Avant chaque service générant au moins 1 Mb / s de trafic Internet, la question se pose: «Comment? sur TCP ou sur UDP? " Dans les domaines d'application, y compris les plateformes de livraison, les préférences et les traditions de prise de telles décisions se sont déjà développées.
En théorie, si, par exemple, une fois qu'un développeur paresseux n'essayait pas de déployer son ML en Python (parce qu'il le savait seulement), le monde n'aurait probablement jamais été rempli d'un tel amour pour le langage méprisable des «encodeurs super-Java». Et aujourd'hui, les faiblesses de ce langage dans le contexte passé d'application lui confèrent sans condition la primauté dans le déploiement et le lancement de nombreux A / B miniers.
Vous pouvez comparer beaucoup: ARM avec Intel, iOS et Android et Mortal Kombat avec Injustice. Et courez dans un holivar spatial, revenons donc au sujet de la livraison d'énormes volumes de contenu multiformat.
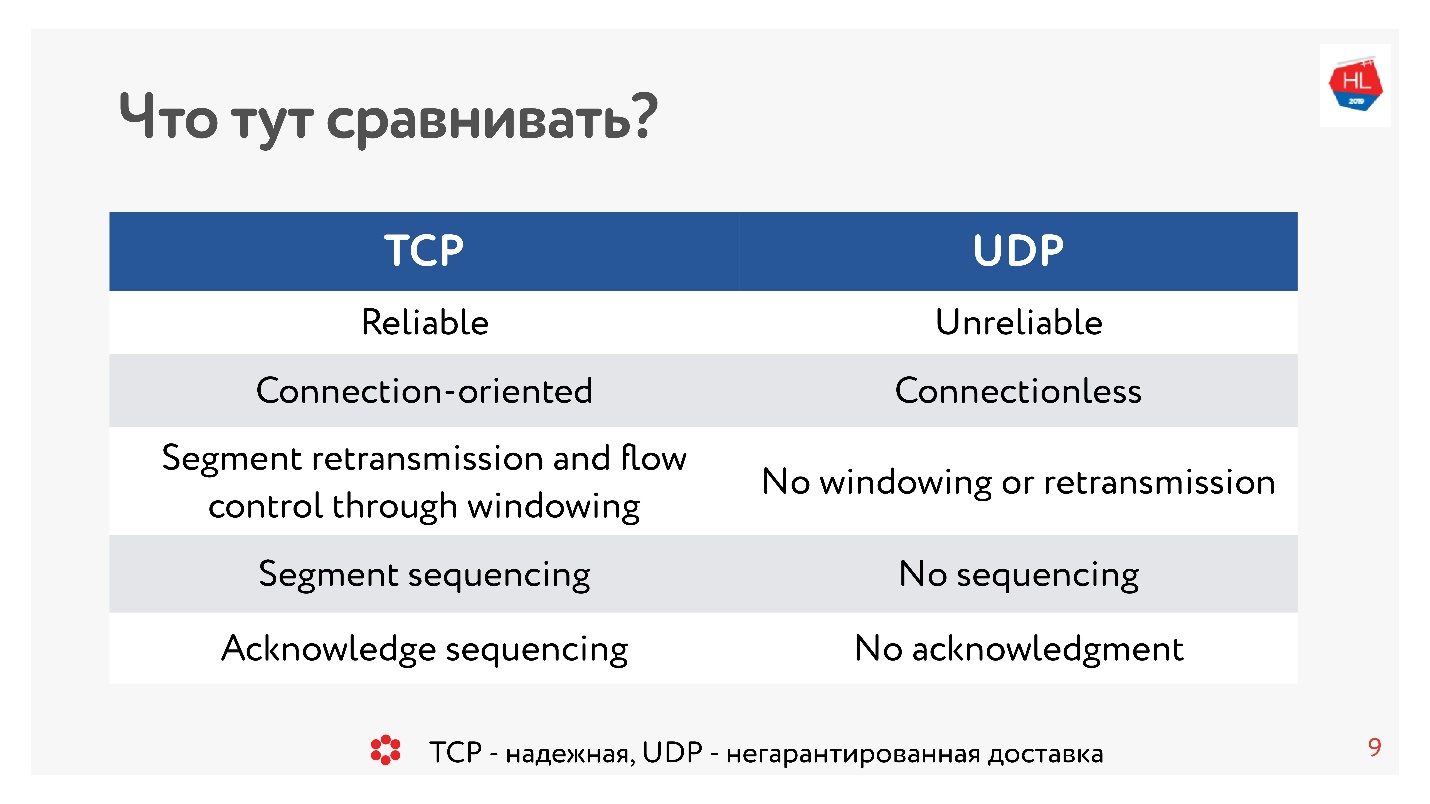
Il y a dix ans, tout le monde était absolument sûr que l'UDP était une livraison non garantie. Si vous avez besoin d'un protocole fiable, c'est TCP. Et contrairement à la tradition dans cet article, nous comparerons des choses apparemment incomparables comme TCP et UDP.
 Attention, sous la coupe 99 illustrations et schémas et tous importants.
Attention, sous la coupe 99 illustrations et schémas et tous importants.La comparaison est effectuée par le responsable du développement des plateformes Vidéo et Cassette chez OK
Alexander Tobol (
alatobol ). Les services de vidéo et de flux d'actualités sur le réseau social OK - exclusivement sur le contenu et sa diffusion sur toutes les plateformes clientes existantes dans des conditions réseau mauvaises ou excellentes, et la question de savoir comment le diffuser - via TCP ou UDP - est crucial.
TCP contre UDP. Théorie minimale
Pour arriver à la comparaison, nous avons besoin d'une petite théorie de base.
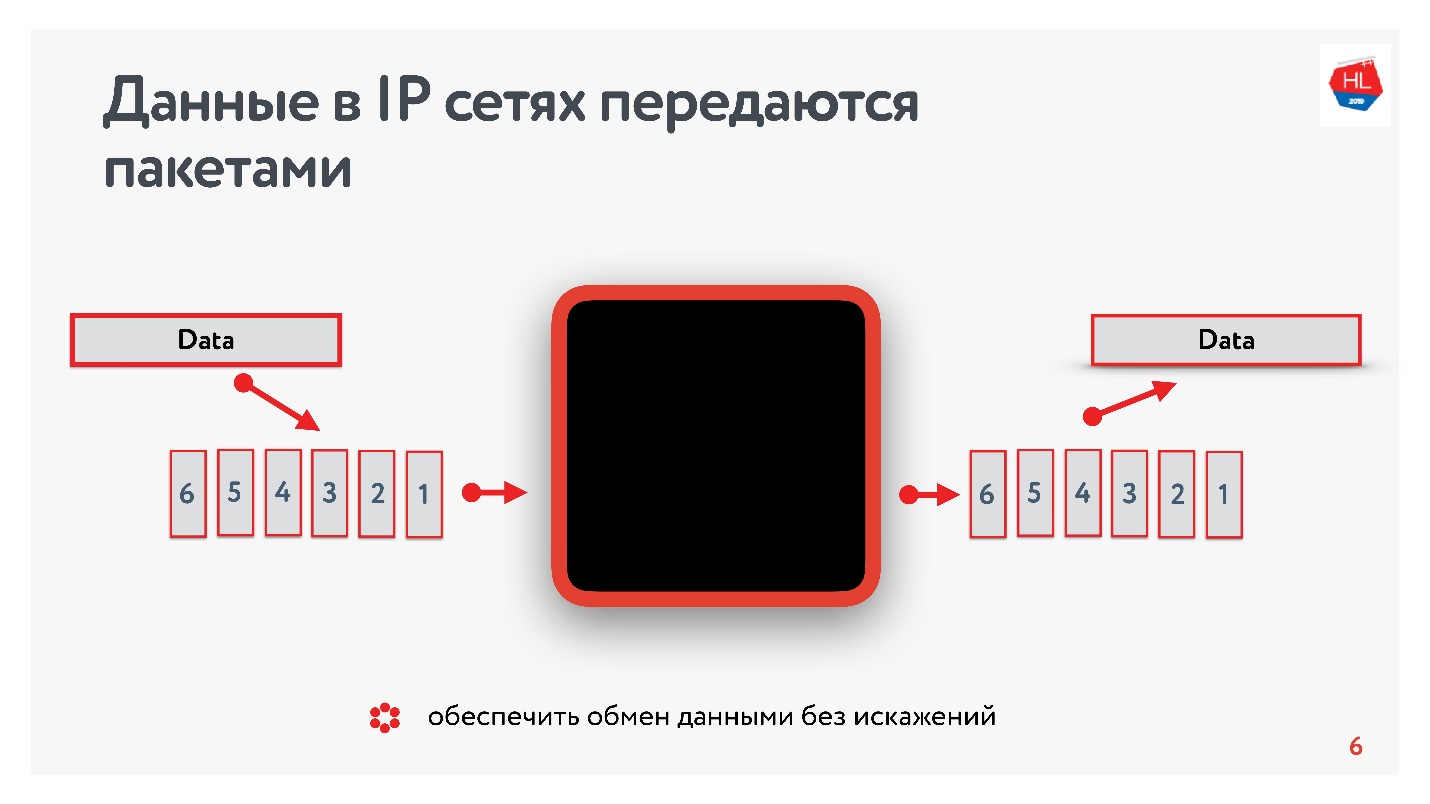
Que savons-nous des réseaux IP? Le flux de données que vous envoyez est divisé en paquets, une sorte de boîte noire remet ces paquets au client. Le client collecte des paquets et reçoit un flux de données. Habituellement, tout cela est transparent et il n'est pas nécessaire de penser à ce qui se trouve aux niveaux inférieurs.
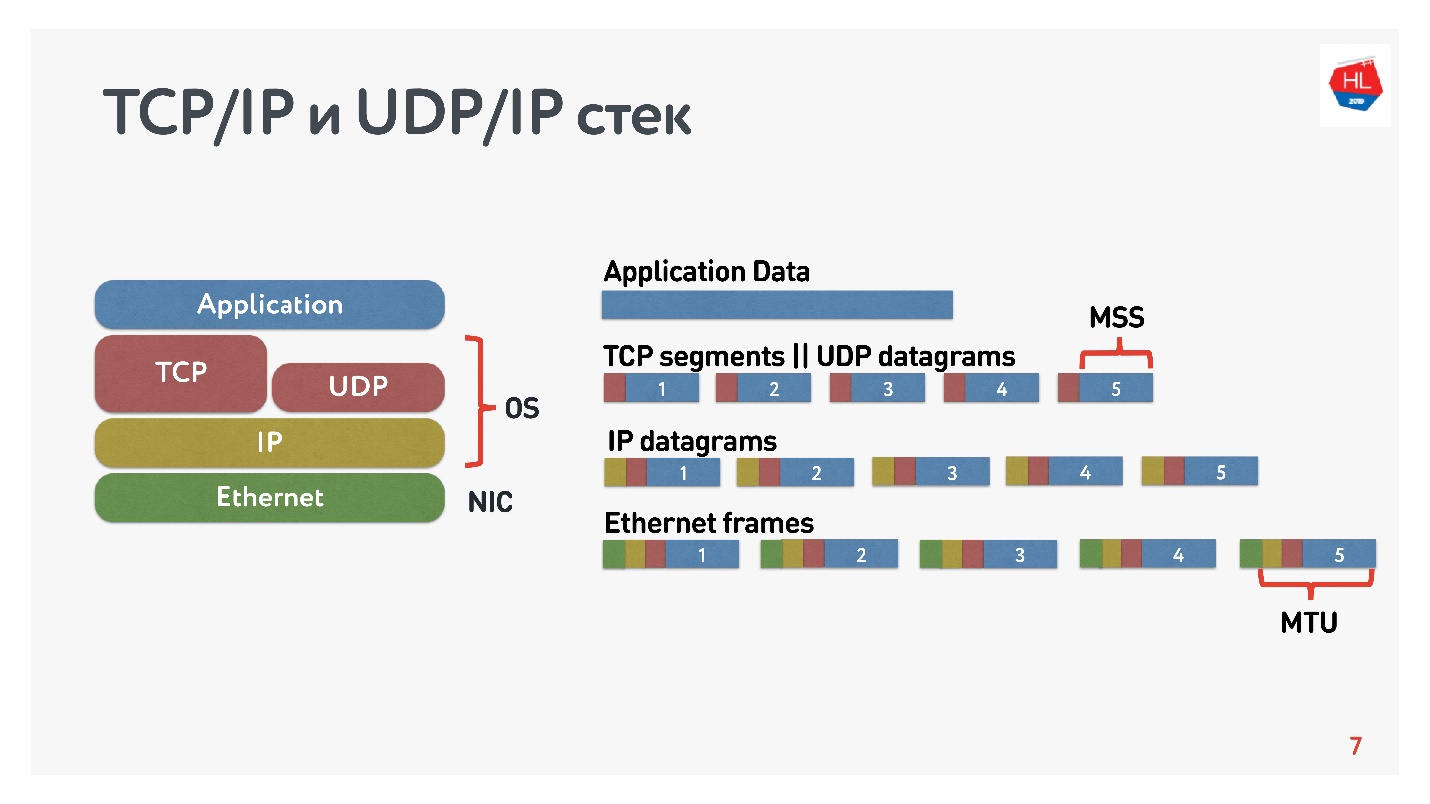
Le diagramme montre la pile TCP / IP et UDP / IP. En bas, il y a des paquets Ethernet, des paquets IP et, au niveau du système d'exploitation, il y a TCP et UDP. TCP et UDP dans cette pile ne sont pas très différents l'un de l'autre. Ils sont encapsulés dans des paquets IP et les applications peuvent les utiliser. Pour voir les différences, vous devez regarder à l'intérieur des paquets TCP et UDP.
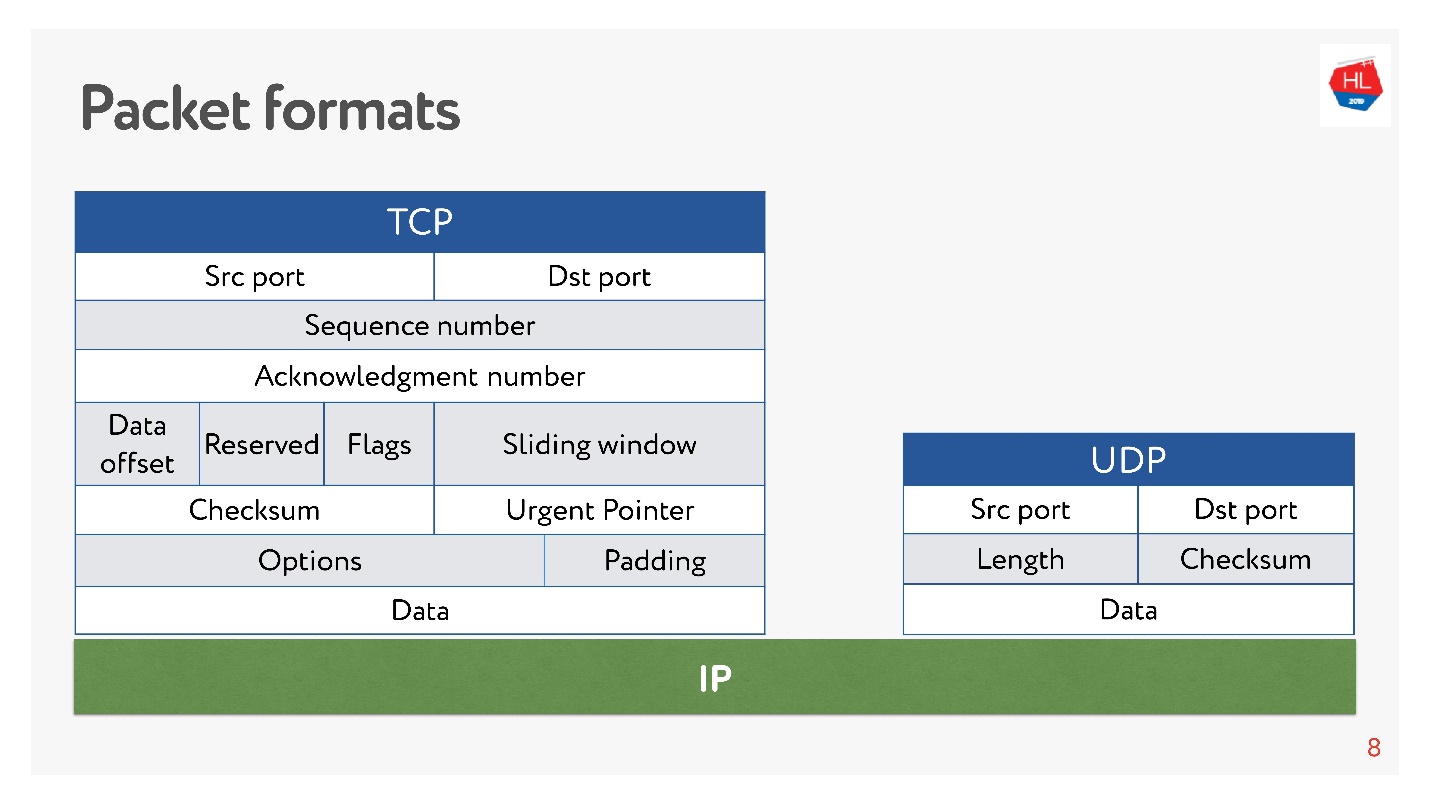
Là et il y a des ports. Mais
dans UDP, il n'y a qu'une somme de contrôle - la longueur du paquet, ce protocole est aussi simple que possible. Et dans TCP, il y a beaucoup de données qui indiquent clairement la fenêtre, l'accusé de réception, la séquence, les paquets, etc. De toute évidence,
TCP est plus complexe .
En termes très approximatifs, TCP est un protocole de livraison fiable et UDP n'est pas fiable.
Et pourtant, malgré la prétendue non-fiabilité de l'UDP, nous déterminerons s'il est possible de fournir des données plus rapidement et plus fiables qu'avec TCP. Essayons de regarder le réseau de l'intérieur et de comprendre comment il fonctionne. En cours de route, nous aborderons les questions suivantes:
- pourquoi comparer TCP ou ce qui ne va pas avec lui;
- avec quoi et sur quoi comparer TCP;
- ce que Google a fait et quelle décision il a prise;
- ce que l'avenir des protocoles réseau nous attend.
Cet article n'aura pas de théorie: les niveaux et modèles OSI, les modèles mathématiques complexes, bien que tout puisse être compté à travers eux. Nous analyserons au maximum comment toucher le réseau non pas en théorie, mais de nos propres mains.
Pourquoi comparer TCP ou ce qui ne va pas
TCP a été inventé en 1974 et 20 ans plus tard, quand je suis allé à l'école, j'ai acheté des cartes Internet, effacé le code et appelé quelque part. De plus, si vous appelez de 2 nuits à 7 heures du matin, Internet était gratuit, mais il était difficile de passer.
Vingt autres années se sont écoulées et les utilisateurs des réseaux sans fil mobiles ont commencé à prévaloir sur les utilisateurs «câblés», tandis que TCP n'a pas changé conceptuellement.
Le monde mobile a gagné, les protocoles sans fil sont apparus et TCP est resté inchangé.
Aujourd'hui, 80% des utilisateurs utilisent le Wi-Fi ou un réseau sans fil 3G-4G.

Dans les réseaux sans fil, il y a:
- perte de paquets - environ 0,6% des paquets que nous envoyons sont perdus en cours de route;
- réorganisation - le réarrangement des paquets dans des lieux, dans la vie réelle est un phénomène assez rare, mais cela se produit dans 0,2% des cas;
- gigue - lorsque les paquets sont envoyés uniformément et arrivent dans les files d'attente avec un retard d'environ 50 ms.
TCP vous cache avec succès toutes ces fonctionnalités de transfert de données dans des réseaux hétérogènes, et vous n'avez pas besoin de plonger à l'intérieur.
Ci-dessous sur la carte est le débit de données TCP moyen en Russie. Si vous supprimez la partie ouest, il est clair que la vitesse est mesurée plus en kilobits qu'en mégabits.
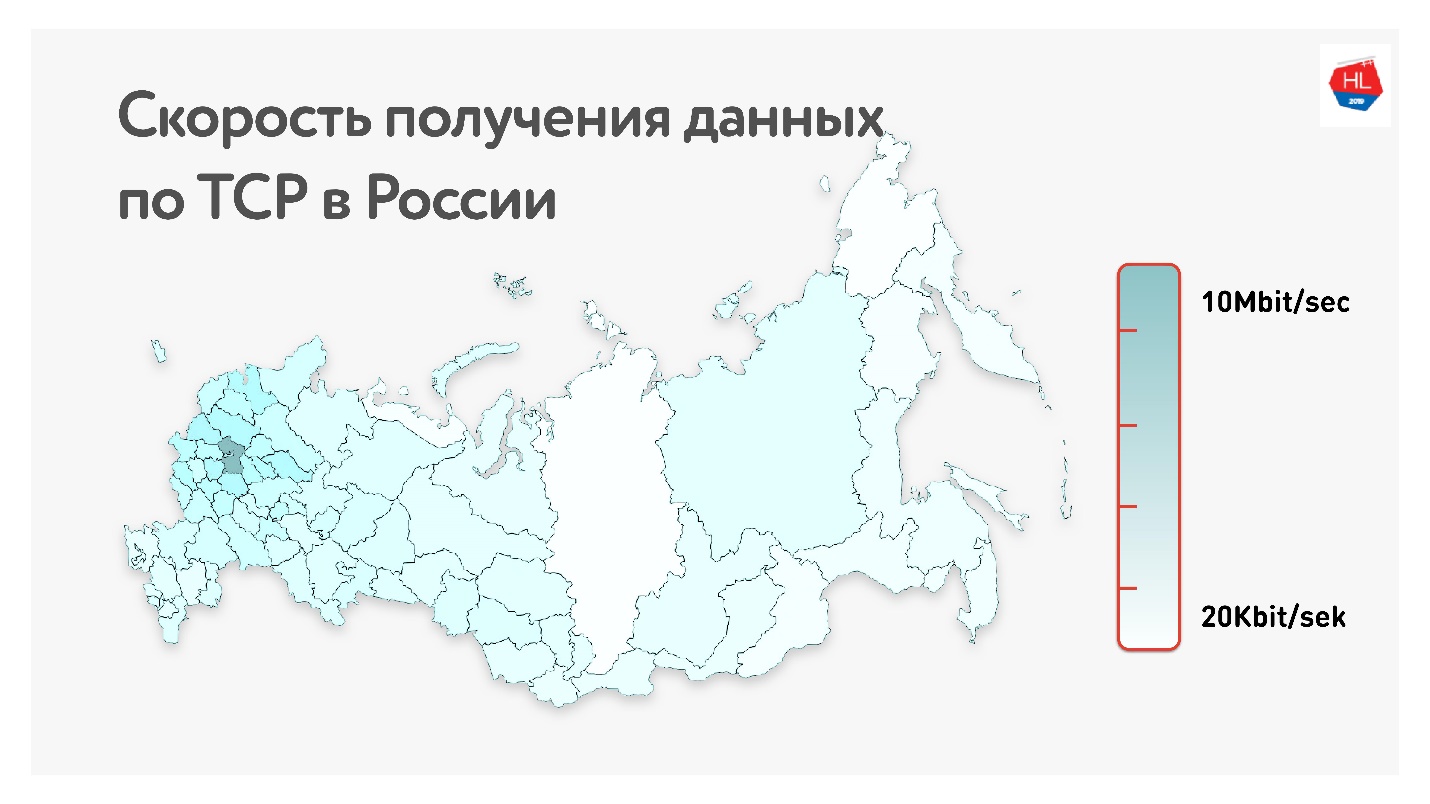
C'est, en moyenne, pour nos utilisateurs (hors partie ouest de la Russie): débit 1,1 Mbps, perte de paquets de 0,6%, RTT (aller-retour) de l'ordre de 200 ms.
Comment calculer RTT
Quand j'ai vu la moyenne de 200 ms, j'ai pensé qu'il y avait une erreur dans les statistiques, et j'ai décidé de mesurer le RTT à nos serveurs dans le MSC d'une manière alternative en utilisant RIPE Atlas. Il s'agit d'un système de collecte de données sur l'état d'Internet. La sonde
RIPE Atlas est disponible gratuitement.
L'essentiel est que vous le connectiez à votre Internet domestique et que vous collectiez le «karma». Elle travaille pendant des jours, certaines personnes répondent à certaines de ses demandes. Ensuite, vous pouvez définir vous-même diverses tâches. Un exemple d'une telle tâche: prendre accidentellement 30 points sur Internet et demander à mesurer RTT, c'est-à-dire exécuter la commande ping sur le site Web Odnoklassniki.
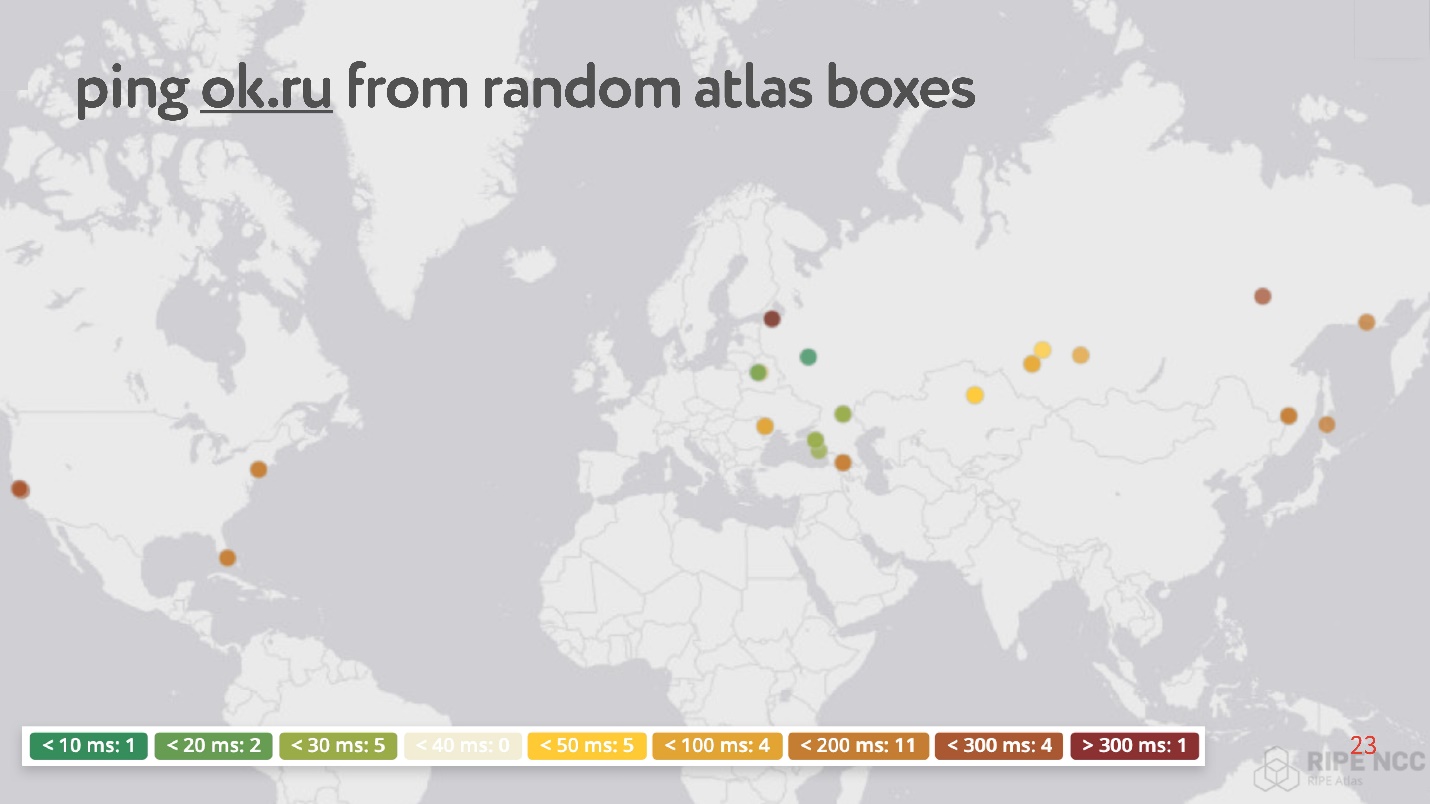
Curieusement, parmi les points aléatoires, il y en a beaucoup qui ont un ping de 200 à 300 ms.
Dans l'ensemble,
les réseaux sans fil sont populaires et instables (bien que ce dernier soit généralement ignoré, car on pense que TCP peut gérer cela):
- Plus de 80% des utilisateurs utilisent Internet sans fil;
- Les paramètres des réseaux sans fil changent dynamiquement en fonction, par exemple, du fait que l'utilisateur a tourné le coin;
- Les réseaux sans fil ont des taux élevés de perte de paquets, de gigue, de réorganisation;
- Canal asymétrique fixe, changement d'adresse IP.
La consommation de contenu dépend de la vitesse d'Internet
C'est très facile à vérifier - il y a beaucoup de statistiques. J'ai pris des
statistiques sur la vidéo, qui disent que plus la vitesse d'Internet dans le pays est élevée, plus les utilisateurs regardent la vidéo.
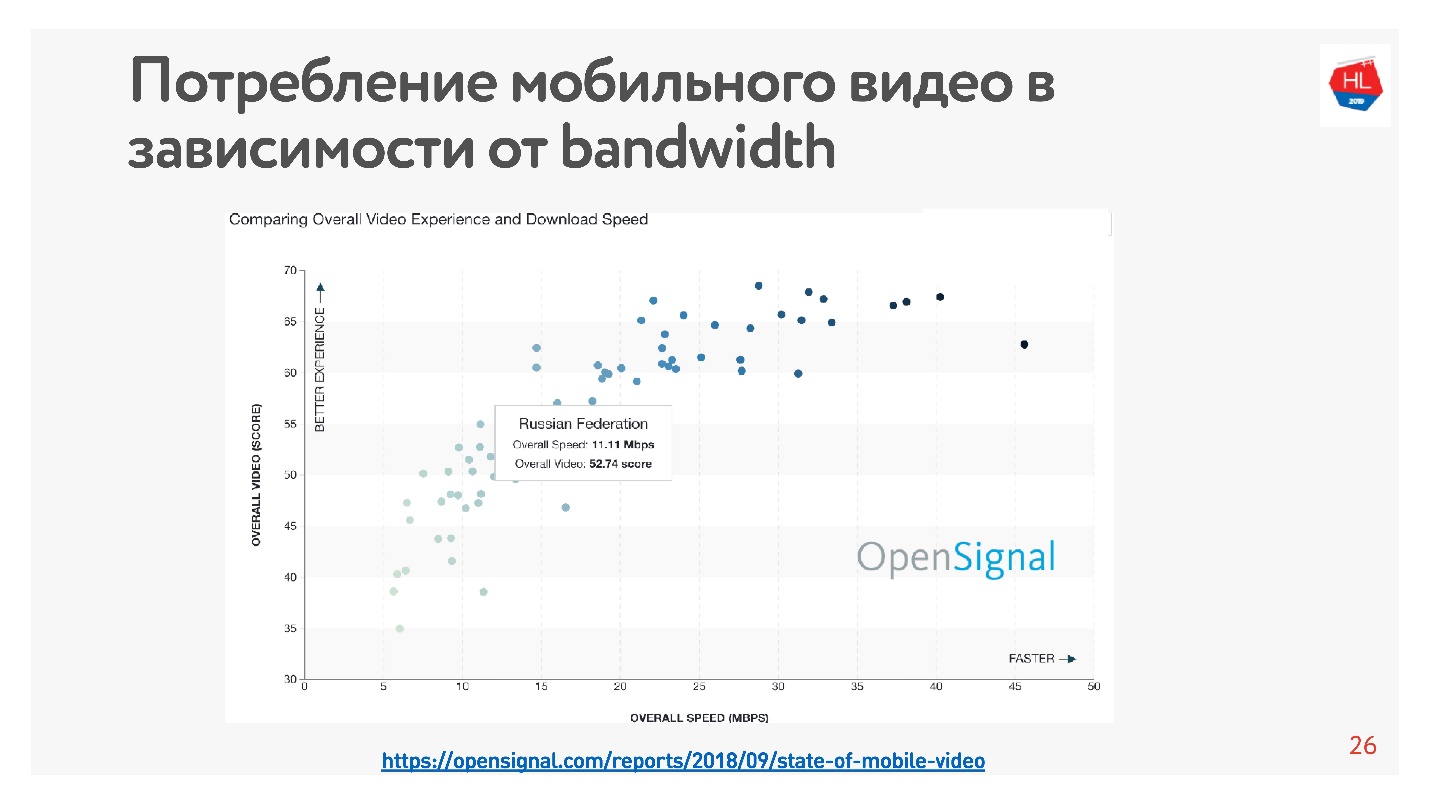
Selon ces statistiques, la Russie dispose d'un Internet assez rapide, mais selon nos données internes, la vitesse moyenne est légèrement inférieure.
En faveur du fait que la vitesse d'Internet dans son ensemble est insuffisante, il indique que tous les créateurs de grandes applications, de réseaux sociaux, de services vidéo, etc. optimisent leurs services pour travailler dans un mauvais réseau. Après 10 Ko de données reçues, vous pouvez voir un minimum d'informations dans la bande, et à une vitesse de 500 Ko, vous pouvez regarder la vidéo.
Comment accélérer le chargement
Dans le processus de développement de la plate-forme vidéo, nous avons réalisé que TCP n'est pas très efficace dans les réseaux sans fil. Comment en êtes-vous arrivé à cette conclusion?
Nous avons décidé d'accélérer le téléchargement et avons fait le tour suivant.
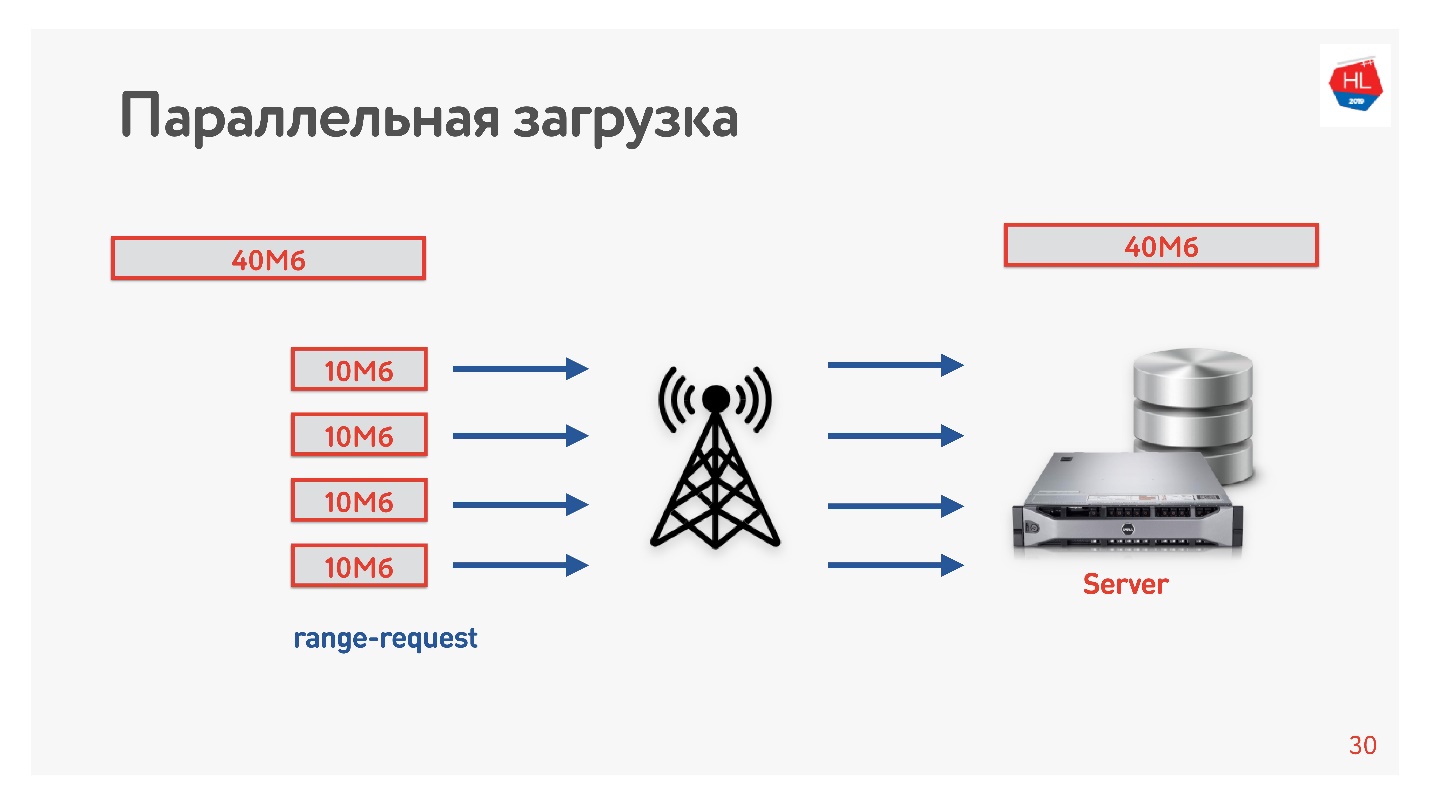
Nous avons téléchargé la vidéo du client sur le serveur en plusieurs flux, c'est-à-dire que 40 Mo sont divisés en 4 parties de 10 Mo et chargés en parallèle. Nous l'avons démarré sur Android et avons obtenu qu'il se charge en parallèle plus rapidement que dans une connexion (
démo dans le rapport). La chose la plus intéressante est que lorsque nous avons déployé des téléchargements parallèles en production, nous avons vu que dans certaines régions, la vitesse de téléchargement a augmenté de 3 fois!
Quatre connexions TCP peuvent effectivement télécharger des données sur le serveur 3 fois plus rapidement.
Nous avons donc augmenté la vitesse de téléchargement de la vidéo et conclu que le téléchargement devait être parallélisé.
TCP dans les réseaux instables
Un effet incroyable avec le parallélisme peut être touché. Il suffit de prendre un compteur de vitesse pour recevoir / envoyer des données (par exemple, Speed Test) et un modulateur de trafic (par exemple, conditionneur de liaison réseau, si vous avez un Mac) Nous limitons le réseau à 1 Mbps pour les téléchargements et téléchargements et commençons à augmenter la perte de paquets.

Le tableau montre le RTT et les pertes. On peut voir que dans le cas d'une perte de 0%, le réseau est utilisé à 100%.
À la prochaine itération, nous augmentons la perte de paquets de 5% et nous voyons que le réseau n'est utilisé que par 74%. Cela semble correct - avec une perte de paquets de 5%, 26% du réseau est perdu. Mais si vous augmentez également le ping, alors
moins de la moitié du canal restera.
Si le canal présente un RTT élevé et une perte de paquets importante, une connexion TCP n'utilise pas complètement le réseau.
Une autre astuce montre que si vous commencez à utiliser des connexions TCP parallèles (vous pouvez simplement exécuter plusieurs tests de vitesse en même temps), vous pouvez voir la croissance inverse de l'utilisation des canaux.
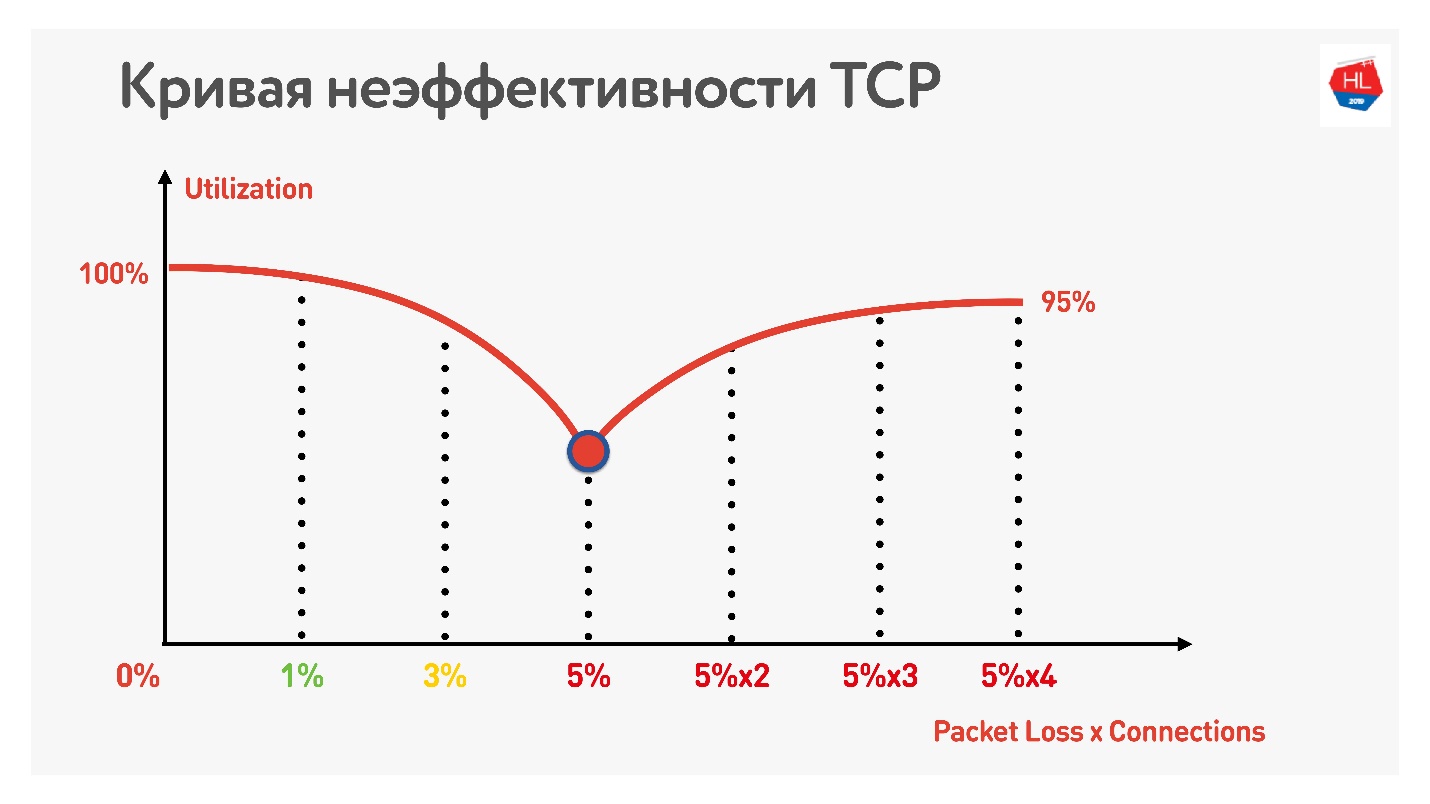
Avec une augmentation du nombre de connexions TCP parallèles, l'utilisation du réseau devient presque égale au débit, moins le pourcentage de pertes.
Ainsi, il s'est avéré:
- Les réseaux mobiles sans fil ont gagné et sont instables.
- TCP n'utilise pas pleinement le canal dans les réseaux instables.
- La consommation de contenu dépend de la vitesse d'Internet: plus la vitesse d'Internet est élevée, plus les utilisateurs regardent, et nous aimons vraiment nos utilisateurs et voulons qu'ils regardent plus.
De toute évidence, vous devez vous déplacer quelque part et envisager des alternatives à TCP.
TCP vs non TCP
Comment comparer le chaud? Il y a deux options.
La première option - au niveau IP, il y a TCP et UDP, nous pouvons nous permettre un autre protocole d'en haut. Évidemment, si vous démarrez votre propre protocole en parallèle avec TCP et UDP, le pare-feu, Brandmauer, les routeurs et le reste du monde impliqués dans la livraison de paquets ne le sauront pas. Par conséquent, vous devrez attendre des années lorsque tout l'équipement est mis à jour et commence à travailler avec le nouveau protocole.
La deuxième option consiste à créer votre propre protocole de livraison de données fiable sur UDP non fiable. Évidemment, vous pouvez attendre longtemps avant que Linux, Android et iOS ajoutent un nouveau protocole à votre noyau, vous devez donc couper le protocole dans l'espace utilisateur.
Cette solution semble intéressante, nous l'appellerons le protocole UDP self-made. Pour commencer à le développer, vous n'avez besoin de rien de spécial: ouvrez simplement le socket UDP et envoyez les données.
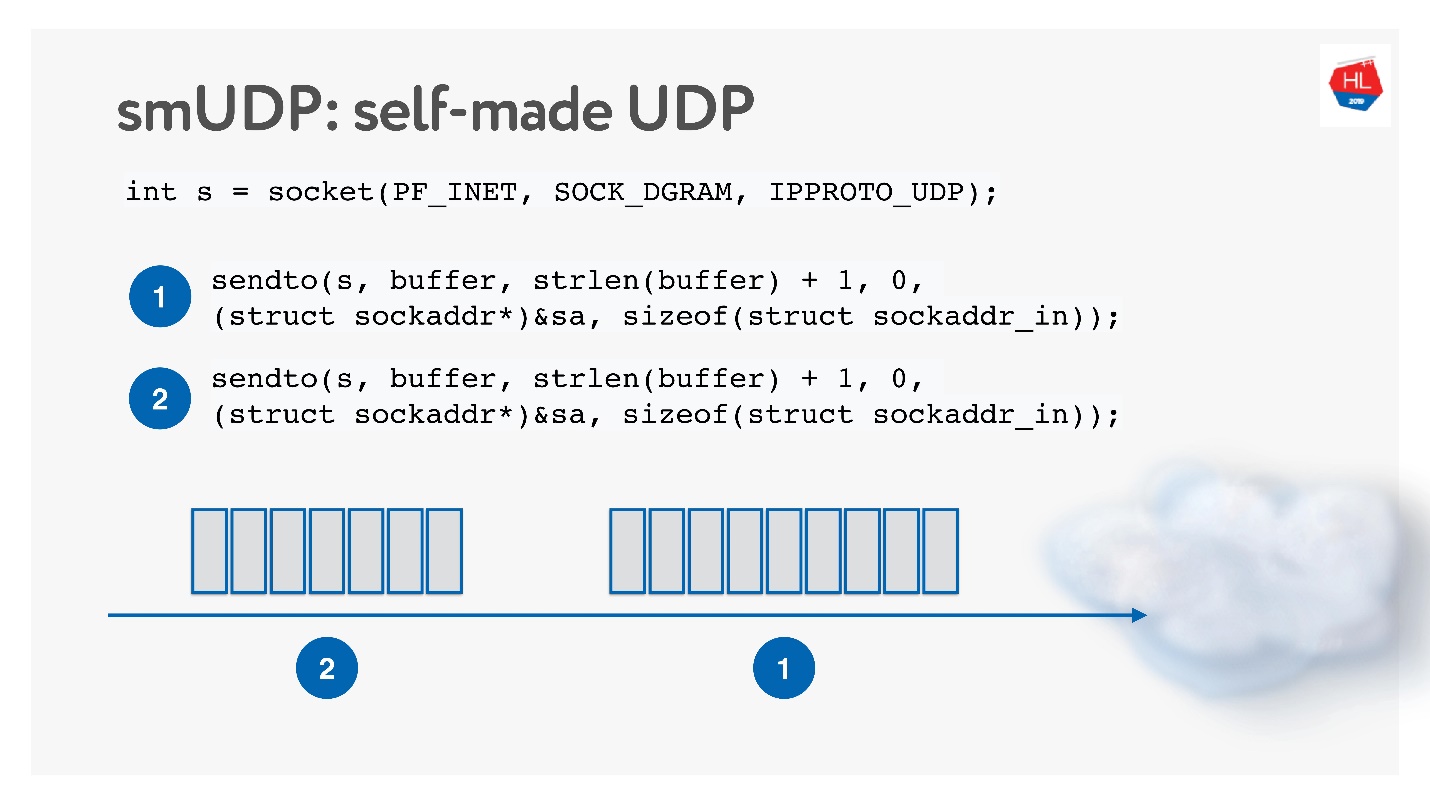
Nous allons le développer tout en étudiant le fonctionnement du réseau.
TCP vs UDP autodidacte
Eh bien, et sur quoi comparer?
Les réseaux sont différents:
- Avec la congestion, lorsqu'il y a beaucoup de paquets et que certains d'entre eux tombent en raison de la congestion des canaux ou des équipements.
- Haut débit avec un aller-retour important (par exemple, lorsque le serveur est relativement éloigné).
- Étrange - lorsque rien ne semble se produire sur le réseau, mais que les paquets disparaissent toujours simplement parce que le point d'accès Wi-Fi est derrière le mur.
Vous pouvez toujours toucher vous-même les profils réseau: sélectionnez l'un ou l'autre profil sur votre téléphone et exécutez le test de vitesse.

En plus des profils de réseau, vous devez également déterminer le profil de consommation de trafic. Voici ceux que nous avons utilisés:
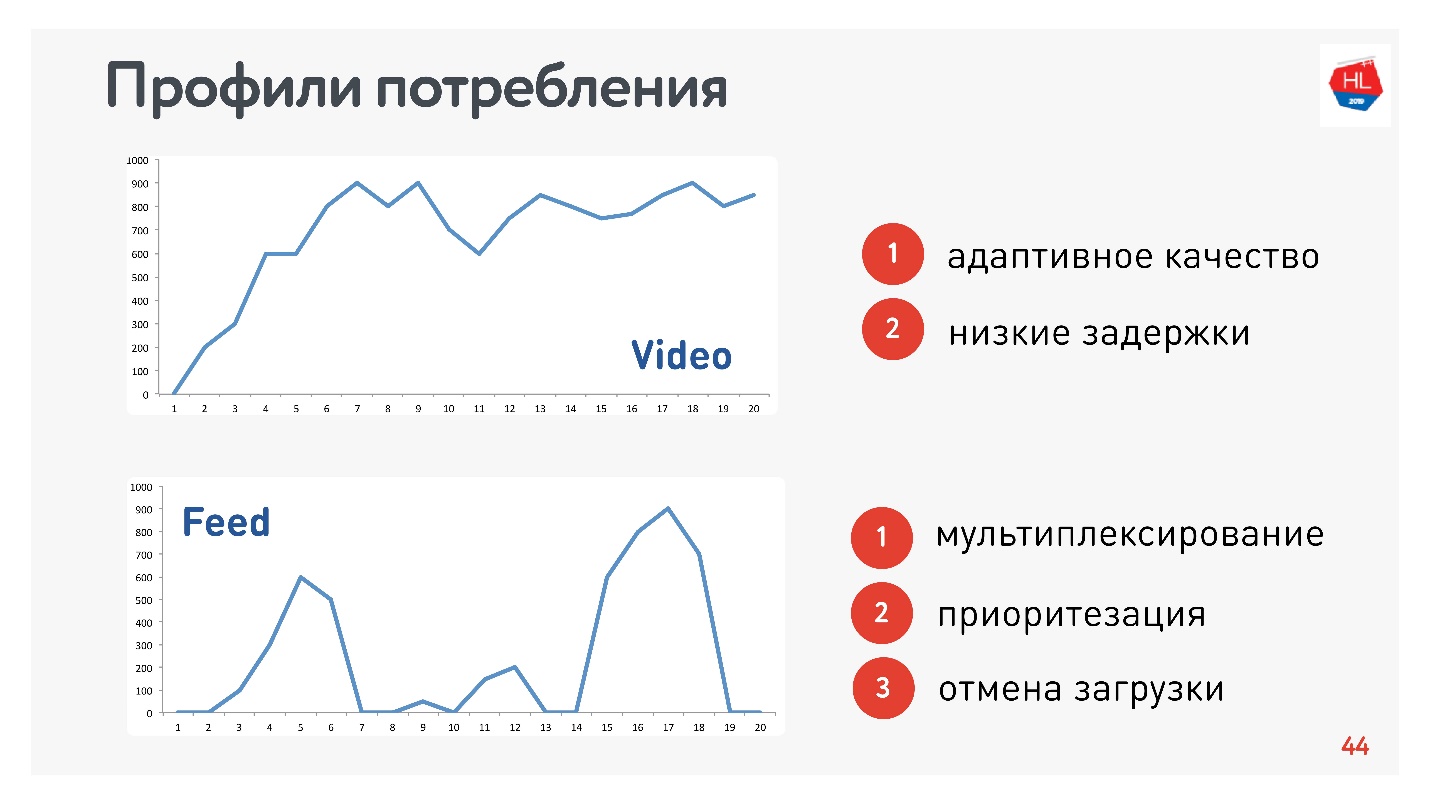
Étant donné que je suis responsable de la vidéo et du flux, les profils sont appropriés:
- Vidéo de profil, lorsque vous vous connectez et diffusez tel ou tel contenu. La vitesse de connexion augmente, comme dans le graphique supérieur. Conditions requises pour ce protocole: faible latence et adaptation du débit binaire.
- Option d'affichage sur bande: chargement de données impulsionnelles, requêtes en arrière-plan, temps d'arrêt Conditions requises pour ce protocole: les données reçues sont multiplexées et hiérarchisées, la priorité du contenu utilisateur est supérieure aux processus d'arrière-plan, il y a annulation du téléchargement.
Bien sûr, vous devez comparer les protocoles sur le HTTP le plus populaire.
HTTP 1.1 et HTTP 2.0
La pile standard des années 2000 ressemblait à HTTP 1.1 en plus de SSL. La pile moderne est HTTP 2.0, TLS 1.3 et tout en haut de TCP.
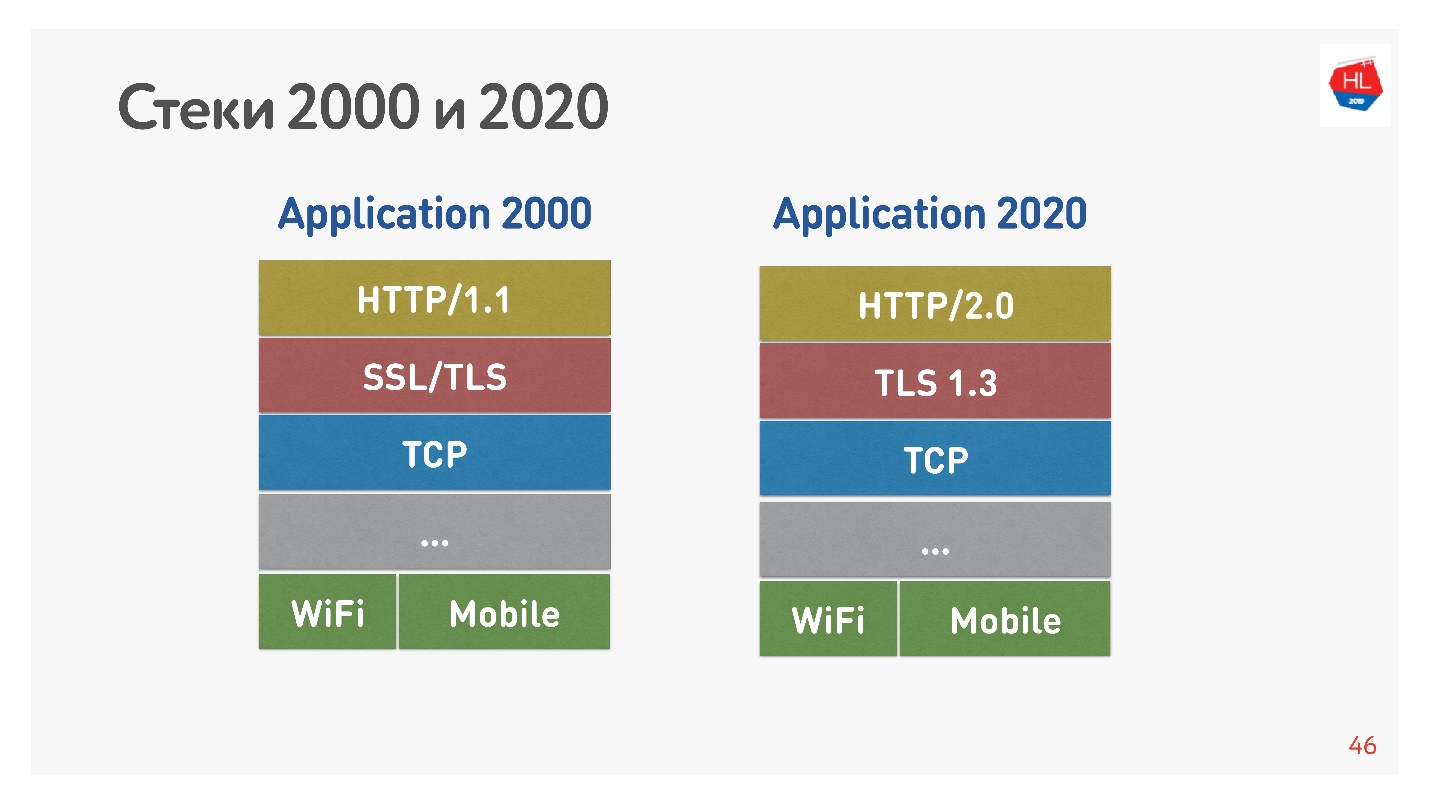
La principale différence est que HTTP 1.1 utilise un pool limité de connexions dans le navigateur à un domaine, ils créent donc un domaine distinct pour les images, les données, etc. HTTP 2.0 offre une connexion multiplexée dans laquelle toutes ces données sont transmises.
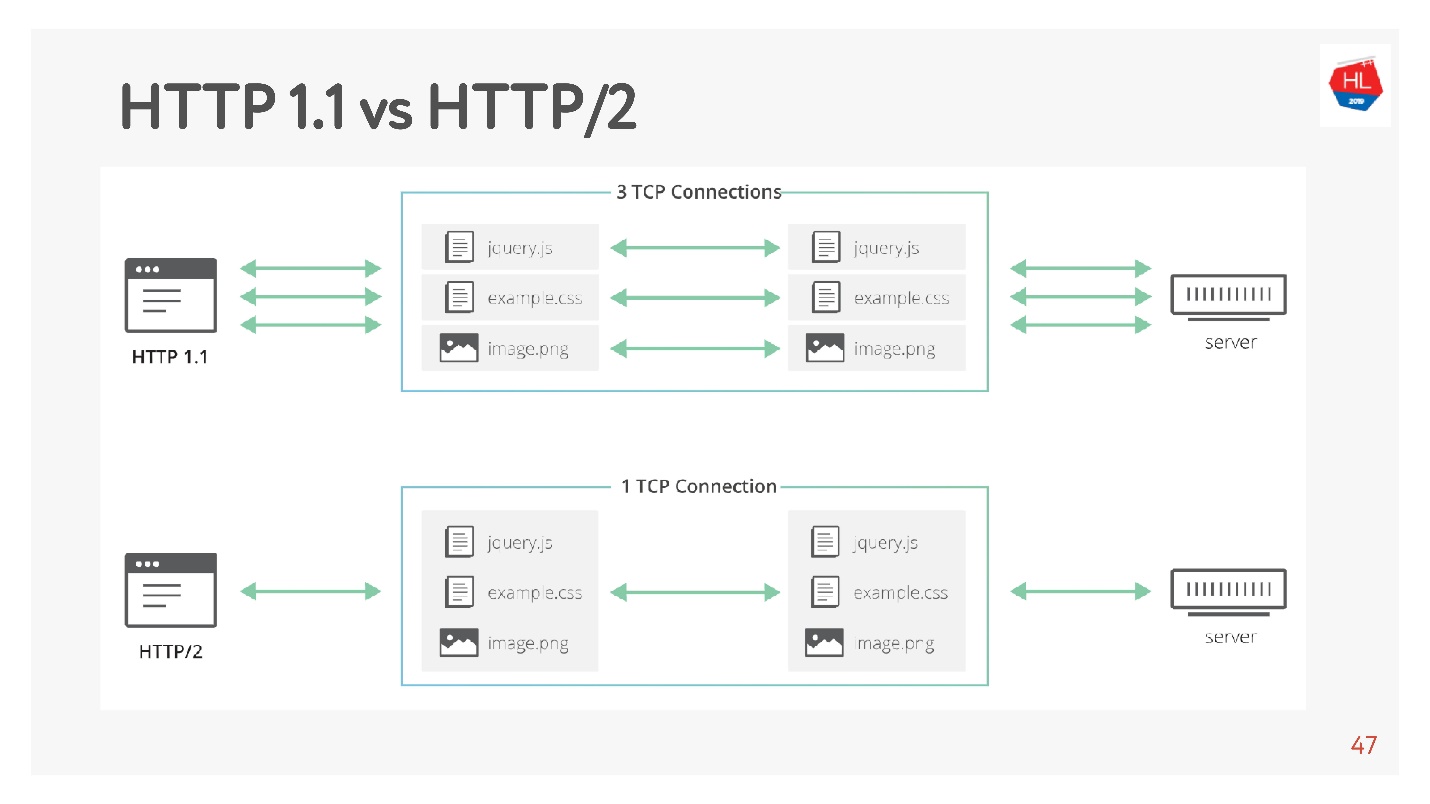
HTTP 1.1 fonctionne comme ceci: faire une demande, obtenir des données, faire une demande, obtenir des données.
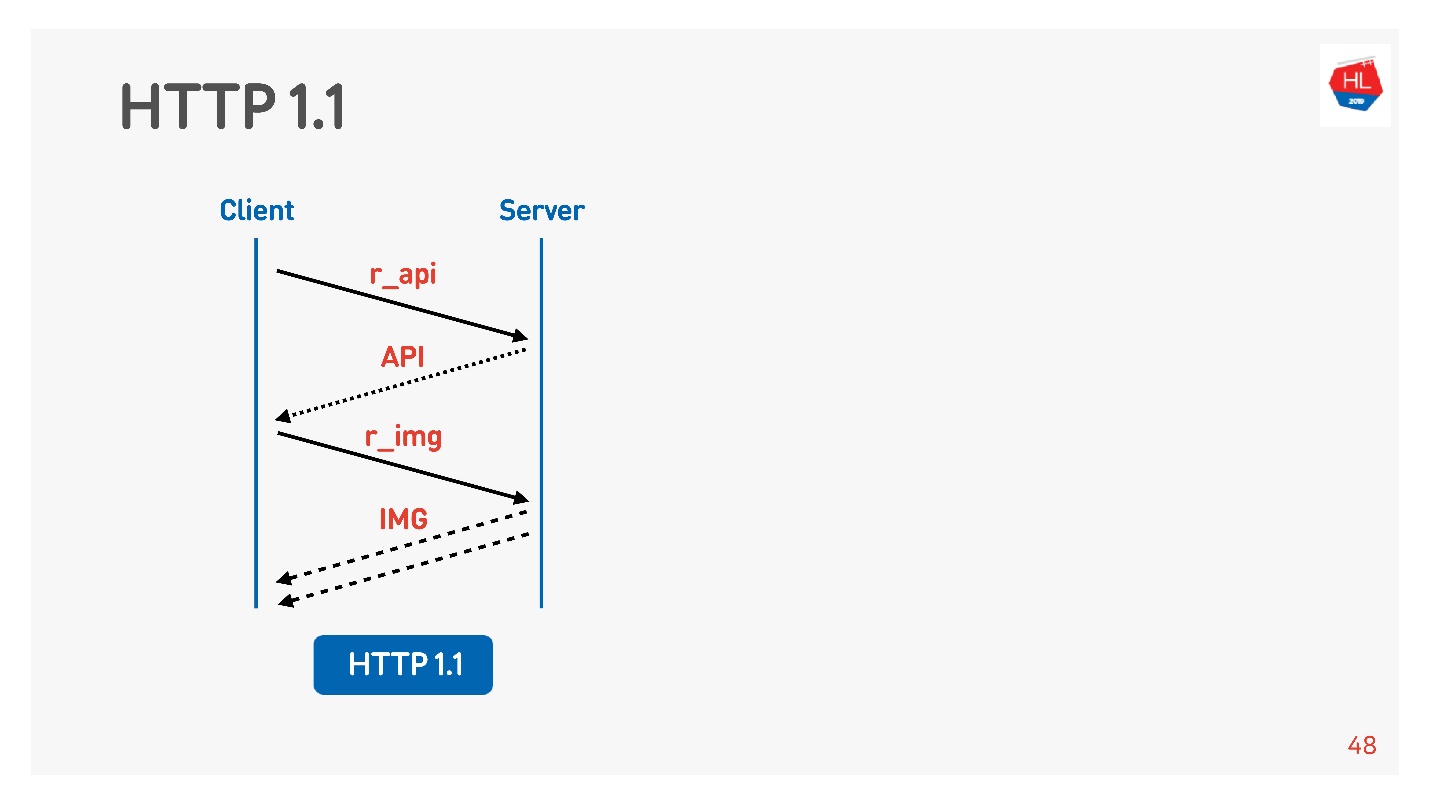
Habituellement, un navigateur ou une application mobile est une puce, c'est-à-dire une connexion pour recevoir des images, des données par API, et vous exécutez simultanément une demande d'image, d'API, de vidéo, etc.
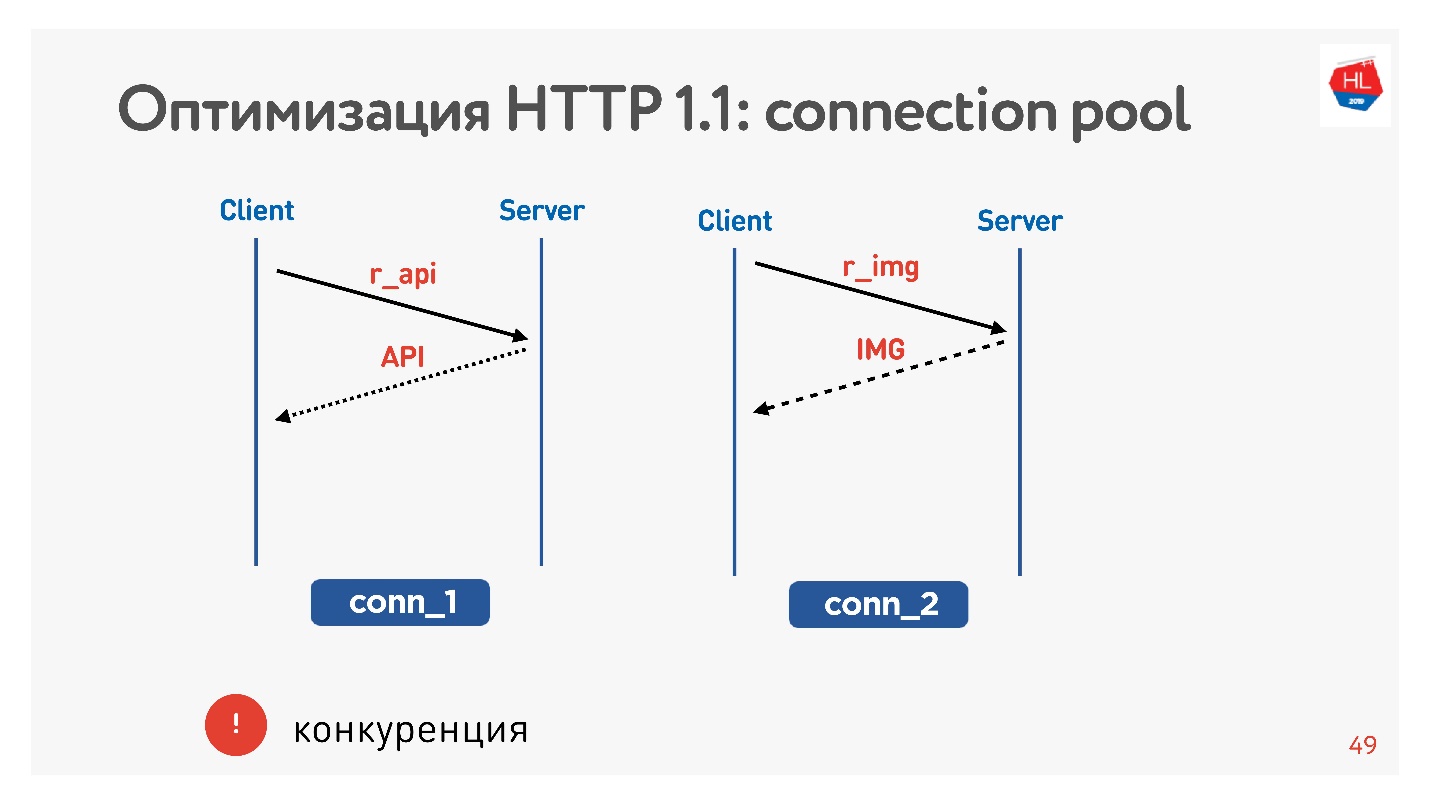
Le principal problème est la concurrence. Vous n'avez aucun contrôle sur les demandes soumises. Vous comprenez que l'utilisateur n'a plus besoin de l'image qu'il a feuilletée, mais qu'il ne peut rien faire.
Avec HTTP 1.1, vous obtenez toujours ce que vous avez demandé, il est difficile d'annuler le téléchargement.
La seule prise socket possible est de fermer la connexion. Ensuite, nous verrons pourquoi c'est mauvais.
Différences dans HTTP 2.0
HTTP 2.0 résout ces problèmes:
- binaire, compression d'en-tête;
- multiplexage de données;
- priorisation;
- annuler le téléchargement;
- poussée du serveur
Examinons des points plus importants pour nous.
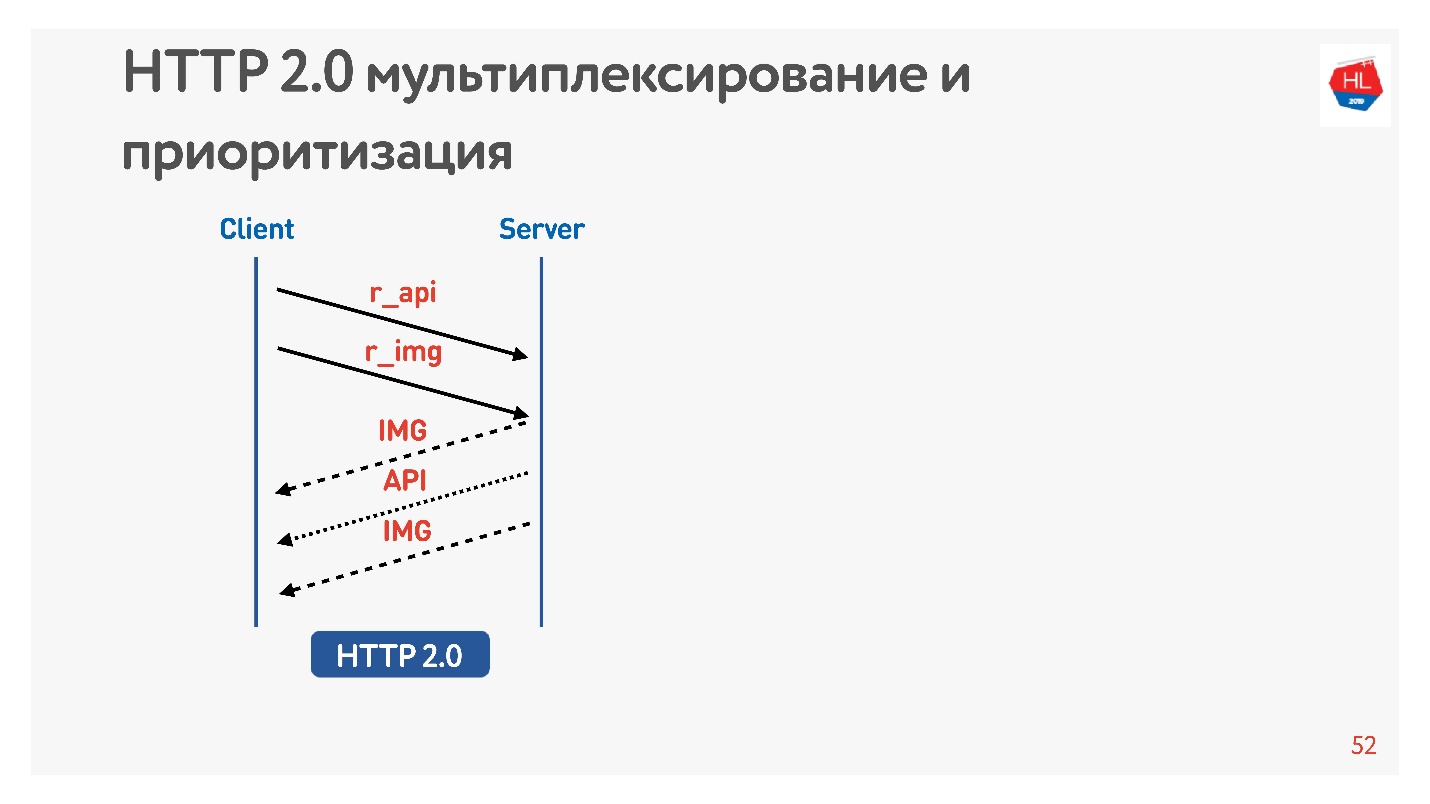
Demandez une image et une API. L'image est immédiatement donnée, l'API préparée après un certain temps. L'API a été donnée - l'image a été donnée à la fin. Tout cela se passe de manière transparente.
Le contenu hautement prioritaire est téléchargé plus tôt.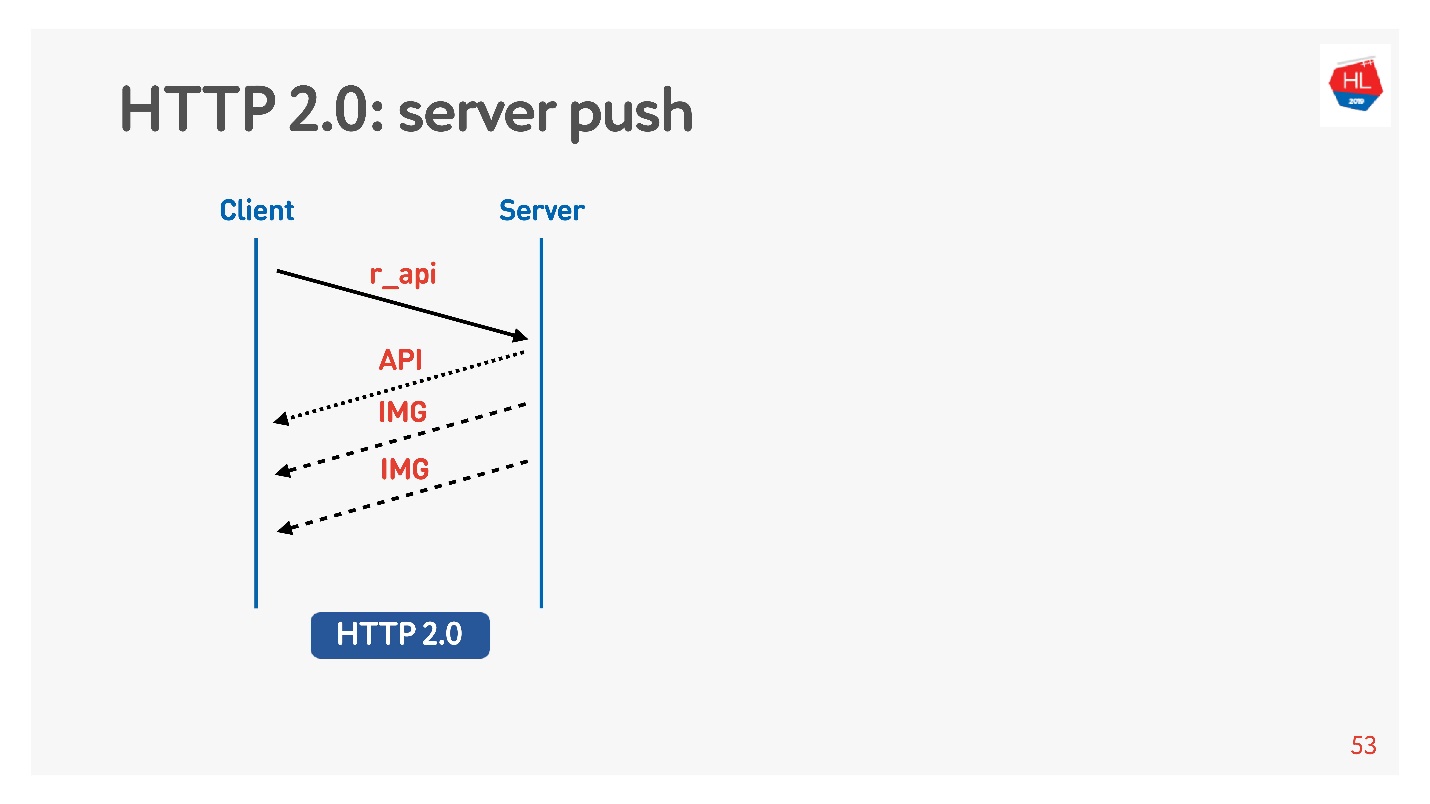 La poussée du serveur
La poussée du serveur est une telle chose lorsque vous avez demandé quelque chose de spécifique comme une API, mais même à la charge sur les images clientes ont été mises en cache qui seraient certainement nécessaires pour afficher, par exemple, une bande.
Il existe également une commande de
réinitialisation du flux que le navigateur exécute lui-même si vous passez d'une page à l'autre, etc. Pour un client mobile, avec son aide, vous pouvez refuser de recevoir des données sans perdre la connexion.
Ainsi, nous comparerons TCP sur différents:
- Profils réseau: Wi-Fi, 3G, LTE.
- Profils de consommation: streaming (vidéo), multiplexage et priorisation avec annulation du téléchargement (HTTP / 2) pour recevoir le contenu de la bande.
Modèle sans perte
Commençons la comparaison avec un réseau simple dans lequel il n'y a que deux paramètres: le temps d'aller-retour et la bande passante.
RTT est ping, le temps de rotation d'un paquet, la réception de l'accusé de réception ou le temps d'écho de réponse.
Pour mesurer la
bande passante -
bande passante réseau - nous envoyons un paquet de paquets et comptons le nombre de paquets transmis à un certain intervalle de temps.
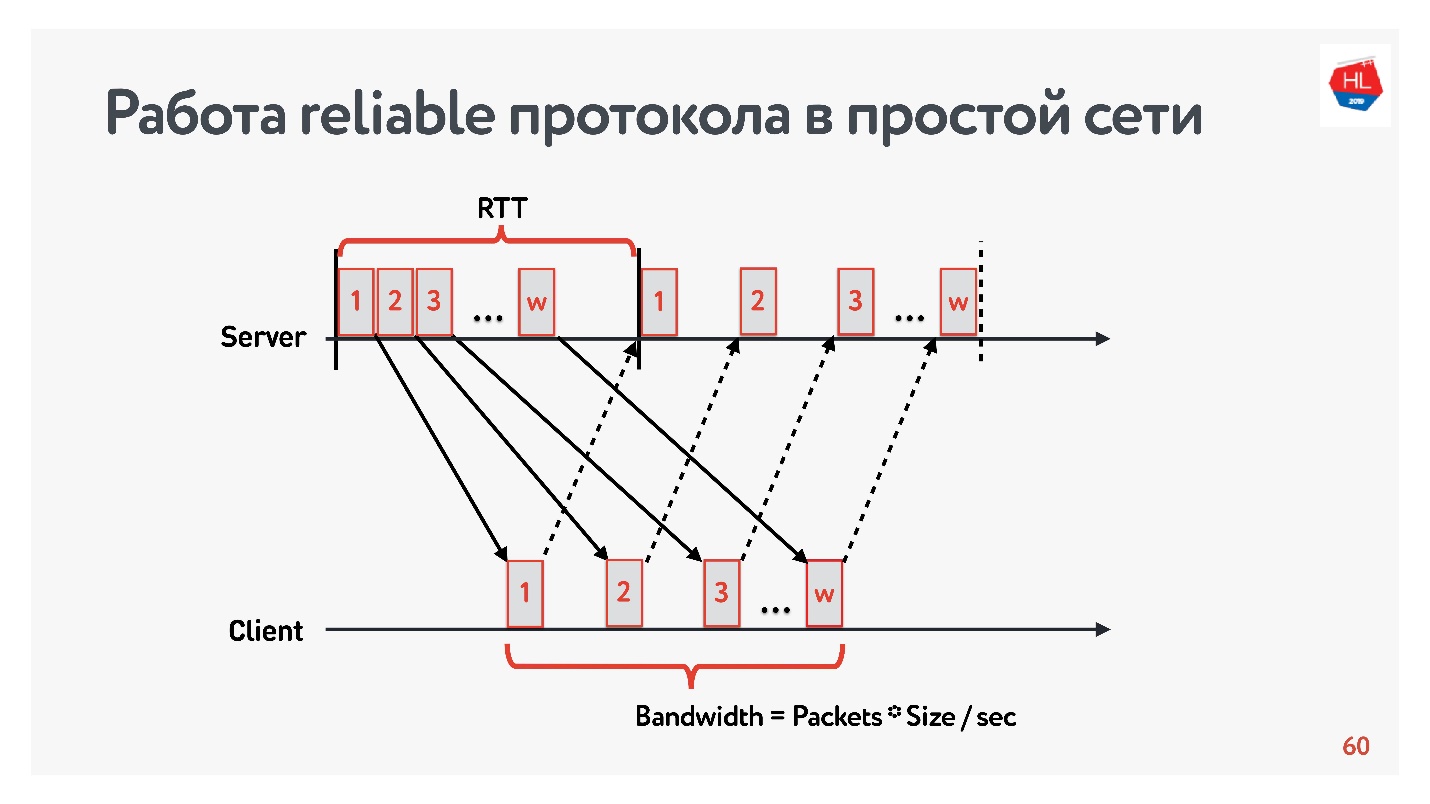
Puisque nous travaillons avec des protocoles fiables, bien sûr, il y a un accusé de réception - nous envoyons des paquets et recevons une confirmation de réception.
Le problème de l'Internet lent
À l'aube du développement de notre service vidéo en 2013, mon ami est allé en Californie et a décidé de regarder une nouvelle série de sa série préférée sur Odnoklassniki. Il avait un RTT de 250 ms, une parfaite Wi-Fi 400 Mbps sur le campus de Google, il voulait voir la nouvelle série en FullHD.
Pensez-vous qu'il a pu regarder la vidéo? La réponse dépend de la configuration du tampon d'envoi / recv sur nos serveurs.
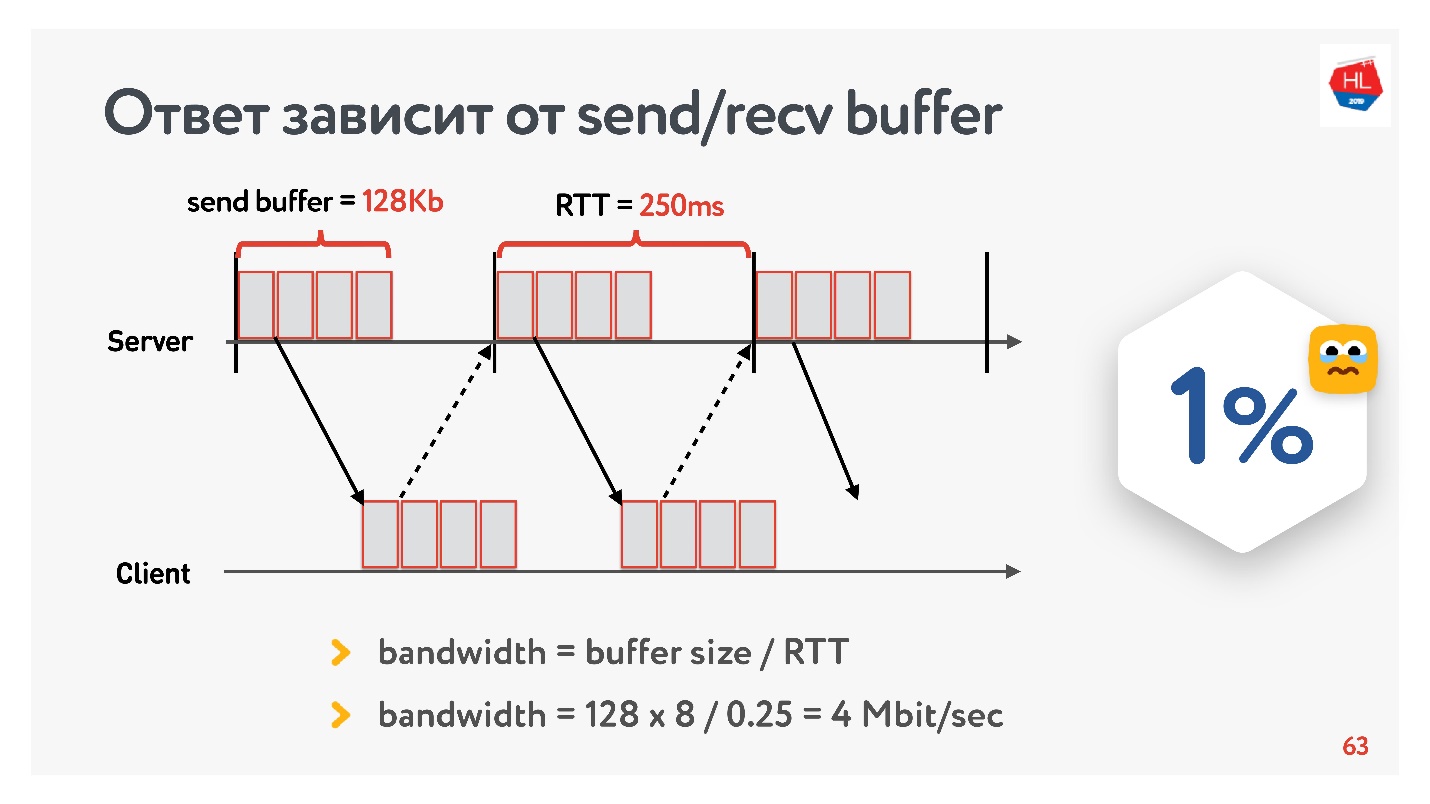
Puisque nous avons un protocole avec accusé de réception, toutes les données qui n'ont pas reçu de confirmation de livraison sont stockées dans un tampon. Si le tampon d'envoi est limité à 128 Ko, alors ces 128 Ko sont inférieurs à ceux du RTT, nous ne pouvons pas envoyer. Ainsi, de notre réseau à 400 Mbit / s, il reste 4 Mbit / s. Cela ne suffit pas pour regarder des vidéos en ligne en FullHD.
Ensuite, j'ai remonté la taille du tampon et regardé comment la vitesse de sortie d'un segment vidéo change vraiment en fonction du changement de taille du tampon. Faites immédiatement une réservation que le tampon recv a été automatiquement réglé, c.-à-d. ce que le serveur a envoyé, le client peut toujours l'accepter.

Une recette TCP évidente: si vous transmettez des données à grande vitesse sur de longues distances, vous devez augmenter la mémoire tampon d'envoi.
Tout semble aller bien. Vous pouvez accéder au service fast.com, qui mesure la vitesse de votre Internet vers les serveurs Netflix. Du bureau, j'ai eu une vitesse de 210 Mbps. Et puis, grâce à Net Shaper, j'ai défini les conditions de la tâche et je suis retourné sur ce site. Magique - j'ai exactement 4 Mbps.
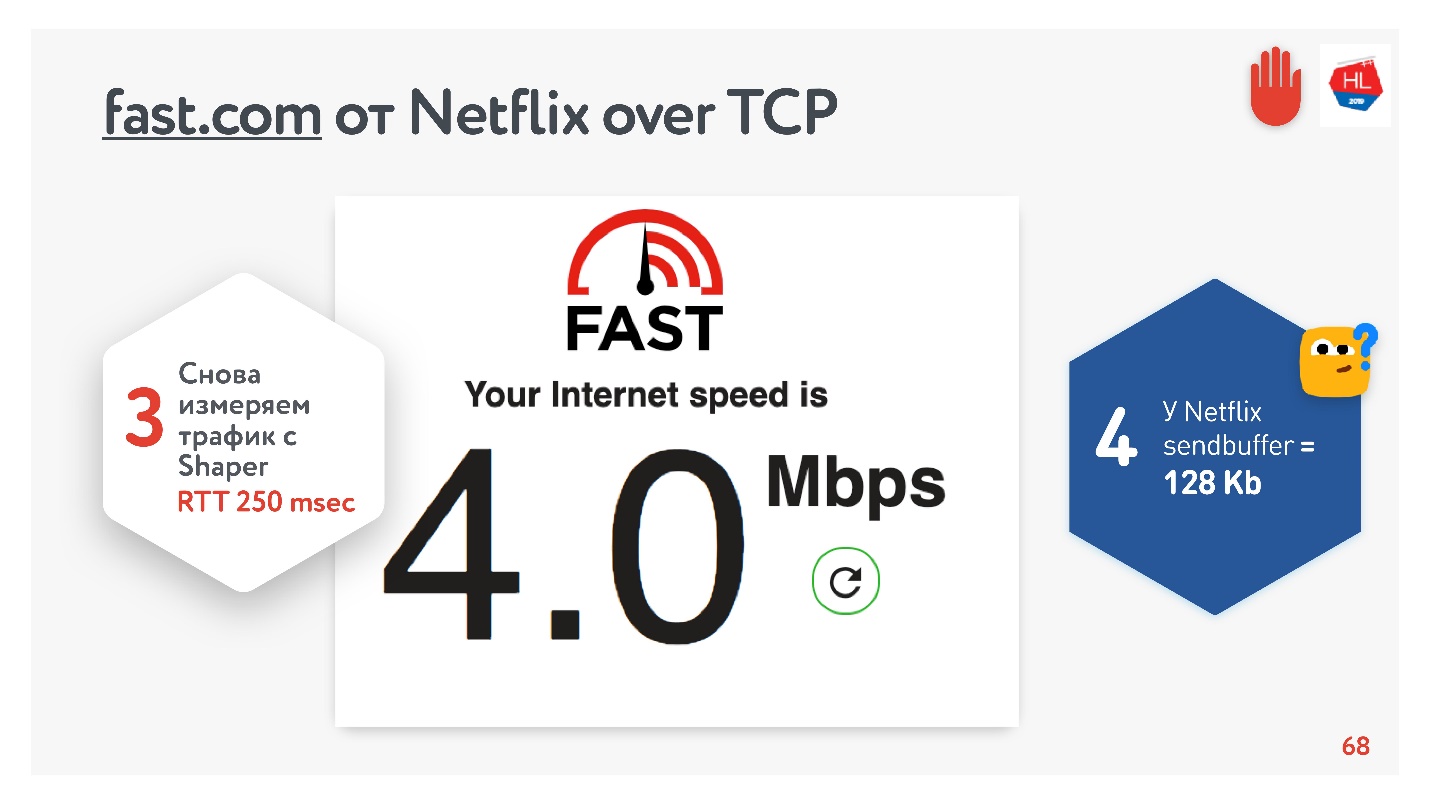
Peu importe comment je le tord, Netflix n'a pas réussi à obtenir un tampon supérieur à 128 Ko.
Taille du tampon
Afin de déterminer la taille de tampon optimale, vous devez comprendre ce que sont les paquets à la volée.
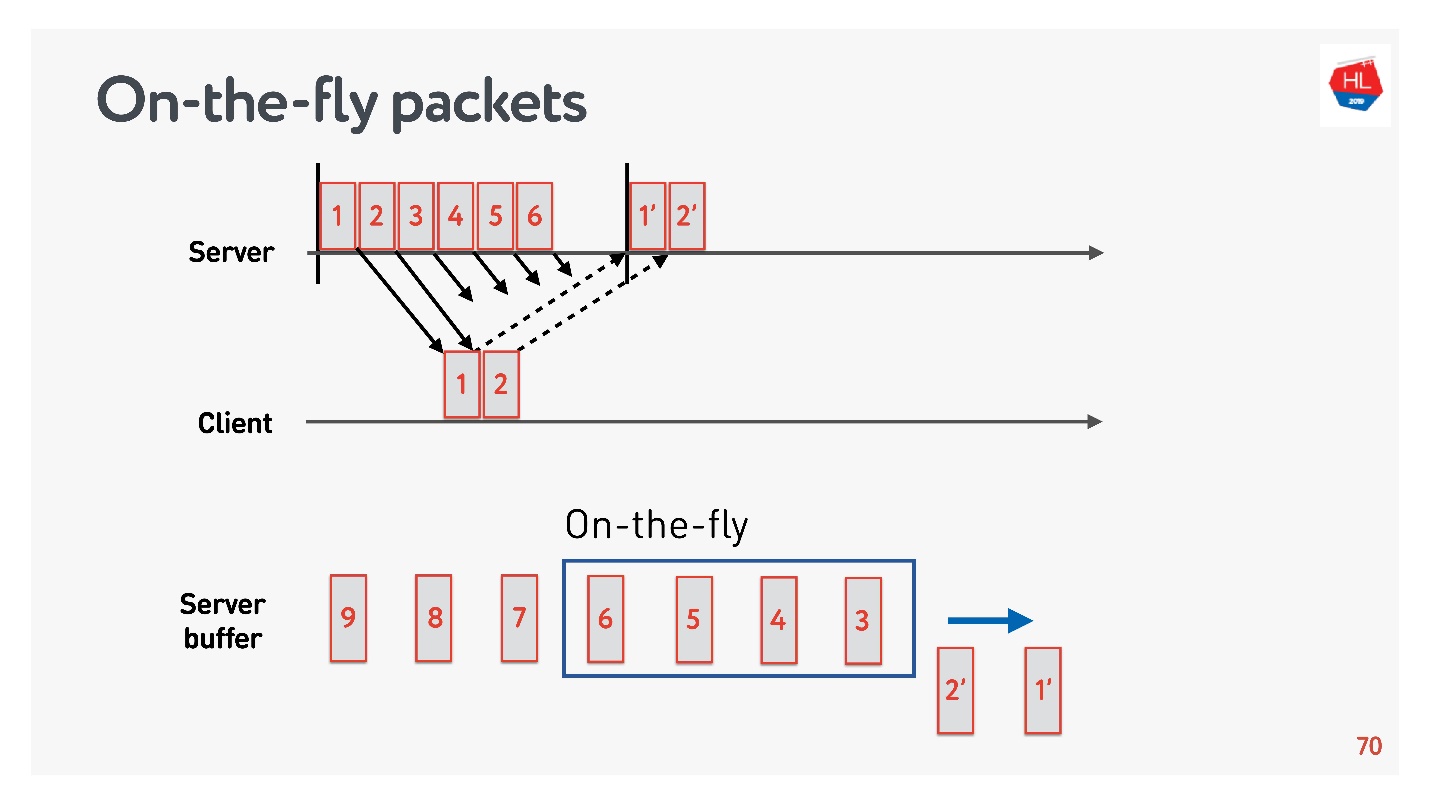
Il existe un état du réseau:
- les paquets 1 et 2 ont déjà été envoyés, une confirmation a été reçue pour eux;
- les paquets 3, 4, 5, 6 ont été envoyés, mais le résultat de la livraison est inconnu (paquets à la volée);
- d'autres paquets sont dans la file d'attente.
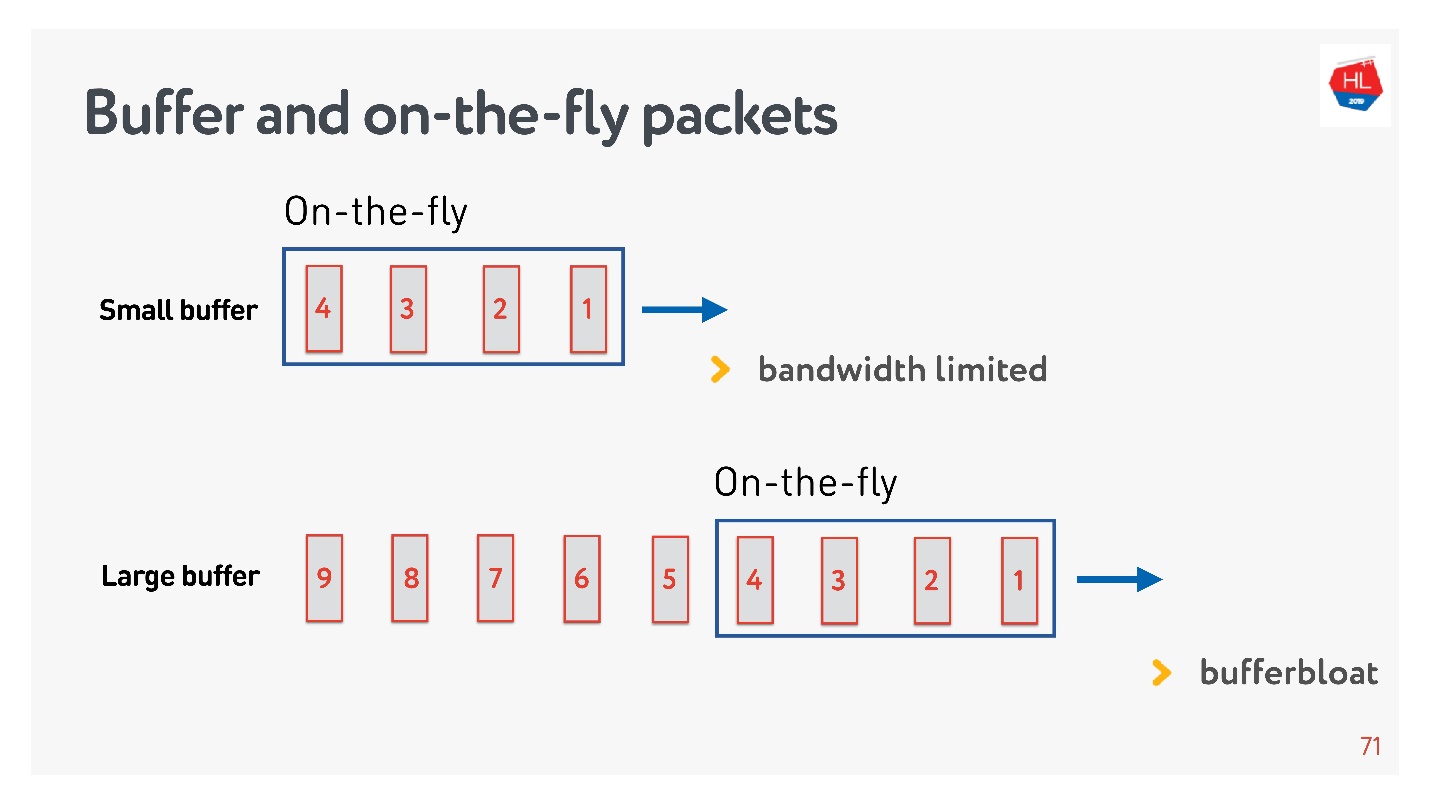
Si le nombre de paquets à la volée est égal à la taille du tampon, alors il n'est pas assez grand. Dans ce cas, le réseau est affamé, pas entièrement utilisé.
La situation inverse est possible - le tampon est trop grand. Dans ce cas, le tampon gonfle. Pourquoi est-ce mauvais?

Si nous parlons de multiplexage de données et envoyons plusieurs demandes en même temps, par exemple, des images dans la même connexion et la même API, alors lorsque toute l'image énorme en mégaoctets est entrée dans le tampon, et que nous essayons de remplir également l'API haute priorité, le tampon gonfle. Vous devez attendre très longtemps lorsque l'image disparaît.
Une solution simple consiste à ajuster automatiquement la taille du tampon. Maintenant, il est disponible sur de nombreux clients et fonctionne quelque chose comme ça.
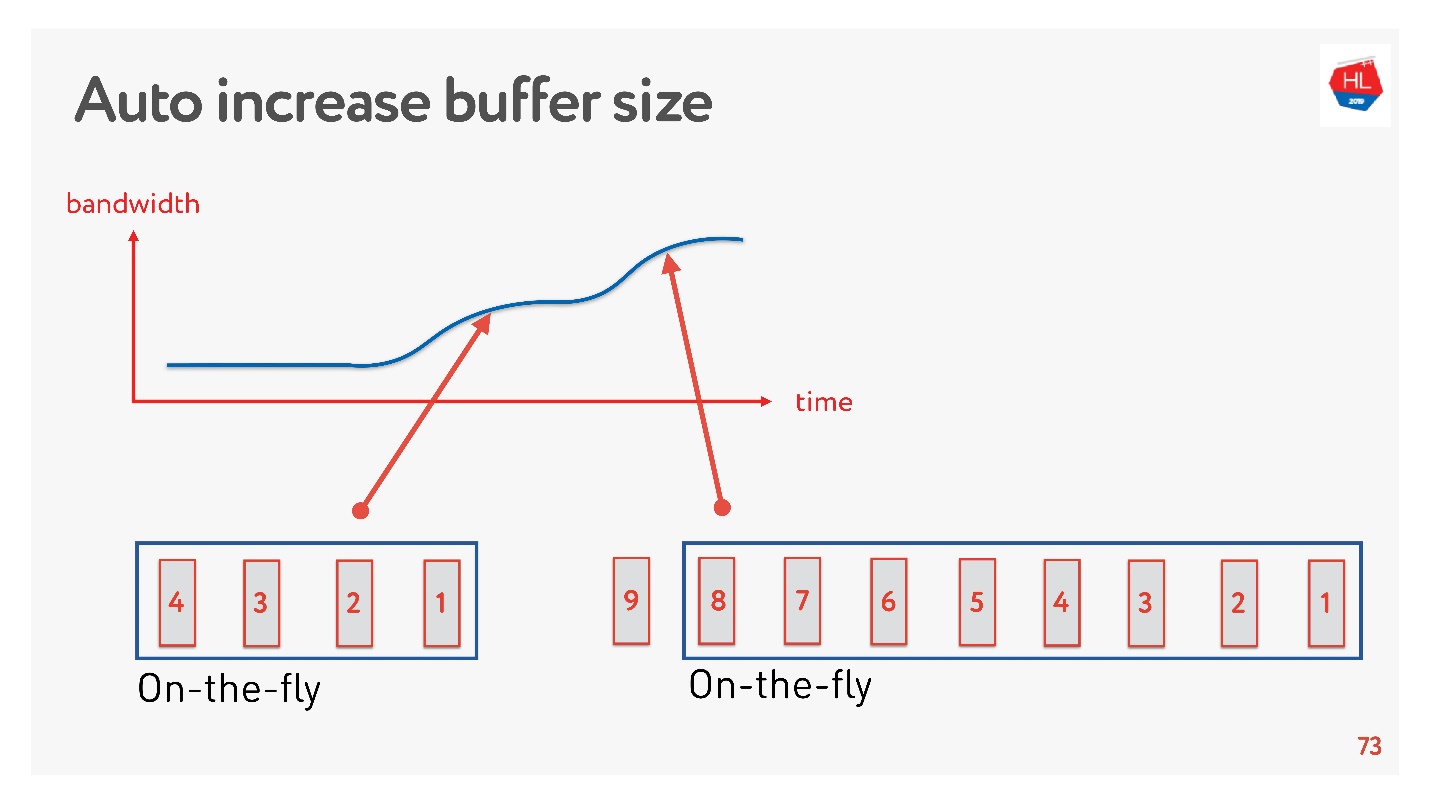
Si beaucoup de paquets peuvent être envoyés maintenant, le tampon augmente, le transfert de données s'accélère, la taille du tampon augmente, tout semble bien se passer.
Mais il y a un problème. Si le tampon a augmenté, il ne peut pas être réduit aussi facilement. C'est une tâche plus difficile. Si la vitesse s'affaisse, le même gonflement du tampon se produit. Le tampon est assez grand et plein, nous devons attendre que toutes les données soient envoyées au client.
Si nous écrivons notre propre protocole UDP, alors tout est très simple - nous avons accès au tampon.
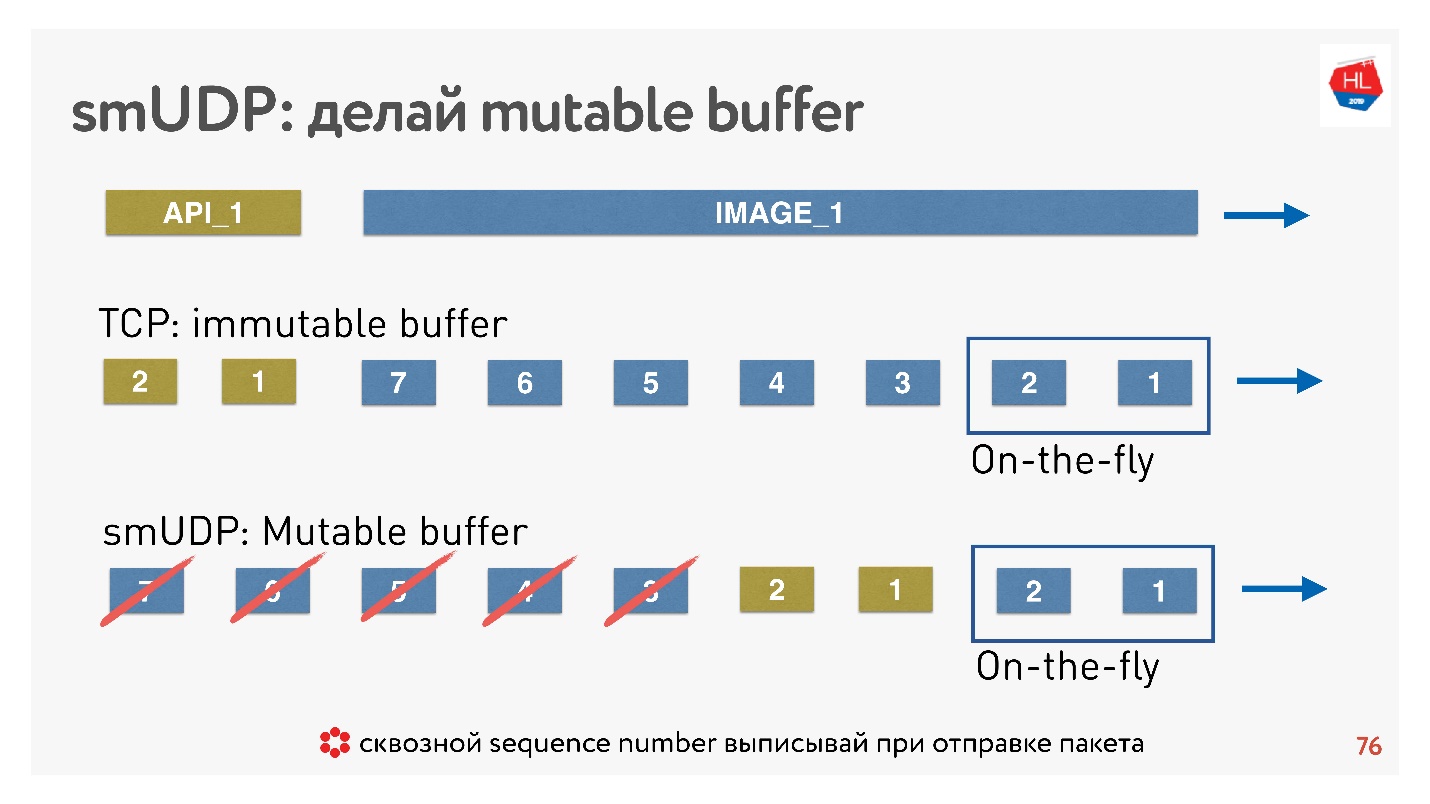
Si TCP dans de telles situations ajoute simplement des données à la fin et que vous ne pouvez rien faire, alors dans un protocole personnalisé, vous pouvez mettre des données, par exemple, en avant, immédiatement après les paquets à la volée.
Et si l'annulation arrive, et le client dit que cette image n'est plus nécessaire, il a besoin des données API, il a fait défiler le contenu plus loin, vous pouvez jeter tout cela hors du tampon et envoyer celui souhaité.
Comment cela se fait-il? Il est connu que pour restaurer des paquets, gérer la livraison, recevoir des accusés de réception, vous avez besoin de certains sequence_id de paquets. Sequence_id nous sommes écrits uniquement pour les paquets à la volée, c'est-à-dire que nous ne les émettons que lorsque nous envoyons des paquets. Tout le reste dans le tampon peut être déplacé comme nous le souhaitons jusqu'à ce que les paquets soient partis.
Conclusion: le buffer TCP doit être correctement configuré, rattraper l'équilibre pour ne pas abouter au réseau et ne pas gonfler le buffer. Pour votre propre protocole UDP, tout est simple - cela peut être contrôlé.
Modèle de réseau avec perte
On passe à un niveau supérieur, le réseau devient un peu plus compliqué, la perte de paquets y apparaît. Pour les réseaux mobiles, c'est une situation courante. Certains des paquets envoyés n'atteignent pas le client. L'algorithme de récupération de retransmission standard fonctionne comme ceci:
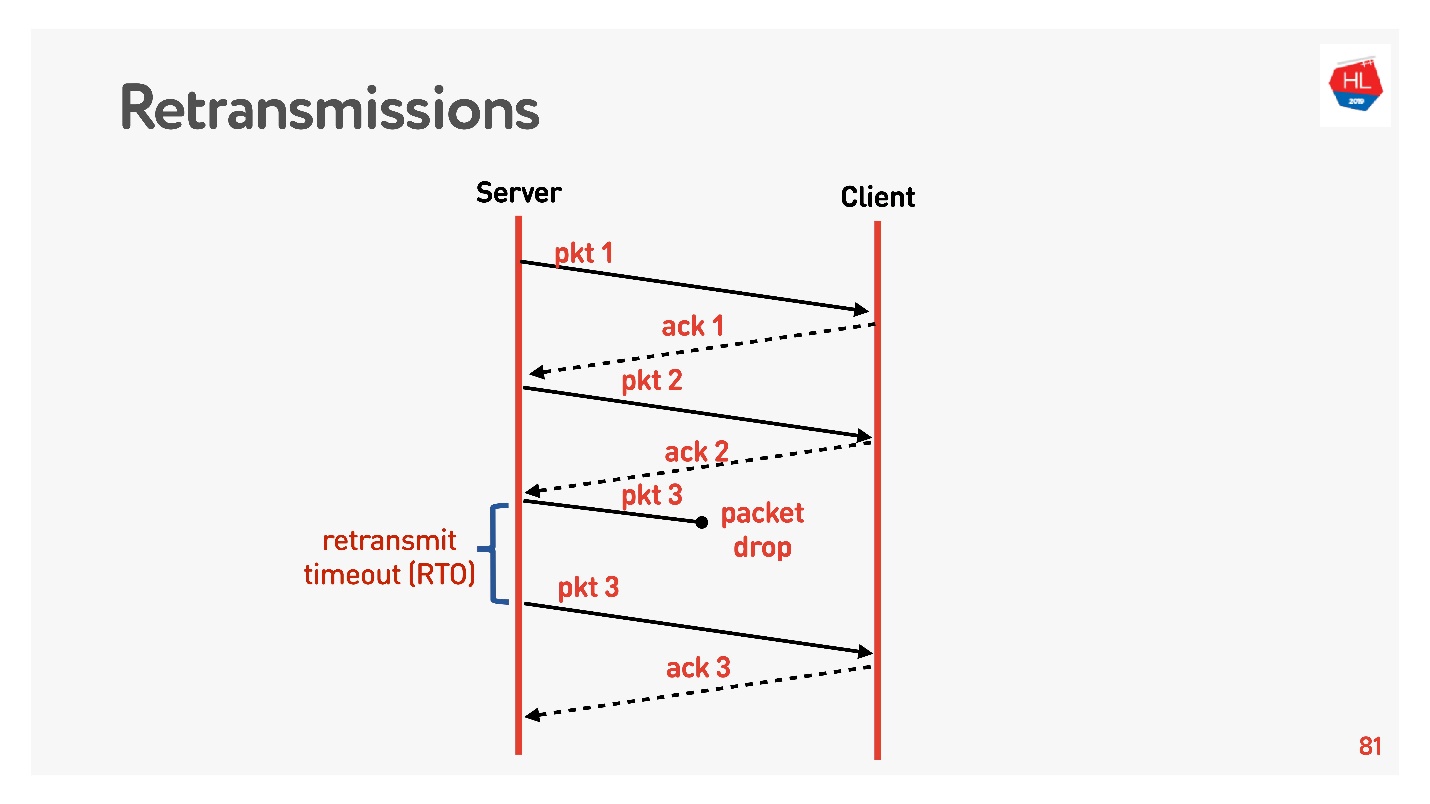
Envoie des paquets, car chaque paquet reçoit un accusé de réception.
Si le délai de retransmission (RTO) est égal à RTT plus certaines constantes, il n'y a pas de confirmation, le paquet est envoyé.Revenons à la courbe d'inefficacité TCP lorsque seulement 5% des paquets sont perdus et que l'utilisation du réseau est de 50%.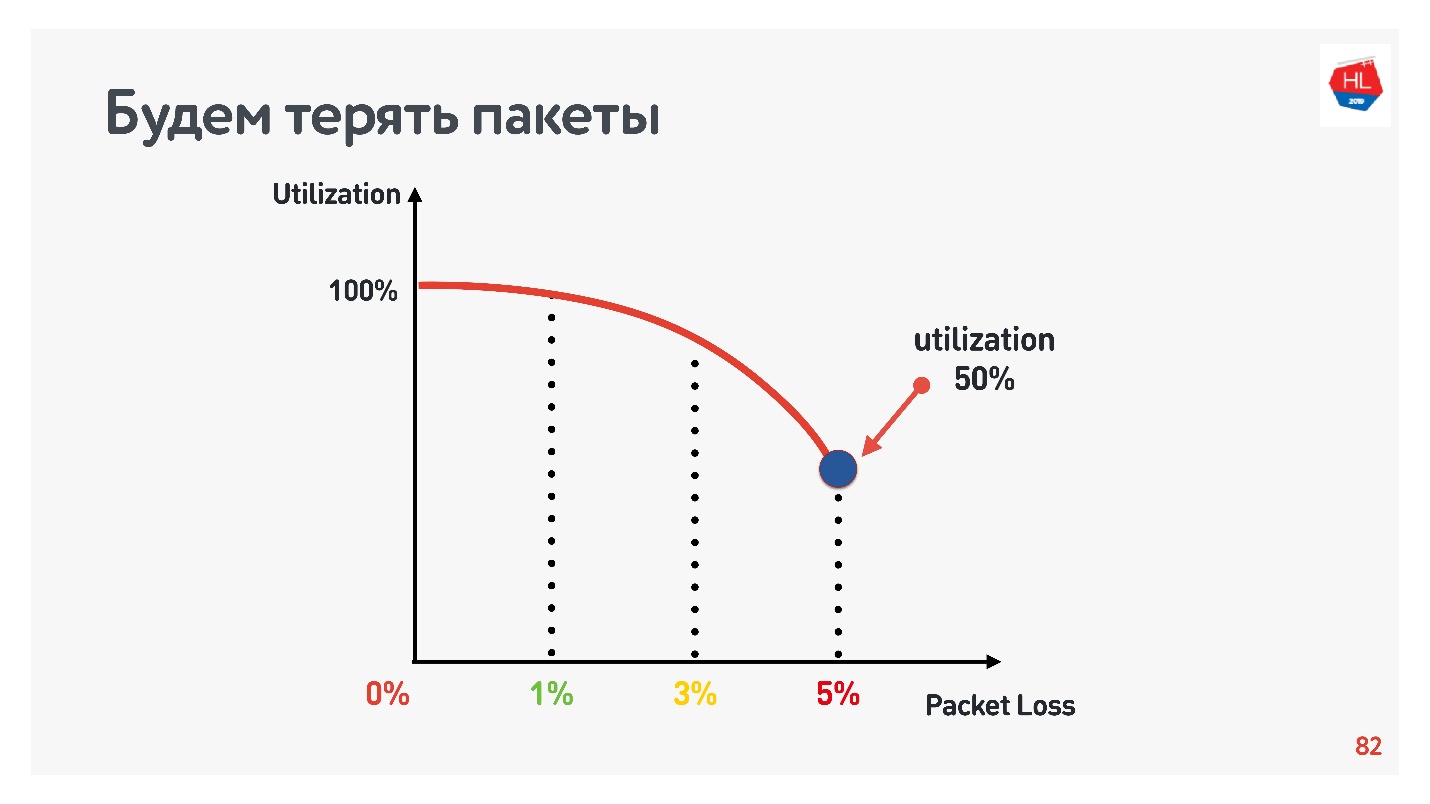 Avec une retransmission qui envoie simplement des paquets, nous ne devrions pas observer un tel problème. Pour comprendre les raisons, vous devez comprendre ce qu'est le contrôle de la congestion.
Avec une retransmission qui envoie simplement des paquets, nous ne devrions pas observer un tel problème. Pour comprendre les raisons, vous devez comprendre ce qu'est le contrôle de la congestion.Contrôle de la congestion
Il est souvent confondu avec le contrôle de flux, alors pensez aux deux.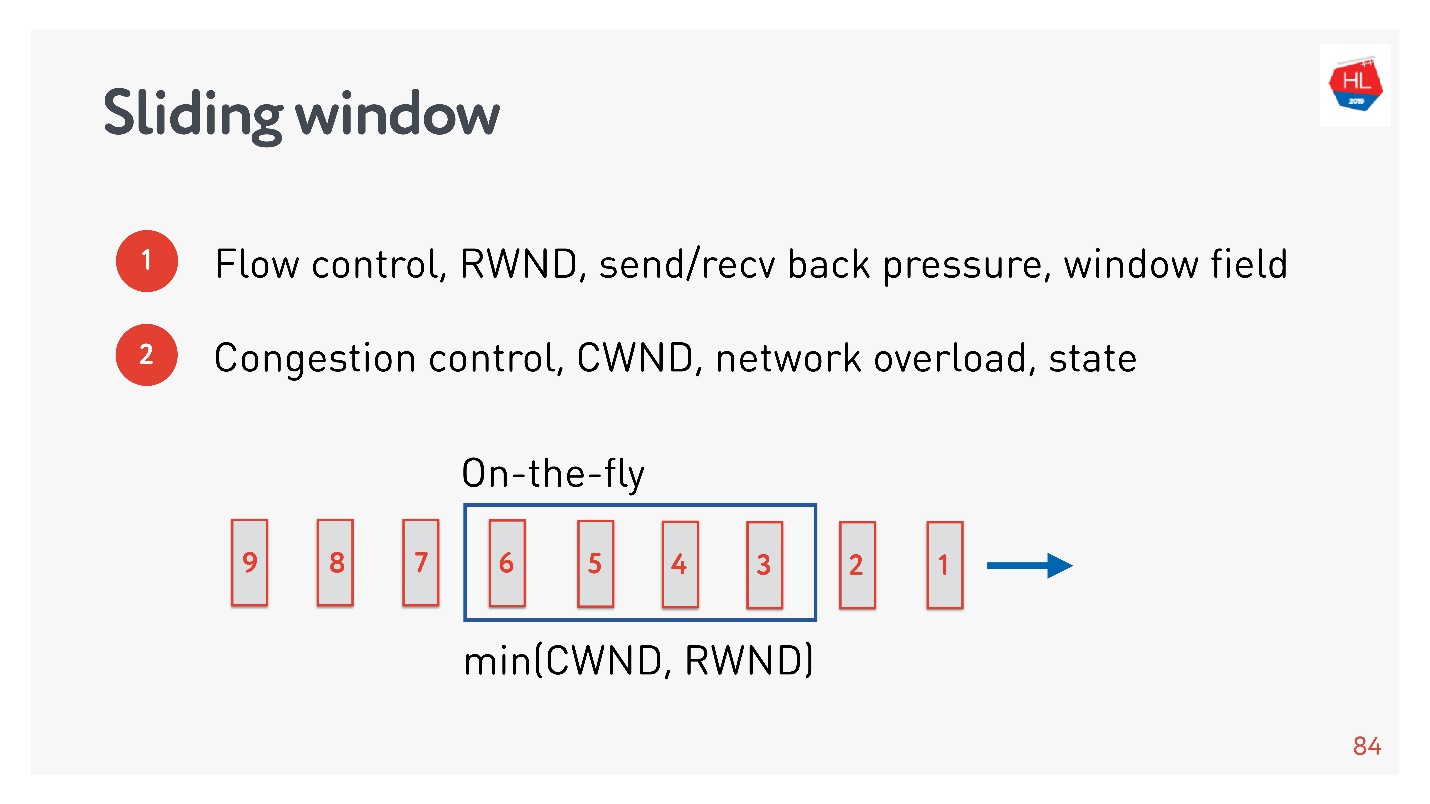
- Flow control — . , , . flow control recv window, . flow control — back pressure , - .
- congestion control . , — .
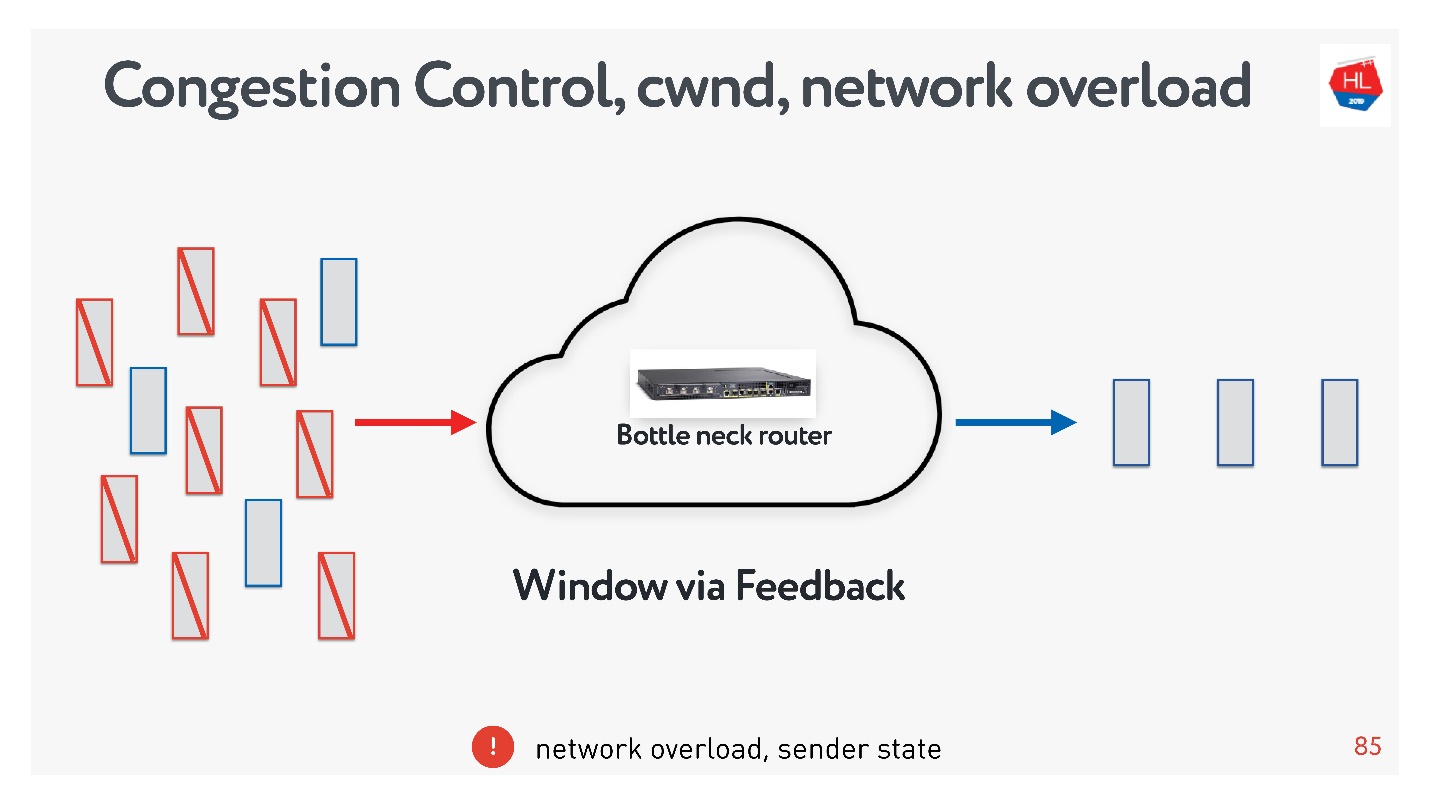
, : , , , . , congestion control.
TCP window.
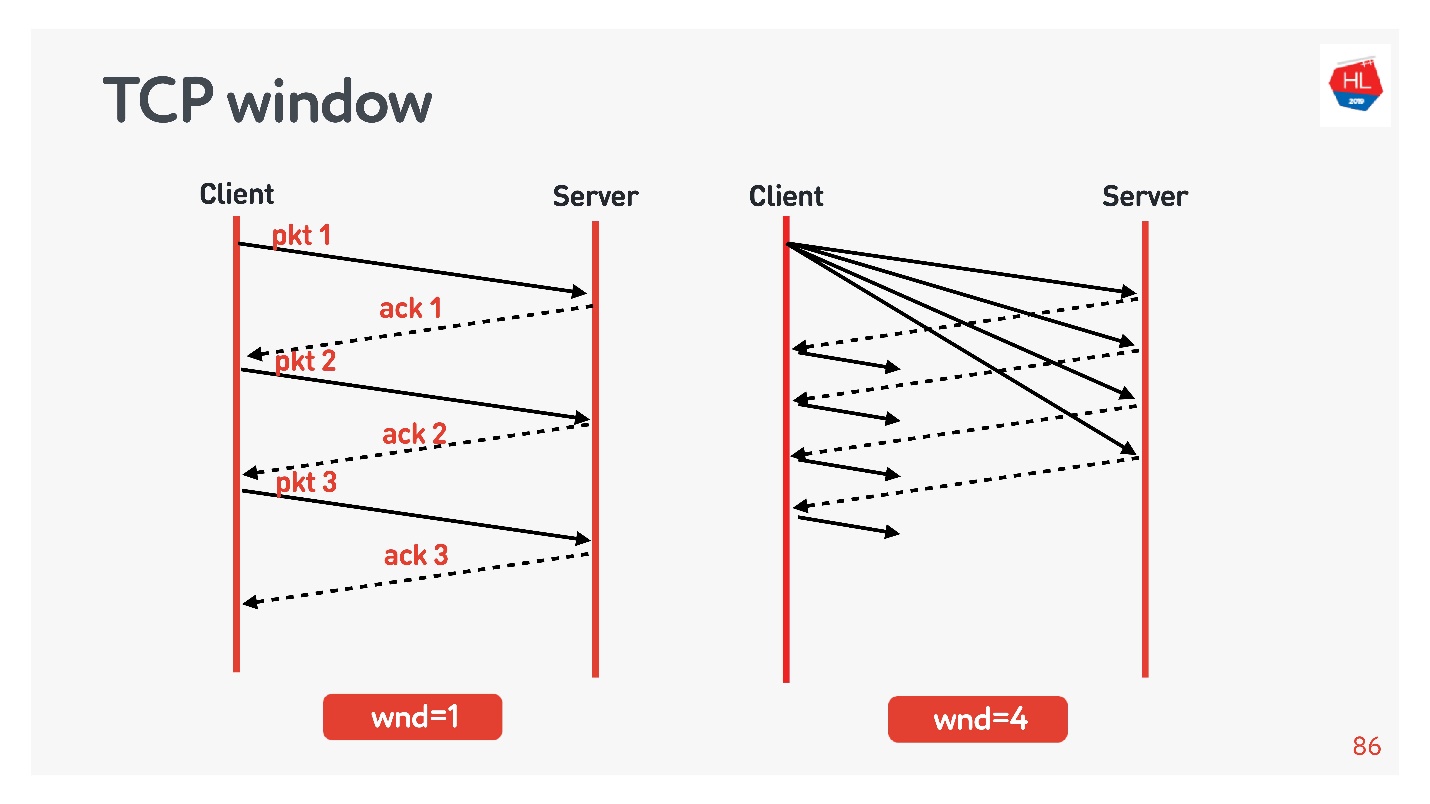
flow control congestion control, .
Exemples:
- TCP window = 1, : acknowledgement, ..
- TCP window = 4, , acknowledgement .
, . initial window TCP = 10.
, , .
?
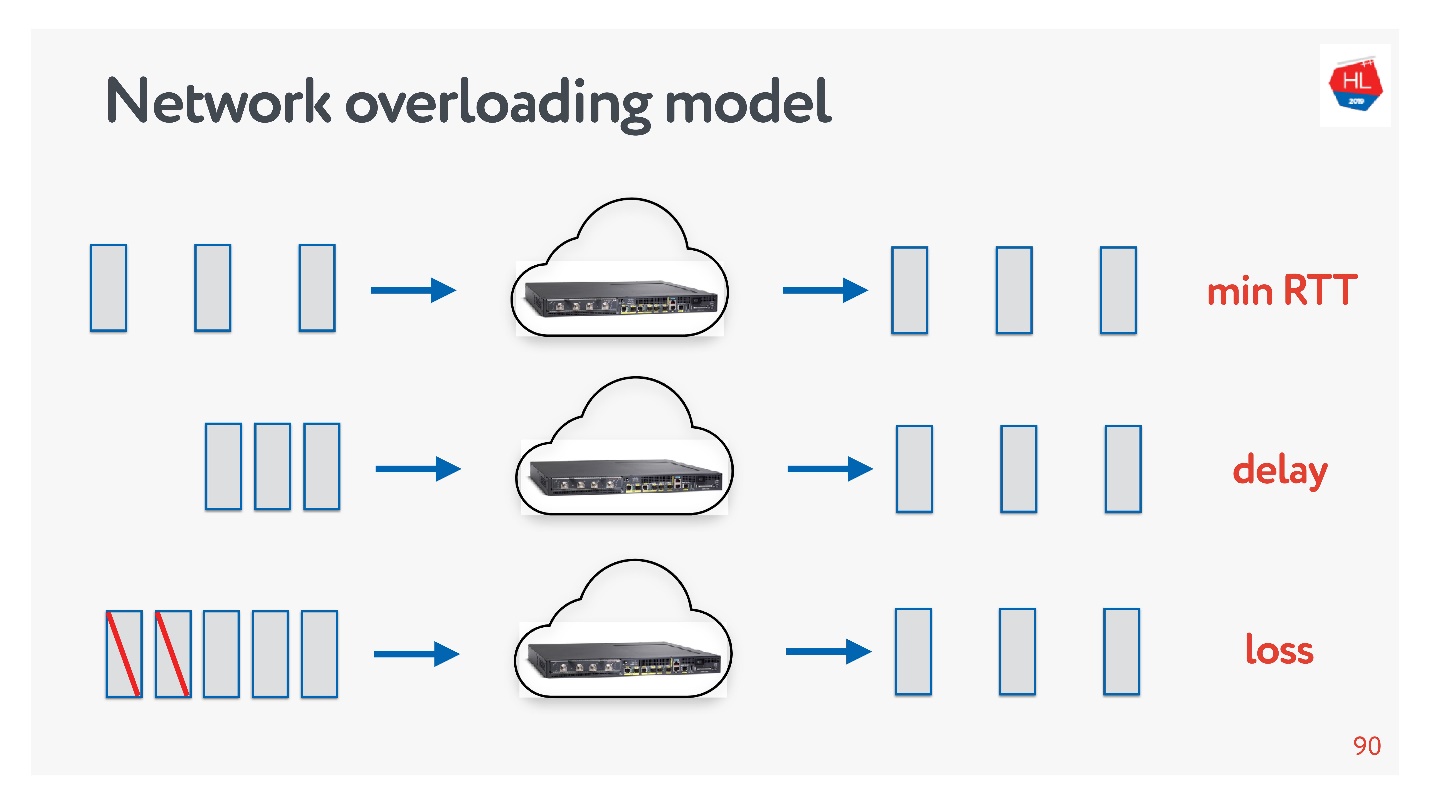
- , . , .
- : , acknowledgements .
- - , acknowledgements ( ).
.
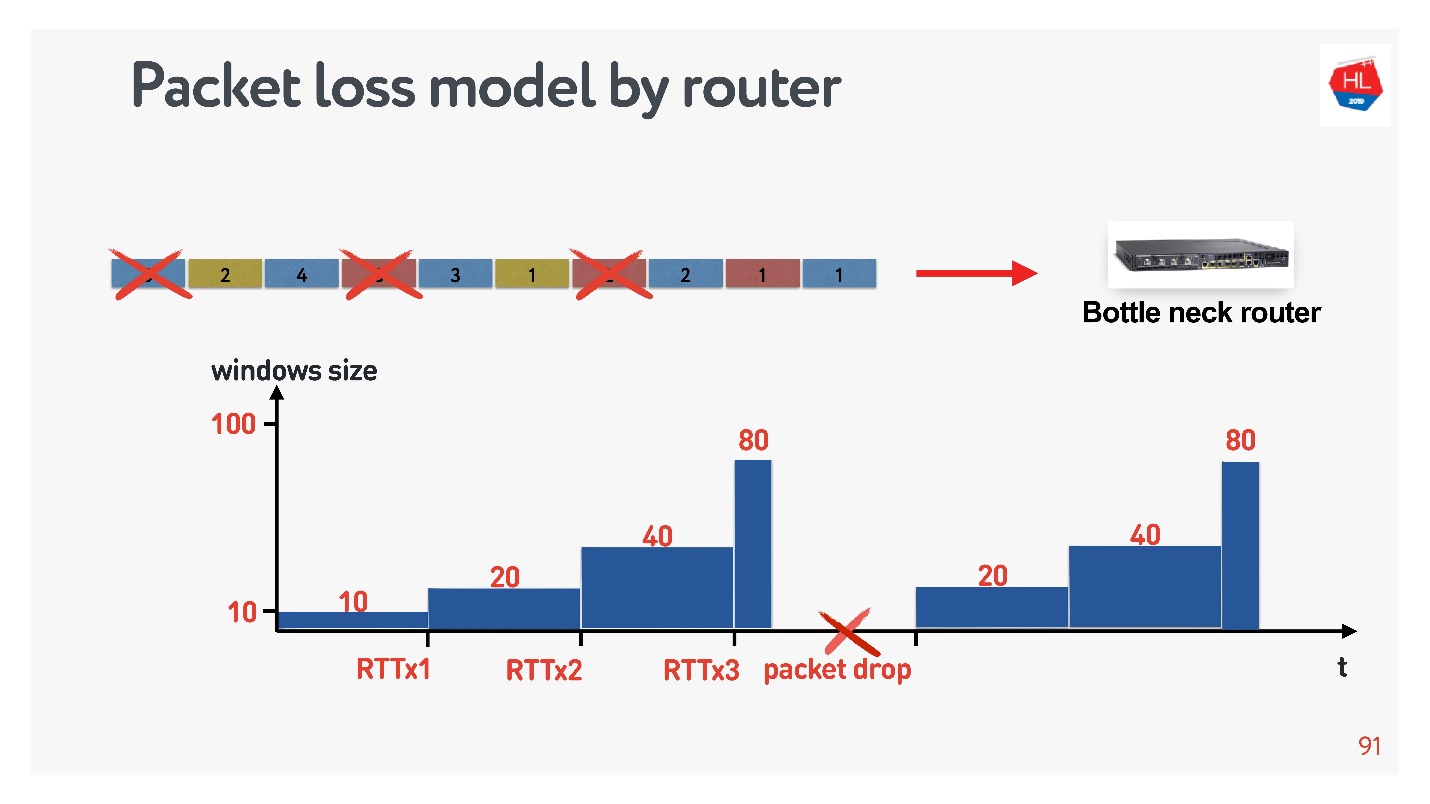
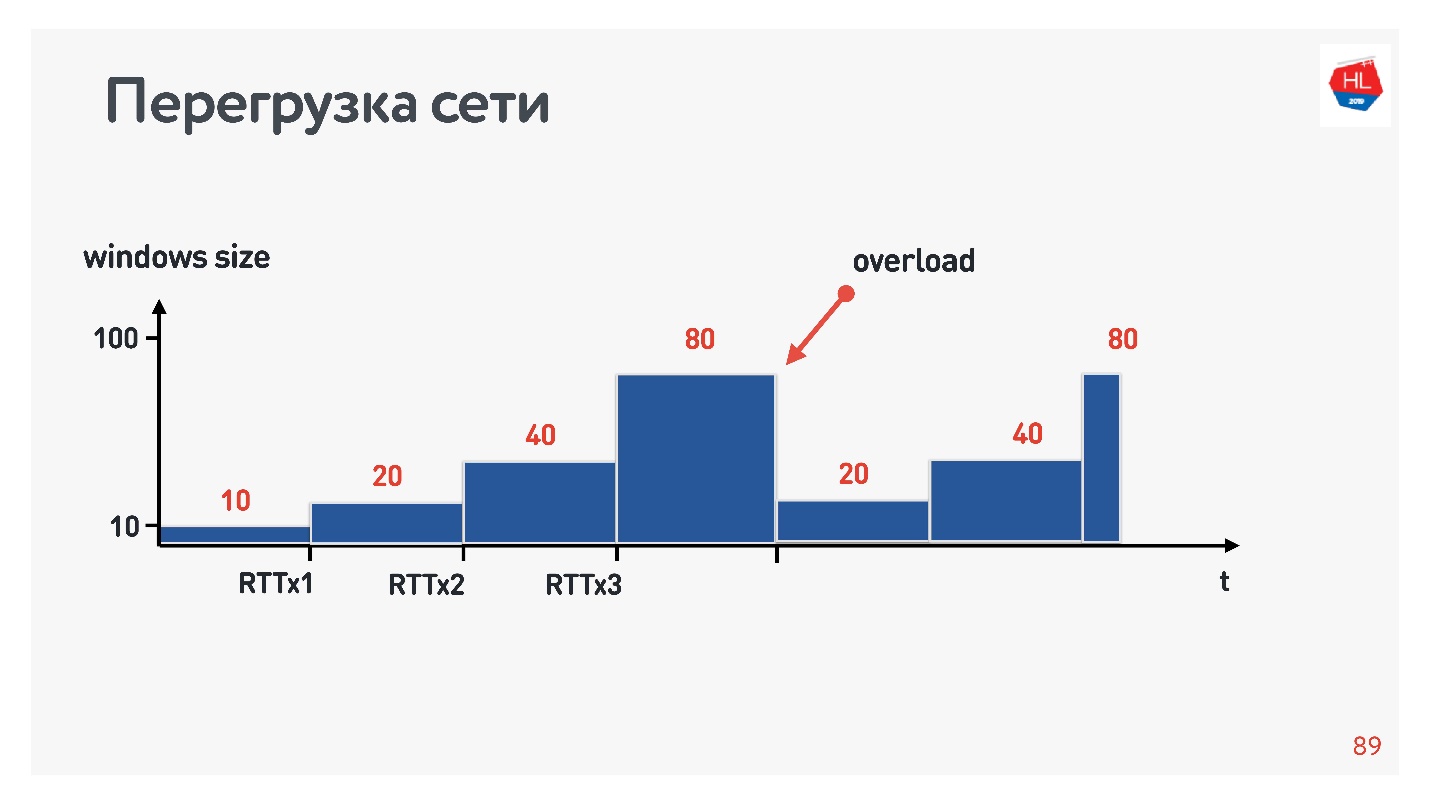
, , . : , .. , . congestion control, TCP window, , .
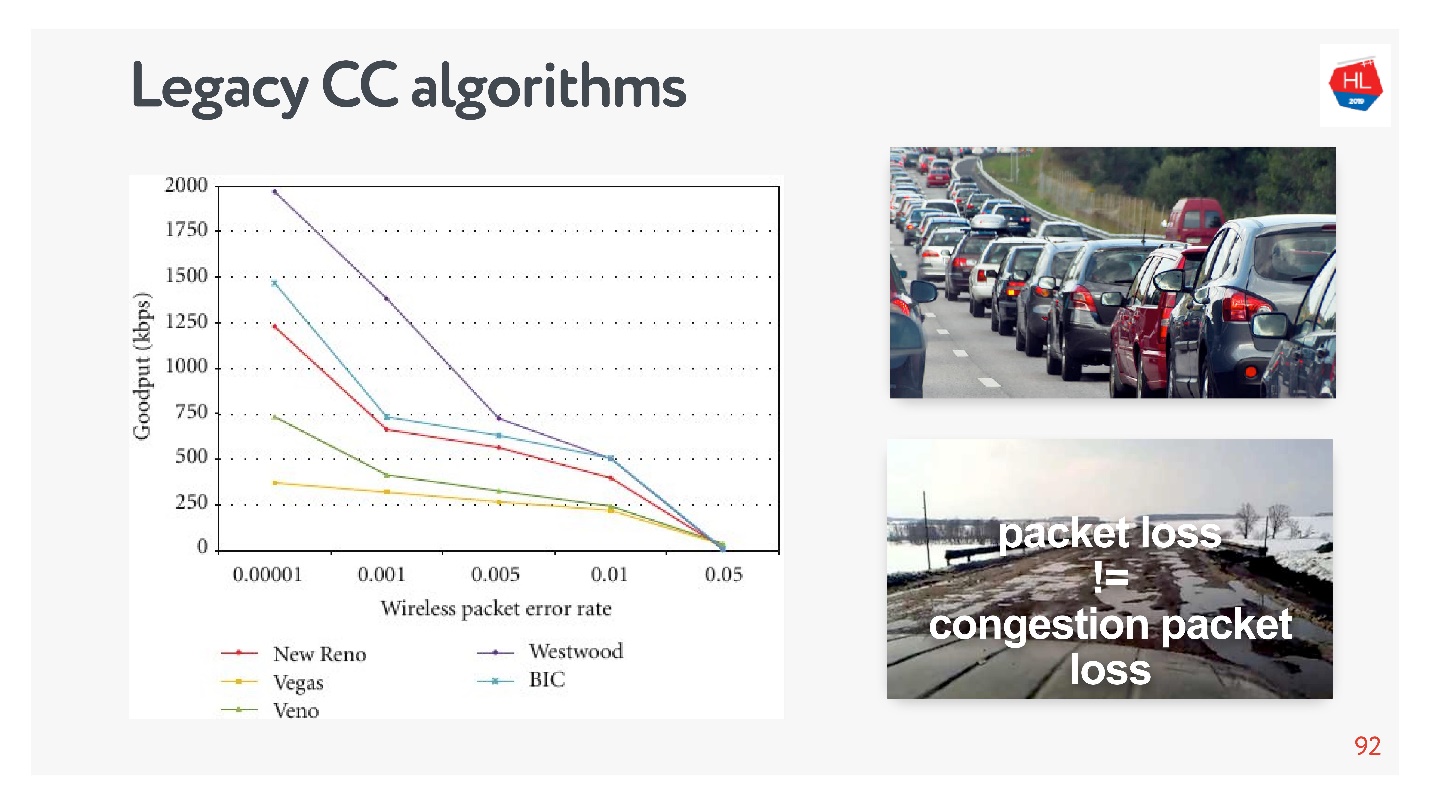
congestion control, , — . packet loss — , . , , — , .
, TCP , , congestion control loss-. congestion control loss delay, , .
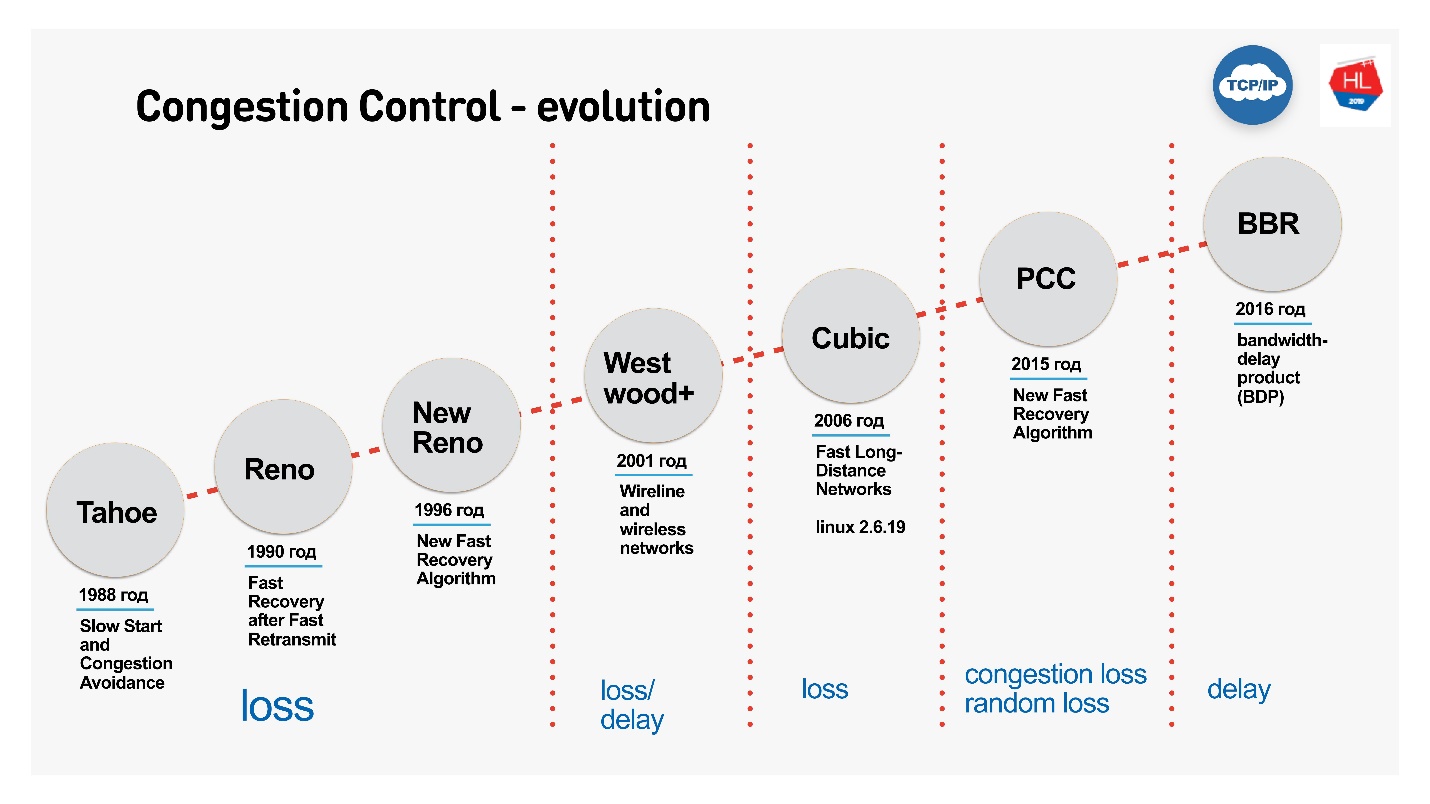
:
- Cubic — Congestion Control Linux 2.6. : — .
- BBR — Congestion Control, Google 2016 . .
BBR Congestion Control
Cubic BBR feedback.
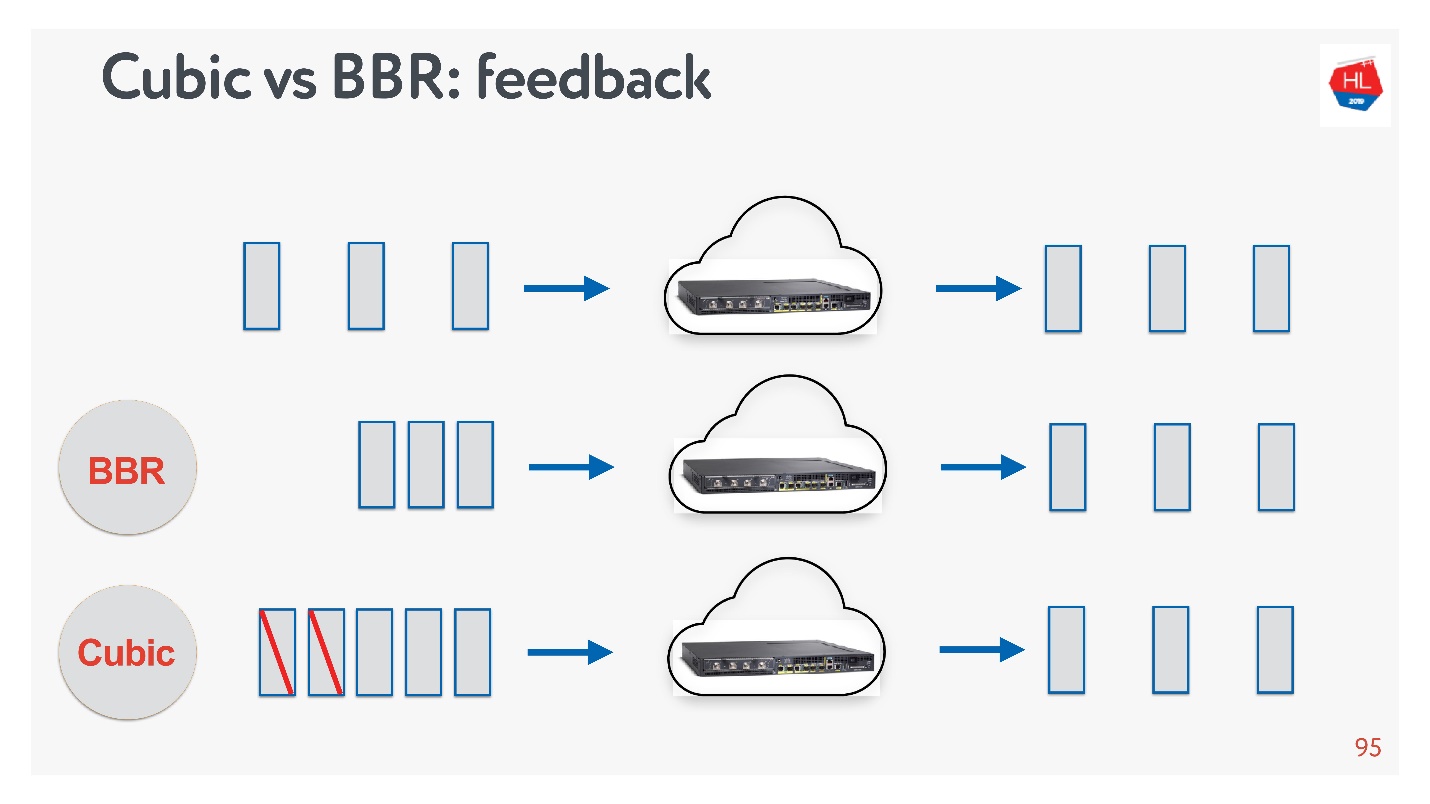
, — acknowledgement . :
Vous trouverez ci-dessous un graphique du délai en fonction du temps de connexion, qui montre ce qui se passe sur différents contrôles de congestion.
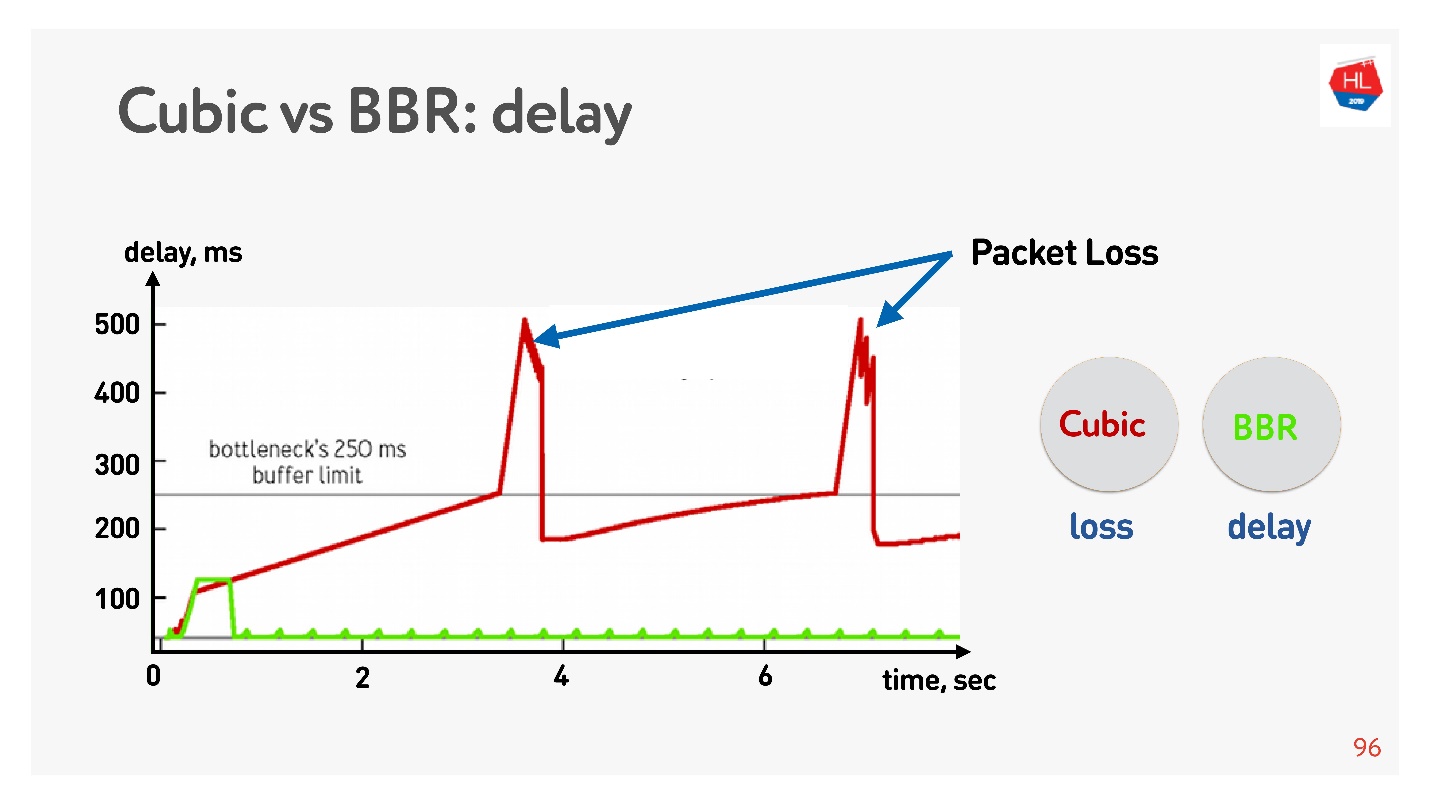
Le BBR détecte d'abord le temps d'aller-retour, envoie de plus en plus de paquets, puis se rend compte que le tampon est obstrué et entre en mode de fonctionnement avec un délai minimum.
Cubic fonctionne de manière agressive - il déborde la totalité du tampon, et lorsque le tampon déborde et la perte de paquets se produit, cubic réduit la fenêtre.
Il semble qu'avec l'aide de BBR, il serait possible de résoudre tous les problèmes, mais il y a de la
gigue sur les réseaux - les paquets sont parfois retardés, parfois regroupés en paquets. Vous les envoyez avec une certaine fréquence, et ils viennent en groupes. Pire encore, lorsque vous recevez des accusés de réception de retour vers ces packages, et ils "jitter" en quelque sorte.
Puisque j'ai promis que tout pourrait être touché à la main, nous ping, par exemple, le site
HighLoad ++ , regardons ping et considérons la gigue entre les packages.
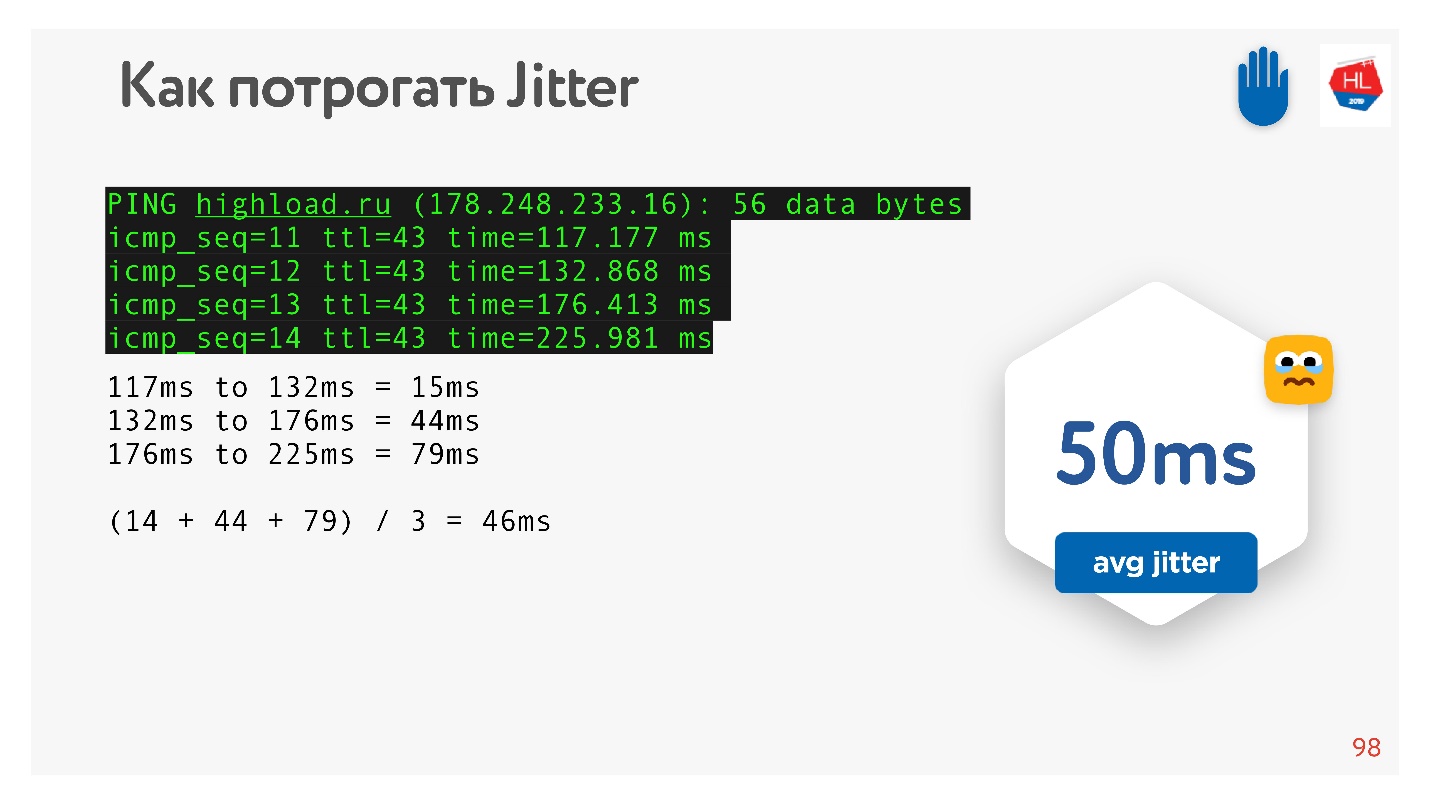
On peut voir que les paquets arrivent de manière inégale, la gigue moyenne est d'environ 50 ms. Naturellement, BBR peut se tromper.
BBR est bon car il fait la distinction entre: une perte de congestion réelle, une perte de paquets due à des débordements de tampon de périphérique et une perte aléatoire due à un réseau sans fil médiocre. Mais cela ne fonctionne pas bien en cas de gigue élevée. Comment puis-je l'aider?
Comment améliorer le contrôle de la congestion
En fait, TCP n'a pas assez d'informations en accusé de réception, il n'a que les paquets qu'il a vus. Il y a également un accusé de réception sélectif, qui indique quels paquets sont confirmés, lesquels ne sont pas encore arrivés. Mais cette information n'est pas suffisante.
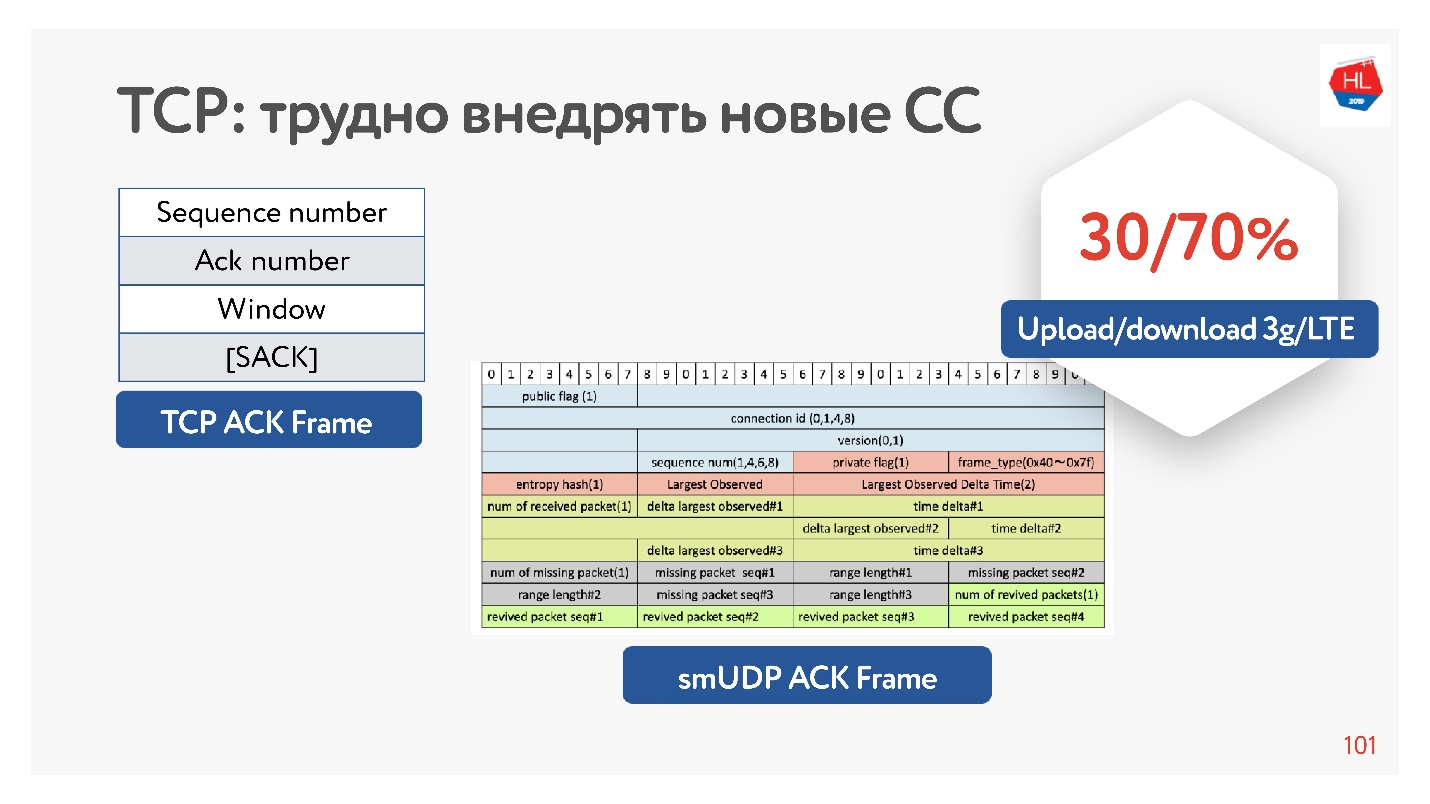
Si vous avez la possibilité de gonfler l'accusé de réception, vous pouvez toujours économiser tout le temps - non seulement en envoyant ces paquets, mais également en arrivant chez le client. C'est, en fait, sur le serveur pour collecter le client de gigue.
Pourquoi est-il généralement efficace de gonfler la reconnaissance? Parce que les réseaux mobiles sont asymétriques. Par exemple, généralement avec 3G ou LTE, 70% de la bande passante est allouée pour le téléchargement de données et 30% pour le téléchargement. L'émetteur commute: upload - download, upload - download, et vous ne l'affectez en aucune façon. Si vous ne déchargez rien, c'est tout simplement inactif. Par conséquent, si vous avez des idées intéressantes, augmentez la reconnaissance, ne soyez pas timide - ce n'est pas un problème.
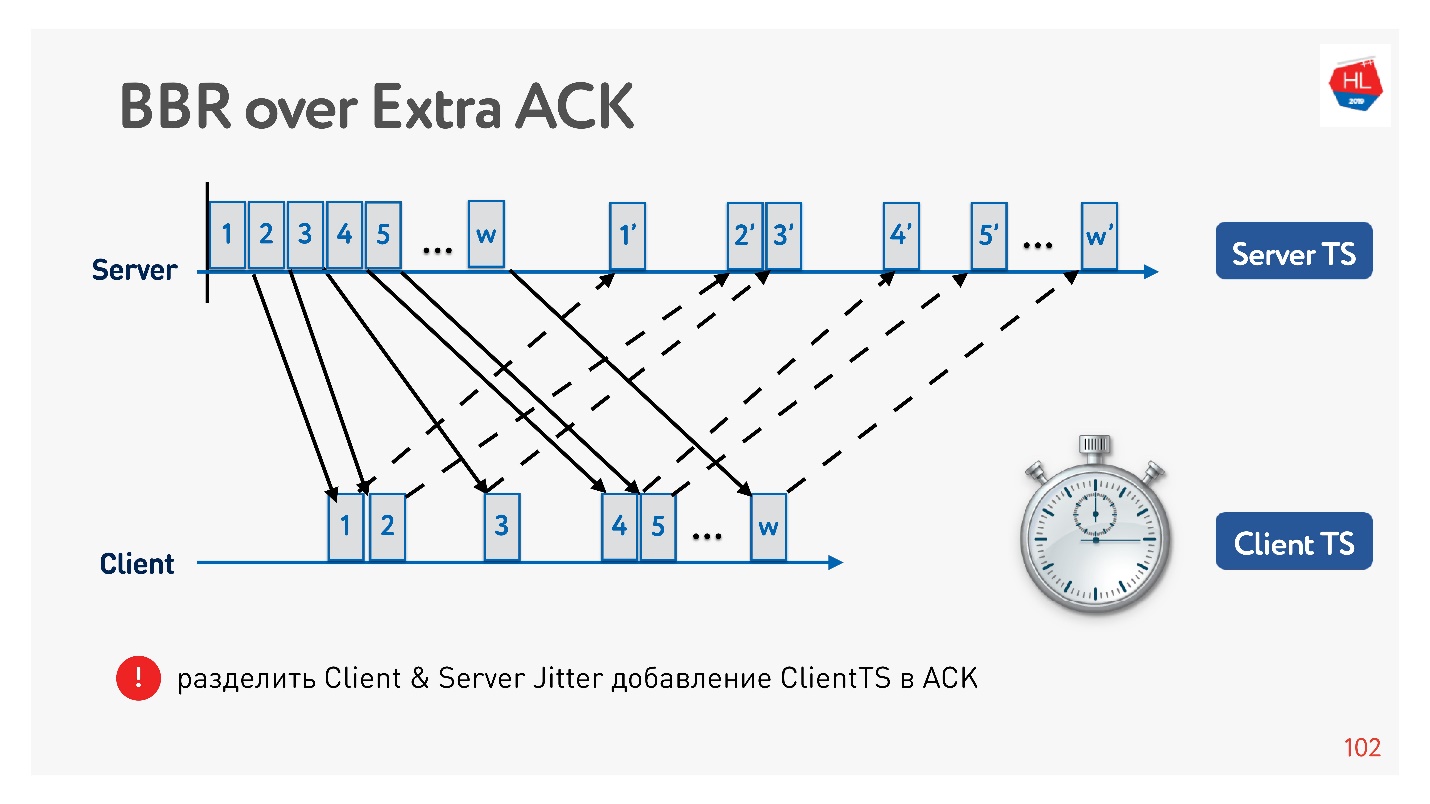
Un exemple de la façon dont vous pouvez utiliser un accusé de réception pour diviser la gigue en envoi et la gigue à recevoir, et les suivre séparément. Ensuite, nous devenons plus flexibles et nous comprenons quand une perte de congestion s'est produite et quand une perte aléatoire s'est produite. Par exemple, vous pouvez comprendre la quantité de gigue dans chaque direction et configurer plus précisément la fenêtre.

Quel contrôle de congestion choisir
Les camarades de classe sont un grand réseau avec beaucoup de trafic différent: vidéo, API, photos. Et il existe des statistiques dont le contrôle de la congestion est préférable.
BBR est toujours efficace pour la vidéo car il réduit les retards. Dans d'autres cas, Cubic est généralement utilisé - il convient aux photographies. Mais il existe d'autres options.

Il existe des dizaines d'options de contrôle de congestion différentes. Afin de choisir le meilleur, vous pouvez collecter des statistiques sur le client et essayer l'un ou l'autre contrôle de congestion pour différents types de profils de charge.
Par exemple, c'est l'effet du démarrage de BBR sur une vidéo.
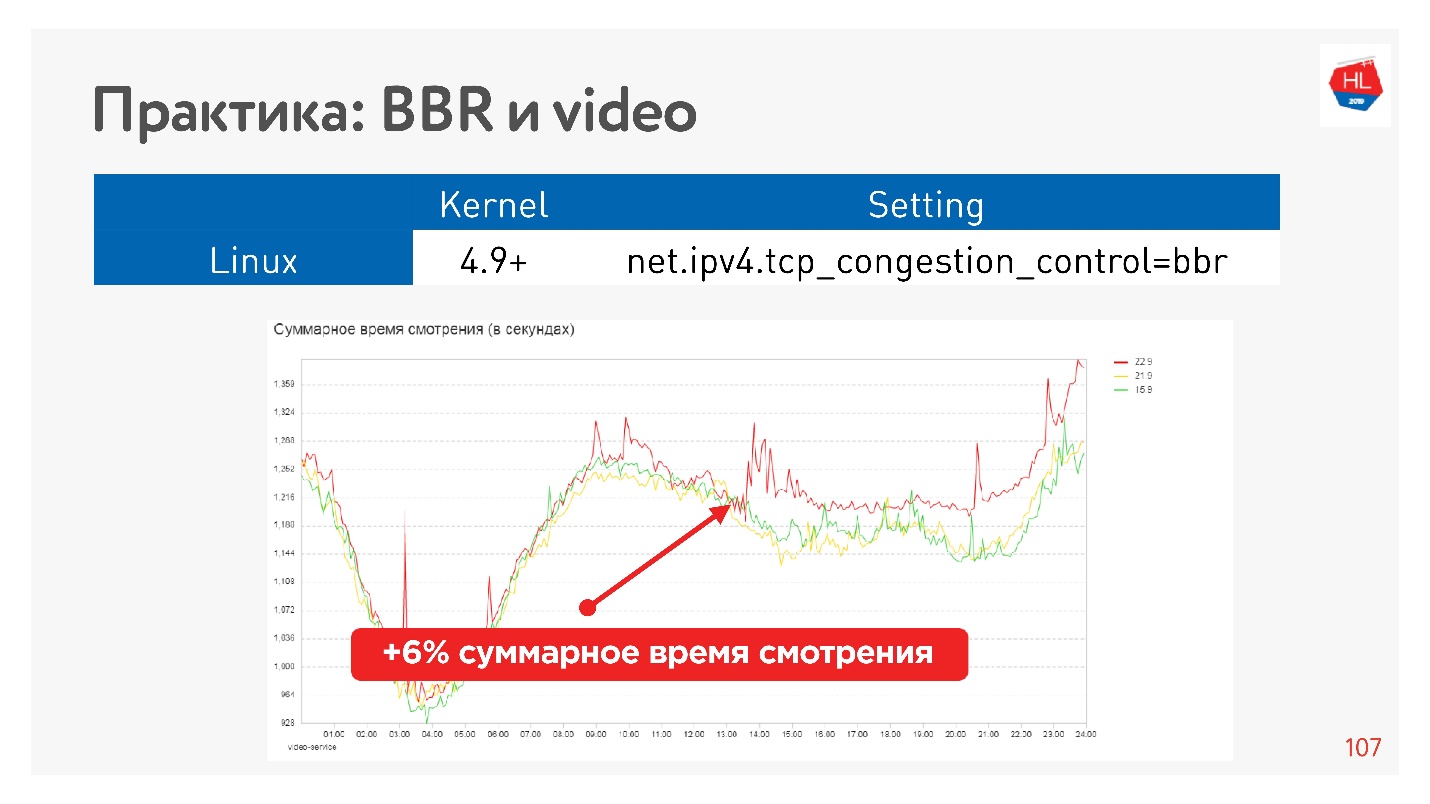
Nous avons réussi à augmenter sérieusement la profondeur de visionnage. Google dit qu'ils ont environ 10% de mémoire tampon en moins dans le lecteur lors de l'utilisation de BBR.
Génial, mais qu'en est-il de nos clients?

Les clients sont un peu lents, ils ont tous Cubic et vous ne pouvez pas l’influencer. Mais ça va, parfois vous pouvez paralléliser des données, et ce sera bien.
Conclusions sur le contrôle de la congestion:- BBR est toujours bon pour la vidéo.
- Dans d'autres cas, si nous utilisons notre propre protocole UDP, vous pouvez prendre le contrôle de la congestion avec vous.
- D'un point de vue TCP, vous ne pouvez utiliser que le contrôle de congestion, qui se trouve dans le noyau. Si vous souhaitez implémenter votre contrôle de congestion dans le noyau, vous devez vous conformer à la spécification TCP. Il est impossible de gonfler la reconnaissance, d'apporter des modifications, car elles ne sont tout simplement pas sur le client.
Si vous faites votre protocole UDP, vous avez beaucoup plus de liberté en termes de contrôle de congestion.
Multiplexage et priorisation
C'est une nouvelle tendance, tout le monde le fait maintenant. Quels sont les problèmes? Si nous utilisons TCP, tout le monde (ou presque) connaît sûrement la situation de blocage en tête de ligne.
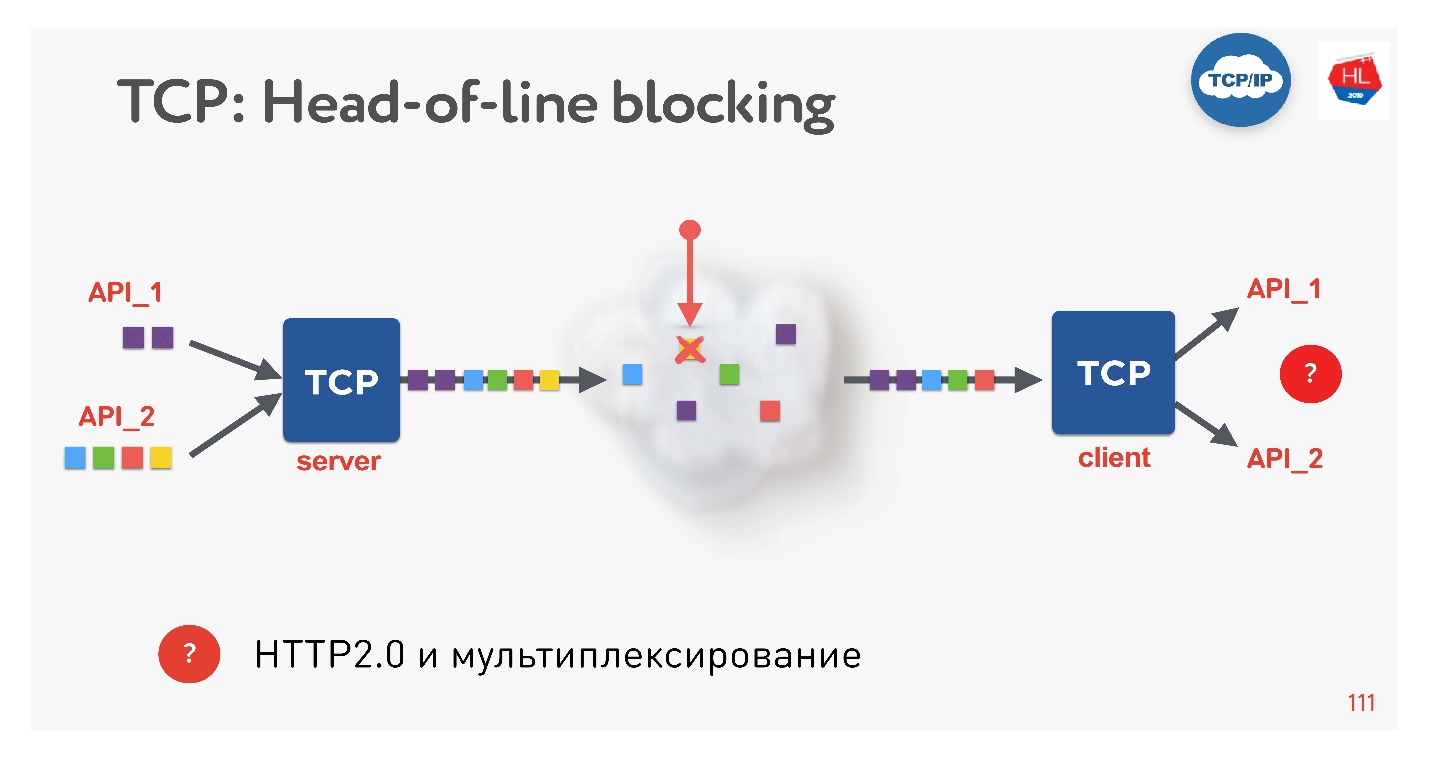
Plusieurs demandes sont multiplexées sur une seule connexion TCP. Nous les avons envoyés au réseau, mais un paquet manquait. Une connexion TCP retransmettra ce paquet; elle retransmettra dans un temps proche de RTT ou plus. Pour le moment, nous ne pourrons rien obtenir, bien que le tampon TCP contienne des données d'une autre demande qui est complètement prête à être récupérée.
Il s'avère que le multiplexage sur TCP, si vous utilisez HTTP 2.0, n'est pas toujours efficace sur les mauvais réseaux.
Le problème suivant est le gonflement du tampon.

Lorsqu'une image est envoyée au client, la mémoire tampon augmente. Nous l'envoyons depuis longtemps, puis une demande d'API apparaît, et elle ne peut en aucun cas être priorisée. Dans de tels cas, la hiérarchisation TCP ne fonctionne pas.
Ainsi, si une perte de paquets se produit, il y a un blocage en tête de ligne et lorsque le client a un débit binaire variable (et cela arrive souvent avec les clients mobiles), l'effet tampon tampon apparaît. Par conséquent, ni le multiplexage, ni la priorisation, ni la poussée du serveur, ni tout le reste ne fonctionne, car nous avons soit des tampons, soit le client attend quelque chose.
Si nous faisons notre propre multiplexage, nous pouvons y mettre diverses données.
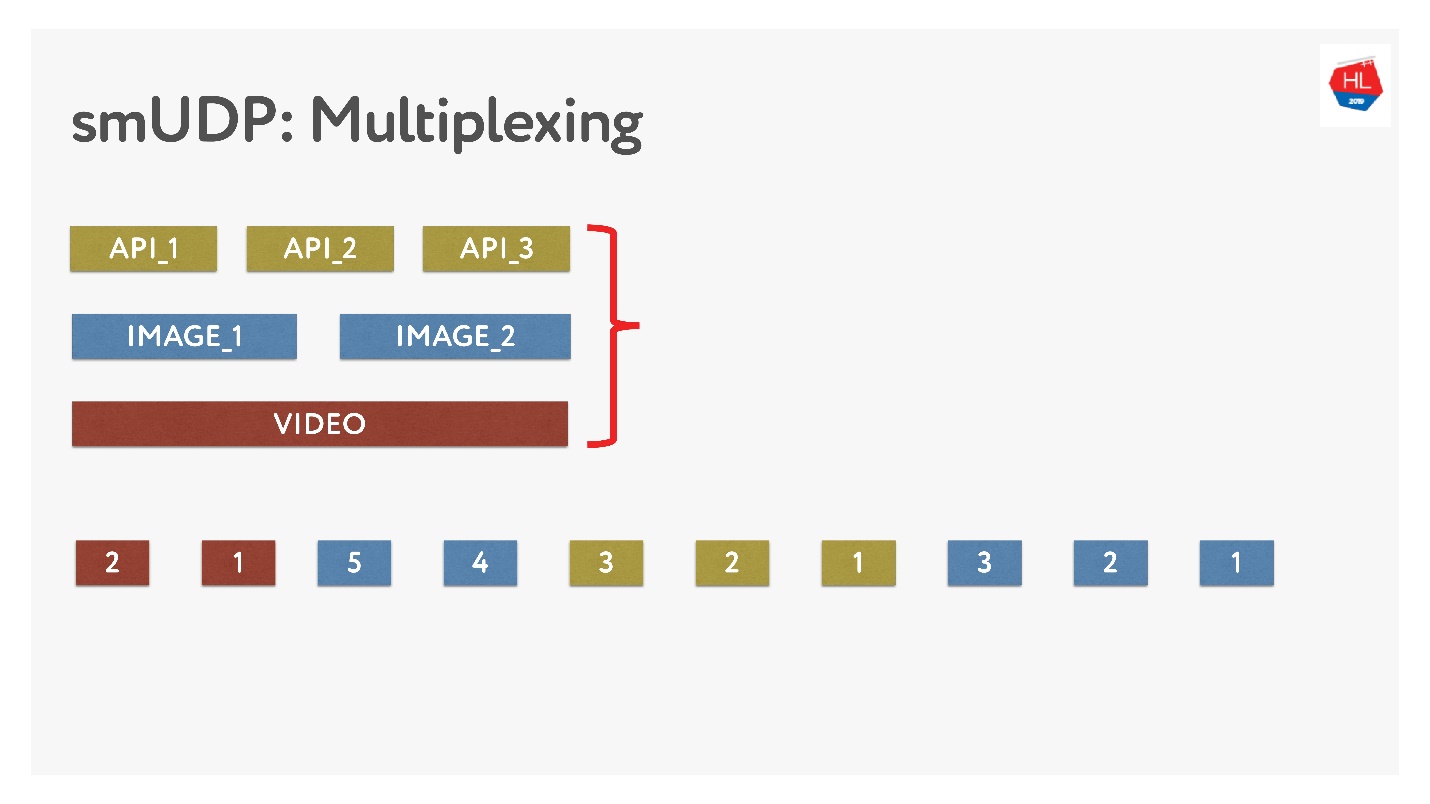
Ce n'est pas difficile, ajoutez simplement des paquets avec des nombres dans le tampon. À la volée - ne touchez pas à ce qui a déjà été envoyé, mais ce qui n'a pas encore été envoyé peut être réorganisé. Cela ressemble à ceci.
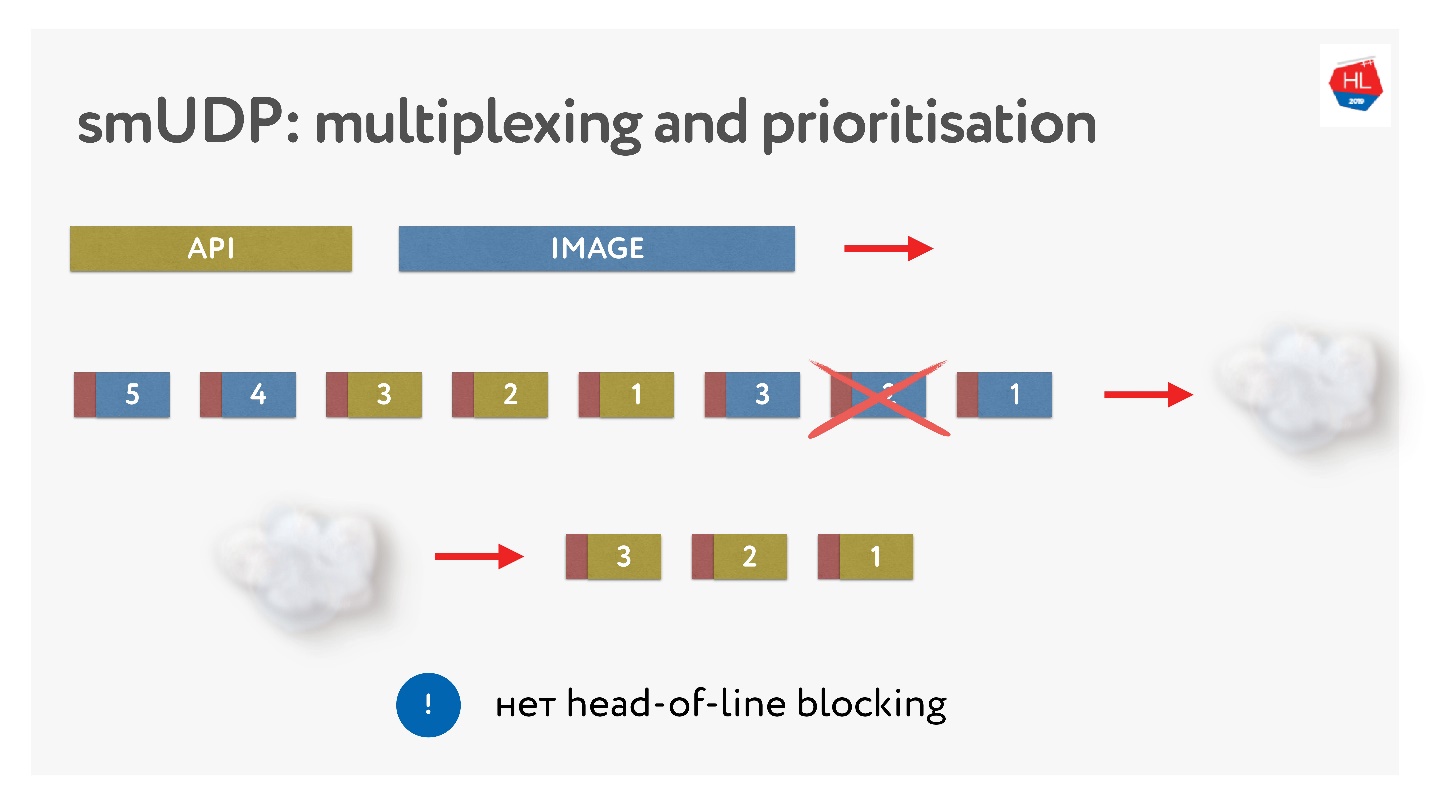
Ils ont envoyé des photos, les ont divisés en paquets, sont venus une demande d'API prioritaire: ils l'ont insérée, ont envoyé la photo. Même s'il manque un paquet, nous pouvons obtenir une demande d'API prête à l'emploi à partir du tampon, il est de haute priorité et atteindra rapidement le client. Dans TCP, par définition, le transfert de données en continu n'est pas possible.
Établir une connexion
Si nous profilons notre application, nous verrons que la plupart du temps, le réseau est inactif au début de l'application, car la connexion est d'abord établie avant l'API, puis nous obtenons les données, puis la connexion est établie avant les images, ces données sont téléchargées, etc. Cela se produit toujours - le réseau est utilisé par des pics.

Pour y faire face, voyons comment la connexion est établie.
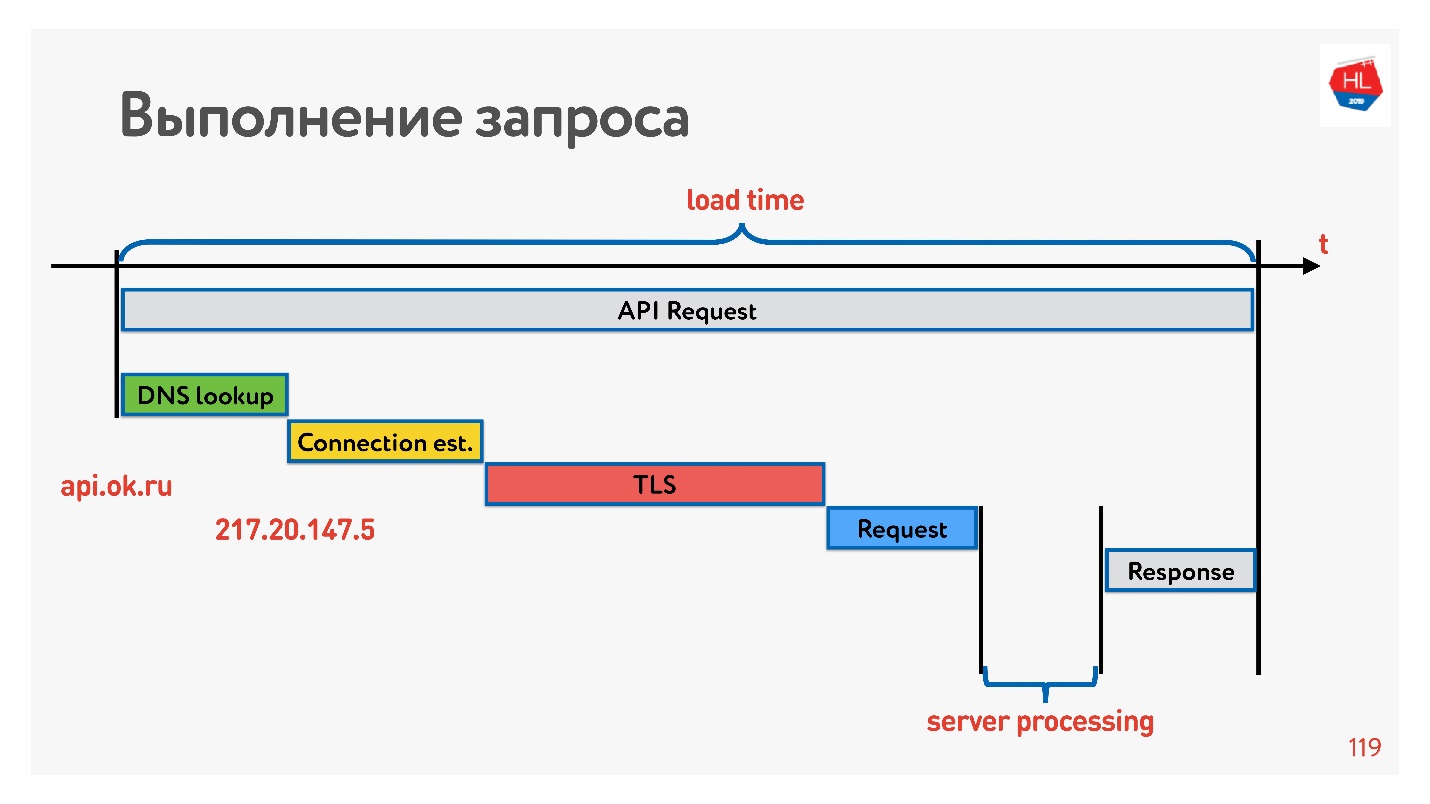
Le premier est de résoudre le DNS - nous ne pouvons rien y faire. Ensuite, établissez une connexion TCP, établissez une connexion sécurisée, puis exécutez la demande et recevez une réponse. La chose la plus intéressante est qu'une partie du travail effectué par le serveur lorsqu'il répond à une demande prend généralement moins de temps que l'établissement d'une connexion.
Maintenant, il est très à la mode de mesurer les nombres de latence pour la mémoire, pour les disques, pour autre chose. Vous pouvez les mesurer pour un réseau 3G, 4G et voir combien de temps il faut dans le pire des cas pour établir une connexion TCP avec TLS.
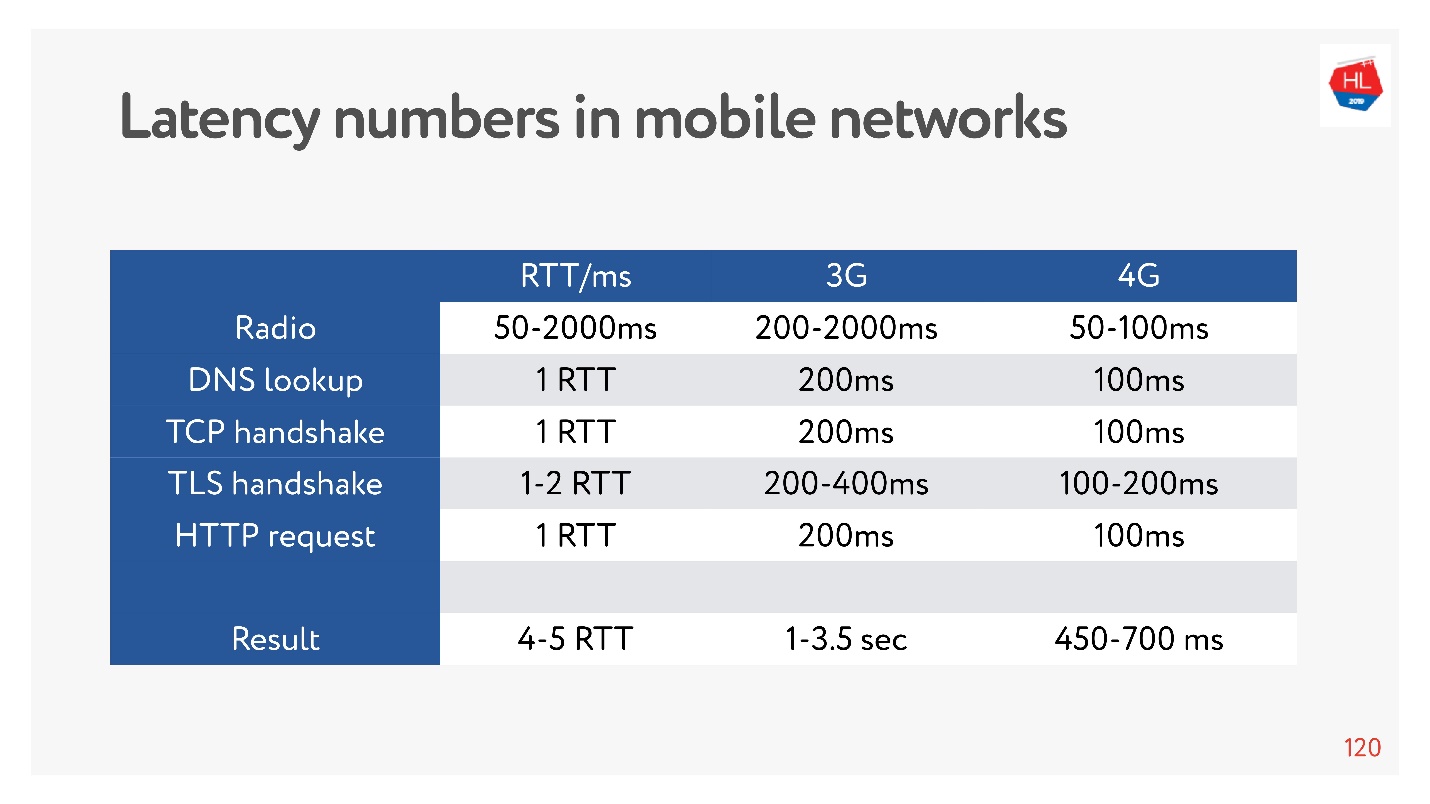
Et cela peut prendre quelques secondes! Même sur 4G jusqu'à 700 ms est également significatif. Mais TCP n'a pas pu vivre aussi facilement pendant tout ce temps.
La connexion est basée sur l'algorithme de prise de
contact TCP à 3 voies de base . Faites syn, syn + ack, puis corrigez la demande plus tard (à gauche dans le diagramme).
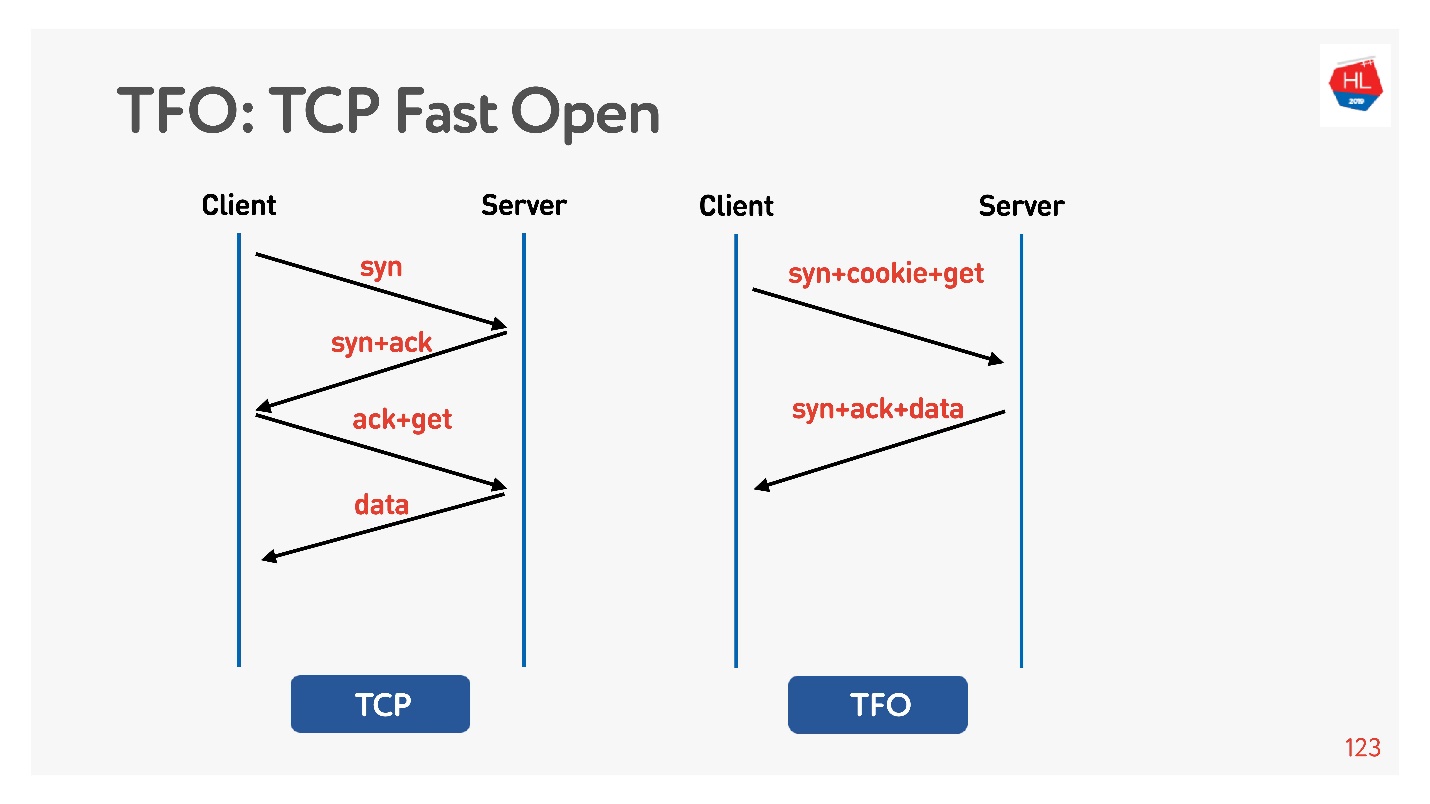
Il y a
TCP Fast Open (à droite). Si vous avez déjà fait une poignée de main avec ce serveur, il y a un cookie, vous pouvez envoyer votre demande immédiatement pour zéro-RTT. Pour l'utiliser, vous devez créer un socket, faire envoyer à () les premières données, dire que vous voulez FASTOPEN.

Nginx peut faire tout cela - allumez-le, tout fonctionnera (ou allumez-le dans le noyau).
TLS
Vérifions que TLS est mauvais.
J'ai à nouveau défini net shaper pendant 200 ms, j'ai fait un ping sur google.com et j'ai vu que RTT = 220 est mon shaper RTT + RTT. Ensuite, j'ai fait une demande via HTTP et HTTPS. J'ai découvert que via HTTP, il est possible d'obtenir une réponse pendant RTT, c'est-à-dire que TFO fonctionne pour Google depuis mon ordinateur. Pour HTTPS, cela a pris plus de temps.

Il s'agit d'une surcharge TLS courante qui nécessite une messagerie pour établir une connexion sécurisée.
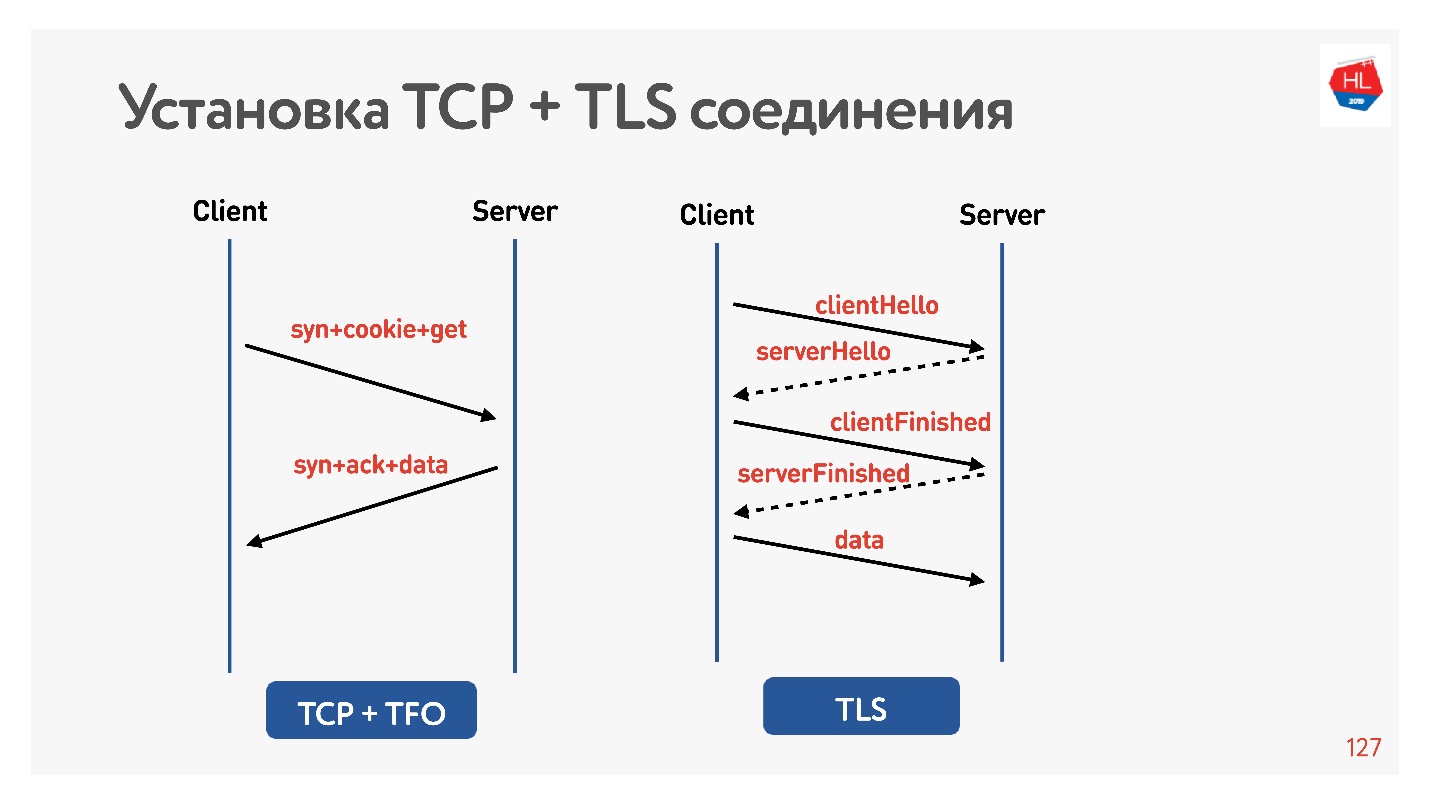
Pour ce faire, ils ont pensé pour nous, a ajouté TLS 1.3. Il est également facile à inclure dans nginx.
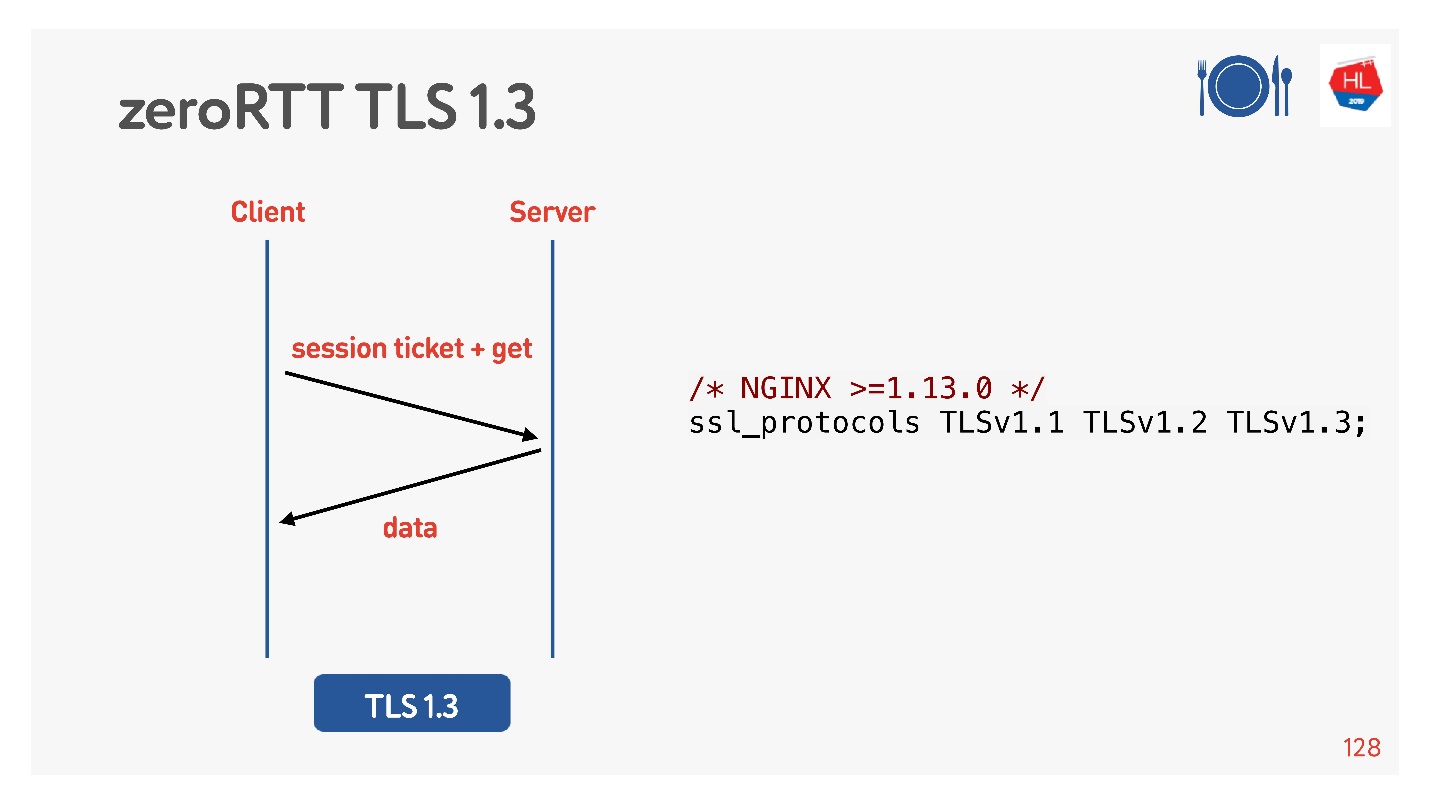
Tout semble fonctionner. Mais voyons ce qu'il y a sur nos clients mobiles qui profitent de tout cela.
Quoi de neuf avec les clients
TCP Fast Open est une bonne chose. Selon les statistiques.
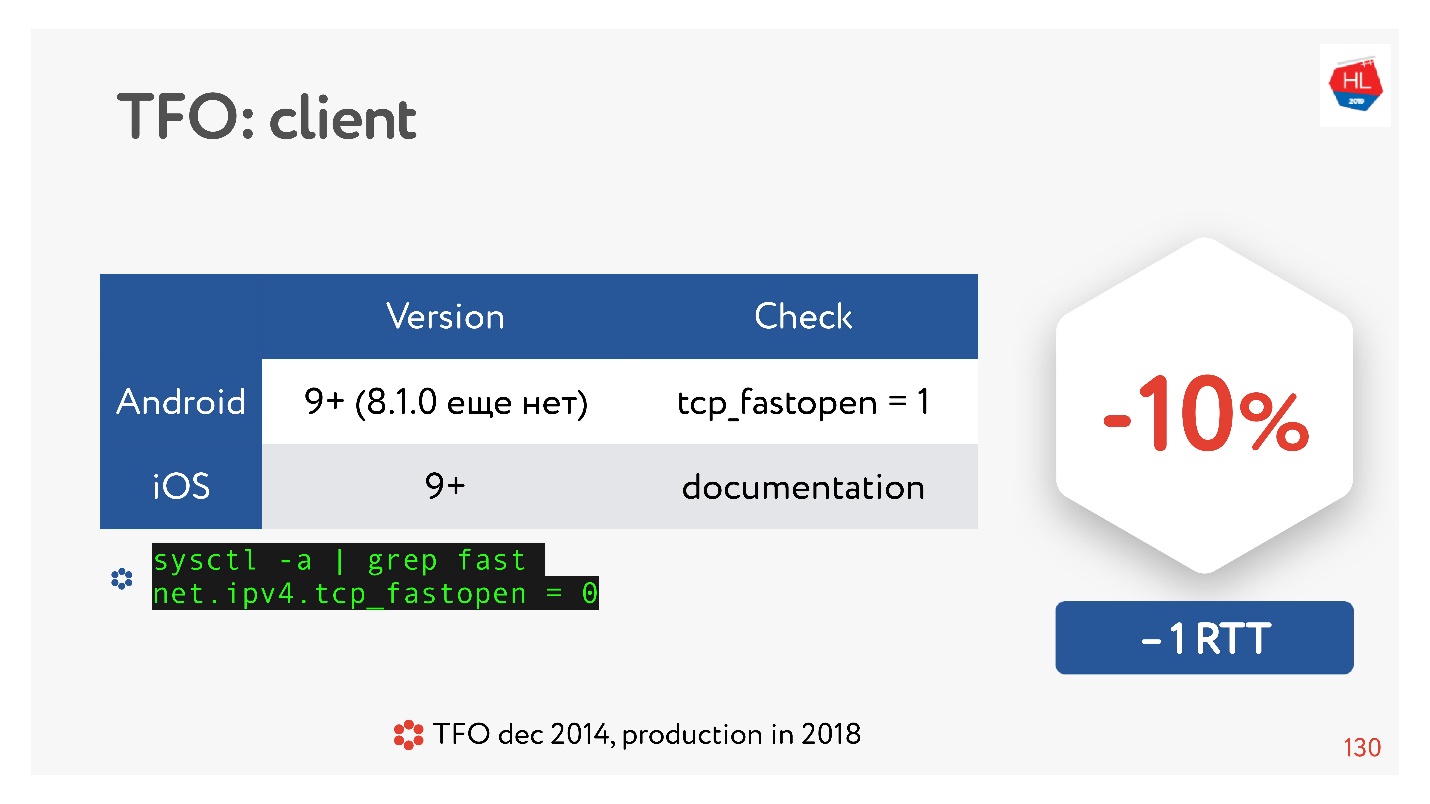
Il existe de nombreux articles qui disent que l'établissement d'une connexion est garanti pour passer 10% plus rapidement. Mais sur Android 8.1.0 (j'ai regardé divers appareils), personne n'a TFO. Sur Android 9, j'ai vu TFO sur l'émulateur, mais pas sur de vrais appareils. IOS est un peu mieux. Ici vous pouvez le voir:
sysctl -a | grep fast net.ipv4.tcp_fastopen = 0
Pourquoi est-ce arrivé? TCP Fast Open a été proposé en 2014, maintenant c'est déjà un standard, il est supporté sous Linux et tout est super. Mais il y a un tel problème que la prise de contact TFO a commencé à s'effondrer dans certains réseaux. En effet, certains fournisseurs (ou certains périphériques) sont habitués à inspecter TCP, à faire leurs optimisations, et ne s'attendaient pas à ce qu'il y ait une prise de contact TFO. Par conséquent, sa mise en œuvre a pris tellement de temps, et jusqu'à présent, les clients mobiles ne l'incluent pas par défaut, au moins Android.
Avec TLS 1.3, qui nous promet, la configuration de la connexion sans RTT est encore meilleure. Je n'ai trouvé aucun appareil Android sur lequel cela fonctionnerait. Par conséquent, Facebook a créé la bibliothèque
Fizz . Il y a quelques mois, il est devenu disponible en open source, vous pouvez le faire glisser avec vous et utiliser TLS 1.3. Il s'avère que même la sécurité doit être entraînée, rien n'apparaît au cœur de cela.
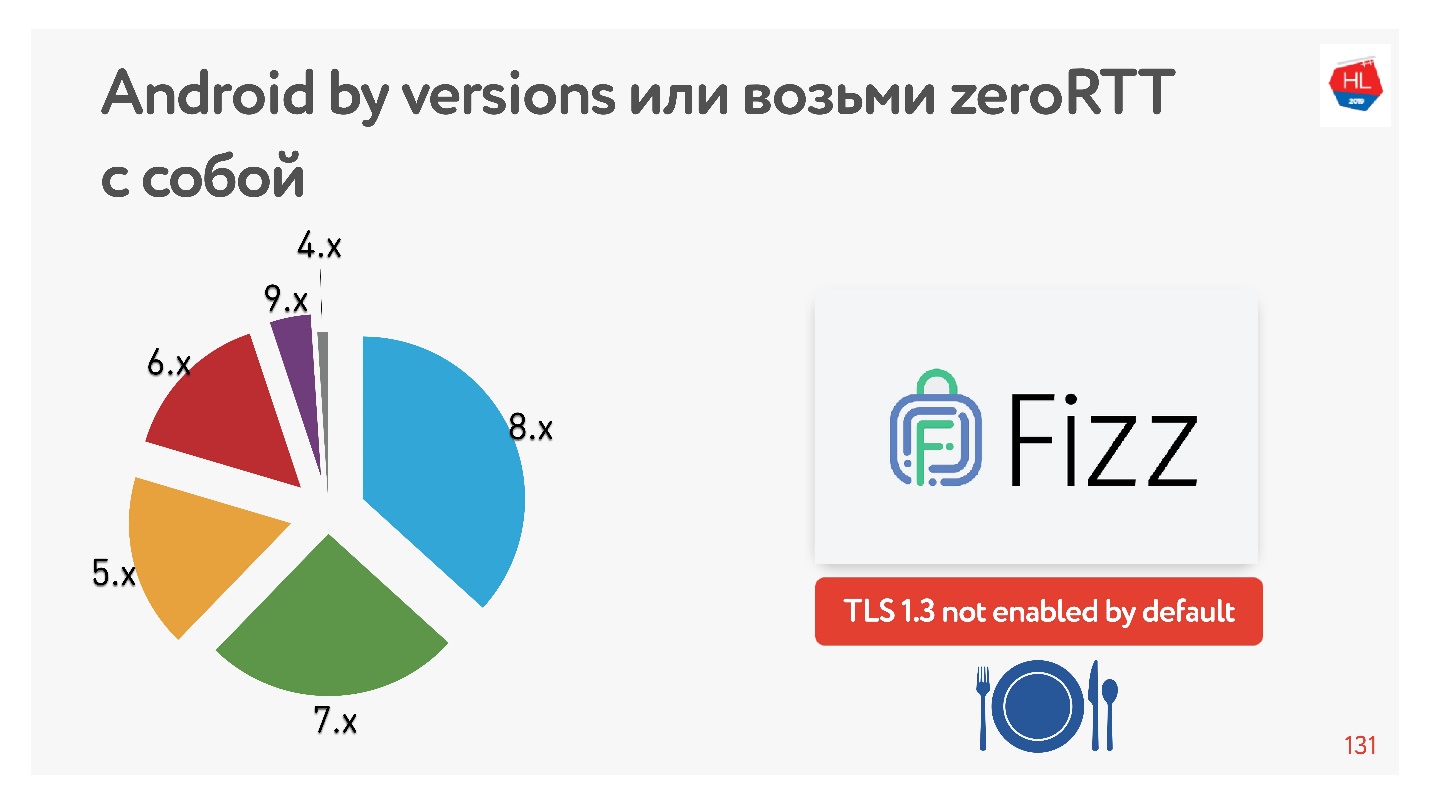
Le diagramme montre l'utilisation de différentes versions d'Android par nos clients mobiles. V 9.x est un peu - où TFO peut apparaître, et TLS1.3 ne se trouve nulle part ailleurs.
Conclusions sur l'établissement d'une connexion:- TFO n'est pas disponible pour 95% des appareils.
- TLS1.3 doit être apporté avec lui-même.
- Si vous devez répéter cela dans UDP, transférez tout cela vers UDP et répétez.
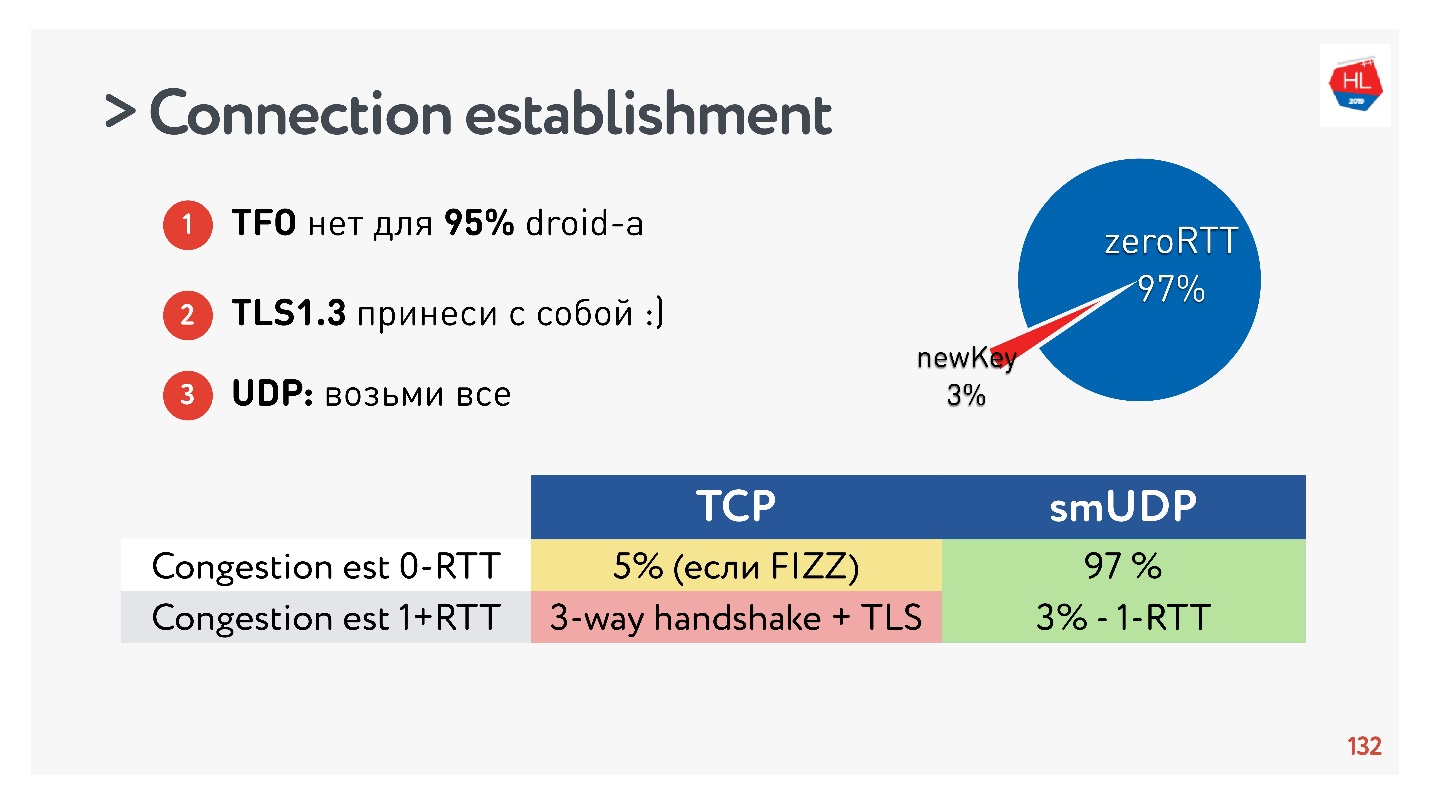
Il s'est avéré que 97% des connexions créées utilisent la clé existante, c'est-à-dire que 97% sont créés pour zéro RTT et seulement 3% sont nouveaux. La clé est stockée sur l'appareil pendant un certain temps.
TCP ne peut pas s'en vanter. Dans un maximum de 5% des cas, si vous faites tout correctement, vous pourrez obtenir le vrai zéro-RTT dont tout le monde parle maintenant.
Changement d'adresse IP
Souvent, lorsque vous quittez votre domicile, votre téléphone passe du Wi-Fi à la 4G.
TCP fonctionne comme ceci: l'adresse IP a changé - la connexion a échoué.
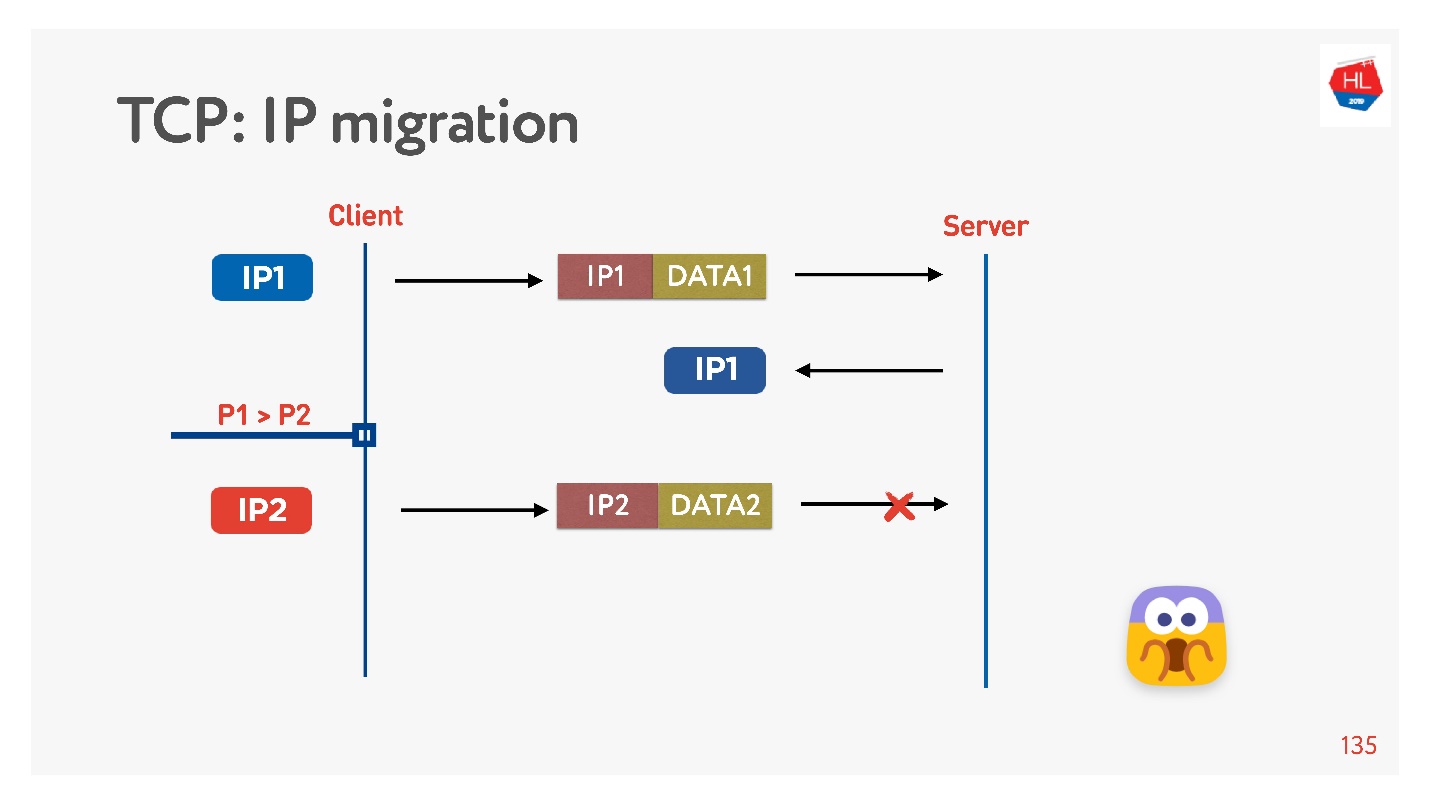
Si vous écrivez votre protocole UDP, c'est très simple, en implémentant un ID de connexion (CUID) dans chaque paquet, vous pouvez l'identifier, même s'il provient d'une adresse IP différente.

Il est clair que vous devez vous assurer qu'il a la bonne clé, que tout est déchiffré, etc. Mais en principe, vous pouvez commencer à répondre à cette adresse, cela ne posera aucun problème.
Dans TCP, la migration IP est une chose impossible.
Si vous faites votre UDP, et que vous êtes arrivé sur le même serveur, vous devez faire un peu de magie, inclure le CID dans chaque paquet, et vous pourrez utiliser la connexion établie lors du changement d'adresse IP.
Réutilisation des connexions
Tout le monde dit que vous devez réutiliser les connexions car les connexions coûtent très cher.

Mais il y a des pièges à réutiliser les composés.
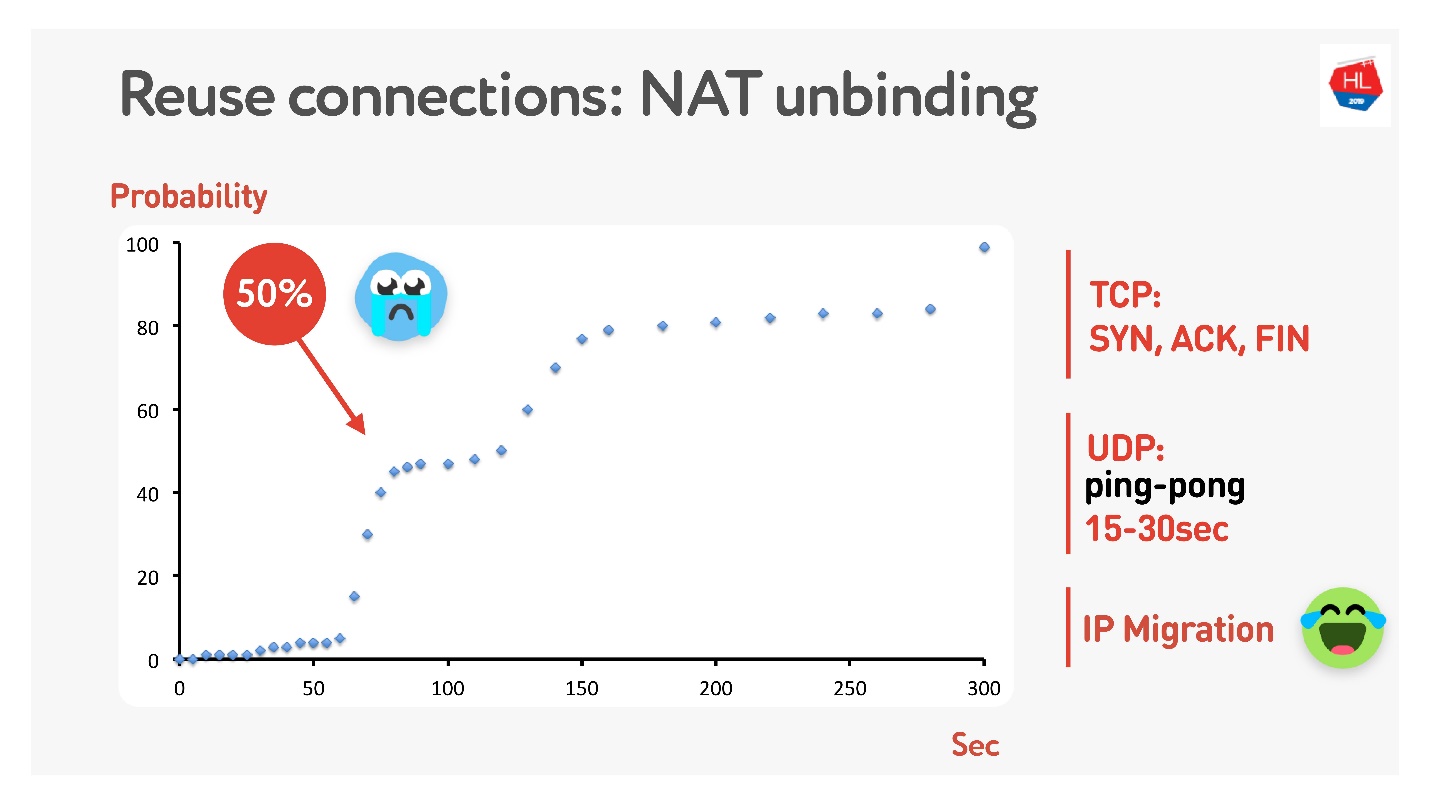
Très probablement, beaucoup de gens se souviennent (sinon, voyez
ici ) que tout le monde n'a pas d'adresse publique, mais il y a NAT, qui stocke généralement le mappage pendant un certain temps sur le routeur domestique. Pour TCP, la quantité à stocker est claire, mais pour UDP, elle n'est pas claire. NAT fonctionne sur un timeout, si vous mesurez soigneusement ce timeout, nous obtenons que dans environ 15-30 secondes, plus de 50% des connexions commenceront à échouer.
Ça va - nous allons faire un paquet de ping-pong pendant 15 s. Pour les cas où la connexion est toujours interrompue, il y a la migration IP, qui vous permet à moindre coût de changer le port sur le routeur.
Stimulation du paquet
C'est une chose très importante si vous faites votre protocole UDP.

Si c'est très simple, plus vous envoyez des paquets en continu au réseau, plus la probabilité de perte de paquets est grande. Si vous filtrez les paquets, la perte de paquets sera plus faible.
Il existe de nombreuses théories différentes sur la façon dont cela fonctionne, mais j'aime celle-ci.
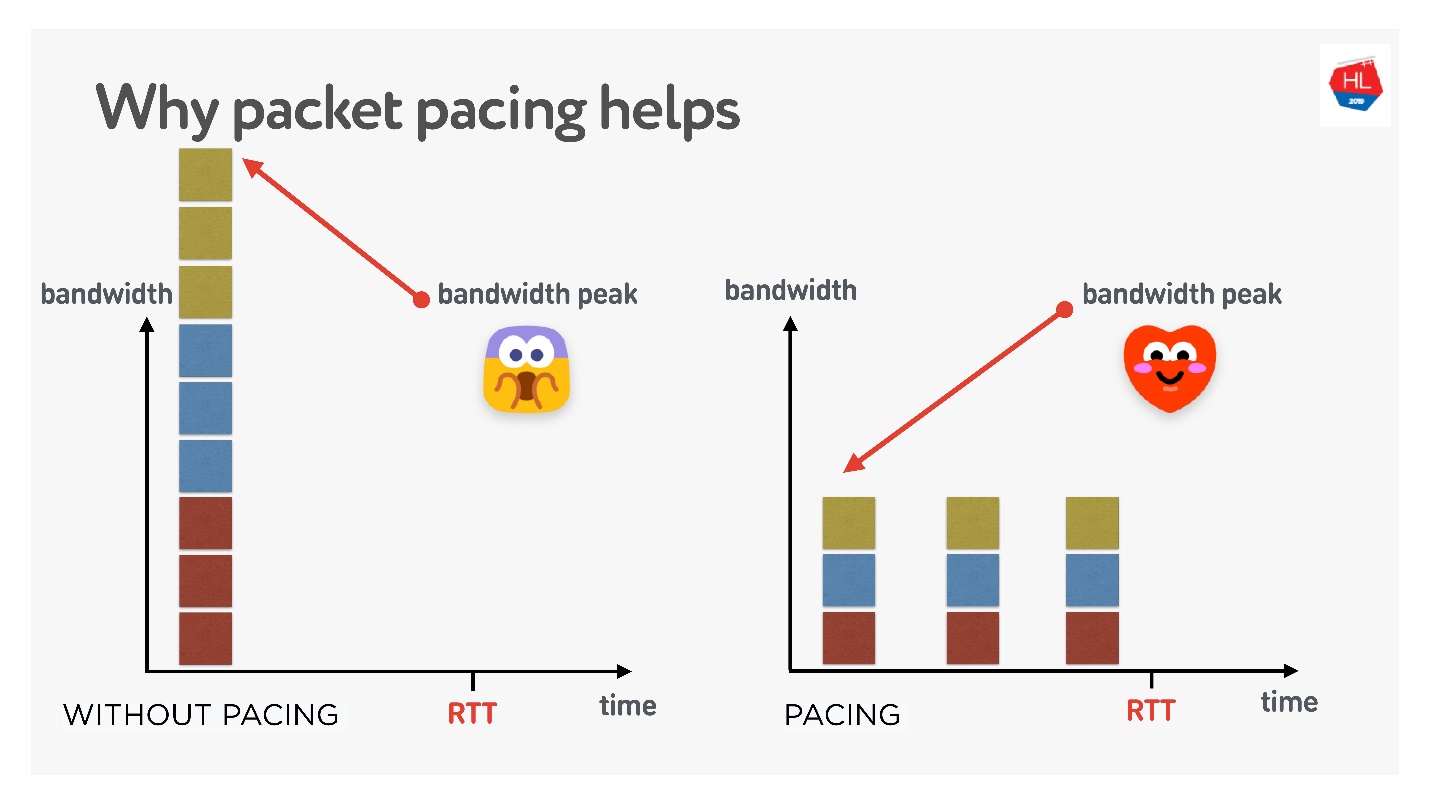
Trois connexions sont créées en même temps. Vous avez la soi-disant fenêtre initiale - 10 packages créés en même temps. Bien sûr, la bande passante pourrait ne pas être suffisante à ce stade. Mais si vous les distribuez soigneusement, les séparez, alors tout ira bien, comme sur la bonne figure.
Ainsi, si vous définissez un débit uniforme pour l'envoi de paquets, les affinez, la probabilité qu'il y ait un dépassement de mémoire tampon unique devient plus faible. Ce n'est pas prouvé, mais théoriquement cela se passe comme ça.

Lorsque vous devez couper des paquets (faire du rythme):
- Lorsque vous créez une fenêtre.
- Lorsque vous agrandissez la fenêtre, par exemple, il est recommandé d'ajouter autant de paquets que possible pour RTT / 2. Cela ne dégradera pas le délai de livraison, mais réduira la perte de paquets.
- En cas de perte de congestion, pour réduire la fenêtre, vous devez étaler encore plus les paquets. 4/5 RTT est une figure sélectionnée empiriquement.
MTU
Lorsque vous écrivez votre protocole UDP, n'oubliez pas de vous souvenir de MTU. MTU est la taille des données que vous pouvez transmettre.
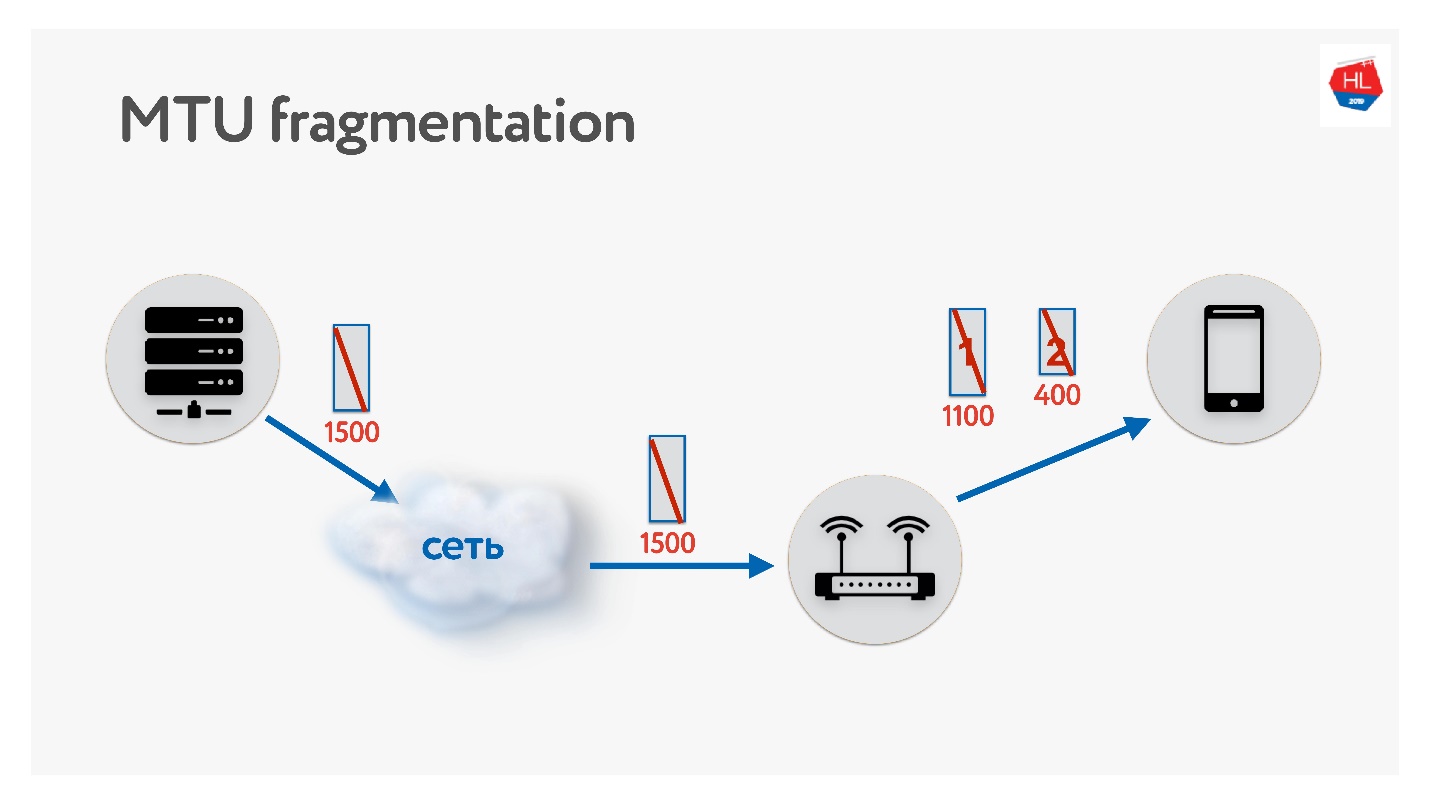
Nous envoyons des paquets du serveur au client, par exemple, avec une taille de 1500. S'il y a un routeur sur le chemin qui ne prend pas en charge cette taille MTU, il le fragmentera. Le seul problème de fragmentation est que si un paquet est perdu, les deux seront perdus et tout cela devra être retransmis. Par conséquent, TCP a un algorithme pour déterminer MTU - PMTU.

Chaque routeur regarde le MTU de son interface, l'envoie à un client, l'autre l'envoie à son client, tout le monde sait combien de MTU ils ont sur le client. Ensuite, la fragmentation est interdite par l'indicateur et des paquets de taille MTU sont envoyés. Si à ce moment quelqu'un à l'intérieur du réseau se rend compte qu'il a moins de MTU, alors via ICMP il dira: "Désolé, le paquet a été perdu car une fragmentation est nécessaire" et indiquera la taille du MTU. Nous changerons cette taille et continuerons à expédier. Dans le pire des cas, notre petit frais généraux est RTT / 2. C'est en TCP.
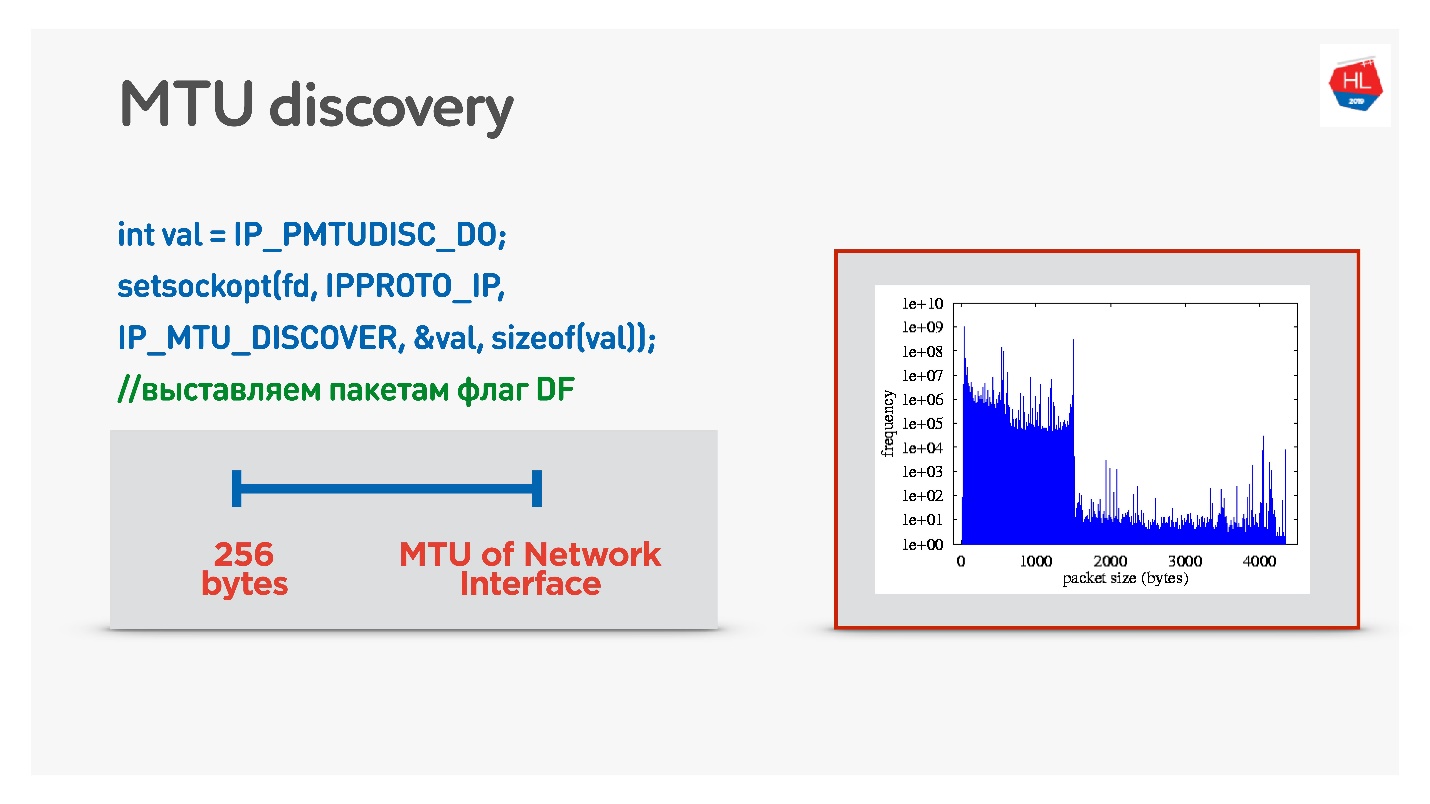
Si dans UDP vous ne voulez pas vous embêter avec ICMP, vous pouvez faire ce qui suit: autoriser la fragmentation lors de l'envoi de données normales. Autrement dit, pour envoyer des paquets fragmentés - laissez-les fonctionner. Et en parallèle pour démarrer un processus qui interdit la fragmentation, une recherche binaire sélectionnera le MTU optimal, auquel nous irons ensuite. Ce n'est pas entièrement efficace, car au début, le MTU semble se réchauffer.
Une option plus délicate consiste à examiner la distribution de MTU parmi les clients mobiles.

De tous les clients, nous avons envoyé des paquets de différentes tailles avec l'interdiction de la fragmentation. Autrement dit, si le paquet n'atteint pas, il tombera et le plus petit MTU devrait atteindre 100%. Mais il y a une petite perte de paquets, il y a donc deux diapositives sur le graphique:
- 1350 octets - au lieu de 98%, nous recevons 95% de livraison immédiatement.
- 1500 octets - MTU, après quoi déjà 80% des clients ne recevront pas de tels paquets.
En fait, nous pouvons dire ceci: nous négligeons 1-2% de nos clients, les laissons vivre sur des packages fragmentés. Mais nous partirons immédiatement de ce dont nous avons besoin - c'est à partir de 1350.
Correction d'erreurs (SACK, NACK, FEC)
Si vous effectuez votre protocole, vous devez corriger les erreurs. Si le paquet est manquant (c'est normal pour les réseaux sans fil), il doit être restauré.
Dans le cas le plus simple (plus de détails
ici ), il y a un relais via Retransmit Time Out (RTO). Si le paquet est manquant, attendez l'heure de retransmission et renvoyez-le.
L'algorithme suivant est la
retransmission rapide . Ce sont tous des algorithmes TCP, mais ils peuvent être facilement portés vers UDP.
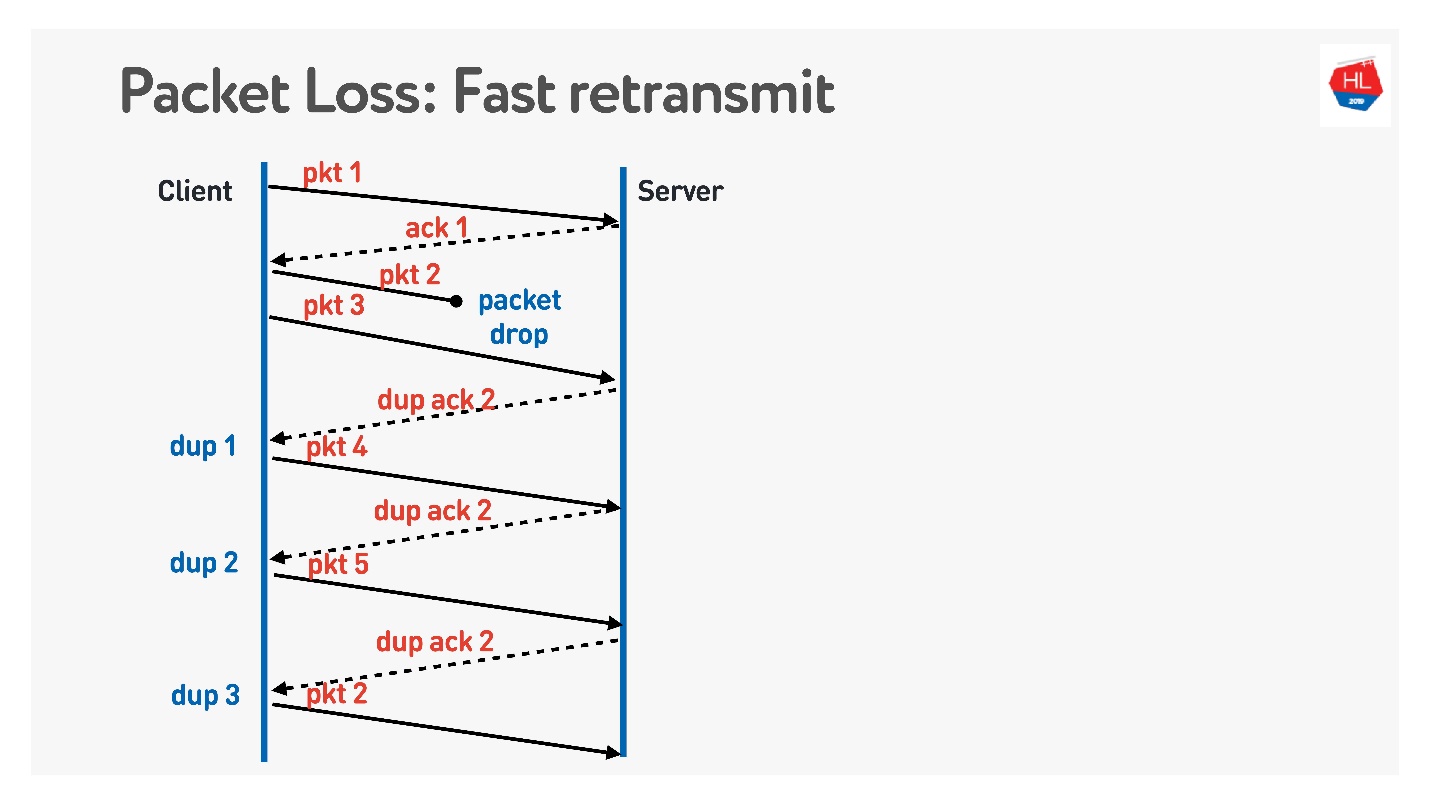
Lorsque le paquet est parti, nous continuons d'envoyer - il y a une transmission d'autres paquets. À ce moment, le serveur dit qu'il a reçu le prochain paquet, mais il n'y en avait pas de précédent. Pour ce faire, il émet un accusé de réception délicat, qui est égal au numéro de package + 1, et définit l'indicateur d'ack en double. Il envoie ces duk ack ainsi, et le troisième, nous comprenons généralement que le paquet a disparu et nous le renvoyons.
Que voulez-vous faire d'autre de classe, ce qui n'est pas dans TCP et ce qu'ils proposent de faire dans UDP est la
correction d'erreur directe .

Il semble que si nous savons que des packages peuvent être perdus, nous pouvons prendre un ensemble de packages, y ajouter un package XOR et résoudre le problème sans retransmissions supplémentaires immédiatement sur le client lors de la réception de données. Mais il y a un problème si plusieurs packages disparaissent. Il semble que cela peut être résolu grâce à la protection de la parité, Reed-Solomon, etc.
Nous l'avons essayé de cette façon, il s'est avéré qu'en fait les paquets disparaissent en paquets.
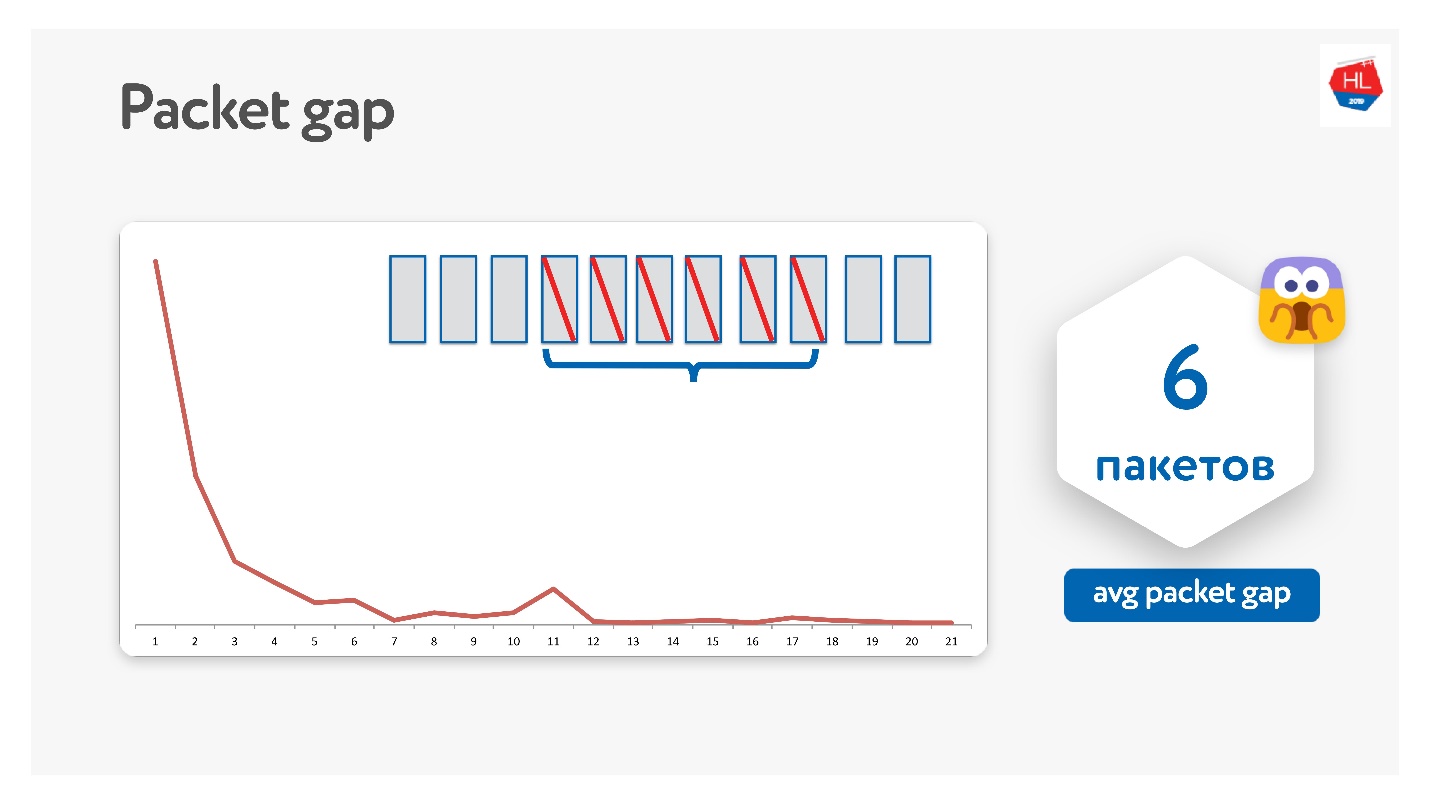
L'écart de paquet moyen s'est avéré être de 6. Il s'agit d'un écart de paquet très gênant - vous avez besoin de beaucoup de codes de correction d'erreur. Dans le même temps, il y a une sorte de pic à 11 - je ne sais pas pourquoi, mais les paquets disparaissent parfois en paquets de 11. En raison de cet écart de paquets, cela ne fonctionne pas.
Google a également essayé, tout le monde rêve de FEC, mais jusqu'à présent, personne n'a travaillé.
Il existe une autre option lorsque la FEC peut vous aider.

En plus de la retransmission via Retransmit Time Out, Fast Retransmit, il existe également une
sonde de perte de queue . C'est une telle chose lorsque vous envoyez des données, et la queue est partie. Autrement dit, vous avez envoyé une partie des données, envoyé le cinquième paquet - il est arrivé. Ensuite, les paquets ont commencé à disparaître, par exemple, en raison de la défaillance du réseau. Les paquets disparaissent, disparaissent et vous avez reçu un accusé de réception uniquement pour le cinquième paquet.
Pour comprendre si ces données ont atteint, après un certain temps, vous commencez à faire TLP (sonde de perte de queue), demandez si la fin est reçue. Le fait est que le transfert de données est terminé et que vous n'envoyez rien, alors la retransmission rapide ne fonctionnera pas. Pour résoudre ce problème, effectuez un TLP.
Vous pouvez ajouter FEC aux TLP. Vous pouvez regarder tous les paquets qui ne sont pas arrivés, compter la parité sur eux et envoyer des TLP avec un paquet de parité.
Tout cela est cool, cela semble fonctionner. Mais il y a un tel problème.
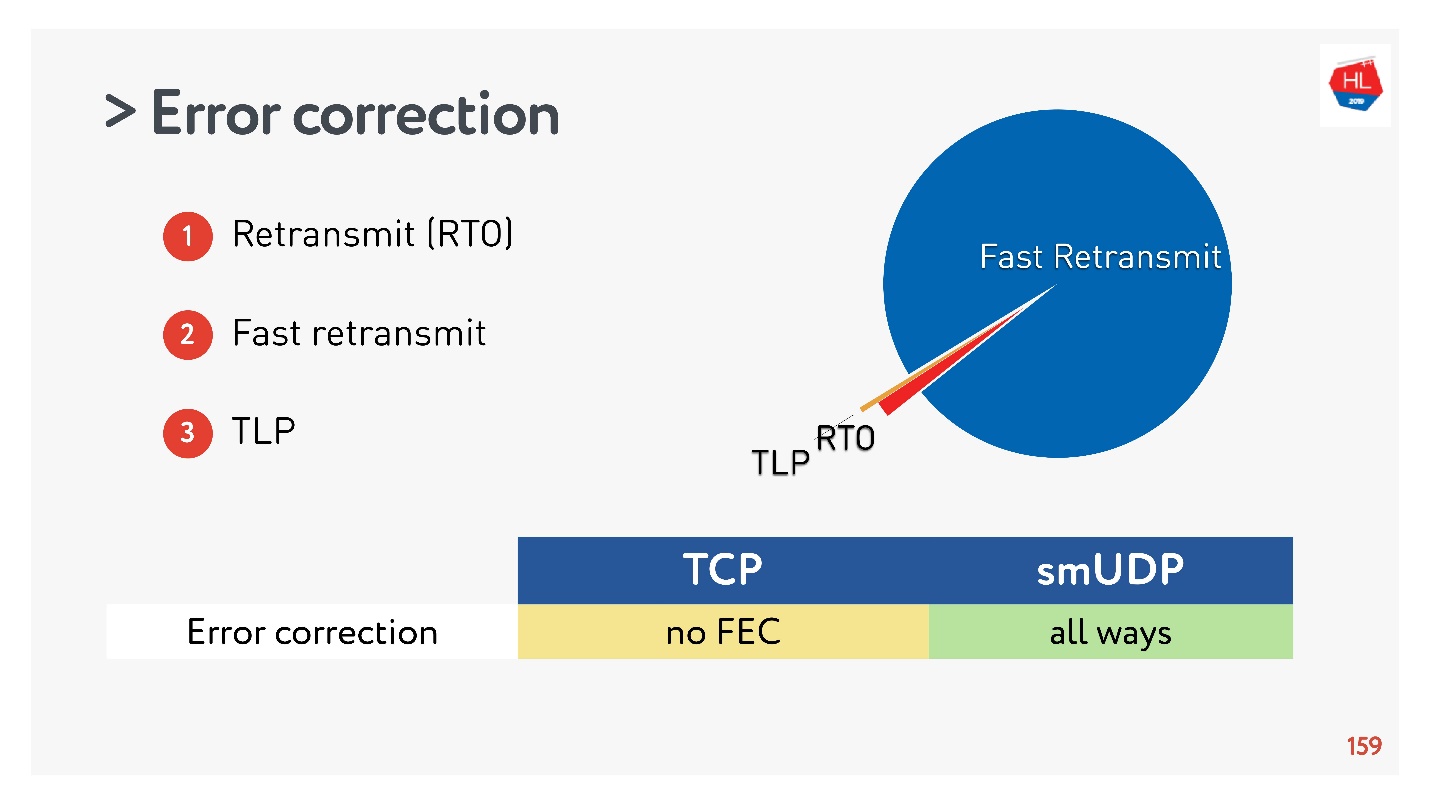
Nous avons collecté des statistiques et il s'est avéré que 98% des erreurs sont réparées par Fast Retransmit. Le reste est réparé via Retransmit Time Out et moins de 1% via TLP. Si vous corrigez quelque chose d'autre FEC, il sera inférieur à 0,5%.
TCP ne prend pas en charge FEC. En UDP, ce n'est pas difficile à faire, mais dans le cas général, les algorithmes de récupération TCP standard suffisent.
Performances
Il serait possible de ne pas nuire aux performances en comparant TCP avec UDP.
TCP est un protocole très ancien avec beaucoup d'optimisations différentes, par exemple LSO (déchargement de gros segments) et zerocopy. Maintenant, pour UDP, tout n'est pas disponible. Par conséquent, les performances UDP ne sont que de 20% par rapport à TCP à partir des mêmes serveurs. Mais il existe déjà des solutions toutes faites (
UDP GSO ,
zerocopy ) qui permettent à Linux de supporter cela.
Le principal problème de prise en charge de l'optimisation pour la zérocopie et le LSO est que la stimulation est perdue.

Temps de commercialisation ou ce qui a tué TCP
Récemment, lorsque les réseaux sans fil mobiles sont devenus populaires, de nombreuses normes TCP différentes sont apparues: TLP, TFO, nouveau contrôle de congestion, RACK, BBR et plus encore.

Mais le principal problème est que beaucoup d'entre eux ne sont pas mis en œuvre, car TCP serait ossifié. Dans de nombreux cas, les opérateurs regardent les paquets TCP et s'attendent à voir ce qu'ils attendent. Par conséquent, il est très difficile de changer.
De plus, les clients mobiles sont mis à jour depuis longtemps et nous ne pouvons pas fournir ces mises à jour. Si vous regardez quelles sont les dernières mises à jour récentes disponibles sur le client et ce qui se trouve sur le serveur, vous pouvez dire qu'il n'y a presque rien sur le client.
Par conséquent, la décision d'écrire un protocole dans l'espace utilisateur, au moins tant que vous accumulez toutes ces fonctionnalités, ne semble pas si mauvaise.

Avec TCP, les fonctionnalités évoluent depuis des années. Pour votre protocole UDP, vous pouvez mettre à jour la version littéralement en une seule mise à jour du client et du serveur. Mais vous devrez ajouter la négociation de version.
TCP vs UDP autodidacte. Combats finaux
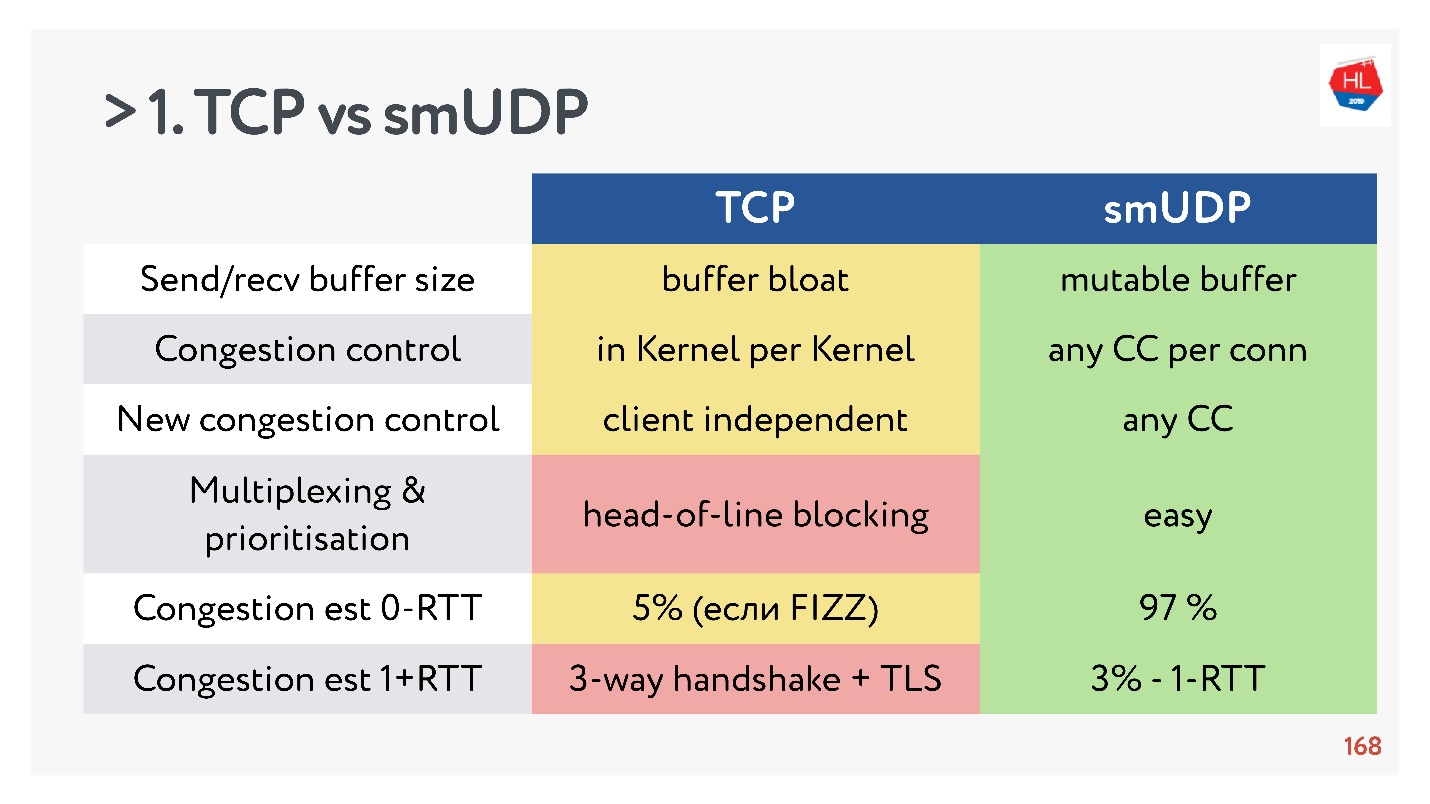
- Send / recv buffer: un tampon mutable peut être fait pour votre protocole, il y aura des problèmes avec le ballonnement du tampon avec TCP.
- Contrôle de congestion, vous pouvez utiliser l'existant. Chez UDP, il y en a.
- Le nouveau contrôle d'encombrement est difficile à ajouter à TCP, car vous devez modifier l'accusé de réception, vous ne pouvez pas le faire sur le client.
- Le multiplexage est un problème critique. Le blocage en tête de ligne se produit, lorsque vous perdez un paquet, vous ne pouvez pas multiplexer vers TCP. Par conséquent, HTTP2.0 sur TCP ne devrait pas augmenter sérieusement.
- Les cas où vous pouvez obtenir une configuration de connexion pour 0-RTT en TCP sont extrêmement rares, de l'ordre de 5% et de l'ordre de 97% pour l'UDP self-made.

- La migration IP n'est pas une fonctionnalité aussi importante, mais dans le cas d'abonnements complexes et de l'état de stockage sur le serveur, elle est absolument nécessaire, mais elle n'est pas implémentée dans TCP.
- La dissociation de Nat n'est pas en faveur de l'UDP. Dans ce cas, UDP a souvent besoin de faire des paquets de ping-pong.
- La stimulation de paquets dans UDP est simple, bien qu'il n'y ait pas d'optimisation, dans TCP cette option ne fonctionne pas.
- MTU et correction d'erreur sont tous deux comparables.
- La vitesse de TCP, bien sûr, est plus rapide que UDP maintenant, si vous distribuez une tonne de trafic. Mais alors certaines optimisations prennent beaucoup de temps à livrer.
Si vous collectez tous les éléments les plus importants, alors UDP, plus probablement, a plus d'avantages que d'inconvénients.
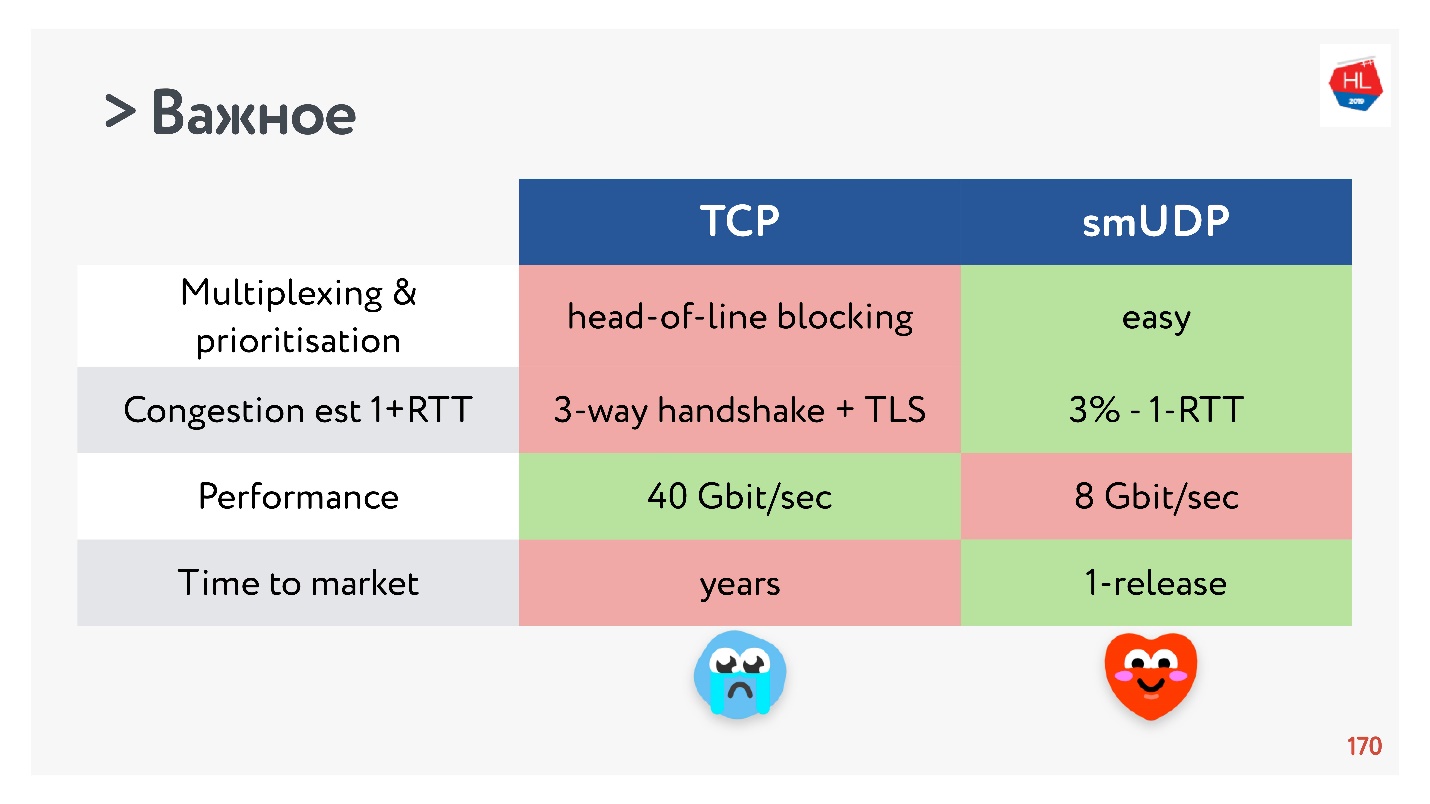 Choisissez UDP!
Choisissez UDP!Test UDP self-made sur les utilisateurs
Nous avons mis en place un banc d'essai.
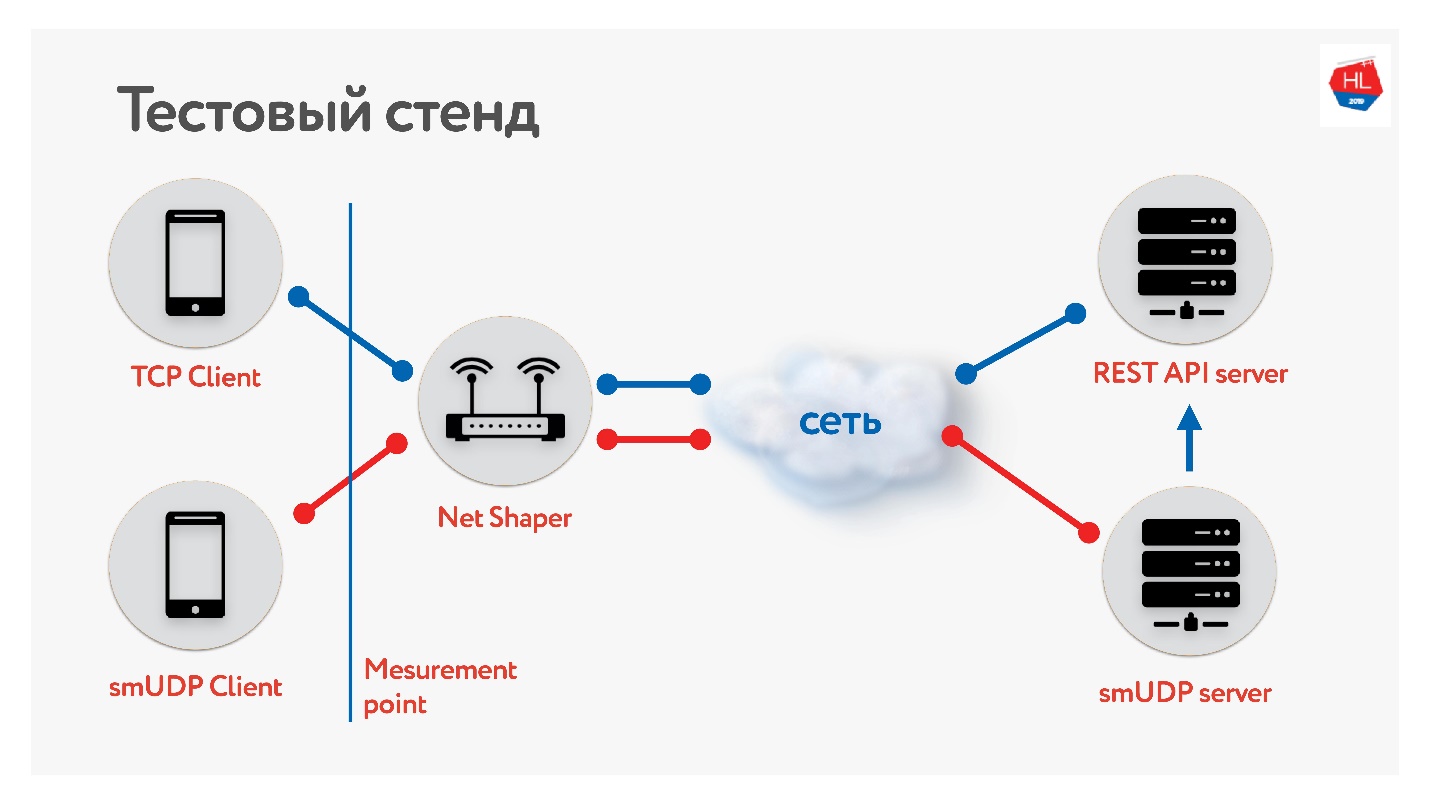
Il existe un client sur TCP et UDP. Nous avons normalisé le trafic via net shaper, envoyé à Internet et au serveur. Un service d'API REST, le second avec UDP. Et UDP va vers la même API REST dans le même centre de données pour vérifier les données. Nous avons collecté différents profils de nos clients mobiles et
lancé le test .

En mesurant la moyenne sur le portail, nous avons vu que nous pouvions réduire le temps d'appel de l'API de 10%, les images de 7%. L'activité des utilisateurs n'a augmenté que de 1%, mais nous n'abandonnons pas, nous pensons que ce sera mieux.

En termes de charges, nous avons maintenant environ 10 millions d'utilisateurs sur notre UDP self-made, un trafic jusqu'à 80 Gb / s, 6 millions de paquets par seconde et 20 serveurs tous servent cela.
Liste de contrôle UDP
Si vous écrivez votre protocole, vous avez besoin d'une liste de contrôle:
- Stimulation
- Découverte du MTU.
- Corrections de bugs requises .
- Contrôle de flux et contrôle de congestion.
- En option, vous pouvez prendre en charge la migration IP, TLP est facile.
N'oubliez pas que les canaux sont asymétriques et que pendant que vous recevez des données du serveur, votre téléchargement peut être inactif, essayez de l'utiliser.
QUIC
Il serait malhonnête de dire que Google ne l'a pas fait.

Il existe un protocole QUIC que Google a implémenté sous HTTP 2.0, qui prend en charge à peu près la même chose.
Pourquoi QUIC n'est pas si rapide
Quand QUIC est sorti, il y avait beaucoup de haine à propos du fait que Google dit que tout fonctionne plus vite, et "je l'ai mesuré à la maison sur un ordinateur - ça marche plus lentement."

Cet
article a un tas d'images et de mesures.
Eh bien, il s'avère que nous avons fait tout cela en vain, les gens ont-ils mesuré pour nous? Il existe de réelles mesures à domicile, même avec des exemples de code.

En fait, il n'y aura aucune amélioration tant que vous ne paralléliserez pas les demandes, ne travaillerez pas sur des réseaux réels et jusqu'à ce que les pertes de paquets soient divisées en perte de congestion et perte aléatoire. Nous avons besoin d'une véritable émulation d'un vrai réseau.
Mais il y a un point positif, disent-ils, QUIC n'est ni meilleur ni pire. Ainsi, dans des réseaux parfaits, QUIC fonctionne bien.
Le futur
Google a récemment nommé HTTP 2.0 au-dessus de QUIC HTTP 3, à ne pas confondre, car HTTP 2.0 pourrait être au-dessus de TCP et au-dessus de QUIC. Maintenant, c'est HTTP 3.
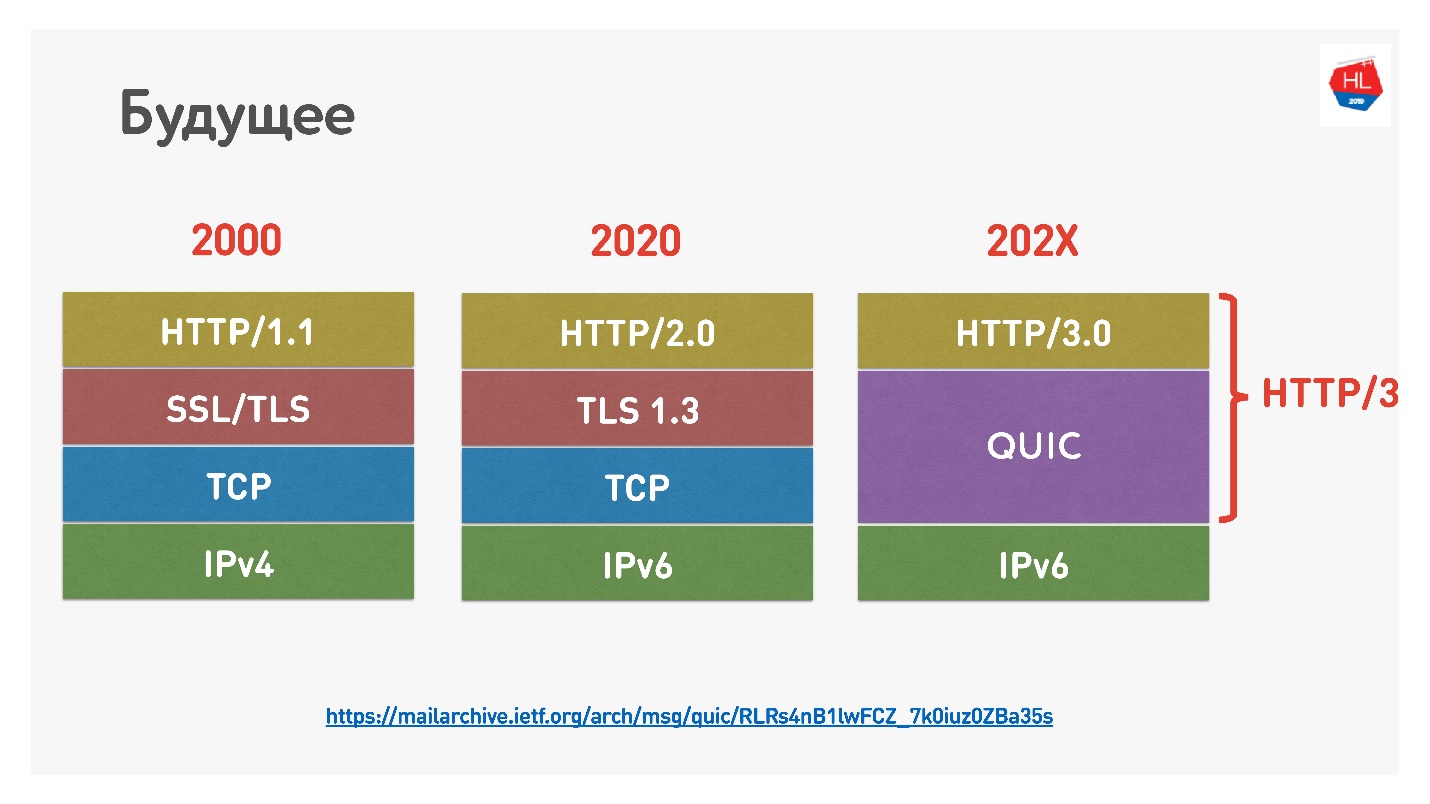
Il y avait aussi
Google QUIC - c'est QUIC, qui est implémenté dans Chrome, et iQUIC - un QUIC standardisé. Le QUIC standardisé n'a été implémenté nulle part, les serveurs iQUIC standard n'ont pas pris de contact avec Google QUIC. Maintenant, ils promettent de résoudre ce problème, et bientôt il sera disponible.
QUIC est partout
Si vous ne croyez toujours pas que TCP est mort, je vous dirai que lorsque vous utilisez Chrome, Android et bientôt iOS et que vous allez sur Google, YouTube, etc., vous utilisez QUIC et UDP (
prooflink ).
QUIC c'est maintenant :
- 1,9% de tous les sites Web;
- 12% de tout le trafic;
- 30% du trafic vidéo sur les réseaux mobiles.
Comment vérifier que vous utilisez QUIC si vous n'y croyez pas? Ouvrez dans Chrome Wireshark. Je cherchais iQUIC, je ne l'ai trouvé nulle part, mais GQUIC arrive.
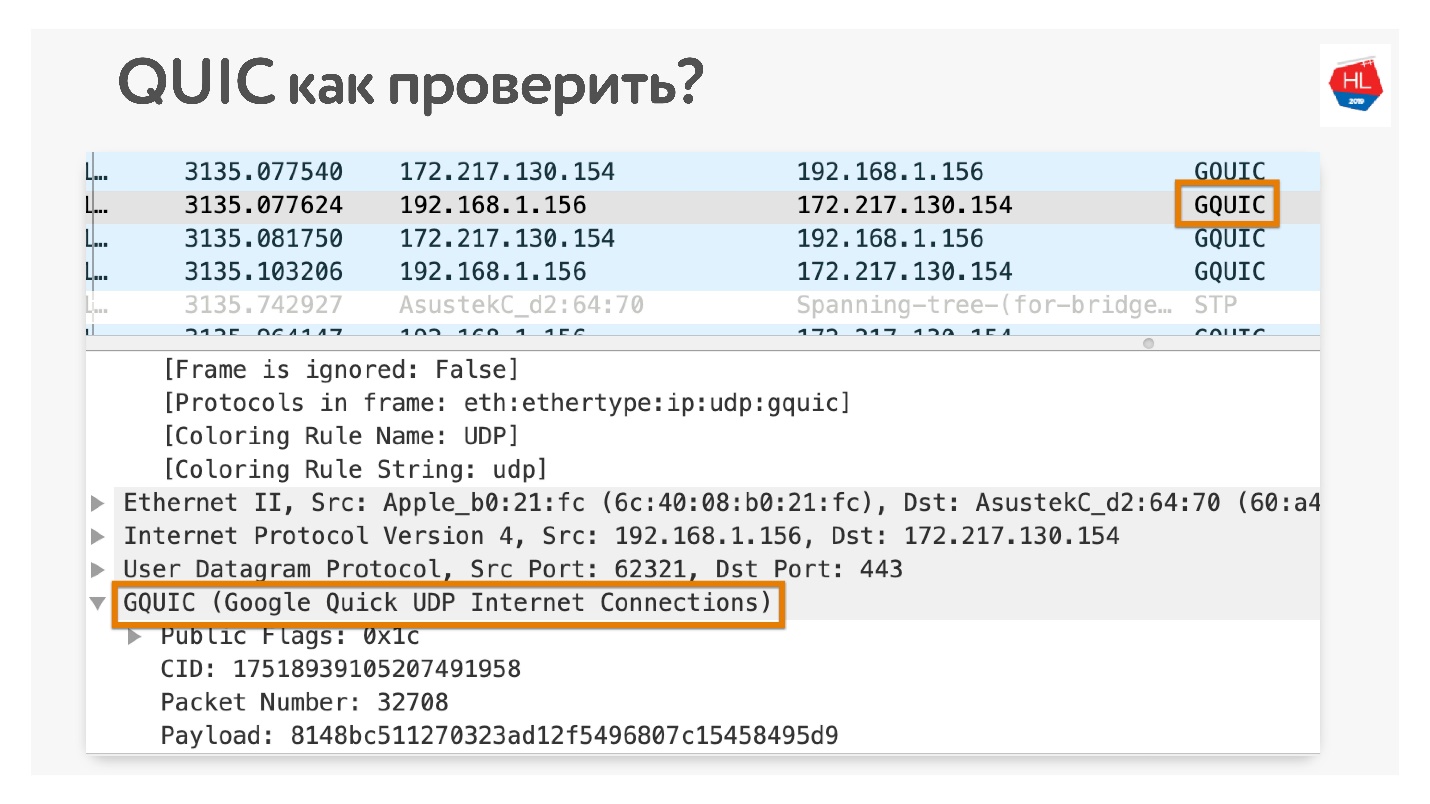
Vous pouvez également aller en ligne dans votre navigateur et également voir ce que GQUIC est là.

Un peu plus d'avenir
Multipath nous attend bientôt.
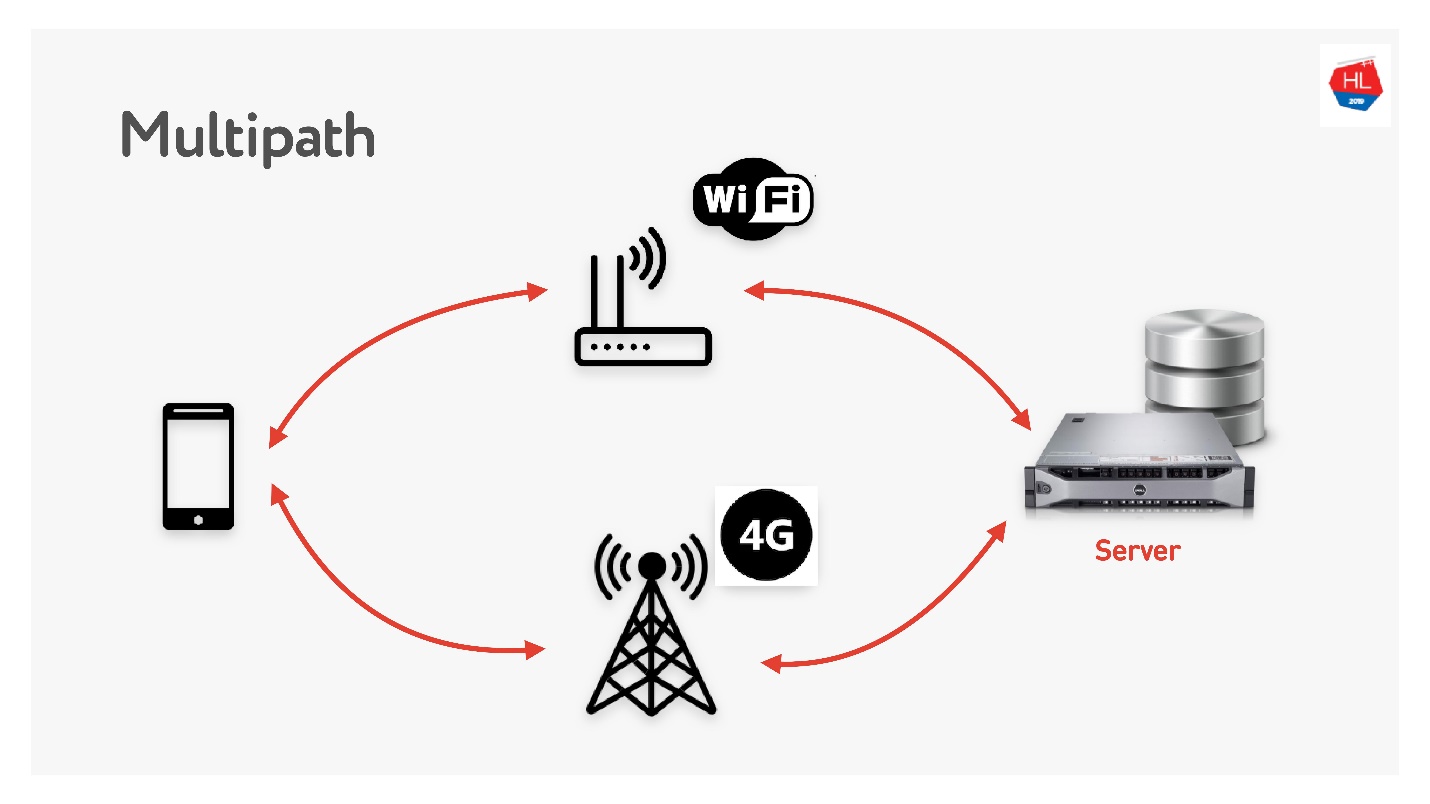
Lorsque vous avez un client mobile disposant à la fois du Wi-Fi et de la 3G, vous pouvez utiliser les deux canaux. Multipath TCP est en cours de développement et sera bientôt disponible dans le noyau Linux. Évidemment, cela n'atteindra pas les clients bientôt, je pense que cela peut être fait sur UDP beaucoup plus rapidement.
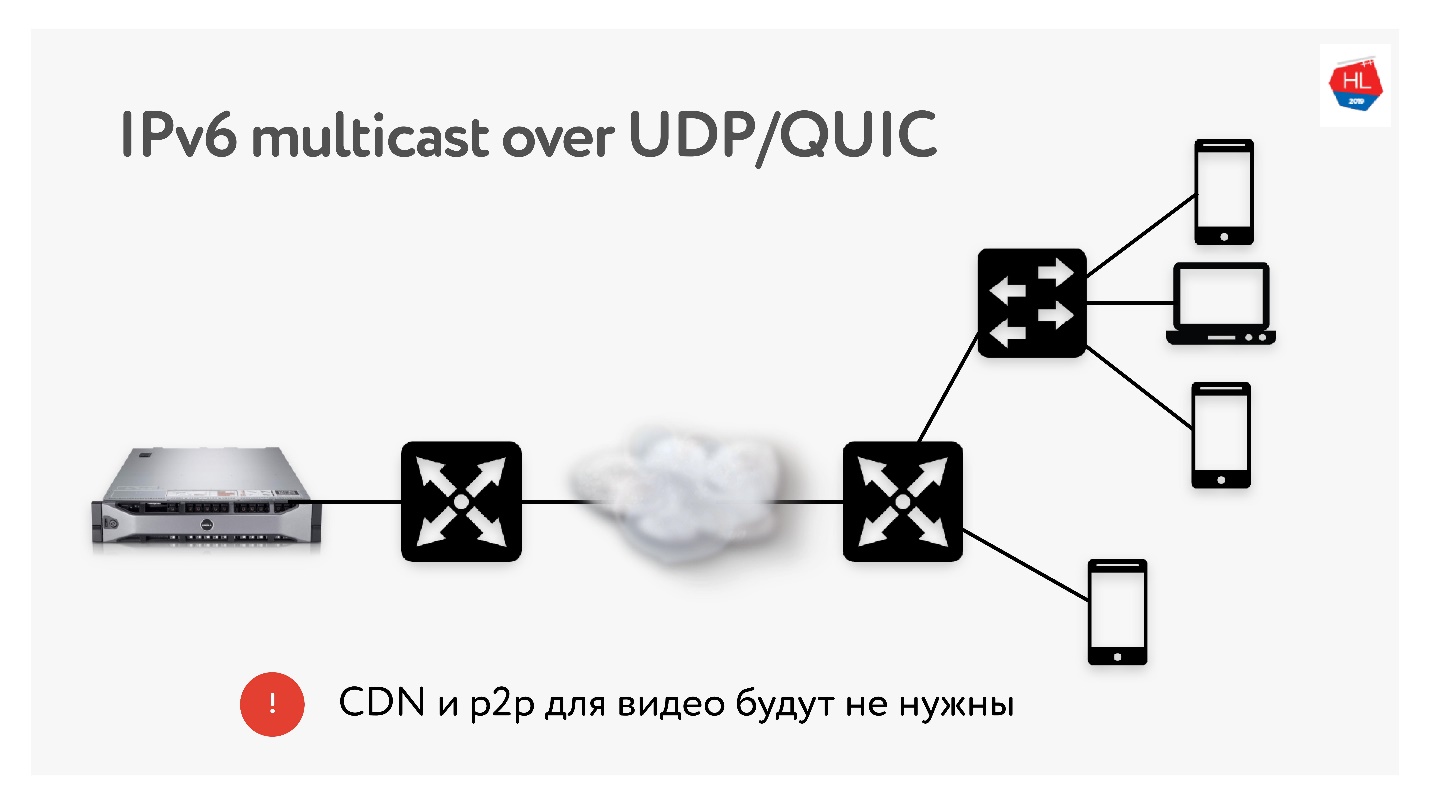
Étant donné que nous effectuons beaucoup de traductions de 3 To chacune, nous utilisons très souvent des technologies telles que la distribution CDN et p2p, lorsque le même contenu doit être fourni à de nombreux utilisateurs à travers le monde.
En IPv6, il existe une multidiffusion avec UDP, qui permettra de livrer des paquets à plusieurs utilisateurs abonnés à la fois. Par conséquent, je pense que les technologies CDN et p2p ne seront pas nécessaires dans un avenir proche si nous livrons tout le contenu en utilisant la multidiffusion sur IPv6.
Conclusions
J'espère que vous comprenez:
- Comment le réseau fonctionne vraiment et que TCP peut être répété sur UDP et mieux fait.
- Ce TCP n'est pas si mal si vous le configurez correctement, mais il a vraiment abandonné et ne se développe presque plus.
- Ne faites pas confiance aux ennemis de UDP qui disent qu'ils ne travailleront pas dans l'espace utilisateur. Tous ces problèmes peuvent être résolus. Essayez-le - c'est le futur proche.
- Si vous ne le croyez pas, vous pouvez et devez toucher le réseau avec vos mains. J'ai montré comment presque tout peut être vérifié.
Vous avez tout lu et compris quoi ensuite?
- Configurez le protocole (TCP, UDP - peu importe) pour la situation (profil réseau + profil de charge).
- Utilisez les recettes TCP que je vous ai dites: TFO, tampon d'envoi / recv, TLS1.3, CC ...
- Faites vos protocoles UDP si vous avez les ressources.
- Si vous avez fait votre UDP, vérifiez dans la liste de contrôle UDP que vous avez fait tout ce dont vous avez besoin. Oublier tout non-sens comme la stimulation, cela ne fonctionnera pas.
Si vous n'avez pas les ressources, préparez votre infrastructure pour QUIC. Tôt ou tard, il viendra vers vous.
Nous déterminons l'avenir. Nous décidons quels protocoles utiliser. Si vous voulez utiliser QUIC - utilisez-le, si vous voulez votre UDP ou restez sur TCP - décidez de l'avenir vous-même.
Liens utiles
Jusqu'au 7 septembre, vous pouvez toujours soumettre une demande pour Moscou HighLoad ++ et partager comment vous préparez vos services pour des charges élevées. Mais le programme se remplit déjà progressivement, d'après Odnoklassniki, des rapports ont été reçus sur la nouvelle architecture du graphique d'amis, sur l' optimisation du service de cadeaux pour des charges élevées et sur ce qu'il faut faire si vous avez tout optimisé et que les données n'atteignent pas l'utilisateur assez rapidement.