L'analyse d'un entonnoir de vente est une tâche typique du marketing Internet, et en particulier du commerce électronique. Avec son aide, vous pouvez:
- Découvrez laquelle des étapes de l'achat vous perdez des clients potentiels.
- Simuler le volume des entrées de revenus supplémentaires, en cas d'extension de chaque étape sur le chemin d'achat.
- Évaluez la qualité du trafic acheté sur différentes plateformes publicitaires.
- Évaluez la qualité du traitement des demandes entrantes pour chacun des gestionnaires.
Dans cet article, je vais vous expliquer comment demander des données à l'API Yandex Metrics Logs dans le langage R, créer et visualiser un entonnoir basé sur celles-ci.
L'un des principaux avantages du langage R est la présence d'un grand nombre de packages qui étendent ses fonctionnalités de base. Dans cet article, nous examinerons les rym , funneljoin et ggplot2 .
À l'aide de rym nous chargeons les données de l'API Logs, utilisons funneljoin pour créer un entonnoir comportemental et utilisons ggplot2 visualiser le résultat.

Table des matières
Demander des données à l'API Logs Yandex Metrics
Qui ne sait pas ce qu'est l' API Logs est une citation de l'aide officielle de Yandex.
L'API Logs vous permet de recevoir des données non agrégées collectées par Yandex.Metrica. Cette API est destinée aux utilisateurs du service qui souhaitent traiter indépendamment des données statistiques et les utiliser pour résoudre des problèmes analytiques uniques.
Pour travailler avec l'API Yandex.Metrica Logs dans R, nous utiliserons le package rym .
Liens utiles vers le package rym rym - R qui est une interface pour interagir avec l'API Yandex Metrica. Vous permet de travailler avec l' API de gestion , l' API de création de rapports , l'API Gore conforme à Google Analytics v3 et l' API Logs .
Installation du package Rym
Pour fonctionner avec n'importe quel package dans R, il doit d'abord être installé et téléchargé. Installez un package une fois à l'aide de la commande install.packages() . Il est nécessaire de connecter le package à chaque nouvelle session de travail dans R à l'aide de la fonction library() .
Pour installer et connecter le package rym utilisez le code suivant:
install.packages("rym") library(rym)
Utilisation de l'API Logs Yandex Metrics à l'aide du package rym
Afin de créer des entonnoirs comportementaux, nous devons télécharger un tableau de toutes les visites effectuées sur votre site et préparer les données pour une analyse plus approfondie.
Autorisation dans l'API Yandex Metrics
Le travail avec l'API commence par l'autorisation. Dans le package rym le processus d'autorisation est partiellement automatisé et démarre lorsque l'une de ses fonctions est appelée.
La première fois que vous accédez à l'API, vous serez redirigé vers le navigateur pour confirmer l'autorisation d'accéder à vos métriques Yandex pour le package rym . Après confirmation, vous serez redirigé vers la page où un code de confirmation d'autorisation sera généré pour vous. Il doit être copié et collé dans la console R en réponse à la demande "Enter authorize code:" .
Ensuite, vous pouvez enregistrer les informations d'identification dans un fichier local en répondant y ou yes à la demande "Do you want save API credential in local file ..." . Dans ce cas, lors des prochains appels à l'API, vous n'aurez pas besoin de vous réauthentifier via le navigateur et les informations d'identification seront chargées à partir du fichier local.
Demander des données à l'API Yandex Metrica
La première chose que nous demandons à l'API Yandex Metrics est une liste des compteurs disponibles et des objectifs configurés. Cela se fait à l'aide des fonctions rym_get_counters() et rym_get_goals() .
# library(rym) # counters <- rym_get_counters(login = " ") # goals <- rym_get_goals("0000000", # login = " ")
En utilisant l'exemple de code ci-dessus, remplacez " " par votre nom d'utilisateur dans Yandex, sous lequel les métriques Yandex dont vous avez besoin sont disponibles. Et "0000000" au numéro du compteur dont vous avez besoin. Vous pouvez voir les numéros des compteurs disponibles dans le tableau des compteurs chargés.
Le tableau des compteurs disponibles - compteurs a la forme suivante:
# A tibble: 2 x 9 id status owner_login name code_status site permission type gdpr_agreement_accepted <int> <fct> <fct> <fct> <fct> <fct> <fct> <fct> <int> 1 11111111 Active site.ru1 Aerosus CS_NOT_FOUND site.ru edit simple 0 2 00000000 Active site.ru Aerosus RU CS_OK site.ru edit simple 1
Le champ id affiche les numéros de tous les compteurs métriques Yandex disponibles.
Le tableau des objectifs est le suivant:
# A tibble: 4 x 5 id name type is_retargeting conditions <int> <fct> <fct> <int> <fct> 1 47873638 url 0 type:contain, url:site.ru/checkout/cart/ 2 47873764 url 0 type:contain, url:site.ru/onestepcheckout/ 3 47874133 url 0 type:contain, url:/checkout/onepage/success 4 50646283 action 0 type:exact, url:click_phone
C'est-à-dire dans le compteur avec lequel je travaille, les actions suivantes sont configurées:
- Aller au panier
- Aller au paiement
- Page de remerciement pour la commande
- Cliquez sur le bouton téléphone
À l'avenir, pour la conversion des données, nous utiliserons les packages inclus dans la bibliothèque tidyr : tidyr , dplyr . Par conséquent, avant d'utiliser l'exemple de code suivant, installez et connectez ces packages ou l'intégralité de la bibliothèque tidyverse .
# install.packages("tidyverse") # library(tidyverse) install.packages(c("dplyr", "tidyr")) library(dplyr) library(tidyr)
La fonction rym_get_logs() vous permet de demander des données aux métriques de l'API Yandex metrics Logs.
# logs <- rym_get_logs(counter = "0000000", date.from = "2019-04-01", date.to = "2019-06-30", fields = "ym:s:visitID, ym:s:clientID, ym:s:date, ym:s:goalsID, ym:s:lastTrafficSource, ym:s:isNewUser", login = " ") %>% mutate(ym.s.date = as.Date(ym.s.date), ym.s.clientID = as.character(ym.s.clientID))
Les principaux arguments de la fonction rym_get_logs() :
- compteur - numéro de compteur à partir duquel vous demandez des journaux;
- date.from - date de début;
- date.to - date de fin;
- champs - une liste des champs que vous souhaitez charger;
- login - Login Yandex sous lequel le compteur spécifié dans counter est disponible.
Ainsi, nous avons demandé des données de visite à l'API Logs qui contient les colonnes suivantes:
- ym: s: visitID - ID visite
- ym: s: clientID - ID utilisateur sur le site
- ym: s: date - Date de visite
- ym: s: butsID - Identifiant des buts atteints lors de cette visite
- ym: s: lastTrafficSource - Source de trafic
- ym: s: isNewUser - Première visite du visiteur
Pour une liste complète des champs disponibles, consultez l' aide de l' API Logs.
Les données reçues nous suffisent pour construire un entonnoir, dans le cadre duquel le travail avec l'API Logs est terminé, et nous passons à l'étape suivante - le post-traitement des données téléchargées.
Package d'entonnoir de construction d'entonnoir
Une partie importante des informations fournies dans cette section est obtenue à partir du package funneljoin README, disponible par référence .
funneljoin objectif funneljoin est de simplifier l'analyse en entonnoir du comportement des utilisateurs. Par exemple, votre tâche consiste à rechercher les personnes qui ont visité votre site puis se sont enregistrées, et à savoir combien de temps s'est écoulé entre la première visite et l'inscription. Ou vous devez trouver les utilisateurs qui ont consulté la fiche produit et l'ont ajoutée au panier dans les deux jours. Le package funneljoin et la fonction after_join() aident à résoudre ces problèmes.
Arguments after_join() :
- x - un ensemble de données contenant des informations sur la réalisation du premier événement (dans le premier exemple, visite du site, dans le second affichage de la fiche produit).
- y - un ensemble de données avec des informations sur l'achèvement du deuxième événement (dans le premier exemple d'inscription, dans le second ajout du produit au panier).
- by_time - une colonne contenant des informations sur la date à laquelle les événements se sont produits dans les tableaux x et y .
- by_user - une colonne avec des identifiants d'utilisateur dans les tableaux x et y .
- mode - la méthode utilisée pour se connecter: "intérieure", "complète", "anti", "semi", "droite", "gauche". Au lieu de cela, vous pouvez également utiliser
after_mode_join (par exemple, after_inner_join au lieu de after_join (..., mode = "inner") ). - type - le type de séquence utilisé pour définir des paires d'événements, tels que "premier-premier", "dernier-premier", "tout-premier après". Plus de détails sont décrits dans la section "Types d'entonnoir".
- max_gap / min_gap (facultatif) - filtre par la durée maximale et minimale entre les premier et deuxième événements.
- gap_col (facultatif) - Indique s'il faut renvoyer une colonne numérique .gap avec une différence de temps entre les événements. La valeur par défaut est FALSE.
Installation de funneljoin
Au moment d'écrire ces funneljoin , le package funneljoin pas publié sur CRAN, vous pouvez donc l'installer à partir de GitHub. Pour installer des packages à partir de GitHub, vous aurez besoin d'un package supplémentaire - devtools .
install.packages("devtools") devtools::install_github("robinsones/funneljoin")
Post-traitement des données reçues de l'API Logs
Pour une étude plus détaillée de la fonctionnalité de construction de l'entonnoir, nous devons amener les données obtenues à partir de l'API Logs sous la forme souhaitée. Le moyen le plus pratique pour manipuler les données, comme je l'ai écrit ci-dessus, est fourni par les tidyr et dplyr .
Pour commencer, procédez comme suit:
- Dans ce cas, une ligne du tableau des journaux contient des informations sur une visite et la colonne ym.s.goalsID est un tableau de la forme -
[0,1,0,...] , qui contient les identificateurs des objectifs atteints au cours de cette visite. Afin d'amener le tableau sous une forme appropriée pour un travail ultérieur, il est nécessaire d'en supprimer les caractères supplémentaires, dans notre cas les crochets. - Il est nécessaire de reformater le tableau afin qu'une ligne contienne des informations sur un objectif atteint lors de la visite. C'est-à-dire si trois objectifs ont été atteints au cours d'une visite, cette visite sera divisée en trois lignes et chaque ligne, dans la colonne ym.s.goalsID, contiendra l'identifiant d'un seul objectif.
- Joignez un tableau avec une liste d'objectifs au tableau du journal pour comprendre exactement quels objectifs ont été atteints lors de chaque visite.
- Renommez la colonne de nom avec les noms d'objectif en événements .
Toutes les actions ci-dessus sont implémentées à l'aide du code suivant:
Code de post-traitement des données reçues de l'API Logs # logs_goals <- logs %>% mutate(ym.s.goalsID = str_replace_all(ym.s.goalsID, # "\\[|\\]", "") %>% str_split(",")) %>% # unnest(cols = c(ym.s.goalsID)) %>% mutate(ym.s.goalsID = as.integer(ym.s.goalsID)) %>% # id left_join(goals, by = c("ym.s.goalsID" = "id")) %>% # rename(events = name) # events
Une petite explication du code. L'opérateur %>% est appelé pipeline et rend le code plus lisible et compact. En fait, il prend le résultat de l'exécution d'une fonction et le transmet comme premier argument à la fonction suivante. Ainsi, une sorte de convoyeur est obtenue, ce qui vous permet de ne pas obstruer la RAM avec des variables superflues qui stockent des résultats intermédiaires.
La fonction str_replace_all supprime les crochets dans la colonne ym.s.goalsID . str_split sépare les identifiants cibles de la colonne ym.s.goalsID en valeurs distinctes, et unnest divise en lignes distinctes, dupliquant les valeurs de toutes les autres colonnes.
En utilisant mutate nous convertissons les identifiants cibles en type entier.
left_join table des objectifs au résultat, qui stocke des informations sur les objectifs configurés. Utiliser la colonne ym.s.goalsID de la table actuelle et la colonne id de la table d' objectifs comme clé.
Enfin, la fonction rename renomme la colonne de nom en événements .
Maintenant, la table logs_goals a l' apparence nécessaire pour un travail ultérieur.
Ensuite, créez trois nouvelles tables:
- first_visits - dates des premières sessions pour tous les nouveaux utilisateurs
- panier - dates d'ajout de produits au panier
- commandes - commandes
Code de création de table # first_visits <- logs_goals %>% filter(ym.s.isNewUser == 1 ) %>% # select(ym.s.clientID, # clientID ym.s.date) # date # cart <- logs_goals %>% filter(events == " ") %>% select(ym.s.clientID, ym.s.date) # orders <- logs_goals %>% filter(events == " ") %>% select(ym.s.clientID, ym.s.date)
Chaque nouvelle table est le résultat du filtrage de la table principale logs_goals obtenue à la dernière étape. Le filtrage est effectué par la fonction de filter .
Pour créer des entonnoirs, il nous suffit de laisser des informations sur l'ID utilisateur et la date de l'événement, qui sont stockées dans les colonnes ym.s.clientID et ym.s.date , dans les nouvelles tables. Les colonnes souhaitées ont été sélectionnées à l'aide de la fonction de select .
Types d'entonnoir
L'argument type accepte toute combinaison des lastbefore first , last , any et firstafter avec first , last , any et firstafter . Voici un exemple des combinaisons les plus utiles que vous pouvez utiliser:
first-first : obtenez les premiers événements x et y pour chaque utilisateur. Par exemple, nous voulons obtenir la date de la première visite et la date du premier achat, auquel cas utilisez d'abord le type d'entonnoir.
# first-first first_visits %>% after_inner_join(orders, by_user = "ym.s.clientID", by_time = "ym.s.date", type = "first-first")
# A tibble: 42 x 3 ym.s.clientID ym.s.date.x ym.s.date.y <chr> <date> <date> 1 1552251706539589249 2019-04-18 2019-05-15 2 1554193975665391000 2019-04-02 2019-04-15 3 1554317571426012455 2019-04-03 2019-04-04 4 15544716161033564779 2019-04-05 2019-04-08 5 1554648729526295287 2019-04-07 2019-04-11 6 1554722099539384487 2019-04-08 2019-04-17 7 1554723388680198551 2019-04-08 2019-04-08 8 15547828551024398507 2019-04-09 2019-05-13 9 1554866701619747784 2019-04-10 2019-04-10 10 1554914125524519624 2019-04-10 2019-04-10 # ... with 32 more rows
Nous avons obtenu un tableau dans lequel 1 ligne contient des données sur la date de la première visite de l'utilisateur sur le site et la date de sa première commande.
first-firstafter : obtenez le premier x , puis le premier y est arrivé après le premier x . Par exemple, un utilisateur a visité à plusieurs reprises votre site et, au cours des visites, il a ajouté des produits au panier, si vous avez besoin d'obtenir la date d'ajout du tout premier produit au panier et la date de la commande la plus proche , utilisez le type d'entonnoir first-firstafter .
cart %>% after_inner_join(orders, by_user = "ym.s.clientID", by_time = "ym.s.date", type = "first-firstafter")
# A tibble: 49 x 3 ym.s.clientID ym.s.date.x ym.s.date.y <chr> <date> <date> 1 1551433754595068897 2019-04-02 2019-04-05 2 1552251706539589249 2019-05-15 2019-05-15 3 1552997205196001429 2019-05-23 2019-05-23 4 1553261825377658768 2019-04-11 2019-04-11 5 1553541720631103579 2019-04-04 2019-04-05 6 1553761108775329787 2019-04-16 2019-04-16 7 1553828761648236553 2019-04-03 2019-04-03 8 1554193975665391000 2019-04-13 2019-04-15 9 1554317571426012455 2019-04-04 2019-04-04 10 15544716161033564779 2019-04-08 2019-04-08 # ... with 39 more rows
lastbefore-firstafter : premier x suivi de y avant le x suivant. Par exemple, un utilisateur a visité à plusieurs reprises votre site, certaines sessions se sont terminées par un achat. Si vous devez obtenir la date de la dernière session avant d'acheter et la date d'achat qui a suivi, utilisez le type d'entonnoir lastbefore-firstafter .
first_visits %>% after_inner_join(orders, by_user = "ym.s.clientID", by_time = "ym.s.date", type = "lastbefore-firstafter")
# A tibble: 50 x 3 ym.s.clientID ym.s.date.x ym.s.date.y <chr> <date> <date> 1 1551433754595068897 2019-04-05 2019-04-05 2 1552251706539589249 2019-05-15 2019-05-15 3 1552251706539589249 2019-05-16 2019-05-16 4 1552997205196001429 2019-05-23 2019-05-23 5 1553261825377658768 2019-04-11 2019-04-11 6 1553541720631103579 2019-04-05 2019-04-05 7 1553761108775329787 2019-04-16 2019-04-16 8 1553828761648236553 2019-04-03 2019-04-03 9 1554193975665391000 2019-04-15 2019-04-15 10 1554317571426012455 2019-04-04 2019-04-04 # ... with 40 more rows
Dans ce cas, nous avons reçu un tableau dans lequel une ligne contient la date à laquelle le dernier produit a été ajouté au panier avant la fin de chaque commande et la date de la commande elle-même.
any-firstafter : récupère tous les x et les premiers y après. Par exemple, un utilisateur a visité à plusieurs reprises votre site, lors de chaque visite, ajouté divers produits au panier et passé périodiquement des commandes avec tous les produits ajoutés. Si vous avez besoin d'obtenir les dates de tous les ajouts de marchandises au panier et les dates de commande, utilisez d'abord le type d'entonnoir.
cart %>% after_inner_join(orders, by_user = "ym.s.clientID", by_time = "ym.s.date", type = "any-firstafter")
# A tibble: 239 x 3 ym.s.clientID ym.s.date.x ym.s.date.y <chr> <date> <date> 1 1551433754595068897 2019-04-02 2019-04-05 2 1551433754595068897 2019-04-02 2019-04-05 3 1551433754595068897 2019-04-03 2019-04-05 4 1551433754595068897 2019-04-03 2019-04-05 5 1551433754595068897 2019-04-03 2019-04-05 6 1551433754595068897 2019-04-05 2019-04-05 7 1551433754595068897 2019-04-05 2019-04-05 8 1551433754595068897 2019-04-05 2019-04-05 9 1551433754595068897 2019-04-05 2019-04-05 10 1551433754595068897 2019-04-05 2019-04-05 # ... with 229 more rows
- any-any: obtenir tous les x et tous les y à côté de chaque x . Par exemple, vous souhaitez recevoir une liste de toutes les visites sur le site avec toutes les commandes ultérieures effectuées par chaque utilisateur.
first_visits %>% after_inner_join(orders, by_user = "ym.s.clientID", by_time = "ym.s.date", type = "any-any")
# A tibble: 122 x 3 ym.s.clientID ym.s.date.x ym.s.date.y <chr> <date> <date> 1 1552251706539589249 2019-04-18 2019-05-15 2 1552251706539589249 2019-04-18 2019-05-15 3 1552251706539589249 2019-04-18 2019-05-15 4 1552251706539589249 2019-04-18 2019-05-16 5 1554193975665391000 2019-04-02 2019-04-15 6 1554193975665391000 2019-04-02 2019-04-25 7 1554317571426012455 2019-04-03 2019-04-04 8 15544716161033564779 2019-04-05 2019-04-08 9 1554648729526295287 2019-04-07 2019-04-11 10 1554722099539384487 2019-04-08 2019-04-17 # ... with 112 more rows
Étapes de l'entonnoir
Les exemples ci-dessus montrent after_inner_join() travailler avec la fonction after_inner_join() , il est pratique de l'utiliser dans les cas où vous avez tous les événements séparés par des tables séparées, dans notre cas selon les tables first_visits , cart et Orders .
Mais l'API Logs vous donne des données sur tous les événements dans une table, et les fonctions funnel_start() et funnel_step() seront un moyen plus pratique de créer une séquence d'actions. funnel_start aide à définir la première étape de l'entonnoir et prend cinq arguments:
- tbl - Table d'événements;
- moment_type - Le premier événement dans l'entonnoir;
- moment - Le nom de la colonne qui contient le nom de l'événement;
- tstamp - Nom de la colonne avec la date à laquelle l'événement s'est produit;
- user - Le nom de la colonne avec les identifiants utilisateur.
logs_goals %>% select(events, ym.s.clientID, ym.s.date) %>% funnel_start(moment_type = " ", moment = "events", tstamp = "ym.s.date", user = "ym.s.clientID")
# A tibble: 52 x 2 ym.s.clientID `ym.s.date_ ` <chr> <date> 1 1556018960123772801 2019-04-24 2 1561216372134023321 2019-06-22 3 1556955573636389438 2019-05-04 4 1559220890220134879 2019-05-30 5 1553261825377658768 2019-04-11 6 1561823182372545402 2019-06-29 7 1556047887455246275 2019-04-23 8 1554722099539384487 2019-04-17 9 1555420652241964245 2019-04-17 10 1553541720631103579 2019-04-05 # ... with 42 more rows
funnel_start renvoie une table avec la colonne ym.s.clientI et ym.s.date_ ym.s.date_ (le nom de votre colonne avec la date, _ et le nom de l'événement).
Les étapes suivantes peuvent être ajoutées à l'aide de la fonction funnel_step() . Dans funnel_start nous avons déjà spécifié les identifiants de toutes les colonnes requises, nous devons maintenant spécifier quel événement sera la prochaine étape dans l'entonnoir en utilisant l'argument moment_type , et le type de connexion est type (par exemple, "first-first" , "first-any" ).
logs_goals %>% select(events, ym.s.clientID, ym.s.date) %>% funnel_start(moment_type = " ", moment = "events", tstamp = "ym.s.date", user = "ym.s.clientID") %>% funnel_step(moment_type = " ", type = "first-last")
# A tibble: 319 x 3 ym.s.clientID `ym.s.date_ ` `ym.s.date_ ` <chr> <date> <date> 1 1550828847886891355 2019-04-01 NA 2 1551901759770098825 2019-04-01 NA 3 1553595703262002507 2019-04-01 NA 4 1553856088331234886 2019-04-01 NA 5 1554044683888242311 2019-04-01 NA 6 1554095525459102609 2019-04-01 NA 7 1554100987632346537 2019-04-01 NA 8 1551433754595068897 2019-04-02 2019-04-05 9 1553627918798485452 2019-04-02 NA 10 155418104743178061 2019-04-02 NA # ... with 309 more rows
Avec funnel_step vous pouvez créer des entonnoirs en plusieurs étapes. Pour créer un entonnoir complet pour chaque utilisateur, dans mon exemple, vous pouvez utiliser le code suivant:
Code pour construire un entonnoir complet pour chaque utilisateur # # events - " " logs_goals <- logs_goals %>% filter(ym.s.isNewUser == 1 ) %>% mutate(events = " ") %>% bind_rows(logs_goals) # logs_goals %>% select(events, ym.s.clientID, ym.s.date) %>% funnel_start(moment_type = " ", moment = "events", tstamp = "ym.s.date", user = "ym.s.clientID") %>% funnel_step(moment_type = " ", type = "first-last") %>% funnel_step(moment_type = " ", type = "first-last") %>% funnel_step(moment_type = " ", type = "first-last")
Et maintenant, la cerise sur le gâteau est summarize_funnel() . Une fonction qui vous permet d'afficher le pourcentage d'utilisateurs qui sont passés de l'étape précédente à la suivante et le pourcentage d'utilisateurs qui sont passés de la première étape à chaque étape suivante.
my_funnel <- logs_goals %>% select(events, ym.s.clientID, ym.s.date) %>% funnel_start(moment_type = " ", moment = "events", tstamp = "ym.s.date", user = "ym.s.clientID") %>% funnel_steps(moment_type = c(" ", " ", " "), type = "first-last") %>% summarize_funnel()
# A tibble: 4 x 4 moment_type nb_step pct_cumulative pct_step <fct> <dbl> <dbl> <dbl> 1 18637 1 NA 2 1589 0.0853 0.0853 3 689 0.0494 0.579 4 34 0.0370 0.749
nb_step — , , pct_cumulative — , pct_step — .
my_funnel , ggplot2 .
ggplot2 — R, . , , .
ggplot2 , 2005 . , photoshop, , .
# install.packages("ggplot2") library(ggplot2) my_funnel %>% mutate(padding = (sum(my_funnel$nb_step) - nb_step) / 2) %>% gather(key = "variable", value = "val", -moment_type) %>% filter(variable %in% c("nb_step", "padding")) %>% arrange(desc(variable)) %>% mutate(moment_type = factor(moment_type, levels = c(" ", " ", " ", " "))) %>% ggplot( aes(x = moment_type) ) + geom_bar(aes(y = val, fill = variable), stat='identity', position='stack') + scale_fill_manual(values = c('coral', NA) ) + geom_text(data = my_funnel, aes(y = sum(my_funnel$nb_step) / 2, label = paste(round(round(pct_cumulative * 100,2)), '%')), colour='tomato4', fontface = "bold") + coord_flip() + theme(legend.position = 'none') + labs(x='moment', y='volume')
:
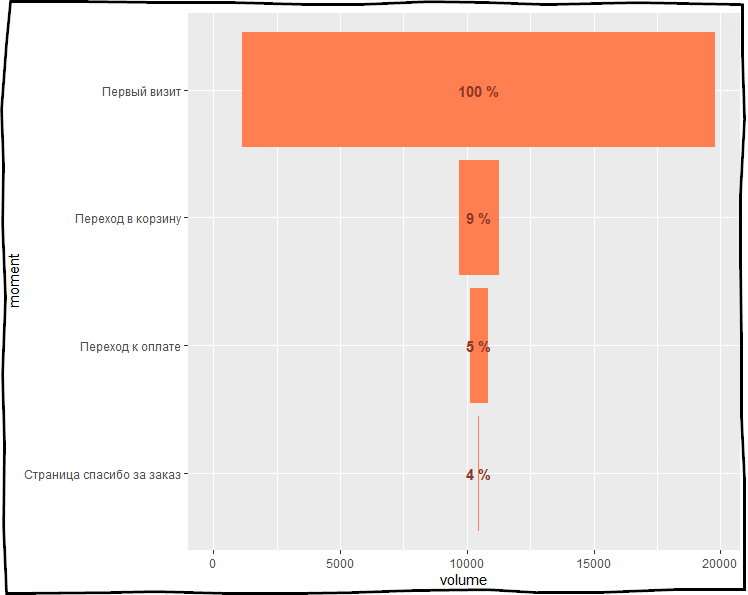
.
- my_funnel .
ggplot — , , , X moment_type .geom_bar — — , aes .scale_fill_manual — , , .geom_text — , % .coord_flip — , .theme — : , .. .labs — .
, , , , .
lapply , R. , , bind_rows .
# first_visits <- rename(first_visits, firstSource = ym.s.lastTrafficSource) # logs_goals <- select(first_visits, ym.s.clientID, firstSource) %>% left_join(logs_goals, ., by = "ym.s.clientID") # my_multi_funnel <- lapply(c("ad", "organic", "direct"), function(source) { logs_goals %>% filter(firstSource == source) %>% select(events, ym.s.clientID, ym.s.date) %>% funnel_start(moment_type = " ", moment = "events", tstamp = "ym.s.date", user = "ym.s.clientID") %>% funnel_steps(moment_type = c(" ", " ", " "), type = "first-last") %>% summarize_funnel() %>% mutate(firstSource = source) }) %>% bind_rows() #
# A tibble: 12 x 5 moment_type nb_step pct_cumulative pct_step firstSource <fct> <int> <dbl> <dbl> <chr> 1 14392 1 NA ad 2 154 0.0107 0.0107 ad 3 63 0.00438 0.409 ad 4 14 0.000973 0.222 ad 5 3372 1 NA organic 6 68 0.0202 0.0202 organic 7 37 0.0110 0.544 organic 8 13 0.00386 0.351 organic 9 607 1 NA direct 10 49 0.0807 0.0807 direct 11 21 0.0346 0.429 direct 12 8 0.0132 0.381 direct
my_multi_funnel , .
# my_multi_funnel %>% mutate(padding = ( 1 - pct_cumulative) / 2 ) %>% gather(key = "variable", value = "val", -moment_type, -firstSource) %>% filter(variable %in% c("pct_cumulative", "padding")) %>% arrange(desc(variable)) %>% mutate(moment_type = factor(moment_type, levels = c(" ", " ", " ", " ")), variable = factor(variable, levels = c("pct_cumulative", "padding"))) %>% ggplot( aes(x = moment_type) ) + geom_bar(aes(y = val, fill = variable), stat='identity', position='stack') + scale_fill_manual(values = c('coral', NA) ) + geom_text(data = my_multi_funnel_df, aes(y = 1 / 2, label =paste(round(round(pct_cumulative * 100, 2)), '%')), colour='tomato4', fontface = "bold") + coord_flip() + theme(legend.position = 'none') + labs(x='moment', y='volume') + facet_grid(. ~ firstSource)
:

?
first_visits ym.s.lastTrafficSource firstSource .left_join ym.s.clientID . firstSource .lapply ad, organic direct. bind_rows .facet_grid(. ~ firstSource) , firstSource .
PS
. PS , R. R4marketing , R .
:
Conclusion
, , R :
- .;
- R RStudio;
rym , funneljoin ggplot2 ;rym rym_get_logs() .;funneljoin .ggplot2 .
, Logs API , : CRM, 1 . , : , -.