
Plus le processus de développement est rapide, plus la société technologique se développe rapidement.
Malheureusement, les applications modernes fonctionnent contre nous - nos systèmes doivent être mis à jour en temps réel et en même temps pour ne pas interférer avec qui que ce soit et ne pas entraîner de temps d'arrêt et d'interruptions. Le déploiement dans de tels systèmes devient une tâche complexe et nécessite des pipelines de livraison continue complexes, même dans de petites équipes.
Ces pipelines ont généralement une application étroite, fonctionnent lentement et ne sont pas fiables. Les développeurs doivent d'abord les créer manuellement, puis les gérer, et les entreprises engagent souvent des équipes DevOps entières pour cela.
La vitesse de développement dépend de la vitesse de ces pipelines. Pour les meilleures équipes, le déploiement prend 5 à 10 minutes, mais il prend généralement beaucoup plus de temps et pour un déploiement, il prend plusieurs heures.
Dans l'obscurité, cela prend 50 ms. Cinquante. Millisecondes Dark est une solution complète avec un langage de programmation, un éditeur et une infrastructure spécialement conçus pour une livraison continue, et tous les aspects de Dark, y compris le langage lui-même, sont construits avec une vue de déploiement instantané sécurisé.
Pourquoi les convoyeurs continus sont-ils si lents?
Disons que nous avons une application Web Python et que nous avons déjà créé un pipeline de livraison continue merveilleux et moderne. Pour un développeur qui est quotidiennement occupé par ce projet, le déploiement d'un changement mineur ressemblera à ceci:
Apporter des changements
- Créer une nouvelle branche dans git
- Faire des changements derrière le commutateur de fonction
- Test unitaire pour vérifier les changements avec et sans interrupteur de fonction
Demande de piscine
- Commit commit
- Publier des modifications dans un référentiel distant sur github
- Demande de piscine
- CI se construit automatiquement en arrière-plan
- Examen du code
- Quelques révisions supplémentaires, si nécessaire
- Fusionnez les modifications avec l'assistant git.
CI s'exécute sur l'assistant
- Définition des dépendances frontales via npm
- Création et optimisation des ressources HTML + CSS + JS
- Exécuter à l'extrémité avant des tests unitaires et fonctionnels
- Installer les dépendances Python depuis PyPI
- Exécuter dans le backend des tests unitaires et fonctionnels
- Test d'intégration aux deux extrémités
- Envoyer des ressources frontales à CDN
- Construire un conteneur pour un programme Python
- Envoi d'un conteneur au registre
- Mise à jour du manifeste Kubernetes
Remplacement de l'ancien code par un nouveau
- Kubernetes lance plusieurs instances d'un nouveau conteneur
- Kubernetes attend que les instances deviennent opérationnelles
- Kubernetes ajoute des instances à l'équilibreur de charge HTTP
- Kubernetes attend que les anciennes instances cessent d'être utilisées
- Kubernetes arrête les anciennes instances
- Kubernetes répète ces opérations jusqu'à ce que de nouvelles instances remplacent toutes les anciennes
Allumez le nouveau commutateur de fonction
- Le nouveau code est inclus uniquement pour moi, pour m'assurer que tout va bien
- Un nouveau code est inclus pour 10% des utilisateurs; les mesures opérationnelles et commerciales sont suivies
- Un nouveau code est inclus pour 50% des utilisateurs; les mesures opérationnelles et commerciales sont suivies
- Le nouveau code est inclus pour 100% des utilisateurs, les mesures opérationnelles et commerciales sont suivies
- Enfin, vous répétez toute la procédure pour supprimer l'ancien code et basculer
Le processus dépend des outils, du langage et de l'utilisation des architectures orientées services, mais en termes généraux, il ressemble à ceci. Je n'ai pas mentionné les déploiements de migration de base de données car cela nécessite une planification minutieuse, mais ci-dessous, je vais décrire comment Dark gère cela.
Il existe de nombreux composants ici, et beaucoup d'entre eux peuvent facilement ralentir, planter, provoquer une concurrence temporaire ou faire tomber le système de travail.
Et puisque ces pipelines sont presque toujours créés pour une occasion spéciale, il est difficile de s'y fier. Beaucoup de gens ont des jours où le code ne peut pas être déployé, car il y a des problèmes dans le Dockerfile, l'une des dizaines de services en panne ou le bon spécialiste en vacances.
Pire encore, bon nombre de ces étapes ne font rien du tout. Nous en avions besoin auparavant lorsque nous avons déployé le code immédiatement pour les utilisateurs, mais nous avons maintenant des commutateurs pour le nouveau code, et ces processus sont divisés. En conséquence, l'étape à laquelle le code est déployé (l'ancien est remplacé par le nouveau) est maintenant devenue un risque supplémentaire.
Bien sûr, c'est un pipeline très réfléchi. L'équipe qui l'a créé a pris du temps et de l'argent pour se déployer rapidement. Les pipelines de déploiement sont généralement beaucoup plus lents et plus peu fiables.
Implémentation de la livraison continue dans l'obscurité
La livraison continue est si importante pour Dark que nous visons le temps en moins d'une seconde. Nous avons parcouru toutes les étapes du pipeline pour supprimer tout ce qui n'était pas nécessaire et nous avons pensé au reste. C'est ainsi que nous avons supprimé les étapes.
Jessie Frazelle a inventé le nouveau mot sans déploiement lors de la conférence Future of Software Development à Reykjavik
Nous avons immédiatement décidé que Dark serait basé sur le concept de «sans déploiement» (merci à Jesse Frazel pour le néologisme). Sans déploiement signifie que tout code est instantanément déployé et prêt à être utilisé en production. Bien sûr, nous ne manquerons pas un code défectueux ou incomplet (je décrirai les principes de sécurité ci-dessous).
Lors de la démonstration Dark, on nous a souvent demandé comment nous avions réussi à accélérer le déploiement. Étrange question. Les gens pensent probablement que nous avons mis au point une sorte de supertechnologie qui compare le code, le compile, l'emballe dans un conteneur, lance une machine virtuelle, lance un conteneur sur une machine froide et des trucs comme ça - et tout cela en 50 ms. Ce n'est guère possible. Mais nous avons créé un moteur de déploiement spécial, qui n'a pas besoin de tout cela.
Dark lance des interprètes dans le cloud. Supposons que vous écriviez du code dans une fonction ou un gestionnaire pour HTTP ou des événements. Nous envoyons diff à l'arborescence de syntaxe abstraite (l'implémentation du code utilisé en interne par notre éditeur et nos serveurs) à nos serveurs, puis exécutons ce code lorsque les demandes sont reçues. Le déploiement ressemble donc à un enregistrement modeste dans la base de données - instantané et élémentaire. Le déploiement est si rapide car il inclut le strict minimum.
À l'avenir, nous prévoyons de créer un compilateur d'infrastructure à partir de Dark, qui créera et exécutera l'infrastructure idéale pour des performances et une fiabilité élevées des applications. Le déploiement instantané, bien sûr, ne va nulle part.
Déploiement sécurisé
Éditeur structuré
Le code dans Dark est écrit dans l'éditeur Dark. L'éditeur structuré ne fait pas d'erreurs de syntaxe. En fait, Dark n'a même pas d'analyseur. Au fur et à mesure que vous tapez, nous travaillons directement avec l'arbre de syntaxe abstraite (AST) comme Paredit , Sketch-n-Sketch , Tofu , Prune et MPS .
Tout code incomplet dans Dark a une sémantique d'exécution valide, un peu comme les trous tapés dans Hazel . Par exemple, si vous modifiez un appel de fonction, nous conservons l'ancienne fonction jusqu'à ce que la nouvelle devienne utilisable.
Chaque programme dans Dark a sa propre signification, donc le code incomplet n'interfère pas avec le travail fini.
Modes d'édition
Vous écrivez du code dans Dark dans deux cas. Premièrement: vous écrivez un nouveau code et êtes le seul utilisateur. Par exemple, il se trouve dans le REPL, et les autres utilisateurs n'y auront jamais accès, ou c'est une nouvelle route HTTP à laquelle vous ne faites référence nulle part. Vous pouvez travailler ici sans aucune précaution, et maintenant vous travaillez approximativement dans l'environnement de développement.
Deuxième situation: le code est déjà utilisé. Si le trafic passe par le code (fonctions, gestionnaires d'événements, bases de données, type), il faut faire attention. Pour ce faire, nous bloquons tout le code utilisé et demandons l'utilisation d'outils plus structurés pour le modifier. Je vais parler des outils structurels ci-dessous: des commutateurs de fonction pour HTTP et les gestionnaires d'événements, une puissante plate-forme de migration pour les bases de données et une nouvelle méthode de contrôle de version pour les fonctions et les types.
Commutateurs de fonction
Une façon de supprimer la complexité supplémentaire dans Dark est de résoudre plusieurs problèmes avec une seule solution. Les commutateurs de fonction effectuent de nombreuses tâches différentes: remplacement de l'environnement de développement local, branches git, déploiement de code et, bien sûr, la publication traditionnelle lente et contrôlée de nouveau code.
La création et le déploiement d'un commutateur de fonction se fait dans notre éditeur en une seule opération. Il crée un espace vide pour le nouveau code et fournit des contrôles d'accès pour l'ancien et le nouveau code, ainsi que des boutons et des commandes pour une transition progressive vers le nouveau code ou son exclusion.
Les commutateurs de fonction sont intégrés dans le langage sombre, et même les commutateurs incomplets accomplissent leur tâche - si la condition dans le commutateur n'est pas remplie, l'ancien code bloqué sera exécuté.
Environnement de développement
Les commutateurs de fonction remplacent l'environnement de développement local. Aujourd'hui, il est difficile pour les équipes de s'assurer que tout le monde utilise les mêmes versions d'outils et de bibliothèques (formateurs de code, linters, gestionnaires de packages, compilateurs, préprocesseurs, outils de test, etc.) Avec Dark, vous n'avez pas besoin d'installer les dépendances localement, de contrôler l'installation locale de Docker ou prendre d'autres mesures pour assurer au moins un semblant d'égalité entre l'environnement de développement et la production. Étant donné qu'une telle égalité est encore impossible , nous ne prétendrons même pas que nous nous y efforçons.
Au lieu de créer un environnement local cloné, les commutateurs dans Dark créent un nouveau sandbox en production qui remplace l'environnement de développement. À l'avenir, nous prévoyons également de créer un sandbox pour d'autres parties de l'application (par exemple, les clones de bases de données instantanées), bien que cela ne semble pas si important pour l'instant.
Succursales et déploiements
Il existe maintenant plusieurs façons d'entrer un nouveau code dans les systèmes: les branches git, la phase de déploiement et les commutateurs de fonction. Ils résolvent un problème dans différentes parties du flux de travail: git - aux étapes avant le déploiement, déploiement - au moment de la transition de l'ancien code au nouveau, et commutateurs de fonction - pour la libération contrôlée du nouveau code.
Le moyen le plus efficace est les commutateurs de fonction (en même temps les plus faciles à comprendre et à utiliser). Avec eux, vous pouvez abandonner complètement les deux autres méthodes. Il est particulièrement utile de supprimer le déploiement - si nous utilisons de toute façon des commutateurs de fonction pour inclure le code, l'étape de transfert des serveurs vers le nouveau code ne crée que des risques inutiles.
Git est difficile à utiliser, surtout pour les débutants, et il le limite vraiment, mais il a des branches pratiques. Nous avons corrigé de nombreux défauts de git. Dark est édité en temps réel et offre la possibilité de travailler ensemble dans le style de Google Docs, afin que vous n'ayez pas à envoyer de code et que vous puissiez moins souvent effectuer une relocalisation et une fusion.
Les commutateurs de fonctionnalités sous-tendent le déploiement sécurisé. Associés à des déploiements instantanés, ils vous permettent de tester rapidement des concepts en petits fragments à faible risque, au lieu d'appliquer un changement majeur susceptible de faire tomber le système.
Versioning
Pour changer les fonctions et les types, nous utilisons le versioning. Si vous souhaitez modifier une fonction, Dark crée une nouvelle version de cette fonction. Ensuite, vous pouvez appeler cette version à l'aide du commutateur dans le gestionnaire HTTP ou d'événements. (Si cette fonction est profondément dans le graphique d'appel, une nouvelle version de chaque fonction est créée dans le processus. Cela peut sembler trop, mais les fonctions n'interfèrent pas si vous ne les utilisez pas, donc vous ne le remarquerez même pas.)
Pour les mêmes raisons, nous proposons des types de version. Nous avons parlé de notre système de type en détail dans un précédent post .
En fonction des versions et des types de versions, vous pouvez modifier progressivement l'application. Vous pouvez vérifier que chaque gestionnaire individuel fonctionne avec la nouvelle version, vous n'avez pas besoin d'apporter immédiatement toutes les modifications aux applications (mais nous avons des outils pour le faire rapidement si vous le souhaitez).
C'est beaucoup plus sûr que de déployer tout en une seule fois, comme c'est le cas actuellement.
Nouvelles versions de packages et bibliothèque standard
Lorsque vous mettez à jour un package dans Dark, nous ne remplaçons pas immédiatement l'utilisation de chaque fonction ou type dans la base de code entière. Ce n'est pas sûr. Le code continue d'utiliser la même version qu'il a utilisé et vous mettez à jour l'utilisation des fonctions et des types vers une nouvelle version pour chaque cas individuel à l'aide des commutateurs.

Une capture d'écran d'une partie d'un processus automatique dans Dark montrant deux versions de la fonction Dict :: get. Dict :: get_v0 a renvoyé le type Any (ce que nous refusons) et Dict :: get_v1 a renvoyé le type Option.
Nous fournissons souvent une nouvelle fonctionnalité dans la bibliothèque standard et excluons les anciennes versions. Les utilisateurs ayant d'anciennes versions dans le code y conserveront l'accès, mais les nouveaux utilisateurs ne pourront pas les obtenir. Nous allons fournir des outils pour transférer les utilisateurs des anciennes versions vers les nouvelles en 1 étape, et à nouveau en utilisant des commutateurs de fonction.
Dark offre également une opportunité unique: une fois que nous avons exécuté votre code de travail, nous pouvons tester les nouvelles versions nous-mêmes, en comparant la sortie des nouvelles et anciennes demandes pour vous informer des changements. Par conséquent, les mises à jour de packages, qui sont souvent effectuées à l'aveugle (ou nécessitent des tests de sécurité rigoureux), posent beaucoup moins de risques et peuvent se produire automatiquement.
Nouvelles versions sombres
La transition de Python 2 à Python 3 s'est étalée sur une décennie et reste toujours un problème. Une fois que nous avons créé Dark pour une livraison continue, ces changements de langue doivent être pris en compte.
Lorsque nous apportons de petites modifications à la langue, nous créons une nouvelle version de Dark. L'ancien code reste dans l'ancienne version de Dark et le nouveau code est utilisé dans la nouvelle version. Pour passer à la nouvelle version de Dark, vous pouvez utiliser les commutateurs ou versions de fonctions.
Ceci est particulièrement utile étant donné que Dark est apparu récemment. De nombreuses modifications apportées à la langue ou à la bibliothèque peuvent échouer. La version progressive de la langue nous permet de faire des mises à jour mineures, c'est-à-dire que nous ne pouvons pas nous précipiter et reporter de nombreuses décisions sur la langue jusqu'à ce que nous ayons plus d'utilisateurs, et donc plus d'informations.
Migrations de bases de données
Il existe une formule standard pour une migration sécurisée des bases de données:
- Réécrire le code pour prendre en charge les nouveaux et les anciens formats
- Convertissez toutes les données dans un nouveau format
- Supprimer l'ancien accès aux données
Par conséquent, la migration de la base de données est retardée et nécessite beaucoup de ressources. Et nous accumulons des schémas obsolètes, car même des tâches simples, telles que la correction du nom d'une table ou d'une colonne, ne valent pas la peine.
Dark a une plateforme de migration de base de données efficace qui (nous l'espérons) simplifiera tellement le processus que vous n'en aurez plus peur. Tous les magasins de données dans Dark (paires clé-valeur ou tables de hachage persistantes) sont de type. Pour migrer un entrepôt de données, il vous suffit de lui affecter un nouveau type et une fonction de restauration et de restauration pour convertir les valeurs entre les deux types.
L'accès aux entrepôts de données dans Dark se fait via des noms de variable versionnés. Par exemple, le magasin de données des utilisateurs s'appellerait initialement Users-v0. Lorsqu'une nouvelle version avec un type différent est créée, le nom change en Users-v1. Si les données sont enregistrées via Users-v0 et que vous y accédez via Users-v1, la fonction de substitution est appliquée. Si les données sont enregistrées via Users-v1 et que vous y accédez via Users-v0, la fonction de restauration est utilisée.
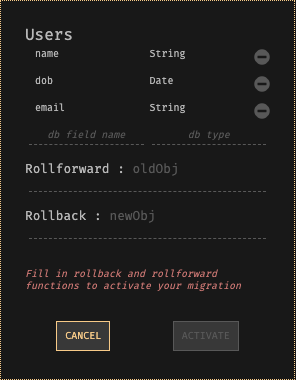
Écran de migration de la base de données avec des noms de champs pour l'ancienne base de données, des expressions de restauration et de restauration, et des instructions pour activer la migration.
Utilisez les commutateurs de fonction pour router les appels vers Users-v0 vers Users-v1. Vous pouvez effectuer ce gestionnaire HTTP à la fois pour réduire les risques, et les commutateurs fonctionnent également pour les utilisateurs individuels afin que vous puissiez vérifier que tout fonctionne comme prévu. Lorsque Users-v0 n'est pas laissé, Dark convertit toutes les données restantes en arrière-plan de l'ancien format vers le nouveau. Vous ne le remarquerez même pas.
Test
Dark est un langage de programmation fonctionnel avec un typage statique et des valeurs immuables; par conséquent, sa surface de test est nettement plus petite que les langages orientés objet avec un typage dynamique. Mais vous devez toujours tester.
Dans Dark, l'éditeur exécute automatiquement des tests unitaires en arrière-plan pour le code modifiable et, par défaut, exécute ces tests pour tous les commutateurs de fonction. À l'avenir, nous voulons utiliser les types statiques pour flouer automatiquement le code pour trouver des bogues.
De plus, Dark gère votre infrastructure en production, ce qui ouvre de nouvelles possibilités. Nous enregistrons automatiquement les requêtes HTTP dans l'infrastructure Dark (pour l'instant, nous enregistrons toutes les requêtes, mais nous voulons ensuite passer à la récupération). Nous testons de nouveaux codes sur eux et effectuons des tests unitaires, et si vous le souhaitez, vous pouvez facilement convertir des requêtes intéressantes en tests unitaires.
Ce dont nous nous sommes débarrassés
Comme nous n'avons pas de déploiement, mais qu'il existe des commutateurs de fonction, environ 60% du pipeline de déploiement reste à la mer. Nous n'avons pas besoin de branches git ou de demandes de pool, de la création de ressources et de conteneurs backend, de l'envoi de ressources et de conteneurs aux registres ou aux étapes de déploiement dans Kubernetes.
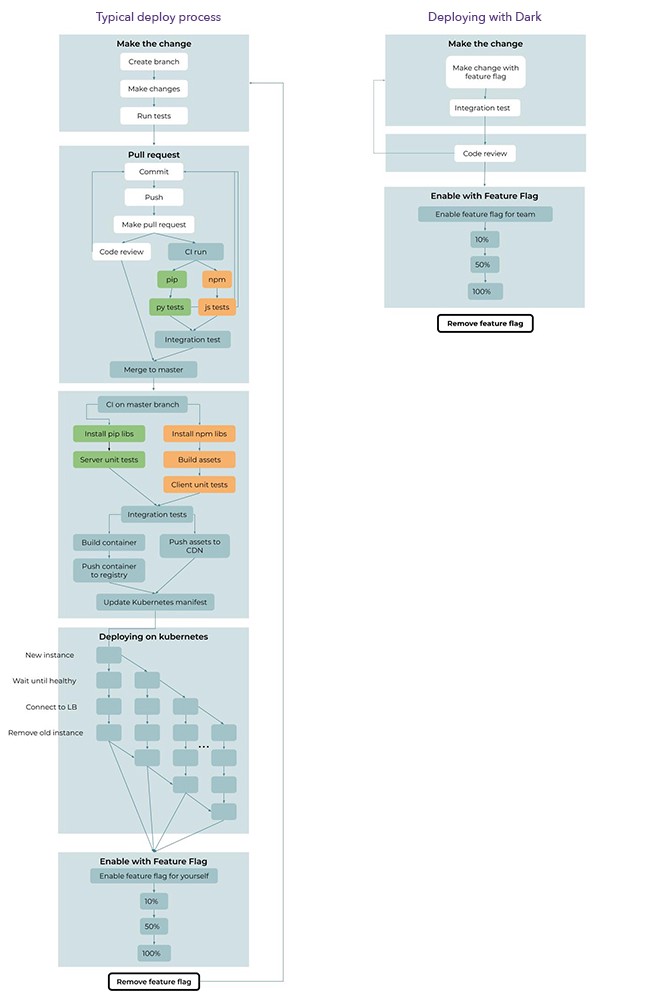
Comparaison du pipeline de livraison continue standard (à gauche) et de l'approvisionnement continu de Dark (à droite). Dans Dark, la livraison se compose de 6 étapes et d'un cycle, tandis que la version traditionnelle comprend 35 étapes et 3 cycles.
Dans Dark, il n'y a que 6 étapes et 1 cycle dans le déploiement (étapes répétées plusieurs fois), tandis que le pipeline d'approvisionnement continu moderne comprend 35 étapes et 3 cycles. Dans Dark, les tests s'exécutent automatiquement et vous ne le voyez même pas; les dépendances sont installées automatiquement; tout ce qui concerne git ou github n'est plus nécessaire; Il n'est pas nécessaire de collecter, tester et envoyer des conteneurs Docker; Le déploiement de Kubernetes n'est plus nécessaire.
Même les étapes restantes dans Dark sont devenues plus faciles. Étant donné que les commutateurs de fonction peuvent être contrôlés en une seule action, vous n'avez pas à parcourir l'intégralité du pipeline de déploiement une deuxième fois pour supprimer l'ancien code.
Nous avons simplifié la livraison du code autant que possible, réduisant le temps et les risques de livraison continue. Nous avons également considérablement simplifié les mises à jour des packages, les migrations de bases de données, les tests, le contrôle de version, l'installation des dépendances, l'égalité entre l'environnement de développement et la production, et les mises à niveau rapides et sûres des versions linguistiques.
Je réponds aux questions à ce sujet sur HackerNews .
Pour en savoir plus sur l'appareil Dark, lisez l'article Dark , suivez-nous sur Twitter (ou moi ), ou inscrivez-vous pour une version bêta et recevez des notifications des articles suivants . Si vous venez à StrangeLoop en septembre, venez à notre lancement .