L'article fournit du code pour générer des rapports réguliers sur l'état des disques de stockage EMC VNX avec des approches alternatives et un historique de création.
J'ai essayé d'écrire du code avec les commentaires les plus détaillés et un fichier. Remplacez uniquement vos mots de passe. Le format des données source est également indiqué, je serai donc heureux si quelqu'un essaie de les appliquer à la maison.
Contexte
Vous pouvez sauter si ce n'est pas intéressant d'où viennent les "jambes".
Nous avons un centre de données. Il n'y a pas de systèmes de stockage très récents. Il existe de nombreux systèmes de stockage, des pannes de disque aussi. Plusieurs fois par semaine, des personnes se rendent au centre de données et changent de lecteur dans le système de stockage. La décision de remplacer les disques est prise après une alarme du système " Remplacement de disque recommandé ".
Rien d'extraordinaire.

Mais récemment, les LUN individuels collectés sur ces systèmes de stockage et présentés à l'environnement virtuel ont commencé à se dégrader sérieusement. Après avoir discuté avec le support technique du fournisseur, il est devenu clair que les disques doivent déjà être changés non seulement lorsque le message d'alarme ci-dessus apparaît, mais également lorsqu'un grand nombre d'autres messages apparaissent que le système ne prend pas en compte les erreurs critiques.
La surveillance SNMP par ces systèmes de stockage n'est pas prise en charge. Vous devez utiliser soit un logiciel propriétaire coûteux (nous ne l'avons pas), soit l' utilitaire de console NaviSECCli , qui doit être connecté à chaque contrôleur (il y en a deux) de chaque système de stockage, mais ce n'était pas très souhaitable.
Il a été décidé d'automatiser la collecte des journaux et de rechercher des erreurs dans ceux-ci. Et la décision de remplacer les disques devrait être laissée aux ingénieurs responsables sur la base des résultats de l'analyse du rapport.
Premiers pas
Initialement, un de mes collègues a écrit du code PowerShell qui faisait ce qui suit:
- A pris une table d'entrée qui contenait les adresses IP des contrôleurs de stockage;
- le cycle est allé aux adresses ip des contrôleurs A , puis aux adresses ip des contrôleurs B ;
- au cours du processus, ils les ont également interrogés pour connaître les numéros de série des disques;
- traité toutes les lignes des journaux et filtré pour le contenu des messages recherchés;
- créé un objet PowerShell et analysé dans ses propriétés les données nécessaires à partir des lignes obtenues ci-dessus;
- fusionné tous les objets résultants dans une table qui a été émise sous forme de csv.
Le code est ci-dessous. Faites immédiatement une réservation qu'il travaille, mais nous avons introduit une solution alternative.
Source PowerShellcd 'd:\Navisphere CLI\' $csv = "D:\VNX-IP.csv" $Filter1 = "name1" $Filter2 = "name2" $Filter3 = "name3" $Data = import-csv $csv -Delimiter ';' | Where {$_.cl -EQ $Filter1 -Or $_.cl -EQ $Filter2 -Or $_.cl -EQ $Filter3} | Sort-Object -Property @{Expression={$_.cl}; Ascending=$true}, @{Expression={$_.Name} ;Ascending=$true} #$Filter1 = "nameOfcl" #$Data = import-csv $csv -Delimiter ';' | Where {$_.Name -EQ $Filter1} $Data | select Name,IP,cl $yStart = (Get-Date).AddDays(-30).ToString('yyyy') $yEnd = (Get-Date).ToString('yyyy') $mStart = (Get-Date).AddDays(-30).ToString('MM') $mEnd = (Get-Date).ToString('MM') $dStart = (Get-Date).AddDays(-30).ToString('dd') $dEnd = (Get-Date).ToString('dd') #$start = (Get-Date).AddDays(-3).ToString('MM\/dd\/yy') #$end = (Get-Date).ToString('MM\/dd\/yy') $i = 1 $table = ForEach ($row in $Data) { Write-Host $row.Name -ForegroundColor "Yellow" Write-Host "SP A" Write-Host (Get-Date).ToString('HH:mm:ss') $txt = .\NaviSECCli.exe -scope 0 -h $row.newA -user myusername -password mypassword getlog -date $mStart/$dStart/$yStart $mEnd/$dEnd/$yEnd | Select-String -Pattern "\(820\)","\(803\)","\(801\)","\(920\)","\(901\)" ForEach ($n in $txt) { $x = $n -Split(' ') $disk = $x[3] + "_" + $x[5] + "_" + $x[7].Split("(")[0] $sn = (.\NaviSECCli.exe -scope 0 -h $row.newA -user myusername -password mypassword getdisk $disk -serial)[1] | %{$_ -replace "Serial Number: ",""} | %{$_ -replace "State: ",""} | %{$_ -replace " ",""} New-Object PSObject -Property @{ i = $i cl = $row.cl Storage = $row.Name SP = "A" Date = $x[0] Time = $x[1] Disk = $disk Error = (($n -Split('\['))[0] -Split('\)'))[1].Trim() eCode = (($n -Split('\('))[1] -Split('\)'))[0] SN = $sn } $i = $i + 1 } Write-Host "SP B" Write-Host (Get-Date).ToString('HH:mm:ss') $txt = .\NaviSECCli.exe -scope 0 -h $row.newB -user myusername -password mypassword getlog -date $mStart/$dStart/$yStart $mEnd/$dEnd/$yEnd | Select-String -Pattern "\(820\)","\(803\)","\(801\)","\(920\)","\(901\)" ForEach ($n in $txt) { $x = $n -Split(' ') $disk = $x[3] + "_" + $x[5] + "_" + $x[7].Split("(")[0] $sn = (.\NaviSECCli.exe -scope 0 -h $row.newA -user myusername -password mypassword getdisk $disk -serial)[1] | %{$_ -replace "Serial Number: ",""} | %{$_ -replace "State: ",""} | %{$_ -replace " ",""} New-Object PSObject -Property @{ i = $i cl = $row.cl Storage = $row.Name SP = "B" Date = $x[0] Time = $x[1] Disk = $disk Error = (($n -Split('\['))[0] -Split('\)'))[1].Trim() eCode = (($n -Split('\('))[1] -Split('\)'))[0] SN = $sn } $i = $i + 1 } Write-Host " " } $table | select i,cl,Storage,SP,Date,Time,Disk,Error,eCode,SN | Export-Csv -Path 'd:\VNX-Errors.csv' -NoTypeInformation -UseCulture -Encoding UTF8
Tout allait bien, il ne restait plus qu'à ajouter un «gloss» sous la forme d'un envoi automatique d'une lettre aux collègues intéressés et d'une mise en forme minimale du csv obtenu. Mais (!) Tous ces problèmes ont fonctionné pendant très longtemps. Les données d'un mois, par exemple, ont été collectées environ 45 minutes , ce qui n'était pas très approprié, car en plus des rapports réguliers, je voulais faire une analyse pour l'année en cours, et ce serait très long. Mais "rejeter - offrir". Ils ont commencé à réfléchir.

De toute évidence, vous devez optimiser le code et activer le calcul parallèle. Dans PowerShell , nous n'avons pas réussi à utiliser plus de 5 threads simultanés à l'aide du workflow et nous n'avons pas encore "fumé" d'autres méthodes. Il a donc été décidé d'essayer de déplacer la logique du script vers R. L'utilitaire NaviSECCli , qui peut être exécuté sous R , effectue l'étude du stockage dans le code source, donc la solution est tout à fait appropriée.
On dit - quelques jours - c'est fait!
Nous avons décidé qu'à la sortie, j'aimerais recevoir une newsletter quotidienne contenant le nombre total d'erreurs dans le texte de la lettre, une sorte de calendrier pour le nombre d'accidents (afin qu'il y ait quelque chose à montrer à la direction), ainsi qu'une pièce jointe sous la forme d'un tableau xlsx. Nous avons déterminé que dans le tableau, je veux avoir 3 onglets:
- Données sur les accidents pendant 3 jours par disque et type d'accident
- Un onglet similaire, mais pendant 30 jours
- Données brutes (si quelqu'un veut les exécuter lui-même dans Excel)
Algorithme de script
1. Téléchargez depuis csv les données disponibles sur les contrôleurs;
2. exécuter en parallèle le calcul d'un cycle pour tous les contrôleurs avec une recherche d'enregistrements des messages d'alarme requis;
3. combiner les résultats dans un bloc de données;
4. faire le traitement et la conversion des données;
5. générer un document xlsx;
6. nous formons le programme que nous enregistrons en png;
7. former une lettre contenant les données collectées;
8. envoyez une lettre.
Passons en revue les points de l'algorithme
1. Téléchargez les données disponibles sur les contrôleurs depuis csv
Format de table source avec paramètres VNX Pour collecter des informations d'urgence, vous devez vous connecter en série aux deux contrôleurs ( colonnes newA et newB ) à l'aide d'un logiciel EMC spécialisé - NaviCLI avec certaines clés.
Pour plus de commodité, nous reformatons la table résultante après le chargement afin que les adresses IP des deux contrôleurs soient dans la même colonne, afin que vous puissiez effectuer un cycle dans la liste, et non deux consécutives. Nous le faisons en utilisant la fonction de collecte . Les problèmes de travailler avec des formats de données "verticaux" ou "horizontaux" sont très bien décrits dans la documentation officielle de la bibliothèque tidyverse . Vous pouvez le lire ici .
Nous lisons les données à l'aide de la fonction read_csv2 , nous déterminons également manuellement les types de colonnes via le paramètre supplémentaire col_types . Il s'agit d'une bonne pratique, car accélère considérablement le chargement. Dans notre cas, ce n'est pas si important, car Le csv d'origine contient moins de 100 lignes, mais nous nous habituons à écrire correctement.
En sortie, nous obtenons une telle trame de données (les nouvelles colonnes sont cntName et cntIP ):
2-3. Nous effectuons des calculs parallèles un cycle pour tous les contrôleurs avec une recherche d'enregistrements des messages d'alarme requis. Combinez les résultats dans une trame de données
Le suivant est le plus intéressant. Informatique parallèle .
Dans R, il existe plusieurs (plutôt, même plusieurs) options pour le calcul parallèle. J'ai plus aimé le lien des bibliothèques foreach et doParallel . Vous pouvez lire à leur sujet et d'autres options de calcul parallèle dans R ici .
En bref, nous prenons seulement 3 étapes :
Étape 1 Enregistrer les noyaux émeraude pure CPU pour travailler en informatique parallèle via registerDoParallel (dans notre cas, nous détectons d'abord le nombre de cœurs en cas)
Enregistrer les cœurs de processeur numCores <- detectCores() registerDoParallel(numCores)
Étape 2 Nous commençons le cycle par foreach (n'oubliez pas de spécifier l'opérateur % dopar% pour que le cycle se déroule en parallèle et d'indiquer, via le paramètre .combine, la manière dont nous allons collecter le résultat). Dans notre cas .combine = rbind , car à la sortie de chaque boucle, nous aurons une trame de données .
Code de récupération de table d'erreur Étape 3 Nous effaçons le cluster de parallélisme créé via stopImplicitCluster ()
Un peu plus de détails sur l'obtention d'un tableau lisible à partir d'un texte d'erreur brut
Sous forme de texte, les erreurs sont les suivantes:
head(errors_raw) [1] "07/13/2019 00:01:46 Bus 0 Enclosure 3 Disk 9(801) Soft SCSI Bus Error [0x00] 841d1080 10006 " [2] "07/13/2019 00:01:46 Bus 0 Enclosure 3 Disk 9(801) Soft SCSI Bus Error [0x00] 841e1a00 10006 " [3] "07/13/2019 00:01:46 Bus 0 Enclosure 3 Disk 9(801) Soft SCSI Bus Error [0x00] 8420b600 10006 " [4] "07/13/2019 00:01:46 Bus 0 Enclosure 3 Disk 9(801) Soft SCSI Bus Error [0x00] 84206900 10006 " [5] "07/13/2019 00:01:46 Bus 0 Enclosure 3 Disk 9(801) Soft SCSI Bus Error [0x00] 841fc900 10006 " [6] "07/13/2019 00:01:46 Bus 0 Enclosure 3 Disk 9(801) Soft SCSI Bus Error [0x00] 841fc000 10006
Ici, nous avons des valeurs séparées par un espace qui, à première vue, même en csv sera inséré normalement. Mais ce n'est pas si simple. La complexité de l'analyse ici est la suivante:
- la date et l'heure sont également séparées par un espace (le plus petit des maux);
- le texte d'erreur est constitué de "mots", c'est-à-dire également séparé par un espace;
- pour une raison quelconque, il n'y a pas d'espace entre le numéro de disque et le code d'erreur (qui est entre crochets).
En général, un paradis pour un amoureux des expressions régulières :)

Je ne m'attarderai pas sur l'analyse, car c'est une question de goût, mais je préciserai que le texte d'erreur devait être déchiré, car les valeurs situées entre la parenthèse fermante du numéro d'erreur et le crochet ouvrant d'une autre valeur. Dans une boucle, c'est la variable des erreurs .
Il est également intéressant de noter que, pour faciliter la création de la trame de données finale, nous, souhaitant parcourir les adresses IP des contrôleurs, définissons la séquence non pas via la colonne avec les adresses IP des contrôleurs (c'est-à-dire i = VNX_ip $ cntIP ), mais via le numéro de ligne (c'est-à-dire e. i = 1: nrow (VNX_ip) ). Cela nous permet, lors de la formation d'une trame de données avec des erreurs déjà analysées, d'ajouter le numéro de cluster et le nom de stockage via les appels VNX_ip $ cl [i] et VNX_ip $ Name [i] respectivement. Sans cela, des jointures devraient être faites, ce qui serait plus lent et pire à lire dans le code.
En fin de compte, nous obtenons une trame de données (pour être honnête, puis tibble , mais la différence dépasse la portée de l'article), qui contient toutes les données dont nous avons besoin. C'est-à-dire sur quel système de stockage, sur quel disque, quand quelle erreur s'est produite.
Vue finale Trame de données La chose la plus intelligente est que le cycle entier d'interrogation parallèle de tous les systèmes de stockage ne prend pas 30 minutes, mais 30 secondes .
Dieu merci, ce n'est pas le cas lorsque 30 secondes sont trop rapides.

Il convient de préciser que le code PowerShell a également collecté les numéros de série des disques de tous les systèmes de stockage dans un cycle, et au moment de la réécriture du code sur R, ces données étaient redondantes. La comparaison de l'exécution n'est donc pas tout à fait honnête, mais reste impressionnante.
La conversion des données pour les documents xlsx a été réduite au filtrage de la table source au cours des 3 derniers jours, ainsi qu'au mois dernier et à la conversion des colonnes avec les noms d'erreur au format "horizontal", de sorte que chaque type d'erreur se trouvait dans une colonne distincte. Une fonction distincte a été écrite pour cela (afin de ne pas dupliquer les mêmes étapes 2 fois)
Fonction de filtrage des sources myErrorStats <- function(data, period, orderColname = quo(Soft_Media_Error)) { data %>% filter(Date > period) %>% group_by(cl, Storage, Disk, Error) %>% summarise(count = n()) %>% spread(Error, count, fill = 0) %>% arrange(desc(!!orderColname)) }
Pour afficher les types d'erreurs dans une colonne distincte, la fonction d' étalement a été appliquée avec la clé supplémentaire fill = 0 , avec laquelle les valeurs manquantes ont été remplies avec 0 . Sans cette clé, s'il n'y avait pas un jour un certain type d'erreur, la colonne correspondante aurait des valeurs NA .
De plus, dans la fonction, je voulais garder la possibilité de passer le nom de la colonne pour le tri en tant que variable, mais en même temps avoir des valeurs par défaut pour cette variable. Pour cela, la syntaxe particulière dplyr est utilisée , dont vous pouvez lire plus ici .
Dans notre cas, lors de la définition des paramètres d'une fonction, nous mettons l'un d'entre eux à la valeur par défaut et le citons ( orderColname = quo (Soft_Media_Error) ), puis, lorsqu'il est appelé, nous mettons des caractères devant lui !! pour obtenir l' arrangement (desc (!! orderColname)) .
L'apparence du tableau avec des erreurs pour le mois J'ai analysé la formation du document xlsx dans l' article sur les rapports sur l'état de la VM , donc je ne m'attarderai pas sur les détails. Tout le code est donné à la fin de l'article.

Voici des fonctionnalités importantes qui améliorent la lisibilité du rapport:
- Onglets signés (par défaut le plus intéressant est ouvert);
- Noms de colonnes en surbrillance
- Mise en forme automatique de toutes les colonnes afin que tout le texte soit lisible sans avoir à développer les colonnes.
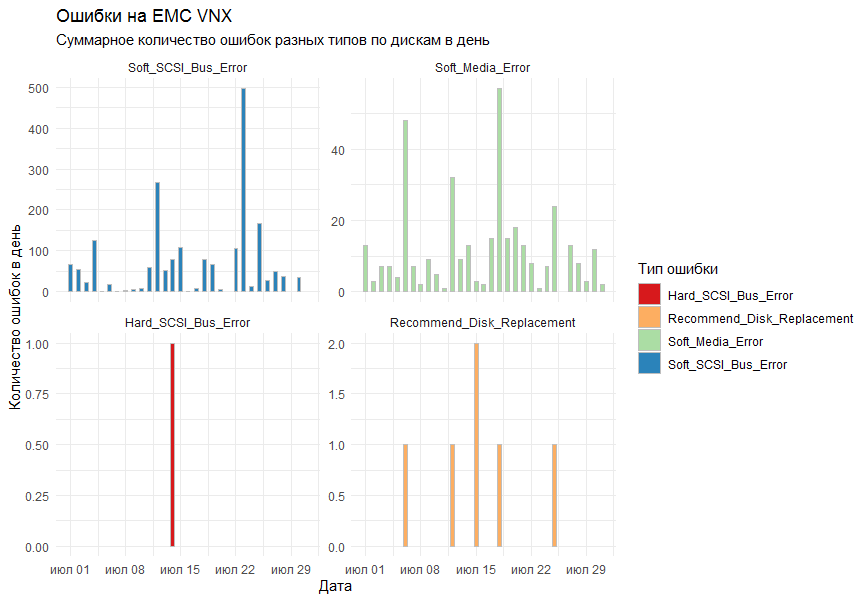
Sur le graphique, je voulais obtenir le nombre total d'erreurs par jour pour tous les systèmes de stockage par type. En tant qu'outil de dessin, il a été décidé d'utiliser la bibliothèque ggplot2 standard.
La première version du graphique montrait toutes les erreurs sur un graphique et ressemblait à ceci:

Des collègues ont déclaré que cela s'est avéré illisible.
Que comprendraient-ils? !!!!
Les remarques ont été prises en compte et la fonction facet_grid a été ajoutée aux colonnes standard ( geom_bar ) pour diviser le résultat en graphiques séparés par type d'erreur.
Le résultat final convenait à tout le monde.

Préparation des données, représentation graphique, enregistrement dans un fichier De l'intéressant dans la formation du calendrier.
Je voulais que les graphiques soient dans un certain ordre. Pour ce faire, le paramètre de formation de lignes dans facet_grid a dû être transféré en tant que facteur, ou plutôt même en tant que facteur ordonné . Le facteur est un format de données aussi astucieux dans R, qui est un ensemble de valeurs (dans notre cas, des chaînes, c'est-à-dire des caractères ), et l'ensemble de ces valeurs est strictement défini (appelé niveaux de facteur), et même ces niveaux sont triés. Cela semble compliqué, mais tout se met en place si vous dites que les noms des mois sont un excellent exemple d'un facteur ordonné. C'est-à-dire nous savons quels noms les mois peuvent avoir, et nous savons aussi (enfin, j'espère) que viennent d'abord janvier, puis février, puis mars, etc. C'est sur le même principe que nous créons un facteur.
La formation et l'envoi de lettres, ainsi que la formation de tâches dans le planificateur Windows ont également été examinées dans l'article sur les rapports sur l'état de la machine virtuelle . On met simplement quelques variables dans le texte et on le formate plus ou moins clairement. N'oubliez pas la pièce jointe.
La forme finale de la lettre Conclusions
R s'est de nouveau révélé être un outil universel pour effectuer les tâches quotidiennes et visualiser leurs résultats. Et avec le calcul parallèle activé, cet outil devient également rapide.
La pratique a également montré que PowerShell est extrêmement lent à analyser les journaux et à les traduire dans un format lisible.
Un grand merci à tous ceux qui ont lu tant de lettres jusqu'à la fin.
Code d'application complet
Code d'application Full R - : EMC VNX 5300
- : NaviCLI-Win-32-x86-en_US-7.31.25.1.29-1
- , : 4*2 CPU, 8 Gb RAM
R > sessionInfo() R version 3.5.3 (2019-03-11) Platform: x86_64-w64-mingw32/x64 (64-bit) Running under: Windows Server 2012 R2 x64 (build 9600) Matrix products: default locale: [1] LC_COLLATE=Russian_Russia.1251 LC_CTYPE=Russian_Russia.1251 LC_MONETARY=Russian_Russia.1251 [4] LC_NUMERIC=C LC_TIME=Russian_Russia.1251 attached base packages: [1] parallel stats graphics grDevices utils datasets methods base other attached packages: [1] taskscheduleR_1.4 pander_0.6.3 doParallel_1.0.14 iterators_1.0.10 foreach_1.4.4 mailR_0.4.1 [7] xlsx_0.6.1 stringi_1.4.3 zoo_1.8-6 lubridate_1.7.4 wesanderson_0.3.6 forcats_0.4.0 [13] stringr_1.4.0 dplyr_0.8.3 purrr_0.3.2 readr_1.3.1 tidyr_0.8.3 tibble_2.1.3 [19] ggplot2_3.2.0 tidyverse_1.2.1 loaded via a namespace (and not attached): [1] tidyselect_0.2.5 reshape2_1.4.3 rJava_0.9-11 haven_2.1.1 lattice_0.20-38 colorspace_1.4-1 [7] vctrs_0.2.0 generics_0.0.2 utf8_1.1.4 rlang_0.4.0 R.oo_1.22.0 pillar_1.4.2 [13] glue_1.3.1 withr_2.1.2 R.utils_2.9.0 RColorBrewer_1.1-2 modelr_0.1.4 readxl_1.3.1 [19] plyr_1.8.4 munsell_0.5.0 gtable_0.3.0 cellranger_1.1.0 rvest_0.3.4 R.methodsS3_1.7.1 [25] codetools_0.2-16 labeling_0.3 fansi_0.4.0 xlsxjars_0.6.1 broom_0.5.2 Rcpp_1.0.1 [31] scales_1.0.0 backports_1.1.4 jsonlite_1.6 digest_0.6.20 hms_0.5.0 grid_3.5.3 [37] cli_1.1.0 tools_3.5.3 magrittr_1.5 lazyeval_0.2.2 crayon_1.3.4 pkgconfig_2.0.2 [43] zeallot_0.1.0 data.table_1.12.2 xml2_1.2.0 assertthat_0.2.1 httr_1.4.0 rstudioapi_0.10 [49] R6_2.4.0 nlme_3.1-137 compiler_3.5.3