Cet article décrit l'implémentation la plus simple de la RAM dans Verilog.
Avant de procéder à l'analyse de code, il est recommandé d'apprendre la syntaxe de base de Verilog.
Vous trouverez ici du matériel de formation .
RAM
Étape 1: déclaration du module avec les signaux d'entrée / sortie correspondants
module ram ( input [word_size - 1:0] data, input [word_size - 1:0] addr, input wr, input clk, output response, output [word_size - 1:0] out ); parameter word_size = 32;
- données - données à écrire.
- addr - adresse de la mémoire en RAM.
- wr - état (lecture / écriture).
- clk - système de cycle d'horloge.
- réponse - état de préparation de la RAM (1 - si la RAM a traité la demande de lecture / écriture, 0 - sinon).
- out - données lues dans la RAM.
Cette implémentation a été intégrée dans Altera Max 10 FPGA, qui a une architecture 32 bits, et donc la taille des données et de l'adresse (word_size) est de 32 bits.
Étape 2: déclarer les registres à l'intérieur du module
Une déclaration de tableau pour stocker des données:
parameter size = 1<<32; reg [word_size-1:0] ram [size-1:0];
Nous devons également stocker les paramètres d'entrée précédents afin de suivre leurs modifications dans le bloc Always:
reg [word_size-1:0] data_reg; reg [word_size-1:0] addr_reg; reg wr_reg;
Et les deux derniers registres pour mettre à jour les signaux de sortie après les calculs dans le bloc toujours:
reg [word_size-1:0] out_reg; reg response_reg;
Nous initialisons les registres:
initial begin response_reg = 1; data_reg = 0; addr_reg = 0; wr_reg = 0; end
Étape 3: implémenter la logique toujours du bloc
always @(negedge clk) begin if ((data != data_reg) || (addr%size != addr_reg)|| (wr != wr_reg)) begin response_reg = 0; data_reg = data; addr_reg = addr%size; wr_reg = wr; end else begin if (response_reg == 0) begin if (wr) ram[addr] = data; else out_reg = ram[addr]; response_reg = 1; end end end
Toujours bloquer est déclenché par negedje, c.-à-d. au moment où l'horloge passe de 1 à 0. Ceci est fait pour synchroniser correctement la RAM avec le cache. Sinon, il peut y avoir des cas où la RAM n'a pas le temps de réinitialiser l'état prêt de 1 à 0 et à l'horloge suivante, le cache décide que la RAM a traité avec succès sa demande, ce qui est fondamentalement faux.
La logique de l'algorithme toujours du bloc est la suivante: si les données sont mises à jour, remettre l'état de préparation à 0 et écrire / lire les données, si l'écriture / lecture est terminée, nous mettons à jour l'état de préparation à 1.
À la fin, ajoutez la section de code suivante:
assign out = out_reg; assign response = response_reg;
Le type de signaux de sortie de notre module est filaire. La seule façon de modifier les signaux de ce type est l'affectation à long terme, qui est interdite à l'intérieur du bloc Always. Pour cette raison, le bloc Always utilise des registres, qui sont ensuite affectés aux signaux de sortie.
Cache de mappage direct
Le cache de mappage direct est l'un des types de cache les plus simples. Dans cette implémentation, le cache se compose de n éléments, et la RAM est conditionnellement divisée en blocs par n, puis le i-ème élément dans le cache correspond à tous ces k-èmes éléments en RAM qui satisfont la condition i = k% n.
L'image ci-dessous montre un cache de taille 4 et une mémoire RAM de taille 16.
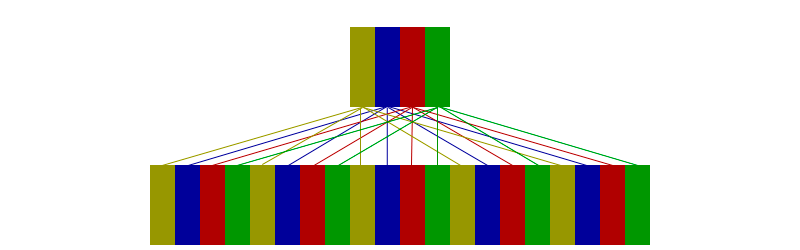
Chaque élément de cache contient les informations suivantes:
- bit de validité - si les informations dans le cache sont pertinentes.
- tag est le numéro de bloc dans la RAM où se trouve cet élément.
- données - informations que nous écrivons / lisons.
Lorsqu'on lui demande de lire, le cache divise l'adresse d'entrée en deux parties - une balise et un index. La taille de l'index est log (n), où n est la taille du cache.
Étape 1: déclaration du module avec les signaux d'entrée / sortie correspondants
module direct_mapping_cache ( input [word_size-1:0] data, input [word_size-1:0] addr, input wr, input clk, output response, output is_missrate, output [word_size-1:0] out ); parameter word_size = 32;
La déclaration du module de cache est identique à la RAM, à l'exception du nouveau signal de sortie is_missrate. Cette sortie stocke des informations indiquant si la dernière demande de lecture a été un taux d'erreur.
Étape 2: déclaration des registres et de la RAM
Avant de déclarer les registres, nous déterminons la taille du cache et de l'index:
parameter size = 64; parameter index_size = 6;
Ensuite, nous déclarons un tableau dans lequel les données que nous écrivons et lisons seront stockées:
reg [word_size-1:0] data_array [size-1:0];
Nous devons également stocker des bits de validité et des balises pour chaque élément dans le cache:
reg validity_array [size-1:0]; reg [word_size-index_size-1:0] tag_array [size-1:0]; reg [index_size-1:0] index_array [size-1:0];
Registres dans lesquels l'adresse d'entrée sera divisée:
reg [word_size-index_size-1:0] tag; reg [index_size-1:0] index;
Registres qui stockent les valeurs d'entrée sur l'horloge précédente (pour suivre les changements dans les données d'entrée):
reg [word_size-1:0] data_reg; reg [word_size-1:0] addr_reg; reg wr_reg;
Registres pour la mise à jour des signaux de sortie après les calculs dans le bloc toujours:
reg response_reg; reg is_missrate_reg; reg [word_size-1:0] out_reg;
Valeurs d'entrée pour la RAM:
reg [word_size-1:0] ram_data; reg [word_size-1:0] ram_addr; reg ram_wr;
Valeurs de sortie pour la RAM:
wire ram_response; wire [word_size-1:0] ram_out;
Déclaration d'un module RAM et connexion des signaux d'entrée et de sortie:
ram ram( .data(ram_data), .addr(ram_addr), .wr(ram_wr), .clk(clk), .response(ram_response), .out(ram_out));
Initialisation du registre:
initial integer i initial begin data_reg = 0; addr_reg = 0; wr_reg = 0; for (i = 0; i < size; i=i+1) begin data_array[i] = 0; tag_array[i] = 0; validity_array[i] = 0; end end
Étape 3: implémenter la logique toujours du bloc
Pour commencer, pour chaque horloge, nous avons deux états - les données d'entrée sont modifiées ou non. Sur cette base, nous avons la condition suivante:
always @(posedge clk) begin if (data_reg != data || addr_reg != addr || wr_reg != wr) begin end // 1: else begin // 2: end end
Bloc 1. Dans le cas où les données d'entrée sont modifiées, la première chose que nous faisons est de réinitialiser l'état de préparation à 0:
response_reg = 0;
Ensuite, nous mettons à jour les registres qui stockaient les valeurs d'entrée de l'horloge précédente:
data_reg = data; addr_reg = addr; wr_reg = wr;
Nous divisons l'adresse d'entrée en une balise et un index:
tag = addr >> index_size; index = addr;
Pour calculer la balise, un décalage bit à droite est utilisé, pour l'index, il suffit de simplement l'affecter, car Les bits supplémentaires de l'adresse ne sont pas pris en compte.
L'étape suivante consiste à choisir entre l'écriture et la lecture:
if (wr) begin // data_array[index] = data; tag_array[index] = tag; validity_array[index] = 1; ram_data = data; ram_addr = addr; ram_wr = wr; end else begin // if ((validity_array[index]) && (tag == tag_array[index])) begin // is_missrate_reg = 0; out_reg = data_array[index]; response_reg = 1; end else begin // is_missrate_reg = 1; ram_data = data; ram_addr = addr; ram_wr = wr; end end
Dans le cas de l'enregistrement, nous modifions d'abord les données dans le cache, puis mettons à jour les données d'entrée pour la RAM. Dans le cas de la lecture, on vérifie la présence de cet élément dans le cache et, s'il existe, on l'écrit dans out_reg, sinon on accède à la RAM.
Bloc 2. Si les données n'ont pas été modifiées depuis l'exécution de l'horloge précédente, nous avons alors le code suivant:
if ((ram_response) && (!response_reg)) begin if (wr == 0) begin validity_array [index] = 1; data_array [index] = ram_out; tag_array[index] = tag; out_reg = ram_out; end response_reg = 1; end
Ici, nous attendons la fin de l'accès à la RAM (s'il n'y avait pas d'accès, ram_response est 1), mettons à jour les données s'il y avait une commande de lecture et définissons la préparation du cache à 1.
Et enfin, mettez à jour les valeurs de sortie:
assign out = out_reg; assign is_missrate = is_missrate_reg; assign response = response_reg;