J'ai initialement publié cet article sur le blog CodingSight .
Il est également disponible en russe ici .Cet article contient la deuxième partie de mon discours lors de la rencontre multithreading. Vous pouvez consulter la première partie
ici et
ici . Dans la première partie, je me suis concentré sur l'ensemble d'outils de base utilisé pour démarrer un thread ou une tâche, les moyens de suivre leur état et d'autres choses intéressantes telles que PLinq. Dans cette partie, je vais résoudre les problèmes que vous pouvez rencontrer dans un environnement multithread et certaines des façons de les résoudre.
Table des matières
Concernant les ressources partagées
Vous ne pouvez pas écrire un programme dont le travail est basé sur plusieurs threads sans avoir de ressources partagées. Même si cela fonctionne sur votre niveau d'abstraction actuel, vous constaterez qu'il a en fait des ressources partagées dès que vous descendez d'un ou plusieurs niveaux d'abstraction. Voici quelques exemples:
Exemple # 1:Pour éviter d'éventuels problèmes, vous faites fonctionner les threads avec différents fichiers, un fichier pour chaque thread. Il vous semble que le programme ne dispose d'aucune ressource partagée.
En descendant de quelques niveaux, vous apprenez qu'il n'y a qu'un seul disque dur, et c'est au pilote ou au système d'exploitation de trouver une solution aux problèmes d'accès au disque dur.
Exemple # 2:Après avoir lu l'
exemple # 1 , vous avez décidé de placer les fichiers sur deux machines distantes différentes avec un matériel et des systèmes d'exploitation physiquement différents. Vous gérez également deux connexions FTP ou NFS différentes.
En redescendant de quelques niveaux, vous comprenez que rien n'a vraiment changé et que le problème d'accès concurrentiel est désormais délégué au pilote de la carte réseau ou au système d'exploitation de la machine sur laquelle le programme s'exécute.
Exemple # 3:Après avoir arraché la plupart de vos cheveux au cours des tentatives de prouver que vous pouvez écrire un programme multi-thread, vous décidez d'abandonner complètement les fichiers et de déplacer les calculs vers deux objets différents, avec les liens vers chacun des objets disponibles uniquement pour leur spécifique fils.
Pour enfoncer la dernière douzaine de clous dans le cercueil de cette idée: un runtime et un garbage collector, un planificateur de threads, physiquement une RAM unifiée et un processeur sont toujours considérés comme des ressources partagées.
Nous avons donc appris qu'il est impossible d'écrire un programme multithread sans ressources partagées à tous les niveaux d'abstraction et sur toute l'étendue de la pile technologique. Heureusement, chaque niveau d'abstraction (en règle générale) s'occupe partiellement ou même complètement des problèmes d'accès concurrentiel ou le refuse tout de suite (exemple: tout cadre d'interface utilisateur ne permet pas de travailler avec des éléments de différents threads). Donc, généralement, les problèmes avec les ressources partagées apparaissent à votre niveau d'abstraction actuel. Pour en prendre soin, le concept de synchronisation est introduit.
Problèmes possibles dans les environnements multithreads
Nous pouvons classer les erreurs logicielles dans les catégories suivantes:
- Le programme ne produit aucun résultat - il se bloque ou se fige.
- Le programme donne un résultat incorrect.
- Le programme produit un résultat correct mais ne satisfait pas à certaines exigences non liées à la fonction - il passe trop de temps ou de ressources.
Dans les environnements multithreads, les principaux problèmes qui entraînent les erreurs # 1 et # 2 sont le
blocage et la
condition de concurrence critique .
Impasse
Deadlock est un blocage mutuel. Il existe de nombreuses variantes d'un blocage. La suivante peut être considérée comme la plus courante:
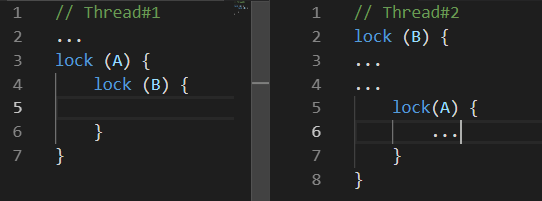
Pendant que le
thread # 1 faisait quelque chose, le
thread # 2 bloquait la ressource
B. Quelque temps plus tard, le
thread n ° 1 a bloqué la ressource
A et tentait de bloquer la ressource B.
Condition de course
Race-Condition est une situation où à la fois, le comportement et les résultats des calculs dépendent du planificateur de threads de l'environnement d'exécution
Le problème est que votre programme peut fonctionner incorrectement une fois sur cent, voire sur un million.
Les choses peuvent empirer lorsque les problèmes arrivent par trois. Par exemple, le comportement spécifique du planificateur de threads peut entraîner un blocage mutuel.
En plus de ces deux problèmes qui conduisent à des erreurs explicites, il y a aussi les problèmes qui, s'ils ne conduisent pas à des résultats de calcul incorrects, peuvent encore faire prendre au programme beaucoup plus de temps ou de ressources pour produire le résultat souhaité. Deux de ces problèmes sont l'
attente occupée et la
famine de fil .
Attente occupée
L'attente occupée est un problème qui survient lorsque le programme dépense les ressources du processeur en attente plutôt qu'en calcul.
En règle générale, ce problème se présente comme suit:
while(!hasSomethingHappened) ;
Ceci est un exemple d'un code extrêmement pauvre car il occupe pleinement un cœur de votre processeur sans rien faire de productif du tout. Un tel code ne peut être justifié que s'il est extrêmement important de traiter rapidement une modification d'une valeur dans un thread différent. Et par «rapidement», je veux dire que vous ne pouvez pas attendre même quelques nanosecondes. Dans tous les autres cas, c'est-à-dire tous les cas où un esprit raisonnable peut arriver, il est beaucoup plus pratique d'utiliser les variantes de ResetEvent et leurs versions Slim. Nous en parlerons un peu plus tard.
Probablement, certains lecteurs suggéreraient de résoudre le problème d'un cœur complètement occupé à attendre en ajoutant Thread.Sleep (1) (ou quelque chose de similaire) dans le cycle. Bien qu'il résoudra ce problème, un nouveau sera créé - le temps nécessaire pour réagir aux modifications sera désormais de 0,5 ms en moyenne. D'une part, ce n'est pas beaucoup, mais d'autre part, cette valeur est catastrophiquement plus élevée que ce que nous pouvons atteindre en utilisant des primitives de synchronisation de la famille ResetEvent.
Fil de famine
Thread Starvation est un problème avec le programme ayant trop de threads fonctionnant simultanément. Ici, nous parlons spécifiquement des threads occupés par le calcul plutôt que par l'attente d'une réponse de certains IO. Avec ce problème, nous perdons tous les avantages de performances possibles avec les threads car le processeur passe beaucoup de temps à changer de contexte.
Vous pouvez trouver de tels problèmes en utilisant divers profileurs. Ce qui suit est une capture d'écran du profileur
dotTrace fonctionnant en mode Timeline
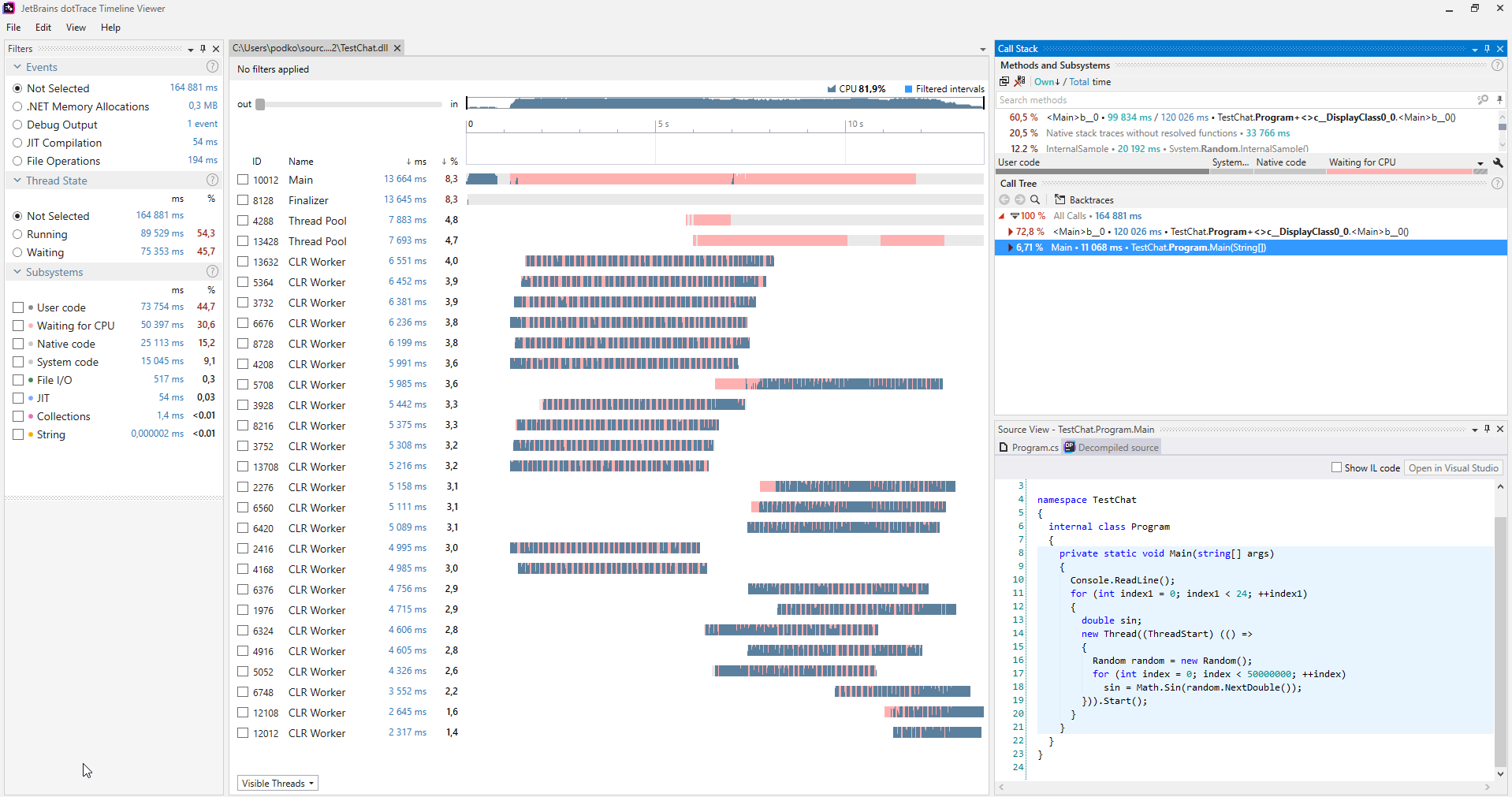 (cliquez pour agrandir).
(cliquez pour agrandir).Habituellement, les programmes qui ne souffrent pas de la famine de threads n'ont pas de sections roses sur les graphiques représentant les threads. De plus, dans la catégorie Sous-systèmes, nous pouvons voir que le programme attendait le CPU pendant 30,6% du temps.
Lorsqu'un tel problème est diagnostiqué, vous pouvez vous en occuper assez simplement: vous avez démarré trop de threads à la fois, alors lancez simplement moins de threads.
Méthodes de synchronisation
Interlocked
Il s'agit probablement de la méthode de synchronisation la plus légère. Interlocked est un ensemble d'opérations atomiques simples. Lorsqu'une opération atomique est en cours d'exécution, rien ne peut se produire. Dans .NET, Interlocked est représenté par la classe statique du même nom avec une sélection de méthodes, chacune implémentant une opération atomique.
Pour réaliser l'horreur ultime des opérations non atomiques, essayez d'écrire un programme qui lance 10 threads, chacun d'eux incrémentant la même variable un million de fois. Une fois leur travail terminé, affichez la valeur de cette variable. Malheureusement, il sera très différent de 10 millions. De plus, il sera différent chaque fois que vous exécuterez le programme. Cela se produit parce que même une opération aussi simple que l'incrément n'est pas atomique et comprend l'extraction de valeur de la mémoire, le calcul de la nouvelle valeur et l'écriture à nouveau dans la mémoire. Ainsi, deux threads peuvent effectuer l'une de ces opérations et un incrément sera perdu dans ce cas.
La classe Interlocked fournit les méthodes Increment / Decrement, et il n'est pas difficile de deviner ce qu'elles sont censées faire. Ils sont vraiment pratiques si vous traitez des données dans plusieurs threads et calculez quelque chose. Un tel code fonctionnera beaucoup plus rapidement que le verrou classique. Si nous utilisions Interlocked dans la situation décrite dans le paragraphe précédent, le programme produirait de manière fiable une valeur de 10 millions dans n'importe quel scénario.
La fonction de la méthode CompareExchange n'est pas si évidente. Cependant, son existence permet la mise en œuvre de nombreux algorithmes intéressants. Plus important encore, ceux de la famille sans verrou.
public static int CompareExchange (ref int location1, int value, int comparand);
Cette méthode prend trois valeurs. La première passe par une référence et c'est la valeur qui sera changée en seconde si location1 est égale à comparand lorsque la comparaison est effectuée. La valeur d'origine de location1 sera retournée. Cela semble compliqué, il est donc plus facile d'écrire un morceau de code qui effectue les mêmes opérations que CompareExchange:
var original = location1; if (location1 == comparand) location1 = value; return original;
La seule différence est que la classe Interlocked l'implémente de manière atomique. Donc, si nous écrivions ce code nous-mêmes, nous pourrions faire face à un scénario dans lequel la condition location1 == comparand a déjà été remplie. Mais lorsque l'instruction location1 = value est en cours d'exécution, un thread différent a déjà modifié la valeur location1, elle sera donc perdue.
Nous pouvons trouver un bon exemple de la façon dont cette méthode peut être utilisée dans le code que le compilateur génère pour tout événement C #.
Écrivons une classe simple avec un événement appelé MyEvent:
class MyClass { public event EventHandler MyEvent; }
Maintenant, construisons le projet dans la configuration Release et ouvrons la construction via
dotPeek avec l'option "Afficher le code généré par le compilateur" activée:
[CompilerGenerated] private EventHandler MyEvent; public event EventHandler MyEvent { [CompilerGenerated] add { EventHandler eventHandler = this.MyEvent; EventHandler comparand; do { comparand = eventHandler; eventHandler = Interlocked.CompareExchange<EventHandler>(ref this.MyEvent, (EventHandler) Delegate.Combine((Delegate) comparand, (Delegate) value), comparand); } while (eventHandler != comparand); } [CompilerGenerated] remove {
Ici, nous pouvons voir que le compilateur a généré un algorithme assez complexe dans les coulisses. Cet algorithme nous empêche de perdre un abonnement à l'événement dans lequel quelques threads sont simultanément abonnés à cet événement. Développons la méthode add tout en gardant à l'esprit ce que fait la méthode CompareExchange dans les coulisses:
EventHandler eventHandler = this.MyEvent; EventHandler comparand; do { comparand = eventHandler;
C'est beaucoup plus gérable, mais nécessite probablement encore une explication. Voici comment je décrirais l'algorithme:
Si MyEvent est toujours le même qu'au moment où nous avons commencé à exécuter Delegate.Combine, définissez-le sur ce que Delegate.Combine renvoie. Si ce n'est pas le cas, réessayez jusqu'à ce que cela fonctionne.De cette façon, les abonnements ne seront jamais perdus. Vous devrez résoudre un problème similaire si vous souhaitez implémenter un tableau dynamique, thread-safe et sans verrouillage. Si plusieurs threads commencent soudainement à ajouter des éléments à ce tableau, il est important que tous ces éléments soient ajoutés avec succès.
Monitor.Enter, Monitor.Exit, lock
Ces constructions sont utilisées pour la synchronisation des threads le plus fréquemment. Ils implémentent le concept d'une section critique: c'est-à-dire que le code écrit entre les appels de Monitor.Enter et Monitor.Exit ne peut être exécuté que sur une ressource à un moment donné par un seul thread. L'opérateur de verrouillage sert de sucre de syntaxe autour des appels d'entrée / sortie enveloppés dans try-finally. Une qualité agréable de la section critique dans .NET est qu'elle prend en charge la réentrance. Cela signifie que le code suivant peut être exécuté sans problème réel:
lock(a) { lock (a) { ... } }
Il est peu probable que quelqu'un écrive de cette manière exacte, mais si vous répandez ce code entre quelques méthodes à travers la profondeur de la pile d'appels, cette fonctionnalité peut vous faire économiser quelques IF. Pour que cette astuce fonctionne, les développeurs de .NET ont dû ajouter une limitation - vous ne pouvez utiliser que des instances de types de référence comme objet de synchronisation, et quelques octets sont ajoutés à chaque objet où l'identificateur de thread sera écrit.
Cette particularité du processus de travail de la section critique en C # impose une limitation intéressante à l'opérateur de verrouillage: vous ne pouvez pas utiliser l'opérateur d'attente à l'intérieur de l'opérateur de verrouillage. Au début, cela m'a surpris car une construction similaire de Monitor.Enter / Exit similaire peut être compilée. Quel est le problème? Il est important de relire le paragraphe précédent et d'appliquer certaines connaissances sur le fonctionnement de async / expect: le code après wait ne sera pas exécuté sur le même thread que le code before wait. Cela dépend du contexte de synchronisation et du fait que la méthode ConfigureAwait est appelée ou non. Il s'ensuit que Monitor.Exit peut être exécuté sur un thread différent de Monitor.Enter, ce qui entraînera la levée de SynchronizationLockException. Si vous ne me croyez pas, essayez d'exécuter le code suivant dans une application console - cela générera une
SynchronizationLockException :
var syncObject = new Object(); Monitor.Enter(syncObject); Console.WriteLine(Thread.CurrentThread.ManagedThreadId); await Task.Delay(1000); Monitor.Exit(syncObject); Console.WriteLine(Thread.CurrentThread.ManagedThreadId);
Il convient de noter que, dans une application WinForms ou WPF, ce code fonctionnera correctement si vous l'appelez à partir du thread principal car il y aura un contexte de synchronisation qui implémentera le retour à UI-Thread après l'appel en attente. Dans tous les cas, il vaut mieux ne pas jouer avec les sections critiques dans le contexte d'un code contenant l'opérateur wait. Dans de tels exemples, il est préférable d'utiliser des primitives de synchronisation que nous verrons un peu plus tard.
Bien que nous soyons sur le sujet des sections critiques dans .NET, il est important de mentionner une particularité supplémentaire de la façon dont elles sont implémentées. Une section critique de .NET fonctionne en deux modes: spin-wait et core-wait. Nous pouvons représenter l'algorithme spin-wait comme le pseudocode suivant:
while(!TryEnter(syncObject)) ;
Cette optimisation vise à capturer une section critique le plus rapidement possible dans un court laps de temps sur la base que, même si la ressource est actuellement occupée, elle sera libérée très bientôt. Si cela ne se produit pas dans un court laps de temps, le thread passera en attente dans le mode de base, ce qui prend du temps - tout comme revenir de l'attente. Les développeurs de .NET ont optimisé autant que possible le scénario des blocs courts. Malheureusement, si de nombreux threads commencent à tirer la section critique entre eux, cela peut entraîner une charge soudaine et élevée sur le processeur.
SpinLock, SpinWait
Ayant déjà mentionné l'algorithme d'attente cyclique (spin-wait), il vaut la peine de parler des structures SpinLock et SpinWait de BCL. Vous devez les utiliser s'il y a des raisons de supposer qu'il sera toujours possible d'obtenir un bloc très rapidement. D'un autre côté, vous ne devriez pas vraiment y penser jusqu'à ce que les résultats du profilage montrent que le goulot d'étranglement de votre programme est provoqué par l'utilisation d'autres primitives de synchronisation.
Monitor.Wait, Monitor.Pulse [Tout]
Nous devrions regarder ces deux méthodes côte à côte. Avec leur aide, vous pouvez implémenter différents scénarios Producteur-Consommateur.
Le producteur-consommateur est un modèle de conception multi-processus / multi-thread impliquant un ou plusieurs threads / processus qui produisent des données et un ou plusieurs processus / threads qui traitent ces données. Habituellement, une collection partagée est utilisée.
Ces deux méthodes ne peuvent être appelées que par un thread qui a actuellement un bloc. La méthode Wait libérera le bloc et gèlera jusqu'à ce qu'un autre thread appelle Pulse.
Pour illustrer cela, j'ai écrit un petit exemple:
object syncObject = new object(); Thread t1 = new Thread(T1); t1.Start(); Thread.Sleep(100); Thread t2 = new Thread(T2); t2.Start();
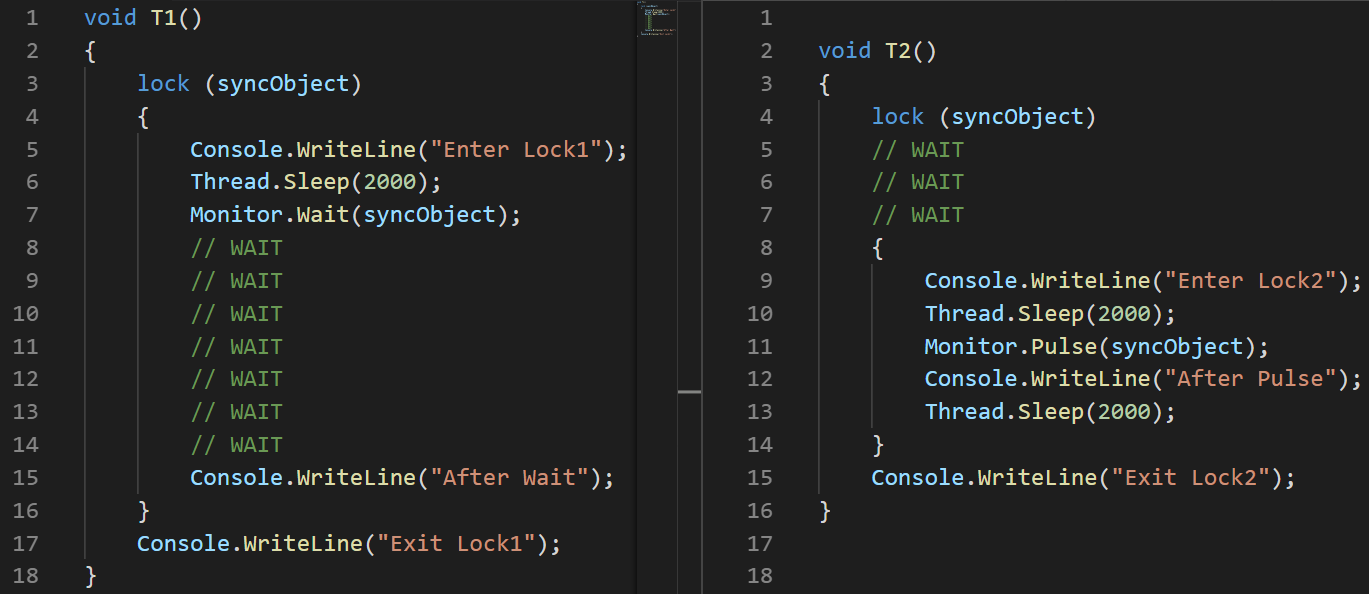 (J'ai utilisé une image plutôt que du texte ici pour montrer avec précision l'ordre d'exécution des instructions)Explication:
(J'ai utilisé une image plutôt que du texte ici pour montrer avec précision l'ordre d'exécution des instructions)Explication: J'ai défini une latence de 100 ms lors du démarrage du deuxième thread pour garantir spécifiquement qu'il sera exécuté plus tard.
- T1: ligne # 2 le thread est démarré
- T1: ligne # 3, le thread entre dans une section critique
- T1: ligne # 6, le fil se met en veille
- T2: Ligne # 3 le thread est démarré
- T2: Ligne # 4 il fige et attend la section critique
- T1: Ligne # 7 il laisse aller la section critique et se fige en attendant la sortie de Pulse
- T2: Ligne # 8 il entre dans la section critique
- T2: Ligne # 11, il signale T1 à l'aide de Pulse
- T2: Ligne # 14 elle sort de la section critique. T1 ne peut pas continuer son exécution avant que cela ne se produise.
- T1: Ligne # 15 elle sort de l'attente
- T1: Ligne # 16 elle sort de la section critique
Il existe une remarque importante dans MSDN concernant l'utilisation des méthodes Pulse / Wait: Monitor ne stocke pas les informations d'état, ce qui signifie que l'appel de la méthode Pulse avant la méthode Wait peut entraîner un blocage. Si un tel cas est possible, il est préférable d'utiliser l'une des classes de la famille ResetEvent.L'exemple précédent montre clairement comment fonctionnent les méthodes Wait / Pulse de la classe Monitor, mais laisse encore quelques questions sur les cas dans lesquels nous devrions les utiliser. Un bon exemple est
cette implémentation de BlockingQueue <T>. D'autre part, l'implémentation de BlockingCollection <T> à partir de System.Collections.Concurrent utilise SemaphoreSlim pour la synchronisation.
ReaderWriterLockSlim
J'adore cette primitive de synchronisation, et elle est représentée par la classe du même nom de l'espace de noms System.Threading. Je pense que beaucoup de programmes fonctionneraient beaucoup mieux si leurs développeurs utilisaient cette classe au lieu du verrou standard.
Idée: beaucoup de threads peuvent lire et le seul peut écrire. Lorsqu'un thread veut écrire, de nouvelles lectures ne peuvent pas être démarrées - il attendra la fin de l'écriture. Il existe également le concept de verrouillage de lecture évolutif. Vous pouvez l'utiliser lorsque, pendant le processus de lecture, vous comprenez qu'il est nécessaire d'écrire quelque chose - un tel verrou sera transformé en verrou d'écriture en une seule opération atomique.
Dans l'espace de noms System.Threading, il existe également la classe ReadWriteLock, mais il est fortement recommandé de ne pas l'utiliser pour de nouveaux développements. La version Slim aidera à éviter les cas qui conduisent à des blocages et permet de capturer rapidement un bloc car elle prend en charge la synchronisation en mode d'attente d'attente avant de passer au mode principal.
Si vous ne connaissiez pas cette classe avant de lire cet article, je pense que vous vous souvenez maintenant de nombreux exemples du code récemment écrit où cette approche des blocs a permis au programme de fonctionner efficacement.
L'interface de la classe ReaderWriterLockSlim est simple et facile à comprendre, mais ce n'est pas si confortable à utiliser:
var @lock = new ReaderWriterLockSlim(); @lock.EnterReadLock(); try {
J'aime généralement l'envelopper dans une classe - cela le rend beaucoup plus pratique.
Idée: créez des méthodes Read / WriteLock qui renvoient un objet avec la méthode Dispose. Vous pouvez ensuite y accéder dans Utilisation, et cela ne différera probablement pas trop du verrou standard en ce qui concerne le nombre de lignes. class RWLock : IDisposable { public struct WriteLockToken : IDisposable { private readonly ReaderWriterLockSlim @lock; public WriteLockToken(ReaderWriterLockSlim @lock) { this.@lock = @lock; @lock.EnterWriteLock(); } public void Dispose() => @lock.ExitWriteLock(); } public struct ReadLockToken : IDisposable { private readonly ReaderWriterLockSlim @lock; public ReadLockToken(ReaderWriterLockSlim @lock) { this.@lock = @lock; @lock.EnterReadLock(); } public void Dispose() => @lock.ExitReadLock(); } private readonly ReaderWriterLockSlim @lock = new ReaderWriterLockSlim(); public ReadLockToken ReadLock() => new ReadLockToken(@lock); public WriteLockToken WriteLock() => new WriteLockToken(@lock); public void Dispose() => @lock.Dispose(); }
Cela nous permet d'écrire simplement ce qui suit plus loin dans le code:
var rwLock = new RWLock();
La famille ResetEvent
J'inclus les classes suivantes dans cette famille: ManualResetEvent, ManualResetEventSlim et AutoResetEvent.
La classe ManualResetEvent, sa version Slim et la classe AutoResetEvent peuvent exister dans deux états:
- Non signalé - dans cet état, tous les threads qui ont appelé WaitOne se figent jusqu'à ce que l'événement passe à un état signalé.
- Signalé - dans cet état, tous les threads précédemment gelés lors d'un appel WaitOne sont libérés. Tous les nouveaux appels WaitOne sur un événement signalé sont effectués relativement instantanément.
AutoResetEvent diffère de ManualResetEvent en ce qu'il passe automatiquement à l'état non signalé après avoir relâché
exactement un thread . Si quelques threads sont figés en attendant AutoResetEvent, l'appel à Set ne libérera qu'un seul thread aléatoire, contrairement à ManualResetEvent qui libère tous les threads.
Regardons un exemple du fonctionnement d'AutoResetEvent:
AutoResetEvent evt = new AutoResetEvent(false); Thread t1 = new Thread(T1); t1.Start(); Thread.Sleep(100); Thread t2 = new Thread(T2); t2.Start();
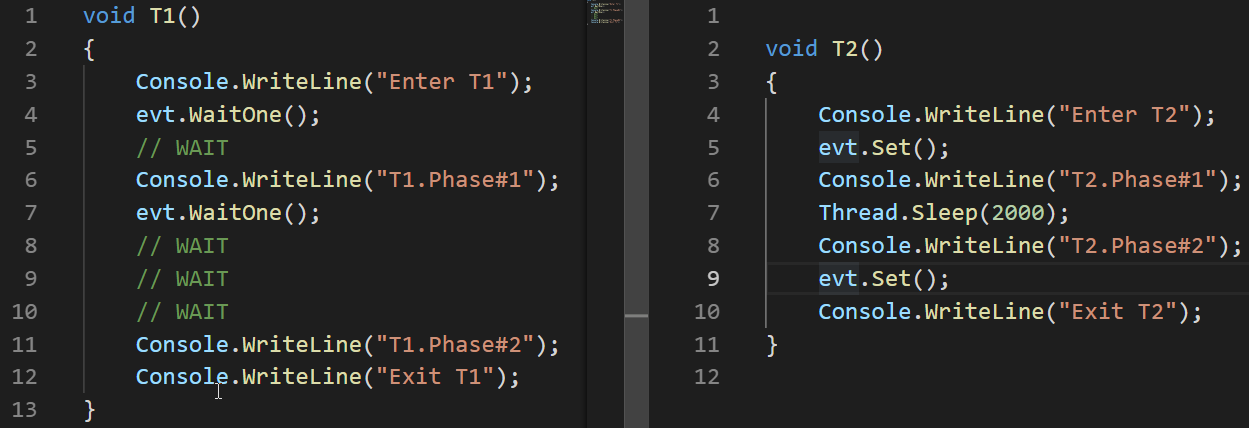
Dans ces exemples, nous pouvons voir que l'événement ne passe automatiquement à l'état non signalé qu'après avoir libéré le thread qui a été gelé lors d'un appel WaitOne.
Contrairement à ReaderWriterLock, ManualResetEvent n'est pas considéré comme obsolète même après l'apparition de sa version Slim. Cette version Slim de la classe peut être efficace pour les courtes attentes comme cela se produit dans le mode Spin-Wait; la version standard convient aux longues attentes.
Outre les classes ManualResetEvent et AutoResetEvent, il existe également la classe CountdownEvent. Cette classe est très utile pour implémenter des algorithmes qui fusionnent les résultats ensemble après une section parallèle. Cette approche est connue sous le nom de
fork-join . Il y a un excellent
article dédié à cette classe, donc je ne le décrirai pas en détail ici.
Conclusions
- Lorsque vous travaillez avec des threads, deux problèmes peuvent conduire à des résultats incorrects ou même à l'absence de résultats: condition de concurrence critique et blocage.
- Les problèmes qui peuvent faire passer plus de temps ou de ressources au programme sont la famine de threads et l'attente occupée.
- .NET offre de nombreuses façons de synchroniser les threads.
- Il existe deux modes d'attente de bloc - Spin Wait et Core Wait. Les primitives de synchronisation des threads Som.e dans .NET les utilisent toutes les deux.
- Interlocked est un ensemble d'opérations atomiques qui peuvent être utilisées pour implémenter des algorithmes sans verrouillage. C'est la primitive de synchronisation la plus rapide.
- Le verrou et le moniteur Les opérateurs Entrée / Sortie implémentent le concept d'une section critique - un fragment de code qui ne peut être exécuté que par un thread à un moment donné.
- Les méthodes Monitor.Pulse / Wait sont utiles pour implémenter des scénarios Producteur-Consommateur.
- ReaderWriterLockSlim peut être plus utile que les cas de verrouillage standard lorsqu'une lecture parallèle est attendue.
- La famille de classes ResetEvent peut être utile pour la synchronisation des threads.