La collecte, le stockage, la conversion et la présentation des données sont les principaux défis auxquels sont confrontés les ingénieurs de données. Le département Business Intelligence Badoo reçoit et traite plus de 20 milliards d'événements envoyés depuis les appareils des utilisateurs par jour, soit 2 To de données entrantes.
L'étude et l'interprétation de toutes ces données ne sont pas toujours une tâche triviale, il devient parfois nécessaire d'aller au-delà des capacités des bases de données toutes faites. Et si vous avez le courage et décidé de faire quelque chose de nouveau, vous devez d'abord vous familiariser avec les principes de fonctionnement des solutions existantes.
En un mot, développeurs curieux et forts d'esprit, cet article est adressé. Vous y trouverez une description du modèle traditionnel d'exécution de requêtes dans des bases de données relationnelles en utilisant le langage de démonstration PigletQL comme exemple.
Table des matières
Contexte
Notre groupe d'ingénieurs est engagé dans les backends et les interfaces, offrant des opportunités d'analyse et de recherche de données au sein de l'entreprise (en passant, nous nous développons ). Nos outils standard sont une base de données distribuée de dizaines de serveurs (Exasol) et un cluster Hadoop pour des centaines de machines (Hive et Presto).
La plupart des requêtes vers ces bases de données sont analytiques, c'est-à-dire affectant des centaines de milliers à des milliards d'enregistrements. Leur exécution prend des minutes, des dizaines de minutes voire des heures, selon la solution utilisée et la complexité de la demande. Avec le travail manuel de l'utilisateur-analyste, ce temps est considéré comme acceptable, mais ne convient pas à la recherche interactive via l'interface utilisateur.
Au fil du temps, nous avons mis en évidence les requêtes analytiques populaires et les requêtes, qui sont difficiles à définir en termes de SQL, et avons développé pour elles de petites bases de données spécialisées. Ils stockent un sous-ensemble de données dans un format adapté aux algorithmes de compression légers (par exemple, streamvbyte), ce qui vous permet de stocker des données sur une seule machine pendant plusieurs jours et d'exécuter des requêtes en quelques secondes.
Les premières langues de requête pour ces données et leurs interprètes ont été implémentées sur une intuition, nous avons dû les affiner constamment, et chaque fois cela prenait un temps inacceptable.
Les langages de requête n'étaient pas suffisamment flexibles, bien qu'il n'y ait aucune raison évidente de limiter leurs capacités. En conséquence, nous nous sommes tournés vers l'expérience des développeurs d'interprètes SQL, grâce auxquels nous avons pu résoudre partiellement les problèmes qui se sont posés.
Ci-dessous, je parlerai du modèle d'exécution de requête le plus courant dans les bases de données relationnelles - Volcano. Le code source de l'interpréteur du dialecte SQL primitif, PigletQL , est joint à l'article , de sorte que toutes les personnes intéressées peuvent facilement se familiariser avec les détails du référentiel.
Structure d'interpréteur SQL
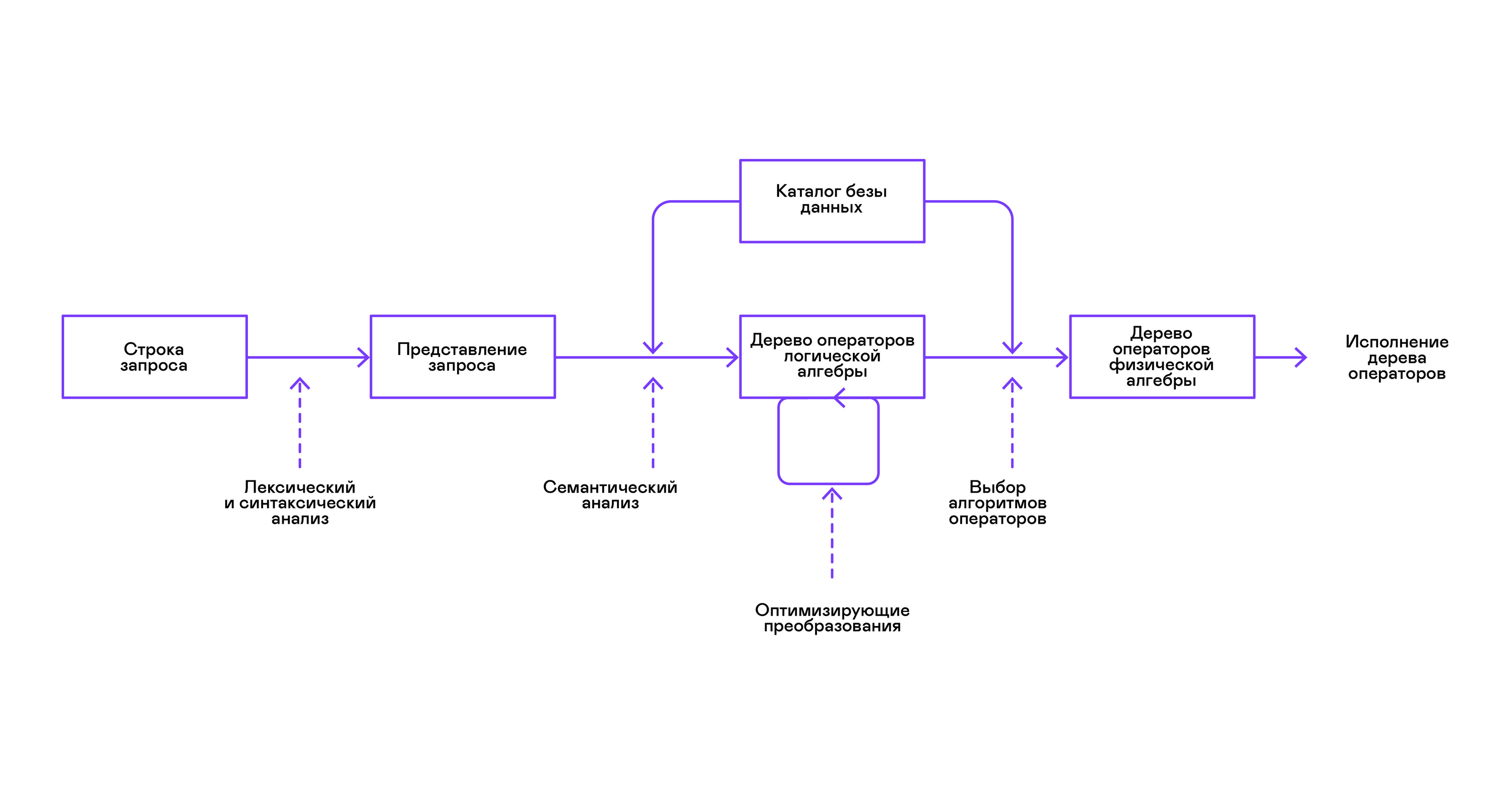
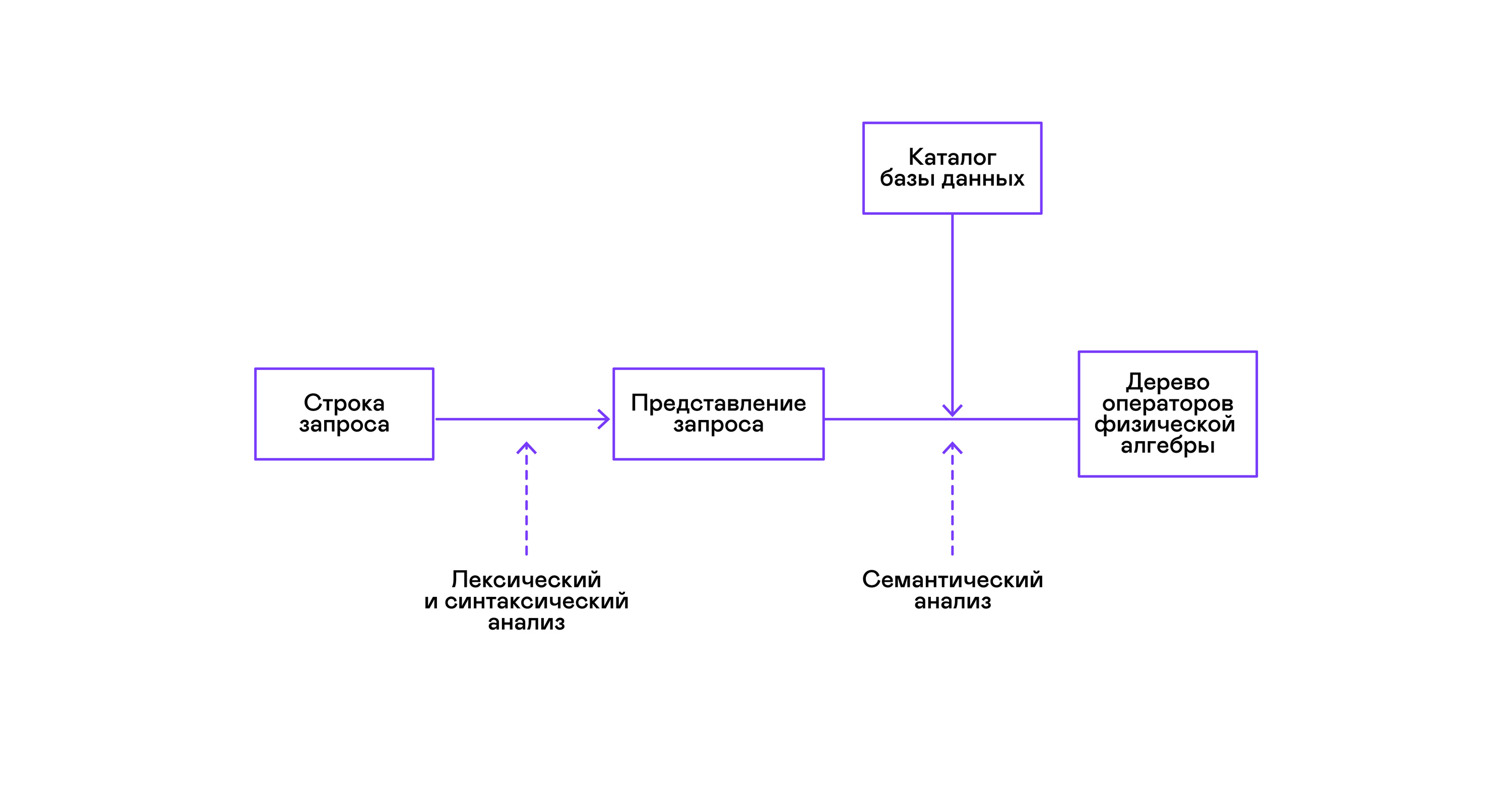
Les bases de données les plus populaires fournissent une interface aux données sous la forme d'un langage de requête SQL déclaratif. Une requête sous la forme d'une chaîne est convertie par l'analyseur en une description de la requête, semblable à une arborescence de syntaxe abstraite. Il est possible d'exécuter des requêtes simples déjà à ce stade, cependant, pour optimiser les transformations et l'exécution ultérieure, cette représentation n'est pas pratique. Dans les bases de données que je connais, des représentations intermédiaires sont introduites à ces fins.
L'algèbre relationnelle est devenue un modèle de représentations intermédiaires. Il s'agit d'un langage dans lequel les transformations ( opérateurs ) effectuées sur les données sont explicitement décrites: sélection d'un sous-ensemble de données selon un prédicat, combinaison de données provenant de différentes sources, etc. De plus, l'algèbre relationnelle est une algèbre au sens mathématique, c'est-à-dire un grand nombre d'équivalents transformations. Par conséquent, il est pratique d'effectuer des transformations d'optimisation sur une requête sous la forme d'un arbre d'opérateurs d'algèbre relationnelle.
Il existe des différences importantes entre les représentations internes dans les bases de données et l'algèbre relationnelle d'origine, il est donc plus correct de l'appeler algèbre logique .
La vérification de la validité d'une requête est généralement effectuée lors de la compilation de la représentation initiale de la requête en opérateurs d'algèbre logique et correspond au stade de l'analyse sémantique dans les compilateurs conventionnels. Le rôle de la table des symboles dans les bases de données est joué par le répertoire de base de données , qui stocke des informations sur le schéma et les métadonnées de la base de données: tables, colonnes de table, index, droits d'utilisateur, etc.
Par rapport aux interprètes à usage général, les interprètes de base de données ont une particularité de plus: les différences de volume de données et les méta-informations sur les données auxquelles les requêtes sont censées être adressées. Dans les tables ou les relations en termes d'algèbre relationnelle, il peut y avoir une quantité différente de données, sur certaines colonnes ( attributs de relation) des index peuvent être construits, etc. Autrement dit, selon le schéma de la base de données et la quantité de données dans les tables, la requête doit être effectuée par différents algorithmes et utilisez-les dans un ordre différent.
Pour résoudre ce problème, une autre représentation intermédiaire est introduite - l'algèbre physique . Selon la disponibilité des index sur les colonnes, la quantité de données dans les tables et la structure de l'arbre d'algèbre logique, différentes formes de l'arbre d'algèbre physique sont proposées, parmi lesquelles la meilleure option est choisie. C'est cet arbre qui est affiché dans la base de données sous forme de plan de requête. Dans les compilateurs conventionnels, cette étape correspond conditionnellement aux étapes d'allocation de registre, de planification et de sélection d'instructions.
La dernière étape du travail de l'interprète est directement l'exécution de l'arbre d'opérateurs d'algèbre physique.
Modèle de volcan et exécution de requête
Les interprètes physiques d'algèbre ont toujours été utilisés dans des bases de données commerciales fermées, mais la littérature académique se réfère généralement à l'optimiseur expérimental Volcano, développé au début des années 90.
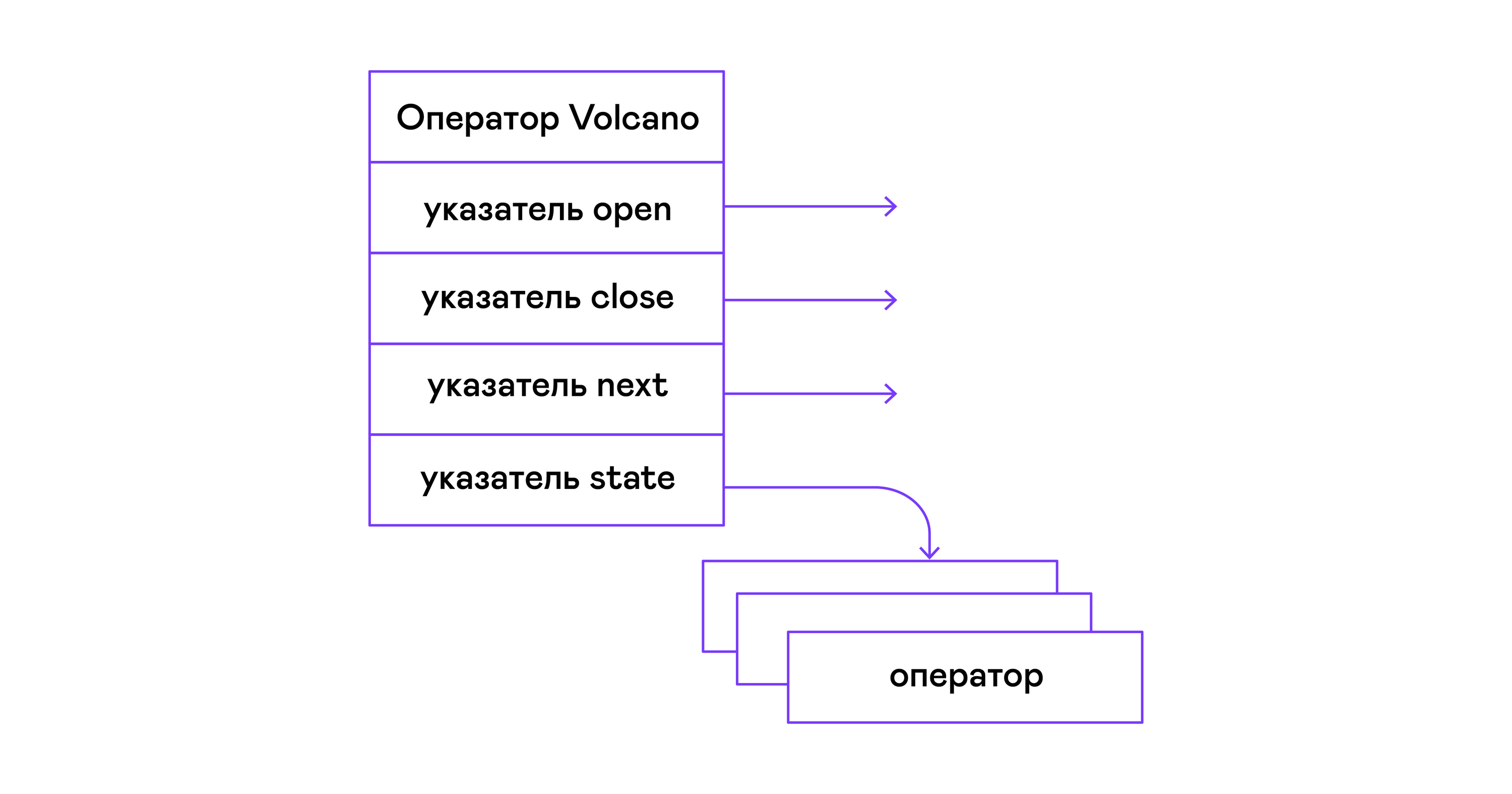
Dans le modèle du volcan, chaque opérateur d'un arbre d'algèbre physique se transforme en une structure à trois fonctions: ouvrir, ensuite, fermer. En plus des fonctions, l'opérateur contient un état de fonctionnement - état. La fonction open initie l'état de l'instruction, la fonction suivante retourne soit le tuple suivant (tuple anglais), soit NULL, s'il n'y a plus de tuples, la fonction close termine l'instruction:
Les opérateurs peuvent être imbriqués pour former un arbre d'opérateurs d'algèbre physique. Ainsi, chaque opérateur itère sur les tuples d'une relation existant sur un support réel ou d'une relation virtuelle formée en énumérant les tuples d'opérateurs imbriqués:
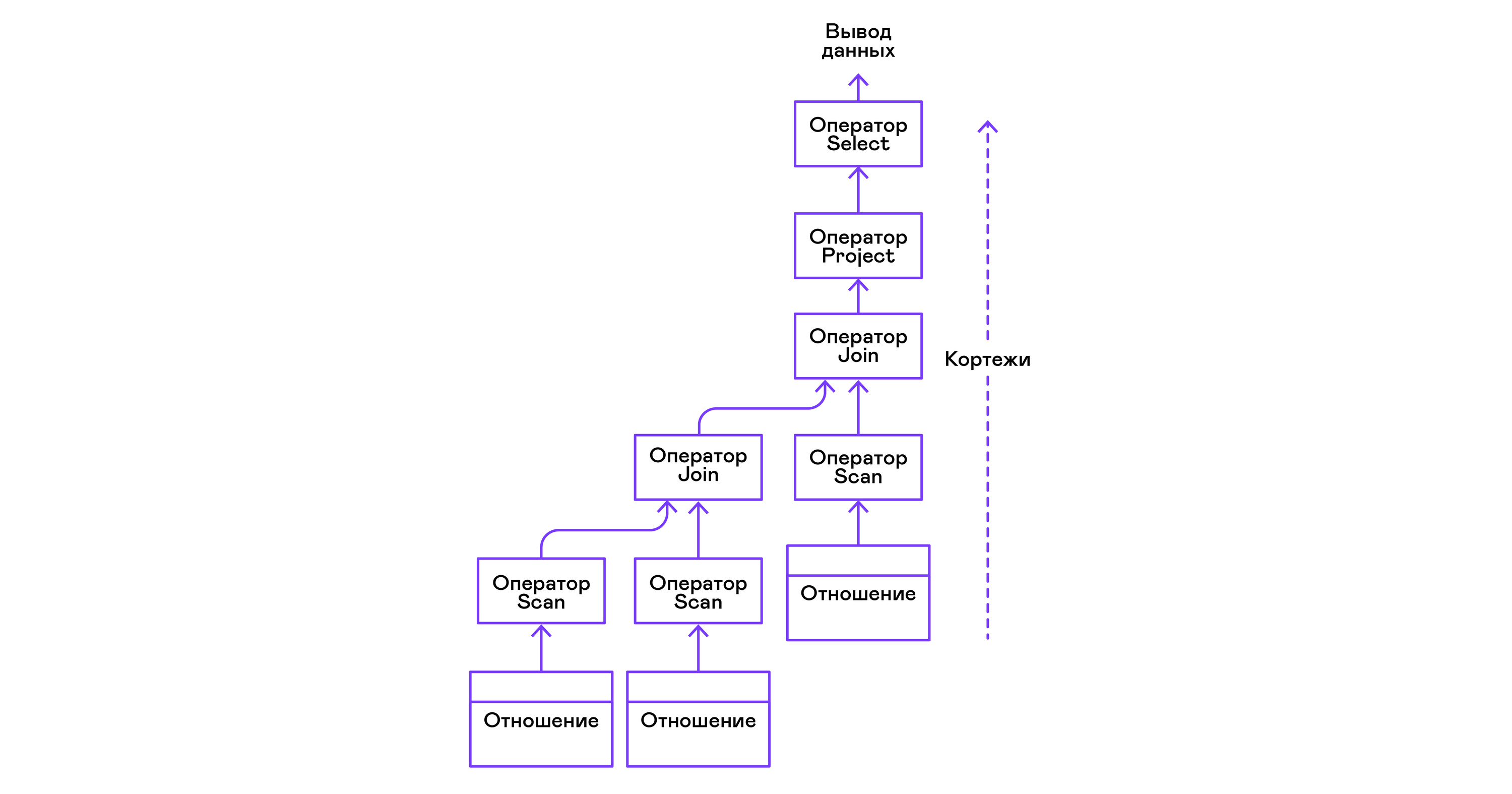
En termes de langages modernes de haut niveau, l'arborescence de ces opérateurs est une cascade d'itérateurs.
Même les interpréteurs de requêtes industriels dans les SGBD relationnels sont repoussés du modèle Volcano, c'est pourquoi je l'ai pris comme base de l'interpréteur PigletQL.
PigletQL
Pour démontrer le modèle, j'ai développé l'interpréteur du langage de requête limité PigletQL . Il est écrit en C, prend en charge la création de tables dans le style de SQL, mais est limité à un seul type - entiers positifs 32 bits. Toutes les tables sont en mémoire. Le système fonctionne dans un seul thread et n'a pas de mécanisme de transaction.
Il n'y a pas d'optimiseur dans PigletQL et les requêtes SELECT sont compilées directement dans l'arborescence d'opérateurs d'algèbre physique. Les requêtes restantes (CREATE TABLE et INSERT) fonctionnent directement à partir des vues internes principales.
Exemple de session utilisateur dans PigletQL:
> ./pigletql > CREATE TABLE tab1 (col1,col2,col3); > INSERT INTO tab1 VALUES (1,2,3); > INSERT INTO tab1 VALUES (4,5,6); > SELECT col1,col2,col3 FROM tab1; col1 col2 col3 1 2 3 4 5 6 rows: 2 > SELECT col1 FROM tab1 ORDER BY col1 DESC; col1 4 1 rows: 2
Lexique et analyseur
PigletQL est un langage très simple, et sa mise en œuvre n'était pas requise aux étapes de l'analyse lexicale et d'analyse.
L'analyseur lexical est écrit à la main. Un objet analyseur ( scanner_t ) est créé à partir de la chaîne de requête, qui distribue les jetons un par un:
scanner_t *scanner_create(const char *string); void scanner_destroy(scanner_t *scanner); token_t scanner_next(scanner_t *scanner);
L'analyse est effectuée à l'aide de la méthode de descente récursive. Tout d'abord, l'objet parser_t est créé qui, après avoir reçu l'analyseur lexical (scanner_t), remplit l'objet query_t avec des informations sur la requête:
query_t *query_create(void); void query_destroy(query_t *query); parser_t *parser_create(void); void parser_destroy(parser_t *parser); bool parser_parse(parser_t *parser, scanner_t *scanner, query_t *query);
Le résultat de l'analyse dans query_t est l'un des trois types de requête pris en charge par PigletQL:
typedef enum query_tag { QUERY_SELECT, QUERY_CREATE_TABLE, QUERY_INSERT, } query_tag; typedef struct query_t { query_tag tag; union { query_select_t select; query_create_table_t create_table; query_insert_t insert; } as; } query_t;
Le type de requête le plus complexe dans PigletQL est SELECT. Il correspond à la structure de données query_select_t :
typedef struct query_select_t { attr_name_t attr_names[MAX_ATTR_NUM]; uint16_t attr_num; rel_name_t rel_names[MAX_REL_NUM]; uint16_t rel_num; query_predicate_t predicates[MAX_PRED_NUM]; uint16_t pred_num; bool has_order; attr_name_t order_by_attr; sort_order_t order_type; } query_select_t;
La structure contient une description de la requête (un tableau d'attributs demandés par l'utilisateur), une liste de sources de données - relations, un tableau de prédicats filtrant les tuples et des informations sur l'attribut utilisé pour trier les résultats.
Analyseur sémantique
La phase d'analyse sémantique en SQL standard implique la vérification de l'existence des tables et des colonnes répertoriées dans les tables et la vérification des types dans les expressions de requête. Pour les vérifications liées aux tables et aux colonnes, le répertoire de la base de données est utilisé, où toutes les informations sur la structure des données sont stockées.
Il n'y a pas d'expressions complexes dans PigletQL, donc la vérification des requêtes se réduit à la vérification des métadonnées de catalogue des tables et des colonnes. Les requêtes SELECT, par exemple, sont validées par la fonction validate_select . Je vais l'apporter sous forme abrégée:
static bool validate_select(catalogue_t *cat, const query_select_t *query) { for (size_t rel_i = 0; rel_i < query->rel_num; rel_i++) { if (catalogue_get_relation(cat, query->rel_names[rel_i])) continue; fprintf(stderr, "Error: relation '%s' does not exist\n", query->rel_names[rel_i]); return false; } if (!rel_names_unique(query->rel_names, query->rel_num)) return false; if (!attr_names_unique(query->attr_names, query->attr_num)) return false; return true; }
Si la demande est valide, l'étape suivante consiste à compiler l'arborescence d'analyse en une arborescence d'opérateurs.
Compilation de requêtes dans une vue intermédiaire
Dans les interpréteurs SQL à part entière, il existe généralement deux représentations intermédiaires: l'algèbre logique et physique.
Un interpréteur PigletQL simple exécute les requêtes CREATE TABLE et INSERT directement à partir de ses arbres d'analyse, c'est-à- dire les structures query_create_table_t et query_insert_t . Les requêtes SELECT plus complexes sont compilées en une seule représentation intermédiaire, qui sera exécutée par l'interpréteur.
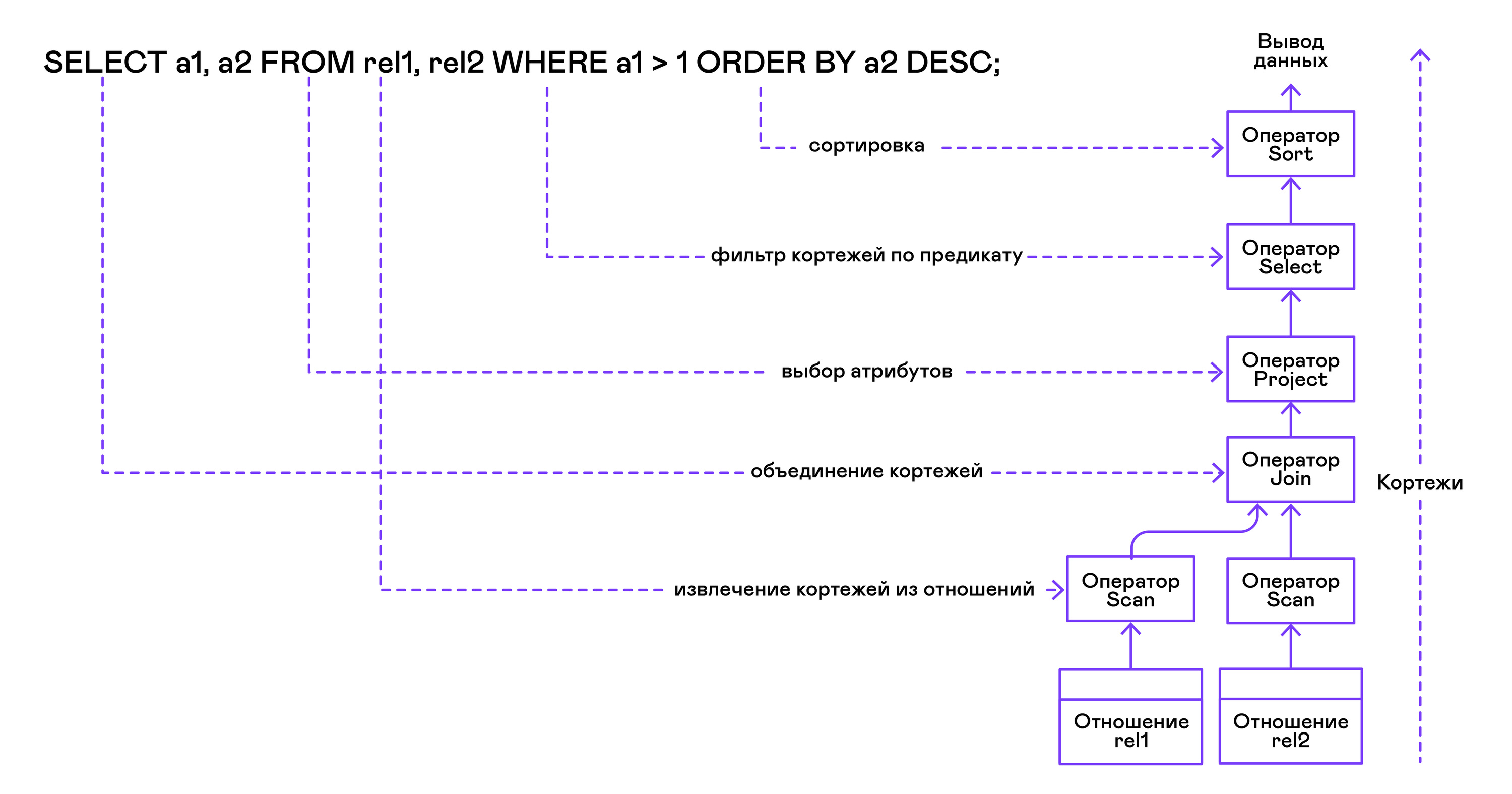
L'arbre des opérateurs est construit à partir des feuilles jusqu'à la racine dans la séquence suivante:
Dans la partie droite de la requête ("... FROM relation1, relation2, ..."), les noms des relations souhaitées sont obtenus, pour chacun desquels une instruction scan est créée.
En extrayant les tuples des relations, les opérateurs de scan sont combinés en un arbre binaire à gauche via l'opérateur de jointure.
Les attributs demandés par l'utilisateur ("SELECT attr1, attr2, ...") sont sélectionnés par l'énoncé de projet.
Si des prédicats sont spécifiés ("... WHERE a = 1 AND b> 10 ..."), alors l'instruction select est ajoutée à l'arborescence ci-dessus.
Si la méthode de tri du résultat est spécifiée ("... ORDER BY attr1 DESC"), alors l'opérateur de tri est ajouté en haut de l'arborescence.
Compilation en code PigletQL:
operator_t *compile_select(catalogue_t *cat, const query_select_t *query) { operator_t *root_op = NULL; { size_t rel_i = 0; relation_t *rel = catalogue_get_relation(cat, query->rel_names[rel_i]); root_op = scan_op_create(rel); rel_i += 1; for (; rel_i < query->rel_num; rel_i++) { rel = catalogue_get_relation(cat, query->rel_names[rel_i]); operator_t *scan_op = scan_op_create(rel); root_op = join_op_create(root_op, scan_op); } } root_op = proj_op_create(root_op, query->attr_names, query->attr_num); if (query->pred_num > 0) { operator_t *select_op = select_op_create(root_op); for (size_t pred_i = 0; pred_i < query->pred_num; pred_i++) { query_predicate_t predicate = query->predicates[pred_i]; } root_op = select_op; } if (query->has_order) root_op = sort_op_create(root_op, query->order_by_attr, query->order_type); return root_op; }
Une fois l'arbre formé, des transformations d'optimisation sont généralement effectuées, mais PigletQL passe immédiatement à l'étape d'exécution de la représentation intermédiaire.
Réalisation d'une présentation intermédiaire
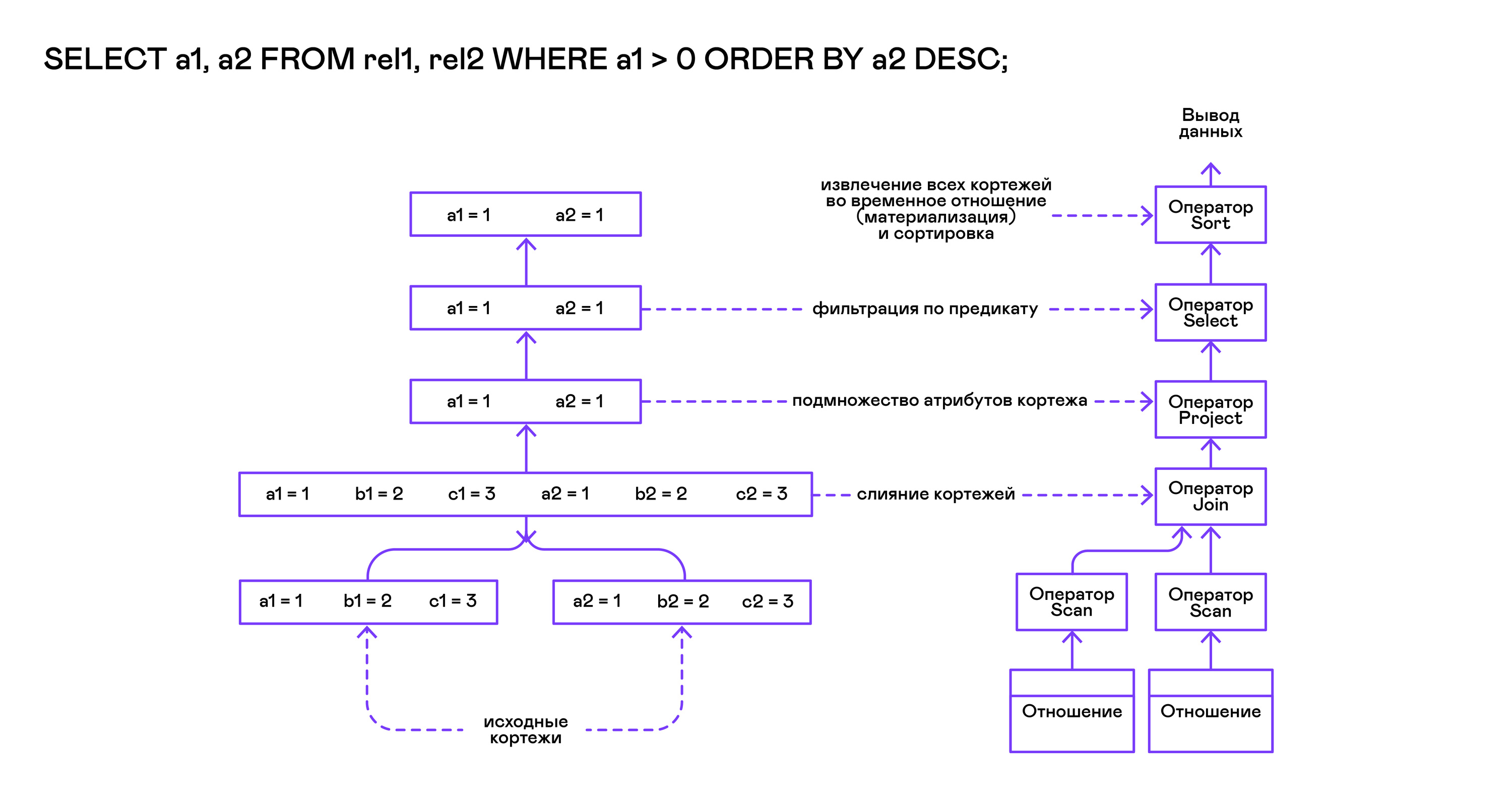
Le modèle Volcano implique une interface pour travailler avec les opérateurs à travers trois opérations communes d'ouverture / de fermeture / de fermeture. Essentiellement, chaque instruction Volcano est un itérateur à partir duquel les tuples sont «tirés» un par un, donc cette approche de l'exécution est également appelée modèle pull.
Chacun de ces itérateurs peut lui-même appeler les mêmes fonctions que les itérateurs imbriqués, créer des tables temporaires avec des résultats intermédiaires et convertir les tuples entrants.
Exécution de requêtes SELECT dans PigletQL:
bool eval_select(catalogue_t *cat, const query_select_t *query) { operator_t *root_op = compile_select(cat, query); { root_op->open(root_op->state); size_t tuples_received = 0; tuple_t *tuple = NULL; while((tuple = root_op->next(root_op->state))) { if (tuples_received == 0) dump_tuple_header(tuple); dump_tuple(tuple); tuples_received++; } printf("rows: %zu\n", tuples_received); root_op->close(root_op->state); } root_op->destroy(root_op); return true; }
La requête est d'abord compilée par la fonction compile_select, qui renvoie la racine de l'arborescence des opérateurs, après quoi les mêmes fonctions d'ouverture / suivante / de fermeture sont appelées sur l'opérateur racine. Chaque appel à next renvoie soit le tuple suivant soit NULL. Dans ce dernier cas, cela signifie que tous les tuples ont été extraits et que la fonction d'itérateur de fermeture doit être appelée.
Les tuples résultants sont recalculés et sortis par la table dans le flux de sortie standard.
Les opérateurs
La chose la plus intéressante à propos de PigletQL est l'arborescence des opérateurs. Je vais montrer l'appareil de certains d'entre eux.
Les opérateurs ont une interface commune et se composent de pointeurs vers la fonction d'ouverture / suivante / de fermeture et d'une fonction de destruction supplémentaire, qui libère les ressources de l'arborescence entière de l'opérateur à la fois:
typedef void (*op_open)(void *state); typedef tuple_t *(*op_next)(void *state); typedef void (*op_close)(void *state); typedef void (*op_destroy)(operator_t *op); struct operator_t { op_open open; op_next next; op_close close; op_destroy destroy; void *state; } ;
En plus des fonctions, l'opérateur peut contenir un état interne arbitraire (pointeur d'état).
Ci-dessous j'analyserai le dispositif de deux opérateurs intéressants: le scan le plus simple et la création d'un tri de relation intermédiaire.
Instruction de scan
L'instruction qui démarre une requête est scan. Il passe en revue tous les tuples de la relation. L'état interne de l'analyse est un pointeur sur la relation d'où les tuples seront récupérés, l'index du tuple suivant dans la relation et une structure de lien vers le tuple actuel transmis à l'utilisateur:
typedef struct scan_op_state_t { const relation_t *relation; uint32_t next_tuple_i; tuple_t current_tuple; } scan_op_state_t;
Pour créer l'état d'une instruction d'analyse, vous avez besoin d'une relation source; tout le reste (pointeurs vers les fonctions correspondantes) est déjà connu:
operator_t *scan_op_create(const relation_t *relation) { operator_t *op = calloc(1, sizeof(*op)); assert(op); *op = (operator_t) { .open = scan_op_open, .next = scan_op_next, .close = scan_op_close, .destroy = scan_op_destroy, }; scan_op_state_t *state = calloc(1, sizeof(*state)); assert(state); *state = (scan_op_state_t) { .relation = relation, .next_tuple_i = 0, .current_tuple.tag = TUPLE_SOURCE, .current_tuple.as.source.tuple_i = 0, .current_tuple.as.source.relation = relation, }; op->state = state; return op; }
Opérations d'ouverture / fermeture dans le cas d'une réinitialisation de l'analyse renvoie au premier élément de la relation:
void scan_op_open(void *state) { scan_op_state_t *op_state = (typeof(op_state)) state; op_state->next_tuple_i = 0; tuple_t *current_tuple = &op_state->current_tuple; current_tuple->as.source.tuple_i = 0; } void scan_op_close(void *state) { scan_op_state_t *op_state = (typeof(op_state)) state; op_state->next_tuple_i = 0; tuple_t *current_tuple = &op_state->current_tuple; current_tuple->as.source.tuple_i = 0; }
L'appel suivant retourne soit le tuple suivant, soit NULL s'il n'y a plus de tuples dans la relation:
tuple_t *scan_op_next(void *state) { scan_op_state_t *op_state = (typeof(op_state)) state; if (op_state->next_tuple_i >= op_state->relation->tuple_num) return NULL; tuple_source_t *source_tuple = &op_state->current_tuple.as.source; source_tuple->tuple_i = op_state->next_tuple_i; op_state->next_tuple_i++; return &op_state->current_tuple; }
Instruction de tri
L'instruction sort produit des tuples dans l'ordre spécifié par l'utilisateur. Pour ce faire, créez une relation temporaire avec des tuples obtenus à partir d'opérateurs imbriqués et triez-la.
L'état interne de l' opérateur:
typedef struct sort_op_state_t { operator_t *source; attr_name_t sort_attr_name; sort_order_t sort_order; relation_t *tmp_relation; operator_t *tmp_relation_scan_op; } sort_op_state_t;
Le tri est effectué selon les attributs spécifiés dans la demande (sort_attr_name et sort_order) sur le rapport temporel (tmp_relation). Tout cela se produit lorsque la fonction open est appelée:
void sort_op_open(void *state) { sort_op_state_t *op_state = (typeof(op_state)) state; operator_t *source = op_state->source; source->open(source->state); tuple_t *tuple = NULL; while((tuple = source->next(source->state))) { if (!op_state->tmp_relation) { op_state->tmp_relation = relation_create_for_tuple(tuple); assert(op_state->tmp_relation); op_state->tmp_relation_scan_op = scan_op_create(op_state->tmp_relation); } relation_append_tuple(op_state->tmp_relation, tuple); } source->close(source->state); relation_order_by(op_state->tmp_relation, op_state->sort_attr_name, op_state->sort_order); op_state->tmp_relation_scan_op->open(op_state->tmp_relation_scan_op->state); }
L'énumération des éléments de la relation temporaire est effectuée par l'opérateur temporaire tmp_relation_scan_op:
tuple_t *sort_op_next(void *state) { sort_op_state_t *op_state = (typeof(op_state)) state; return op_state->tmp_relation_scan_op->next(op_state->tmp_relation_scan_op->state);; }
La relation temporaire est désallouée dans la fonction close:
void sort_op_close(void *state) { sort_op_state_t *op_state = (typeof(op_state)) state; if (op_state->tmp_relation) { op_state->tmp_relation_scan_op->close(op_state->tmp_relation_scan_op->state); scan_op_destroy(op_state->tmp_relation_scan_op); relation_destroy(op_state->tmp_relation); op_state->tmp_relation = NULL; } }
Ici, vous pouvez voir clairement pourquoi les opérations de tri sur des colonnes sans index peuvent prendre beaucoup de temps.
Exemples de travaux
Je vais donner quelques exemples de requêtes PigletQL et les arbres d'algèbre physique correspondants.
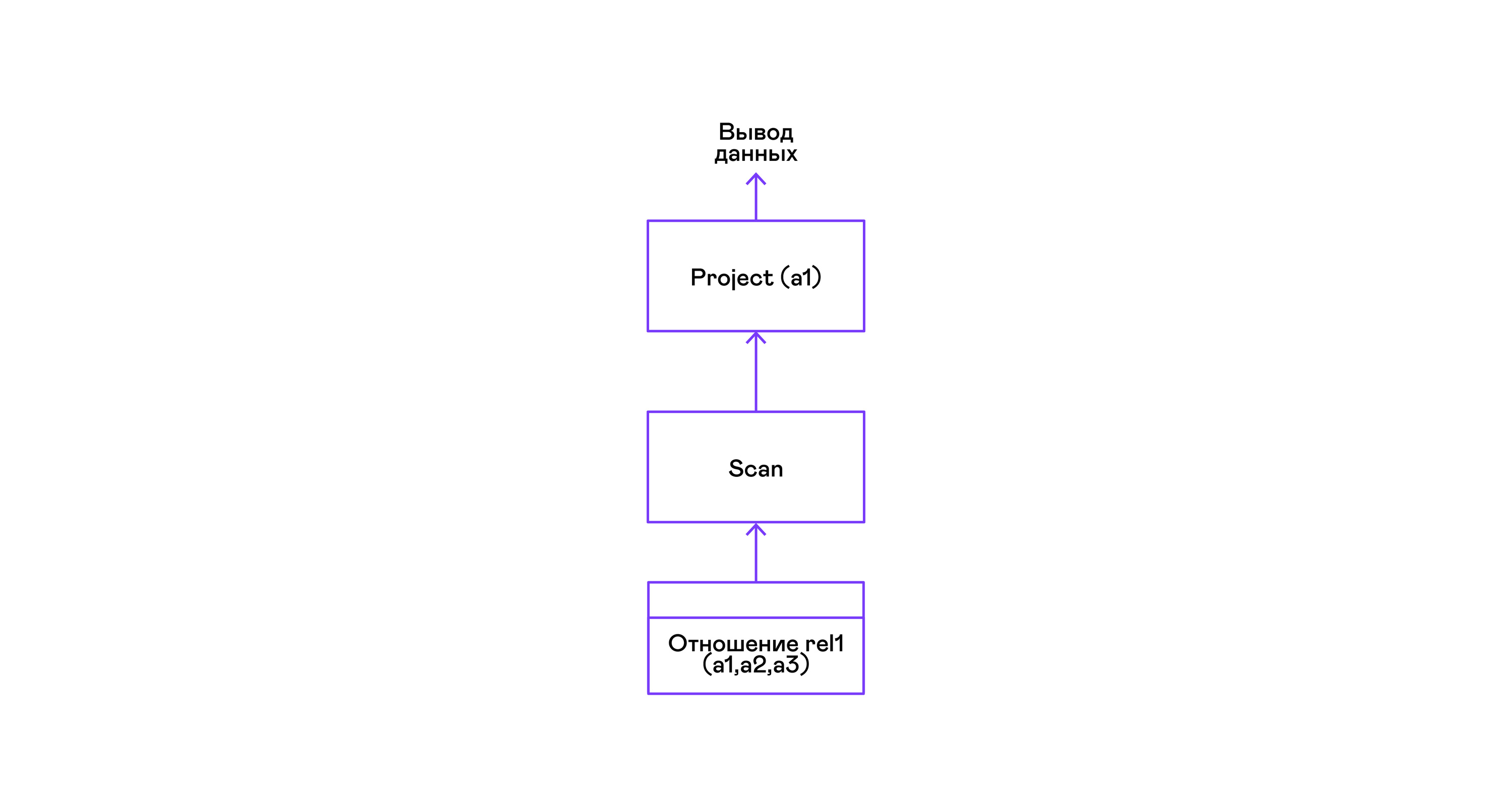
L'exemple le plus simple où tous les tuples d'une relation sont sélectionnés:
> ./pigletql > create table rel1 (a1,a2,a3); > insert into rel1 values (1,2,3); > insert into rel1 values (4,5,6); > select a1 from rel1; a1 1 4 rows: 2 >
Pour les requêtes les plus simples, seules les tuples de récupération de la relation de scan sont utilisées et la sélection du seul attribut de projet à partir des tuples:
Choisir des tuples avec un prédicat:
> ./pigletql > create table rel1 (a1,a2,a3); > insert into rel1 values (1,2,3); > insert into rel1 values (4,5,6); > select a1 from rel1 where a1 > 3; a1 4 rows: 1 >
Les prédicats sont exprimés par l'instruction select:
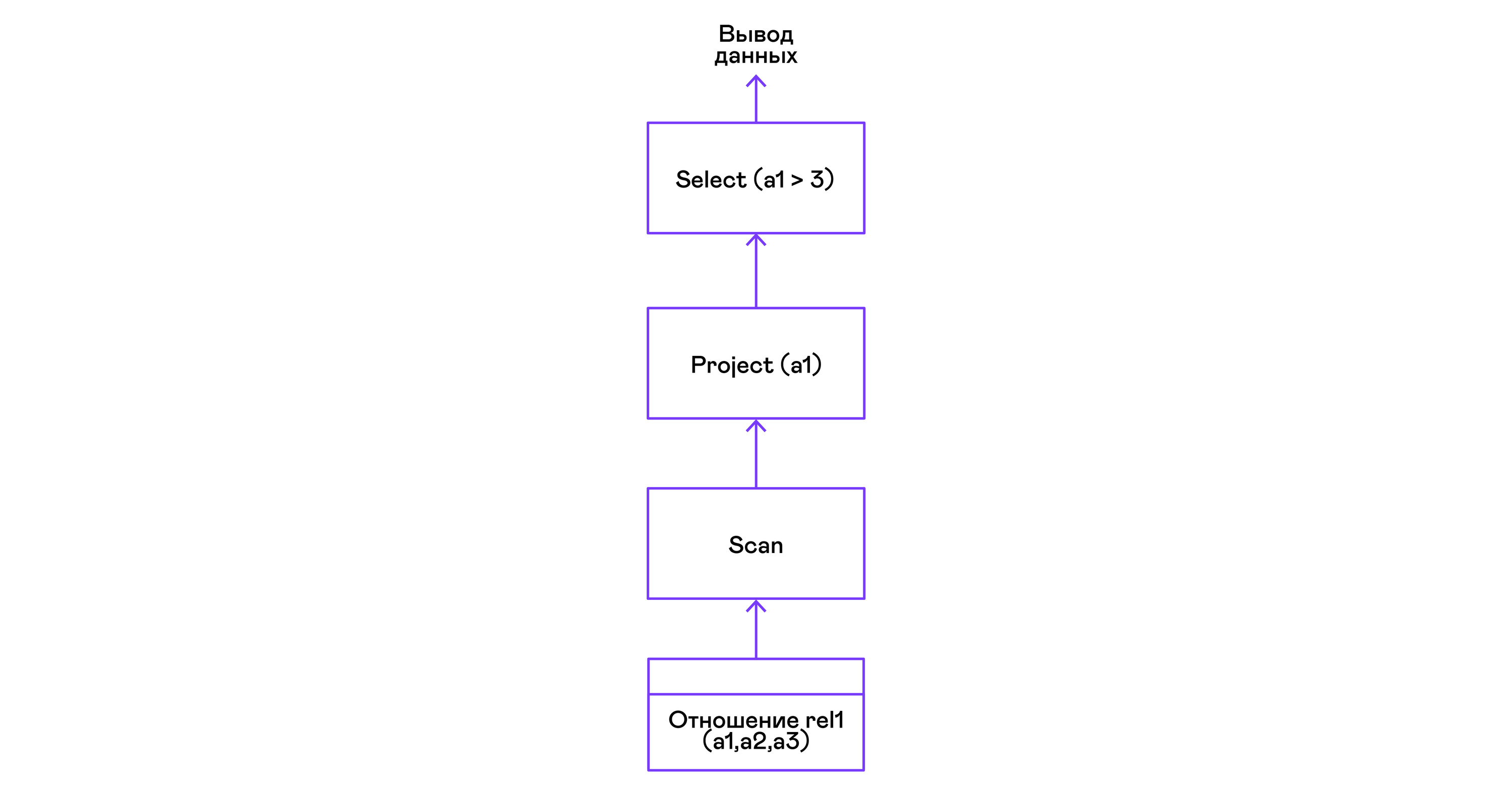
Sélection de tuples avec tri:
> ./pigletql > create table rel1 (a1,a2,a3); > insert into rel1 values (1,2,3); > insert into rel1 values (4,5,6); > select a1 from rel1 order by a1 desc; a1 4 1 rows: 2
L'opérateur de tri de numérisation dans l'appel ouvert crée ( matérialise ) une relation temporaire, y place tous les tuples entrants et trie le tout. Après cela, dans les prochains appels, il déduit les tuples de la relation temporaire dans l'ordre spécifié par l'utilisateur:

Combinaison de tuples de deux relations avec un prédicat:
> ./pigletql > create table rel1 (a1,a2,a3); > insert into rel1 values (1,2,3); > insert into rel1 values (4,5,6); > create table rel2 (a4,a5,a6); > insert into rel2 values (7,8,6); > insert into rel2 values (9,10,6); > select a1,a2,a3,a4,a5,a6 from rel1, rel2 where a3=a6; a1 a2 a3 a4 a5 a6 4 5 6 7 8 6 4 5 6 9 10 6 rows: 2
L'opérateur de jointure dans PigletQL n'utilise aucun algorithme complexe, mais forme simplement un produit cartésien à partir des ensembles de tuples des sous-arbres gauche et droit. C'est très inefficace, mais pour un interprète de démonstration, cela fera:
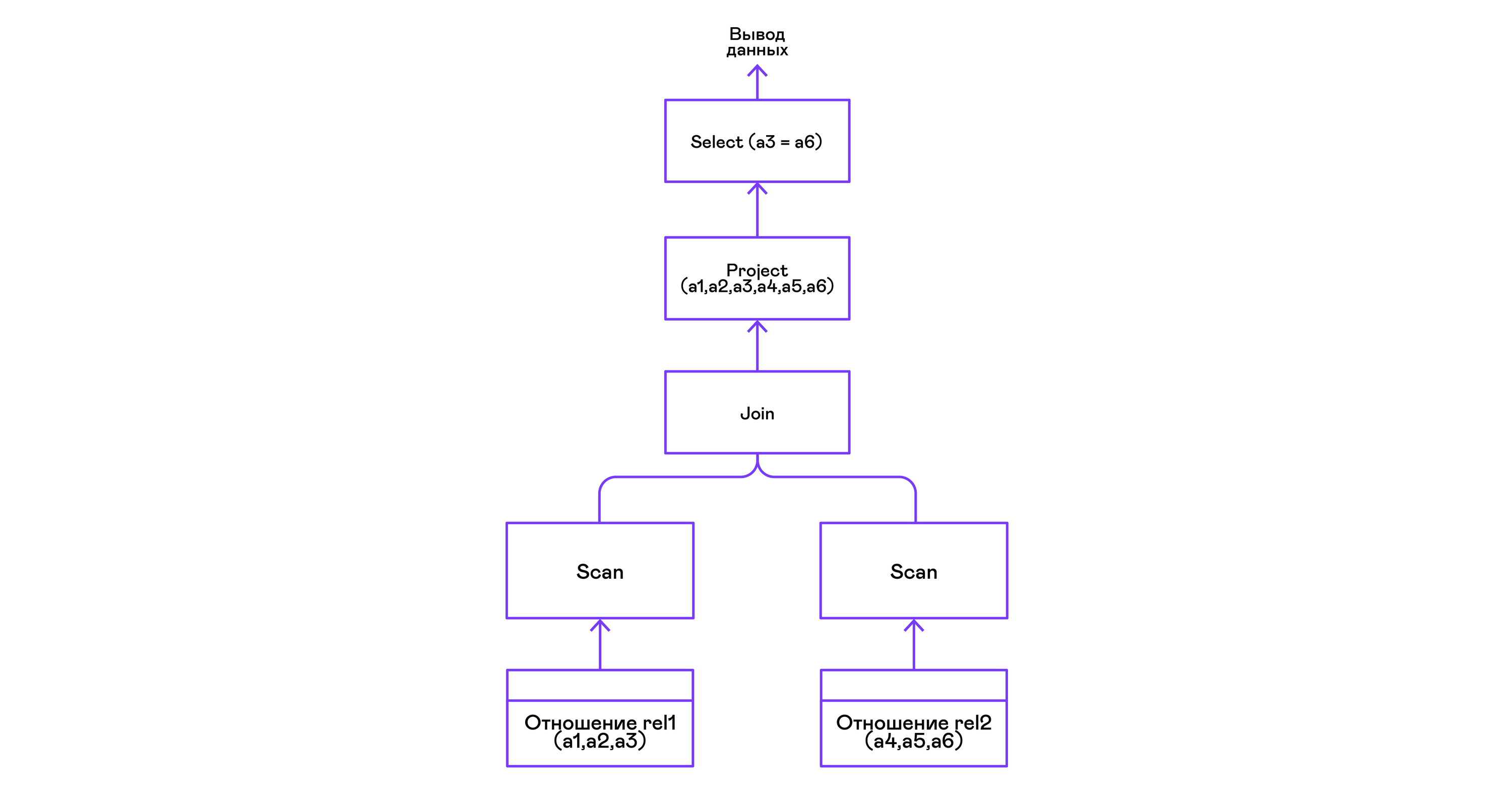
Conclusions
En conclusion, je note que si vous faites un interprète d'un langage similaire à SQL, alors vous devriez probablement prendre l'une des nombreuses bases de données relationnelles disponibles. Des milliers d'années-personnes ont été investies dans des optimiseurs modernes et des interprètes de requêtes de bases de données populaires, et il faut des années pour développer même les bases de données à usage général les plus simples.
Le langage de démonstration PigletQL imite le travail de l'interpréteur SQL, mais en réalité nous n'utilisons que des éléments individuels de l'architecture Volcano et uniquement pour ces (rares!) Types de requêtes difficiles à exprimer dans le cadre du modèle relationnel.
Néanmoins, je le répète: même une connaissance superficielle de l'architecture de tels interprètes est utile dans les cas où il est nécessaire de travailler de manière flexible avec les flux de données.
Littérature
Si vous êtes intéressé par les problèmes de base du développement de bases de données, alors les livres valent mieux que «Implémentation du système de base de données» (Garcia-Molina H., Ullman JD, Widom J., 2000), vous ne trouverez pas.
Son seul inconvénient est une orientation théorique. Personnellement, j'aime quand des exemples concrets de code ou même un projet de démonstration sont attachés au matériel. Pour cela, vous pouvez vous référer au livre «Conception et implémentation de base de données» (Sciore E., 2008), qui fournit le code complet d'une base de données relationnelle en Java.
Les bases de données relationnelles les plus populaires utilisent encore des variations sur le thème du volcan. La publication originale est écrite dans une langue très accessible et peut être facilement trouvée sur Google Scholar: "Volcano - un système d'évaluation de requête extensible et parallèle" (Graefe G., 1994).
Bien que les interprètes SQL aient beaucoup changé en détail au cours des dernières décennies, la structure très générale de ces systèmes n'a pas changé depuis très longtemps. Vous pouvez vous en faire une idée dans un article de synthèse du même auteur, «Techniques d'évaluation des requêtes pour les grandes bases de données» (Graefe G. 1993).