Le titre de cet article peut sembler un peu étrange. En effet: si vous travaillez dans le domaine de la Data Science en 2019, vous êtes déjà en demande. La demande de spécialistes dans ce domaine ne cesse de croître: au moment de la rédaction de ce rapport, 144 527 offres d'emploi avec le mot-clé «Data Science» ont été publiées sur LinkedIn.
Néanmoins, il vaut vraiment la peine de suivre les dernières nouvelles et tendances de l'industrie. Pour vous aider, l'équipe de
CV Compiler et moi avons analysé plusieurs centaines d'emplois Data Science en juin 2019 et déterminé quelles compétences les employeurs attendent le plus des candidats.
Compétences en Data Science les plus recherchées en 2019
Ce graphique montre les compétences que les employeurs mentionnent le plus souvent dans les emplois Data Science en 2019:
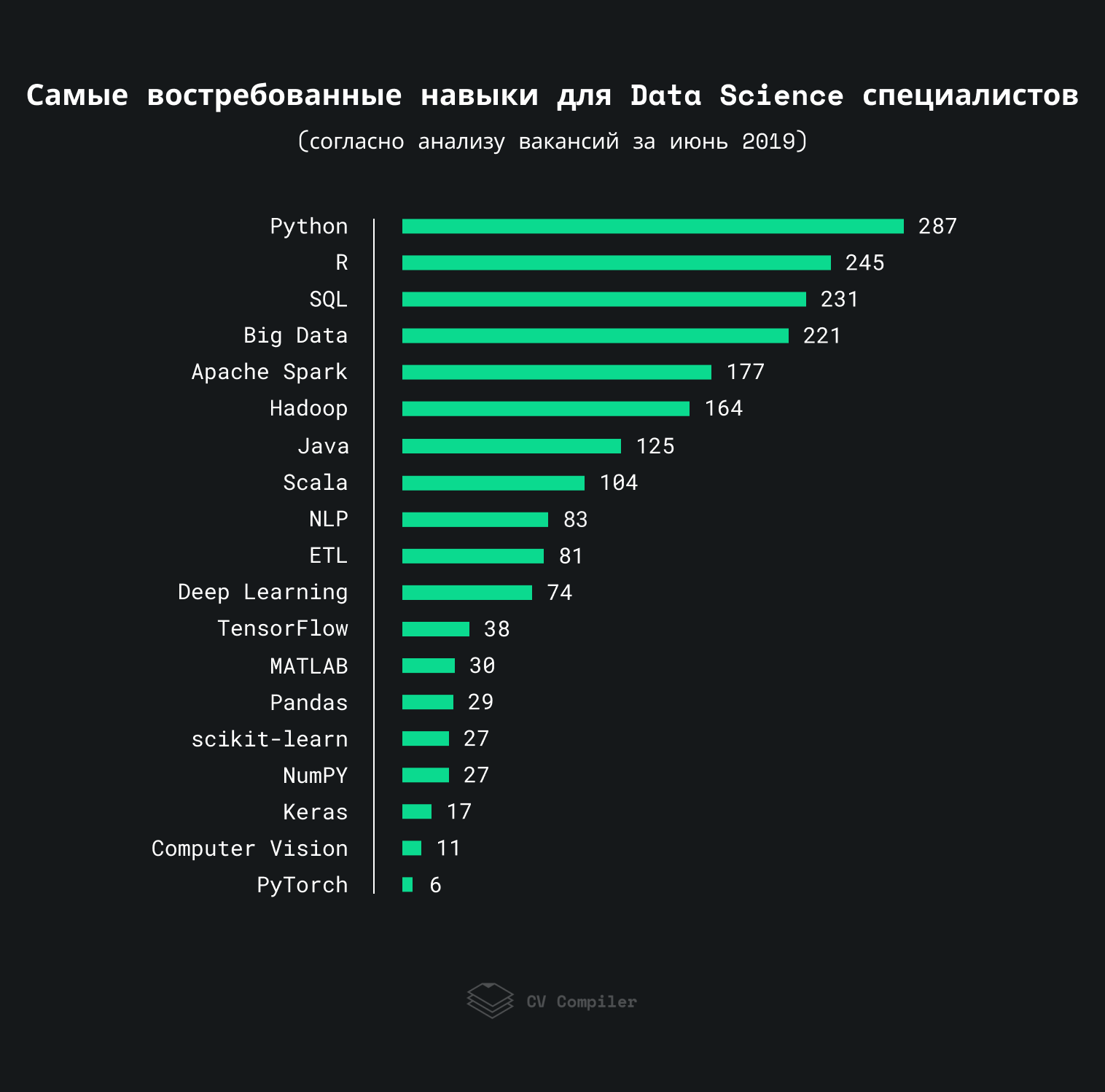
Nous avons analysé environ 300 tâches avec StackOverflow, AngelList et des ressources similaires. Certains mandats pourraient être répétés plus d'une fois dans la même vacance.
Important: Cette note démontre les préférences des employeurs plutôt que des spécialistes dans le domaine de la science des données.
Tendances clés de la science des données
De toute évidence, la science des données n'est pas principalement des frameworks et des bibliothèques, mais des connaissances fondamentales. Cependant, certaines tendances et technologies méritent d'être mentionnées.
Big data
Selon
une étude de marché du Big Data en 2018 , l'utilisation du Big Data dans les entreprises est passée de 17% en 2015 à 59% en 2018. En conséquence, la popularité des outils pour travailler avec le Big Data a augmenté. Si vous ignorez Apache Spark et Hadoop (nous parlerons de ce dernier plus en détail), les outils les plus populaires sont
MapReduce (36) et
Redshift (29).
Hadoop
Malgré la popularité de Spark et du stockage cloud, l'
ère Hadoop n'est pas encore terminée. Par conséquent, certaines entreprises s'attendent à ce que les candidats connaissent
Apache Pig (30),
HBase (32) et des technologies similaires.
HDFS (20) se retrouve également dans certains emplois.
Traitement des données en temps réel
Compte tenu de l'utilisation omniprésente de divers capteurs et appareils mobiles, ainsi que de la popularité de l'
IoT (18), les entreprises tentent d'apprendre à traiter les données en temps réel. Par conséquent, les plates-formes de threading telles que
Apache Flink (21) sont populaires auprès des employeurs.
Ingénierie des fonctionnalités et réglage des hyperparamètres
La préparation des données et la sélection des paramètres du modèle est une partie importante du travail de tout spécialiste dans le domaine de la science des données. Par conséquent, le terme
Data Mining (128) est très populaire parmi les employeurs. Certaines entreprises prêtent également attention à l'
Hyperparameter Tuning (21) (un terme comme
Feature Engineering ne doit pas être oublié non plus ). La sélection des paramètres optimaux pour le modèle est importante, car les performances globales du modèle dépendent du succès de cette opération.
Visualisation des données
La capacité de traiter correctement les données et d'afficher les modèles nécessaires est importante. Cependant,
la visualisation des données (55) est une compétence tout aussi importante. Vous devez être en mesure de présenter les résultats de votre travail dans un format compréhensible pour tout membre de l'équipe ou client. En termes d'outils de visualisation des données, les employeurs préfèrent
Tableau (54).
Tendances générales
Dans les postes vacants, nous sommes également
tombés sur des termes tels que
AWS (86),
Docker (36), ainsi que
Kubernetes (24). On peut conclure que les tendances générales dans le domaine du développement de logiciels ont lentement migré vers le domaine de la science des données.
Opinion d'expert
Cette liste de technologies reflète vraiment l'état réel des choses dans le monde de la science des données. Cependant, il n'y a rien de moins important que d'écrire du code. C'est la capacité d'interpréter correctement les résultats de leur travail, ainsi que de les visualiser et de les présenter sous une forme compréhensible. Tout dépend du public - si vous parlez de vos réalisations à des candidats scientifiques, parlez leur langue, mais si vous présentez les résultats au client, il ne se souciera pas du code - seulement du résultat que vous avez obtenu.
Carla Gentry
Data Scientist, propriétaire de
Analytical SolutionLinkedIn |
TwitterCe graphique montre les tendances actuelles dans le domaine de la science des données, mais il est plutôt difficile de prédire l'avenir en fonction de cela. J'ai tendance à croire que la popularité de R diminuera (comme la popularité de MATLAB), tandis que la popularité de Python ne fera qu'augmenter. Hadoop et Big Data se sont également retrouvés sur la liste par inertie: Hadoop va bientôt disparaître (plus personne n'investit sérieusement dans cette technologie), et le Big Data a cessé d'être une tendance à la hausse. L'avenir de Scala n'est pas entièrement clair: Google prend officiellement en charge Kotlin, qui est beaucoup plus facile à apprendre. Je suis également sceptique quant à l'avenir de TensorFlow: la communauté scientifique préfère PyTorch, et l'influence de la communauté scientifique dans le domaine de la Data Science est beaucoup plus élevée que dans tous les autres domaines. (Ceci est mon opinion personnelle, qui peut ne pas coïncider avec l'opinion de Gartner).
Andrey Burkov,
Directeur du Machine Learning chez Gartner,
auteur du
livre d'apprentissage automatique de cent pages .
LinkedInPyTorch est le moteur de l'apprentissage renforcé, ainsi qu'un cadre solide pour l'exécution de code parallèle sur plusieurs GPU (ce qui n'est pas le cas avec TensorFlow). PyTorch aide également à créer des graphiques dynamiques qui sont efficaces lorsque vous travaillez avec des réseaux de neurones récurrents. TensorFlow fonctionne avec des graphiques statiques et est plus difficile à étudier, mais il est utilisé par plus de développeurs et de chercheurs. Cependant, PyTorch est plus proche de Python en termes de débogage de code et de bibliothèques pour la visualisation des données (matplotlib, seaborn). La plupart des outils de débogage de code Python peuvent être utilisés pour déboguer du code PyTorch. TensorFlow possède également son propre outil de débogage - tfdbg.
Ganapati Pulipaka,
Chief Data Scientist chez Accenture,
Gagnant du Top 50 Tech Leader Award.
LinkedIn |
TwitterÀ mon avis, le travail et la carrière en Data Science ne sont pas la même chose. Pour travailler, vous aurez besoin de l'ensemble des compétences ci-dessus, mais pour bâtir une carrière réussie en science des données, la compétence la plus importante est la capacité d'apprendre. La science des données est un domaine capricieux, et vous devrez apprendre à maîtriser les nouvelles technologies, les outils et les approches afin de suivre le rythme. Poser constamment de nouveaux défis et essayer de ne pas «se contenter de peu».
Lon Riesberg
Fondateur / Conservateur de
Data Elixir ,
ex-nasa.
Twitter |
LinkedInLa science des données est un domaine en développement rapide et complexe dans lequel les connaissances fondamentales sont aussi importantes que l'expérience avec certains outils. Nous espérons que cet article vous aidera à déterminer quelles compétences sont nécessaires pour devenir un spécialiste plus recherché dans le domaine de la science des données en 2019. Bonne chance!
Cet article a été écrit par l'équipe de CV Compiler , un outil pour améliorer les CV pour la science des données et d'autres professionnels de l'informatique.