Dans les grands systèmes cloud, le problème de l'équilibrage automatique ou de l'équilibrage de la charge des ressources informatiques est particulièrement aigu. Tionics s'est également occupé de cette problématique (développeur et opérateur de services cloud, nous faisons partie du groupe Rostelecom).
Et, comme notre plate-forme de développement principale est Openstack et que, comme tout le monde, nous sommes paresseux, il a été décidé de choisir une sorte de module prêt à l'emploi qui fait déjà partie de la plate-forme. Notre choix s'est porté sur Watcher, que nous avons décidé d'utiliser pour nos besoins.

Voyons d'abord les termes et définitions.
Termes et définitions
Un objectif est un résultat final lisible par l'homme, observable et mesurable qui doit être atteint. Pour atteindre chaque objectif, il existe une ou plusieurs stratégies. Une stratégie est une implémentation d'un algorithme capable de trouver une solution pour un objectif donné.
Une action est une tâche élémentaire qui modifie l'état actuel d'une ressource gérée cible d'un cluster OpenStack, telle que: la migration d'une machine virtuelle (migration), la modification de l'état de l'alimentation d'un nœud (change_node_power_state), la modification de l'état d'un service nova (change_nova_service_state), la modification d'une saveur (redimensionnement) , enregistrement d'un message NOP (nop), absence d'actions pendant un certain temps - pause (sommeil), transfert de disque (volume_migrate).
Plan d'action (Plan d'action) - un flux spécifique d'actions menées dans un ordre spécifique pour atteindre un objectif spécifique. Le plan d'action contient également une estimation de la performance globale avec un ensemble d'indicateurs de performance. Le plan d'action est généré par Watcher lors d'un audit réussi, à la suite de quoi la stratégie utilisée trouve une solution pour atteindre l'objectif. Un plan d'action consiste en une liste d'actions séquentielles.
L'audit est une demande d'optimisation de cluster. L'optimisation est effectuée afin d'atteindre un objectif dans un cluster donné. Pour chaque audit réussi, Watcher génère un plan d'action.
L'étendue de l'audit est un ensemble de ressources au sein desquelles un audit est effectué (zone (s) de disponibilité, agrégateurs de nœuds, nœuds de calcul individuels ou nœuds de stockage, etc.). Une portée d'audit est définie dans chaque modèle. Si l'étendue de l'audit n'est pas spécifiée, l'ensemble du cluster est audité.
Modèle d'audit - Un ensemble enregistré de paramètres pour démarrer un audit. Des modèles sont nécessaires pour exécuter des audits avec les mêmes paramètres plusieurs fois. Le modèle doit nécessairement contenir le but de l'audit, si les stratégies ne sont pas indiquées, alors les stratégies existantes les plus appropriées sont sélectionnées.
Un cluster est un ensemble de machines physiques qui fournissent des ressources informatiques, de stockage et de réseau et sont gérées par le même nœud de contrôle OpenStack.
Le modèle de données de cluster (CDM) est une représentation logique de l'état actuel et de la topologie des ressources gérées en cluster.
Indicateur d'efficacité (indicateur d'efficacité) - un indicateur qui indique comment la solution créée à l'aide de cette stratégie est mise en œuvre. Les indicateurs de performance sont spécifiques à un objectif particulier et sont couramment utilisés pour calculer l'efficacité globale d'un plan d'action final.
La spécification d'efficacité est un ensemble de caractéristiques spécifiques associées à chaque objectif, qui définit divers indicateurs de performance que la stratégie assurant la réalisation de l'objectif correspondant doit fournir dans sa décision. En effet, chaque solution proposée par la stratégie sera vérifiée pour la conformité au cahier des charges avant de calculer son efficacité globale.
Un «moteur de notation» est un fichier exécutable qui a des entrées bien définies, des sorties bien définies et effectue une tâche purement mathématique. Ainsi, le calcul ne dépend pas de l'environnement dans lequel il est effectué - il donnera le même résultat n'importe où.
Watcher Planner fait partie du moteur de décision Watcher. Ce module accepte l'ensemble des actions générées par la stratégie et crée un plan de workflow qui définit comment planifier ces différentes actions dans le temps et pour chaque action, quelles sont les conditions préalables.
Objectifs et stratégies des observateurs
Objectif fictif -
objectif de réserve utilisé à des fins de test.
Stratégies associées: Stratégie factice, Stratégie factice utilisant des exemples de moteurs de notation et Stratégie factice avec redimensionnement. La stratégie factice est une stratégie factice utilisée pour les tests d'intégration via Tempest. Cette stratégie ne fournit aucune optimisation utile; son seul but est d'utiliser des tests Tempest.
Stratégie fictive utilisant des exemples de moteurs de notation - la stratégie est similaire à la précédente, elle ne diffère que par l'utilisation de l'échantillon «moteur d'évaluation», qui effectue des calculs à l'aide de méthodes d'apprentissage automatique.
Stratégie factice avec redimensionnement - la stratégie est similaire à la précédente, elle ne diffère que par l'utilisation du changement de saveur (migration et redimensionnement).
Non utilisé en production.
Économie d'énergie - minimisez la consommation d'énergie. Stratégie pour cet objectif La stratégie d'économie d'énergie en conjonction avec la stratégie de consolidation de la charge de travail VM (consolidation de serveur) est capable d'exécuter des fonctions de gestion dynamique de l'alimentation (DPM), qui économisent de l'énergie en consolidant dynamiquement les charges de travail même pendant les périodes de faible charge de ressources: les machines virtuelles sont transférées vers moins de nœuds et les nœuds inutiles sont déconnectés. Après la consolidation, la stratégie propose une décision d'activer / désactiver les nœuds en fonction des paramètres donnés: «min_free_hosts_num» - le nombre de nœuds inclus libres qui attendent la charge, et «free_used_percent» - le pourcentage de nœuds inclus gratuits par rapport au nombre de nœuds occupés par les machines. Pour que la stratégie
fonctionne, Ironic doit être
allumé et configuré pour fonctionner avec la mise sous / hors tension des nœuds.Options stratégiques
Il doit y avoir au moins deux nœuds dans le cloud. La méthode utilisée consiste à modifier l'état d'alimentation du nœud (change_node_power_state).
La stratégie ne nécessite pas de collecte de métriques.Consolidation du serveur - minimisez le nombre de nœuds de calcul (consolidation). Il a deux stratégies: Consolidation de serveur hors ligne de base et Stratégie de consolidation de charge de travail VM.
La stratégie de consolidation de serveurs hors ligne de base minimise le nombre total de serveurs utilisés et minimise également le nombre de migrations.
La stratégie de base nécessite les mesures suivantes:
Paramètres de stratégie: migration_attempts - le nombre de combinaisons pour rechercher des candidats potentiels à l'arrêt (par défaut, 0, aucune restriction), période - intervalle de temps en secondes pour obtenir une agrégation statique à partir de la source de données métrique (par défaut, 700).
Méthodes utilisées: migration, changement d'état du service nova (change_nova_service_state).
La stratégie de consolidation de la charge de travail VM est basée sur l'algorithme heuristique de premier ajustement, qui se concentre sur la charge CPU mesurée et tente de minimiser les nœuds qui ont trop ou trop peu de charge, en tenant compte des limitations de capacité des ressources. Cette stratégie fournit une solution qui conduit à une utilisation plus efficace des ressources de cluster en utilisant les quatre étapes suivantes:
- Phase de déchargement - traitement des ressources surutilisées;
- Phase de consolidation - traitement des ressources sous-utilisées;
- Optimisation de la solution - réduction du nombre de migrations;
- Désactivation des nœuds de calcul inutilisés.
La stratégie nécessite les mesures suivantes:
Les mesures suivantes sont facultatives, mais améliorent la précision de la stratégie si elles sont disponibles:
Paramètres de stratégie: période - intervalle de temps en secondes pour obtenir une agrégation statique à partir de la source de données métrique (3600 par défaut).
Utilise les mêmes méthodes que la stratégie précédente. Plus de détails
ici .
Équilibrage de la charge de travail - équilibrez la charge de travail entre les nœuds de calcul. L'objectif comprend trois stratégies: stratégie de migration de l'équilibre de la charge de travail, stabilisation de la charge de travail, stratégie d'équilibre de la capacité de stockage.
La stratégie de migration de Workload Balance lance des migrations de machines virtuelles basées sur la charge de travail des machines virtuelles hôtes. La décision de transfert est prise chaque fois que le% d'utilisation du CPU ou de la RAM du nœud dépasse le seuil spécifié. Dans ce cas, la machine virtuelle déplacée doit rapprocher le nœud de la charge de travail moyenne de tous les nœuds.
Prérequis
- Utilisation de processeurs physiques;
- Au moins deux nœuds de calcul physiques;
- Le composant Ceilometer installé et configuré est le ceilometer-agent-compute travaillant sur chaque nœud informatique et l'API Ceilometer, ainsi que la collecte des métriques suivantes:
Options stratégiques:
La méthode utilisée est la migration.
Stabilisation de la charge de travail - une stratégie visant à stabiliser la charge de travail à l'aide de la migration en direct. La stratégie est basée sur l'algorithme d'écart type et détermine s'il y a congestion dans le cluster et y répond en déclenchant la migration de la machine pour stabiliser le cluster.
Prérequis
- Utilisation de processeurs physiques;
- Au moins deux nœuds de calcul physiques;
- Le composant Ceilometer installé et configuré est le ceilometer-agent-compute travaillant sur chaque nœud informatique et l'API Ceilometer, ainsi que la collecte des métriques suivantes:
Stratégie d'équilibrage de la capacité de stockage (stratégie mise en œuvre depuis Queens) - la stratégie transfère les disques en fonction de la charge des pools Cinder. La décision de transfert est prise chaque fois que l'utilisation du pool dépasse le seuil spécifié. Un disque itinérant devrait rapprocher le pool de la charge moyenne de tous les pools Cinder.
Exigences et limitations
- Au moins deux piscines Cinder;
- Possibilité de migrer des disques.
- Collecteur de modèles de données de cluster.
Options stratégiques:
La méthode utilisée est la migration de disque (volume_migrate).
Noisy Neighbour - identifiez et migrez un «voisin bruyant» - une machine virtuelle de faible priorité qui affecte négativement les performances d'une machine virtuelle de haute priorité d'un point de vue IPC, en utilisant le cache de dernier niveau. Propre stratégie: voisin bruyant (le paramètre de stratégie utilisé est cache_threshold (la valeur par défaut est 35), la migration démarre lorsque les performances chutent à la valeur spécifiée. Pour que la stratégie fonctionne, les
métriques LLC (Last Level Cache) incluses
, le dernier serveur Intel avec prise en charge CMT , et également collection des métriques suivantes:
Modèle de données de cluster (par défaut): collecteur de modèles de données de cluster Nova. La méthode appliquée est la migration.
Le travail à cet effet via Dashboard n'est pas entièrement implémenté dans le Queens.
Optimisation thermique - optimisez les conditions de température. La température de sortie (air d'échappement) est l'un des systèmes de télémétrie thermique importants pour mesurer l'état de la charge thermique / de travail du serveur. À cet effet, il existe une stratégie - Stratégie basée sur la température de sortie, qui prend des décisions sur le transfert des charges de travail vers des nœuds avec des conditions de température favorables (la température la plus basse à la sortie) lorsque la température à la sortie des hôtes d'origine atteint un seuil personnalisé.
Pour que la stratégie fonctionne, vous avez besoin d'un serveur avec et installé Intel Power Node Manager
3.0 ou version ultérieure , ainsi que la collecte des mesures suivantes:
Options stratégiques:
La méthode utilisée est la migration.
Optimisation du flux d'air - optimisez le mode de ventilation. Propre stratégie - Uniform Airflow utilisant la migration en direct. La stratégie démarre la migration de la machine virtuelle chaque fois que le flux d'air du ventilateur du serveur dépasse le seuil spécifié.
Pour fonctionner, la stratégie nécessite:
- Matériel: nœuds de calcul <avec prise en charge de NodeManager 3.0;
- Au moins deux nœuds de calcul;
- Les composants de l'API ceilometer-agent-compute et Ceilometer installés et configurés sur chaque nœud informatique peuvent signaler avec succès des mesures telles que le débit d'air, la puissance du système et la température d'entrée:
Pour que la stratégie fonctionne, vous avez besoin d'un serveur avec Intel Power Node Manager 3.0 ou version ultérieure installé et configuré.
Limitations: Le concept n'est pas destiné à la production.
Il est proposé d'utiliser cet algorithme avec des audits continus, car une seule machine virtuelle devrait être migrée par itération.
Des migrations en direct sont possibles.
Options stratégiques:
La méthode utilisée est la migration.
Maintenance matérielle - maintenance matérielle. Une stratégie liée à cet objectif est la migration de zone. La stratégie est un outil pour une migration automatique efficace et minimale des machines virtuelles et des disques en cas de maintenance matérielle. La stratégie construit un plan d'action en fonction des pondérations: un ensemble d'actions plus pondérées sera planifié avant les autres. Il existe deux options de configuration: les poids d'action (poids_action) et la parallélisation.
Limitations: il est nécessaire d'ajuster les échelles d'actions et de parallélisation.
Options stratégiques:
Éléments d'un tableau de nœuds de calcul:
Éléments d'un tableau de nœuds de stockage:
Éléments des objets prioritaires:
Méthodes utilisées - migration de machines virtuelles, migration de disques.
Non classé est un objectif de soutien utilisé pour faciliter l'élaboration d'une stratégie. Il ne contient pas de spécifications et peut être utilisé chaque fois que la stratégie n'est pas encore liée à un objectif existant. Cet objectif peut également être utilisé comme étape de transition. Une stratégie connexe est Actuator.
Créez un nouvel objectif
Le Watcher Decision Engine possède une interface de plug-in «objectif externe» qui vous permet d'intégrer un objectif externe qui peut être atteint à l'aide d'une stratégie.
Avant de créer un nouvel objectif, vous devez vous assurer qu'aucun des objectifs existants ne répond à vos besoins.
Créer un nouveau plugin
Pour créer une nouvelle cible, vous devez: étendre la classe cible, implémenter la méthode de classe
get_name () pour renvoyer un identifiant unique pour la nouvelle cible que vous souhaitez créer. Cet identifiant unique doit correspondre au nom du point d'entrée que vous déclarerez ultérieurement.
Ensuite, vous devez implémenter la méthode de classe
get_display_name () pour renvoyer le nom d'affichage traduit de la cible que vous souhaitez créer (n'utilisez pas la variable pour renvoyer la chaîne traduite afin qu'elle puisse être automatiquement collectée par l'outil de traduction.).
Implémentez la méthode de classe
get_translatable_display_name () pour renvoyer la clé de traduction (en fait le nom d'affichage anglais) de votre nouvelle cible. La valeur de retour doit correspondre à la chaîne traduite en get_display_name ().
Implémentez sa méthode
get_efficacy_specification () pour renvoyer une spécification de performance pour votre objectif. La méthode get_efficacy_specification () renvoie l'instance Unclassified () fournie par Watcher. Cette spécification de performance est utile dans le processus de développement de votre objectif car elle répond à la spécification vide.
→
Plus de détails iciArchitecture Watcher (plus d'infos
ici ).
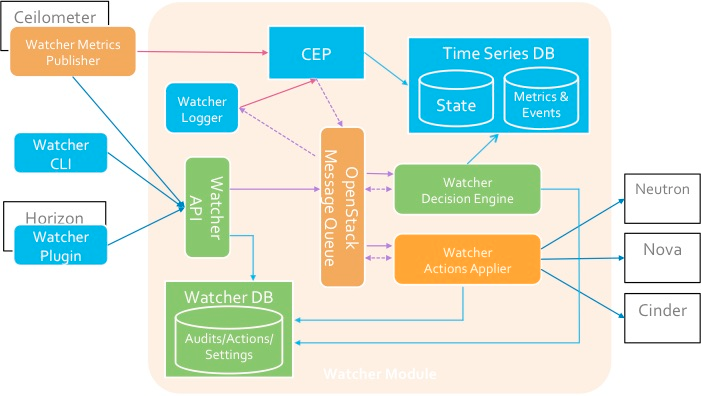
Composants
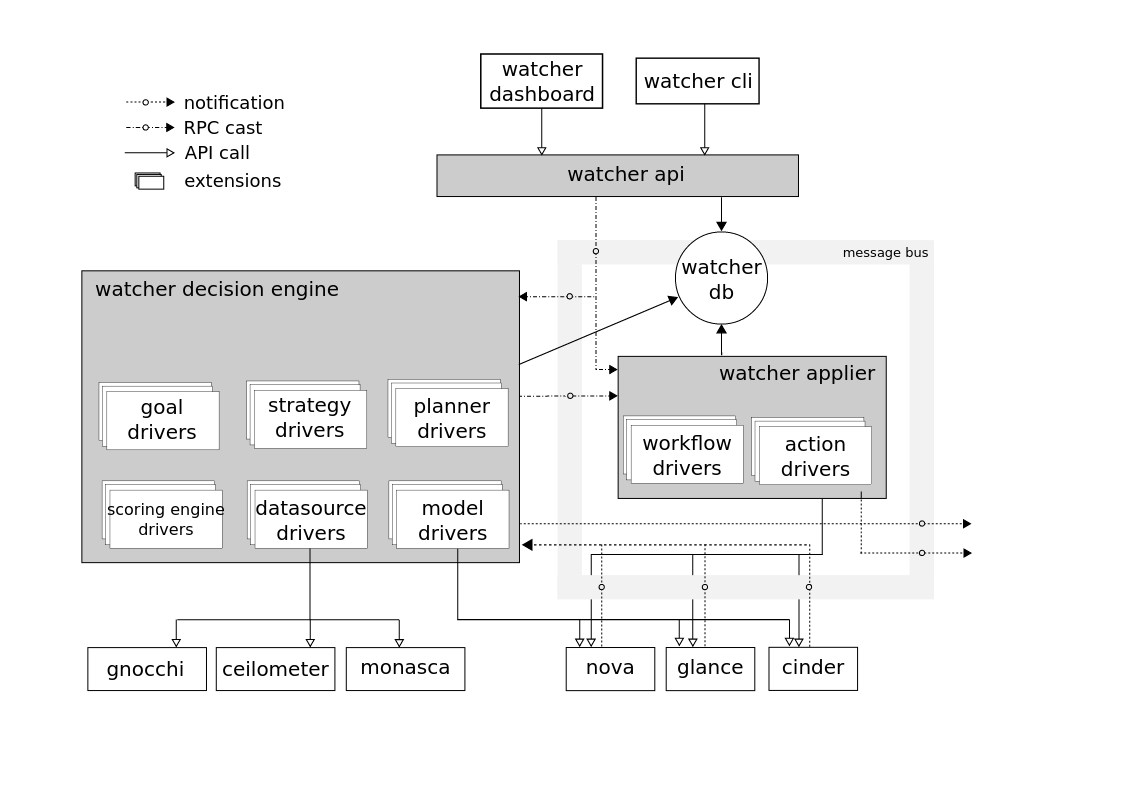 API Watcher
API Watcher - un composant qui implémente l'API REST fournie par Watcher. Mécanismes d'interaction: CLI, plugin Horizon, SDK Python.
Watcher DB - Base de données Watcher.
Watcher Applier - un composant qui implémente la mise en œuvre du plan d'action créé par le composant Watcher Decision Engine.
Le Watcher Decision Engine est un composant chargé de calculer un ensemble d'actions d'optimisation potentielles pour atteindre un objectif d'audit. Si aucune stratégie n'est spécifiée, le composant sélectionne indépendamment la plus appropriée.Watcher Metrics Publisher est un composant qui collecte et calcule certaines métriques ou événements et les publie au point de terminaison CEP. Les fonctionnalités peuvent également être fournies par l'éditeur Ceilometer.Moteur de traitement d'événements complexes (CEP)- moteur de traitement d'événements complexes. Pour des raisons de performances, plusieurs instances du moteur CEP peuvent s'exécuter en même temps, chacune d'entre elles gérant un type spécifique de métrique / événement. Dans le système Watcher, le CEP lance deux types d'actions: - écrire les événements / métriques correspondants dans la base de données des séries temporelles; - envoyer des événements pertinents au composant Watcher Decision Engine lorsque cet événement peut affecter le résultat de la stratégie d'optimisation actuelle, car le cluster Openstack n'est pas un système statique.L'interaction des composants est réalisée selon le protocole AMQP.→ Configuration de WatcherSchéma d'interaction avec Watcher

Résultats des tests des observateurs
- Optimization — Action plans 500 ( Queens, ), , , .
- Action details , ( Queens, ).
- Dummy () , .
- Unclassified , .
- Workload Balancing ( Storage Capacity balance) , . .
- Workload Balancing ( Workload Balance Migration Strategy) , .
- Workload Balancing ( Workload Stabilization Strategy) .
- Noisy Neighbor , .
- Hardware maintenance , ( , ).
- nova.conf ( default compute_monitors = cpu.virt_driver) .
- Server Consolidation ( Basic) .
- Server Consolidation ( VM workload consolidation) . . , , .
- Watcher ( — Optimization, - ):
[watcher_strategies.basic]
datasource = ceilometer, gnocchi - Saving Energy . , - Ironic, baremetal service.
- Thermal Optimization . , Server Consolidation ( VM workload consolidation) ( )
- Les audits pour Airflow Optimization échouent.
Les erreurs de fin d'audit suivantes sont également rencontrées. Traceback dans les journaux decision-engine.log (l'état du cluster n'est pas défini).→ Discussion de l'erreur iciConclusion
Le résultat de nos recherches de deux mois a été la conclusion sans équivoque que pour obtenir un système d'équilibrage de charge à part entière, nous devrons travailler en étroite collaboration pour finaliser les outils de la plate-forme Openstack.Watcher s'est avéré être un produit sérieux et en développement rapide avec un énorme potentiel, pour la pleine utilisation duquel beaucoup de travail sérieux sera requis.Mais plus à ce sujet dans les prochains articles du cycle.