
Au cours des dernières années, les bases de données chronologiques sont passées d'une chose curieuse (hautement spécialisée dans les systèmes de surveillance ouverts (et liés à des solutions spécifiques) ou aux projets Big Data) à un «bien de consommation». Sur le territoire de la Fédération de Russie, des remerciements particuliers doivent être adressés à Yandex et ClickHouse pour cela. Jusqu'à présent, si vous aviez besoin d'enregistrer une grande quantité de données de séries chronologiques, vous deviez soit accepter la nécessité de soulever une pile Hadoop monstrueuse et l'accompagner, soit communiquer avec des protocoles spécifiques à chaque système.
Il peut sembler qu'en 2019, un article sur lequel le TSDB devrait être utilisé se composera d'une seule phrase: «utilisez simplement ClickHouse». Mais ... il y a des nuances.
En effet, ClickHouse se développe activement, la base d'utilisateurs augmente et le soutien est très actif, mais sommes-nous devenus les otages du succès public de ClickHouse, qui a éclipsé d'autres solutions, peut-être plus efficaces / fiables?
Au début de l'année dernière, nous avons commencé à traiter notre propre système de surveillance, au cours duquel la question s'est posée de choisir la base de données appropriée pour le stockage des données. Je veux raconter ici l'histoire de ce choix.
Énoncé du problème
Tout d'abord, la préface nécessaire. Pourquoi avons-nous besoin de notre propre système de surveillance et comment a-t-il été organisé?
Nous avons commencé à fournir des services de support en 2008, et en 2010, il est devenu clair qu'il était difficile d'agréger les données sur les processus se produisant dans l'infrastructure client avec les solutions qui existaient à l'époque (nous parlons, Dieu me pardonne, Cacti, Zabbix et le nouveau-né Graphite).
Nos principales exigences étaient:
- prise en charge (à l'époque - des dizaines, et à l'avenir - des centaines) de clients au sein d'un même système et en même temps la présence d'un système centralisé de gestion des alertes;
- flexibilité dans la gestion du système d'alerte (escalade d'alertes entre préposés, comptabilité horaire, base de connaissances);
- la possibilité de détailler en profondeur les graphiques (Zabbix à l'époque dessinait des graphiques sous forme d'images);
- stockage à long terme d'une grande quantité de données (un an ou plus) et possibilité de les sélectionner rapidement.
Dans cet article, nous nous intéressons au dernier point.
En ce qui concerne le stockage, les exigences étaient les suivantes:
- le système devrait fonctionner rapidement;
- il est souhaitable que le système ait une interface SQL;
- le système doit être stable et avoir une base d'utilisateurs et un support actifs (une fois que nous avons été confrontés à la nécessité de prendre en charge des systèmes tels que, par exemple, MemcacheDB, que nous avons cessé de développer, ou le stockage distribué MooseFS, dont le bugtracker a été effectué en chinois: répéter cette histoire pour notre projet ne voulait pas);
- Correspondance avec le théorème de la PAC: cohérence (nécessaire) - les données doivent être pertinentes, nous ne voulons pas que le système de gestion des notifications ne reçoive pas de nouvelles données et ne crache pas d'alertes sur la non-arrivée de données pour tous les projets; Tolérance de partition (nécessaire) - nous ne voulons pas obtenir de systèmes Split Brain; Disponibilité (non critique, dans le cas d'une réplique active) - nous pouvons passer nous-mêmes au système de sauvegarde en cas d'accident, avec un code.
Curieusement, à cette époque, MySQL était la solution parfaite pour nous. Notre structure de données était extrêmement simple: identifiant du serveur, identifiant du compteur, horodatage et valeur; l'échantillonnage rapide des données chaudes a été fourni par un grand pool de tampons, et l'échantillonnage des données historiques a été fourni par SSD.
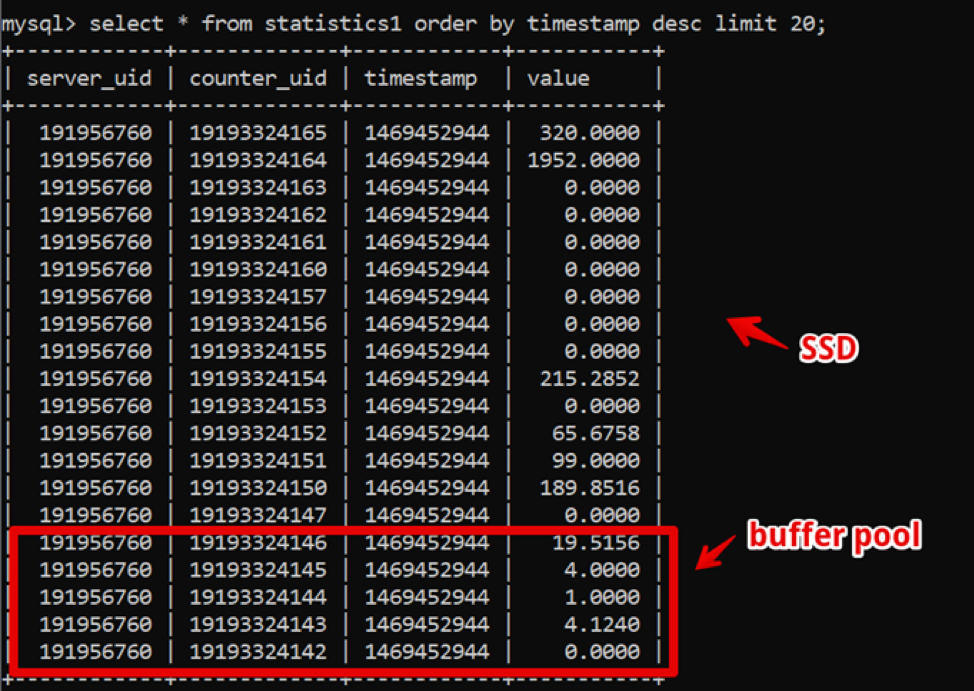
Ainsi, nous avons réalisé un échantillonnage de nouvelles données de deux semaines, avec des détails jusqu'à 200 secondes avant que les données soient complètement restituées, et avons vécu dans ce système pendant un certain temps.
Pendant ce temps, le temps a passé et la quantité de données a augmenté. En 2016, les volumes de données ont atteint des dizaines de téraoctets, ce qui en termes de stockage SSD loué représentait une dépense importante.
À ce stade, les bases de données en colonnes se propageaient activement, ce à quoi nous avons commencé à réfléchir activement: dans les bases de données en colonnes, les données sont stockées, comme vous pouvez le comprendre, dans des colonnes, et si vous regardez nos données, il est facile de voir un grand nombre de prises qui pourraient être Si vous utilisez une base de données de colonnes, compressez avec compression.
Cependant, le système clé pour le travail de l'entreprise a continué de fonctionner de manière stable, et je ne voulais pas expérimenter la transition vers autre chose.
En 2017, lors de la conférence Percona Live à San Jose, probablement la première fois que les développeurs de Clickhouse s'annonçaient. À première vue, le système était prêt pour la production (enfin, Yandex.Metrica est une production sévère), le support était rapide et simple et, surtout, l'opération était simple. Depuis 2018, nous avons entamé le processus de transition. Mais à ce moment-là, il y avait beaucoup de systèmes TSDB «adultes» et testés dans le temps, et nous avons décidé d'allouer beaucoup de temps et de comparer les alternatives afin de nous assurer qu'il n'y avait pas de solutions Clickhouse alternatives, selon nos besoins.
En plus des besoins de stockage déjà indiqués, de nouveaux sont apparus:
- le nouveau système devrait fournir au moins les mêmes performances que MySQL, sur la même quantité de fer;
- le stockage du nouveau système devrait occuper beaucoup moins d'espace;
- Le SGBD devrait toujours être facile à gérer;
- Je voulais minimiser l'application lors du changement du SGBD.
Quels systèmes nous avons commencé à considérer
Apache Hive / Apache ImpalaAncienne pile Hadoop battue. En fait, il s'agit d'une interface SQL construite en plus de stocker des données dans des formats natifs sur HDFS.
Pour.
- Avec un fonctionnement stable, il est très facile de mettre à l'échelle les données.
- Il existe des solutions de colonnes pour le stockage des données (moins d'espace).
- Exécution très rapide de tâches parallèles en présence de ressources.
Inconvénients
- Il s'agit d'un Hadoop et il est difficile à utiliser. Si nous ne sommes pas prêts à prendre une solution prête à l'emploi dans le cloud (et nous ne sommes pas prêts pour le coût), toute la pile devra être assemblée et prise en charge par les administrateurs, mais je ne le veux vraiment pas.
- Les données sont agrégées très rapidement .
Cependant:

La vitesse est atteinte en faisant évoluer le nombre de serveurs informatiques. En termes simples, si nous sommes une grande entreprise engagée dans l'analyse et les affaires, il est extrêmement important d'agréger les informations le plus rapidement possible (même au prix d'utiliser un grand nombre de ressources informatiques) - cela peut être notre choix. Mais nous n'étions pas prêts à multiplier le parc de fer pour accélérer les tâches.
Druide / pinotDéjà beaucoup plus sur TSDB en particulier, mais encore une fois - Hadoop-stack.
Il y a un
excellent article comparant les avantages et les inconvénients de Druid et Pinot par rapport à ClickHouse .
En quelques mots: Druid / Pinot sont plus beaux que Clickhouse dans les cas où:
- Vous avez une nature hétérogène des données (dans notre cas, nous enregistrons uniquement la série temporelle des métriques du serveur, et, en fait, il s'agit d'un seul tableau. Mais il peut y avoir d'autres cas: séries chronologiques d'équipement, séries chronologiques économiques, etc. - chacune ayant sa propre structure, qui doivent être agrégées et traitées).
- De plus, il y a beaucoup de ces données.
- Des tableaux et des données avec des séries chronologiques apparaissent et disparaissent (c'est-à-dire qu'une sorte d'ensemble de données est entré, il a été analysé et supprimé).
- Il n'y a pas de critère clair selon lequel les données peuvent être partitionnées.
Dans les cas opposés, ClickHouse se montre mieux, et c'est notre cas.
Clickhouse- Similaire à SQL.
- Facile à gérer.
- Les gens disent que ça marche.
Il fait partie de la liste restreinte des tests.
InfluxdbAlternative étrangère à ClickHouse. Parmi les inconvénients: la haute disponibilité n'est présente que dans la version commerciale, mais elle doit être comparée.
Il fait partie de la liste restreinte des tests.
CassandraD'une part, nous savons qu'il est utilisé pour stocker des séries temporelles métriques par des systèmes de surveillance tels que, par exemple,
SignalFX ou OkMeter. Cependant, il y a des détails.
Cassandra n'est pas une base de données de colonnes au sens habituel. Il ressemble plus à une minuscule, mais chaque ligne peut avoir un nombre différent de colonnes, ce qui permet d'organiser facilement une représentation de colonne. En ce sens, il est clair qu'avec une limite de 2 milliards de colonnes, vous pouvez stocker certaines données dans les colonnes (oui, la même série temporelle). Par exemple, dans MySQL, il y a une limite de 4096 colonnes et il est facile de tomber sur une erreur avec le code 1117 si vous essayez de faire de même.
Le moteur Cassandra se concentre sur le stockage de grandes quantités de données dans un système distribué sans assistant, et dans le théorème CAP ci-dessus, Cassandra se concentre davantage sur AP, c'est-à-dire sur l'accessibilité des données et la résistance au partitionnement. Ainsi, cet outil peut être formidable si vous n'avez qu'à écrire dans cette base de données et à en lire rarement. Et ici, il est logique d’utiliser Cassandra comme stockage «froid». C'est-à-dire, comme un endroit fiable à long terme pour stocker de grandes quantités de données historiques qui sont rarement nécessaires, mais peuvent être obtenues si nécessaire. Néanmoins, par souci d'exhaustivité, nous allons le tester. Mais, comme je l'ai dit plus tôt, nous ne souhaitons pas réécrire activement le code de la solution DB sélectionnée, nous allons donc le tester quelque peu limité - sans adapter la structure de la base de données aux spécificités de Cassandra.
ProméthéeEh bien, et par intérêt, nous avons décidé de tester les performances de la boutique Prometheus - juste pour comprendre si nous sommes plus rapides que les solutions actuelles ou plus lentes et combien.
Méthodologie et résultats des tests
Nous avons donc testé 5 bases de données dans les 6 configurations suivantes: ClickHouse (1 nœud), ClickHouse (table distribuée de 3 nœuds), InfluxDB, Mysql 8, Cassandra (3 nœuds) et Prometheus. Le plan de test est le suivant:
- remplir les données historiques de la semaine (840 millions de valeurs par jour; 208 000 métriques);
- générer une charge d'enregistrement (6 modes de charge ont été considérés, voir ci-dessous);
- parallèlement à l'enregistrement, nous réalisons périodiquement des échantillons, en émulant les demandes d'un utilisateur travaillant avec des graphiques. Afin de ne pas trop compliquer les choses, nous avons sélectionné les données par 10 mesures (tout autant sur le graphique du processeur) par semaine.
Nous chargeons en émulant le comportement de notre agent de surveillance, qui envoie des valeurs à chaque métrique toutes les 15 secondes. Dans ce cas, nous souhaitons varier:
- nombre total de mesures dans lesquelles les données sont écrites;
- intervalle d'envoi de valeurs dans une métrique;
- taille du lot.
À propos de la taille du lot. Comme il n'est pas recommandé de charger presque toutes nos bases expérimentales avec des insertions uniques, nous aurons besoin d'un relais, qui collecte les métriques entrantes et les regroupe autant que possible et les écrit sur la base avec une insertion de paquet.
De plus, afin de mieux comprendre comment interpréter les données reçues plus tard, imaginez que nous n'envoyons pas seulement un tas de métriques, mais les métriques sont organisées en serveurs - 125 métriques par serveur. Ici, le serveur n'est qu'une entité virtuelle - juste pour comprendre que, par exemple, 10 000 mesures correspondent à environ 80 serveurs.
Et donc, en tenant compte de tout cela, nos 6 modes de charge d'enregistrement de la base:
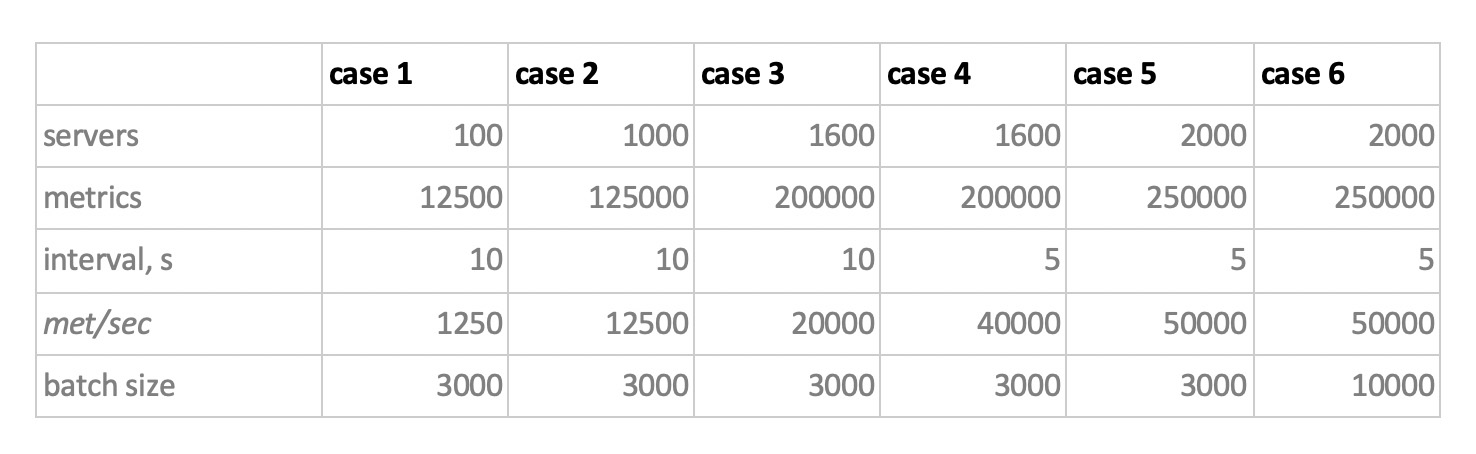
Il y a deux points. Premièrement, pour cassandra, ces tailles de lots se sont avérées trop importantes, nous avons utilisé des valeurs de 50 ou 100. Et deuxièmement, puisque le prometeus fonctionne strictement en mode pull, c'est-à-dire il marche et collecte des données à partir de sources métriques (et même pushgateway, malgré son nom, ne change pas fondamentalement la situation), les charges correspondantes ont été implémentées à l'aide d'une combinaison de configurations statiques.
Les résultats des tests sont les suivants:
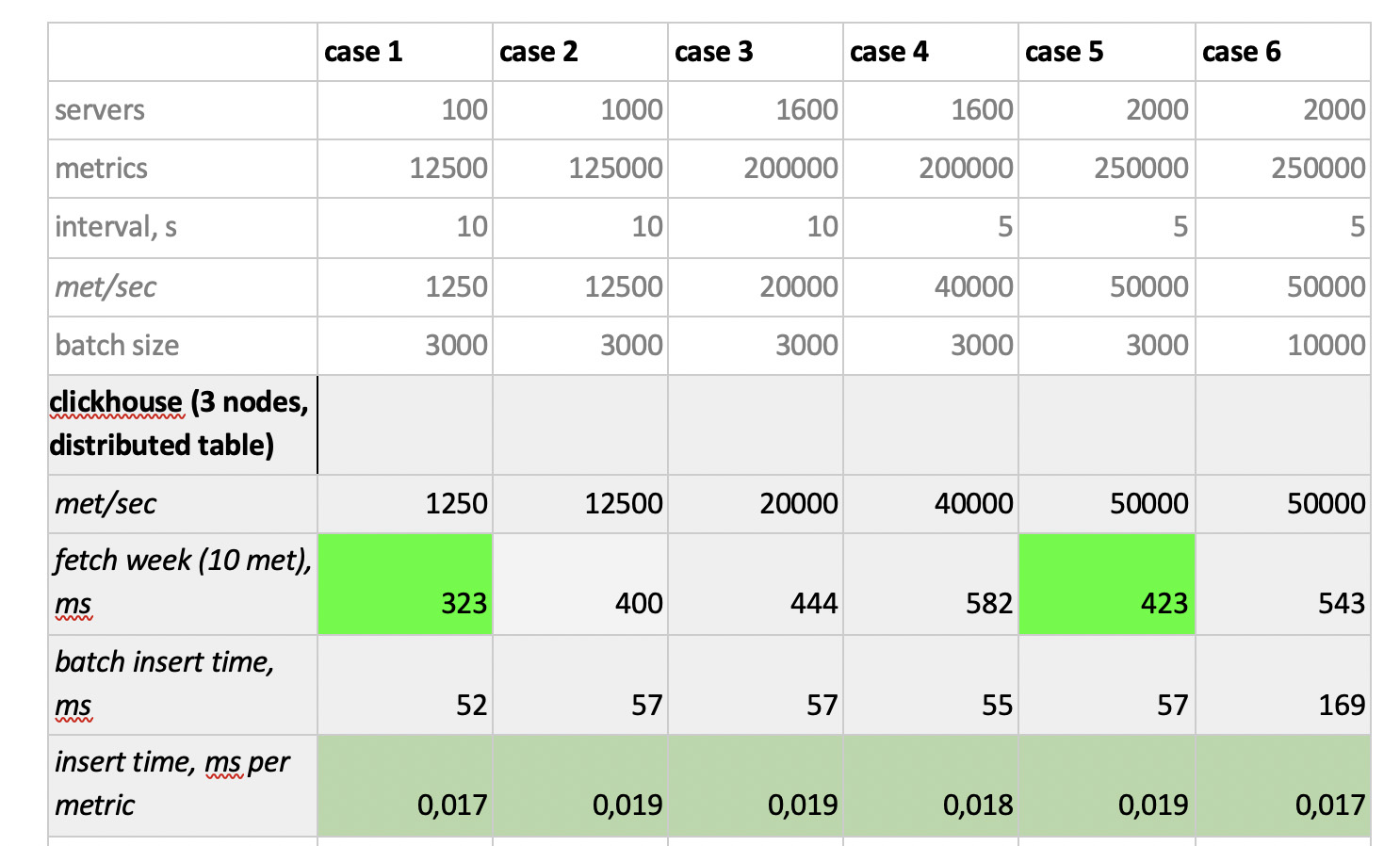
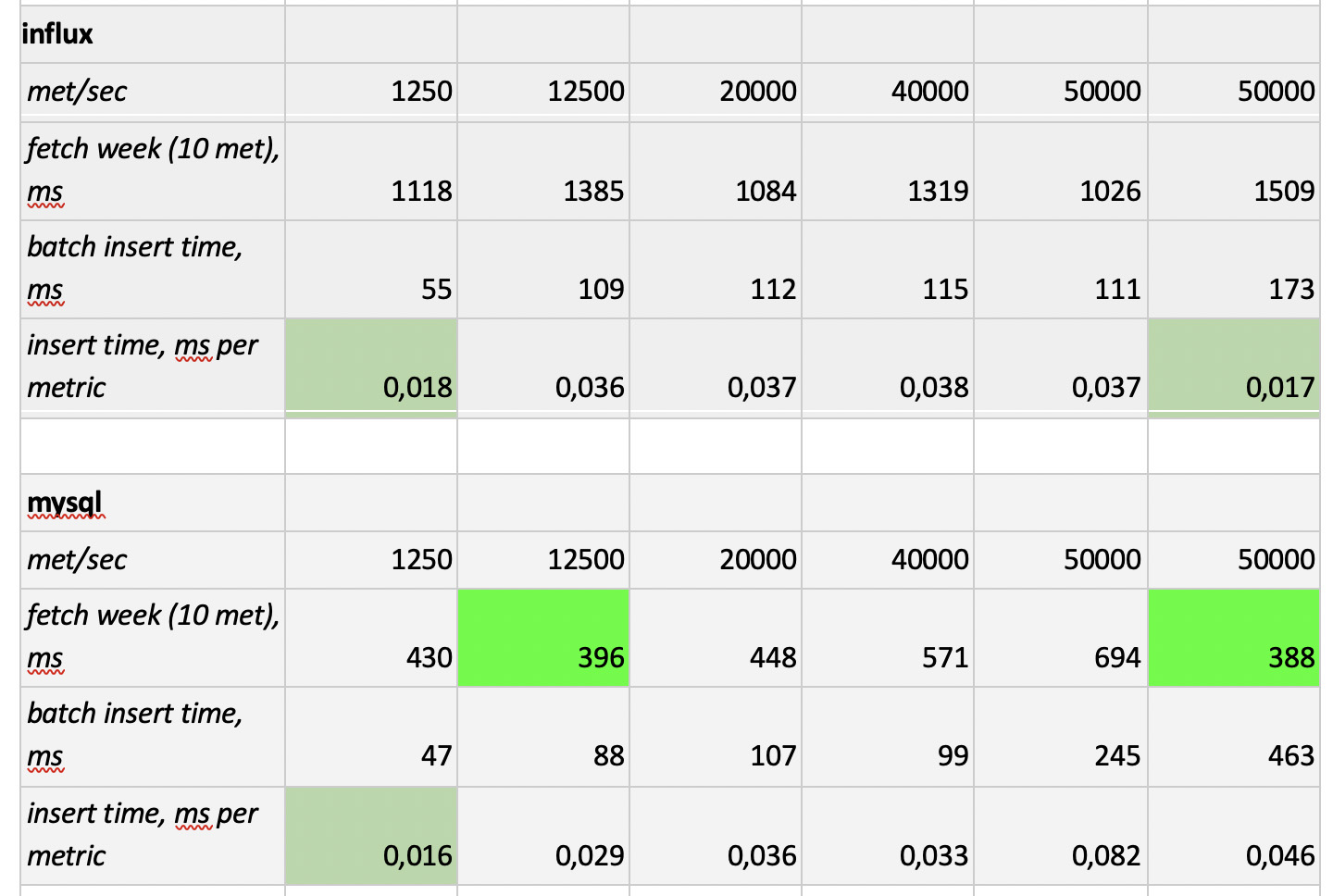
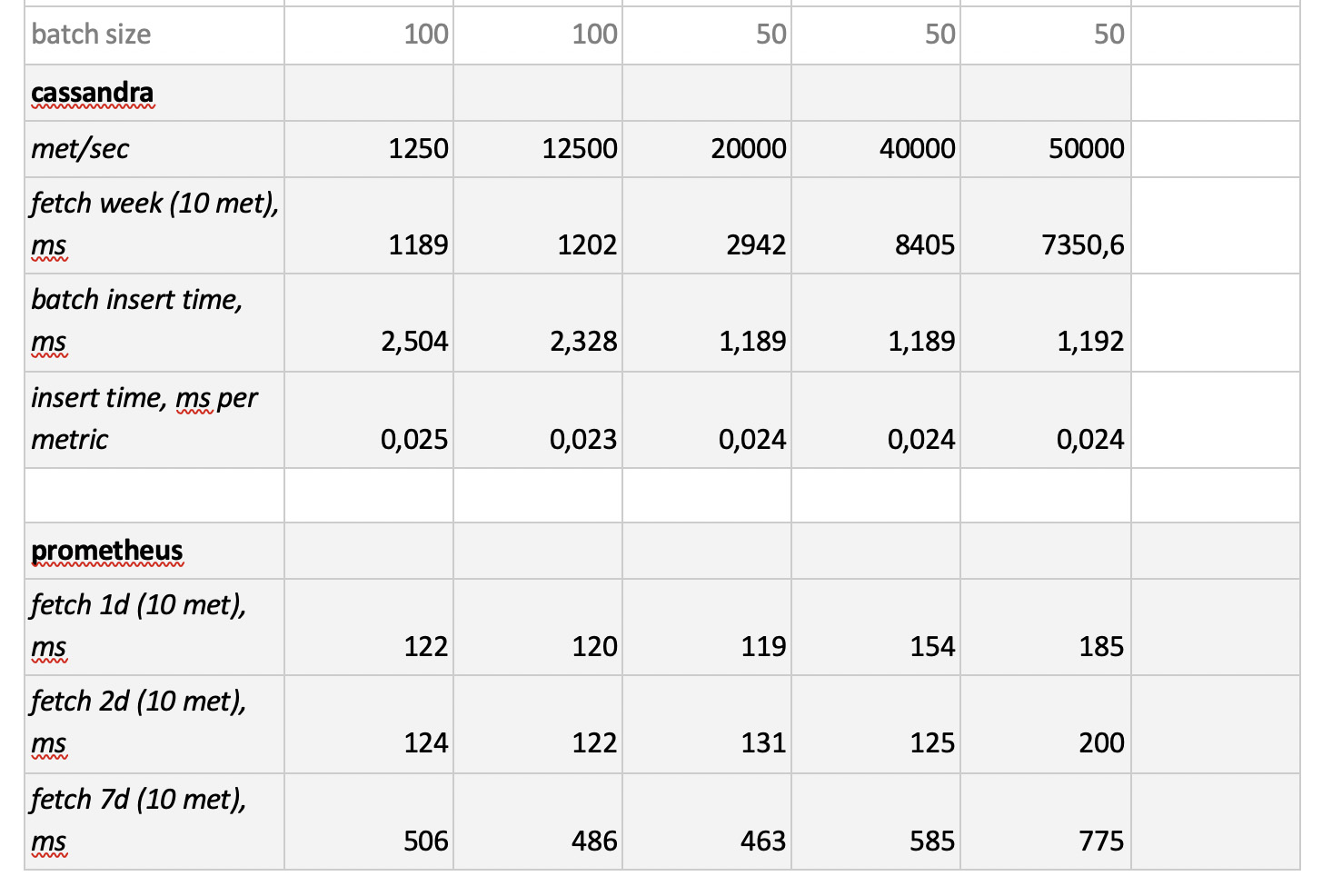 Ce qui mérite d'être noté
Ce qui mérite d'être noté : des échantillons incroyablement rapides de Prometheus, des échantillons terriblement lents de Cassandra, des échantillons inacceptablement lents d'InfluxDB; ClickHouse a gagné en termes de vitesse d'enregistrement, et Prometheus ne participe pas au concours, car il s'insère en lui-même et nous ne mesurons rien.
En conséquence : ClickHouse et InfluxDB se sont montrés les meilleurs, mais un cluster d'Influx ne peut être construit que sur la base de la version Enterprise, qui coûte de l'argent, et ClickHouse ne coûte rien et est fabriqué en Russie. Aux États-Unis, il est logique que le choix soit probablement en faveur de inInfluxDB, et dans notre cas, il est en faveur de ClickHouse.