Bref article sur l'exploitation des processus métier dans le contexte d'un intérêt croissant pour le concept de «jumeau numérique». En raison de l'émergence périodique de ce sujet, je considère approprié de partager les approches de la solution.
Énoncé du problème
La situation est extrêmement simple.
- Il existe la société X (Y, Z, ...).
- L'entreprise a des processus d'affaires automatisés par divers systèmes informatiques.
- Il existe des analystes commerciaux qui ont dessiné des diagrammes bpmn pour ces processus. Plus précisément, leur propre «idée bpmn» de l'apparence de ces processus.
- Les utilisateurs professionnels veulent avoir une sorte de représentation (KPI) de ces processus.
Comment découvrir la vérité et compter ces métriques?
Il s'agit d'une continuation des publications précédentes .
Postulats de base:
- Il existe un journal des événements temporaire (divers journaux des systèmes informatiques, cdr \ xdr, juste des enregistrements d'événements dans la base de données) de différents degrés de pureté, d'exhaustivité et de cohérence.
- Les systèmes informatiques agissent comme une machine à états et «marchent» entre les différents états en fonction des actions des utilisateurs et de la logique métier définie par les programmeurs.
- L'interaction utilisateur est réalisée sous une forme transactionnelle.
Corrections du monde physique:
- Le nombre de modifications apportées au système informatique est tel que les diagrammes bpmn des analystes commerciaux n'ont presque rien à voir avec la réalité.
- Les données peuvent être très non structurées (par exemple, les journaux d'application).
- "Transactionnel" est un concept logique. Les enregistrements d'événements eux-mêmes ne contiennent que des attributs inhérents à cet état et il n'y a pas d'identifiant de transaction de bout en bout.
- Le nombre d'enregistrements par jour est de dizaines, centaines, milliers de millions de pièces .
Solution de décompte
Pour résoudre de tels problèmes, il est nécessaire:
- Reconstruire les transactions
- Reconstruire de vrais processus métier
- faire des calculs;
- générer des résultats dans un format lisible par l'homme.
Vous pouvez commencer à chercher des solutions de fournisseurs et payer des millions. Mais nous avons R. entre nos mains, cela nous permet parfaitement de résoudre ce problème. Brèves considérations ci-dessous.
Tout semble simple et R a un bon ensemble cohérent de paquets bupaR . Mais une mouche dans la pommade est présente et elle empoisonne tout. Cet ensemble dans un délai acceptable ne peut faire face qu'à un petit nombre d'événements (des centaines de milliers - plusieurs millions).
Pour les gros volumes, d'autres approches doivent être utilisées.
Ajoutez de la vitesse!
Émuler un jeu de données d'entrée
Pour démontrer des idées, il est nécessaire de former une sorte d'ensemble de données de test. Prenons un exemple de chaîne fédérale de magasins comme source physique d'un modèle mathématique. Heureusement, cela est compréhensible pour tout le monde. Bien qu'avec le même succès, il peut s'agir de distributeurs automatiques de billets, de centres d'appels, de transports publics, d'approvisionnement en eau, etc.
- Il y a des magasins de différentes tailles (petites, moyennes et grandes).
- Dans les magasins, il y a des caisses (terminaux POS).
- Les numéros des magasins peuvent être alphanumériques; les numéros des terminaux peuvent être numériques.
- Les acheteurs se rendent dans les magasins et achètent quelque chose tout en payant avec une carte.
- L'interaction du terminal pos avec la carte et la banque est décrite par un certain ensemble d'états et les règles de transition entre eux.
- Les transactions sont réussies, infructueuses, différées et incomplètes (la banque n'est pas disponible, par exemple).
- Les transactions ont des délais d'attente.
Prenez l'ensemble de modèles de transactions commerciales suivant:
"INIT-REQUEST-RESPONSE-SUCCESS" "INIT-REQUEST-RESPONSE-ERROR" "INIT-REQUEST-RESPONSE-DEFFERED" "INIT-REQUEST" "INIT"
Pour démontrer l'approche, nous allons créer un petit échantillon, mais tout fonctionne bien sur des milliards d'enregistrements (pour un tel volume sans optimisation superdeep, le temps caractéristique est mesuré en seulement quelques centaines de secondes sur un seul serveur aux performances très médiocres).
Spoilers directs pour les gros volumes:
- dans de nombreux endroits,
tidyverse signifie que tidyverse ne pouvez pas obtenir de réponse; - l'optimisation même des micropas est utile et peut apporter une contribution significative.
Exemple de code de simulation library(tidyverse) library(datapasta) library(tictoc) library(data.table) library(stringi) library(anytime) library(rTRNG) data.table::setDTthreads(0) # data.table data.table::getDTthreads() # set.seed(46572) RcppParallel::setThreadOptions(numThreads = parallel::detectCores() - 1) # -- -, # 5 -, 2 -- bo_pattern <- tibble::tribble( # , , ~pattern, ~prob, ~mean_duration, "INIT-REQUEST-RESPONSE-SUCCESS", 0.7, 5, "INIT-REQUEST-RESPONSE-ERROR", 0.15, 5, "INIT-REQUEST-RESPONSE-DEFFERED", 0.07, 8, "INIT-REQUEST", 0.05, 2, "INIT", 0.03, 0.5 ) # + checkmate::assertTRUE(sum(bo_pattern$prob) == 1) df <- bo_pattern %>% separate_rows(pattern) %>% # mutate(coeff = sum(prob)) %>% group_by(pattern) %>% # summarise(event_prob = sum(prob/coeff)*100) %>% ungroup() checkmate::assertTRUE(sum(df$event_prob) == 100) # 3 : (4 ), (12 ), (30 ) df1 <- tribble( ~type, ~n_pos, ~n_store, "small", 4, 10, "medium", 12, 5, "large", 30, 2 ) %>% # mutate(store = map2(row_number(), n_store, ~sample(x = .x * 1000 + 1:.y, size = .y, replace = FALSE))) %>% unnest(store) %>% # mutate(pos = map(n_pos, ~sample(x = .x, size = .x, replace = FALSE))) %>% unnest(pos) %>% mutate(pattern = sample(bo_pattern$pattern, n(), replace = TRUE, prob = bo_pattern$prob)) tic("Generate transactions") # , # , df2 <- df1 %>% # select(-matches("duration")) %>% left_join(bo_pattern, by = "pattern") %>% # sample_frac(size = 200, replace = TRUE) %>% mutate(duration = rnorm(n(), mean = mean_duration, sd = mean_duration * .25)) %>% select(-prob, -mean_duration) %>% # , > # 30 filter(duration > 0.5 & duration < 30) %>% # POS mutate(session_id = row_number()) %>% # , separate_rows(pattern) %>% rename(event = pattern) toc() tic("Generate time markers, data.table way") samples_tbl <- data.table::as.data.table(df2) %>% # setkey(session_id, duration, physical = FALSE) %>% # # 1- , , 5 # .[, ticks := base::sort(runif(.N, 5, 5 + duration)), by = .(session_id, duration)] %>% # match.arg base::order!! # # 0 1 # # .[, tshift := runif(.N, 0, 1)] %>% # trng ( ) # , .[, trand := runif_trng(.N, 0, 1, parallelGrain = 100L) * duration] %>% # , # .[, ticks := sort(tshift), by = .(session_id)] %>% # , session_id, , .[, t_idx := session_id + trand / max(trand)/10] %>% # # session_id . .[, tshift := (sort(t_idx) - session_id) * 10 * max(trand)] %>% # , POS (60 ) .[event == "INIT", tshift := tshift + runif_trng(.N, 0, 60, parallelGrain = 100L)] %>% # .[, `:=`(duration = NULL, trand = NULL, t_idx = NULL, n_store = NULL, n_pos = NULL, timestamp = as.numeric(anytime("2019-03-11 08:00:00 MSK")))] %>% # , 01.03.2019 .[, timestamp := timestamp + cumsum(tshift), by = .(store, pos)] %>% # .[timestamp <= as.numeric(anytime("2019-04-11 23:00:00 MSK")), ] %>% # .[, timestamp := anytime(timestamp, tz = "Europe/Moscow")] %>% as_tibble() %>% select(store, pos, event, timestamp, session_id) toc()
Pour la pureté de l'expérience, on ne laisse que les paramètres significatifs et on mélange le tout. Dans la vie réelle, il est toujours nécessaire de jeter au hasard une partie des fragments (éventuellement dans des blocs de temps séparés), émulant ainsi les pertes de réception des données.
# log_tbl <- samples_tbl %>% select(store, pos, state = event, timestamp_msk = timestamp) %>% sample_n(n()) # log_tbl %>% mutate(timegroup = lubridate::ceiling_date(timestamp_msk, unit = "10 mins")) %>% ggplot(aes(timegroup)) + # geom_bar(width = 0.7*600) + geom_bar(colour = "white", size = 1.3) + theme_bw()
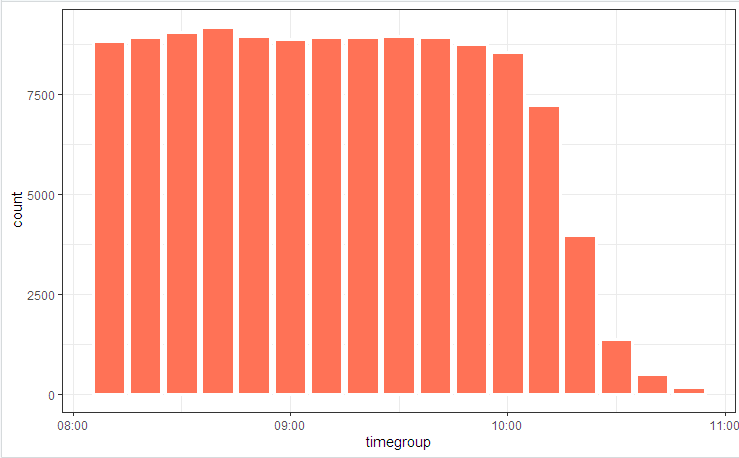
Nous illustrons le diagramme de processus avec une image

et la répartition des états

De légères fluctuations sont dues au fait que la table est considérée au début (elle est incluse dans le code), et bupaR::process_map fonctionné à la fin lorsque certaines des données générées aléatoirement qui ne correspondaient pas aux contraintes intégrales ont été coupées par des éléments de filtrage.
Reconstruction de transaction
La première chose qui est généralement offerte lorsque vous devez collecter / désassembler / comparer des séries chronologiques est les regroupements et les cycles de comparaison. Dans les démos avec 100 entrées, cette randonnée fonctionnera, mais pas des millions de listes. Pour faire face à cette tâche, vous devez localiser les points de perte de temps (boucles internes, allocations de mémoire intermédiaires et copie) et essayer de les éliminer au minimum.
Par conséquent, ce problème peut être réduit à dix lignes.
code de reconstruction de transaction clean_dt <- as.data.table(log_tbl) %>% # INIT .[, start := (state == "INIT")] %>% # session_id , # .[, event_date := lubridate::as_date(timestamp_msk)] %>% .[, date_str := format(.BY[[1]], "%y%m%d"), by = event_date] %>% # # timestamp_msk setorder(store, pos, timestamp_msk) %>% # -- .[, session_id := paste(date_str, store, pos, cumsum(start), sep = "_")] %>% # ( 30 ) # .[, time_shift := timestamp_msk - shift(timestamp_msk), by = .(store, pos)] %>% # , INIT .[, time_locf := cummax(as.numeric(timestamp_msk) * as.numeric(start)), by = .(store, pos)] %>% .[, time_shift := as.numeric(timestamp_msk) - time_locf] %>% # , 30 .[, lost_chain := time_shift > 30] %>% # .[, time_shift := as.numeric(!start) * as.numeric(timestamp_msk - shift(timestamp_msk, fill = 0))] %>% # INIT # .[, time_accu := cumsum(time_shift)] %>% .[, date_str := NULL] # # tidyverse , dt <- as.data.table(clean_dt) %>% # !!! .[lost_chain != TRUE] %>% # 1- .[order(timestamp_msk, store, pos)] %>% .[, bp_pattern := stri_join(state, collapse = "-"), by = session_id] # as_tibble(dt) %>% distinct(session_id, bp_pattern) %>% count(session_id, sort = TRUE)
En quelques secondes, nous avons une image reconstruite des processus métier.
Et (qui aurait pensé !!!) en fait, il s'avère que les processus métier automatisés dans les systèmes informatiques fonctionnent quelque peu différemment (ou pas du tout) comme les analystes commerciaux ont convaincu tout le monde. Les merveilles et arguments des «maîtres d'ouvrage» accompagneront l'étude du tableau final.
Appliquer activement des astuces
Lorsque la vitesse de calcul devient une quantité importante, l'écriture d'un code de travail ne suffit pas. Il faut faire attention à tous les niveaux. Il existe également un certain nombre d'astuces algorithmiques qui peuvent réduire considérablement le temps d'exécution.
En particulier, dans cette tâche, nous pouvons mentionner les éléments suivants:
- Pour le traitement principal, uniquement
data.table (vitesse, travail sur les liens) + prise en compte de l'optimisation interne des requêtes. POSIXct peut contenir des millisecondes (bien qu'il ne s'affiche pas normalement, mais peut être corrigé avec des options(digits.secs=X) ), nous les options(digits.secs=X) ici, il sera plus facile de comparer et de trier.- Évitez le tri physique à l'intérieur des groupes! Un seul tri physique de l'ensemble du vecteur assure le tri des données en groupes.
- Évitez l'informatique au sein des groupes. Nous essayons de faire tout ce qui est possible sur les données source (nous appliquons la vectorisation, réduisons les factures des appels de fonction).
- Nous utilisons un délai d'expiration de transaction pour traiter les écarts de temps.
- Les méthodes locf (Last Observation Carried Forward) sont lentes. Pour transférer des propriétés sur une chronologie, utilisez
cumsum , cummax . - Opérations longues, telles que POSIX -> conversion de chaînes, recherche régulière, etc. Nous ne le faisons pas élément par élément, mais sur des circonvolutions. Les frais généraux sur l'indexation interne et le regroupement du champ converti sont incomparablement plus petits.
- Nous utilisons activement le multithreading (y compris intra-paquet).
- Ne négligez pas la microoptimisation. Par exemple,
stri_c est plusieurs fois plus rapide que paste0 .
# 1 log <- getLog(fileName) bench::mark( paste0 = paste0(log$value, collapse = "\n"), stringi = stri_c(log$value, collapse = "\n") ) # # A tibble: 2 x 13 # expression min median `itr/sec` mem_alloc `gc/sec` n_itr n_gc total_time # <bch:expr> <bch:> <bch:> <dbl> <bch:byt> <dbl> <int> <dbl> <bch:tm> # 1 paste0 58ms 59.1ms 16.9 496KB 0 9 0 533ms # 2 stringi 16.9ms 17.5ms 57.1 0B 0 29 0 508ms
Article précédent - Couteau suisse Json .