Remarque perev. : Nous présentons à votre attention des détails techniques sur les raisons de la récente panne du service cloud, servi par les créateurs de Grafana. Ceci est un exemple classique de la façon dont une nouvelle fonctionnalité apparemment extrêmement utile conçue pour améliorer la qualité des infrastructures ... peut faire beaucoup de mal si l'on ne prévoit pas les nombreuses nuances de son application dans les réalités de la production. C'est merveilleux quand de tels documents apparaissent qui vous permettent non seulement d'apprendre de vos erreurs. Les détails se trouvent dans la traduction de ce texte du vice-président des produits de Grafana Labs.
Vendredi 19 juillet, le service Hosted Prometheus de Grafana Cloud a cessé de fonctionner pendant environ 30 minutes. Je m'excuse auprès de tous les clients qui ont souffert de l'échec. Notre tâche est de fournir les outils nécessaires au suivi, et nous comprenons que leur inaccessibilité complique votre vie. Nous prenons cet incident très au sérieux. Cette note explique ce qui s'est passé, comment nous y avons réagi et ce que nous faisons pour que cela ne se reproduise plus.
Contexte
Le service Grafana Cloud Hosted Prometheus est basé sur
Cortex , un projet de la CNCF visant à créer un service Prometheus évolutif, hautement accessible et multi-locataire. L'architecture Cortex est constituée d'un ensemble de microservices distincts, chacun remplissant sa fonction: réplication, stockage, requêtes, etc. Cortex se développe activement, il a constamment de nouvelles opportunités et améliore sa productivité. Nous déployons régulièrement de nouvelles versions de Cortex sur des clusters afin que les clients puissent profiter de ces opportunités - heureusement, Cortex peut mettre à jour sans temps d'arrêt.
Pour des mises à jour fluides, le service Ingester Cortex nécessite une réplique Ingester supplémentaire pendant le processus de mise à jour.
( Remarque : Ingester est le composant principal de Cortex. Sa tâche consiste à collecter un flux constant d'échantillons, à les regrouper en morceaux de Prometheus et à les stocker dans une base de données comme DynamoDB, BigTable ou Cassandra.) Cela permet aux Ingesters plus âgés. transmettre les données actuelles aux nouveaux Ingénieurs. Il convient de noter que les ingérents exigent des ressources. Pour leur travail, il est nécessaire d'avoir 4 cœurs et 15 Go de mémoire par pod, soit 25% de la puissance du processeur et de la mémoire de la machine de base dans le cas de nos clusters Kubernetes. En général, nous avons généralement beaucoup plus de ressources inutilisées dans un cluster que 4 cœurs et 15 Go de mémoire, de sorte que nous pouvons facilement exécuter ces ingérateurs supplémentaires lors des mises à jour.
Cependant, il arrive souvent qu'en fonctionnement normal aucune de ces machines ne dispose de ces 25% de ressources non réclamées. Oui, nous ne nous efforçons pas: le CPU et la mémoire sont toujours utiles pour d'autres processus. Pour résoudre ce problème, nous avons décidé d'utiliser
Kubernetes Pod Priorities . L'idée est de donner aux Ingesters une priorité plus élevée que les autres microservices (sans état). Lorsque nous devons exécuter un Ingester supplémentaire (N + 1), nous forçons temporairement d'autres pods plus petits. Ces pods sont transférés vers des ressources libres sur d'autres machines, laissant un «trou» suffisamment grand pour lancer un Ingester supplémentaire.
Jeudi 18 juillet, nous avons lancé quatre nouveaux niveaux de priorité dans nos clusters:
critique ,
élevé ,
moyen et
faible . Ils ont été testés sur un cluster interne sans trafic client pendant environ une semaine. Par défaut, les pods sans priorité donnée ont reçu
une priorité
moyenne ; une classe avec une priorité
élevée a été définie pour les Ingénieurs.
Critical était réservé à la surveillance (Prometheus, Alertmanager, node-exporter, kube-state-metrics, etc.). Notre configuration est ouverte, et voir PR
ici .
Accident
Vendredi 19 juillet, l'un des ingénieurs a lancé un nouveau cluster Cortex dédié pour un gros client. La configuration de ce cluster n'incluait pas les nouvelles priorités des pods, donc tous les nouveaux pods ont reçu la priorité par défaut -
medium .
Le cluster Kubernetes ne disposait pas de suffisamment de ressources pour le nouveau cluster Cortex, et le cluster de production Cortex existant n'a pas été mis à jour (les utilisateurs ont été laissés sans priorité
élevée ). Étant donné que les ingesters du nouveau cluster sont passés par défaut à
une priorité
moyenne et que les pods existants en production ont fonctionné sans priorité du tout, les ingesters du nouveau cluster ont chassé les ingesters du cluster de production Cortex existant.
ReplicaSet pour l'Ingester préempté dans le cluster de production a détecté le module préempté et en a créé un nouveau pour conserver le nombre de copies spécifié. Le nouveau pod a été défini sur
une priorité
moyenne par défaut, et le prochain "ancien" Ingénieur en production a perdu des ressources. Le résultat a été
un processus semblable à une avalanche qui a conduit à évincer toutes les gousses d'Ingester pour les clusters de production de Cortex.
Les ingestion gardent l'état et stockent les données des 12 dernières heures. Cela nous permet de les compresser plus efficacement avant d'écrire dans un stockage à long terme. Pour ce faire, Cortex répartit les données de la série à l'aide d'une table de hachage distribuée (DHT) et réplique chaque série sur trois ingérateurs à l'aide de la cohérence de quorum de style Dynamo. Cortex n'écrit pas de données sur les Ingesters, qui sont désactivés. Ainsi, lorsqu'un grand nombre d'Ingesters quittent la DHT, Cortex ne peut pas fournir une réplication suffisante des enregistrements et ils «tombent».
Détection et élimination
De nouvelles notifications Prometheus basées sur le "
budget basé sur l'
erreur " (les détails apparaissent dans un futur article) ont commencé à sonner l'alarme 4 minutes après le début de l'arrêt. Au cours des cinq minutes suivantes, nous avons effectué des diagnostics et étendu le cluster Kubernetes sous-jacent pour prendre en charge les clusters de production nouveaux et existants.
Cinq minutes plus tard, les anciens Ingesters ont enregistré avec succès leurs données, et les nouveaux ont démarré, et les clusters Cortex sont redevenus disponibles.
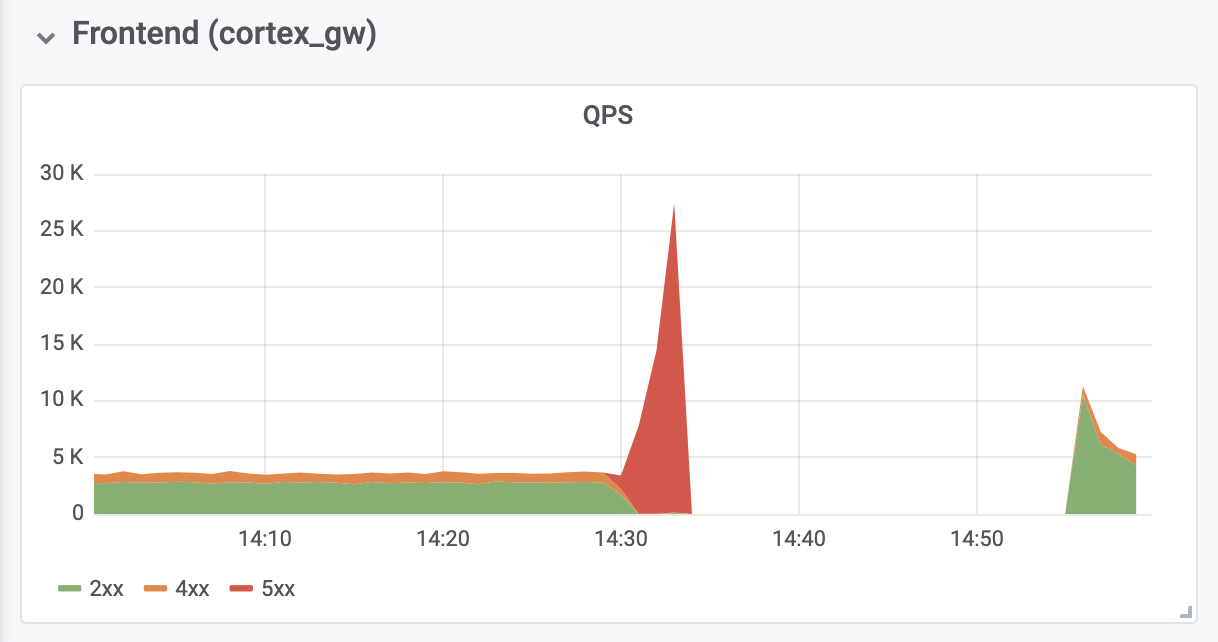
Il a fallu 10 minutes supplémentaires pour diagnostiquer et corriger les erreurs de mémoire insuffisante (MOO) à partir des proxys d'authentification inverse situés en face de Cortex. Les erreurs MOO ont été causées par une augmentation de dix fois de QPS (comme nous le pensons, en raison de demandes trop agressives de la part des serveurs clients Prometheus).
Les conséquences
Le temps d'arrêt total était de 26 minutes. Aucune donnée n'a été perdue. Les utilisateurs ont réussi à télécharger toutes les données en mémoire vers un stockage à long terme. Lors d'un arrêt, les serveurs clients Prometheus ont enregistré les entrées
distantes dans le tampon à l'aide de la
nouvelle API remote_write basée sur
WAL (créée par
Callum Styan de Grafana Labs) et ont répété les entrées ayant échoué après l'échec.
 Opérations d'écriture du cluster de production
Opérations d'écriture du cluster de productionConclusions
Il est important d'apprendre de cet incident et de prendre les mesures nécessaires pour éviter une récidive.
Rétrospectivement, nous devons admettre que nous n'aurions pas dû définir la priorité par défaut à
moyen tant que tous les ingestionnaires en production n'ont pas obtenu une priorité
élevée . De plus, ils auraient dû s'occuper à l'avance de leur priorité
élevée . Maintenant, tout est réparé. Nous espérons que notre expérience aidera d'autres organisations à envisager l'utilisation des priorités des pods dans Kubernetes.
Nous ajouterons un niveau de contrôle supplémentaire sur le déploiement de tout objet supplémentaire dont les configurations sont globales pour le cluster. Désormais, ces changements seront évalués par plus de personnes. En outre, la modification qui a conduit à l'échec a été jugée trop insignifiante pour un document de projet distinct - elle n'a été discutée que dans le problème GitHub. Désormais, toutes ces modifications de configuration seront accompagnées d'une documentation de projet appropriée.
Enfin, nous automatisons le redimensionnement du proxy d'authentification inverse pour éviter les MOO pendant la congestion, ce dont nous avons été témoins, et analysons les paramètres Prometheus par défaut liés à la restauration et à la mise à l'échelle pour éviter des problèmes similaires à l'avenir.
L'échec vécu a également eu des conséquences positives: après avoir reçu les ressources nécessaires, Cortex s'est automatiquement rétabli sans aucune intervention supplémentaire. Nous avons également acquis une expérience précieuse avec
Grafana Loki , notre nouveau système d'agrégation de journaux, qui a contribué à garantir que tous les ingestion se comportaient correctement pendant et après l'accident.
PS du traducteur
Lisez aussi dans notre blog: