
Bonjour, je suis Andrey Shalnev, responsable QA Automation du projet Skyeng Vimbox. Au cours de l'année, l'équipe et moi avons été engagés dans l'optimisation des processus de tests automatiques et nous sommes maintenant très proches de sa phase finale. Et c'est une bonne raison d'exhaler, de revoir l'arriéré et de prendre des résultats intermédiaires. Pour Habra, j'ai décidé de faire une sélection des dix choses les plus utiles et en même temps simples qui nous ont aidés à faire face à la tâche d'optimisation des autotests. J'espère que l'article sera utile aux équipes d'AQ dans les entreprises en croissance, où les anciens processus de test ne peuvent plus faire face à la charge et où la question de la réorganisation soulève le problème.
Comment nous organisons les autotests
Vimbox utilise Angular pour le frontend, nous écrivons donc des tests sur une pile assez classique pour cette solution - Protractor + Jasmine + JS / Typescript. Au cours de l'année, nous avons considérablement repensé la suite de tests de régression. Dans sa forme initiale, il était redondant et peu pratique - tests de plusieurs centaines de lignes avec un temps de passage de 5 à 10 minutes, avec cette longueur d'un scénario de test séparé, il n'atteint très souvent pas la fin en raison d'un faux fichier. Nous avons maintenant divisé les tests en scénarios plus courts et plus stables, nous utilisons failFast pour que le temps d'exécution soit acceptable (un test qui se bloque au milieu n'essaiera pas de terminer chaque étape suivante et attendra qu'il expire). De plus, nous nous sommes débarrassés des contrôles redondants: nous nous assurons qu'une fonctionnalité spécifique est fonctionnelle en général, mais nous n'essayons pas de la vérifier dans toutes les variantes possibles.
Les autotests sont priorisés. Un petit ensemble de priorités absolues - Test d'acceptation des utilisateurs (UAT) - s'exécute toutes les heures sur la prod, après le déploiement des principaux projets et lors du test des tâches sur les bancs d'essai.
Le processus aux stands ressemble à ceci: le développeur transfère la tâche aux tests, QA la déploie sur son stand et exécute les tests - UAT et régression. En UAT, nous avons environ 150 cas, régression - environ 700 tests, il est constamment mis à jour. La plupart des cas importants et critiques, cette suite couvre environ 80% et s'exécute à chaque itération.
Ten Life Hacks
Spécifiez explicitement le rôle de l'instance de navigateur . La spécificité des tests Vimbox est que dans la grande majorité des cas, deux instances de navigateur ou plus sont utilisées, car la leçon a au moins deux côtés - un enseignant et un étudiant. browser1 , il y avait un problème: une instance de navigateur était indiquée par un numéro, il était entendu que tout le monde comprenait que browser1 était un enseignant, et browser2 et au-delà étaient des étudiants. Mais ce n'est pas toujours le cas, il est arrivé que le navigateur de l'élève soit le premier. De plus, il y a des tests où les élèves eux-mêmes sont différents - par exemple, nous devons nous assurer que vous ne pouvez pas accidentellement entrer dans la leçon de quelqu'un d'autre. Pour faire comprendre à tout le monde quel utilisateur se trouve dans quelle instance de navigateur, ils ont commencé à indiquer explicitement le rôle dans son nom: teacher.browser , student.browser , wrongStudent.browser , etc. Vous avez des scripts de test plus lisibles.
Nous utilisons les fonctions fléchées: () => , pas la function() . Premièrement, un tel enregistrement est plus court. Deuxièmement, une syntaxe plus moderne, nous essayons de nous éloigner de l'archaïque. Troisièmement, les fonctions fléchées évitent les problèmes avec le pointeur this partir de JavaScript. La fonction flèche ne crée pas sa portée lexicale , il est donc possible de se référer à quelque chose défini en dehors de this . Débarrassez-vous de la béquille classique = this .
Nous utilisons des chaînes de modèle au lieu de concaténations avec des avantages: `Student $ {studentName}`, et non "Student" + studentName . Nous essayons d'utiliser des chaînes de motifs au lieu de concaténations avec des plus.
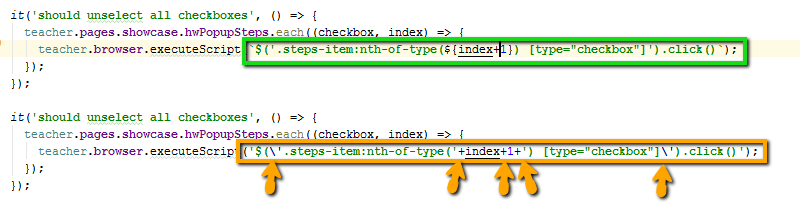
Il s'agit d'une syntaxe moderne, elle est plus lisible, les deux types de guillemets (simples et doubles) peuvent être utilisés à l'intérieur de la chaîne et non filtrés.
Nous utilisons TypeScript . Surtout pour des conseils d'environnement de développement plus adéquats et une navigation de code normale. Maintenant, dans la plupart des cas, au lieu de quelques conseils, une transition directe vers la méthode / le champ est possible. Dans le même temps, le passage à TypeScript n'a pas nécessité beaucoup de refactoring en même temps: pour commencer, vous pouvez simplement changer les extensions de fichier de .js en .ts, le projet reste réalisable. Modifiez ensuite progressivement la syntaxe de require en Import , la navigation est améliorée.
Divisez les grands objets de page en sous-classes pour faciliter la maintenance de ces objets. Notre plus grande leçon d'objet de page a atteint quatre mille lignes de code, il était difficile de parcourir, rappelez-vous ce qui a commencé, ce qui ne l'a pas été. Maintenant, le code le plus long est d'environ 1300 lignes. Nous pouvons dire qu'en faisant cela, nous nous sommes débarrassés de la grande classe antipattern. En outre, ils ont supprimé les commentaires inutiles et travaillé sur la commodité et l'intelligibilité des noms des méthodes: dans la plupart des cas, si la méthode est nommée conformément à la convention claire pour tout le monde, un commentaire expliquant son travail n'est tout simplement pas nécessaire.
Nous exécutons l'UAT en parallèle dans plusieurs threads pour faciliter le travail avec l'UAT sur le prod. Le fait est qu'avec nous, un tel test s'exécute une fois par heure et s'exécute dans un thread pendant 15 minutes. Si un fichier s'y trouve, il redémarrera et finira par fonctionner pendant une demi-heure. Lors d'un déploiement, cela peut être un problème car la file d'attente est retardée. Le résultat de l'utilisation du parallèle est de 2-3 minutes sur l'UAT (ou 6 avec un redémarrage). La file d'attente se déplace plus rapidement, des informations sur le problème ou sur le fait que le fichier s'est avéré faux arrivent plus rapidement.
Nous exécutons régulièrement UAT et régression sur des bancs de test . Chacun de nos testeurs manuels possède son propre serveur. Nous avions l'habitude d'exécuter des tests de régression sur prod après que le testeur manuel ait trouvé une partie importante des bogues - en fait, nous venons de le vérifier. Maintenant, nous exécutons des autotests à chaque itération de test manuel de la tâche, ce qui, d'une part, facilite le travail d'un testeur manuel (il n'a pas besoin de percer ce qui est automatiquement), et d'autre part, raccourcit le cycle de rétroaction. Si le développeur a cassé quelque chose, il le saura une demi-heure après le déploiement de la tâche, et non le lendemain. De plus, sur le banc de test, vous pouvez faire beaucoup de choses indésirables sur la production: changer le numéro de version du produit, supprimer / ajouter du contenu de test, modifier sans crainte la base de données pour préparer la situation de test, etc.
Supprimez les fichiers vides . Nous essayons de maintenir la cohérence entre la structure du répertoire dans les autotests et dans Testrail. Mais en même temps, à un moment donné, nous avons rencontré un problème - Testrail a un grand nombre de cas avec une faible priorité (seulement environ 9000+ cas), car Il est utilisé comme base de connaissances du projet. Dans le même temps, seulement un millier des cas les plus importants sont couverts par des autotests. Si nous obtenons une correspondance parfaite, nous obtenons un grand nombre de fichiers et de répertoires inutilisés. Cela complique la navigation du projet et nuit à la compréhension de ce qui est réellement testé. En conséquence, seuls les dossiers et fichiers nécessaires ont été laissés, le reste a été supprimé.
Nous corrigeons les bugs trouvés . La tâche principale des autotests n'est pas de trouver des bogues, mais de s'assurer rapidement qu'ils ne sont pas là, donc quelque chose est rarement détecté. La fixation résout deux problèmes: premièrement, nous voyons des statistiques où les problèmes demeurent le plus souvent et lesquels, et deuxièmement, nous nous débarrassons du sentiment que nous faisons quelque chose de mal. Lorsque les tests ne trouvent rien, la question se pose: faisons-nous tout correctement, peut-être que nos tests ne servent à rien? Et puis il y a une tablette qui montre que lorsqu'ils ont pu attraper: plus de 60 bugs par an. Dans le même temps, la signification d'exécuter des tests sur les serveurs de production et de test est devenue évidente. Le lancement fréquent sur le prod - toutes les heures - permet de détecter les problèmes d'infrastructure (un service externe n'est pas disponible, notre serveur est tombé en panne), le lancement avant les tests manuels détecte les pannes introduites par le nouveau code.
Attributs data-qa-id implémentés , par exemple, [data-qa-id="btn-login"] . Objectif: sélecteurs plus stables. Nous avons convenu avec l'équipe de développement que si vous modifiez l'implémentation de certains éléments, s'ils y voient l'attribut data-qa-id , ils comprennent que c'est pour les autotests, ils ne le modifient pas et ils le transfèrent avec précision. Cet attribut a un nom logique, qui en lui-même est capable de dire de quoi l'élément est responsable. De plus, nous ne dépendons pas de l'implémentation spécifique de l'élément - quel id ordinaire lui est suspendu, quelle classe, étiquette, différentiel, lien y est accroché. Il est devenu plus calme: les sélecteurs se cassent moins souvent, dans certains cas, des informations supplémentaires peuvent être affichées avec cet attribut. Par exemple, vous avez besoin du nom d'une étape d'une leçon. Si vous regardez le nom de l'étape dans XPath, le sélecteur peut s'avérer long, à plusieurs niveaux et peu lisible, et si vous travaillez avec le modèle html dans le code angulaire, vous pouvez afficher le même nom dans un court attribut compréhensible, en contournant le long XPath.
Partagez vos astuces de vie et vos pensées dans les commentaires!