Cet article est une sorte de master class «DVC pour automatiser les expériences ML et le versionnage des données», qui a eu lieu le 18 juin au ML REPA (Machine Learning REPA:
Reproductibilité, Expériences et Automatisation des Pipelines) sur notre site bancaire.
Ici, je vais parler des caractéristiques du travail interne de DVC et comment l'utiliser dans des projets.
Les exemples de code utilisés dans l'article sont disponibles
ici . Le code a été testé sur MacOS et Linux (Ubuntu).
Table des matières
Partie 1
2e partie
Configuration DVC
Le contrôle de version des données est un outil conçu pour gérer les versions de modèle et de données dans les projets ML. Il est utile à la fois au stade expérimental et pour le déploiement de vos modèles en exploitation.
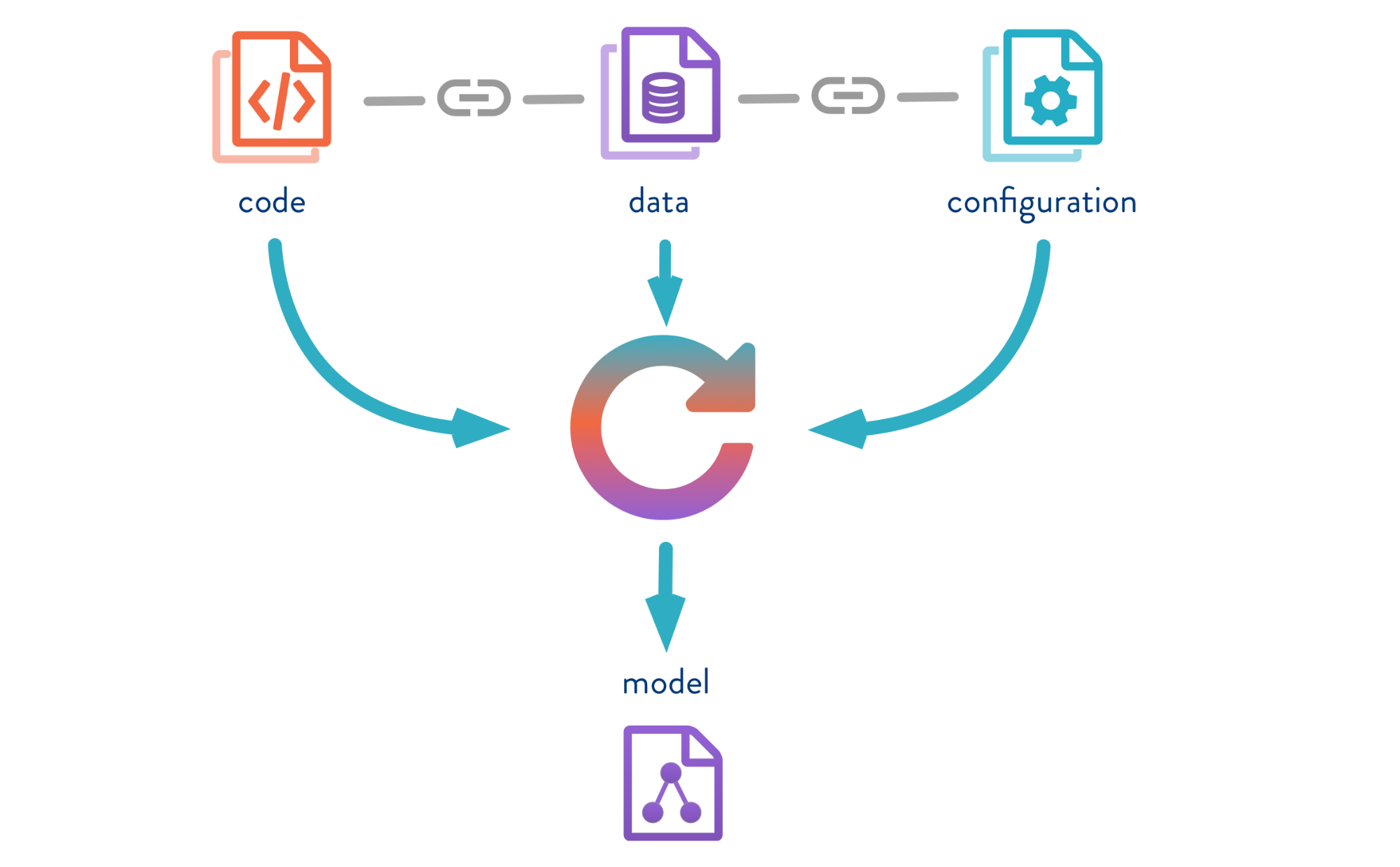
DVC vous permet de versionner des modèles, des données et des pipelines dans des projets DS.
La source est
ici .
Regardons le fonctionnement du DVC en utilisant l'exemple du problème de classification des couleurs de l'iris. Pour cela,
Iris Data Set sera utilisé. Jupyter Notebook fournit d'autres
exemples de travail avec DVC.
Ce que vous devez faire:- cloner un référentiel;
- créer un environnement virtuel;
- installez les packages python nécessaires;
- initialiser DVC.
Nous clonons donc le référentiel, créons un environnement virtuel et installons les packages nécessaires. Les instructions d'installation et de lancement se trouvent dans le référentiel README.
1. Clonez ce référentiel
git clone https://gitlab.com/7labs.ru/tutorials-dvc/dvc-1-get-started.git cd dvc-1-get-started
2. Créez et activez un environnement virtuel
pip install virtualenv virtualenv venv source venv/bin/activate
3. Installez les bibliothèques python (y compris dvc)
pip install -r requirements.txt
Pour installer DVC, utilisez la commande
pip install dvc . Après l'installation, vous devez initialiser le DVC dans le dossier du projet
dvc init , qui générera un ensemble de dossiers pour les travaux ultérieurs du DVC.
4. extraire une nouvelle branche dans le référentiel de démonstration (pour ne pas effacer le contenu de la branche principale)
git checkout -b dvc-tutorial
5. Initialiser DVC
dvc init commit dvc init git commit -m "Initialize DVC"
DVC fonctionne au-dessus de Git, utilise son infrastructure et a une syntaxe similaire.
Dans le processus, DVC crée des méta-fichiers pour décrire les pipelines et les fichiers versionnés, que vous devez enregistrer dans Git l'historique de votre projet. Par conséquent, après avoir exécuté
dvc init vous devez exécuter
git commit pour valider tous les paramètres
dvc init .
Le dossier
.dvc apparaîtra dans votre référentiel, dans lequel se trouvent le
cache et la
config .
Le contenu de
.dvc ressemblera à ceci:
./ ../ .gitignore cache/ config
La configuration est la configuration DVC et le cache est le dossier système dans lequel DVC stockera toutes les données et les modèles que vous allez mettre à jour.
DVC créera également un fichier
.gitignore , dans lequel il écrira les fichiers et dossiers qui n'ont pas besoin d'être validés dans le référentiel. Lorsque vous transférez un fichier vers DVC pour le contrôle de version dans Git, les versions et les métadonnées seront enregistrées et le fichier lui-même sera stocké dans le cache.
Vous devez maintenant installer toutes les dépendances, puis effectuer une
checkout dans la nouvelle branche
dvc-tutorial , dans laquelle nous travaillerons. Et téléchargez l'ensemble de données Iris.
Obtenir des données
wget -P data/ https://raw.githubusercontent.com/uiuc-cse/data-fa14/gh-pages/data/iris.csv
Caractéristiques DVC
Modèles de version et données
La source est
ici .
Permettez-moi de vous rappeler que si vous transférez des données sous le contrôle du DVC, il commencera à suivre tous les changements. Et nous pouvons travailler avec ces données de la même manière qu'avec Git: enregistrer la version, l'envoyer au référentiel distant, obtenir la bonne version des données, changer et basculer entre les versions. L'interface chez DVC est très simple.
Entrez la commande
dvc add et spécifiez le chemin d'accès au fichier dont nous avons besoin pour la version. DVC créera le métafichier iris.csv avec l'extension .dvc et écrira des informations à ce sujet dans le dossier cache. Commettons ces modifications afin que les informations sur le début du contrôle de version apparaissent dans l'historique Git.
dvc add data/iris.csv
À l'intérieur du fichier dvc généré, son hachage est stocké avec des paramètres standard.
Output - le chemin d'accès au fichier dans le dossier dvc, que nous avons ajouté sous le contrôle de DVC. Le système prend les données, les place dans le cache et crée un lien vers le cache dans le répertoire de travail. Ce fichier peut être ajouté à l'historique Git et ainsi versionné. DVC prend en charge la gestion des données elles-mêmes. Les deux premiers caractères du hachage sont utilisés comme dossier dans le cache et les caractères restants sont utilisés comme nom du fichier créé.
 Automatisation des pipelines ML
Automatisation des pipelines MLEn plus du contrôle de la version des données, nous pouvons créer des pipelines (pipelines) - des chaînes de calculs entre lesquelles des dépendances sont définies. Voici le pipeline standard pour la formation et l'évaluation des classificateurs:
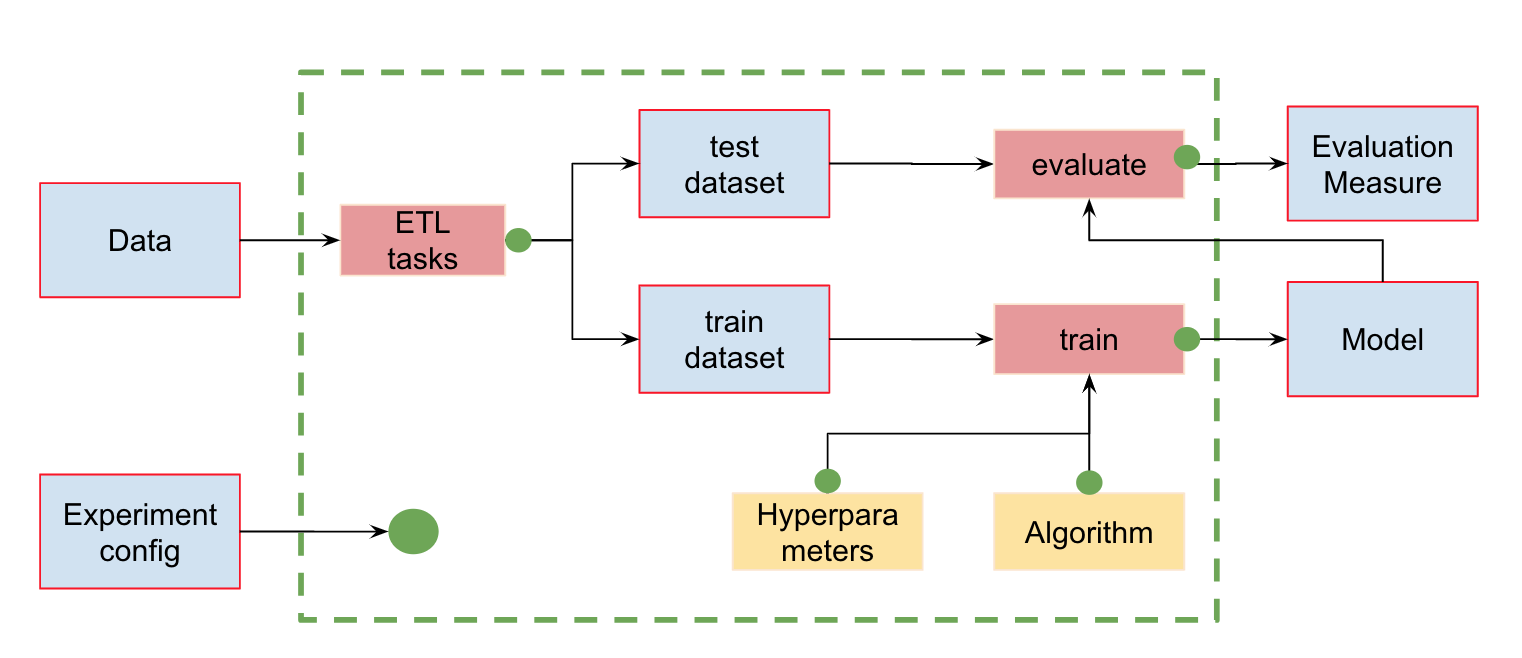
En entrée, nous avons des données qui doivent être prétraitées, divisées en train et test, calculer les caractéristiques et ensuite seulement former le modèle et l'évaluer. Ce pipeline peut être divisé en plusieurs parties. Par exemple, pour distinguer le stade de chargement et de prétraitement des données, le fractionnement des données, l'évaluation, etc. et la connexion de ces chaînes.
Pour ce faire, le DVC dispose d'une merveilleuse commande
dvc run , dans laquelle nous passons certains paramètres et spécifions le module Python que nous devons exécuter.
Maintenant - par exemple, la phase de lancement du calcul des signes. Tout d'abord, regardons le contenu du module featureization.py:
import pandas as pd def get_features(dataset): features = dataset.copy()
Ce code prend l'ensemble de données, calcule les caractéristiques et les enregistre dans iris_featurized.csv. Nous avons laissé le calcul des signes supplémentaires à l'étape suivante.
Pour créer un pipeline, vous devez exécuter la commande pour chaque étape du calcul
dvc run .

Tout d'abord, dans la commande
dvc run , spécifiez le nom du métafichier stage_feature_extraction.dvc, dans lequel le DVC écrira les métadonnées nécessaires concernant l'étape de calcul. Grâce à l'argument
-d , nous spécifions les dépendances nécessaires: le module featureization.py et le fichier de données iris.csv. Nous spécifions également le fichier iris_featurized.csv, dans lequel les signes sont enregistrés, et la commande de lancement python src / featurization.py elle-même.
dvc run -f stage_feature_extraction.dvc \ -d src/featurization.py \ -d data/iris.csv \ -o data/iris_featurized.csv \ python src/featurization.py
Le DVC créera un métafichier et suivra les modifications dans le module Python et le fichier iris.csv.
Si des modifications s'y produisent, le DVC redémarre cette étape de calcul dans le pipeline.
Le fichier stage_feature_extraction.dvc résultant contiendra son hachage, sa commande de démarrage, ses dépendances et sa sortie (il existe des paramètres supplémentaires pour eux qui peuvent être trouvés dans les métadonnées).
Vous devez maintenant enregistrer ce fichier dans l'historique des validations Git. Ainsi, nous pouvons créer une nouvelle branche et la pousser dans le référentiel Git. Vous pouvez vous engager dans une histoire Git en créant chaque étape individuellement ou toutes les étapes à la fois.
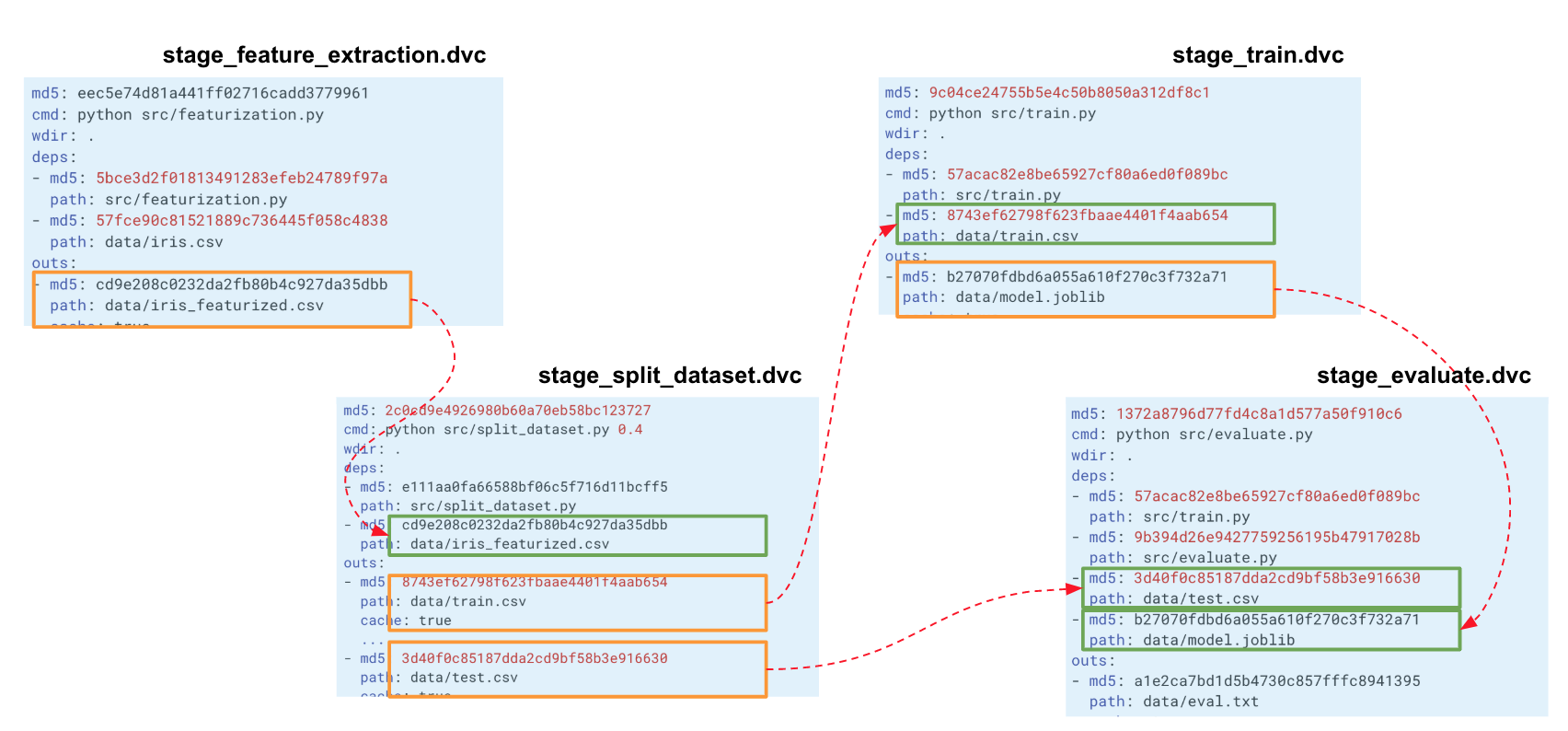
Lorsque nous construisons une telle chaîne pour l'ensemble de notre expérience, DVC crée un graphe de calcul (DAG), par lequel il peut commencer soit le recalcul de l'ensemble du pipeline ou d'une partie. Les hachages de la sortie d'un étage vont aux entrées d'un autre. Selon eux, DVC suit les dépendances et construit un graphique de calculs. Si vous avez modifié le code quelque part dans split_dataset.py, le DVC ne chargera pas les données et recalculera éventuellement les signes, mais redémarrera cette étape et les étapes de formation et d'évaluation suivantes.
 Suivi des métriques
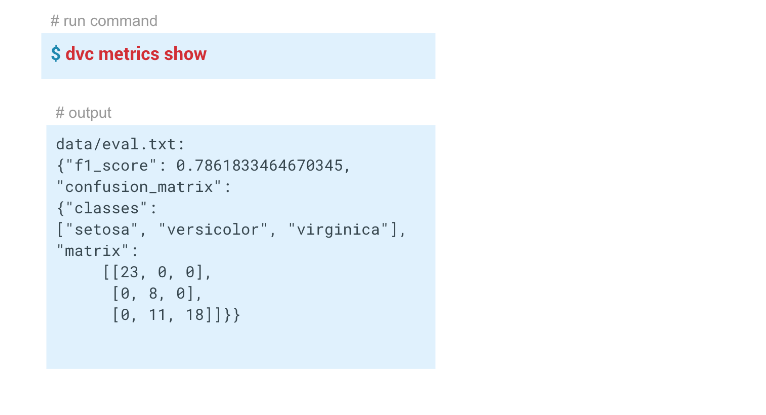
Suivi des métriquesÀ l'aide de la commande
dvc metrics show , vous pouvez afficher les métriques du lancement actuel, la branche dans laquelle nous nous trouvons. Et si nous passons l'option
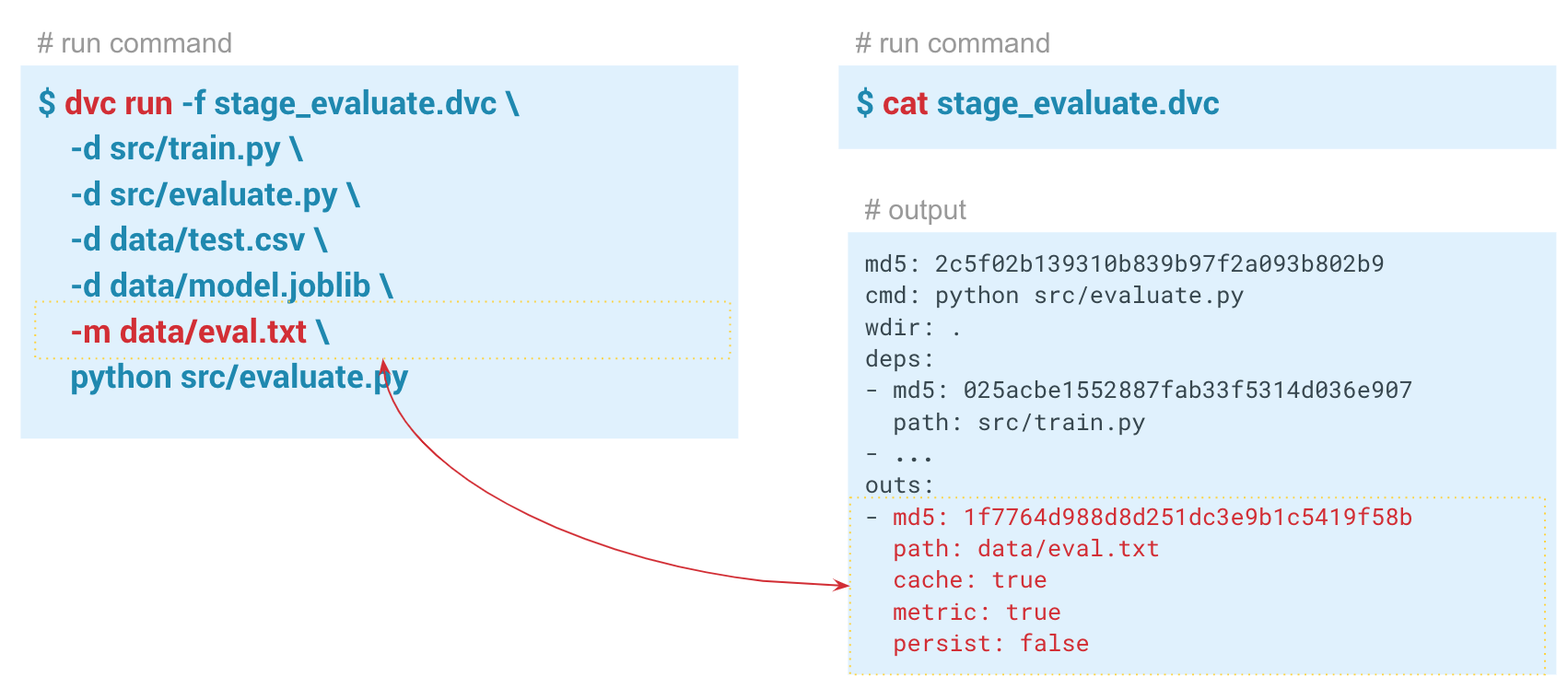
-a , le DVC affichera toutes les métriques qui sont dans l'historique Git. Pour que DVC commence à suivre les métriques, lors de la création de l'étape d'évaluation, nous passons le paramètre
-m via data / eval.txt. Le module assess.py écrit des métriques dans ce fichier, dans ce cas
f1 et des
confusion metrics . Dans le dossier de sortie du fichier dvc de cette étape, le
cache et les
metrics définis sur true. En d'autres termes, la commande dvc metrics show affichera le contenu du fichier eval.txt sur la console. De plus, en utilisant les arguments de cette commande, vous pouvez afficher uniquement
f1_score ou seulement
confusion_matrix .
Dans cet exemple, nous avons obtenu ces résultats:
 Reproductibilité du pipeline
Reproductibilité du pipelineCeux qui ont travaillé avec cet ensemble de données savent qu'il est très difficile de construire un bon modèle dessus.
Nous avons maintenant un pipeline créé à l'aide de DVC. Le système suit l'historique des données et du modèle, peut se redémarrer en tout ou en partie et peut afficher des mesures. Nous avons terminé toute l'automatisation nécessaire.
Nous avions un modèle avec f1 = 0,78. Nous voulons l'améliorer en modifiant certains paramètres. Pour ce faire, redémarrez l'intégralité du pipeline, idéalement, avec une seule commande. De plus, si vous travaillez en équipe, vous souhaiterez peut-être transmettre le modèle et le code à vos collègues afin qu'ils puissent continuer à travailler dessus.
La
dvc repro permet de redémarrer des pipelines ou des étapes individuelles (dans ce cas, vous devez spécifier l'étape reproduite après la commande).
dvc repro stage_evaluate , l'étape tentera de redémarrer l'intégralité du pipeline. Mais si nous faisons cela dans l'état actuel, le DVC ne verra aucun changement et ne redémarrera pas. Et si nous changeons quelque chose, il trouvera le changement et redémarrera le pipeline à partir de ce moment.
$ dvc repro stage_evaluate.dvc Stage 'data/iris.csv.dvc' didn't change. Stage 'stage_feature_extraction.dvc' didn't change. Stage 'stage_split_dataset.dvc' didn't change. Stage 'stage_train.dvc' didn't change. Stage 'stage_evaluate.dvc' didn't change. Pipeline is up to date. Nothing to reproduce.
Dans ce cas, le DVC n'a vu aucun changement dans les dépendances de l'étape stage_evaluate et a refusé de redémarrer. Et si nous spécifions l'option
-f , il redémarrera toutes les étapes préliminaires et affichera un avertissement indiquant qu'il supprime les versions précédentes des données dont il effectuait le suivi. Chaque fois que le DVC redémarre la scène, il supprime le cache précédent, l'écrase en fait pour ne pas dupliquer les données. Au moment où le fichier DVC est lancé, son hachage sera vérifié, et s'il a changé, le pipeline redémarrera et écrasera toutes les sorties de ce pipeline. Si vous souhaitez éviter cela, vous devez d'abord exécuter une version spécifique des données dans un référentiel distant.
La possibilité de redémarrer les pipelines et de suivre les dépendances de chaque étape vous permet d'expérimenter plus rapidement avec des modèles.
Par exemple, vous pouvez modifier les caractéristiques ("décommenter" les lignes de calcul des caractéristiques dans
featurization.py ). DVC verra ces changements et redémarrera l'ensemble du pipeline.
Enregistrement de données dans un référentiel distant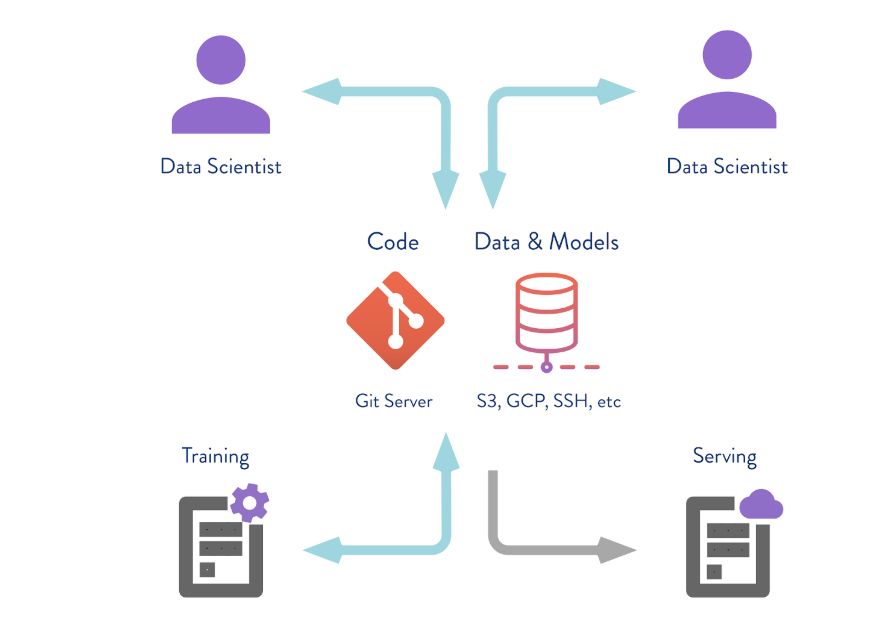
DVC peut fonctionner non seulement avec le stockage de version locale. Si vous exécutez la commande
dvc push , le DVC enverra la version actuelle du modèle et des données à un référentiel de référentiel distant préconfiguré. Si votre collègue fait ensuite le
git clone votre référentiel et de
dvc pull , il obtiendra la version des données et des modèles qui est destinée à cette branche. L'essentiel est que tout le monde ait accès à ce référentiel.
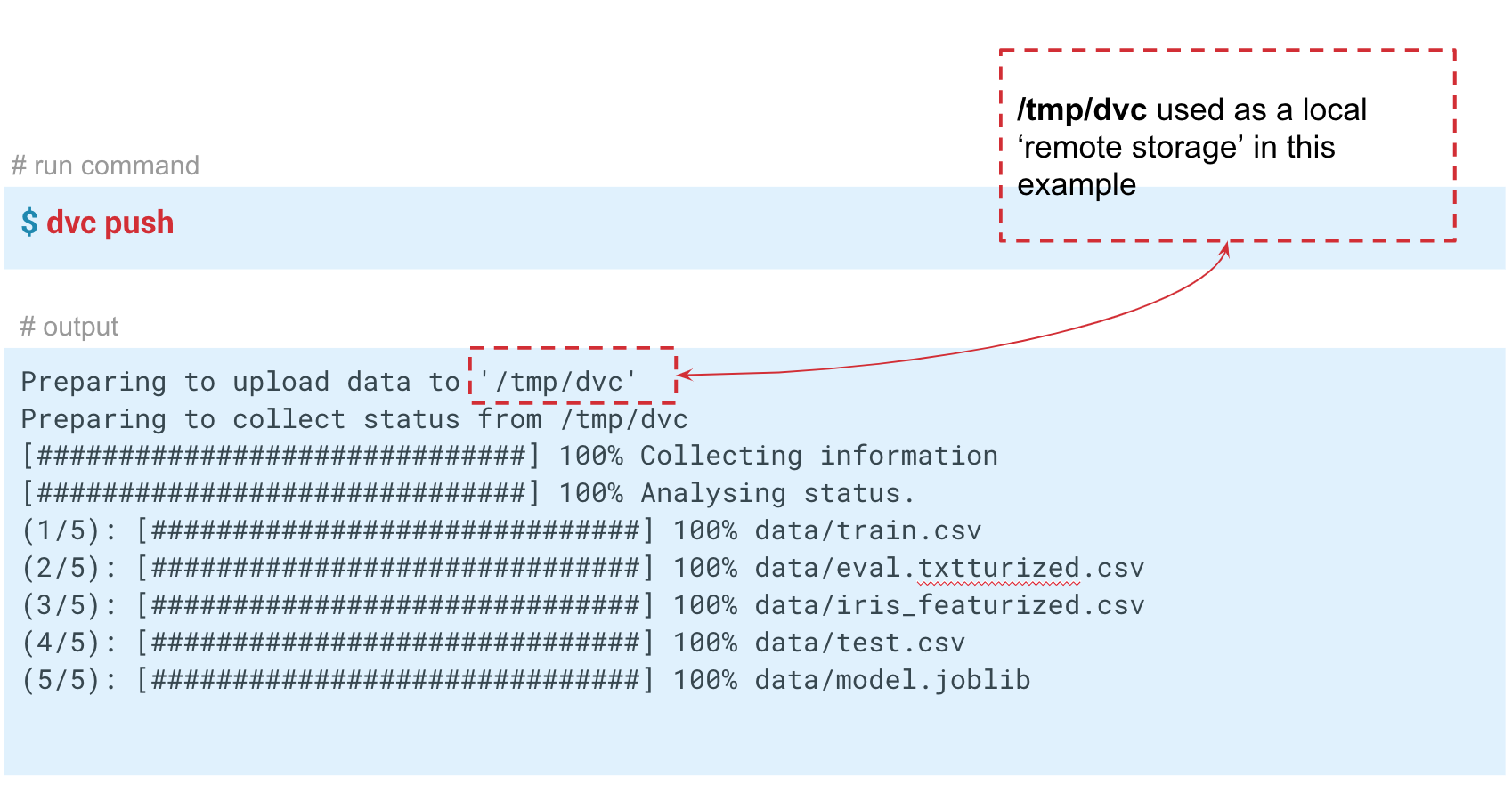
Dans ce cas, nous simulons le stockage «distant» dans le dossier temp / dvc. De la même manière, le stockage distant est créé dans le cloud. Validez ce changement pour qu'il reste dans l'histoire de Git. Maintenant, nous pouvons faire
dvc push pour envoyer des données à ce stockage, et votre collègue fait juste
dvc pull pour les obtenir.
Nous avons donc examiné trois situations dans lesquelles le DVC et les fonctionnalités de base sont utiles:
- Version des données et des modèles . Si vous n'avez pas besoin de pipelines et de référentiels distants, vous pouvez versionner les données pour un projet spécifique, en travaillant sur la machine locale. DVC vous permet de travailler rapidement avec des données en dizaines de gigaoctets.
- Échange de données et de modèles entre équipes . Vous pouvez utiliser des solutions cloud pour stocker des données. Il s'agit d'une option pratique si vous avez une équipe distribuée ou s'il existe des restrictions sur la taille des fichiers envoyés par courrier. En outre, cette technique peut être utilisée dans des situations où vous vous envoyez un carnet, mais elles ne démarrent pas.
- Organisation du travail d'équipe au sein d'un grand serveur . L'équipe peut travailler avec la version locale des mégadonnées, par exemple plusieurs dizaines ou centaines de gigaoctets, de sorte que vous ne les copiez pas d'avant en arrière, mais utilisez un stockage distant qui n'enverra et n'enregistrera que les versions critiques des modèles ou des données.
2e partie
Comment implémenter DVC dans vos projets?Pour assurer la reproductibilité du projet, certaines exigences doivent être respectées.
En voici les principaux:
- tous les pipelines sont automatisés;
- contrôle des paramètres de lancement de chaque étape des calculs;
- contrôle de version du code, des données et des modèles;
- contrôle environnemental;
- la documentation.
Si tout cela est fait, alors le projet est plus susceptible d'être reproductible. DVC vous permet de remplir les 3 premières exigences de cette liste.
Lorsque vous essayez de mettre en œuvre le DVC dans votre entreprise, vous pouvez rencontrer des réticences: «Pourquoi en avons-nous besoin? Nous avons un cahier Jupyter. " Certains de vos collègues ne travaillent peut-être qu'avec Jupyter Notebook, et il leur est beaucoup plus difficile d'écrire de tels pipelines et du code dans l'EDI. Dans ce cas, vous pouvez passer par une implémentation étape par étape.
- La façon la plus simple de commencer est de versionner le code et les modèles.
Et puis passez à l'automatisation des pipelines. - Automatisez d'abord les étapes qui redémarrent et changent souvent,
puis l'ensemble du pipeline.
Si vous avez un nouveau projet et quelques passionnés dans une équipe, il est préférable d'utiliser DVC immédiatement. Ainsi, par exemple, cela s'est avéré dans notre équipe! Lors du démarrage d'un nouveau projet, mes collègues m'ont soutenu et nous avons commencé à utiliser le DVC par nous-mêmes. Ensuite, ils ont commencé à partager avec d'autres collègues et équipes. Quelqu'un a repris notre engagement. Aujourd'hui, le DVC n'est pas encore un outil généralement accepté dans notre banque, mais il est utilisé dans plusieurs projets.