
La traduction de l'article a été préparée pour les étudiants du cours "MS SQL Server Developer"
Les bases de données relationnelles sont l'une des bases de données les plus couramment utilisées à ce jour, et par conséquent, des compétences en SQL pour la plupart des publications sont requises. Dans cet article, avec des questions SQL issues d'entretiens, je vais vous présenter les questions les plus fréquemment posées sur SQL (Structured Query Language - Structured Query Language). Cet article est un guide idéal pour explorer tous les concepts liés à SQL, Oracle, MS SQL Server et la base de données MySQL.
Notre article sur les questions SQL est une ressource universelle avec laquelle vous pouvez accélérer la préparation d'un entretien. Il consiste en un ensemble de 65 des questions les plus courantes qu'un enquêteur peut poser lors d'un entretien. Il commence généralement par des questions SQL de base, puis passe à des questions plus complexes en fonction de la discussion et de vos réponses. Ces questions d'entrevue SQL vous aideront à maximiser vos avantages à différents niveaux de compréhension.
Commençons!
Interview SQL Questions
Question 1. Quelle est la différence entre DELETE et TRUNCATE?
Non. Question 2. Quels sont les sous-ensembles de SQL?
- DDL (Data Definition Language) - vous permet d'effectuer diverses opérations avec la base de données, telles que CREATE (créer), ALTER (modifier) et DROP (supprimer des objets).
- DML (Data Manipulation Language) - vous permet d'accéder et de manipuler des données, par exemple, insérer, mettre à jour, supprimer et récupérer des données d'une base de données.
- DCL (Data Control Language) - vous permet de contrôler l'accès à la base de données. Un exemple est GRANT (octroi de droits), REVOKE (révocation de droits).
Question 3. Qu'entend-on par SGBD? Quels types de SGBD existe-t-il?
La base de données est une collecte de données structurée. Système de gestion de base de données (SGBD) - logiciel qui interagit avec l'utilisateur, les applications et la base de données elle-même pour collecter et analyser les données. Le SGBD permet à l'utilisateur d'interagir avec la base de données. Les données stockées dans la base de données peuvent être modifiées, récupérées et supprimées. Ils peuvent être de tout type, tels que des chaînes, des nombres, des images, etc.
Il existe deux types de SGBD:
- Système de gestion de base de données relationnelle: les données sont stockées dans des relations (tables). Un exemple est MySQL.
- Système de gestion de base de données non relationnelle: il n'y a pas de concept de relations, tuples et attributs. Un exemple est Mongo.
Question 4. Qu'entend-on par table et champ en SQL?
Un tableau est un ensemble de données organisé sous forme de lignes et de colonnes. Un champ est une colonne d'une table. Par exemple:
Tableau: Student_Information
Champ: Stu_Id, Stu_Name, Stu_Marks
Question 5. Que sont les jointures dans SQL?
L'opérateur JOIN est utilisé pour joindre des lignes de deux tables ou plus en fonction d'une colonne connectée entre elles. Il est utilisé pour joindre deux tables ou en obtenir des données. Il existe 4 types de connexion en SQL, à savoir:
- Jointure intérieure
- Jointure droite
- Jointure gauche
- Jointure complète
Question 6. Quelle est la différence entre les types de données CHAR et VARCHAR dans SQL?
Char et Varchar servent de types de données de caractères, mais varchar est utilisé pour les chaînes de caractères de longueur variable, tandis que Char est utilisé pour les chaînes de longueur fixe. Par exemple, char (10) ne peut stocker que 10 caractères et ne peut pas stocker une chaîne de toute autre longueur, tandis que varchar (10) peut stocker une chaîne de n'importe quelle longueur jusqu'à 10, c'est-à-dire par exemple 6, 8 ou 2.
Question 7. Qu'est-ce qu'une clé primaire?

- Une clé primaire est une colonne ou un ensemble de colonnes qui identifie de manière unique chaque ligne d'une table.
- Identifie de façon unique une ligne dans un tableau
- Valeurs nulles non autorisées
_Exemple: dans la table Student Stu, la clé primaire est.
Question 8. Quelles sont les contraintes?
Les contraintes sont utilisées pour indiquer les restrictions sur le type de données d'une table. Ils peuvent être spécifiés lors de la création ou de la modification d'une table. Exemples de restrictions:
- PAS NUL
- VÉRIFIER
- PAR DÉFAUT
- UNIQUE
- CLÉ PRIMAIRE
- CLÉ ÉTRANGÈRE
Question 9. Quelle est la différence entre SQL et MySQL?
SQL est le langage de requête structuré standard basé sur la langue anglaise, tandis que MySQL est un système de gestion de base de données. SQL est un langage de base de données relationnelle utilisé pour accéder et gérer les données, MySQL est un SGBD relationnel (système de gestion de base de données), ainsi que SQL Server, Informix, etc.
Question 10. Qu'est-ce qu'une clé unique?
- Identifie de façon unique une ligne dans un tableau.
- De nombreuses clés uniques sont autorisées dans une même table.
- Les valeurs NULL sont autorisées ( note de traduction: dépend du SGBD; dans SQL Server, NULL ne peut être ajouté qu'une seule fois dans un champ avec UNIQUE KEY ).
Question 11. Qu'est-ce qu'une clé étrangère?
- Une clé étrangère maintient l'intégrité référentielle en fournissant un lien entre les données de deux tables.
- La clé étrangère dans la table enfant fait référence à la clé primaire dans la table parent.
- Une contrainte de clé étrangère empêche les actions qui rompent les relations entre les tables enfant et parent.
Question 12. Qu'entend-on par intégrité des données?
L'intégrité des données détermine la précision ainsi que la cohérence des données stockées dans la base de données. Il définit également des contraintes d'intégrité pour appliquer des règles métier aux données lorsqu'elles sont entrées dans une application ou une base de données.
Question 13. Quelle est la différence entre les index cluster et non cluster en SQL?
- Différences entre les index cluster et non cluster en SQL:
Un index cluster est utilisé pour récupérer facilement et rapidement des données à partir d'une base de données, tandis que la lecture à partir d'un index non cluster est relativement plus lente. - Un index cluster change la façon dont les enregistrements sont stockés dans la base de données - il trie les lignes par une colonne qui est définie comme un index cluster, tandis que dans un index non cluster, il ne change pas la méthode de stockage, mais crée un objet séparé à l'intérieur du tableau qui pointe vers les lignes du tableau d'origine lors de la recherche.
- Une table ne peut avoir qu'un seul index clusterisé, alors qu'elle peut en avoir plusieurs non clusterisés.
Question 14. Écrivez une requête SQL pour afficher la date actuelle.
SQL possède une fonction GetDate () intégrée qui permet de renvoyer l'horodatage / la date actuelle.
Question 15. Énumérez les types de connexions
Il existe différents types de jointures qui sont utilisées pour extraire des données entre les tables. Fondamentalement, ils sont divisés en quatre types, à savoir:
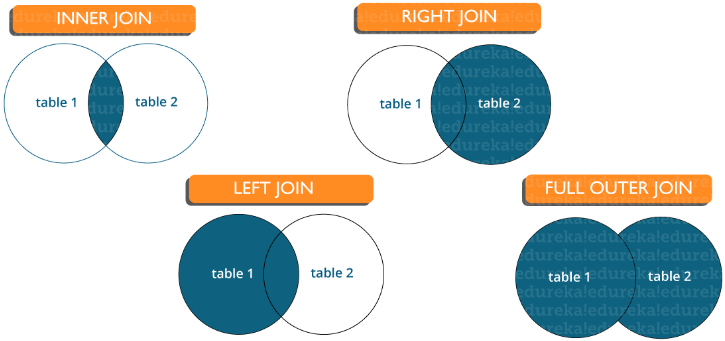
Jointure interne : dans MySQL, le type le plus courant. Il est utilisé pour renvoyer toutes les lignes de plusieurs tables pour lesquelles la condition de jointure est remplie.
Jointure gauche : dans MySQL, elle est utilisée pour renvoyer toutes les lignes de la table gauche (première) et uniquement les lignes correspondantes de la table droite (seconde) pour lesquelles la condition de jointure est remplie.
Jointure droite : dans MySQL, elle est utilisée pour renvoyer toutes les lignes de la table de droite (deuxième) et uniquement les lignes correspondantes de la table de gauche (première) pour lesquelles la condition de jointure est remplie.
Jointure complète : renvoie tous les enregistrements pour lesquels il existe une correspondance dans l'une des tables. Par conséquent, il renvoie toutes les lignes de la table de gauche et toutes les lignes de la table de droite.
Question 16. Qu'entendez-vous par dénormalisation?
La dénormalisation est une technique utilisée pour convertir des formes normales supérieures aux formes normales inférieures. Il aide les développeurs de bases de données à améliorer les performances de l'ensemble de l'infrastructure en introduisant une redondance dans la table. Il ajoute des données redondantes à la table, compte tenu des fréquentes requêtes de base de données qui combinent les données de différentes tables en une seule table.
Question 17. Que sont les entités et les relations?
Entités: une personne, un lieu ou un objet dans le monde réel, dont les données peuvent être stockées dans une base de données. Les tables stockent des données qui représentent un type d'entité. Par exemple, une base de données bancaire possède une table client pour stocker les informations client. La table des clients stocke ces informations sous la forme d'un ensemble d'attributs (colonnes du tableau) pour chaque client.
Relations: relations ou relations entre entités qui sont en quelque sorte liées les unes aux autres. Par exemple, le nom d'un client est associé à un numéro de compte client et des informations de contact, qui peuvent figurer dans le même tableau. Il peut également y avoir des relations entre des tables individuelles (par exemple, du client aux comptes).
Question 18. Qu'est-ce qu'un indice?
Les index se rapportent à une méthode d'optimisation des performances qui permet une récupération plus rapide des enregistrements d'une table. L'index crée une structure distincte pour le champ indexé et, par conséquent, permet une récupération plus rapide des données.
Question 19. Décrivez les différents types d'index.
Il existe trois types d'index, à savoir:
- Index unique: cet index empêche le champ d'avoir des valeurs en double si la colonne est indexée de manière unique. Si une clé primaire est définie, un index unique peut être appliqué automatiquement.
- Index clusterisé: cet index modifie l'ordre physique de la table et effectue des recherches en fonction des valeurs clés. Chaque table ne peut avoir qu'un seul index cluster.
- Index non clusterisé: ne modifie pas l'ordre physique de la table et conserve l'ordre logique des données. Chaque table peut avoir de nombreux index non clusterisés.
Question 20. Qu'est-ce que la normalisation et quels sont ses avantages?
La normalisation est le processus d'organisation des données dont le but est d'éviter la duplication et la redondance. Quelques avantages:
- Meilleure organisation de base de données
- Plus de tables avec de petites rangées
- Accès efficace aux données
- Plus grande flexibilité pour les requêtes
- Recherche rapide d'informations
- Plus facile à mettre en œuvre la sécurité des données
- Permet une modification facile
- Réduisez les données redondantes et dupliquées
- Base de données plus compacte
- Assure la cohérence des données après les modifications
Question 21. Quelle est la différence entre DROP et TRUNCATE?
La commande DROP supprime la table elle-même et vous ne pouvez pas effectuer de commandes Rollback, tandis que la commande TRUNCATE supprime toutes les lignes de la table ( notez la traduction: dans SQL Server, Rollback fonctionnera normalement et restaurera DROP ).
Question 22. Expliquez les différents types de normalisation.
Il existe de nombreux niveaux de normalisation consécutifs. Ce sont les soi-disant formes normales. Chaque forme normale suivante comprend la précédente. Les trois premières formes normales sont généralement suffisantes.
- Premier formulaire normal (1NF) - pas de groupes en double dans les lignes
- La deuxième forme normale (2NF) - chaque valeur de colonne non clé (prise en charge) dépend de la clé primaire entière
- Troisième forme normale (3NF) - chaque valeur non clé dépend uniquement de la clé primaire et ne dépend pas d'une autre valeur non clé de la colonne
Question 23. Quelle est la propriété ACID dans la base de données?
ACIDE signifie atomicité, cohérence, isolation, durabilité. Il est utilisé pour fournir un traitement fiable des transactions de données dans un système de base de données.
Atomicité. Garantit que la transaction est entièrement terminée ou échoue, où la transaction représente une seule opération de données logiques. Cela signifie que si une partie d'une transaction échoue, la transaction entière échoue et l'état de la base de données reste inchangé.
Cohérence. Garantit que les données doivent respecter toutes les règles de validation. Autrement dit, vous pouvez dire que votre transaction ne laissera jamais votre base de données dans un état invalide.
Isolement. Le principal objectif de l'isolement est de contrôler le mécanisme des modifications de données parallèles.
Longévité. La durabilité implique que si la transaction a été confirmée (COMMIT), les changements intervenus au sein de la transaction seront conservés indépendamment de ce qui pourrait se mettre en travers de leur chemin (par exemple, perte de puissance, panne ou erreurs de toute nature).
Question 24. Qu'entendez-vous par «déclencheur» en SQL?
Un déclencheur dans SQL est un type spécial de procédure stockée conçu pour être exécuté automatiquement lorsque ou après la modification des données. Cela vous permet d'exécuter un package de code lorsqu'une insertion, une mise à jour ou toute autre requête est effectuée sur une table spécifique.
Question 25. Quelles instructions sont disponibles dans SQL?
Trois types d'instructions sont disponibles en SQL, à savoir:
- Opérateurs arithmétiques
- Opérateurs logiques
- Opérateurs de comparaison
Question 26. Les valeurs NULL correspondent-elles à zéro ou à l'espace?
NULL n'est pas nul ou espace du tout. Une valeur NULL représente une valeur qui n'est pas disponible, inconnue, affectée ou non applicable, tandis que zéro est un nombre et l'espace est un caractère.
Question 27. Quelle est la différence entre une jointure croisée et une jointure naturelle?
Une jointure croisée crée un produit croisé ou cartésien de deux tables, tandis qu'une jointure naturelle est basée sur toutes les colonnes qui ont le même nom et les mêmes types de données dans les deux tables.
Question 28. Qu'est-ce qu'une sous-requête dans SQL?
Une sous-requête est une requête à l'intérieur d'une autre requête qui définit une requête pour récupérer des données ou des informations d'une base de données. Dans une sous-requête, la requête externe est appelée la requête principale, tandis que la requête interne est appelée la sous-requête. Les sous-requêtes sont toujours exécutées en premier et le résultat de la sous-requête est transmis à la requête principale. Il peut être imbriqué dans SELECT, UPDATE ou dans toute autre requête. Une sous-requête peut également utiliser n'importe quel opérateur de comparaison, tel que>, <ou =.
Question 29. Quels sont les types de sous-requêtes?
Il existe deux types de sous-requêtes, à savoir: corrélées et non corrélées.
- Sous-requête corrélée: il s'agit d'une requête qui sélectionne les données d'une table avec un lien vers une requête externe. Elle n'est pas considérée comme une requête indépendante car elle fait référence à une autre table ou colonne de la table.
- Sous-requête non corrélée: cette requête est une requête indépendante dans laquelle la sortie de la sous-requête est substituée dans la requête principale.
Question 30. Énumérez les façons d'obtenir le nombre d'enregistrements dans le tableau?
Pour compter le nombre d'enregistrements dans une table, vous pouvez utiliser les commandes suivantes:
SELECT * FROM table1
SELECT COUNT(*) FROM table1
SELECT rows FROM sysindexes WHERE id = OBJECT_ID(table1) AND indid < 2
Nous publierons 35 autres questions avec des réponses dans la prochaine partie ... Suivez l'actualité!