Bienvenue, Habr!
À un moment donné, nous avons été les premiers à
introduire le thème
Kafka sur le marché russe et à continuer de
suivre son développement. En particulier, le sujet de l'interaction entre Kafka et
Kubernetes nous a semblé intéressant. Un article de revue (et plutôt prudent) à ce sujet a été publié sur le blog de la société Confluent en octobre dernier, rédigé par Gwen Shapira. Aujourd'hui, nous voulons attirer votre attention sur un article d'avril plus récent de Johann Gyger, qui, bien que non dénué de point d'interrogation dans le titre, examine le sujet de manière plus substantielle, accompagnant le texte de liens intéressants. Veuillez nous pardonner la traduction gratuite de "chaos monkey" si vous le pouvez!
Présentation
Kubernetes est conçu pour gérer des charges sans état. En règle générale, ces charges de travail sont présentées sous la forme d'une architecture de microservices, elles sont légères, bien adaptées à la mise à l'échelle horizontale, obéissent aux principes des applications à 12 facteurs et permettent de travailler avec des disjoncteurs et des singes du chaos.
Kafka, d'autre part, agit essentiellement comme une base de données distribuée. Ainsi, lorsque vous travaillez, vous devez faire face à la condition, et c'est beaucoup plus lourd qu'un microservice. Kubernetes prend en charge les charges avec état, mais comme Kelsey Hightower le fait remarquer dans deux de ses tweets, elles doivent être manipulées avec soin:
Il semble à certains que si vous lancez Kubernetes sur une charge avec état, il se transforme en une base de données entièrement gérée qui peut rivaliser avec RDS. Ce n'est pas le cas. Peut-être que si vous travaillez dur, vissez des composants supplémentaires et attirez une équipe d'ingénieurs SRE, vous pouvez installer RDS sur Kubernetes.
Je recommande toujours à tout le monde de faire preuve d'une extrême prudence lors du lancement de charges préservant l'état sur Kubernetes. La plupart de ceux qui sont intéressés par «puis-je exécuter des charges avec état sur Kubernetes» n'ont pas une expérience suffisante de travail avec Kubernetes, et souvent avec la charge qu'ils demandent.
Alors, dois-je exécuter Kafka sur Kubernetes? Contre-question: Kafka fonctionnera-t-il mieux sans Kubernetes? C'est pourquoi je tiens à souligner dans cet article comment Kafka et Kubernetes se complètent mutuellement, et quels pièges peuvent rencontrer lorsqu'ils sont combinés.
Délai de livraison
Parlons de la chose de base - l'environnement d'exécution lui-même
Le processusLes courtiers Kafka sont pratiques lorsque vous travaillez avec le CPU. TLS peut entraîner des frais généraux. Dans le même temps, les clients Kafka peuvent charger davantage le processeur s'ils utilisent le chiffrement, mais cela n'affecte pas les courtiers.
La mémoireLes courtiers de Kafka engloutissent la mémoire. La taille du tas JVM est généralement à la mode pour limiter 4 à 5 Go, mais vous aurez également besoin de beaucoup de mémoire système, car Kafka utilise très activement le cache de pages. Dans Kubernetes, définissez correctement les limites de conteneur pour les ressources et les demandes.
Entrepôt de donnéesLe stockage des données dans les conteneurs est éphémère - les données sont perdues au redémarrage. Vous pouvez utiliser le volume
emptyDir pour les données Kafka, et l'effet sera similaire: vos données de courtier seront perdues après la fin. Vos messages peuvent toujours être enregistrés sur d'autres courtiers en tant que répliques. Par conséquent, après un redémarrage, un courtier défaillant doit d'abord répliquer toutes les données, et ce processus peut prendre beaucoup de temps.
C'est pourquoi le stockage de données à long terme doit être utilisé. Qu'il s'agisse d'un stockage à long terme non local avec le système de fichiers XFS ou, plus précisément, ext4. N'utilisez pas NFS. Ai-je prévenu. Les versions NFS v3 ou v4 ne fonctionneront pas. En bref, le courtier Kafka se terminera s'il ne peut pas supprimer le répertoire de données en raison du problème de «renommage stupide» qui est pertinent dans NFS. Si je ne vous ai toujours pas convaincu,
lisez très attentivement
cet article . L'entrepôt de données doit être non local afin que Kubernetes puisse sélectionner de manière plus flexible un nouveau nœud après un redémarrage ou une relocalisation.
RéseauComme avec la plupart des systèmes distribués, les performances de Kafka dépendent beaucoup de la latence du réseau minimale et de la bande passante maximale. N'essayez pas de placer tous les courtiers sur le même nœud, car cela réduirait la disponibilité. Si le nœud Kubernetes échoue, l'ensemble du cluster Kafka échoue également. En outre, ne dispersez pas le cluster Kafka dans des centres de données entiers. Il en va de même pour le cluster Kubernetes. Un bon compromis dans ce cas est de choisir différentes zones d'accès.
La configuration
Manifestes courantsLe site Web de Kubernetes a un
très bon guide sur la façon de configurer ZooKeeper à l'aide de manifestes. Puisque ZooKeeper fait partie de Kafka, c'est à partir de là qu'il est commode de commencer à se familiariser avec les concepts de Kubernetes applicables ici. Une fois que vous avez compris cela, vous pouvez utiliser les mêmes concepts avec le cluster Kafka.
- Sub : sub est la plus petite unité déployable de Kubernetes. Le module contient votre charge de travail et le module lui-même correspond au processus de votre cluster. Un foyer contient un ou plusieurs conteneurs. Chaque serveur ZooKeeper de l'ensemble et chaque courtier du cluster Kafka fonctionneront selon une approche distincte.
- StatefulSet : StatefulSet est un objet Kubernetes qui fonctionne avec plusieurs charges de travail avec état, qui nécessitent une coordination. StatefulSet offre des garanties concernant la commande des foyers et leur caractère unique.
- Services sans tête : les services vous permettent de détacher les modules des clients à l'aide d'un nom logique. Dans ce cas, Kubernetes est responsable de l'équilibrage de charge. Cependant, lors de la maintenance de charges de travail avec état, comme dans le cas de ZooKeeper et Kafka, les clients doivent échanger des informations avec une instance spécifique. C'est là que les services sans tête sont utiles: dans ce cas, le client aura toujours un nom logique, mais vous n'aurez pas à aller directement au bas.
- Volume pour le stockage à long terme : ces volumes sont nécessaires pour la configuration du stockage à long terme sur bloc non local, qui a été mentionné ci-dessus.
Yolean fournit un ensemble complet de manifestes qui facilitent le démarrage de Kafka sur Kubernetes.
Tableaux de barreHelm est un gestionnaire de packages pour un Kubernetes, qui peut être comparé aux gestionnaires de packages pour le système d'exploitation, tels que yum, apt, Homebrew ou Chocolatey. Son utilisation est pratique pour installer des progiciels prédéfinis décrits dans les diagrammes de Helm. Un diagramme de Helm bien choisi facilite la tâche difficile: comment configurer correctement tous les paramètres pour utiliser Kafka sur Kubernetes. Il existe plusieurs diagrammes de Kafka: celui officiel est
dans un état incubateur , il y en a un de
Confluent , un de
Bitnami de plus.
Les opérateursHelm ayant certains inconvénients, un autre outil gagne en popularité: les opérateurs Kubernetes. L'opérateur n'emballe pas seulement le logiciel pour Kubernetes, mais vous permet également de déployer ce logiciel et de le gérer.
La liste des
opérateurs impressionnants mentionne deux opérateurs pour Kafka. L'un d'eux est
Strimzi . Avec l'aide de Strimzi, il est facile de lever un cluster Kafka en quelques minutes. Pratiquement aucune configuration n'est requise, de plus, l'opérateur lui-même fournit de belles fonctionnalités, par exemple le cryptage TLS de type "point à point" à l'intérieur du cluster. Confluent fournit également
son propre opérateur .
PerformancesIl est très important de tester les performances en fournissant à l'instance Kafka installée des points de contrôle. Ces tests vous aideront à identifier les goulots d'étranglement potentiels avant le début des problèmes. Heureusement, Kafka fournit déjà deux outils de test de performances:
kafka-producer-perf-test.sh et
kafka-consumer-perf-test.sh . Utilisez-les activement. Pour référence, vous pouvez vous référer aux résultats décrits dans
cet article par Jay Kreps, ou utiliser
cette critique de Stéphane Maarek Amazon MSK.
Les opérations
SuiviLa transparence du système est très importante - sinon vous ne comprendrez pas ce qui s'y passe. Aujourd'hui, il existe une solide boîte à outils qui fournit une surveillance basée sur des métriques dans le style natif du cloud. Deux outils populaires à cet effet sont Prométhée et Grafana. Prometheus peut collecter des métriques de tous les processus Java (Kafka, Zookeeper, Kafka Connect) à l'aide de l'exportateur JMX - de la manière la plus simple. Si vous ajoutez des métriques cAdvisor, vous pouvez mieux comprendre comment les ressources sont utilisées dans Kubernetes.
Strimzi a un exemple de tableau de bord Grafana très pratique pour Kafka. Il affiche des mesures clés, par exemple, sur les secteurs sous-répliqués ou ceux qui sont hors ligne. Tout y est très clair. Ces mesures sont complétées par des informations sur l'utilisation et les performances des ressources, ainsi que des indicateurs de stabilité. Ainsi, vous obtenez une surveillance de base du cluster Kafka sans raison!
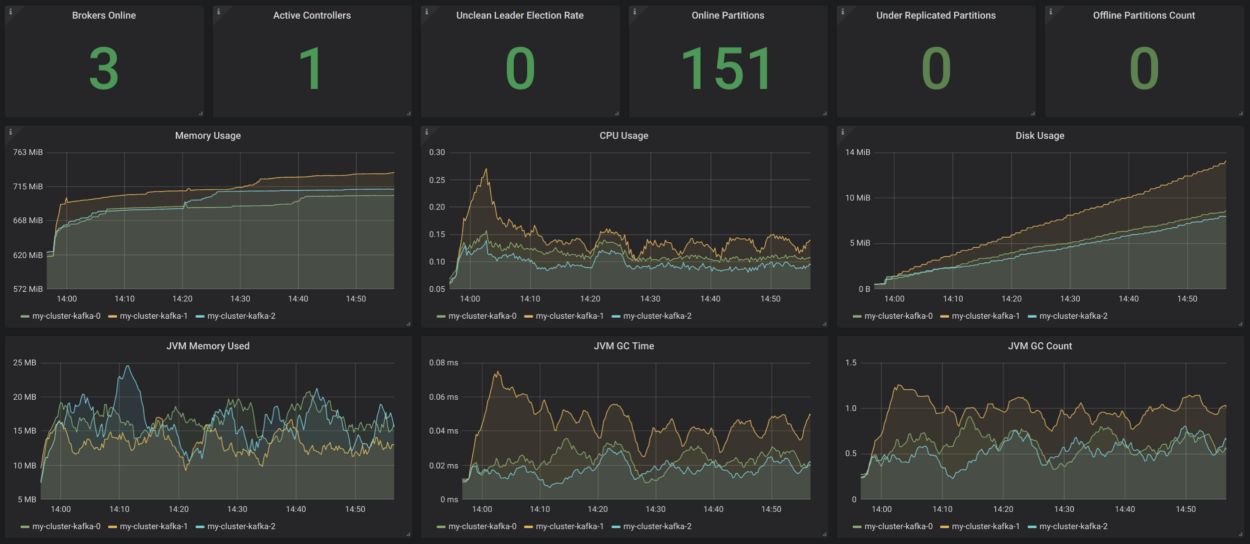
Source:
strimzi.io/docs/master/#kafka_dashboardIl serait bon de compléter tout cela avec une surveillance des clients (mesures pour les consommateurs et les producteurs), ainsi qu'une surveillance des retards (pour cela, il y a
Burrow ) et une surveillance de bout en bout - pour cela, utilisez
Kafka Monitor .
JournalisationLa journalisation est une autre tâche critique. Assurez-vous que tous les conteneurs de votre installation Kafka sont connectés dans
stdout et
stderr , et assurez-vous que votre cluster Kubernetes regroupe tous les journaux dans une infrastructure de
journalisation centrale, comme
Elasticsearch .
Bilan de santéKubernetes utilise des sondes de vivacité et de préparation pour vérifier si vos pods fonctionnent correctement. Si le test en direct échoue, Kubernetes arrête ce conteneur, puis le redémarre automatiquement si la stratégie de redémarrage est définie en conséquence. Si le contrôle de disponibilité échoue, Kubernetes l'isole du service de demande. Ainsi, dans de tels cas, une intervention manuelle n'est plus nécessaire du tout, et c'est un gros plus.
Déploiement des mises à jourStatefulSet prend en charge les mises à jour automatiques: lorsque vous choisissez une stratégie RollingUpdate, chacune sous Kafka sera mise à jour à son tour. De cette façon, les temps d'arrêt peuvent être réduits à zéro.
Mise à l'échelleFaire évoluer un cluster Kafka n'est pas une tâche facile. Cependant, dans Kubernetes, il est très facile de faire évoluer les modules vers un certain nombre de répliques, ce qui signifie que vous pouvez identifier de manière déclarative autant de courtiers Kafka que vous le souhaitez. Le plus difficile dans ce cas est la réaffectation des secteurs après une augmentation ou une réduction. Encore une fois, Kubernetes vous aidera dans cette tâche.
AdministrationLes tâches liées à l'administration de votre cluster Kafka, en particulier la création de rubriques et la réaffectation de secteurs, peuvent être effectuées à l'aide de scripts shell existants, ouvrant l'interface de ligne de commande dans vos pods. Cependant, cette solution n'est pas trop belle. Strimzi prend en charge la gestion des sujets à l'aide d'un autre opérateur. Il y a quelque chose à modifier ici.
Sauvegarde et restaurationMaintenant, la disponibilité de Kafka dépendra de la disponibilité de Kubernetes. Si votre cluster Kubernetes tombe, dans le pire des cas, le cluster Kafka tombe également. Selon la loi de Murphy, cela se produira et vous perdrez des données. Pour réduire ce type de risque, ayez un bon concept de sauvegarde. Vous pouvez utiliser MirrorMaker, une autre option consiste à utiliser S3 pour cela, comme décrit dans cet
article de Zalando.
Conclusion
Lorsque vous travaillez avec des clusters Kafka de petite ou moyenne taille, il est certainement conseillé d'utiliser Kubernetes, car il offre une flexibilité supplémentaire et simplifie le travail avec les opérateurs. Si vous avez des exigences non fonctionnelles très graves concernant la latence et / ou le débit, il peut être préférable d'envisager une autre option de déploiement.