Imaginez une situation typique la première année: vous avez lu
l’algorithme Dinits ,
l’avez mis en œuvre, mais cela n’a pas fonctionné et vous ne savez pas pourquoi. La solution standard consiste à commencer le débogage par étapes, en dessinant à chaque fois l'état actuel du graphique sur une feuille de papier, mais cela est terriblement gênant. J'ai essayé de corriger la situation dans le cadre d'un projet de semestre sur le génie logiciel, et dans un article, je vais vous expliquer comment je me suis retrouvé avec un plug-in pour Visual Studio. Vous pouvez le télécharger
ici , le code source et la documentation peuvent être trouvés
ici . Voici une capture d'écran du graphique obtenu pour l'algorithme Dinits.
À propos de moi
Je m'appelle Olga, je suis diplômée de la troisième année de la direction "Mathématiques Appliquées et Informatique" au HSE de Saint-Pétersbourg avec un diplôme en Génie Logiciel. Avant d'entrer à l'université, je n'étais pas impliqué dans la programmation.
Recherche: exigences
Dans notre faculté, nous pratiquons le travail de recherche au semestre Habituellement, cela se passe comme ceci: au début du semestre, une présentation des travaux de recherche a lieu - des représentants de différentes entreprises proposent toutes sortes de projets. Ensuite, les étudiants choisissent leurs projets préférés, les superviseurs choisissent leurs étudiants préférés, etc. Au final, chaque étudiant trouve un projet pour lui-même.
Mais il y a une autre façon: vous pouvez trouver indépendamment un superviseur et un projet, puis convaincre le conservateur que ce projet peut vraiment être une R&D à part entière. Pour ce faire, prouvez que:
- Vous allez faire quelque chose de nouveau. Bien sûr, le projet peut avoir des analogues, mais votre option devrait avoir certains avantages par rapport à eux.
- La tâche devrait être assez difficile, c'est-à-dire que le travail devrait y être pour un semestre et non pour une journée. En même temps, il faut que le projet se soit vraiment fait en un semestre.
- Votre projet doit être utile au monde. Autrement dit, lorsqu'on lui demande pourquoi cela est nécessaire, vous ne devez pas répondre: "Eh bien, je dois faire une sorte de recherche."
J'ai choisi la deuxième voie. La première chose à faire après avoir convenu avec le superviseur a été de trouver le sujet du projet. La liste des idées comprenait: un vérificateur de style de code pour Lua, un débogueur qui vous permet de calculer des expressions en parties, et un outil pour les olympiades / la formation en programmation, qui vous permet de visualiser ce qui se passe dans le code. Autrement dit, un visualiseur de structures de données arbitraires combiné avec un débogueur. Par exemple, une personne écrit un
arbre cartésien et, dans le processus, les sommets, les arêtes, le sommet actuel, etc. sont dessinés. Finalement, j'ai décidé de m'attarder sur cette option.
Plan de travail du projet
Mon travail sur le projet a comporté les étapes suivantes:
- L'étude du sujet était nécessaire pour comprendre si ce problème avait déjà été résolu (alors le sujet du projet devrait être changé), quels sont leurs analogues, quels sont leurs avantages et leurs inconvénients, que je pourrais prendre en compte dans mon travail.
- Définir la fonctionnalité spécifique que l'outil créé possédera. Le thème du projet a été énoncé de manière assez abstraite, ce qui était nécessaire pour s'assurer que la tâche est assez compliquée, mais en même temps, elle peut être achevée en un semestre.
- La création d'une interface utilisateur prototype a été nécessaire pour montrer comment l'outil créé peut être utilisé. Il a ajouté encore plus de spécificité qu'un ensemble de fonctionnalités décrites par des mots.
- Choix des dépendances - vous devez comprendre comment tout sera organisé du point de vue du développeur et décider des outils qui seront utilisés dans le processus d'écriture du code.
- Créer un prototype (preuve de concept) , c'est-à-dire un exemple minimal dans lequel la plupart seraient codés en dur. Avec cet exemple, j'ai dû gérer tous les outils que j'allais utiliser, et aussi apprendre à résoudre toutes les difficultés qui se sont posées en cours de route, de sorte que la version finale était déjà écrite «propre».
- Travail sur la partie contenu , c'est-à-dire le développement et la mise en œuvre de la logique de l'outil.
- La protection du projet est nécessaire afin de parler rapidement du travail effectué et de donner l'occasion de l'évaluer à tout le monde, même aux personnes qui ne farfouillent pas sur le sujet. C'est une formation avant l'obtention du diplôme. Dans le même temps, un projet bien conçu ne garantit pas que le rapport se révélera bon, car il nécessite d'autres compétences, par exemple la capacité de parler au public.
J'ai toujours effectué la planification avec mon superviseur. Nous avons également toujours proposé et discuté toutes les idées qui ont surgi en cours de route. De plus, le superviseur m'a donné des conseils sur le code et m'a aidé à gérer le temps. À propos de tous les problèmes techniques (bugs incompréhensibles, etc.), j'ai également toujours signalé, mais le plus souvent j'ai réussi à les résoudre moi-même.
Recherche par sujet
Pour commencer, notre leadership aurait dû être convaincu que ce sujet mérite d'être mon travail de recherche. Et pour partir du premier point: la recherche d'analogues.
Il s'est avéré qu'il existe de nombreux analogues. Mais la plupart d'entre eux ont été conçus pour la visualisation de la mémoire. Autrement dit, ils auraient fait un excellent travail avec la visualisation de l'arbre cartésien, mais ils ne peuvent pas comprendre que le
tas sur le tableau ne doit pas être dessiné comme un tableau, mais comme un arbre. Ceux-ci comprenaient
gdbgui , un
débogueur d'affichage de données , un plug-in pour Eclipse
jGRASP et un plug-in pour Visual Studio
Data Structures Visualizer . Ce dernier a également été créé pour les problèmes de programmation des olympiades, mais n'a pu visualiser que des structures de données sur des pointeurs.
Il y avait quelques autres outils:
Algojammer pour python (et nous voulions des atouts, comme le langage le plus populaire parmi olympiadniki) et l'outil
Lens développé en 1994. Ce dernier, à en juger par la description, a fait presque ce dont il avait besoin, mais, malheureusement, il a été créé sous Sun OS 4.1.3 (un système d'exploitation de 1992). Ainsi, malgré la disponibilité des codes sources, il a été décidé de ne pas perdre de temps sur cette archéologie douteuse.
Ainsi, après quelques recherches, il a été constaté que Tula, qui ferait exactement ce que nous voulions, tout en travaillant sur des machines modernes, n'est pas encore dans la nature.
Définition de la fonctionnalité
La deuxième étape consistait à prouver que cette tâche est assez compliquée, mais réalisable. Pour ce faire, il a fallu proposer quelque chose de plus spécifique que «Je veux une belle photo, et que tout en devienne clair immédiatement».
Dans ce projet, nous avons décidé de nous concentrer sur la visualisation uniquement des graphes: il existe de nombreux algorithmes sur les graphes qui peuvent être implémentés de différentes manières, et même s'ils sont limités, la tâche reste non triviale.
Il est également plus ou moins évident que l'outil doit en quelque sorte être intégré au débogueur. Nous devons être capables de visualiser les valeurs des variables et des expressions, et de dessiner une image finale à partir de ces valeurs.
Après cela, il était nécessaire de trouver un certain langage qui nous permette de construire un graphique en fonction de l'état actuel du programme comme nous le voulons. En plus du graphique lui-même, il était nécessaire de prévoir la possibilité de changer la couleur des sommets et des bords, d'y ajouter des étiquettes arbitraires et de modifier d'autres propriétés. En conséquence, la première idée était:
- Déterminez ce que nous avons des sommets, par exemple, des nombres de 0 à n.
- Déterminez la présence d'une arête entre les sommets à l'aide de la condition booléenne. Dans ce cas, les arêtes sont de types différents et chaque type possède son propre ensemble de propriétés.
- De plus, nous pouvons définir des propriétés de sommet telles que la couleur, en utilisant également la condition booléenne.
- Parcourez les étapes avec le débogueur: toutes les expressions sont calculées, toutes les conditions sont vérifiées et, en fonction de cela, un graphique est dessiné.
Prototypage d'interface utilisateur
J'ai dessiné le prototype de l'interface utilisateur dans
NinjaMock . Cela était nécessaire pour mieux comprendre à quoi ressemblera l'interface du point de vue de l'utilisateur et quelles actions il devra effectuer. S'il y avait des problèmes avec le prototype, nous comprendrions qu'il y a des incohérences logiques, et cette idée devrait être rejetée. Pour la fidélité, j'ai pris quelques algorithmes. L'image ci-dessous montre des exemples de la façon dont j'ai imaginé les paramètres de visualisation
DFS et
l'algorithme Floyd .
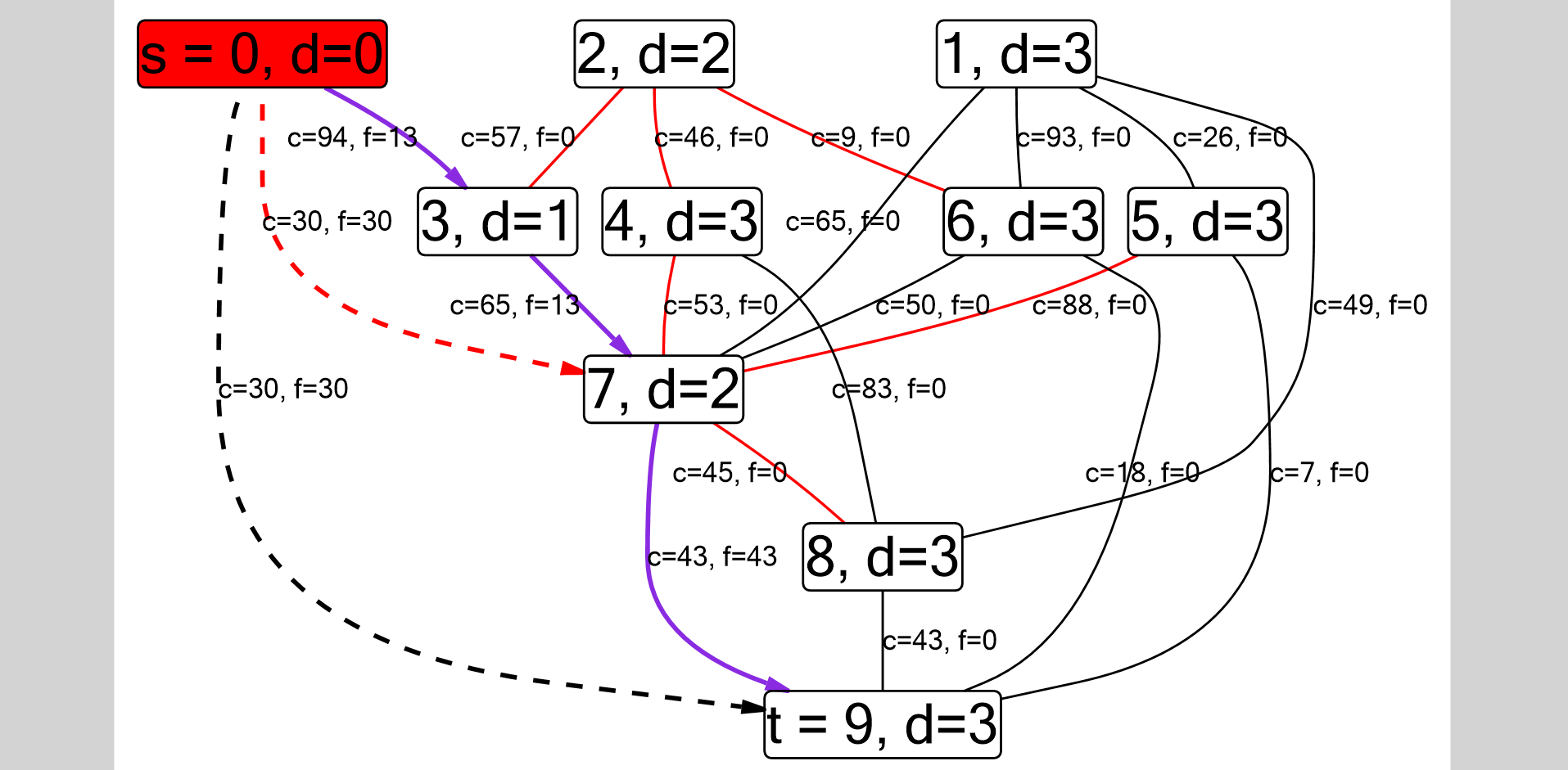
 Comme j'imaginais les paramètres pour DFS. Le graphe est stocké sous forme de liste d'adjacence, donc l'arête entre les sommets i et j est déterminée par la condition
Comme j'imaginais les paramètres pour DFS. Le graphe est stocké sous forme de liste d'adjacence, donc l'arête entre les sommets i et j est déterminée par la condition g[i].find() != g[i].end() (en fait, pour ne pas dupliquer les arêtes, nous devons vérifier que i <= j ). Le chemin DFS est affiché séparément: p[j] == i . Ces bords seront orientés.
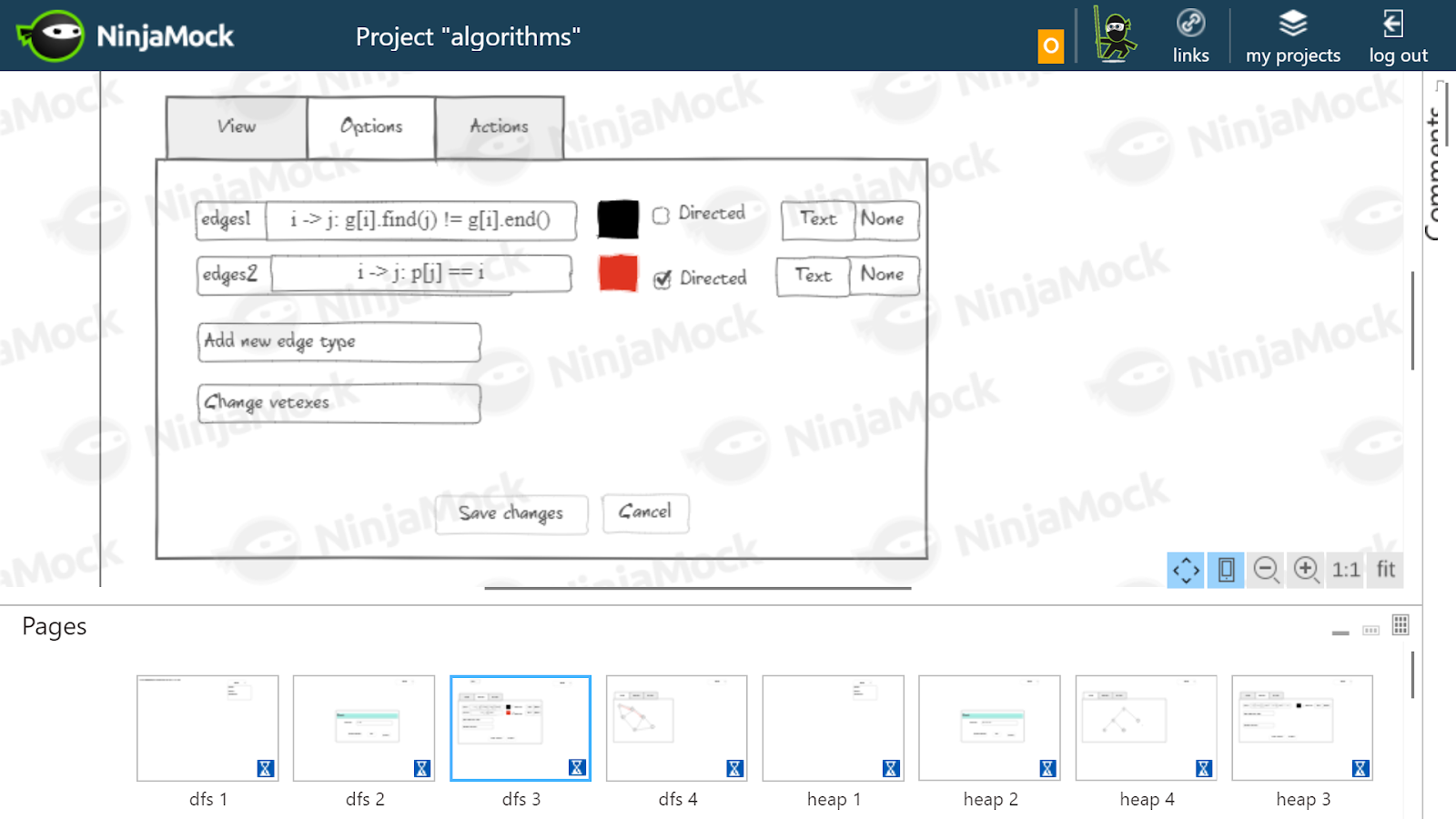
J'ai supposé que pour l'algorithme de Floyd, il serait nécessaire de dessiner en noir les bords réels stockés dans le tableau c , et en gris - les chemins les plus courts trouvés à ce stade, stockés dans le tableau d . Pour chaque bord et chemin le plus court, son poids est écrit.Sélection des dépendances
Pour l'étape suivante, il fallait comprendre comment faire tout cela. Tout d'abord, l'intégration avec un débogueur était nécessaire. La première chose qui vient à l'esprit lorsque le mot "débogueur" est gdb, mais il faudrait alors créer l'intégralité de l'interface graphique à partir de zéro, ce qui est vraiment difficile pour un étudiant à faire pendant un semestre. La deuxième idée évidente est de créer un plugin pour un environnement de développement existant. Comme options, j'ai considéré QTCreator, CLion et Visual Studio.
L'option CLion a été rejetée presque immédiatement, car, d'une part, elle a fermé le code source, et d'autre part, tout est très mauvais avec la documentation (et personne n'a besoin de difficultés supplémentaires). QTCreator, contrairement à Visual Studio, est multiplateforme et open source, et donc, au début, nous avons décidé de nous y attarder.
Il s'est avéré, cependant, que QTCreator est mal adapté pour l'extension à l'aide de plugins. La première étape de la création d'un plugin pour QTCreator consiste à créer à partir des sources. Cela m'a pris une semaine et demie. Au final, j'ai envoyé deux rapports de bogues (
ici et
là ) concernant le processus d'assemblage. Oui, c'est tout l'effort déployé pour créer QTCreator juste pour découvrir que le débogueur dans QTCreator n'a pas d'API publique. Je suis revenu à une autre option, à savoir Visual Studio.
Et cela s'est avéré être la bonne décision: Visual Studio a non seulement une excellente API, mais aussi une excellente documentation pour cela. L'
_debugger.GetExpression(...).Value expression a
_debugger.GetExpression(...).Value simplifiée en appelant
_debugger.GetExpression(...).Value . Visual Studio offre également la possibilité d'itérer sur les cadres et d'évaluer l'expression dans le contexte de l'un d'eux. Pour ce faire, remplacez la propriété
CurrentStackFrame par celle requise. Vous pouvez également suivre les mises à jour du concours de débogage pour redessiner l'image lors de la modification.
Bien sûr, il n'était pas supposé que je serais engagé dans la visualisation de graphiques à partir de zéro - il y a beaucoup de bibliothèques spéciales pour cela. Le plus célèbre d'entre eux est
Graphviz , et nous avions prévu de l'utiliser dans un premier temps. Mais pour un plug-in pour Visual Studio, il serait plus logique d'utiliser la bibliothèque pour C #, puisque j'allais écrire dessus. J'ai fait une petite recherche sur
Google et j'ai trouvé la bibliothèque
MSAGL : elle avait toutes les fonctionnalités requises et avait une interface simple et intuitive.
Preuve de concept
Désormais, disposant d'un mécanisme de calcul des expressions arbitraires d'une part et d'une bibliothèque de visualisation des graphes d'autre part, il fallait faire un prototype. Le premier prototype a été fait pour DFS, puis l'
algorithme Dinits,
l'algorithme Kuhn , la
recherche de composants doublement connectés , l'arbre cartésien et le
SNM ont été pris comme exemples. J'ai pris mes anciennes implémentations de ces algorithmes de la première à la deuxième année, créé un nouveau plug-in, dessiné un graphique correspondant à cette tâche (tous les noms de variables étaient codés en dur). Voici un exemple de graphique que j'ai obtenu pour l'algorithme de Kuhn:
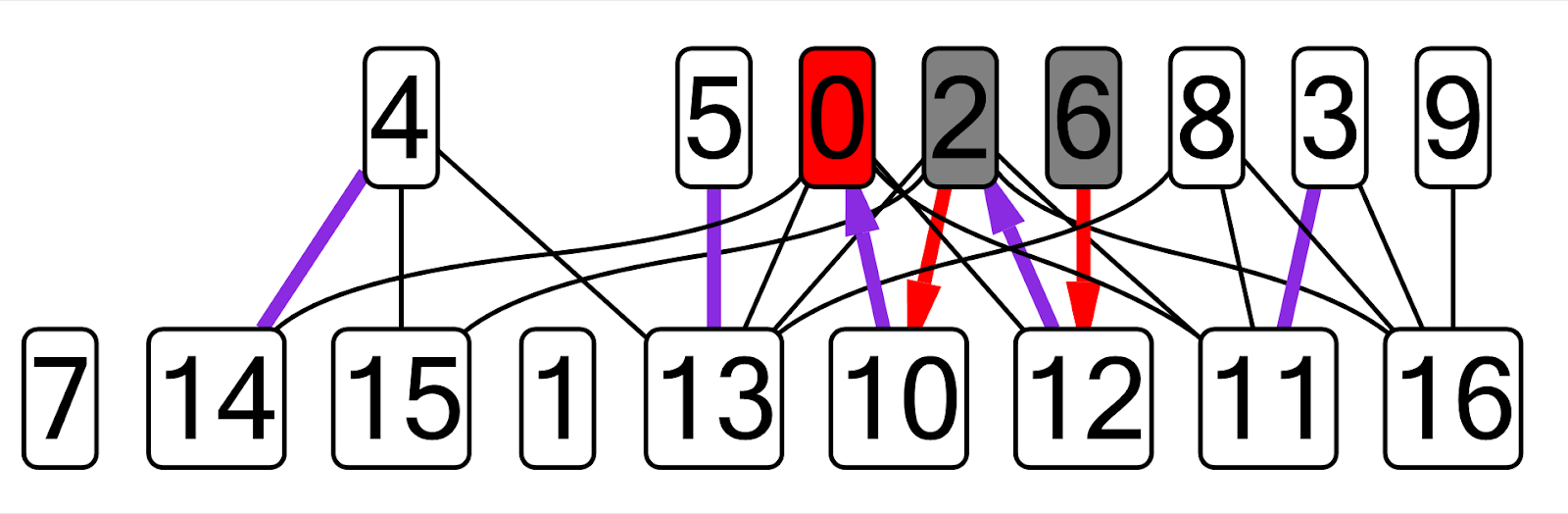 Sur ce graphique, les arêtes correspondantes actuelles sont affichées en violet, le sommet dfs actuel est affiché en rouge, les sommets visités sont gris, les bords d'une chaîne alternative qui ne provient pas de la correspondance sont affichés en rouge.
Sur ce graphique, les arêtes correspondantes actuelles sont affichées en violet, le sommet dfs actuel est affiché en rouge, les sommets visités sont gris, les bords d'une chaîne alternative qui ne provient pas de la correspondance sont affichés en rouge.J'ai considéré qu'il était permis de modifier légèrement le code de l'algorithme pour le rendre plus facile à visualiser. Par exemple, dans le cas de l'arbre cartésien, il s'est avéré qu'il est plus facile d'ajouter tous les nœuds créés à un vecteur que de contourner l'arbre à l'intérieur du plugin.
Une découverte désagréable a été que le débogueur dans Visual Studio ne prend pas en charge les méthodes et fonctions d'appel à partir de la STL. Cela signifiait qu'il n'était pas possible de vérifier la présence d'un élément dans le conteneur en utilisant
std::find , comme supposé à l'origine. Ce problème peut être résolu soit en créant une fonction définie par l'utilisateur, soit en dupliquant la propriété "l'élément est contenu dans le conteneur" dans un tableau booléen.
Dans mes plugins d'essai, quelque chose comme ce qui suit s'est produit (si le graphique a été stocké en tant que liste d'adjacence):
- Vient d'abord la boucle
for de 0 à _debugger.GetExpression("n").Value , qui a ajouté tous les sommets au graphique, chacun avec son propre numéro.
- Ensuite, il y a deux
_debugger.GetExpression($"g[{i}].size()").Value imbriquées for , la première sur i - de 0 à n , la seconde sur j - de 0 à _debugger.GetExpression($"g[{i}].size()").Value , et le bord {i, _debugger.GetExpression($"g[{i}][{j}]").Value} .
- Si nécessaire, des informations supplémentaires ont été ajoutées aux étiquettes des sommets et des arêtes. Par exemple, la valeur du tableau
d , qui est responsable de la distance au sommet sélectionné.
- Si l'algorithme était basé sur dfs, un cycle a ensuite parcouru tous les cadres en verre et tous les sommets de la pile (
stackFrame.FunctionName.Equals("dfs") && stackFrame.Arguments.Item(1) == v ) étaient surlignés en gris.
- Ensuite, pour chaque
i de 0 à n , dénotant les nombres des sommets, certaines conditions ont été vérifiées, et si elles étaient satisfaites, alors certaines propriétés ont changé au sommet, le plus souvent la couleur.
À ce moment-là, j'ai écrit le code «au besoin», sans essayer de trouver un schéma général pour tous les algorithmes, ou d'écrire le code au moins d'une manière magnifique. La création de chaque nouveau plugin a commencé avec le copier-coller du précédent.
Configuration graphique
Après la recherche, il a fallu élaborer un schéma général applicable à tous les algorithmes. La première chose qui a été introduite a été les index des sommets et des arêtes. Chaque index a un nom unique et des extrémités de plage, calculées à l'aide de
_debugger.GetExpression . Pour accéder à la valeur de l'index, utilisez son nom entouré de __ (c'est-à-dire __x__). Les expressions avec des emplacements pour substituer des valeurs d'index, ainsi que le nom de la fonction actuelle (__CURRENT_FUNCTION__) et les valeurs de ses arguments (__ARG1__, __ARG2__, ...), sont appelées modèles.
Les index sont substitués pour chaque sommet ou arête, puis ils sont calculés dans le débogueur. Des modèles ont été utilisés pour filtrer certaines valeurs d'index (si le graphique est stocké en tant que matrice d'adjacence
c , alors les indices seront a et b de 0 à n, et le modèle de validation est
c[__a__][__b__] ). Les limites de la plage d'index sont également des modèles, car elles peuvent contenir des index précédents.
Un graphique peut avoir différents types de sommets et d'arêtes. Par exemple, dans le cas de la recherche de la correspondance maximale dans un graphique bipartite, chaque fraction peut être indexée séparément. Par conséquent, le concept de famille a été introduit pour les sommets et les arêtes. Pour chaque famille, l'indexation et toutes les propriétés sont déterminées indépendamment. Dans ce cas, les arêtes peuvent connecter des sommets de différentes familles.
Vous pouvez attribuer des propriétés spécifiques à une famille de sommets ou d'arêtes qui seront appliquées de manière sélective aux éléments de la famille. La propriété est appliquée si la condition est remplie. La condition se compose d'un modèle évalué comme
true ou
false et d'une expression régulière pour le nom de la fonction. La condition est vérifiée soit uniquement pour le cadre en verre actuel, soit pour tous les cadres en verre (puis elle est considérée comme remplie si elle est satisfaite pour au moins un).
Les propriétés sont très diverses. Pour les sommets: étiquette, couleur de remplissage, couleur de bordure, largeur de bordure, forme, style de bordure (par exemple, ligne pointillée). Pour les bords: étiquette, couleur, largeur, style, orientation (vous pouvez spécifier deux flèches - du début à la fin ou vice versa; dans ce cas, il peut y avoir deux flèches en même temps).
Il est important qu'à chaque fois que le graphe soit dessiné à partir de zéro, l'état précédent ne soit en aucun cas pris en compte. Cela peut être un problème si le graphique change dynamiquement au cours de l'algorithme - les sommets et les bords peuvent changer radicalement leur position, et il est alors difficile de comprendre ce qui se passe.
Une description détaillée de la configuration du graphique peut être trouvée
ici .
Interface utilisateur
Avec l'interface, j'ai décidé de ne pas trop m'embêter. La fenêtre principale avec les paramètres (
ToolWindow ) contient une zone de texte pour la
configuration sérialisée en JSON et une liste des familles de sommets et d'arêtes. Chaque famille a sa propre fenêtre avec des paramètres et chaque propriété de la famille a une fenêtre supplémentaire (trois niveaux d'imbrication sont obtenus). Le graphique lui-même est dessiné dans une fenêtre séparée. Cela n'a pas fonctionné pour le mettre dans ToolWindow, j'ai donc envoyé un
rapport de bogue aux développeurs MSAGL, mais ils ont répondu que ce n'était pas le cas d'utilisation cible.
Un autre rapport de bogue a été envoyé à Visual Studio, car les TextBox se bloquaient parfois dans les fenêtres de paramètres supplémentaires.
Plugin
Afin de configurer le graphe, le plugin a une interface utilisateur et la possibilité de (dé) sérialiser la config en JSON. Le schéma général d'interaction de tous les composants est le suivant:
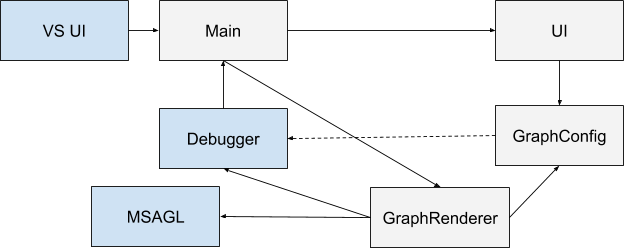
Le bleu montre les composants qui existaient à l'origine, le gris - que j'ai créé. Lorsque Visual Studio démarre, l'extension est initialisée (ici le composant principal est désigné comme Main). L'utilisateur a la possibilité de spécifier la configuration via l'interface. Chaque fois que le contexte du débogueur est modifié, le composant principal est notifié. Si la configuration est définie et que le programme en cours de débogage est exécuté, GraphRenderer est lancé. Il reçoit une entrée de configuration et à l'aide d'un débogueur construit un graphique dessus, qui est ensuite affiché dans une fenêtre spéciale.
Des exemples
En conséquence, j'ai créé un outil qui vous permet de visualiser les algorithmes graphiques et nécessite de petites modifications dans le code. Il a été testé sur huit tâches différentes. Voici quelques photos résultantes:
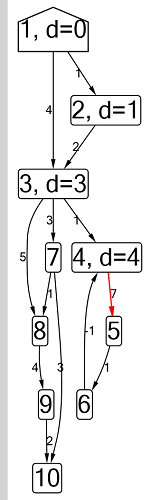 Algorithme de Ford-Bellman : le sommet auquel nous comptons les chemins les plus courts est indiqué par une maison, la distance la plus courte actuellement trouvée pour les sommets est d, et le bord le long duquel passe la relaxation est rouge.
Algorithme de Ford-Bellman : le sommet auquel nous comptons les chemins les plus courts est indiqué par une maison, la distance la plus courte actuellement trouvée pour les sommets est d, et le bord le long duquel passe la relaxation est rouge.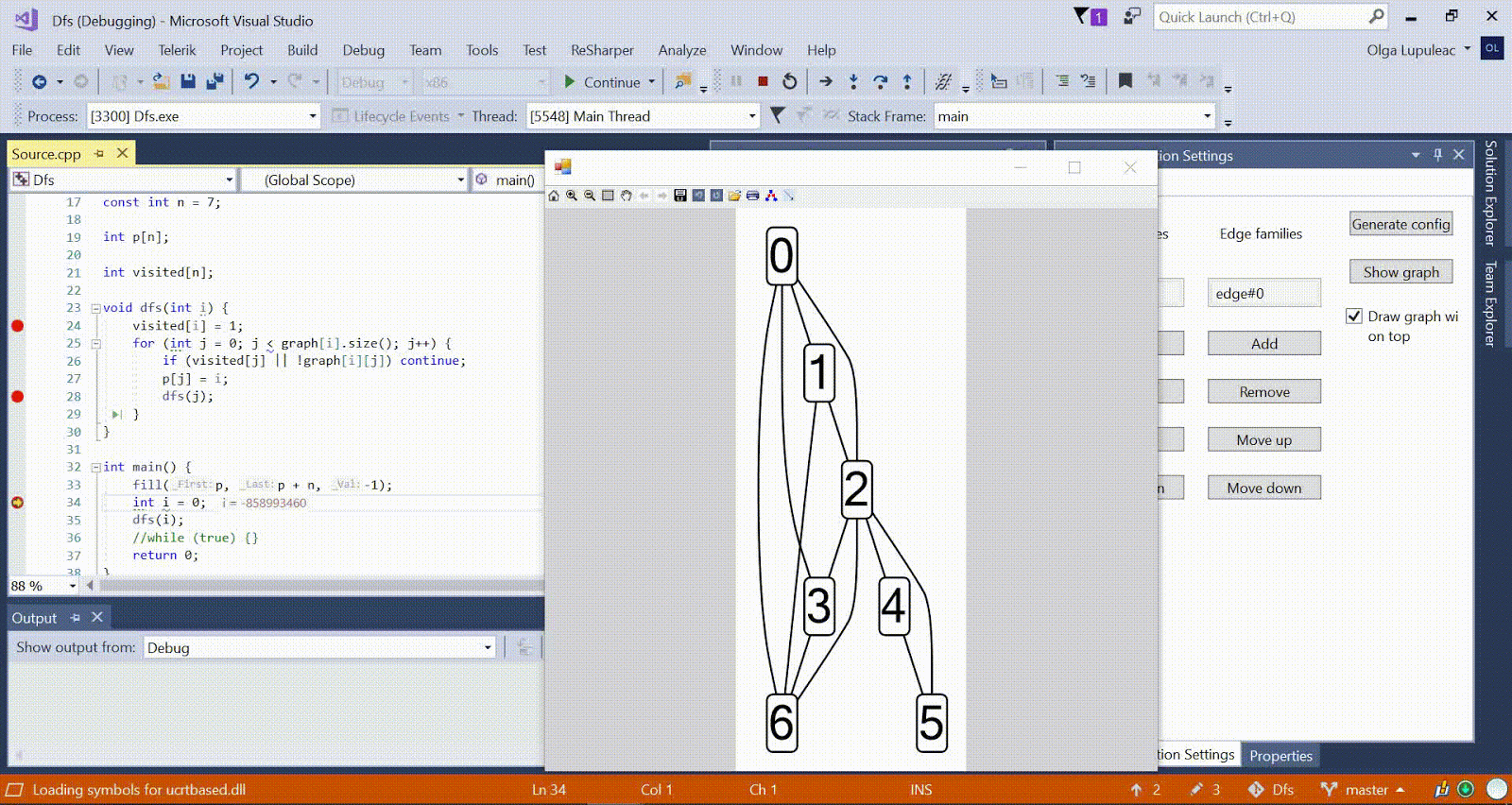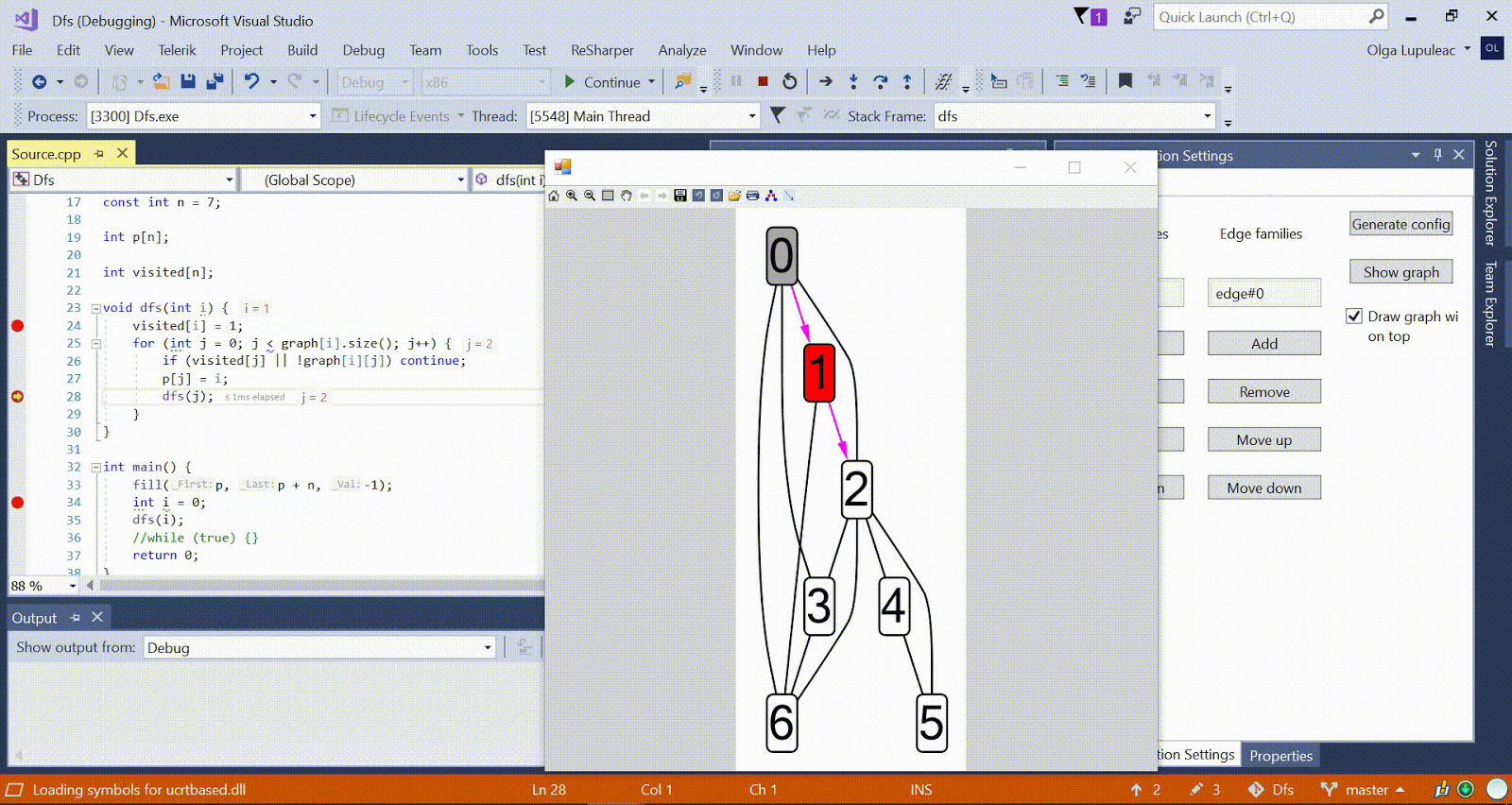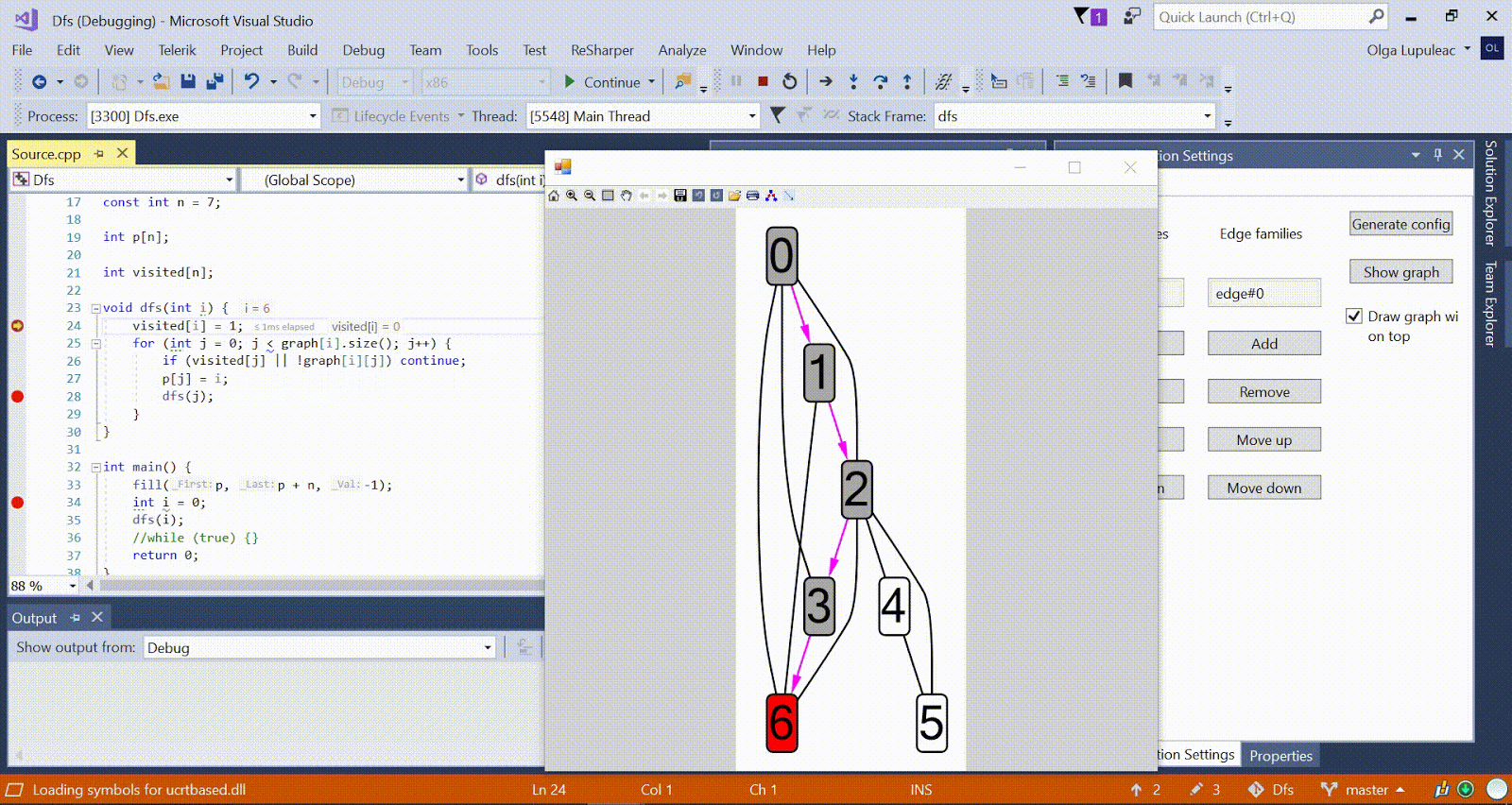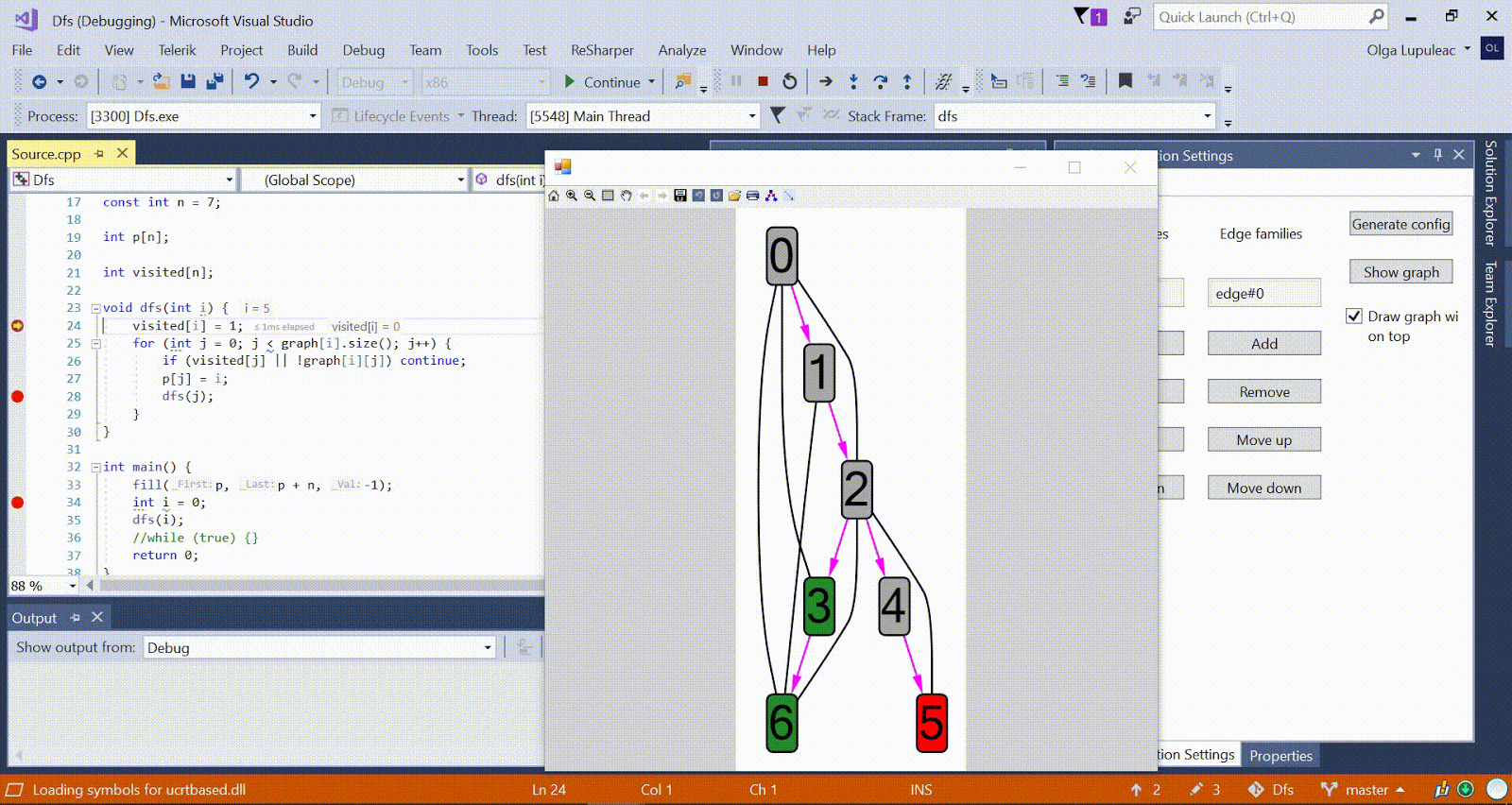 Animation avec DFS - le sommet actuel est affiché en rouge, les sommets de la pile sont gris et les autres sommets visités sont verts. Les côtes framboises indiquent la direction du bypass.
Animation avec DFS - le sommet actuel est affiché en rouge, les sommets de la pile sont gris et les autres sommets visités sont verts. Les côtes framboises indiquent la direction du bypass.D'autres exemples d'algorithmes sont disponibles
ici.Protection NIR
Pour protéger le travail de recherche, les étudiants sont tenus de parler de leur travail pendant un semestre en sept minutes. En même temps, que le sujet ait été proposé dans le cadre de la présentation d'un travail de recherche ou que l'étudiant l'ait trouvé seul, vous devez être en mesure de répondre pour justifier pourquoi le sujet du projet répond aux exigences décrites au début. En règle générale, un rapport est structuré comme suit: il y a d'abord la motivation, puis un examen des analogues, on explique pourquoi ils ne nous conviennent pas, puis des buts et objectifs sont formulés, puis chacune des tâches est décrite comment elle a été résolue. À la fin, il y a une diapositive avec les résultats, qui dit encore une fois que l'objectif a été atteint et que toutes les tâches ont été résolues.
Comme j'avais déjà décidé de la motivation et de la révision des analogues au stade initial, je devais simplement rassembler toutes les informations et les compresser en sept minutes. Au final, j'ai réussi, la défense s'est bien déroulée, on m'a donné le score maximum pour la recherche.
Les références