Pensez-vous qu'il est difficile d'écrire votre propre chatbot en Python qui peut prendre en charge la conversation? Cela s'est avéré très facile si vous trouvez un bon ensemble de données. De plus, cela peut être fait même sans réseaux de neurones, même si une certaine magie mathématique sera toujours nécessaire.
Nous allons procéder par petites étapes: d'abord, rappelez-vous comment charger des données dans Python, puis apprenez à compter les mots, connectez progressivement l'algèbre linéaire et le théoricien, et à la fin, nous créons un bot pour Telegram à partir de l'algorithme de chat résultant.
Ce tutoriel convient à ceux qui ont déjà un peu touché Python, mais qui ne sont pas particulièrement familiers avec l'apprentissage automatique. Je n'ai intentionnellement utilisé aucune bibliothèque nlp-sh pour montrer que quelque chose qui fonctionne peut être assemblé sur sklearn nu.
Rechercher une réponse dans le jeu de données de dialogue
Il y a un an, on m'a demandé de montrer aux gars qui n'avaient pas encore été engagés dans l'analyse de données une application d'apprentissage machine inspirante que vous pouvez créer vous-même. J'ai essayé d'amener un bot-talker avec eux, et nous l'avons vraiment fait en une soirée. Nous avons aimé le processus et le résultat, et nous en avons parlé sur
mon blog . Et maintenant, je pensais que Habru serait intéressant.
Alors c'est parti. Notre tâche est de créer un algorithme qui donnera une réponse appropriée à n'importe quelle phrase. Par exemple, sur "comment allez-vous?" répondez "excellent, et vous?". Le moyen le plus simple d'y parvenir est de trouver une base de données prête à l'emploi de questions et réponses. Par exemple, prenez des sous-titres d'un grand nombre de films.
Cependant, j'agirai encore plus de manière
infidèle et je prendrai les données du
concours Yandex.Algorithm 2018 - ce sont les mêmes dialogues des films pour lesquels les employés de Toloka ont tracé de bonnes et de bonnes séquences. Yandex a collecté ces données pour former Alice (articles sur ses tripes
1 ,
2 ,
3 ). En fait, j'ai été inspirée par Alice quand j'ai créé ce bot. Le
tableau de Yandex montre les trois dernières phrases et la réponse à celles-ci (réponse), mais nous n'utiliserons que la plus récente (context_0).
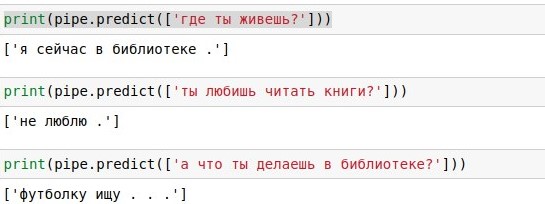
Ayant une telle base de données de boîtes de dialogue, vous pouvez simplement y rechercher chaque réplique de l'utilisateur, et donner une réponse prête à ce sujet (s'il y en a beaucoup, choisissez au hasard). Avec "comment ça va?" cela s'est avéré super, comme en témoigne la capture d'écran ci-jointe. Il s'agit en fait d'un
bloc-notes jupyter en Python 3. Si vous voulez répéter cela vous-même, la façon la plus simple est d'installer
Anaconda - il comprend Python et un tas de packages utiles. Ou vous ne pouvez rien installer, mais exécuter un ordinateur portable
dans un cloud Google .

Le problème des recherches textuelles est qu'elles ont une faible couverture. À la phrase "comment allez-vous?" dans la base de données de 40 000 réponses, il n'y avait pas de correspondance exacte, bien qu'elle ait la même signification. Par conséquent, dans la section suivante, nous compléterons notre code en utilisant différents calculs pour implémenter une recherche approximative. Et avant cela, vous pouvez lire sur la bibliothèque
pandas et comprendre ce que fait chacune des 6 lignes du code ci-dessus.
Vectorisation de texte
Maintenant, nous parlons de la façon de transformer des textes en vecteurs numériques afin d'effectuer une recherche approximative sur eux.
Nous avons déjà rencontré la bibliothèque pandas en Python - elle vous permet de charger des tables, de les rechercher, etc. Maintenant, parlons de la bibliothèque
scikit-learn (sklearn), qui permet une manipulation des données plus délicate - ce qu'on appelle l'apprentissage automatique. Cela signifie que tout algorithme doit d'abord afficher les données (ajustement) afin qu'il apprenne quelque chose d'important à leur sujet. En conséquence, l'algorithme «apprend» à faire quelque chose d'utile avec ces données - les transformer (transformer), ou même prédire des valeurs inconnues (prédire).
Dans ce cas, nous voulons convertir des textes («questions») en vecteurs numériques. Cela est nécessaire pour qu'il soit possible de trouver des textes «proches» les uns des autres, en utilisant le concept mathématique de distance. La distance entre deux points peut être calculée par le théorème de Pythagore - comme la racine de la somme des carrés des différences de leurs coordonnées. En mathématiques, cela s'appelle la métrique euclidienne. Si nous pouvons transformer des textes en objets qui ont des coordonnées, alors nous pouvons calculer la métrique euclidienne et, par exemple, trouver dans la base de données une question qui ressemble le plus à «à quoi pensez-vous?».
Le moyen le plus simple de spécifier les coordonnées du texte est de numéroter tous les mots de la langue et de dire que la i-ème coordonnée du texte est égale au nombre d'occurrences du i-ème mot qu'il contient. Par exemple, pour le texte «Je ne peux pas m'empêcher de pleurer», la coordonnée du mot «pas» est 2, les coordonnées des mots «je», «peut» et «pleurer» sont 1 et les coordonnées de tous les autres mots (des dizaines de milliers) sont 0. Cette représentation perd des informations sur l'ordre des mots, mais fonctionne toujours assez bien.
Le problème est que pour les mots que l'on trouve souvent (par exemple, les particules «et» et «a»), les coordonnées seront disproportionnellement grandes, bien qu'elles contiennent peu d'informations. Pour atténuer ce problème, les coordonnées de chaque mot peuvent être divisées par le logarithme du nombre de textes où un tel mot apparaît - cela s'appelle tf-idf et fonctionne également bien.

Il n'y a qu'un seul problème: dans notre base de données de 60 000 «questions» textuelles, qui contiennent 14 000 mots différents. Si vous transformez toutes les questions en vecteurs, vous obtenez une matrice de 60k * 14k. Ce n'est pas très cool de travailler avec ça, donc nous parlerons de réduire la dimension plus tard.
Réduction dimensionnelle
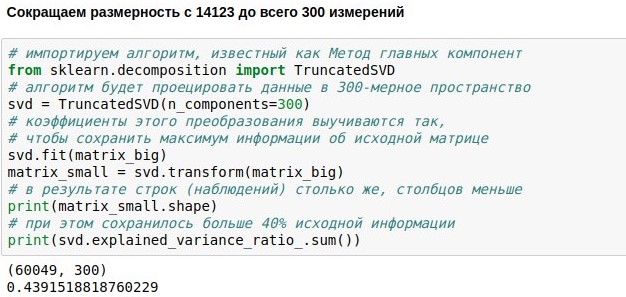
Nous avons déjà défini la tâche de créer un chatbot de chat, des données téléchargées et vectorisées pour sa formation. Nous avons maintenant une matrice numérique représentant les répliques d'utilisateurs. Il se compose de 60 000 lignes (il y avait tellement de répliques dans la base de données de dialogues) et de 14 000 colonnes (il y avait tellement de mots différents). Notre tâche consiste maintenant à la réduire. Par exemple, pour présenter chaque texte non pas comme un vecteur à 14123 dimensions, mais seulement comme un vecteur à 300 dimensions.
Ceci peut être réalisé en multipliant notre matrice de taille 60049x14123 par une matrice de projection spécialement sélectionnée de taille 14123x300, nous obtenons ainsi le résultat 60049x300. L'algorithme PCA (
méthode des composants principaux ) sélectionne la matrice de projection afin que la matrice d'origine puisse ensuite être reconstruite avec la plus petite erreur standard. Dans notre cas, il a été possible de conserver environ 44% de la matrice d'origine, bien que la dimension ait été réduite de près de 50 fois.
Qu'est-ce qui rend une compression aussi efficace possible? Rappelons que la matrice d'origine contient des compteurs pour mentionner des mots individuels dans les textes. Mais les mots, en règle générale, ne sont pas utilisés indépendamment les uns des autres, mais dans leur contexte. Par exemple, plus le mot «blocage» apparaît souvent dans le texte de l'actualité, plus il y a de fois, très probablement, le mot «télégrammes» dans ce texte. Mais la corrélation du mot "blocage", par exemple, avec le mot "caftan" est négative - on les trouve dans des contextes différents.
Ainsi, il s'avère que la méthode des composants principaux ne se souvient pas des 14 000 mots, mais de 300 contextes typiques par lesquels ces mots peuvent ensuite être essayés pour être restaurés. Les colonnes de la matrice de projection correspondant à des mots synonymes sont généralement similaires les unes aux autres car ces mots se trouvent souvent dans le même contexte. Cela signifie qu'il est possible de réduire les mesures redondantes sans perdre le caractère informatif.
Dans de nombreuses applications modernes, la matrice de projection de mots est calculée par des réseaux de neurones (par exemple
word2vec ). Mais en fait, une simple algèbre linéaire suffit déjà pour un résultat pratiquement utile. La méthode des composantes principales est réduite par calcul à SVD, et il s'agit de calculer les vecteurs propres et les valeurs propres de la matrice. Cependant, cela peut être programmé sans même connaître les détails.
Rechercher des voisins proches
Dans les sections précédentes, nous avons téléchargé la boîte de dialogue sur python, l'avons vectorisée et réduit la dimension, et maintenant nous voulons enfin apprendre à rechercher nos voisins les plus proches dans notre espace à 300 dimensions et enfin répondre aux questions de manière significative.
Puisque nous avons appris à mapper des questions à l'espace euclidien de dimension peu élevée, la recherche de voisins peut être effectuée assez rapidement. Nous utiliserons l'algorithme de recherche de voisin
BallTree prêt à l'emploi. Mais nous écrirons notre modèle wrapper, qui choisirait l'un des k voisins les plus proches, et plus le voisin est proche, plus la probabilité de son choix est élevée. Car toujours prendre un des plus proches voisins est ennuyeux, mais ne pas être lié à la ressemblance est dangereux.
Par conséquent, nous voulons transformer les distances trouvées de la requête aux textes de référence en probabilité de choisir ces textes. Pour ce faire, vous pouvez utiliser la fonction softmax, qui se trouve souvent encore à la sortie des réseaux de neurones. Elle transforme ses arguments en un ensemble de nombres non négatifs, dont la somme est 1 - exactement ce dont nous avons besoin. De plus, nous pouvons utiliser les "probabilités" obtenues pour un choix aléatoire de réponse.
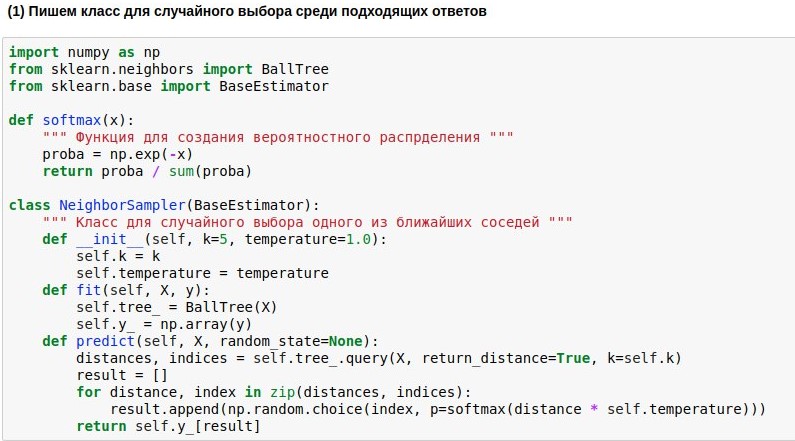
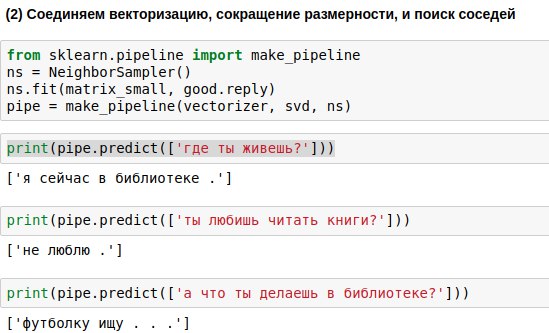
Les phrases que l'utilisateur entrera doivent passer par les trois algorithmes - le vectoriseur, la méthode du composant principal et l'algorithme de sélection de la réponse. Pour écrire moins de code, vous pouvez les lier en une seule chaîne (pipeline), en appliquant les algorithmes de manière séquentielle.
En conséquence, nous avons obtenu un algorithme qui, sur la question d'un utilisateur, est capable de trouver une question similaire à celle-ci et d'y répondre. Et parfois, ces réponses semblent même presque significatives.
Publier un bot sur Telegram
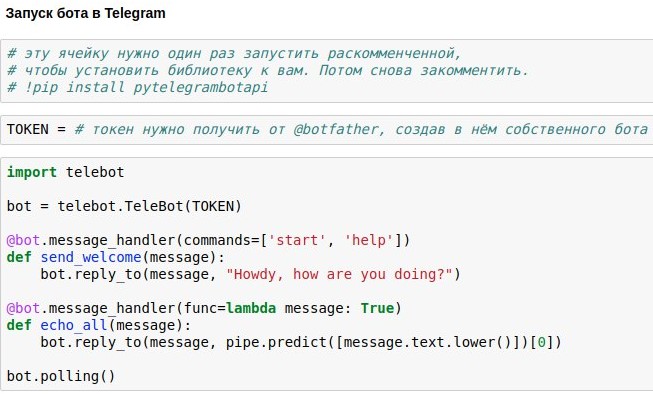
Nous avons déjà compris comment créer une salle de discussion de chatbot qui donnerait des réponses approximativement pertinentes aux demandes des utilisateurs. Maintenant, je vous montre comment libérer un tel chatbot sur Telegram.
La façon la plus simple de l'utiliser est l'API Telegram wrapper prête à l'emploi pour python - par exemple,
pytelegrambotapi . Donc, instructions étape par étape:
- Enregistrez votre futur robot avec @botfather et obtenez un jeton d'accès, que vous devrez insérer dans votre code.
- Exécutez la commande d'installation une fois - pip install pytelegrambotapi sur la ligne de commande (ou via! Directement dans le bloc-notes).
- Exécutez le code comme dans la capture d'écran. La cellule passera en mode d'exécution (*), et pendant qu'elle est dans ce mode, vous pouvez communiquer avec votre bot autant que vous le souhaitez. Pour arrêter le bot, appuyez sur Ctrl + C. La triste, mais importante vérité: si vous êtes en Russie, très probablement, avant de démarrer cette cellule, vous devrez activer le VPN afin de ne pas obtenir d'erreur lors de la connexion aux télégrammes. Une alternative plus simple au VPN est d'écrire tout le code non pas sur votre ordinateur local, mais dans google colab ( quelque chose comme ça ).
- Si vous souhaitez que le bot fonctionne en permanence, vous devez mettre son code sur un service cloud - par exemple, AWS, Heroku, now.sh ou Yandex.Cloud. Vous pouvez apprendre comment les exécuter dans les moindres détails sur les sites de ces services ou dans des articles sur Habré. Par exemple, un navet avec un petit exemple d'un bot fonctionnant sur heroku et mettant des journaux dans mongodb.
Je ne télécharge pas intentionnellement le code complet de l'article - vous obtiendrez beaucoup plus de plaisir et d'expérience utile lorsque vous l'imprimerez vous-même et obtiendrez un bot de travail grâce à vos propres efforts. Eh bien, ou si vous êtes trop paresseux pour le faire, vous pouvez discuter avec
ma version du bot.