Comme vous le savez, les index jouent un rôle important dans le SGBD, fournissant une recherche rapide des enregistrements nécessaires. Par conséquent, il est si important de les entretenir en temps opportun. De nombreux documents ont été écrits sur l'analyse et l'optimisation, y compris sur Internet. Par exemple, une revue récente de ce sujet a été faite dans
cette publication .
Il existe de nombreuses solutions payantes et gratuites pour cela. Par exemple, il existe une
solution clé en main basée sur une méthode d'optimisation adaptative d'index.
Ensuite, considérez l'utilitaire gratuit
SQLIndexManager , créé par
AlanDenton .
La principale différence technique entre SQLIndexManager et un certain nombre d'autres analogues est faite par l'auteur lui-même
ici et
ici .
Dans le même article, nous examinons le projet et les possibilités d'utilisation de cette solution logicielle.
Discutez de cet utilitaire
ici .
Au fil du temps, la plupart des commentaires et bogues ont été corrigés.
Passons maintenant à l'utilitaire SQLIndexManager lui-même.
L'application est écrite en C # .NET Framework 4.5 dans Visual Studio 2017 et utilise DevExpress pour les formulaires:
et ressemble à ceci:
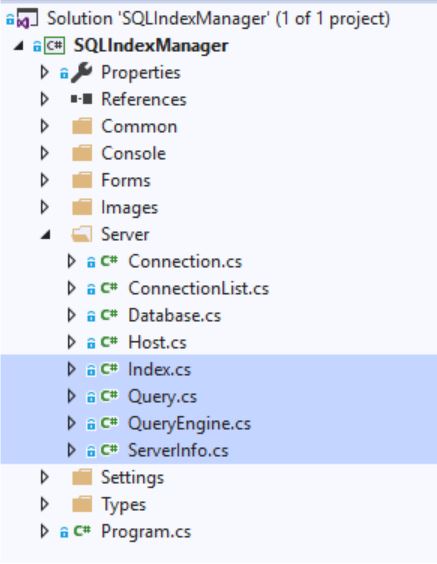
Toutes les demandes sont générées dans les fichiers suivants:
- Index
- Requête
- Queryengine
- ServerInfo
Lors de la connexion à la base de données et de l'envoi de demandes au SGBD, l'application est signée comme suit:
ApplicationName=”SQLIndexManager”
Lorsque l'application démarre, une fenêtre modale s'ouvre pour ajouter une connexion:
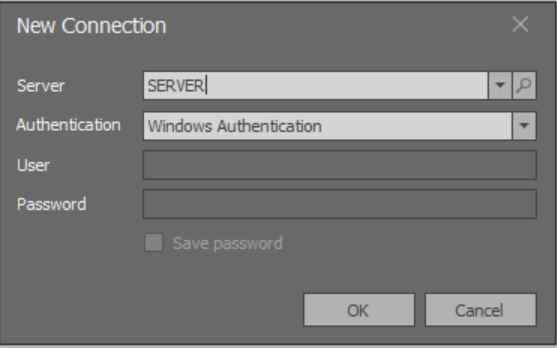
Ici, le chargement de la liste complète de toutes les instances de MS SQL Server disponibles sur les réseaux locaux ne fonctionne pas encore.
Vous pouvez également ajouter une connexion en utilisant le bouton le plus à gauche du menu principal:
Ensuite, les requêtes SGBD suivantes seront lancées:
Obtention d'informations sur le SGBD SELECT ProductLevel = SERVERPROPERTY('ProductLevel') , Edition = SERVERPROPERTY('Edition') , ServerVersion = SERVERPROPERTY('ProductVersion') , IsSysAdmin = CAST(IS_SRVROLEMEMBER('sysadmin') AS BIT)
Obtenir une liste des bases de données disponibles avec leurs brèves propriétés SELECT DatabaseName = t.[name] , d.DataSize , DataUsedSize = CAST(NULL AS BIGINT) , d.LogSize , LogUsedSize = CAST(NULL AS BIGINT) , RecoveryModel = t.recovery_model_desc , LogReuseWait = t.log_reuse_wait_desc FROM sys.databases t WITH(NOLOCK) LEFT JOIN ( SELECT [database_id] , DataSize = SUM(CASE WHEN [type] = 0 THEN CAST(size AS BIGINT) END) , LogSize = SUM(CASE WHEN [type] = 1 THEN CAST(size AS BIGINT) END) FROM sys.master_files WITH(NOLOCK) GROUP BY [database_id] ) d ON d.[database_id] = t.[database_id] WHERE t.[state] = 0 AND t.[database_id] != 2 AND ISNULL(HAS_DBACCESS(t.[name]), 1) = 1
Après avoir exécuté les scripts ci-dessus, une fenêtre apparaît contenant de brèves informations sur les bases de données de l'instance sélectionnée de MS SQL Server:
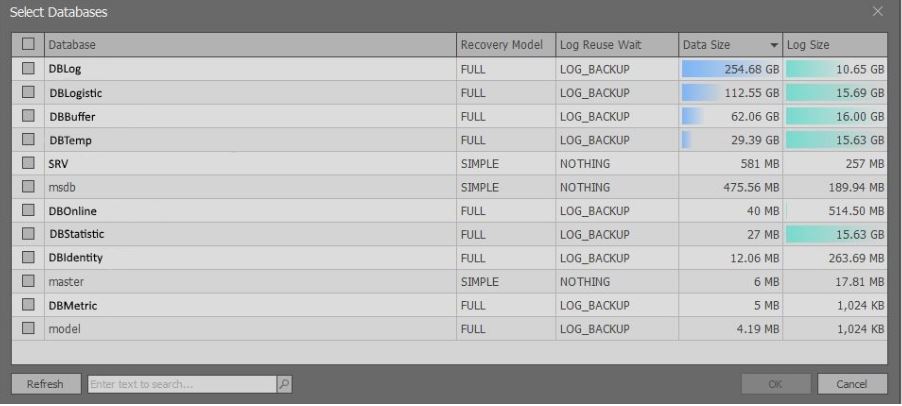
Il convient de noter que des informations étendues sont affichées en fonction des droits. S'il existe un
administrateur système , vous pouvez sélectionner des données dans la
vue sys.master_files . S'il n'y a pas de tels droits, moins de données sont renvoyées afin de ne pas ralentir la demande.
Ici, vous devez sélectionner la base de données d'intérêt et cliquer sur le bouton "OK".
Ensuite, le script suivant sera exécuté pour chaque base de données sélectionnée pour analyser l'état des index:
Analyse de l'état de l'index declare @Fragmentation float=15; declare @MinIndexSize bigint=768; declare @MaxIndexSize bigint=1048576; declare @PreDescribeSize bigint=32768; SET NOCOUNT ON SET ARITHABORT ON SET NUMERIC_ROUNDABORT OFF IF OBJECT_ID('tempdb.dbo.#AllocationUnits') IS NOT NULL DROP TABLE
Comme vous pouvez le voir dans les requêtes elles-mêmes, des tables temporaires sont souvent utilisées. Ceci est fait de manière à ce qu'il n'y ait pas de recompilation, et dans le cas d'un grand schéma, le plan pourrait être généré en parallèle lors de l'insertion de données, car l'insertion avec des variables de table n'est possible que dans un seul flux.
Après avoir exécuté le script ci-dessus, une fenêtre avec la table d'index apparaîtra:

Ici, vous pouvez également afficher d'autres informations détaillées, telles que:
- une base de données
- nombre de sections
- date et heure du dernier appel
- compression
- groupe de fichiers
etc.
Les colonnes elles-mêmes peuvent être personnalisées:
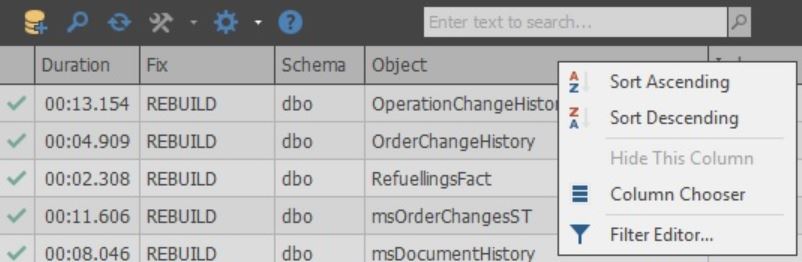
Dans les cellules de la colonne Fix, vous pouvez choisir quelle action sera effectuée lors de l'optimisation. De plus, une fois la numérisation terminée, l'action par défaut est sélectionnée en fonction des paramètres sélectionnés:
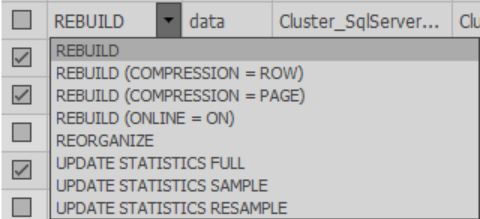
Vous devez sélectionner les index souhaités pour le traitement.
En utilisant le menu principal, vous pouvez enregistrer le script (le même bouton démarre le processus d'optimisation d'index lui-même):
enregistrer le tableau dans différents formats (le même bouton vous permet d'ouvrir des paramètres détaillés pour l'analyse et l'optimisation des indices):

De plus, les informations peuvent être mises à jour en cliquant sur le troisième bouton à gauche dans le menu principal à côté de la loupe.
Un bouton avec une loupe vous permet de sélectionner la base de données souhaitée pour examen.
Il n'existe actuellement aucun système d'aide complet. Par conséquent, en appuyant sur le "?" cela provoquera simplement l'apparition d'une fenêtre modale contenant des informations de base sur le produit logiciel:
En plus de tout ce qui précède, le menu principal dispose d'une barre de recherche:

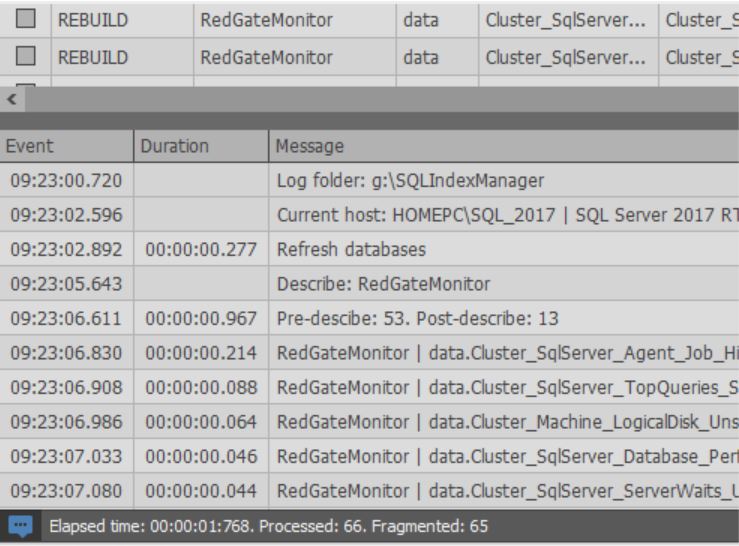
Lors du démarrage du processus d'optimisation d'index:

Toujours en bas de la fenêtre, vous pouvez voir le journal des actions effectuées:
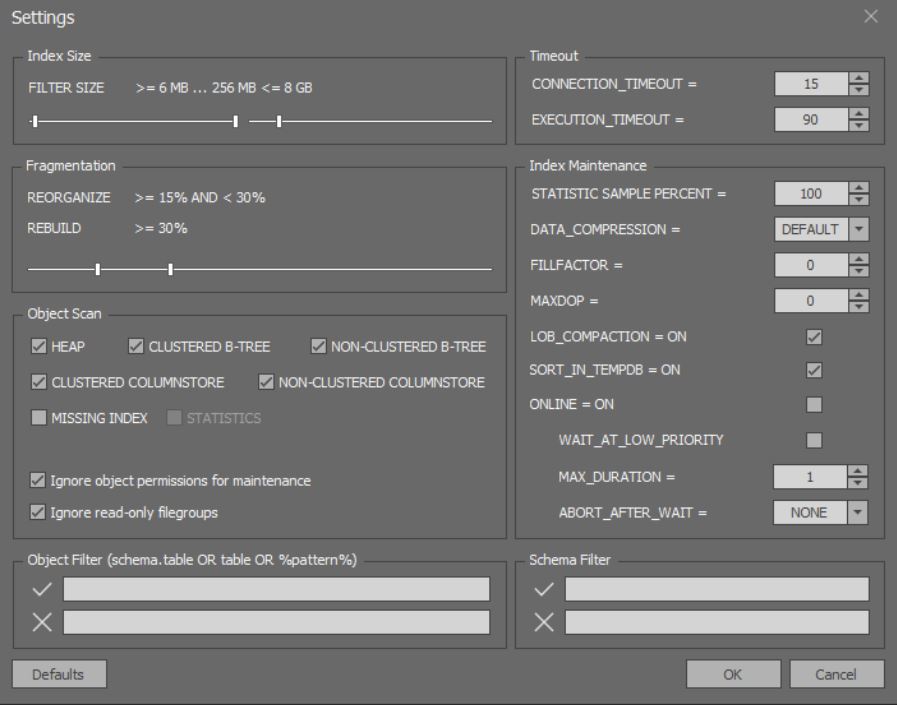
Dans la fenêtre d'analyse détaillée et d'optimisation des index, vous pouvez configurer des options plus subtiles:
 Suggestions pour l'application:
Suggestions pour l'application:- permettre la mise à jour sélective des statistiques non seulement pour les index mais également de différentes manières (mise à jour complète ou partielle)
- permettent non seulement de sélectionner la base de données, mais aussi différents serveurs (c'est très pratique quand il y a beaucoup d'instances de MS SQL Server)
- pour une plus grande flexibilité d'utilisation, il est proposé d'envelopper les commandes dans les bibliothèques et de les exporter vers les commandes PowerShell, comme cela se fait, par exemple, ici: dbatools.io/commands
- permettent d'enregistrer et de modifier les paramètres personnels à la fois pour l'ensemble de l'application et, si nécessaire, pour chaque instance de MS SQL Server et chaque base de données
- des clauses 2 et 4, il découle de la volonté de faire des groupes sur les bases de données et des groupes sur les instances de MS SQL Server, pour lesquels les paramètres sont les mêmes
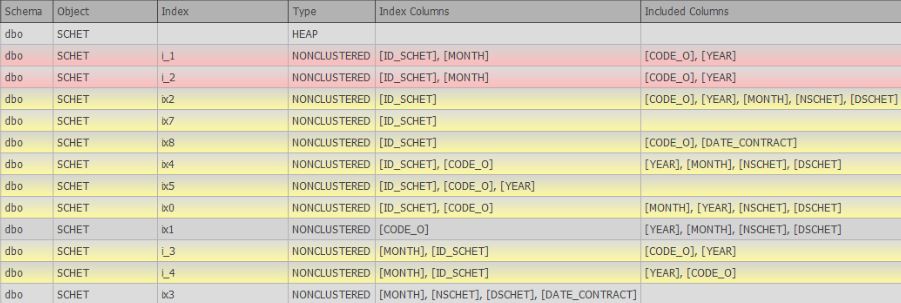
- rechercher des indices en double (complets et incomplets, qui diffèrent légèrement ou ne diffèrent que dans les colonnes incluses)
- Étant donné que SQLIndexManager est utilisé uniquement pour le SGBD MS SQL Server, vous devez refléter cela dans le nom, par exemple, comme suit: SQLIndexManager pour MS SQL Server
- Supprimez toutes les parties de l'application de l'interface graphique dans des modules séparés et réécrivez-les dans .NET Core 2.1
Au moment de la rédaction de cet article, l'article 6 des souhaits est en cours d'élaboration et il existe déjà un soutien sous la forme d'une recherche de doublons complets et similaires:
Les sources