
Nous continuons à publier des analyses des tâches qui ont été proposées lors du récent championnat. Viennent ensuite les tâches issues du cycle de qualification pour les spécialistes de l'apprentissage automatique. Il s'agit de la troisième piste sur quatre (backend, frontend, ML, analytics). Les participants devaient créer un modèle pour corriger les fautes de frappe dans les textes, proposer une stratégie pour jouer sur les machines à sous, évoquer un système de recommandations de contenu et composer plusieurs autres programmes.
A. Typos
Condition
(épigraphe) (d'un forum)
- Qui a composé ce non-sens?
- Astrophysiciens. Ce sont aussi des gens.
- Vous avez fait 10 erreurs dans le mot «journalistes».
De nombreux utilisateurs font des fautes de frappe, certaines à cause de la frappe des touches et d'autres à cause de leur analphabétisme. Nous voulons vérifier si l'utilisateur pourrait réellement avoir à l'esprit un autre mot que celui qu'il a tapé.
Plus formellement, supposons que le modèle d'erreur suivant se produise: l'utilisateur commence par un mot qu'il veut écrire, puis y fait ensuite un certain nombre d'erreurs. Chaque erreur est une substitution d'une sous-chaîne du mot pour une autre sous-chaîne. Une erreur correspond au remplacement d'une seule position (c'est-à-dire que si l'utilisateur veut faire une seule erreur par la règle "abc" → "cba", alors à partir de la chaîne "abcabc" il peut obtenir soit "cbaabc" ou "abccba"). Après chaque erreur, le processus se répète. La même règle peut être utilisée plusieurs fois à différentes étapes (par exemple, dans l'exemple ci-dessus, «cbacba» peut être obtenu en deux étapes).
Il est nécessaire de déterminer le nombre minimum d'erreurs qu'un utilisateur pourrait commettre s'il avait en tête un mot donné et en écrivait un autre.
Formats d'E / S et exempleFormat d'entrée
La première ligne contient le mot que, selon notre hypothèse, l'utilisateur avait en tête (il est composé de lettres de l'alphabet latin en minuscules, la longueur ne dépasse pas 20).
La deuxième ligne contient le mot qu'il a effectivement écrit (il se compose également de lettres de l'alphabet latin en minuscules, la longueur ne dépasse pas 20).
La troisième ligne contient un seul nombre N (N <50) - le nombre de remplacements qui décrivent diverses erreurs.
Les N lignes suivantes contiennent des remplacements possibles au format & lt séquence de lettres "correcte" & gt <space> <séquence de lettres "erronée">. Les séquences ne comportent pas plus de 6 caractères.
Format de sortie
Il est nécessaire d'imprimer un numéro - le nombre minimum d'erreurs que l'utilisateur pourrait commettre. Si ce nombre dépasse 4 ou s'il est impossible d'en obtenir un autre à partir d'un mot, imprimez -1.
Exemple
Solution
Essayons de générer à partir de l'orthographe correcte tous les mots possibles avec pas plus de 4 erreurs. Dans le pire des cas, il peut y avoir O ((L﹒N)
4 ). Dans les limites du problème, il s'agit d'un nombre assez important, vous devez donc comprendre comment réduire la complexité. Au lieu de cela, vous pouvez utiliser l'algorithme de rencontre au milieu: générer des mots avec pas plus de 2 erreurs, ainsi que des mots à partir desquels vous pouvez obtenir un mot écrit par l'utilisateur avec pas plus de 2 erreurs. Notez que la taille de chacun de ces ensembles ne dépassera pas 10
6 . Si le nombre d'erreurs commises par l'utilisateur ne dépasse pas 4, ces ensembles se recouperont. De même, nous pouvons vérifier que le nombre d'erreurs ne dépasse pas 3, 2 et 1.
struct FromTo { std::string from; std::string to; }; std::pair<size_t, std::string> applyRule(const std::string& word, const FromTo &fromTo, int pos) { while(true) { int from = word.find(fromTo.from, pos); if (from == std::string::npos) { return {std::string::npos, {}}; } int to = from + fromTo.from.size(); auto cpy = word; for (int i = from; i < to; i++) { cpy[i] = fromTo.to[i - from]; } return {from, std::move(cpy)}; } } void inverseRules(std::vector<FromTo> &rules) { for (auto& rule: rules) { std::swap(rule.from, rule.to); } } int solve(std::string& wordOrig, std::string& wordMissprinted, std::vector<FromTo>& replaces) { std::unordered_map<std::string, int> mapping; std::unordered_map<int, std::string> mappingInverse; mapping.emplace(wordOrig, 0); mappingInverse.emplace(0, wordOrig); mapping.emplace(wordMissprinted, 1); mappingInverse.emplace(1, wordMissprinted); std::unordered_map<int, std::unordered_set<int>> edges; auto buildGraph = [&edges, &mapping, &mappingInverse](int startId, const std::vector<FromTo>& replaces, bool dir) { std::unordered_set<int> mappingLayer0; mappingLayer0 = {startId}; for (int i = 0; i < 2; i++) { std::unordered_set<int> mappingLayer1; for (const auto& v: mappingLayer0) { auto& word = mappingInverse.at(v); for (auto& fromTo: replaces) { size_t from = 0; while (true) { auto [tmp, wordCpy] = applyRule(word, fromTo, from); if (tmp == std::string::npos) { break; } from = tmp + 1; { int w = mapping.size(); mapping.emplace(wordCpy, w); w = mapping.at(wordCpy); mappingInverse.emplace(w, std::move(wordCpy)); if (dir) { edges[v].emplace(w); } else { edges[w].emplace(v); } mappingLayer1.emplace(w); } } } } mappingLayer0 = std::move(mappingLayer1); } }; buildGraph(0, replaces, true); inverseRules(replaces); buildGraph(1, replaces, false); { std::queue<std::pair<int, int>> q; q.emplace(0, 0); std::vector<bool> mask(mapping.size(), false); int level{0}; while (q.size()) { auto [w, level] = q.front(); q.pop(); if (mask[w]) { continue; } mask[w] = true; if (mappingInverse.at(w) == wordMissprinted) { return level; } for (auto& v: edges[w]) { q.emplace(v, level + 1); } } } return -1; }
Bandit armé de plusieurs armes
Condition
Il s'agit d'une tâche interactive.
Vous ne savez pas comment cela s'est passé, mais vous vous êtes retrouvé dans une salle avec des machines à sous avec un sac entier de jetons. Malheureusement, au box-office, ils refusent d'accepter les jetons et vous avez décidé de tenter votre chance. Il y a beaucoup de machines à sous dans la salle que vous pouvez jouer. Pour un jeu avec une machine à sous, vous utilisez un jeton. En cas de victoire, la machine vous donne un dollar, en cas de perte - rien. Chaque machine a une probabilité fixe de gagner (que vous ne connaissez pas), mais elle est différente pour différentes machines. Après avoir étudié le site Web du fabricant de ces machines, vous avez découvert que la probabilité de gagner pour chaque machine est sélectionnée au hasard au stade de la fabrication à partir de la
distribution bêta avec certains paramètres.
Vous souhaitez maximiser vos gains attendus.
Formats d'E / S et exempleFormat d'entrée
Une exécution peut consister en plusieurs tests.
Chaque test commence par le fait que votre programme sur la ligne contient deux entiers séparés par un espace: le nombre N est le nombre de jetons dans votre sac, et M est le nombre de machines dans le hall (N ≤ 10
4 , M ≤ min (N, 100) ) La ligne suivante contient deux nombres réels α et β (1 ≤ α, β ≤ 10) - les paramètres de la distribution bêta de la probabilité de gagner.
Le protocole de communication avec le système de contrôle est le suivant: vous faites exactement N requêtes. Pour chaque demande, imprimez sur une ligne séparée le numéro de la machine que vous jouerez (de 1 à M inclus). En réponse, sur une ligne séparée, il y aura soit «0» soit «1», ce qui signifie respectivement une défaite et une victoire dans un jeu avec la machine à sous demandée.
Après le dernier test, au lieu des nombres N et M, il y aura deux zéros.
Format de sortie
La tâche sera considérée comme terminée si votre décision n'est pas bien pire que la décision du jury. Si votre décision est nettement pire que la décision du jury, vous recevrez le verdict «mauvaise réponse».
Il est garanti que si votre décision n'est pas pire que la décision du jury, alors la probabilité de recevoir le verdict «mauvaise réponse» ne dépasse pas
10-6 .
Remarques
Exemple d'interaction:
____________________ stdin stdout ____________________ ____________________ 5 2 2 2 2 1 1 0 1 1 2 1 2 1
Solution
Ce problème est bien connu, il pourrait être résolu de différentes manières. La décision principale du jury a mis en œuvre la stratégie d'
échantillonnage de Thompson , mais comme le nombre d'étapes était connu au début du programme, il existe des stratégies plus optimales (par exemple, UCB1). De plus, on pourrait même s'en sortir avec la stratégie epsilon-greedy: avec une certaine probabilité ε jouer une machine aléatoire et avec une probabilité (1 - ε) jouer une machine avec les meilleures statistiques de victoire.
class SolverFromStdIn(object): def __init__(self): self.regrets = [0.] self.total_win = [0.] self.moves = [] class ThompsonSampling(SolverFromStdIn): def __init__(self, bandits_total, init_a=1, init_b=1): """ init_a (int): initial value of a in Beta(a, b). init_b (int): initial value of b in Beta(a, b). """ SolverFromStdIn.__init__(self) self.n = bandits_total self.alpha = init_a self.beta = init_b self._as = [init_a] * self.n
C. Alignement des peines
Condition
L'une des tâches les plus importantes pour former un bon modèle de traduction automatique est un bon cas de phrases parallèles. En règle générale, la source des offres parallèles est constituée de documents parallèles. Il s'avère que souvent pour construire un certain corpus de phrases parallèles, il n'est pas nécessaire de connaître autre chose que leur longueur. En particulier, vous remarquerez peut-être que plus la phrase est longue dans la langue source, plus elle sera traduite longtemps. Une certaine difficulté réside dans le fait que pendant la traduction, le nombre de phrases dans le texte peut changer: parfois deux phrases adjacentes dans la traduction peuvent être combinées en une seule, ou vice versa - une phrase peut être divisée en deux. Dans certains cas rares, des phrases peuvent être entièrement omises dans une traduction, ou une traduction peut apparaître dans une traduction qui n'était pas dans l'original.
Plus formellement, supposons que le modèle génératif suivant pour les enceintes parallèles soit vrai. À chaque étape, nous effectuons l'une des opérations suivantes:
1. ArrêtezAvec la probabilité p
h, la génération des coques se termine.
2. [1-0] Ignorer les offresAvec la probabilité p
d, nous attribuons une phrase au texte original. Nous n'attribuons rien à la traduction. La longueur de la phrase dans la langue d'origine L ≥ 1 est choisie dans la distribution discrète:
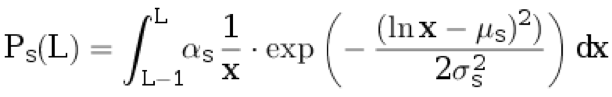
.
Ici
μ s ,
σ s sont les paramètres de distribution, et
α s est le coefficient de normalisation choisi pour que

.
3. [0-1] Insérer une propositionAvec la probabilité p
i nous attribuons une phrase à la traduction. Nous n'attribuons rien à l'original. La longueur d'une phrase dans une langue de traduction L ≥ 1 est choisie dans une distribution discrète:

.
Ici
μ t ,
σ t sont les paramètres de distribution, et
α t est le coefficient de normalisation choisi pour que

.
4. TraductionAvec la probabilité (1 - p
d - p
i - p
h ) on prend la longueur de la phrase dans la langue d'origine L
s ≥ 1 de la distribution p
s (avec arrondi). Ensuite, nous générons la longueur de la phrase dans la langue de traduction L
t ≥ 1 à partir de la distribution discrète conditionnelle:
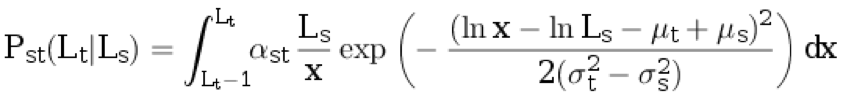
.
Ici,
α st est le coefficient de normalisation, et les paramètres restants sont décrits dans les paragraphes précédents.
La prochaine étape est une autre:
1. [2-1] Avec la probabilité p
divisé s, la phrase générée dans la langue d'origine se divise en deux phrases non vides, de sorte que le nombre total de mots
augmente exactement d'un . La probabilité qu'une phrase de longueur L
s se décompose en parties de longueur L
1 et L
2 (c'est-à-dire L
1 + L
2 = L
s + 1) est proportionnelle à P
s (L
1 ) ⋅ P
s (L
2 ).
2. [1-2] Avec la probabilité p
divisée t, la phrase générée dans la langue cible se divise en deux phrases non vides, de sorte que le nombre total de mots augmente d'exactement une. La probabilité qu'une phrase de longueur L
t se désagrège en parties de longueur L1 et L2 (c'est-à-dire L
1 + L
2 = L
t + 1) est proportionnelle à P
t (L
1 ) ⋅ P
t (L
2 ).
3. 3. [1-1] Avec une probabilité de (1 - p
split s - p
split t ), aucune des deux phrases générées ne se désintègre.
Formats d'E / S, exemples et notesFormat d'entrée
La première ligne du fichier contient les paramètres de distribution: p
h , p
d , p
i , p
split s , p
split t , μ
s , σ
s , μ
t , σ
t . 0,1 ≤ σ
s <σ
t ≤ 3. 0 ≤ μ
s , μ
t ≤ 5.
La ligne suivante contient les nombres N
s et N
t - le nombre de phrases dans le cas dans la langue d'origine et dans la langue cible, respectivement (1 ≤ N
s , N
t ≤ 1000).
La ligne suivante contient N
s entiers - la longueur des phrases dans la langue d'origine. La ligne suivante contient N
t entiers - la longueur des phrases dans la langue cible.
La ligne suivante contient deux nombres: j et k (1 ≤ j ≤ N
s , 1 ≤ k ≤ N
t ).
Format de sortie
Il est nécessaire de dériver la probabilité que les phrases d'indices j et k dans les textes, respectivement, soient parallèles (c'est-à-dire qu'elles sont générées à une étape de l'algorithme et qu'aucune d'entre elles n'est le résultat de la décroissance).
Votre réponse sera acceptée si l'erreur absolue ne dépasse pas 10
–4 .
Exemple 1
Exemple 2
Exemple 3
Remarques
Dans le premier exemple, la séquence initiale de nombres peut être obtenue de trois manières:
• D'abord, avec la probabilité p
d ajouter une phrase au texte original, puis avec la probabilité p
i ajouter une phrase à la traduction, puis avec la probabilité p
h terminer la génération.
La probabilité de cet événement est P
1 = p
d * P
s (4) * p
i * P
t (20) * p
h .
• D'abord, avec la probabilité p
d ajouter une phrase au texte original, puis avec la probabilité p
i ajouter une phrase à la traduction, puis avec la probabilité p
h terminer la génération.
La probabilité de cet événement est égale à P
2 = p
i * P
t (20) * p
d * P
s (4) * p
h .
• Avec probabilité (1 - p
h - p
d - p
i ) générer deux phrases, puis avec probabilité (1 - p
split s - p
split t ) tout laisser tel quel (c'est-à-dire, ne pas diviser l'original ou la traduction en deux phrases ) et après cela avec une probabilité p
h terminer la génération.
La probabilité de cet événement est

.
Par conséquent, la réponse est calculée comme suit:

.
Solution
La tâche est un cas particulier d'alignement utilisant des modèles de Markov cachés (alignement HMM). L'idée principale est que vous pouvez calculer la probabilité de générer une paire spécifique de documents en utilisant ce modèle et
l'algorithme de transfert : dans ce cas, l'état est une paire de préfixes de document. Par conséquent, la probabilité requise d'alignement d'une paire spécifique de phrases parallèles peut être calculée par l'algorithme
avant-arrière .
Code #include <iostream> #include <iomanip> #include <cmath> #include <vector> double p_h, p_d, p_i, p_tr, p_ss, p_st, mu_s, sigma_s, mu_t, sigma_t; double lognorm_cdf(double x, double mu, double sigma) { if (x < 1e-9) return 0.0; double res = std::log(x) - mu; res /= std::sqrt(2.0) * sigma; res = 0.5 * (1 + std::erf(res)); return res; } double length_probability(int l, double mu, double sigma) { return lognorm_cdf(l, mu, sigma) - lognorm_cdf(l - 1, mu, sigma); } double translation_probability(int ls, int lt) { double res = length_probability(ls, mu_s, sigma_s); double mu = mu_t - mu_s + std::log(ls); double sigma = std::sqrt(sigma_t * sigma_t - sigma_s * sigma_s); res *= length_probability(lt, mu, sigma); return res; } double split_probability(int l1, int l2, double mu, double sigma) { int l_sum = l1 + l2; double total_prob = 0.0; for (int i = 1; i < l_sum; ++i) { total_prob += length_probability(i, mu, sigma) * length_probability(l_sum - i, mu, sigma); } return length_probability(l1, mu, sigma) * length_probability(l2, mu, sigma) / total_prob; } double log_prob10(int ls) { return std::log(p_d * length_probability(ls, mu_s, sigma_s)); } double log_prob01(int lt) { return std::log(p_i * length_probability(lt, mu_t, sigma_t)); } double log_prob11(int ls, int lt) { return std::log(p_tr * (1 - p_ss - p_st) * translation_probability(ls, lt)); } double log_prob21(int ls1, int ls2, int lt) { return std::log(p_tr * p_ss * split_probability(ls1, ls2, mu_s, sigma_s) * translation_probability(ls1 + ls2 - 1, lt)); } double log_prob12(int ls, int lt1, int lt2) { return std::log(p_tr * p_st * split_probability(lt1, lt2, mu_t, sigma_t) * translation_probability(ls, lt1 + lt2 - 1)); } double logsum(double v1, double v2) { double res = std::max(v1, v2); v1 -= res; v2 -= res; v1 = std::min(v1, v2); if (v1 < -30) { return res; } return res + std::log(std::exp(v1) + 1.0); } double loginc(double* to, double from) { *to = logsum(*to, from); } constexpr double INF = 1e25; int main(void) { using std::cin; using std::cout; cin >> p_h >> p_d >> p_i >> p_ss >> p_st >> mu_s >> sigma_s >> mu_t >> sigma_t; p_tr = 1.0 - p_h - p_d - p_i; int Ns, Nt; cin >> Ns >> Nt; using std::vector; vector<int> ls(Ns), lt(Nt); for (int i = 0; i < Ns; ++i) cin >> ls[i]; for (int i = 0; i < Nt; ++i) cin >> lt[i]; vector< vector< double> > fwd(Ns + 1, vector<double>(Nt + 1, -INF)), bwd = fwd; fwd[0][0] = 0; bwd[Ns][Nt] = 0; for (int i = 0; i <= Ns; ++i) { for (int j = 0; j <= Nt; ++j) { if (i >= 1) { loginc(&fwd[i][j], fwd[i - 1][j] + log_prob10(ls[i - 1])); loginc(&bwd[Ns - i][Nt - j], bwd[Ns - i + 1][Nt - j] + log_prob10(ls[Ns - i])); } if (j >= 1) { loginc(&fwd[i][j], fwd[i][j - 1] + log_prob01(lt[j - 1])); loginc(&bwd[Ns - i][Nt - j], bwd[Ns - i][Nt - j + 1] + log_prob01(lt[Nt - j])); } if (i >= 1 && j >= 1) { loginc(&fwd[i][j], fwd[i - 1][j - 1] + log_prob11(ls[i - 1], lt[j - 1])); loginc(&bwd[Ns - i][Nt - j], bwd[Ns - i + 1][Nt - j + 1] + log_prob11(ls[Ns - i], lt[Nt - j])); } if (i >= 2 && j >= 1) { loginc(&fwd[i][j], fwd[i - 2][j - 1] + log_prob21(ls[i - 1], ls[i - 2], lt[j - 1])); loginc(&bwd[Ns - i][Nt - j], bwd[Ns - i + 2][Nt - j + 1] + log_prob21(ls[Ns - i], ls[Ns - i + 1], lt[Nt - j])); } if (i >= 1 && j >= 2) { loginc(&fwd[i][j], fwd[i - 1][j - 2] + log_prob12(ls[i - 1], lt[j - 1], lt[j - 2])); loginc(&bwd[Ns - i][Nt - j], bwd[Ns - i + 1][Nt - j + 2] + log_prob12(ls[Ns - i], lt[Nt - j], lt[Nt - j + 1])); } } } int j, k; cin >> j >> k; double rlog = fwd[j - 1][k - 1] + bwd[j][k] + log_prob11(ls[j - 1], lt[k - 1]) - bwd[0][0]; cout << std::fixed << std::setprecision(12) << std::exp(rlog) << std::endl; }
D. Bande de recommandations
Condition
Considérez un flux de recommandations pour le contenu hétérogène. Il mélange des objets de différents types (photos, vidéos, actualités, etc.). Ces objets sont généralement classés par pertinence pour l'utilisateur: plus l'objet est pertinent (intéressant) pour l'utilisateur, plus il se trouve en haut de la liste des recommandations. Cependant, avec un tel classement, des situations surviennent souvent dans lesquelles plusieurs objets du même type apparaissent dans la liste des recommandations. Cela aggrave considérablement la variété externe de nos recommandations et les utilisateurs n'aiment donc pas. Il est nécessaire de mettre en œuvre un algorithme qui, selon la liste des recommandations, constituera une nouvelle liste qui sera exempte de ce problème et sera la plus pertinente.
Soit une liste initiale de recommandations donnée a = [a
0 , a
1 , ..., a
n - 1 ] de longueur n> 0. Un objet avec le nombre i a le type avec le nombre b
i ∈ {0, ..., m - 1}. De plus, un objet sous le numéro i a une pertinence r (a
i ) = 2
−i . Considérons la liste obtenue à partir de l'initial en choisissant un sous-ensemble d'objets et en les réarrangeant: x = [a
i 0 , a
i 1 , ..., a
i k - 1 ] de longueur k (0 ≤ k ≤ n). Une liste est dite admissible si deux objets consécutifs ne coïncident pas en type, c'est-à-dire b
i j ≠ b
i j + 1 pour tout j = 0, ..., k - 2. La pertinence de la liste est calculée par la formule
. Vous devez trouver la liste de pertinence maximale parmi toutes les valides.
Formats d'E / S et exemplesFormat d'entrée
Sur la première ligne, les nombres n et m s'écrivent avec un espace (1 ≤ n ≤ 100000, 1 ≤ m ≤ n). Les n lignes suivantes contiennent les nombres b
i pour i = 0, ..., n - 1 (0 ≤ b
i ≤ m - 1).
Format de sortie
Notez, avec un espace, le nombre d'objets dans la liste finale: i
0 , i
1 , ..., i
k - 1 .
Exemple 1
Exemple 2
Exemple 3
Solution
À l'aide de calculs mathématiques simples, on peut montrer que le problème peut être résolu par une approche «gourmande», c'est-à-dire que dans la liste optimale de recommandations, chaque élément a l'objet le plus pertinent de tous qui sont valides au même début de la liste. La mise en œuvre de cette approche est simple: nous prenons des objets dans une rangée et les ajoutons à la réponse, si possible. Lorsqu'un objet invalide est rencontré (dont le type coïncide avec le type du précédent), nous le mettons de côté dans une file d'attente séparée, à partir de laquelle nous l'insérons dans la réponse dès que possible. Notez qu'à chaque instant, tous les objets de cette file d'attente auront un type correspondant. À la fin, plusieurs objets peuvent rester dans la file d'attente, ils ne seront plus inclus dans la réponse.
std::vector<int> blend(int n, int m, const std::vector<int>& types) { std::vector<int> result; std::queue<int> repeated; for (int i = 0; i < n; ++i) { if (result.empty() || types[result.back()] != types[i]) { result.push_back(i); if (!repeated.empty() && types[repeated.front()] != types[result.back()]) { result.push_back(repeated.front()); repeated.pop(); } } else { repeated.push(i); } } return result; }
D. Clusterisation des séquences de caractères
Il y a un alphabet fini A = {a
1 , a
2 , ..., a
K - 1 , a
K = S}, a
i ∈ {a, b, ..., z}, S est la fin de la ligne.
Considérez la méthode suivante pour générer des chaînes aléatoires sur l'alphabet A:
1. Le premier caractère x
1 est une variable aléatoire de distribution P (x
1 = a
i ) = q
i (on sait que q
K = 0).
2. Chaque caractère suivant est généré sur la base du précédent conformément à la distribution conditionnelle P (x
i = a
j || x
i - 1 = a
l ) = p
jl .
3. Si x
i = S, la génération s'arrête et le résultat est x
1 x
2 ... x
i - 1 .
L'ensemble des lignes générées à partir d'un mélange de deux modèles décrits avec des paramètres différents est donné. Il est nécessaire que chaque ligne donne l'index de la chaîne à partir de laquelle elle a été générée.
Formats d'E / S, exemple et notesFormat d'entrée
La première ligne contient deux nombres 1000 ≤ N ≤ 2000 et 3 ≤ K ≤ 27 - le nombre de lignes et la taille de l'alphabet, respectivement.
La deuxième ligne contient une ligne composée de K - 1 lettres minuscules différentes de l 'alphabet latin, indiquant les premiers K - 1 éléments de l' alphabet.
Chacune des N lignes suivantes est générée selon l'algorithme décrit dans la condition.
Format de sortie
N lignes, la i-ème ligne contient le numéro de cluster (0/1) pour la séquence sur la i + 1-ème ligne du fichier d'entrée. La coïncidence avec la vraie réponse doit être d'au moins 80%.
Exemple
Remarques
Note au test de la condition: en elle les 50 premières lignes sont générées à partir de la distribution
P (x
i = a | x
i - 1 = a) = 0,5, P (x
i = S | x
i - 1 = a) = 0,5, P (x
1 = a) = 1; deuxième 50 - de la distribution
P (x
i = b | x
i - 1 = b) = 0,5, P (x
i = S | x
i - 1 = b) = 0,5, P (x
1 = b) = 1.
Solution
Le problème est résolu en utilisant l'
algorithme EM : on suppose que l'échantillon présenté est généré à partir d'un mélange de deux chaînes de Markov dont les paramètres sont restaurés au cours des itérations. Une restriction de 80% des bonnes réponses est faite afin que l'exactitude de la solution ne soit pas affectée par les exemples qui ont une forte probabilité dans les deux chaînes. Par conséquent, lorsqu'ils sont correctement restaurés, ces exemples peuvent être affectés à une chaîne incorrecte en termes de réponse générée.
import random import math EPS = 1e-9 def empty_row(size): return [0] * size def empty_matrix(rows, cols): return [empty_row(cols) for _ in range(rows)] def normalized_row(row): row_sum = sum(row) + EPS return [x / row_sum for x in row] def normalized_matrix(mtx): return [normalized_row(r) for r in mtx] def restore_params(alphabet, string_samples): n_tokens = len(alphabet) n_samples = len(string_samples) samples = [tuple([alphabet.index(token) for token in s] + [n_tokens - 1, n_tokens - 1]) for s in string_samples] probs = [random.random() for _ in range(n_samples)] for _ in range(200): old_probs = [x for x in probs]
.