Bonjour, Habr! Je m'appelle Nikolai et je suis engagé dans la construction et la mise en œuvre de modèles d'apprentissage automatique à Sberbank. Aujourd'hui, je vais parler du développement d'un système de recommandation pour les paiements et les transferts dans l'application sur vos smartphones.
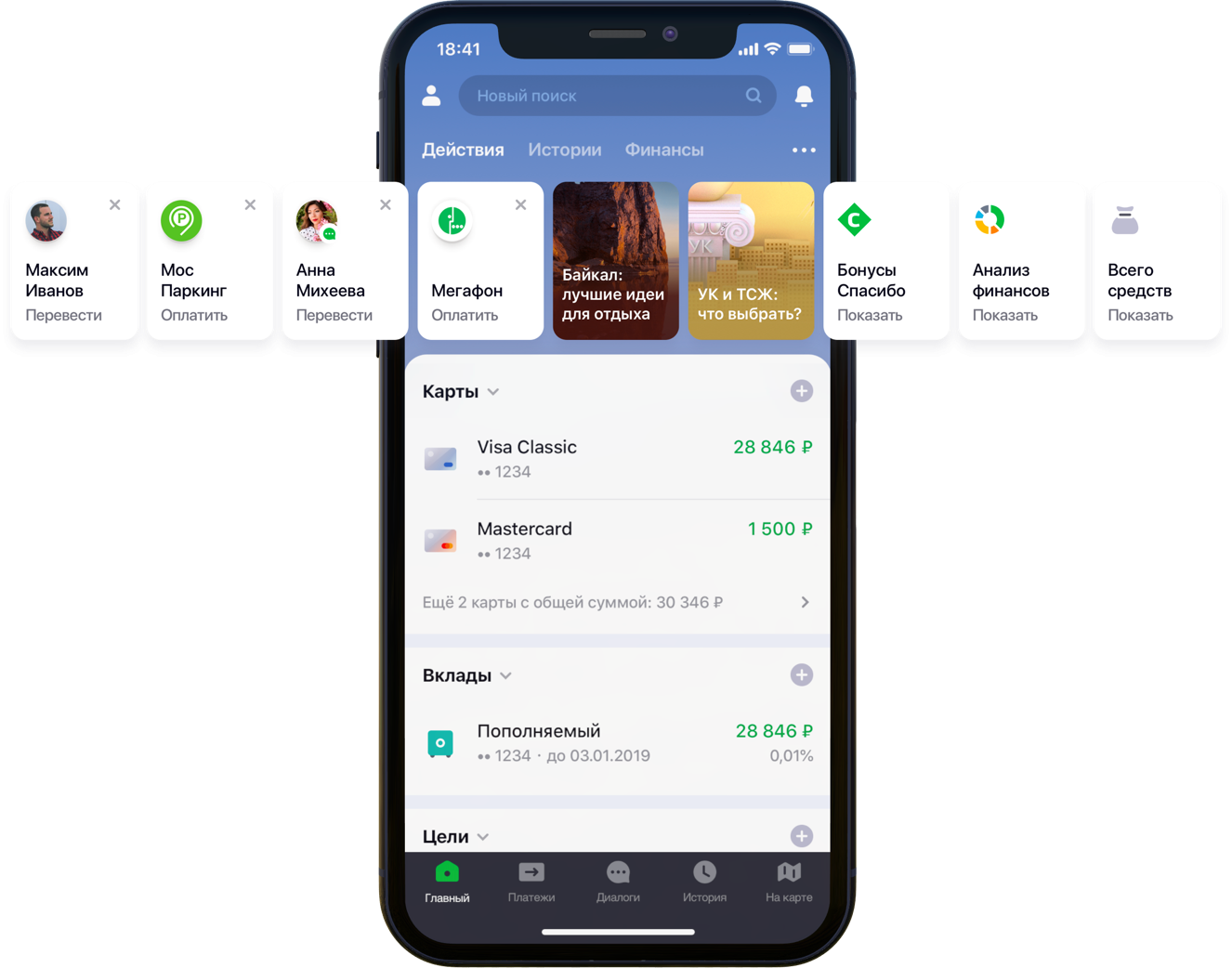 Conception de l'écran principal de l'application mobile avec recommandations
Conception de l'écran principal de l'application mobile avec recommandationsNous avions 2 centaines de milliers d'options de paiement possibles, 55 millions de clients, 5 sources bancaires différentes, une demi-colonne développeur et une montagne d'activité bancaire, des algorithmes et tout cela, toutes les couleurs, ainsi qu'un litre de graines aléatoires, une boîte d'hyperparamètres, un demi-litre de facteurs de correction et deux des dizaines de bibliothèques. Ce n'est pas que tout cela était nécessaire dans le travail, mais depuis qu'il a commencé à améliorer la vie des clients, allez dans votre passe-temps jusqu'à la fin. Sous la coupe se trouve l'histoire de la bataille pour l'UX, la formulation correcte du problème, la lutte contre la dimensionnalité des données, la contribution à l'open source et nos résultats.
Énoncé du problème
Au fur et à mesure du développement et de l'extension, l'application Sberbank Online gagne des fonctionnalités utiles et des fonctionnalités supplémentaires. En particulier, dans l'application, vous pouvez transférer de l'argent ou payer des services de diverses organisations.
«Nous avons examiné attentivement tous les chemins utilisateur à l'intérieur de l'application et nous avons réalisé que beaucoup d'entre eux peuvent être considérablement réduits. Pour ce faire, nous avons décidé de personnaliser l'écran principal en plusieurs étapes. Tout d'abord, nous avons essayé de supprimer de l'écran ce que le client n'utilise pas, à commencer par les cartes bancaires. Ensuite, ils ont mis en évidence les actions que le client avait déjà effectuées plus tôt et pour lesquelles il pouvait entrer dans l'application dès maintenant. Maintenant, la liste des actions comprend les paiements aux organisations et les transferts aux contacts, puis la liste de ces actions sera élargie », a déclaré mon collègue Sergey Komarov, qui développe la fonctionnalité du point de vue du client dans l'équipe Sberbank Online. Il est nécessaire de construire un modèle qui remplirait les emplacements désignés dans les widgets Actions (figure ci-dessus) avec des recommandations personnelles de paiements et de transferts au lieu de règles simples.
Solution
Dans l'équipe, nous avons décomposé la tâche en deux parties:
- la recommandation de la répétition des opérations de paiement de services ou de transfert de fonds (bloc "Opérations recommandées")
- recommandation d'exemples de demandes de recherche de paiement pour des services non utilisés auparavant par ce client (bloc «Exemples de recherche»)
Nous avons décidé de tester d'abord la fonctionnalité sur l'onglet de recherche:
Conception d'écran de recherche recommandéeOpérations recommandées
Optimisation du scoring
Si nous définissons la sous-tâche comme une recommandation de répéter les opérations, cela nous permet de nous débarrasser du calcul et de l'évaluation de milliers de milliards de combinaisons de toutes les opérations possibles pour tous les clients et de nous concentrer sur un nombre beaucoup plus limité d'entre elles. Si, sur l'ensemble des opérations disponibles pour nos clients, le client hypothétique avec le hachage YYY n'a utilisé que le paiement pour le gaz et le stationnement, alors nous évaluerons la probabilité de répéter uniquement ces opérations pour ce client:
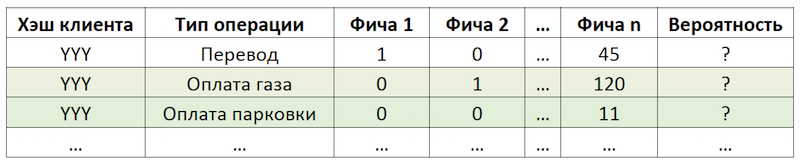 Un exemple de réduction de la dimension des données pour le scoring
Un exemple de réduction de la dimension des données pour le scoringPréparation de l'ensemble de données
L'échantillon est une observation transactionnelle, enrichie de facteurs de démographie des clients, d'agrégats financiers et de diverses caractéristiques de fréquence d'une opération particulière.
La variable cible dans ce cas est binaire et reflète le fait de l'événement le jour suivant le jour où les facteurs sont calculés. Ainsi, en déplaçant itérativement le jour du calcul des facteurs et en positionnant le drapeau de la variable cible, nous multiplions et marquons les mêmes opérations et les marquons différemment selon la position par rapport à ce jour.
Schéma d'observationEn calculant la coupe du 17/03/2019 pour le client "YYY", nous obtenons deux observations:
Un exemple des observations pour un ensemble de données«Fonction 1» peut signifier, par exemple, le solde sur toutes les cartes du client, «Fonction 2» - la présence de ce type d'opération la semaine dernière.
Nous prenons les mêmes transactions, mais formons des observations pour une formation à une date différente:
Schéma d'observationNous obtiendrons des observations pour un ensemble de données avec d'autres valeurs des deux entités et de la variable cible:
 Un exemple des observations pour un ensemble de données
Un exemple des observations pour un ensemble de donnéesDans les exemples ci-dessus, pour plus de clarté, les valeurs réelles des facteurs sont données, mais en fait, les valeurs sont traitées par un algorithme automatique: les résultats de la
conversion WOE sont introduits dans l'entrée du modèle. Il vous permet d'amener les variables dans une relation monotone avec la variable cible et en même temps de vous débarrasser des effets des valeurs aberrantes. Par exemple, nous avons le facteur «Nombre de cartes» et une certaine distribution de la variable cible:
 Exemple de conversion WOE
Exemple de conversion WOELa transformation WOE nous permet de transformer une dépendance non linéaire en au moins une dépendance monotone. Chaque valeur du facteur analysé est associée à sa propre valeur WOE et donc un nouveau facteur est formé, et l'original est supprimé de l'ensemble de données:
 L'effet de la transformation WOE sur la relation avec la variable cible
L'effet de la transformation WOE sur la relation avec la variable cibleLe dictionnaire de conversion des valeurs variables en WOE est enregistré et utilisé ultérieurement pour la notation. Autrement dit, si nous devons calculer les probabilités pour demain, nous créons un ensemble de données comme dans les tableaux avec des exemples d'observations ci-dessus, convertissons les variables nécessaires en WOE avec le code enregistré et appliquons le modèle à ces données.
La formation
Le choix de la méthode était strictement limité - interprétabilité. Par conséquent, afin de respecter les délais, il a été décidé de reporter les explications en utilisant le même
SHAP dans la seconde moitié du problème et de tester des méthodes relativement simples: régression et neurones superficiels. L'outil était SAS Miner, un logiciel de prétraitement, d'analyse et de construction de modèles sur diverses données sous une forme interactive, ce qui permet d'économiser beaucoup de temps sur l'écriture de code.
 Interface SAS Miner
Interface SAS MinerÉvaluation de la qualité
La comparaison de la métrique GINI sur un échantillon hors du temps a montré que le réseau neuronal fait le mieux face à la tâche:
Tableau comparatif des modèles de qualité et des règles de fréquenceLe modèle a deux points de sortie. Les recommandations sous forme de cartes widget sur l'écran principal incluent des opérations dont la prévision est supérieure à un certain seuil (voir la première image dans le billet). La frontière est sélectionnée sur la base d'un équilibre de qualité et de couverture, qui dans une telle architecture représente la moitié de toutes les opérations effectuées. Les 4 premières opérations sont envoyées au bloc «opérations recommandées» de l'écran de recherche (voir la deuxième image).
Exemples de recherche
Passant à la deuxième partie de la tâche, nous revenons au problème d'un grand nombre d'options de paiement possibles pour les services des fournisseurs qui doivent être évaluées et triées au sein de chaque client - des milliards de paires. En plus de cela, nous avons des données implicites, c'est-à-dire qu'il n'y a aucune information sur l'évaluation des paiements effectués, ni pourquoi le client n'a effectué aucun paiement. Par conséquent, pour commencer, il a été décidé de tester différentes méthodes d'élargissement de la matrice des paiements des clients aux fournisseurs: ALS et FM.
SLA
ALS (Alternating Least Squares) ou Alternating Least Squares - en filtrage collaboratif, l'une des méthodes pour résoudre le problème de la factorisation de la matrice d'interaction. Nous présenterons nos données transactionnelles sur le paiement des services sous la forme d'une matrice dans laquelle les colonnes sont des identifiants uniques des services de tous les fournisseurs et les lignes sont des clients uniques. Dans les cellules, nous plaçons le nombre d'opérations de clients spécifiques avec des prestataires spécifiques pendant une certaine période:
 Principe de décomposition matricielle
Principe de décomposition matricielleLe sens de la méthode est que nous créons deux de ces matrices de dimension inférieure, dont la multiplication donne le résultat le plus proche de la grande matrice d'origine dans les cellules remplies. Le modèle apprend à créer une description factorielle cachée pour les clients et les fournisseurs. Une implémentation de la méthode dans la bibliothèque
implicite a été utilisée. La formation se déroule selon l'algorithme suivant:
- Les matrices des clients et des fournisseurs avec des facteurs cachés sont initialisées. Leur nombre est l'hyperparamètre du modèle.
- La matrice des facteurs cachés des fournisseurs est fixe et la dérivée de la fonction de perte pour la correction de la matrice client est considérée. L'auteur a utilisé une méthode intéressante de gradients conjugués , qui vous permet d'accélérer considérablement cette étape.
- L'étape précédente est répétée de la même manière pour la matrice des facteurs cachés des clients.
- Les étapes 2-3 alternent jusqu'à ce que l'algorithme converge.
La préparation
Les données transactionnelles ont été transformées en une matrice d'interactions avec un degré de rareté de ~ 99% avec une grande inégalité entre les prestataires. Pour séparer les données en échantillons de train et de validation, nous avons masqué au hasard la proportion de cellules remplies:
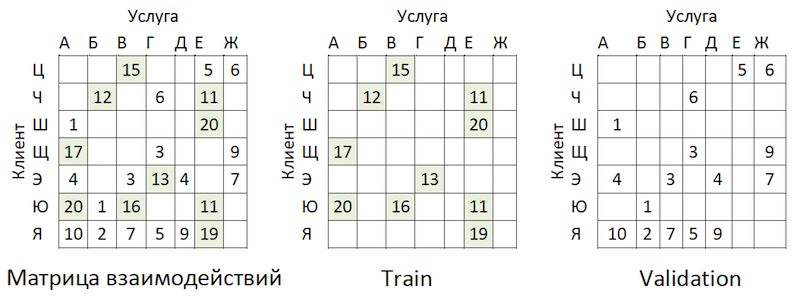 Exemple de partage de données
Exemple de partage de donnéesLes transactions ont été prises comme test pour la période suivant la formation, et présentées dans une matrice du même format - elle s'est avérée hors du temps.
La formation
Le modèle possède plusieurs hyperparamètres qui peuvent être ajustés pour améliorer la qualité:
- Alpha est le coefficient par lequel la matrice est pondérée, ajustant le degré de confiance ( C_iu ) que le service donné est vraiment «aimé» par le client.
- Le nombre de facteurs dans les matrices cachées des clients et des fournisseurs est le nombre de colonnes et de lignes, respectivement.
- Coefficient de régularisation L2 λ.
- Le nombre d'itérations de la méthode.
Nous avons utilisé la bibliothèque
hyperopt , qui nous permet d'évaluer l'effet des hyperparamètres sur la métrique de qualité à l'aide de la méthode
TPE et de sélectionner leur valeur optimale. L'algorithme commence par un démarrage à froid et effectue plusieurs évaluations de la métrique de qualité en fonction des valeurs des hyperparamètres analysés. Ensuite, en substance, il essaie de sélectionner un ensemble de valeurs d'hyperparamètres qui est plus susceptible de donner une bonne valeur pour la métrique de qualité. Les résultats sont enregistrés dans un dictionnaire à partir duquel vous pouvez créer un graphique et évaluer visuellement le résultat de l'optimiseur (le bleu c'est mieux):
Le graphique de la dépendance de la métrique de qualité sur la combinaison d'hyperparamètresLe graphique montre que les valeurs des hyperparamètres affectent fortement la qualité du modèle. Puisqu'il est nécessaire d'appliquer des plages pour chacune d'entre elles à l'entrée de la méthode, le graphique peut en outre déterminer s'il est judicieux d'agrandir l'espace de valeurs ou non. Par exemple, dans notre tâche, il est clair qu'il est logique de tester de grandes valeurs pour le nombre de facteurs. À l'avenir, cela a vraiment amélioré le modèle.
Métrique et complexité de l'évaluation de la qualité
Comment évaluer la qualité du modèle? L'une des mesures les plus couramment utilisées pour les systèmes de recommandation où la commande est importante est
MAP @ k ou Mean Average Precision à K.Cette mesure estime la précision du modèle sur K recommandations, en tenant compte de l'ordre des articles dans la liste de ces recommandations en moyenne pour tous les clients.
Malheureusement, une opération d'évaluation de la qualité, même sur un échantillon, a pris plusieurs heures. Après avoir retroussé nos manches, nous avons commencé à profiler la fonction mean_average_pecision_at_k () avec la bibliothèque line_profiler. La tâche était encore compliquée par le fait que la fonction utilisait du code cython et devait être correctement
prise en compte , faute de quoi les statistiques nécessaires n'étaient tout simplement pas collectées. En conséquence, nous avons de nouveau été confrontés au problème de la dimensionnalité de nos données. Pour calculer cette métrique, vous devez obtenir des estimations de chaque service de tous les possibles pour chaque client et sélectionner les recommandations personnelles top-K en les triant à partir du tableau résultant. Même en considérant l'utilisation du tri partiel de numpy.argpartition () avec la complexité O (n), le tri des notes s'est avéré être l'étape la plus longue étirant la notation de qualité au fil du temps. Comme numpy.argpartition () n'a pas utilisé tous les noyaux de notre serveur, il a été décidé d'améliorer l'algorithme en réécrivant cette partie en C ++ et OpenMP via cython. Un nouvel algorithme succinct est le suivant:
- Les données sont découpées en lots par les clients.
- Une matrice vide et des pointeurs vers la mémoire sont initialisés.
- Les chaînes de lots par pointeurs sont triées de deux manières: par la fonction partial_sort puis triées par la bibliothèque d'algorithmes C ++.
- Les résultats sont écrits en parallèle dans les cellules de la matrice vide.
- Les données sont renvoyées en python.
Cela nous a permis d'accélérer plusieurs fois le calcul des recommandations. La révision a été
ajoutée au référentiel officiel.
Analyse des résultats OOT
Et maintenant, il est temps d'évaluer la qualité du modèle. Pourquoi avons-nous besoin d'un échantillonnage hors temps? Si nous regardons la distribution des opérations par les fournisseurs, nous verrons l'image suivante:
Répartition de la popularité des prestataires de servicesIl y a un déséquilibre. Cela conduit au fait que le modèle essaie de recommander des services populaires. Retour à l'image ci-dessus:
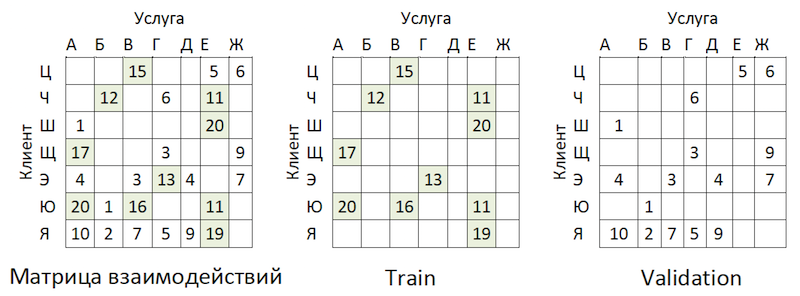
Le problème est que si vous vérifiez la précision du modèle en masquant la même matrice, comme cela est conseillé presque partout, alors pour la plupart des clients (exemples marginaux: «W», «E» et «I») la qualité des prévisions de validation (nous ferons comme si elle n'a pas participé à la sélection des hyperparamètres) sera élevé si ce sont les prestataires les plus populaires. En conséquence, nous obtenons une fausse confiance dans la force du modèle. Par conséquent, nous avons agi comme suit:
- Estimations formées des prestataires par modèle.
- Les couples client-service existants ont été exclus des classifications (voir la figure ci-dessous) et des matrices OOT.
- Formé à partir des notes restantes des recommandations K-top et noté MAP @ k sur le reste OOT.
 La logique de préparation de la matrice de génération des prévisions
La logique de préparation de la matrice de génération des prévisionsEn tant que ligne de base, nous avons compilé une liste de fournisseurs, triée par popularité, et multipliée par tous les clients, en excluant à nouveau les paires de service client existantes. Il s'est avéré être triste et pas du tout ce que nous attendions et avons vu sur les échantillons de train \ validation:
Tableau de comparaison de la référence et de la qualité du modèleArrête ça! Nous avons des facteurs clients et des paramètres de fournisseurs. Nous obtenons des machines de factorisation.
FM
Machines de factorisation (machine de factorisation) - un algorithme d'apprentissage avec un enseignant, conçu pour trouver des relations entre des facteurs qui décrivent des entités en interaction, qui sont présentées sous la forme de matrices clairsemées. Nous avons utilisé l'implémentation FM de la bibliothèque
LightFM .
Format des données
En plus de la matrice d'interaction normalisée, la
méthode utilise deux jeux de données supplémentaires avec des facteurs pour les clients et pour les services des fournisseurs sous la forme de matrices codées à chaud connectées à des matrices uniques:
 La logique de préparation de la matrice de génération des prévisions
La logique de préparation de la matrice de génération des prévisionsÉvaluation de la qualité
La qualité du modèle FM sur nos données s'est avérée inférieure à ALS:
Tableau comparatif des modèles de qualité et de référenceChanger l'architecture du modèle - Booster
Il a été décidé de venir de l'autre côté. Rappelant la répartition de la popularité des services, nous en avons identifié 300, transactions qui couvrent 80% de l'ensemble des opérations, et formé un classificateur sur celles-ci. Ici, les données représentent des agrégats de transactions client enrichis de fonctionnalités client:
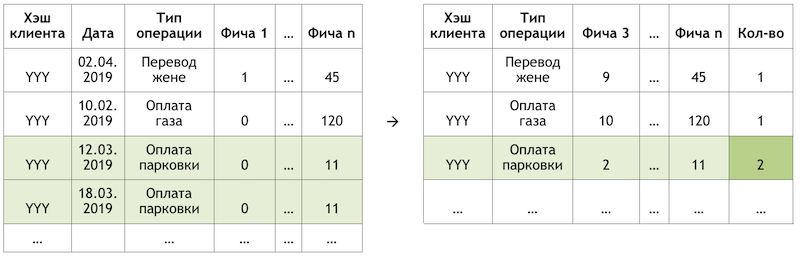 Schéma d'agrégation de transactions
Schéma d'agrégation de transactionsPourquoi seulement côté client, demandez-vous? Parce que dans ce cas, pour préparer des recommandations, il nous suffira d'avoir une ligne par client. En lui appliquant le modèle, nous obtenons le vecteur de sortie des probabilités pour toutes les classes, à partir duquel il est facile de choisir des recommandations top-K. Si nous ajoutons les fonctionnalités des services du fournisseur à l'ensemble de formation, alors au stade de l'application du modèle, nous serons obligés soit de préparer 300 lignes pour chaque client - une pour chaque service du fournisseur avec des fonctionnalités les décrivant, soit de construire un autre modèle pour le tri préalable des candidats évaluant les candidats. .
L'ajout de fonctionnalités aux clients de la SLA n'a pas augmenté nos données, car nous avons déjà pris en compte l'activité transactionnelle - par exemple, dans des sections de MCC ou des catégories dans le style de "gamer" ou de "théâtre". Dans ce format, nous avons réussi à obtenir de bons résultats:
Tableau comparatif des modèles de qualité et de référenceFiltre régional
Malgré la haute qualité du modèle, un problème de plus demeure dans cette approche. Étant donné que l'architecture des données et du modèle n'implique pas l'utilisation de fonctionnalités des services des fournisseurs, le modèle ne prend pas pleinement en compte la géographie et peut recommander que les gens paient pour le service d'un fournisseur local d'une autre région. Pour minimiser ce risque, nous avons développé un petit filtre pour pré-couper les options avant de formuler des recommandations. Une fleur de récursivité facile est jetée sur l'algorithme:
- Nous collectons des informations sur la région du client à partir des profils bancaires et d'autres sources internes.
- Nous distinguons les principales régions de présence pour chaque fournisseur.
- Nous clarifions / complétons les informations sur la région du client par les régions des prestataires qu'il utilise.
Après ces manipulations, à
l' aide de
l'indice Herfindahl, nous séparons les prestataires régionaux, qui sont représentés dans un ensemble limité de régions, des prestataires fédéraux:
Séparation des prestataires par présence dans les régionsNous formons un masque avec des fournisseurs régionaux acceptables pour les clients et excluons les éléments inutiles des prédictions du modèle avant de créer une liste de recommandations.
Conclusion
Nous avons développé deux modèles qui forment ensemble un ensemble complet de recommandations sur les paiements et les transferts. Il a été possible de réduire le chemin du client pour la moitié des opérations récurrentes en un seul clic. Dans les plans futurs visant à améliorer le modèle des «opérations recommandées» à l'aide de données de rétroaction (les cartes peuvent être masquées, etc.), ce qui réduira le seuil de sélection des recommandations et augmentera la couverture. Il est également prévu d'étendre la couverture des paiements recommandés dans le modèle des «exemples de recherche» et de développer un algorithme d'optimisation de la notation pour celui-ci.
Nous sommes passés par la voie épineuse de la construction d'un système de recommandation de paiements et de transferts. Sur le chemin, nous avons eu des bosses et acquis de l'expérience dans la décomposition et la simplification de telles tâches, l'évaluation correcte de ces systèmes, l'applicabilité des méthodes, un travail optimal avec de grands volumes de données et nous avons considérablement élargi notre compréhension des spécificités de ces tâches. En chemin, j'ai réussi à contribuer à l'open source, que nous utilisons nous-mêmes. Je vous souhaite des tâches intéressantes, des lignes de base réalistes et une F1 unique. Merci de votre attention!