
Bonjour, je suis Alexey, développeur full-stack de la plateforme Vimbox. Quand je suis arrivé à Skyeng, ils ont décidé ici si cela valait le temps de passer sur le système d'autotest et m'ont demandé de partager mon expérience des travaux précédents. Et j'ai eu une telle expérience: au moment où nous avons quitté l'endroit précédent, nous avons écrit en php et tordu plus de 3 000 tests. En conséquence, j'ai fait une petite présentation interne racontant le rake que j'ai réussi à suivre en quelques années de développement de ces autotests, luttant pour leur vitesse, leur lisibilité du code et leur efficacité globale. La présentation a semblé utile à mes collègues, je l'ai donc mise dans le texte pour être utile également à un public plus large.
Pour commencer, les termes qui seront discutés dans l'article:
- Test d'acceptation - test de bout en bout: ici le navigateur ou l'émulateur de navigateur exécute le script
- Test unitaire ( test unitaire) - test de méthode
- Test fonctionnel - un test d'un contrôleur ou d'un composant, quand il s'agit de frontend
- Fixture - l'état de l'environnement de test nécessaire pour que le test fonctionne (variables globales, données dans la base de données et autres participants au script de test)
Avantages et inconvénients de différents types de tests
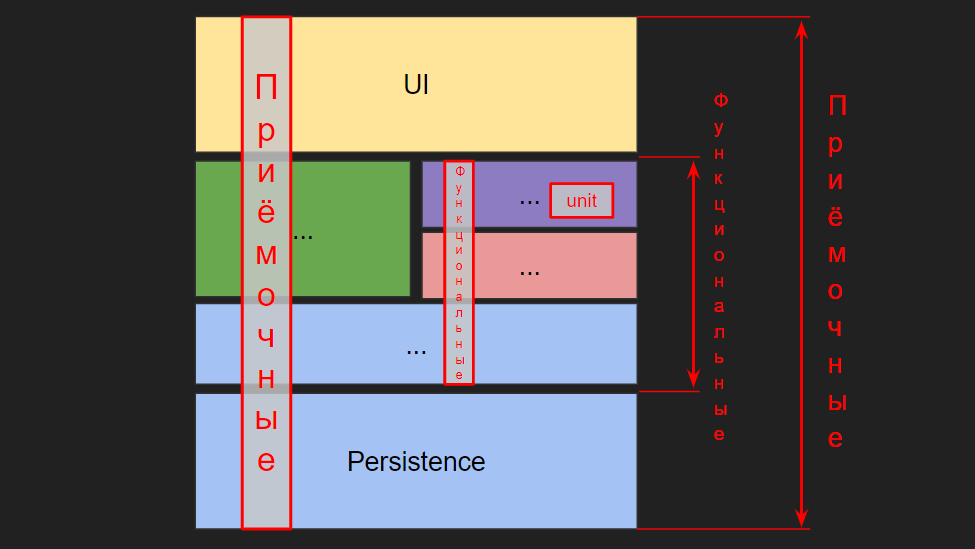
Tests d'acceptation
- Avantages: évident d'après le nom, ces tests couvrent l'ensemble du système de haut en bas, assurez-vous que tout fonctionne comme il se doit.
- Inconvénients: les retours de ces tests sont très lents, ils fonctionnent longtemps, ils ne sont pas très fiables, il y a beaucoup de faux positifs. Lors d'un précédent travail, nous étions également confrontés au fait que les pilotes Web n'ont pas détecté certains des éléments que nous avons vus avec nos yeux. Maintenant, cela a probablement été corrigé, mais j'ai dû les abandonner.
Tests unitaires
- Avantages: facile à écrire, fonctionne rapidement. Ils couvrent un petit morceau de code, vous n'avez pas besoin de nombreux états, par conséquent, vous n'avez pas non plus besoin d'un grand appareil.
- Inconvénients: instable aux changements dans l'architecture ou la structure interne du code. Si vous devez fusionner deux méthodes en une seule ou séparément, sélectionnez une classe, supprimez une méthode, vous devez réécrire les tests.
Les tests fonctionnels sont une solution intermédiaire.
- Avantages: acceptation plus fiable, plus résistante aux modifications de la structure du code que modulaire.
- Inconvénients: plus lent que modulaire, plus difficile à écrire, car besoin de préparer un gros luminaire.
Le combat pour la vitesse
Dans l'ancien travail, nous avons écrit de nombreux tests fonctionnels, et le principal défi était la vitesse de réponse. J'ai dû attendre longtemps le résultat, même avec un lancement local sur l'ordinateur du développeur. La vitesse était si lente qu'il n'était pas possible d'appliquer l'approche du «développement par les tests», car elle impliquait l'exécution d'autotests plusieurs fois par heure. Trouvé un goulot d'étranglement - travailler avec la base de données. Comment y faire face?
L'expérience d'abord: moki
Mock dans PhpUnit est un objet créé dynamiquement dont la classe est héritée dynamiquement de la classe parodiée. Vous pouvez configurer ce que les méthodes du mok retourneront, vous pouvez vérifier quelles méthodes du moq combien de fois avec quels paramètres ont été appelés
Le principal avantage de moki - ils vous permettent de couper des fonctionnalités entières. En remplaçant le service par moch, nous nous débarrassons de la nécessité de penser à ce qui s'y passe, de développer des scripts et des fixations supplémentaires pour que tout fonctionne correctement. En conséquence: moins de fixtures, et la vitesse de réponse est plus élevée en raison du fait que nous avons coupé le code supplémentaire qui exécute les requêtes vers la base de données.
L'avantage implicite des foules est qu'elles facilitent l'organisation des dépendances. Lorsque vous écrivez un code, sachant qu'il sera nécessaire d'y écrire un test, où quelque chose est remplacé par mokami, vous pensez immédiatement aux dépendances.
Moins : le code de test est trop attaché à l'implémentation. Pendant le test, nous devons créer un objet factice et réfléchir aux méthodes qui doivent être appelées dessus.
Le deuxième inconvénient constaté est que les tests sont devenus moins fiables. Ils «ne remarquent pas» même les changements d'interface, sans parler de l'implémentation. C'est-à-dire nous avons supprimé la méthode quelque part et après un long moment, nous avons constaté que les tests qui la couvraient fonctionnent toujours comme si de rien n'était, car nous avons vu sa simulation, et il a prétendu que tout allait bien.
Je considère que l'expérience avec les mokas n'a pas réussi à accélérer les tests.
Expérience deux: SQLite
L'option suivante est le SGBD SQLite , il peut créer une base de données en RAM. J'ai dû écrire un schéma de traducteur PostgreSQL dans SQLite, après chaque migration, un nouveau schéma SQLite a été généré. Les tests de ce circuit ont créé une base de données vide dans la RAM. Cette approche a augmenté la vitesse des tests sur les machines locales de deux à quatre fois. Il est devenu réaliste d'exécuter toute la suite de tests plusieurs fois par heure.
Mais il y avait des inconvénients. Nous avons perdu de nombreuses fonctionnalités natives de PostgreSQL (json, quelques fonctions d'agrégation pratiques, etc.). Les requêtes devaient être écrites pour qu'elles fonctionnent à la fois sur PostgreSQL et SQLite.
Troisième expérience: optimisation PostgreSQL
Cette décision fonctionnait, mais a causé quelques douleurs. À un moment donné, nous avons appris que PostgreSQL peut être optimisé pour les autotests, ce qui réduit le temps de réponse d'environ quatre fois. Pour ce faire, ajoutez quelques paramètres à postgresql.conf:
fsync=off synchronous_commit=off full_page_writes=off
Ce sont des paramètres de fiabilité, ils garantissent que si le serveur meurt au milieu d'une transaction, il se terminera correctement lorsque tout recommencera à fonctionner. Il est clair que de tels réglages ne peuvent pas être effectués en production, mais c'était pratique pour les tests automatiques.
Ce paramètre est appliqué à l'ensemble du cluster, affecte toutes les bases de données, il ne peut pas être appliqué à une seule base de données. Si vous parvenez à localiser les bases de données dans un cluster distinct et à désactiver fsync dans celui-ci, cela est très pratique.
Un peu de new
Je voudrais également mentionner le danger du new opérateur. Les services créés avec son aide ne peuvent pas être remplacés par des mokas et des talons. Conclusion:
- N'utilisez pas
new pour créer des objets qui sont essentiellement des services. - Il peut être utilisé dans les usines, car ils peuvent être remplacés. Mais les usines elles-mêmes ne devraient pas être créées par de
new . - Il peut être utilisé pour créer des modèles, des entités, des DTO (objets de transfert de données), des objets de valeur.
Conclusions de trois ans d'expérience
- Lors des travaux précédents, nous avions refusé les tests d'acceptation, mais maintenant je les réessayerais: de nombreux bugs ont probablement été corrigés dans les pilotes Web.
- Si vous devez couvrir de nouvelles fonctionnalités avec des tests, vous devez écrire uniquement des tests fonctionnels des contrôleurs / composants. Dans cette situation, nous avons un risque élevé de changements structurels, les tests unitaires leur sont instables.
- Il ne devrait pas y avoir beaucoup de tests de ce type, car beaucoup == lentement, ils ne fonctionnent pas aussi rapidement que les tests modulaires. Il vaut la peine de couvrir uniquement les cas qui peuvent «tirer» (ils ont la probabilité d'une erreur à l'avenir).
- Les tests unitaires sont écrits sur des méthodes riches en algorithmes (logique complexe qui doit être testée) ou sur des méthodes avec peu de risques de changements structurels à l'avenir.
- Les inconvénients du moka dépassent généralement les avantages. Il est logique de les utiliser uniquement comme substitution de passerelles vers des API externes, et parfois des services à partir de code hérité, qui sont très difficiles à tester.
- Si vous décidez d'écrire du code sans test, il est conseillé de penser: «lorsque vous le créez, que se passe-t-il si à l'avenir nous voulons toujours écrire un test pour lui?»
- Les tests doivent être faciles et agréables à écrire, ils donnent fiabilité, confiance, aident à mieux comprendre le code, gèrent les dépendances.
- Faites attention à la lisibilité des tests. Il faut se rapporter au code de test de la même manière que le code qu'il couvre.
- Appareils DB - partie du test, devraient également être lisibles