Avec ce post, j'ouvre une série où mes collègues et moi vous expliquerons comment ML est utilisé dans Mail.ru Search. Aujourd'hui, je vais expliquer comment le classement est organisé et comment nous utilisons les informations sur les interactions des utilisateurs avec notre moteur de recherche pour améliorer le moteur de recherche.
Tâche de classement
Qu'entend-on par classement d'une tâche? Imaginez que dans l'exemple de formation, il existe un ensemble de requêtes pour lesquelles l'ordre des documents par pertinence est connu. Par exemple, vous savez quel document est le plus pertinent, qui est le deuxième plus pertinent, etc. Et vous devez rétablir cet ordre pour toute la population. Autrement dit, pour toutes les demandes de la population en général, la première place est placée le document le plus pertinent, et le dernier - le plus hors de propos.
Voyons comment ces problèmes sont résolus dans les grands moteurs de recherche.
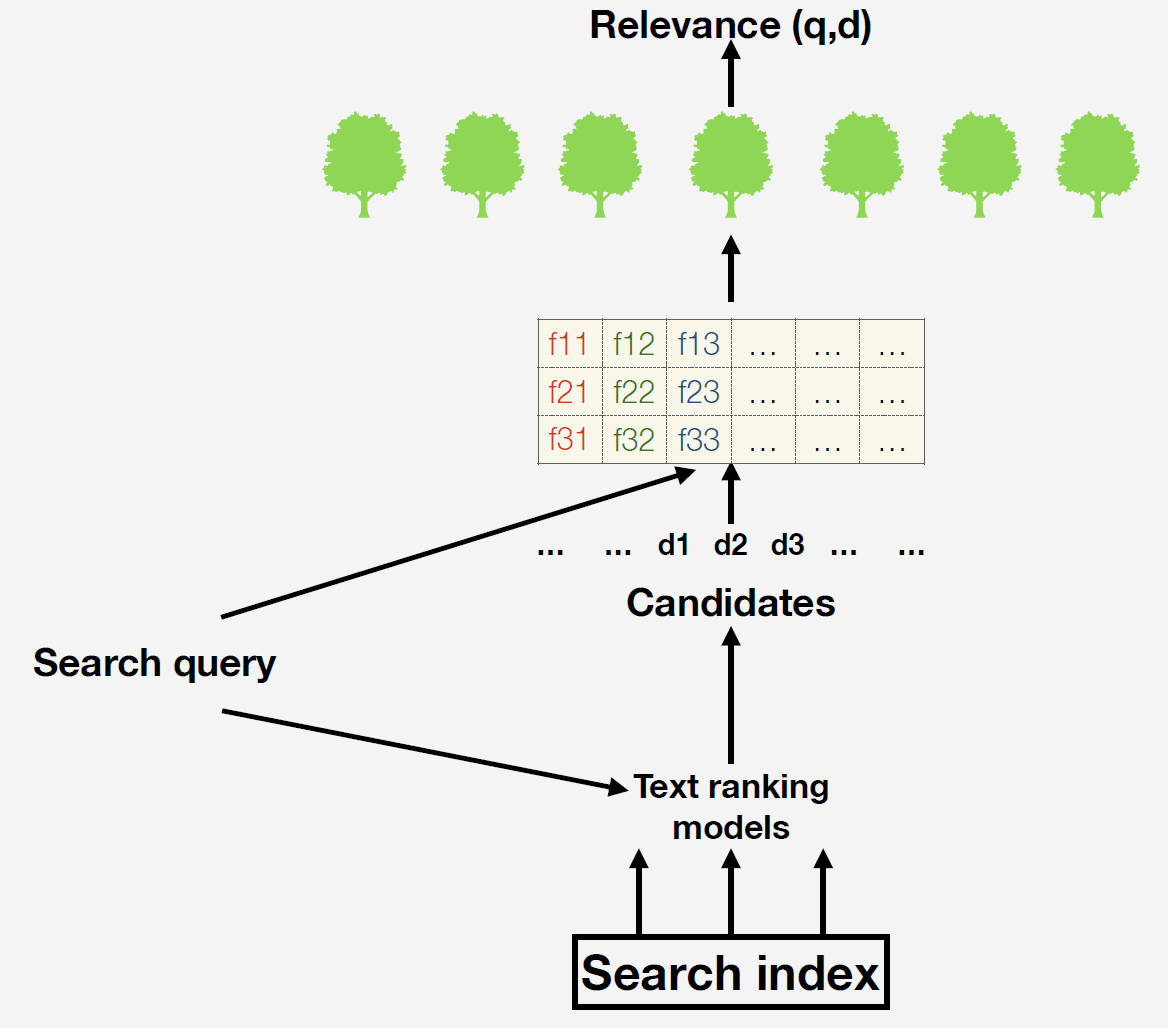
Nous avons un index de recherche - c'est une base de données de plusieurs milliards de documents. Lorsqu'une demande arrive, nous générons d'abord une liste de candidats pour le classement final à l'aide de modèles de texte simples. L'option la plus simple consiste à récupérer des documents qui, en principe, contiennent des mots de la demande. Pourquoi cette étape est-elle nécessaire? Le fait est qu'il est impossible pour tous les documents disponibles de construire des panneaux et de former des prévisions du modèle final. Après avoir déjà calculé les signes. Quels signes pouvons-nous prendre? Par exemple, le nombre d'occurrences de mots d'une requête dans un document ou le nombre de clics sur un document donné. Vous pouvez utiliser des facteurs complexes formés par machine: dans la recherche à l'aide de réseaux de neurones, nous prédisons la pertinence du document à la demande et insérons cette prévision avec une nouvelle colonne dans notre espace de fonctionnalités.
Pourquoi faisons-nous tout cela? Nous voulons maximiser les mesures des utilisateurs afin que les utilisateurs trouvent les résultats pertinents dans nos résultats aussi facilement que possible et nous reviennent aussi souvent que possible.
Notre modèle final utilise un ensemble d'arbres de décision construits en utilisant l'augmentation du gradient. Il existe deux options pour créer une métrique cible pour la formation:
- Nous créons un département d'évaluateurs - des personnes spécialement formées à qui nous adressons des questions et disons: "Les gars, évaluez la pertinence de notre émission." Ils répondront par des chiffres qui mesurent la pertinence. Pourquoi cette approche est-elle mauvaise? Dans ce cas, nous maximiserons le modèle par rapport aux opinions de personnes qui ne sont pas nos utilisateurs. Nous n'optimiserons pas pour la métrique que nous voulons vraiment optimiser.
- Pour cette raison, nous utilisons la deuxième approche pour la variable cible: nous montrons aux utilisateurs les résultats, regardons vers quels documents ils passent, lesquels sautent. Et puis nous utilisons ces données pour former le modèle final.
Comment le problème de classement est-il résolu?
Il existe trois approches pour résoudre le problème de classement:
- Point par point , c'est par point. Nous considérerons la pertinence comme une mesure absolue et affinerons le modèle de la différence absolue entre la pertinence prévue et celle que nous connaissons de l'échantillon de formation. Par exemple, l'évaluateur a donné au document une note de 3, et nous dirions 2, donc nous affinons le modèle de 1.
- Par paire, par paire. Nous comparerons les documents entre eux. Par exemple, dans l'échantillon de formation, il y a deux documents, et nous savons lequel est le plus pertinent pour cette demande. Ensuite, nous affinerons le modèle s'il met la prévision inférieure à la moins pertinente, c'est-à-dire que la paire est mal arrangée.
- Listwise . Il est également basé sur la pertinence relative, mais pas à l'intérieur des paires: nous classons l'ensemble du problème par le modèle et évaluons le résultat - si le document le plus pertinent n'est pas en premier lieu, nous obtenons une grande amende.
Quelle approche est préférable d'utiliser pour notre variable cible? Pour ce faire, il convient de discuter d'une question importante: «les clics peuvent-ils être utilisés comme mesure de la pertinence absolue d'un document?» C'est impossible, car ils dépendent de la position du document dans le numéro. Après avoir reçu le problème, vous cliquez probablement sur le document qui sera le plus élevé, car il vous semble que les premiers documents sont plus pertinents.
Comment vérifier une telle hypothèse? Nous prenons deux documents en haut du problème et les échangeons. Si les clics étaient une mesure absolue de pertinence, leur nombre ne dépendrait que du document lui-même et non de la position. Mais ce n'est pas le cas. Le document ci-dessus obtient toujours plus de clics. Par conséquent, les clics ne peuvent jamais être utilisés comme mesure de pertinence absolue. Par conséquent, vous pouvez utiliser soit par paire, soit par liste.
Nous collectons un ensemble de données
Maintenant, nous extrayons les données de l'ensemble d'apprentissage. Nous avons eu cette session:
Des quatre documents, il y avait un clic sur les deuxième et quatrième. En règle générale, les gens regardent les résultats de haut en bas. Vous avez regardé le premier document, vous ne l'aimiez pas, cliqué sur le second. Puis ils sont revenus à la recherche, ont regardé le troisième et ont cliqué sur le quatrième. De toute évidence, vous avez aimé le second plus que le premier, et le quatrième plus que le premier et le troisième. Ce sont les paires que nous générons pour toutes les demandes et nous utilisons des modèles pour la formation.
Tout semble aller bien, mais il y a un problème: les gens ne cliquent que sur les documents tout en haut du problème. Par conséquent, si vous créez uniquement l'échantillon de formation de cette manière, la distribution sera exactement la même que dans l'échantillon de test. Il est nécessaire d'aligner en quelque sorte la distribution. Nous le faisons en ajoutant des exemples négatifs: ce sont des documents qui étaient en bas du classement, l'utilisateur ne les a certainement pas vus, mais nous savons qu'ils sont mauvais.

Nous avons donc obtenu un tel schéma de classement de la formation: ils ont montré aux utilisateurs les résultats, collecté des clics auprès d'eux, ajouté des exemples négatifs pour aligner la distribution et recyclé le modèle de classement. Ainsi, nous prenons en compte la réaction des utilisateurs à votre classement actuel, prenons en compte les erreurs et améliorons le classement. Nous répétons ces procédures plusieurs fois jusqu'à la convergence. Il est important de noter que nous recherchons non seulement par le Web, mais aussi par vidéo, par images, et le schéma décrit fonctionne parfaitement dans tout type de recherche. En conséquence, les mesures comportementales se développent beaucoup. Dans la deuxième itération, il est légèrement plus petit, dans la troisième itération, il est encore plus petit et, par conséquent, converge vers un optimum local.
Réfléchissons à la raison pour laquelle nous convergeons à un optimum local, et non à un optimum global.
Supposons que vous soyez un fan de football et que vous n'ayez pas eu le temps de regarder le match de votre équipe préférée le soir. Réveillez-vous le matin et entrez le nom de l'équipe dans la barre de recherche pour connaître le résultat du match. Voir les trois premiers documents - ce sont les pages officielles du club, il n'y a pas d'informations utiles. Vous ne feuilleterez pas l'intégralité du problème, ne récupérerez pas une autre demande. Peut-être même que vous cliquez sur un document non pertinent. Mais en conséquence, bouleversez-vous, fermez le SERP et ouvrez un autre moteur de recherche.

Bien que ce problème ne se trouve pas seulement dans la recherche, il est particulièrement pertinent ici. Imaginez une boutique en ligne, qui est une grosse bande sans la possibilité de dire quelle catégorie particulière de produits vous souhaitez voir. C'est exactement ce qui se passe avec les résultats de recherche: après avoir envoyé la demande, vous ne pouvez plus expliquer ce dont vous avez vraiment besoin: des informations sur l'équipe de football ou le score du dernier match.
Imaginez qu'un homme brutal soit allé dans une boutique en ligne aussi étrange, qui se compose d'une bande de recommandations, et dans ses recommandations, il ne voit que des produits typiquement féminins. Peut-être qu'il clique même sur une robe, car elle est portée sur une belle fille. Nous enverrons ce clic à l'ensemble d'entraînement et déciderons que l'homme aime cette robe plus qu'une éponge. Lorsqu'il reviendra dans notre système, il verra déjà des robes. Au départ, nous n'avions pas de produits valides pour l'utilisateur, donc cette approche ne nous permettra pas de corriger cette erreur. Nous étions dans un optimum local, dans lequel le pauvre ne peut plus nous dire qu'il n'aime ni les éponges ni les robes. Ce problème est souvent appelé problème de rétroaction positive.
Nouvelle amélioration
Comment améliorer un moteur de recherche? Comment sortir d'un optimum local? De nouveaux facteurs doivent être ajoutés. Supposons que nous ayons fait un très bon facteur qui, sur demande avec le nom de l'équipe de football, produira un document pertinent, c'est-à-dire les résultats du dernier match. Quel pourrait être le problème ici? Si vous entraînez le modèle sur d'anciennes données, sur des données hors ligne, puis prenez l'ancien ensemble de données en quelques clics et ajoutez-y cet attribut. Il peut être pertinent, mais vous ne l'avez pas utilisé auparavant dans le classement, et donc les gens n'ont pas cliqué sur les documents pour lesquels cet attribut est bon. Il ne correspond pas à votre variable cible, il ne sera donc tout simplement pas utilisé par le modèle.
Dans de tels cas, nous utilisons souvent cette solution: en contournant le modèle final, nous forçons notre classement à utiliser cette fonctionnalité. Nous montrons de force le résultat du dernier match sur demande avec le nom de l'équipe, et si l'utilisateur a cliqué dessus, alors pour nous ce sont les informations qui nous permettent de comprendre que le signe est bon.
Regardons un exemple. Récemment, nous avons fait de belles photos pour les documents Instagram:

Il semble que de si belles images devraient autant que possible satisfaire nos utilisateurs. Évidemment, nous devons faire un signe que le document a une telle image. Nous ajoutons à l'ensemble de données, recyclons le modèle de classement et voyons comment cette fonctionnalité est utilisée. Et puis nous analysons le changement des mesures comportementales. Ils se sont un peu améliorés, mais est-ce la meilleure solution?
Non, car pour de nombreuses demandes, vous ne montrez pas de belles images. Vous n'avez pas donné à l'utilisateur la possibilité de montrer comment il les aime. Pour résoudre ce problème, pour certaines demandes qui impliquent de montrer des documents Instagram, en contournant de force le modèle, nous avons montré de belles images et regardé si elles avaient cliqué dessus. Dès que les utilisateurs ont apprécié l'innovation, ils ont commencé à recycler le modèle sur des ensembles de données, dans lesquels les utilisateurs ont eu l'occasion de montrer l'importance de ce facteur. Après cette procédure, sur un nouvel ensemble de données, le facteur a commencé à être utilisé plusieurs fois plus souvent et a considérablement augmenté les métriques utilisateur.
Nous avons donc examiné l'énoncé du problème de classement et discuté des pièges qui vous attendront lors de l'apprentissage des commentaires des utilisateurs. La principale chose que vous devriez retirer de cet article: en utilisant la rétroaction comme cible de formation, n'oubliez pas que l'utilisateur ne peut laisser cette rétroaction que là où le modèle actuel le permet. Ces commentaires peuvent vous jouer un tour lorsque vous essayez de créer un nouveau modèle d'apprentissage automatique.