La première tâche la plus souvent rencontrée par les développeurs qui commencent à programmer en JavaScript est de consigner les événements dans le journal de la console à l'aide de la méthode
console.log . À la recherche d'informations sur le débogage du code JavaScript, vous trouverez des centaines d'articles de blog, ainsi que des instructions sur StackOverflow, vous conseillant de «simplement» sortir des données vers la console via la méthode
console.log . C'est une telle pratique courante que j'ai dû introduire des règles pour le contrôle de la qualité du code, comme
no-console , afin de ne pas laisser des entrées de journal aléatoires dans le code de production. Mais que se passe-t-il si vous devez enregistrer spécifiquement un événement pour fournir des informations supplémentaires?
Cet article décrit diverses situations dans lesquelles vous devez conserver des journaux; Il montre la différence entre les méthodes
console.log et
console.error dans Node.js et montre comment passer la fonction de journalisation aux bibliothèques sans surcharger la console utilisateur.

Fondements théoriques de l'utilisation de Node.js
Les méthodes
console.log et
console.error peuvent être utilisées à la fois dans le navigateur et dans Node.js. Cependant, lorsque vous utilisez Node.js, il y a une chose importante à retenir. Si vous créez le code suivant dans Node.js à l'aide d'un fichier appelé
index.js ,

puis l'exécuter dans le terminal en utilisant le
node index.js , puis les résultats de l'exécution de la commande seront situés l'un au-dessus de l'autre:

Malgré le fait qu'ils semblent similaires, le système les traite différemment. Si vous regardez la section sur le fonctionnement de la
console dans la
documentation Node.js , il s'avère que
console.log imprime le résultat via
stdout et
console.error imprime via
stderr .
Chaque processus peut fonctionner avec trois flux (
stream ) par défaut:
stdin ,
stdout et
stderr . Le flux
stdin traite l'entrée pour un processus, par exemple, les clics sur les boutons ou la sortie redirigée (plus de détails ci-dessous). Le flux de sortie standard
stdout sert à la sortie des données d'application. Enfin, le flux d'erreurs
stderr standard est conçu pour afficher des messages d'erreur. Si vous avez besoin de savoir à quoi
stderr et quand l'utiliser, lisez
cet article .
En bref, il peut être utilisé pour utiliser les opérateurs de redirection (
> ) et de pipeline (
| ) pour travailler avec les erreurs et les informations de diagnostic séparément des résultats réels de l'application. Si l'opérateur
> vous permet de rediriger la sortie du résultat de la commande vers un fichier, alors en utilisant l'opérateur
2> vous pouvez rediriger la sortie du flux d'erreurs
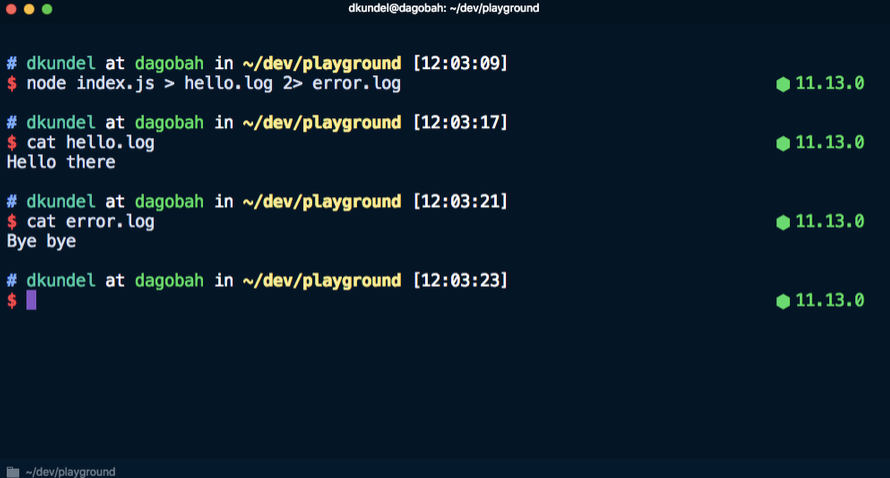
stderr vers un fichier. Par exemple, cette commande envoie
Hello dans le fichier
hello.log et
Bye bye dans le fichier
error.log .

Quand dois-je écrire des événements dans le journal?
Maintenant que nous avons passé en revue les aspects techniques qui sous-tendent la journalisation, passons à divers scénarios dans lesquels vous devez enregistrer des événements. En règle générale, ces scénarios se répartissent en plusieurs catégories:
Cet article ne traite que des trois derniers scénarios basés sur Node.js.
Journalisation des applications serveur
Il existe plusieurs raisons pour consigner les événements qui se produisent sur le serveur. Par exemple, la journalisation des demandes entrantes vous permet d'obtenir des statistiques sur la fréquence à laquelle les utilisateurs rencontrent des erreurs 404, quelle pourrait en être la raison ou quelle application cliente
User-Agent est utilisée. Vous pouvez également connaître l'heure à laquelle l'erreur s'est produite et sa cause.
Afin d'expérimenter avec le matériel donné dans cette partie de l'article, vous devez créer un nouveau catalogue pour le projet. Dans le répertoire du projet, créez
index.js pour le code à utiliser et exécutez les commandes suivantes pour démarrer le projet et installer
express :

Nous mettons en place un serveur avec middleware, qui enregistrera chaque requête dans la console en utilisant la méthode
console.log . Nous mettons les lignes suivantes dans le fichier
index.js :
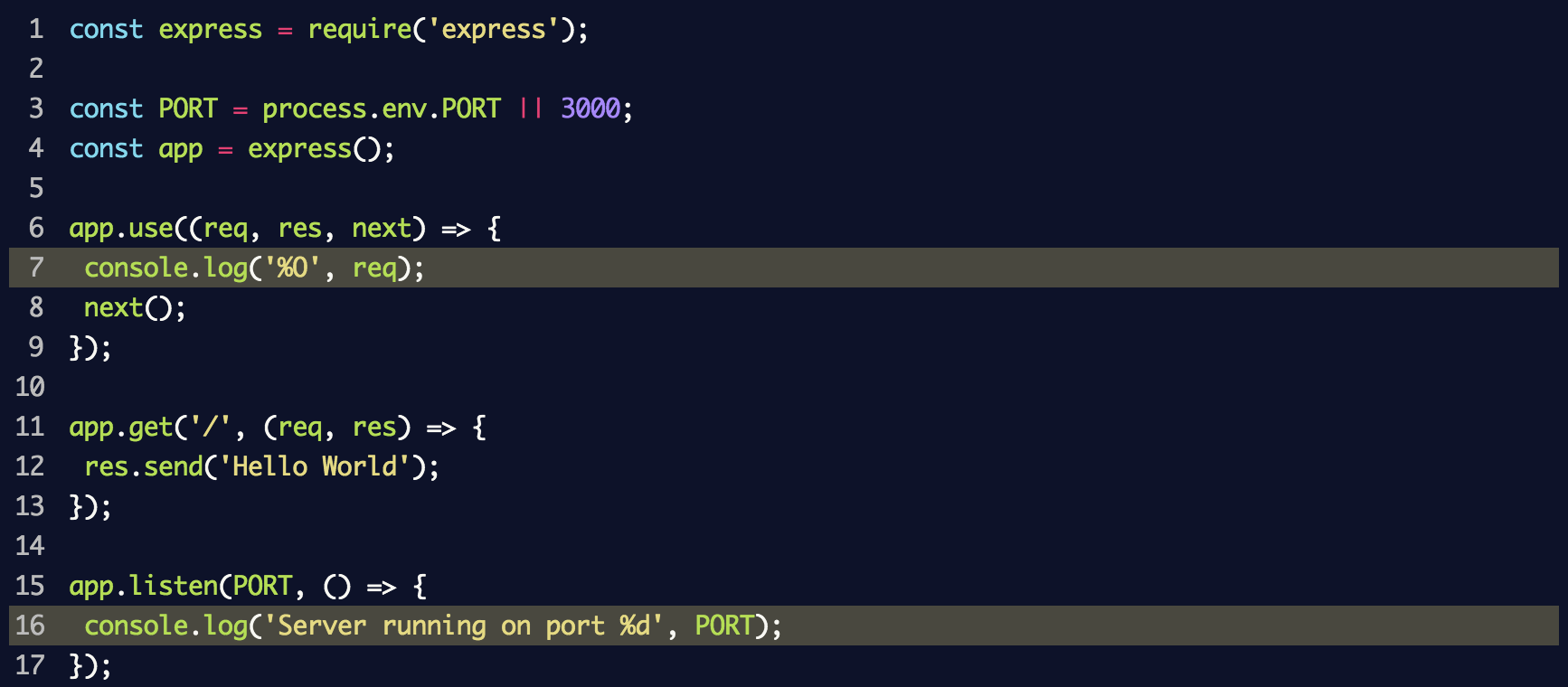
Cela utilise
console.log('%O', req) pour journaliser l'objet entier dans le journal. Du point de vue de la structure interne, la méthode
console.log utilise
util.forma t, qui, en plus de
%O prend en charge d'autres espaces réservés. Des informations à leur sujet peuvent être trouvées dans la
documentation Node.js.Lors de l'exécution du
node index.js pour démarrer le serveur et du passage à
localhost : 3000, la console affiche de nombreuses informations inutiles:
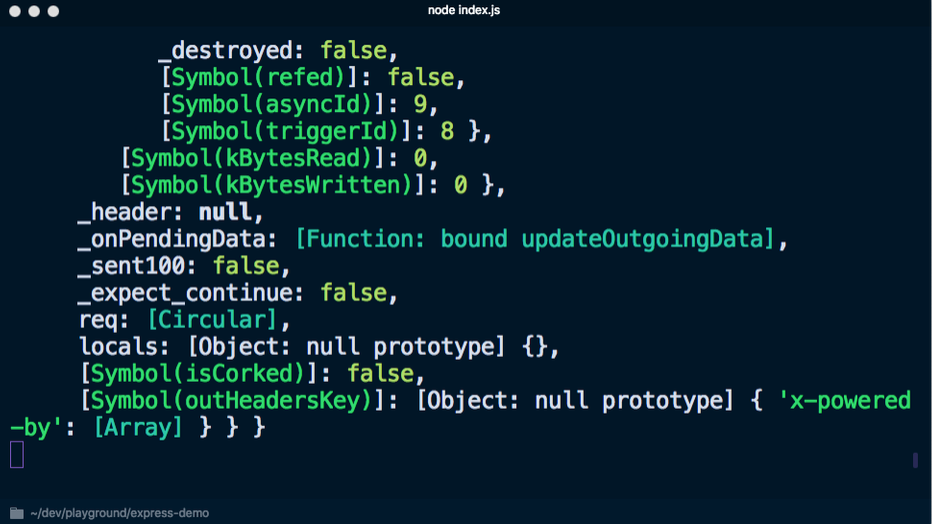
Si vous utilisez plutôt
console.log('%s', req) pour ne pas afficher complètement l’objet, vous n’obtiendrez pas beaucoup d’informations:
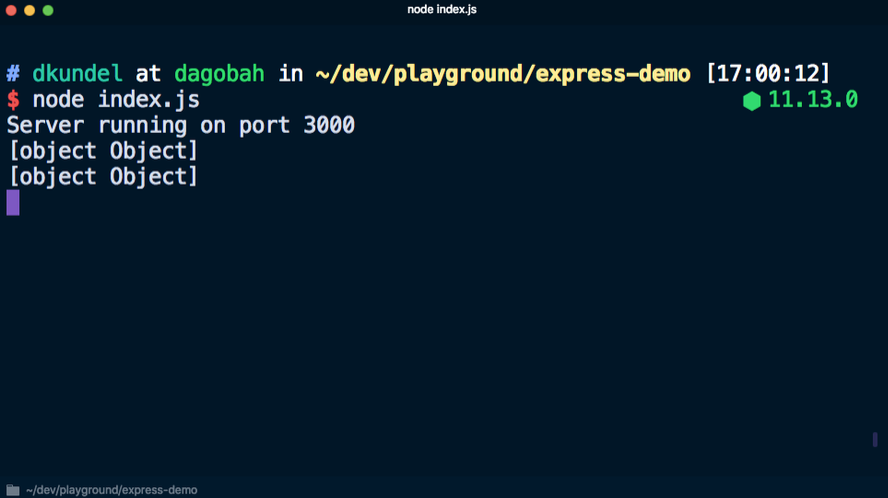
Vous pouvez écrire votre propre fonction de journalisation, qui ne produira que les données nécessaires, mais vous devez d'abord décider quelles informations sont nécessaires. Bien que l'accent soit généralement mis sur le contenu du message, en réalité, il est souvent nécessaire d'obtenir des informations supplémentaires, notamment:
- horodatage - pour savoir quand les événements se sont produits;
- nom de l'ordinateur / serveur - si un système distribué est en cours d'exécution;
- identificateur de processus - si plusieurs processus Node s'exécutent en utilisant, par exemple,
pm2 ; - message - un message réel avec un certain contenu;
- trace de pile - si une erreur est enregistrée;
- variables / informations supplémentaires.
De plus, étant donné que dans tous les cas, tout est
stderr flux
stdout et
stderr , il est nécessaire de conserver un journal à différents niveaux, ainsi que de configurer et de filtrer les entrées de journal en fonction du niveau.
Cela peut être réalisé en accédant à différentes parties du
process et en écrivant plusieurs lignes de code en JavaScript. Cependant, Node.js est remarquable en ce qu'il possède déjà un écosystème
npm et plusieurs bibliothèques qui peuvent être utilisées à ces fins. Cela comprend:
pino ;winston ;- roarr ;
- bunyan (cette bibliothèque n'a pas été mise à jour depuis deux ans).
Pino est souvent préféré car il est rapide et possède son propre écosystème. Voyons comment
pino peut aider à la journalisation. Un autre avantage de cette bibliothèque est le package
express-pino-logger , qui vous permet d'enregistrer des requêtes.
Installez
pino et
express-pino-logger :

Après cela, nous mettons à jour le fichier
index.js pour utiliser le
index.js des événements et le middleware:
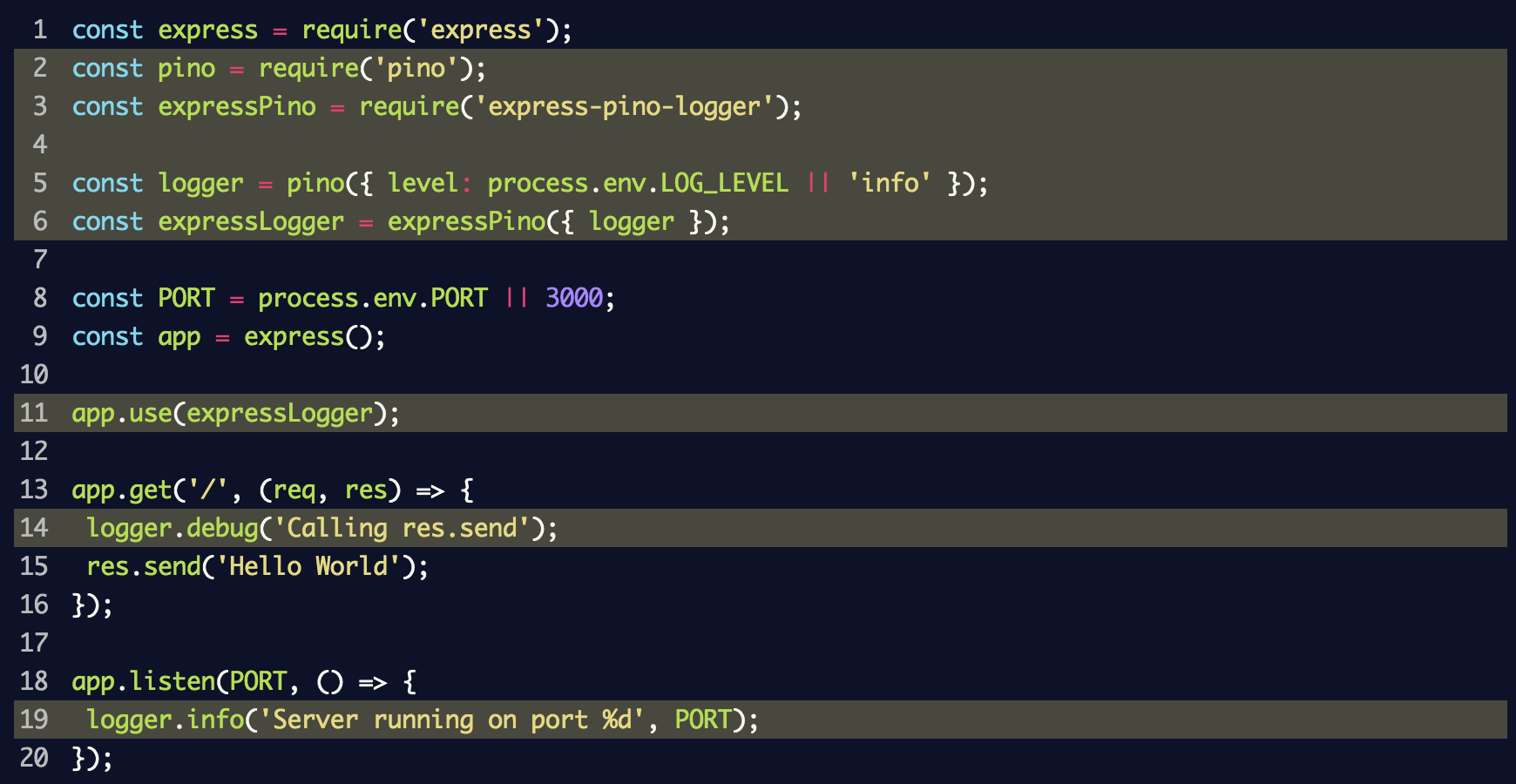
Dans ce fragment, nous avons créé une instance de l'
logger événements pour
pino et l'avons transmise à
express-pino-logger pour créer un nouveau logiciel de journalisation d'événements multiplateforme avec lequel vous pouvez appeler
app.use . De plus,
console.log remplacé dans
logger.info par
logger.info et
logger.debug ajouté à l'itinéraire pour afficher différents niveaux du journal.
Si vous redémarrez le serveur en exécutant à plusieurs reprises le
node index.js , vous obtiendrez un résultat différent à la sortie, dans lequel chaque ligne / ligne sera sortie au format JSON. Encore une fois, accédez à
localhost : 3000 pour voir une autre nouvelle ligne au format JSON.
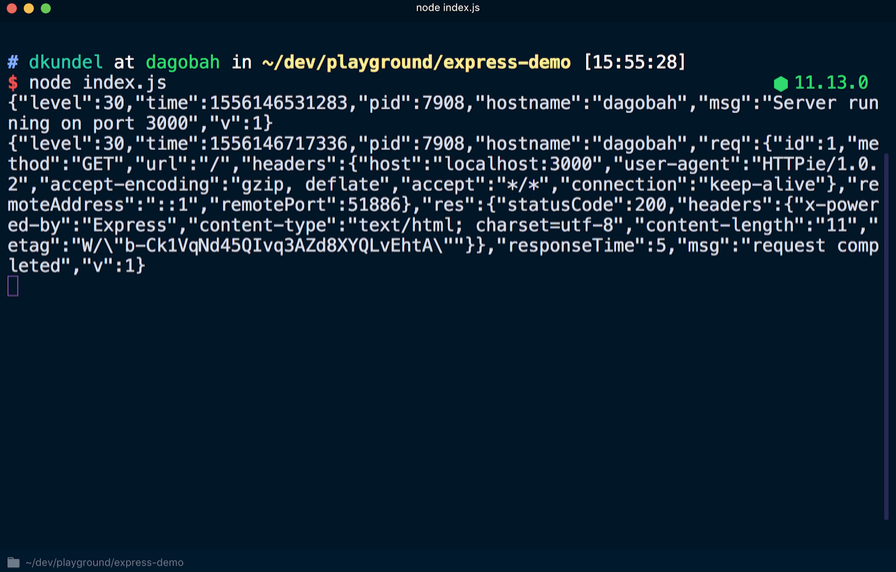
Parmi les données au format JSON, vous pouvez trouver les informations mentionnées précédemment, comme un horodatage. Notez également que le message
logger.debug pas affiché. Pour le rendre visible, vous devez modifier le niveau de journal par défaut. Après avoir créé une instance de l'enregistrement d'événement de l'enregistreur, la valeur
process.env.LOG_LEVEL été définie. Cela signifie que vous pouvez modifier la valeur ou accepter la valeur d'
info par défaut.
LOG_LEVEL=debug node index.js exécutant
LOG_LEVEL=debug node index.js , nous modifions le niveau de journalisation.
Avant de faire cela, il est nécessaire de résoudre le problème du format de sortie, ce qui n'est pas très pratique pour la perception pour le moment. Cette étape est intentionnelle. Selon la philosophie
pino , pour des raisons de performances, il est nécessaire de transférer le traitement des écritures de journal vers un processus distinct, en passant la sortie (à l'aide de l'opérateur
| ). Le processus consiste à traduire la sortie dans un format plus pratique pour la perception humaine, ou à la télécharger sur le cloud. Cette tâche est effectuée par des outils de transfert appelés
transports . Consultez la
documentation de la boîte à outils transports et voyez pourquoi les erreurs
pino ne sont pas sorties via
stderr .
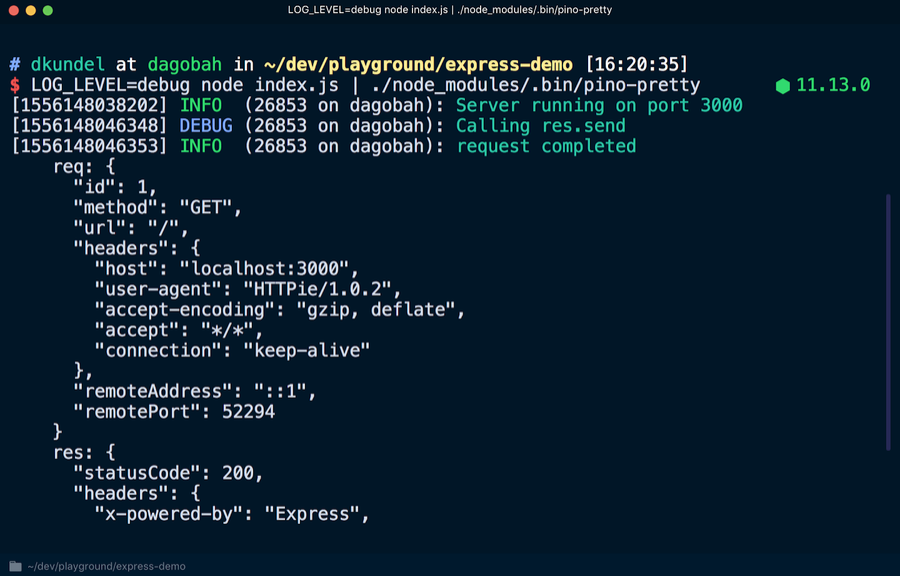
Pour afficher une version plus lisible du magazine, utilisez l'outil
pino-pretty . Exécutez dans le terminal:

Toutes les entrées de journal sont transférées à l'aide de la
| à la disposition de
pino-pretty , grâce à quoi la sortie est "effacée", qui ne contiendra que des informations importantes affichées dans différentes couleurs. Si vous interrogez à nouveau
localhost : 3000, un message de
debug débogage doit apparaître.
Afin de rendre les entrées de journal plus lisibles ou de les convertir, il existe de nombreux outils de transmission. Ils peuvent même être affichés en utilisant des emojis en utilisant
pino-colada . Ces outils seront utiles pour le développement local. Lorsque le serveur est en production, il peut être nécessaire de transférer les données du journal à l'aide d'
un autre outil , de les écrire sur le disque à l'aide de
> pour un traitement ultérieur, ou d'effectuer deux opérations en même temps à l'aide d'une commande spécifique, par exemple
tee .
Le
document traite également de la rotation des fichiers journaux, du filtrage et de l'écriture des données des journaux dans d'autres fichiers.
Journalisation de la bibliothèque
En explorant les moyens d'organiser efficacement la journalisation des applications serveur, vous pouvez utiliser la même technologie pour vos propres bibliothèques.
Le problème est que dans le cas de la bibliothèque, vous devrez peut-être conserver un journal à des fins de débogage sans charger l'application cliente. Au contraire, le client doit pouvoir activer le journal si le débogage est nécessaire. Par défaut, la bibliothèque ne doit pas enregistrer la sortie, ce qui donne à l'utilisateur ce droit.
Un bon exemple de ceci est le cadre
express . De nombreux processus se déroulent dans la structure interne du framework
express , ce qui peut susciter un intérêt à l'étudier plus en profondeur lors du débogage d'application. La
documentation du framework express indique que vous pouvez ajouter
DEBUG=express:* au début de la commande comme suit:

Si vous appliquez cette commande à une application existante, vous pouvez voir beaucoup de résultats supplémentaires qui aideront au débogage:
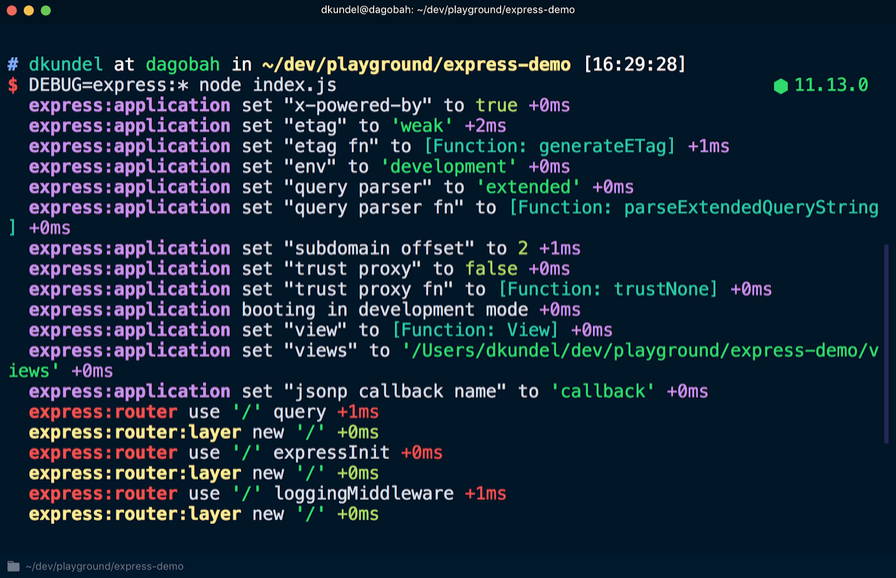
Ces informations ne sont visibles que si le journal de débogage est activé. Il existe un package de
debug pour cela. Il peut être utilisé pour écrire des messages dans «l'espace de noms», et si l'utilisateur de la bibliothèque inclut cet espace de noms ou un caractère générique qui lui correspond dans leur
variable d'environnement DEBUG , les messages seront affichés. Vous devez d'abord installer la bibliothèque de
debug :

Créez un nouveau fichier appelé
random-id.j s qui simulera la bibliothèque et y placera le code suivant:
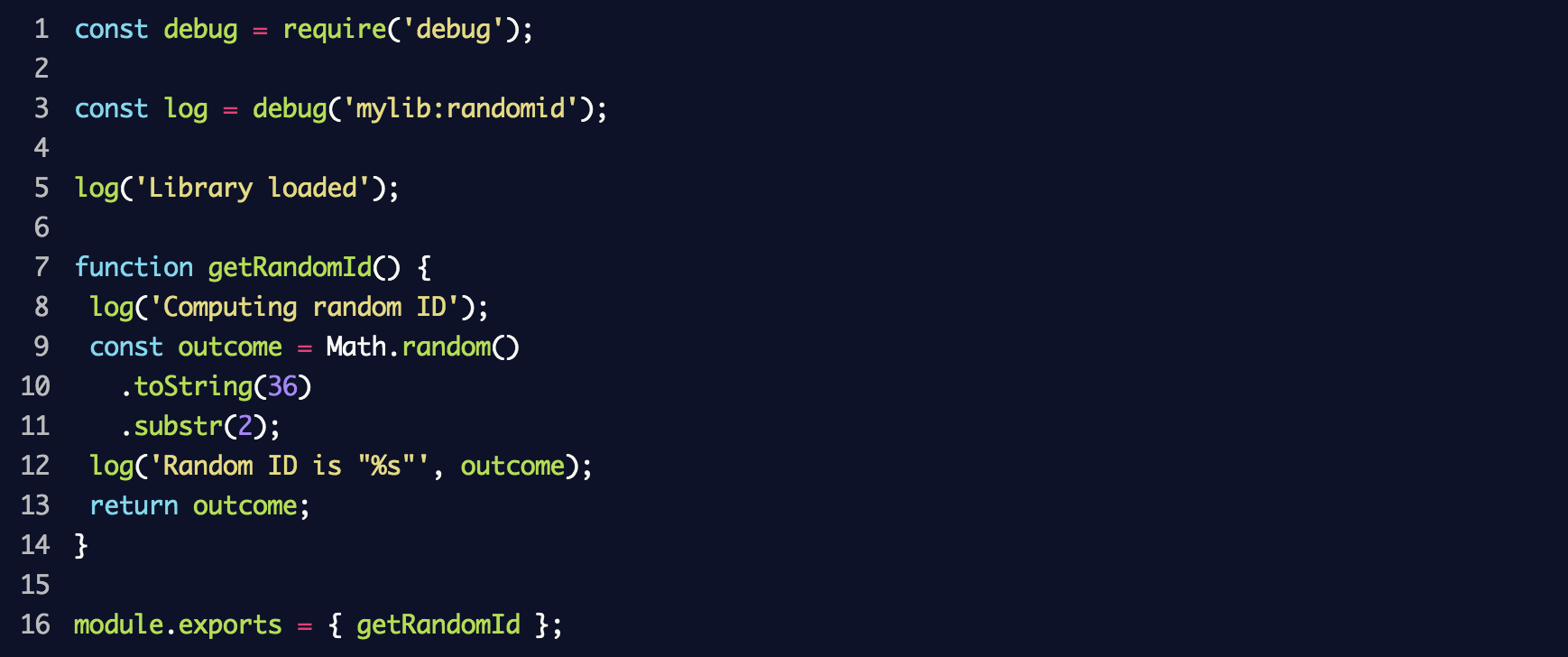
Par conséquent, un nouvel enregistreur d'événements de
debug sera créé avec l'
mylib:randomid , dans lequel deux messages seront ensuite enregistrés. Nous l'utilisons dans
index.js de la section précédente:
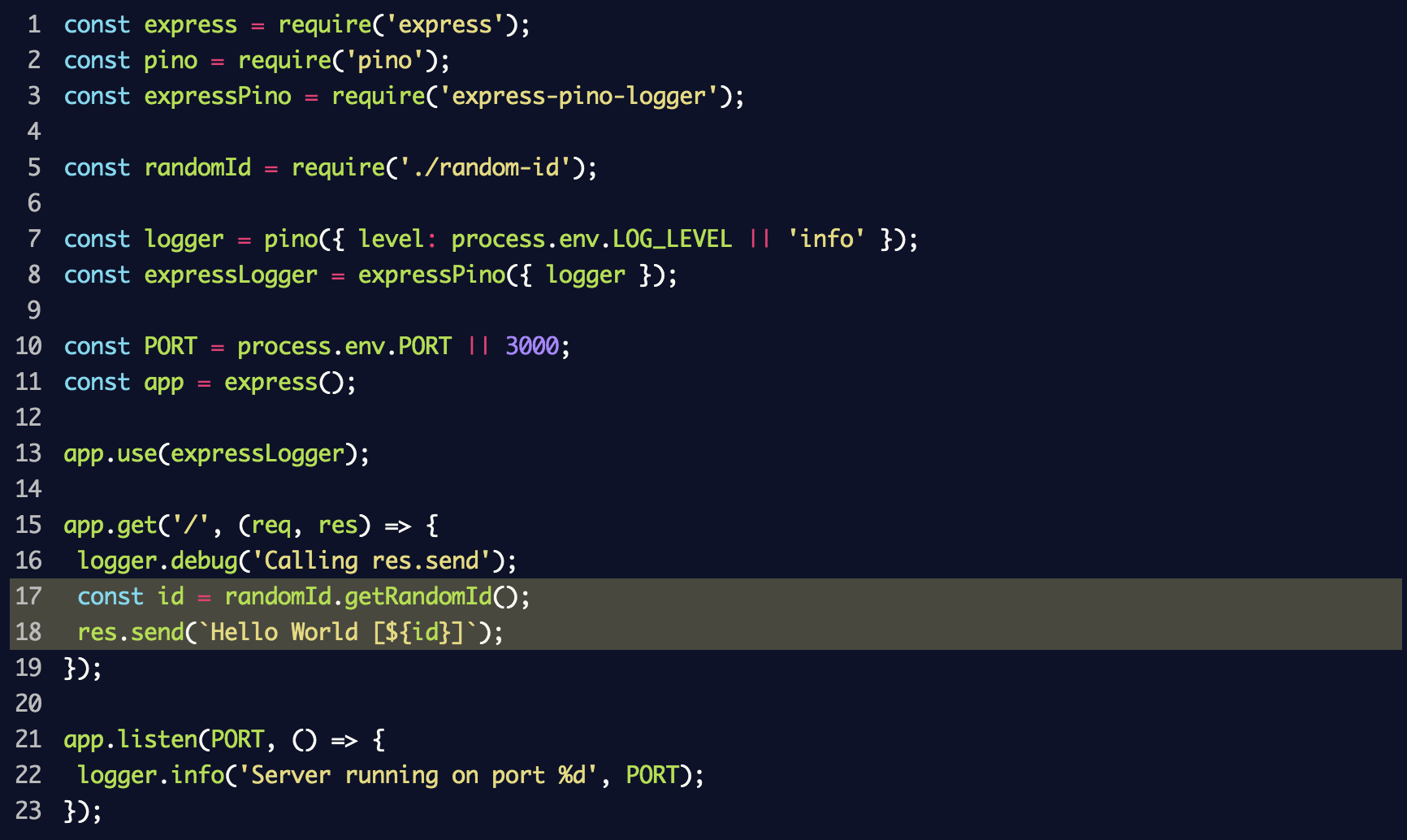
Si vous redémarrez le serveur, en ajoutant cette fois
DEBUG=mylib:randomid node index.js , les entrées du journal de débogage de notre "bibliothèque" seront affichées:
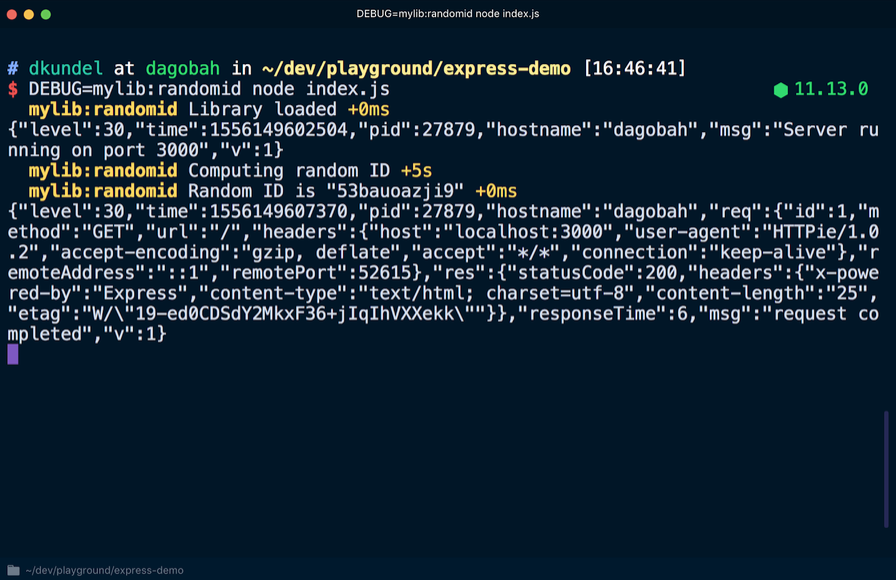
Si les utilisateurs de la bibliothèque souhaitent placer des informations de débogage dans les entrées du journal
pino , ils peuvent utiliser une bibliothèque appelée
pino-debug créée par la commande
pino pour formater correctement ces entrées.
Installez la bibliothèque:

Avant d'utiliser
debug pour la première fois,
pino-debug doit être initialisé. La façon la plus simple de le faire est d'utiliser les
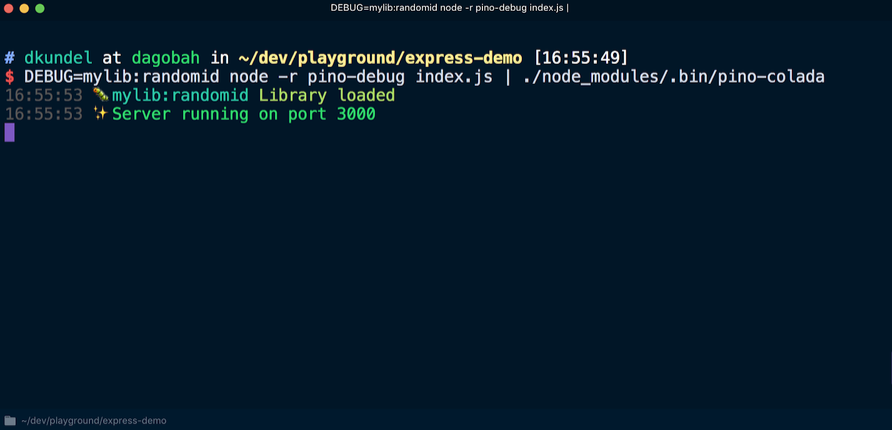
drapeaux -r ou --require pour demander un module avant d'exécuter le script. Nous redémarrons le serveur à l'aide de la commande (à condition que
pino-colada installé):

Par conséquent, les entrées du journal de débogage de la bibliothèque s'affichent de la même manière que dans le journal des applications:
Sortie de l'interface de ligne de commande (CLI)
Le dernier cas décrit dans cet article est la journalisation de l'interface de ligne de commande. De préférence, le journal qui enregistre les événements liés à la logique du programme est séparé du journal pour enregistrer les données d'interface de ligne de commande. Pour enregistrer tous les événements liés à la logique du programme, vous devez utiliser une bibliothèque spécifique, par exemple le
debug . Dans ce cas, vous pouvez réutiliser la logique du programme sans être limité à un scénario à l'aide de l'interface de ligne de commande.
En créant une interface de ligne de commande à l'aide de Node.js , vous pouvez ajouter différentes couleurs, des blocs de valeurs variables ou des outils de mise en forme pour donner à l'interface un aspect visuellement attrayant. Cependant, vous devez garder à l'esprit plusieurs scénarios.
Selon l'un d'eux, l'interface peut être utilisée dans le cadre d'un système d'intégration continue (CI), auquel cas il vaut mieux abandonner la mise en forme des couleurs et la présentation visuellement surchargée des résultats. Certains systèmes d'intégration continue ont l'indicateur
CI défini. Vous pouvez vérifier que vous êtes dans un système d'intégration continue à l'aide du package
is-ci , qui prend en charge plusieurs de ces systèmes.
Certaines bibliothèques, telles que
chalk , définissent des systèmes d'intégration continue et remplacent la sortie de texte en couleur vers la console. Voyons comment cela fonctionne.
Installez
chalk avec la
install chalk npm
install chalk et créez un fichier appelé
cli.js Mettez les lignes suivantes dans le fichier:

Maintenant, si vous exécutez ce script en utilisant le
node cli.js , les résultats seront présentés en utilisant différentes couleurs:
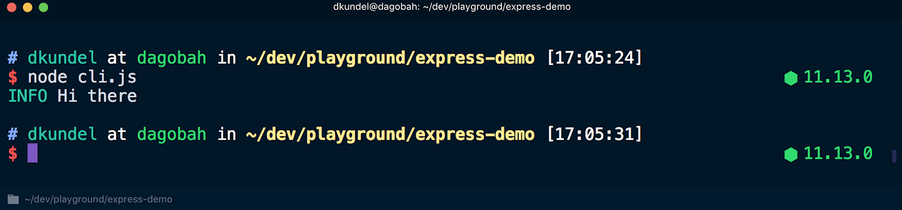
Mais si vous exécutez le script en utilisant
CI=true node cli.js , la mise en forme des couleurs des textes sera annulée:
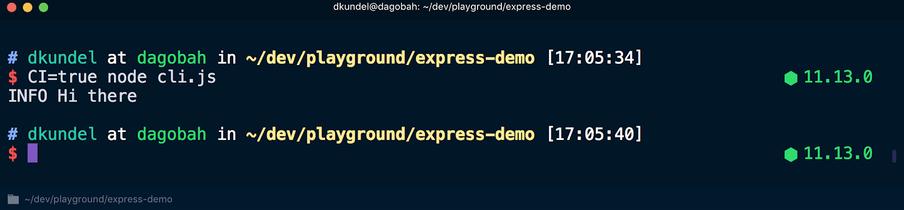
Dans un autre scénario à retenir,
stdout fonctionne en mode terminal, c'est-à-dire les données sont sorties vers le terminal. Dans ce cas, les résultats peuvent être bien affichés à l'aide de
boxen . Sinon, la sortie sera très probablement redirigée vers un fichier ou ailleurs.
Vous pouvez vérifier le fonctionnement des
stdin ,
stdout ou
stderr en mode terminal en regardant l'attribut
isTTY du flux correspondant. Par exemple,
process.stdout.isTTY .
TTY signifie "téléscripteur" et dans ce cas est conçu spécifiquement pour le terminal.
Les valeurs peuvent varier pour chacun des trois threads, selon la façon dont les processus Node.js ont été démarrés. Des informations détaillées à ce sujet peuvent être trouvées dans la
documentation Node.js, dans la section «Entrée / sortie des processus» .
Voyons comment la valeur de
process.stdout.isTTY varie dans différentes situations.
cli.js fichier
cli.js pour le vérifier:

Exécutez maintenant le
node cli.js dans le terminal et voyez le mot
true , après quoi le message s'affiche en police colorée:

Après cela, nous réexécutons la commande, mais redirige la sortie vers un fichier, puis affichons le contenu:

Cette fois, le mot
undefined est apparu dans le terminal, suivi d'un message affiché dans une police incolore, car le flux
stdout redirigé hors du mode terminal. Ici, la
chalk utilise l'outil
supports-color , qui du point de vue de la structure interne vérifie l'
isTTY flux correspondant.
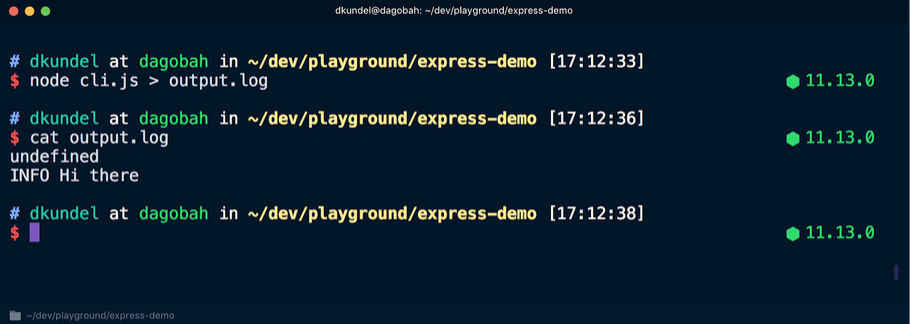
Des outils comme la
chalk font ces choses par eux-mêmes. Cependant, lors du développement d'une interface de ligne de commande, vous devez toujours être conscient des situations où l'interface fonctionne dans un système d'intégration continue ou la sortie est redirigée. Ces outils vous aident à utiliser l'interface de ligne de commande à un niveau supérieur. Par exemple, les données dans le terminal peuvent être organisées de manière plus structurée et si
isTTY n'est
undefined , passez à une méthode d'analyse plus simple.
Conclusion
Commencer à utiliser JavaScript et entrer la première ligne dans le journal de la console à l'aide de
console.log assez simple. Mais avant de déployer le code en production, vous devez considérer plusieurs aspects de l'utilisation du journal. Cet article n'est qu'une introduction aux différentes méthodes et solutions utilisées pour organiser le journal des événements. Il ne contient pas tout ce que vous devez savoir. Par conséquent, il est recommandé de prêter attention aux projets open source réussis et de surveiller comment ils ont résolu le problème de journalisation et quels outils sont utilisés. Et maintenant, essayez de vous connecter sans générer de données sur la console.
Si vous connaissez d'autres outils qui méritent d'être mentionnés, écrivez-les dans les commentaires.