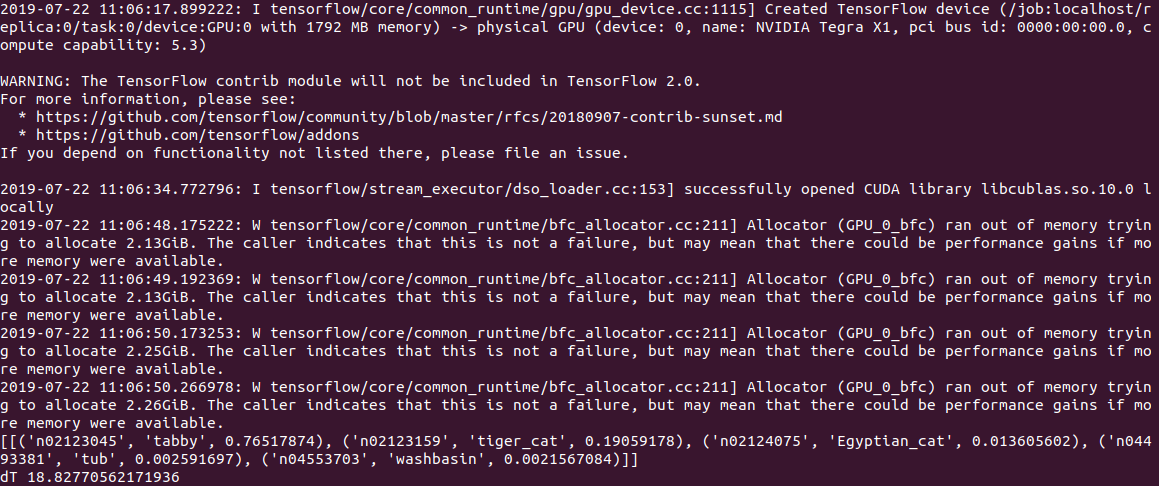
En général, même 3s par image, ce n'est pas encore le temps réel. La définition de l'option gpu_options.allow_growth recommandée en cas de débordement de pile n'aide pas, si quelqu'un connaît une autre manière, écrivez dans les commentaires.
Modifier : comme demandé dans les commentaires, le premier démarrage de tensorflow prend toujours beaucoup de temps et il est incorrect de mesurer le temps d'utilisation. En effet, lors du traitement du deuxième fichier et des fichiers suivants, les résultats sont bien meilleurs - 0,6s sans GPU et 0,2s avec GPU. Sur le bureau, la vitesse est cependant de 2,0 s et 0,05 s, respectivement.
Une caractéristique pratique de ResNet50 est qu'au premier démarrage, il pompe tout le modèle sur le disque (environ 100 Mo), puis le code fonctionne de manière complètement autonome, sans inscription ni SMS. Ce qui est particulièrement agréable, étant donné que la plupart des services d'IA modernes ne fonctionnent que sur le serveur, et sans Internet, l'appareil se transforme en "citrouille".
Chats vs chiens
Considérez le problème suivant. En utilisant Keras, nous allons créer un réseau de neurones qui peut distinguer les chats des chiens. Ce sera un réseau neuronal convolutionnel (CNN - Convolutional Neural Network), nous prendrons la conception du réseau de
cette publication. Un ensemble d'images d'entraînement de chats et de chiens est déjà inclus dans le package tensorflow_datasets, vous n'aurez donc pas à les photographier vous-même.
Nous chargeons un ensemble d'images et le divisons en trois blocs - formation, vérification et test. Nous «normalisons» chaque image, ce qui porte les couleurs à la plage 0..1.
import tensorflow as tf from tensorflow.keras import layers import tensorflow_datasets as tfds from keras.preprocessing import image import numpy as np import time IMAGE_SIZE = 64 IMG_SHAPE = (IMAGE_SIZE, IMAGE_SIZE, 3) splits = tfds.Split.TRAIN.subsplit(weighted=(80, 10, 10)) (cat_train, cat_valid, cat_test), info = tfds.load('cats_vs_dogs', split=list(splits), with_info=True, as_supervised=True) label_names = info.features['label'].int2str def pre_process_image(image, label): image = tf.cast(image, tf.float32) image = image / 255.0
Nous écrivons la fonction de génération d'un réseau neuronal convolutionnel.
def custom_model():
Nous pouvons maintenant organiser une formation en réseau sur notre kit «chat-chien». La formation prend beaucoup de temps (20 minutes sur le GPU et 1-2 heures sur le CPU), donc à la fin nous enregistrons le modèle dans un fichier.
tl_model = custom_model() t_start = time.time() tl_model.fit(train_batch, steps_per_epoch=8000, epochs=2, validation_data=validation_batch, validation_steps=10, callbacks=None) print("Training done, dT:", time.time() - t_start) print(tl_model.summary()) validation_steps = 20 loss0, accuracy0 = tl_model.evaluate(validation_batch, steps=validation_steps) print("Loss: {:.2f}".format(loss0)) print("Accuracy: {:.2f}".format(accuracy0)) tl_model.save("dog_cat_model.h5")
Soit dit en passant, la tentative de lancement de la formation directement sur le Jetson Nano a échoué - après 5 minutes, la planche a surchauffé et a suspendu. Pour les calculs gourmands en ressources, un refroidisseur est requis pour la carte, bien que dans l'ensemble, cela n'a aucun sens de faire de telles tâches directement sur Jetson Nano - vous pouvez entraîner le modèle sur un PC et utiliser le fichier enregistré fini sur Nano.
Un autre écueil est apparu ici - la bibliothèque tensowflow version 14 a été installée sur le PC, et la dernière version pour Jetson Nano est jusqu'à présent 13. Et le modèle enregistré dans la 14e version n'a pas été lu dans le 13e, j'ai dû installer les mêmes versions en utilisant pip.
Enfin, nous pouvons charger le modèle à partir d'un fichier et l'utiliser pour reconnaître des images.
def predict_model(model, image_file): img = image.load_img(image_file, target_size=(IMAGE_SIZE, IMAGE_SIZE)) t_start = time.time() img_arr = np.expand_dims(img, axis=0) result = model.predict_classes(img_arr) print("Result: {}, dT: {}".format(label_names(result[0][0]), time.time() - t_start)) model = tf.keras.models.load_model('dog_cat_model.h5') predict_model(model, "cat.png") predict_model(model, "dog1.png") predict_model(model, "dog2.png")
La photo du chat a été utilisée de la même façon, mais pour le test "chien" 2 photos ont été utilisées:

Le premier a deviné correctement, et le second a d'abord eu des erreurs et le réseau neuronal pensait que c'était un chat, j'ai dû augmenter le nombre d'itérations d'entraînement. Cependant, j'aurais probablement fait une erreur la première fois;)
Le temps d'exécution sur Jetson Nano s'est avéré être assez petit - la toute première photo a été traitée en 0,3 s, mais toutes les suivantes ont été beaucoup plus rapides, apparemment les données sont mises en cache en mémoire.
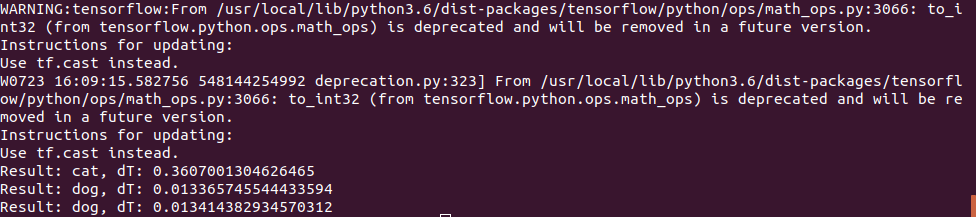
En général, nous pouvons supposer que sur de tels réseaux neuronaux simples, la vitesse de la carte est assez suffisante même sans optimisation, 100fps est une valeur suffisante même pour la vidéo en temps réel.
Conclusion
Comme vous pouvez le voir, même les modèles standard de Keras et Tensorflow peuvent être utilisés sur Nano, bien qu'avec un succès variable - quelque chose fonctionne, quelque chose ne fonctionne pas. Cependant, les résultats peuvent être améliorés, des instructions sur l'optimisation du modèle et la réduction de la taille de la mémoire peuvent être lues
ici .
Mais heureusement pour nous, les fabricants l'ont déjà fait pour nous. Si les lecteurs sont toujours intéressés, la dernière partie sera consacrée aux
bibliothèques prêtes à l'
emploi optimisées pour travailler avec Jetson Nano.