Bonjour à tous!
Je m'appelle Vitaliy Bendik. Je suis chef d'équipe pour le développement d'applications Android chez Lamoda. En 2018, j'ai pris la parole au Mosdroid Aluminium avec un
reportage dont je souhaite partager la transcription.

Il s'agira de la façon dont nous maintenons la stabilité de l'application mobile. C'est très important pour nous, car notre audience mobile est de millions d'utilisateurs. De plus, en termes de part dans les commandes de nos clients, les applications ont depuis longtemps dépassé les sites, les versions desktop et mobile au total, et la plateforme iOS est devenue un leader absolu, devant le site desktop.
Dans le rapport, je dirai:
- ce que nous entendons par stabilité d'application;
- À propos de l'architecture de notre application mobile;
- sur les processus, les pratiques et les outils que nous utilisons.
Alors, qu'est-ce qu'une
application stable pour nous? Il s'agit d'une application qui ne plante pas, ne se bloque pas et fonctionne de manière prévisible. Quand je dis qu'il ne tombe pas, je veux dire qu'il ne tombe pas dans au moins 95% -99% des utilisateurs.
L'architecture

Comme vous l'avez peut-être deviné, cette image montre une architecture pure à laquelle nous essayons d'adhérer. En tant que couche Présentation, nous utilisons MVP avec quelques ajouts, dont je parlerai ci-dessous.
Notre application mobile est adaptée pour les téléphones et les tablettes. Par conséquent, la disposition est souvent différente, mais se compose de blocs similaires ou identiques. À cet égard, nous avons une entité telle que Widget. Il vous permet de décomposer une activité ou un fragment en blocs plus petits qui peuvent être réutilisés dans d'autres écrans. Cela a du sens, car du point de vue du code qui se trouve dans le fragment ou dans l'activité, il est rarement nécessaire de distinguer le contexte de l'interface utilisateur qu'il exécute. Et ces fragments de code peuvent être rendus dans certaines abstractions et réutilisés. Cette approche rappelle quelque peu la bibliothèque SoundCloud -
LightCycle .


 Page produit. Exemples d'éléments de widget
Page produit. Exemples d'éléments de widgetEn ce qui concerne l'interaction du présentateur avec le modèle, tout est standard ici: le présentateur interagit avec le reste de l'application via un interacteur, qu'il s'agisse de référentiels ou de gestionnaires.
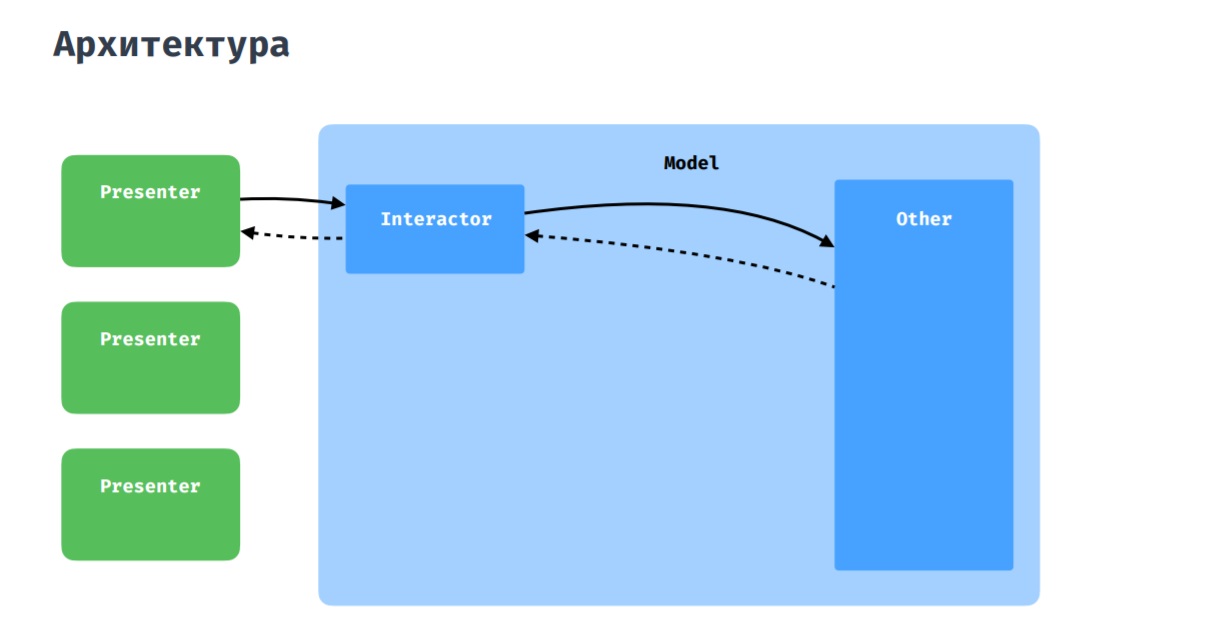
Il arrive que plusieurs présentateurs doivent communiquer entre eux, échanger des données. Pour cela, nous avons un coordinateur, qui peut être perçu comme un interacteur partagé entre plusieurs présentateurs.

Pile
- Nous écrivons tout le nouveau code dans Kotlin , et nous utilisons Moxy comme implémentation MVP.
- En tant que DI, nous utilisons Dagger2 .
- Pour travailler avec le réseau - Retrofit .
- Pour travailler avec des images - Glide .
- Nous ajoutons des plantages à New Relic .
- Nous utilisons également Lottie .
- Pour le moment, nous utilisons activement Kotlin Coroutines .
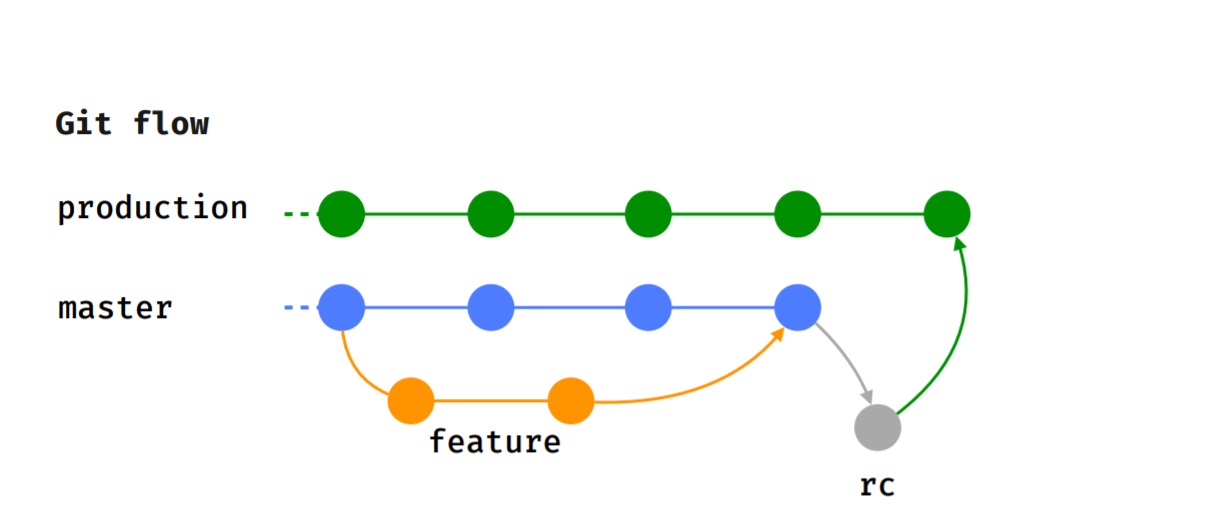
Processus de développement
Nous adhérons au flux Git, c'est-à-dire que chaque fonctionnalité est implémentée dans une branche de fonctionnalité distincte, qui, après une révision du code, est soumise pour test.
Une fois que le testeur a réussi le test et que nous avons décidé de la version à laquelle cette fonctionnalité ira, elle fusionne dans le maître.
Lorsque le moment de la libération arrive (nous serons libérés toutes les 2 semaines), la branche rc, où les tests de fumée sont effectués, est allouée, des cas de test sont exécutés. Après cela, la fonctionnalité fusionne dans la branche de production et est publiée sur Google Play Beta.
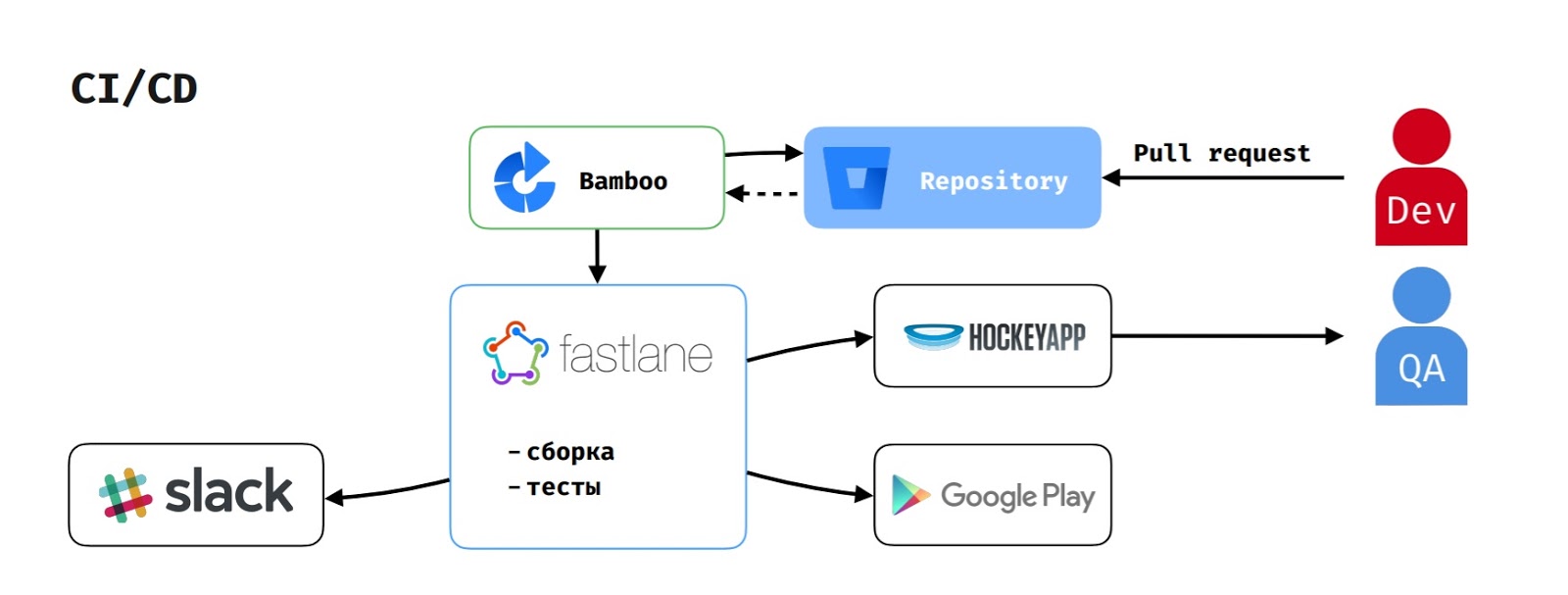
Quant à CI / CD, puisque nous utilisons la pile Atlassian, Bamboo agit comme un serveur de build.
Lorsqu'un développeur crée une pull-request, la tâche de génération démarre sur Bamboo. Elle extrait le code du référentiel, exécute le script sur fastlane, qui collecte l'application, exécute les tests et le signale à Slack.
Si le testeur a démarré l'assemblage afin de tester la fonctionnalité, apk est également chargé dans HockeyApp.
Pour publier la version sur Google Play Beta, le gestionnaire de diffusion lance la tâche correspondante sur Bamboo, qui exécute le même flux, mais télécharge également la version sur Google Play Beta.
Pratiques appliquées
Version préliminaireAu départ, nous avions deux types de montage, comme beaucoup:
Version de débogage dans laquelle ProGuard et l'épinglage SSL étaient désactivés.
Version de version dans laquelle ProGuard et SSL Pinning ont été inclus.
Le processus ressemblait à ceci: le développeur termine le travail sur la fonctionnalité et la donne pour les tests. Le testeur collecte l'ensemble de débogage, teste les cas de test sur celui-ci et vérifie l'exactitude des analyses envoyées par l'application. Si tout va bien, alors il envoie la tâche à Ready for release, et elle attend le moment où nous commençons à collecter le communiqué.
Lorsque vient le temps de publier l'application, le développeur fusionne toutes les tâches en maître, sélectionne la branche rc et lui donne un contrôle qualité pour les tests de fumée. QA collecte l'assemblage de la version et commence à exécuter des tests. Mais il y a des moments où quelque chose ne va pas. Les problèmes surviennent généralement en raison de ProGuard. Bien sûr, ils sont rapidement corrigés, mais cela peut retarder la libération ou la retarder pendant un certain temps.
Pour cette raison, nous avons créé une version préliminaire dans laquelle ProGuard est activé et l'épinglage SSL est désactivé. Cela permet aux testeurs de vérifier l'exactitude des analyses soumises (c'est la raison pour laquelle les testeurs n'ont pas initialement construit la version finale).
Maintenant, les QA sont en train de construire une version préliminaire. Cela leur donne la possibilité de tester des analyses et de faire face aux problèmes causés par ProGuard le plus tôt possible.
Spécification d'abordIl s'agit d'une approche dans laquelle la spécification est principale. Lorsque nous développons une nouvelle fonctionnalité et qu'elle nécessite un backend, une spécification est d'abord créée, puis, sur la base de celle-ci, le développement de la fonctionnalité démarre à la fois du backend et des clients. Toutes les modifications passent par la spécification, et ce n'est qu'alors que des modifications sont apportées au serveur principal et aux clients. Cette spécification génère également une documentation Swagger sur les méthodes API.
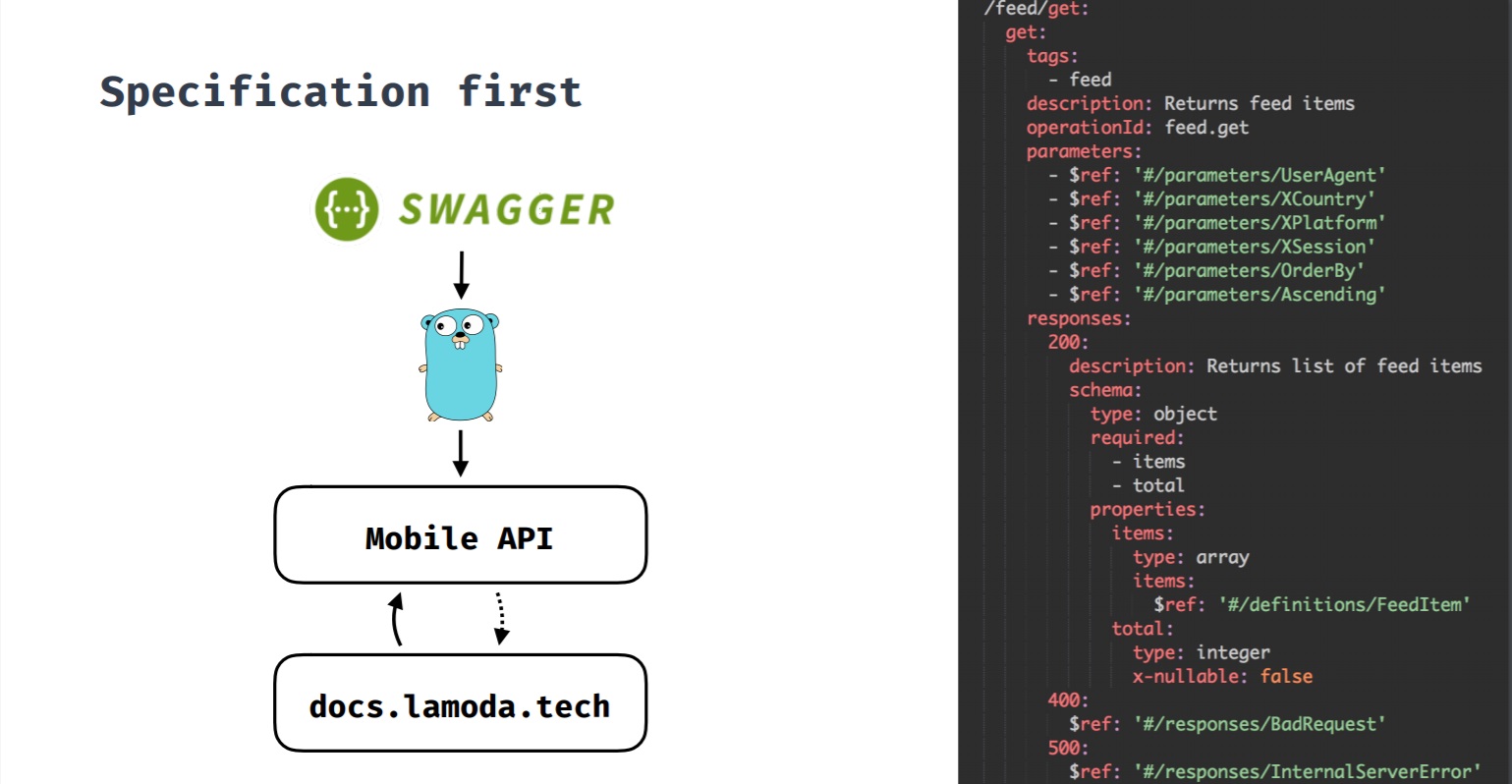
Au départ, nous avions une API dont les clients n'étaient pas seulement des applications mobiles. Les méthodes API n'étaient pas cohérentes, ce qui rendait souvent les changements difficiles.
Souvent, on a aussi rencontré des cas amusants. Par exemple, lorsque la méthode renvoie une liste de marques, dans le cas où il y en avait plusieurs, elle renvoyait un tableau et s'il n'y avait qu'une seule marque, elle renvoyait un objet.

Ou, en l'absence de marques, soit null a été retourné, soit en général 4 caractères null
(pas JSON). Dans ce cas, l'application était difficile.

Par conséquent, au fil du temps, nous sommes arrivés à la conclusion que les applications mobiles nécessitent leur propre API, qui prendrait en compte leurs spécificités et associerait l'application mobile à un tas de systèmes Lamoda internes avec lesquels vous devez interagir.

Dans le même temps, nous avons décidé d'essayer la première approche de la spécification (spécification Swagger). Lorsqu'un développeur commence à travailler sur une fonctionnalité qui a besoin d'un backend, il fait une pull-request avec un contrat de fonctionnalité. Ensuite, toutes les parties intéressées des équipes iOS, Android et backend sont ajoutées à cette pull-request. Lorsque tout le monde est satisfait du contrat de la nouvelle méthode API, la demande d'extraction est versée dans la branche backend et les développeurs backend commencent à développer des fonctionnalités. Les clients commencent également à développer des fonctionnalités, car le contrat est désormais résolu et vous pouvez vous y fier et, si nécessaire, créer moki.
Bascule de fonctionLa société dispose de son propre outil de développement A / B, qui vous permet de mettre en œuvre des expériences et des bascules de fonctionnalités. La fonction bascule nous ferme la fonctionnalité non critique pour l'utilisateur, qui, si nécessaire, peut être désactivée. Par exemple, si quelque chose s'est mal passé, ou si nous devons réduire la charge sur le backend (en option, le «Black Friday»).
Les bascules de fonctionnalités nous permettent également de tester les bibliothèques pour voir si une autre bibliothèque résoudra mieux notre problème et se comportera plus stable. Sinon, nous pouvons toujours revenir à notre bibliothèque précédente.
Surveillance réelle des utilisateursReal User Monitoring vous permet de mesurer les performances des applications du point de vue d'un utilisateur. Par exemple, un client a cliqué sur un article d'un catalogue. Combien de temps devra-t-il attendre avant de voir le résultat de son action, c'est-à-dire qu'il voit une fiche produit avec des photos?
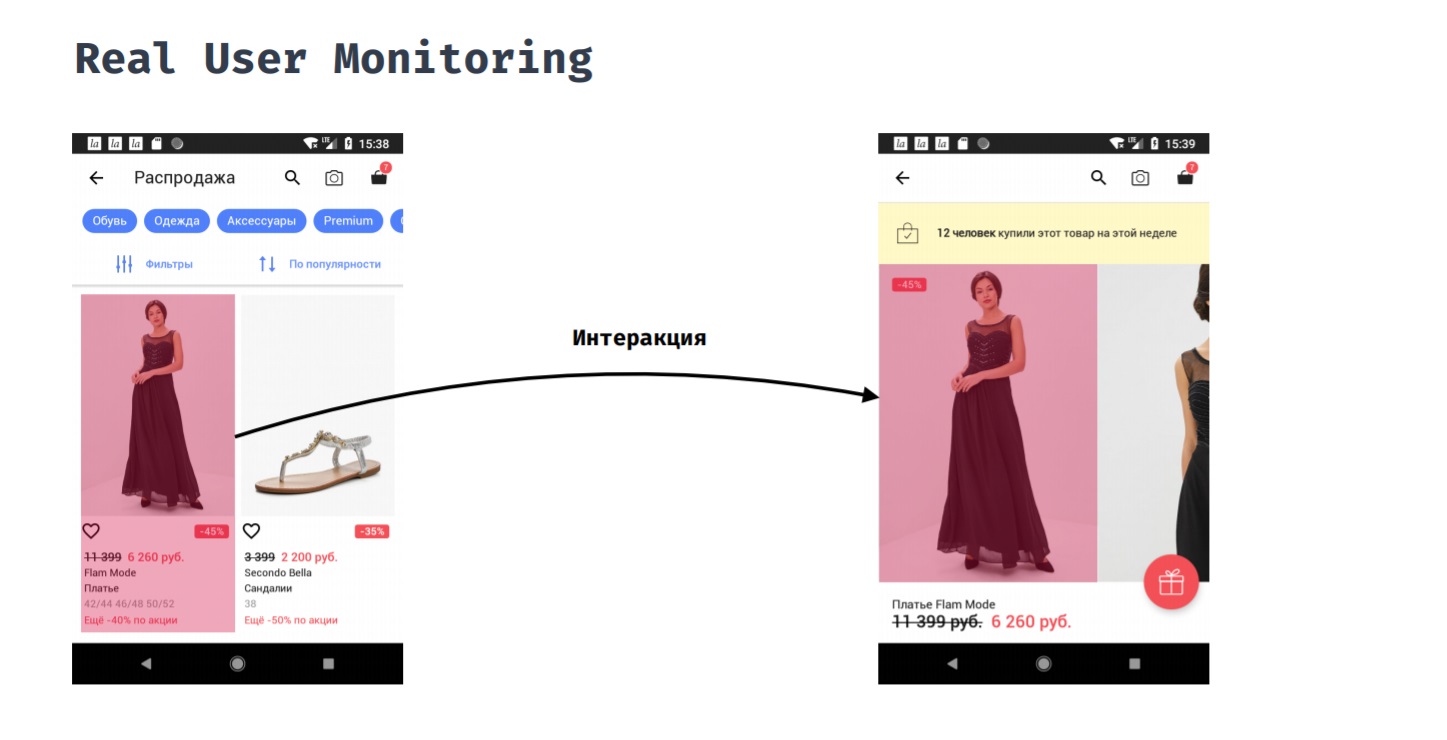
Cela ne peut pas être fait automatiquement, car le point de départ et le point final de cette mesure doivent être définis manuellement. Seul le développeur comprend quand on peut supposer que l'utilisateur est prêt à interagir avec le nouvel écran. Dans le processus de cette interaction, nous pouvons être intéressés par des choses telles que:
1. consommation de mémoire;
2. Consommation CPU;
3. ce qui s'est passé sur le flux principal;
4. ce qui a été chargé à partir du réseau;
5. ce qui s'est passé dans d'autres threads.
Cela nous donne la possibilité de résoudre les problèmes s'ils surviennent, car il devient clair que cela a effectivement pris la plupart du temps et que nous pouvons l'optimiser pour que l'application soit plus réactive à l'utilisateur.
Remboursement de la dette technique
Avant de déployer la nouvelle version, nous corrigeons les plantages survenus dans la version précédente. Il ne s'agit pas de plantages critiques, car cela nécessiterait certainement des correctifs, mais des plantages qui ne se produisent pas trop souvent n'affectent pas les performances de l'entreprise, mais sont désagréables pour les utilisateurs.
Après la sortie de la version, nous la déployons en pourcentage, surveillons les indicateurs critiques et répondons aux incidents s'ils se produisent. Pour le roulement par phases, nous utilisons la console Google Play. Le roulement est réalisé comme suit: déployé de 5%, nous suivons l'indicateur; si tout est en ordre, continuez. Si quelque chose s'est produit, créez un correctif et déployez-le déjà. Ensuite, nous faisons un roulement de 10%, 20% et 50%.
Quels endroits critiques
surveillons- nous?
- Demandes réseau, y compris de bibliothèques tierces: erreurs, temps de réponse, chargement.
- L'automne.
- Exceptions gérées, les soi-disant «exceptions traitées». Ce sont des exceptions qui auraient pu se produire si nous ne les avions pas enveloppés de try-catch. Cela permet à l'application de ne pas tomber si une exception s'est produite dans la fonctionnalité non critique pour l'utilisateur. Par exemple, il est mauvais de tomber à cause de l'analyse. Cependant, il est important que les produits comprennent qu'une fonctionnalité améliore ou aggrave la conversion. L'utilisation d'exceptions gérées nous permet de répondre et de résoudre ces problèmes.
Les outils
- Outil A / B
- NewRelic RPM
- NewRelic Insights.
L'outil A / B est un mécanisme permettant de mener des expériences et un mécanisme de roulement des variables, les mêmes fonctions-bascule. Il s'agit d'un développement interne, il est donc bien intégré dans de nombreux systèmes: dans les applications mobiles, sur le site, en back-end. Il vous permet de transmettre la configuration de bascule de fonction non pas dans une demande distincte derrière elle, mais dans les en-têtes des réponses aux demandes que l'application fait.
Cela nous donne l'opportunité:
- Déployez des expériences sur le bureau lorsque nous voulons tester une fonctionnalité à l'intérieur de notre bureau.
- Déployez une expérience, ainsi que des bascules de fonctionnalités pour un utilisateur spécifique.
Le système est indépendant des facteurs externes. Si nous utilisions un outil tiers, à un moment donné, il pourrait être bloqué (bonjour, Roskomnadzor) ou quelque chose pourrait mal tourner. Pour nous, cela serait critique, car dans ce cas, nous ne pourrions pas basculer rapidement entre les fonctionnalités. Et puisque c'est notre propre développement, nous n'avons pas un tel problème.
NewRelic est un outil qui vous permet de surveiller de nombreux indicateurs différents en temps réel. Parmi la variété des fonctionnalités de New Relic, nous utilisons, par exemple, l'instrumentation automatique de code. C'est elle qui nous permet de surveiller les requêtes réseau non seulement vers notre backend, mais aussi tout le reste (y compris à partir de bibliothèques tierces). NewRelic prend en charge un certain ensemble de clients standard pour travailler avec le réseau. Il vous permet également de collecter des informations:
1. sur la consommation de mémoire;
2. sur la consommation du processeur;
3. sur les opérations liées à JSON;
4. sur les opérations liées à SQlite.
De plus, nous utilisons NewRelic pour collecter les rapports de plantage, pour collecter les exceptions gérées et pour les interactions avec les utilisateurs - c'est exactement la même
surveillance réelle des utilisateurs . Nous l'avons implémenté via le mécanisme des interactions utilisateurs NewRelic.
Mais qu'en est-il de la stabilité?
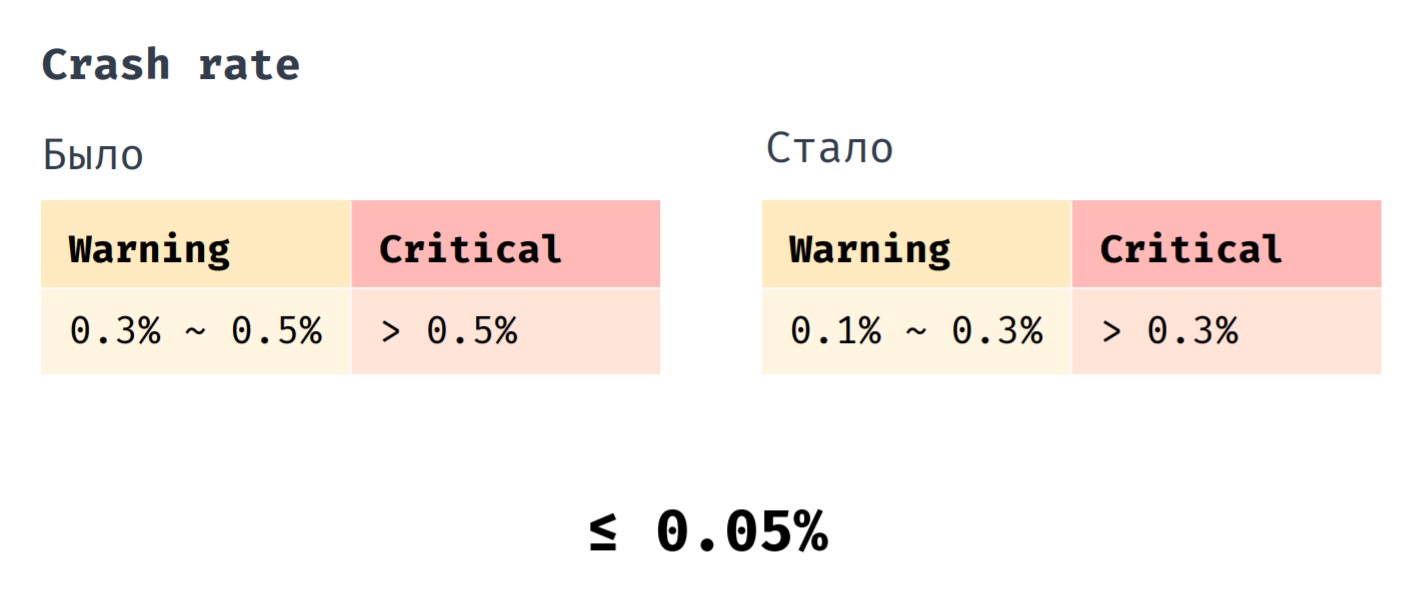
Nous avons un indicateur tel que le taux d'accident. Auparavant, nous avons déployé le correctif lorsque son indicateur était compris entre 0,3% et 0,5%. Il est absolument essentiel que sa valeur dépasse 0,5% .Nous déployons maintenant le correctif lorsque le taux de crash se situe entre 0,1% et 0,3%. Une valeur critique est supérieure à 0,3% et si, auparavant, le taux de crash moyen de notre application était de 0,1%, il est désormais de 0,05%.
En conclusion, je voudrais énumérer les pratiques les plus importantes qui nous aident à maintenir la stabilité des applications. Nous testons l'application aussi près que possible de la version de production, fermons la fonctionnalité non critique des bascules de fonction, ainsi que surveillons et répondons aux indicateurs qui sont importants pour nous.