Les systèmes d'information modernes sont assez complexes. Enfin et surtout, leur complexité est due à la complexité des données qui y sont traitées. La complexité des données réside souvent dans la variété des modèles de données utilisés. Ainsi, par exemple, lorsque les données deviennent "volumineuses", l'une des caractéristiques gênantes est considérée non seulement leur volume ("volume"), mais aussi leur variété ("variété").
Si vous ne trouvez toujours pas de défaut dans le raisonnement, poursuivez votre lecture.

Persistance polyglotte
Ce qui précède conduit au fait que parfois même dans le cadre d'un système, il est nécessaire d'utiliser plusieurs SGBD différents pour stocker des données et résoudre diverses tâches pour leur traitement, chacune prenant en charge son propre modèle de données. Avec la main légère de M. Fowler, l' auteur de plusieurs livres bien connus et l'un des co-auteurs d' Agile Manifesto, cette situation a été appelée stockage multivarié («persistance polyglotte»).
Fowler possède également l'exemple suivant d'organisation du stockage de données dans une application entièrement fonctionnelle et très chargée dans le domaine du commerce électronique.

Cet exemple, bien sûr, est quelque peu exagéré, mais certaines considérations en faveur du choix de l'un ou l'autre SGBD pour le but correspondant peuvent être trouvées, par exemple, ici .
Il est clair qu’être ministre dans un tel zoo n’est pas facile.
- La quantité de code qui effectue le stockage de données augmente proportionnellement au nombre de SGBD utilisés; la quantité de code qui synchronise les données est bonne sinon proportionnelle au carré de ce nombre.
- Un multiple du nombre de SGBD utilisés augmente les coûts de fourniture des caractéristiques d'entreprise (évolutivité, tolérance aux pannes, haute disponibilité) pour chacun des SGBD utilisés.
- Il n'est pas possible de fournir les caractéristiques d'entreprise du sous-système de stockage dans son ensemble - en particulier transactionnel.
Du point de vue du directeur du zoo, tout ressemble à ceci:
- Une augmentation multiple du coût des licences et du support technique du fabricant du SGBD.
- Le personnel est gonflé et les délais d'exécution sont plus longs.
- Pertes ou pénalités financières directes dues à des données incohérentes.
Il y a une augmentation significative du coût total de possession du système (TCO). Existe-t-il un moyen de sortir de la situation de «stockage multivarié»?
Multimodèle
Le terme «stockage multivarié» est entré en vigueur en 2011. La prise de conscience des problèmes de l'approche et la recherche d'une solution ont pris plusieurs années, et en 2015, la réponse a été formulée par la bouche des analystes de Gartner:
Il semble que cette fois les analystes de Gartner ne se soient pas trompés de prévision. Si vous allez sur la page avec la note principale du SGBD sur les moteurs DB, vous pouvez voir que la plupart de ses leaders se positionnent précisément comme des SGBD multimodèles. La même chose peut être vue sur la page avec n'importe quelle évaluation privée.
Le tableau ci-dessous montre le SGBD - les leaders de chacune des évaluations privées, déclarant leur multi-modèle. Pour chaque SGBD, le modèle pris en charge initial (une fois le seul) est indiqué et, avec lui, les modèles pris en charge maintenant. Il existe également des SGBD qui se positionnent comme «initialement multi-modèles», qui n'ont pas de modèle hérité initial, selon les créateurs.
Notes de tableauLes astérisques dans le tableau indiquent les déclarations nécessitant des réserves:
- PostgreSQL ne prend pas en charge un modèle de données graphique, mais il est pris en charge par un produit basé sur celui - ci , tel que, par exemple, AgensGraph.
- En ce qui concerne MongoDB, il est plus correct de parler davantage de la présence d'opérateurs graphiques dans le langage de requête (
$lookup , $graphLookup ) que de la prise en charge du modèle graphique, bien que, bien sûr, leur introduction ait nécessité quelques optimisations au niveau du stockage physique dans le sens de la prise en charge du modèle graphique. - Pour Redis, cela fait référence à l'extension RedisGraph .
De plus, pour chacune des classes, nous montrerons comment le support de plusieurs modèles dans le SGBD de cette classe est implémenté. Nous considérerons les modèles relationnels, documentaires et graphiques les plus importants et montrerons avec des exemples de SGBD spécifiques comment les "manquants" sont implémentés.
SGBD multimodèle basé sur un modèle relationnel
Les principaux SGBD sont actuellement relationnels; la prévision de Gartner ne pourrait pas être considérée comme vraie si les SGBDR ne montraient pas de mouvement en direction du multimodèle. Et ils démontrent. Maintenant, l'idée qu'un SGBD multimodèle est comme un couteau suisse, ce qui ne peut pas être bien fait, peut être envoyée immédiatement à Larry Ellison.
L'auteur, cependant, aime l'implémentation du multimodélisation dans Microsoft SQL Server, sur l'exemple duquel la prise en charge du SGBDR pour les modèles de documents et de graphiques sera décrite.
Modèle de document dans MS SQL Server
À propos de la façon dont MS SQL Server prend en charge le modèle de document, il y avait déjà deux excellents articles sur Habré, je me limiterai à une brève relecture et commentaire:
La façon de prendre en charge le modèle de document dans MS SQL Server est assez typique pour les SGBD relationnels: les documents JSON sont proposés pour être stockés dans des champs de texte brut. La prise en charge du modèle de document consiste à fournir des opérateurs spéciaux pour analyser ce JSON:
JSON_VALUE pour récupérer les valeurs d'attribut scalaire,JSON_QUERY pour récupérer des sous-documents.
Le deuxième argument des deux opérateurs est une expression dans la syntaxe de type JSONPath.
On peut dire de manière abstraite que les documents stockés de cette manière ne sont pas des «entités de première classe» dans un SGBD relationnel, contrairement aux tuples. Plus précisément, MS SQL Server n'a actuellement pas d'index sur les champs des documents JSON, ce qui rend difficile de joindre des tables par les valeurs de ces champs et même de sélectionner des documents par ces valeurs. Cependant, il est possible de créer une colonne calculable et un index dessus dans ce champ.
De plus, MS SQL Server offre la possibilité de construire facilement un document JSON à partir du contenu des tables à l'aide de l'instruction FOR JSON PATH , une fonctionnalité qui, dans un sens, est l'opposé du stockage ordinaire précédent. Il est clair que quelle que soit la rapidité du SGBDR, cette approche contredit l'idéologie des SGBD de documents, qui stockent en fait des réponses toutes faites aux requêtes populaires, et ne peuvent résoudre que des problèmes de facilité de développement, mais pas de vitesse.
Enfin, MS SQL Server vous permet de résoudre le problème qui est l'inverse de la construction du document: vous pouvez décomposer JSON en tables à l'aide d' OPENJSON . Si le document n'est pas complètement plat, vous devrez utiliser CROSS APPLY .
Modèle de graphique dans MS SQL Server
La prise en charge des modèles de graphes ( LPG ) implémentés dans Microsoft SQL Server est également assez prévisible : il est proposé d'utiliser des tables spéciales pour stocker les nœuds et pour stocker les bords des graphiques. Ces tables sont créées à l'aide des expressions CREATE TABLE AS NODE et CREATE TABLE AS EDGE respectivement.
Les tables du premier type sont similaires aux tables ordinaires pour stocker des enregistrements avec la seule différence externe que la table contient le champ système $node_id - un identifiant unique du nœud de graphique dans la base de données.
De même, les tables du deuxième type ont les champs système $from_id et $to_id , les enregistrements de ces tables définissent clairement les relations entre les nœuds. Une table distincte est utilisée pour stocker les relations de chaque type.
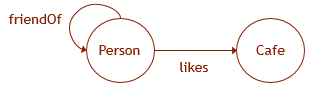 Nous illustrons ce qui a été dit par l'exemple. Laissez les données du graphique avoir un schéma comme indiqué dans la figure. Ensuite, pour créer la structure correspondante dans la base de données, vous devez exécuter les requêtes DDL suivantes:
Nous illustrons ce qui a été dit par l'exemple. Laissez les données du graphique avoir un schéma comme indiqué dans la figure. Ensuite, pour créer la structure correspondante dans la base de données, vous devez exécuter les requêtes DDL suivantes:
CREATE TABLE Person ( ID INTEGER NOT NULL, name VARCHAR(100) ) AS NODE; CREATE TABLE Cafe ( ID INTEGER NOT NULL, name VARCHAR(100), ) AS NODE; CREATE TABLE likes ( rating INTEGER ) AS EDGE; CREATE TABLE friendOf AS EDGE;
La principale spécificité de ces tables est qu'il est possible d'utiliser des modèles de graphique avec une syntaxe de type Cypher dans leurs requêtes (cependant, « * », etc., ne sont pas encore pris en charge). En outre, sur la base des mesures de performances, on peut supposer que la méthode de stockage des données dans ces tables est différente du mécanisme de stockage des données dans des tables ordinaires et est optimisée pour effectuer de telles requêtes de graphique.
SELECT Cafe.name FROM Person, likes, Cafe WHERE MATCH (Person-(friendOf)-(likes)->Cafe) AND Person.name = 'John';
De plus, il est assez difficile de ne pas utiliser ces modèles de graphique lorsque vous travaillez avec de telles tables, car dans les requêtes SQL ordinaires pour résoudre des problèmes similaires, des efforts supplémentaires seront nécessaires pour obtenir les identifiants de nœud du "graphique" du système ( $node_id , $from_id , $to_id ; pour cela pour la même raison, les demandes d'insertion de données ne sont pas données ici car trop lourdes).
En résumant la description des implémentations des modèles de documents et de graphiques dans MS SQL Server, je voudrais noter que de telles implémentations d'un modèle au-dessus d'un autre ne semblent pas réussir principalement en termes de conception de langage. Il faut étendre une langue avec une autre, les langues ne sont pas complètement «orthogonales», les règles de compatibilité peuvent être assez bizarres.
SGBD multimodèle basé sur un modèle de document
Dans cette section, je voudrais illustrer l'implémentation du multimodèle dans les SGBD de document en utilisant l'exemple de MongoDB, le plus populaire d'entre eux (comme cela a été dit, il ne contient que les opérateurs de graphes conditionnellement $lookup et $graphLookup qui ne fonctionnent pas sur les collections de fragments), mais sur l'exemple, il est plus mature et " Entreprise »SGBD MarkLogic .
Donc, laissez la collection contenir un ensemble de documents XML de la forme suivante (MarkLogic permet également de stocker des documents JSON):
<Person INN="631803299804"> <name>John</name> <surname>Smith</surname> </Person>
Modèle relationnel chez MarkLogic
Une représentation relationnelle d'une collection de documents peut être créée à l'aide d'un modèle d'affichage (le contenu des éléments de value dans l'exemple ci-dessous peut être XPath arbitraire):
<template xmlns="http://marklogic.com/xdmp/tde"> <context>/Person</context> <rows> <row> <view-name>Person</view-name> <columns> <column> <name>SSN</name> <value>@SSN</value> <type>string</type> </column> <column> <name>name</name> <value>name</value> </column> <column> <name>surname</name> <value>surname</value> </column> </columns> </row> <rows> </template>
Une requête SQL peut être adressée à la vue créée (par exemple, via ODBC):
SELECT name, surname FROM Person WHERE name="John"
Malheureusement, la vue relationnelle créée à l'aide du modèle d'affichage est en lecture seule. Lors du traitement d'une demande, MarkLogic essaiera d'utiliser des index de documents . Il y avait autrefois des vues relationnelles limitées dans MarkLogic qui étaient entièrement basées sur des index et accessibles en écriture, mais maintenant elles sont considérées comme obsolètes.
Modèle de graphique dans MarkLogic
Avec la prise en charge du modèle graphique ( RDF ), les choses sont à peu près les mêmes. Encore une fois, en utilisant le modèle d'affichage, vous pouvez créer une représentation RDF de la collection de documents à partir de l'exemple ci-dessus:
<template xmlns="http://marklogic.com/xdmp/tde"> <context>/Person</context> <vars> <var> <name>PREFIX</name> <val>"http://example.org/example#"</val> </var> </vars> <triples> <triple> <subject><value>sem:iri( $PREFIX || @SSN )</value></subject> <predicate><value>sem:iri( $PREFIX || surname )</value></predicate> <object><value>xs:string( surname )</value></object> </triple> <triple> <subject><value>sem:iri( $PREFIX || @SSN )</value></subject> <predicate><value>sem:iri( $PREFIX || name )</value></predicate> <object><value>xs:string( name )</value></object> </triple> </triples> </template>
Le graphe RDF résultant peut être adressé avec une requête SPARQL:
PREFIX : <http://example.org/example
Contrairement au relationnel, le modèle de graphe MarkLogic prend en charge de deux autres manières:
- Le SGBD peut être un référentiel séparé à part entière de données RDF (les triplets qu'il contient seront appelés gérés, par opposition à l' extrait extrait ci-dessus).
- RDF en sérialisation spéciale peut simplement être inséré dans des documents XML ou JSON (et les triplets seront alors appelés non gérés ). C'est probablement une telle alternative aux mécanismes
idref , etc.
L' API optique donne une bonne idée de la façon dont «vraiment» tout fonctionne dans MarkLogic, en ce sens, elle est de bas niveau, bien que son objectif soit plutôt le contraire - pour essayer d'abstraire du modèle de données utilisé, pour assurer un travail cohérent avec les données dans différents modèles, pr
SGBD multimodèle «sans le modèle principal»
Les SGBD sont également disponibles sur le marché, se positionnant comme initialement multi-modèles, n'ayant pas de modèle de base hérité. Il s'agit notamment d' AangoDB , d' OrientDB (depuis 2018, la société de développement appartient à SAP) et de CosmosDB (un service inclus dans la plateforme cloud Microsoft Azure).
En fait, il existe des modèles «de base» dans ArangoDB et OrientDB. Dans les deux cas, il s'agit de modèles de données propriétaires, qui sont des généralisations de documents. Les généralisations visent principalement à faciliter la capacité de produire des requêtes graphiques et relationnelles.
Ces modèles sont les seuls disponibles pour une utilisation dans les SGBD indiqués; leurs propres langages de requête sont conçus pour fonctionner avec eux. Bien sûr, ces modèles et SGBD sont prometteurs, mais le manque de compatibilité avec les modèles et les langages standard rend impossible l'utilisation de ces SGBD dans les systèmes hérités - en les remplaçant par le SGBD qu'ils utilisent déjà.
Sur ArangoDB et OrientDB sur Habré, il y avait déjà un merveilleux article: JOIN dans les bases de données NoSQL .
Arangodb
ArangoDB revendique la prise en charge d'un modèle de données de graphique.
Les nœuds de graphique dans ArangoDB sont des documents ordinaires et les bords sont des documents d'un type spécial qui ont, avec les champs système habituels ( _key , _rev , _rev ), les champs système _from et _from . Les documents dans les SGBD de documents sont traditionnellement combinés en collections. Les collections de documents représentant des bords sont appelées collections de bords dans ArangoDB. Soit dit en passant, les documents des collections de bords sont également des documents, de sorte que les bords dans ArangoDB peuvent également agir comme des nœuds.
Données sourceSupposons que nous ayons une collection de persons dont les documents ressemblent à ceci:
[ { "_id" : "people/alice" , "_key" : "alice" , "name" : "" }, { "_id" : "people/bob" , "_key" : "bob" , "name" : "" } ]
Ayons aussi une collection de cafes :
[ { "_id" : "cafes/jd" , "_key" : "jd" , "name" : " " }, { "_id" : "cafes/jj" , "_key" : "jj" , "name" : "-" } ]
La collection de likes pourrait alors ressembler à ceci:
[ { "_id" : "likes/1" , "_key" : "1" , "_from" : "persons/alice" , "_to" : "cafes/jd", "since" : 2010 }, { "_id" : "likes/2" , "_key" : "2" , "_from" : "persons/alice" , "_to" : "cafes/jj", "since" : 2011 } , { "_id" : "likes/3" , "_key" : "3" , "_from" : "persons/bob" , "_to" : "cafes/jd", "since" : 2012 } ]
Requêtes et résultatsUne requête de style graphique en AQL utilisée dans ArangoDB qui retourne sous forme lisible par l'homme des informations sur qui aime quel café ressemble à ceci:
FOR p IN persons FOR c IN OUTBOUND p likes RETURN { person : p.name , likes : c.name }
Dans un style relationnel, lorsque nous sommes plus susceptibles de «calculer» les relations, plutôt que de les stocker, cette requête peut être réécrite comme ceci (à propos, vous pouvez vous passer de la collection likes ):
FOR p IN persons FOR l IN likes FILTER p._key == l._from FOR c IN cafes FILTER l._to == c._key RETURN { person : p.name , likes : c.name }
Le résultat dans les deux cas sera le même:
[ { "person" : "" , likes : "-" } , { "person" : "" , likes : " " } , { "person" : "" , likes : " " } ]
Plus de requêtes et de résultatsS'il semble que le format du résultat ci-dessus est plus typique pour un SGBD relationnel que pour un document, vous pouvez essayer cette requête (ou vous pouvez utiliser COLLECT ):
FOR p IN persons RETURN { person : p.name, likes : ( FOR c IN OUTBOUND p likes RETURN c.name ) }
Le résultat sera le suivant:
[ { "person" : "" , likes : ["-" , " "] } , { "person" : "" , likes : [" "] } ]
Oriententb
L'implémentation du modèle graphique au-dessus du modèle de document dans OrientDB est basée sur la capacité des champs de document à avoir, en plus des valeurs scalaires plus ou moins standard, des valeurs de types tels que LINK , LINKLIST , LINKSET , LINKMAP et LINKBAG . Les valeurs de ces types sont des liens ou des collections de liens vers des identificateurs de document système .
L'identifiant de document attribué par le système a une «signification physique», indiquant la position de l'enregistrement dans la base de données, et ressemble à ceci: @rid : #3:16 . Ainsi, les valeurs des propriétés de référence sont des pointeurs vraiment plus probables (comme dans un modèle graphique), plutôt que des conditions de sélection (comme dans un modèle relationnel).
Comme dans ArangoDB, dans OrientDB, les bords sont représentés par des documents séparés (bien que si le bord n'a pas ses propres propriétés, il peut être allégé et un document séparé ne lui correspondra pas).
Données sourceDans un format proche du format de vidage de la base de données OrientDB, les données de l'exemple précédent pour ArangoDB ressembleraient à ceci:
[ { "@type": "document", "@rid": "#11:0", "@class": "Person", "name": "", "out_likes": [ "#30:1", "#30:2" ], "@fieldTypes": "out_likes=LINKBAG" }, { "@type": "document", "@rid": "#12:0", "@class": "Person", "name": "", "out_likes": [ "#30:3" ], "@fieldTypes": "out_likes=LINKBAG" }, { "@type": "document", "@rid": "#21:0", "@class": "Cafe", "name": "-", "in_likes": [ "#30:2", "#30:3" ], "@fieldTypes": "in_likes=LINKBAG" }, { "@type": "document", "@rid": "#22:0", "@class": "Cafe", "name": " ", "in_likes": [ "#30:1" ], "@fieldTypes": "in_likes=LINKBAG" }, { "@type": "document", "@rid": "#30:1", "@class": "likes", "in": "#22:0", "out": "#11:0", "since": 1262286000000, "@fieldTypes": "in=LINK,out=LINK,since=date" }, { "@type": "document", "@rid": "#30:2", "@class": "likes", "in": "#21:0", "out": "#11:0", "since": 1293822000000, "@fieldTypes": "in=LINK,out=LINK,since=date" }, { "@type": "document", "@rid": "#30:3", "@class": "likes", "in": "#21:0", "out": "#12:0", "since": 1325354400000, "@fieldTypes": "in=LINK,out=LINK,since=date" } ]
Comme nous pouvons le voir, les sommets stockent également des informations sur les bords entrants et sortants. Lorsque vous utilisez l' API Document, vous devez vous-même respecter l'intégrité référentielle, et l'API Graph s'en charge. Mais voyons à quoi ressemble l'appel à OrientDB dans «propre», non intégré dans les langages de programmation, les langages de requête.
Requêtes et résultatsUne requête similaire à la requête de l'exemple pour ArangoDB dans OrientDB ressemble à ceci:
SELECT name AS person_name, OUT('likes').name AS cafe_name FROM Person UNWIND cafe_name
Le résultat sera obtenu comme suit:
[ { "person_name": "", "cafe_name": " " }, { "person_name": "", "cafe_name": "-" }, { "person_name": "", "cafe_name": "-" } ]
Si le format du résultat semble à nouveau trop "relationnel", vous devez supprimer la ligne avec UNWIND() :
[ { "person_name": "", "cafe_name": [ " ", "-" ] }, { "person_name": "", "cafe_name": [ "-" ' } ]
Le langage de requête OrientDB peut être décrit comme SQL avec des insertions de type Gremlin. La version 2.2 a introduit un formulaire de demande de type Cypher, MATCH :
MATCH {CLASS: Person, AS: person}-likes->{CLASS: Cafe, AS: cafe} RETURN person.name AS person_name, LIST(cafe.name) AS cafe_name GROUP BY person_name
Le format du résultat sera le même que dans la requête précédente. Pensez à ce qui doit être supprimé pour le rendre plus «relationnel», comme dans la toute première requête.
Azure CosmosDB
Dans une moindre mesure, ce qui a été dit ci-dessus concernant ArangoDB et OrientDB fait référence à Azure CosmosDB. CosmosDB fournit les API d'accès aux données suivantes: SQL, MongoDB, Gremlin et Cassandra.
L'API SQL et l'API MongoDB sont utilisées pour accéder aux données dans le modèle de document. API Gremlin et API Cassandra - pour accéder aux données dans le graphique et la colonne, respectivement. Les données de tous les modèles sont enregistrées au format du modèle interne de CosmosDB: ARS («atom-record-sequence»), qui est également proche de celui du document.

Mais le modèle de données sélectionné par l'utilisateur et l'API utilisée sont fixes au moment de la création du compte dans le service. Il est impossible d'accéder aux données chargées dans un modèle au format d'un autre modèle, ce qui serait illustré par quelque chose comme ceci:

Ainsi, le multimodèle dans Azure CosmosDB n'est aujourd'hui qu'une opportunité d'utiliser plusieurs bases de données qui prennent en charge différents modèles du même fabricant, ce qui ne résout pas tous les problèmes de stockage multivarié.
SGBD multimodèle basé sur un modèle graphique?
Il est à noter qu'il n'existe sur le marché aucun SGBD multimodèle basé sur un modèle graphique (à l'exception de la prise en charge multimodèle simultanée de deux modèles graphiques: RDF et LPG; voir ceci dans une publication précédente ). Les plus grandes difficultés sont l'implémentation au dessus du modèle graphique du document, plutôt que le relationnel.
La question de savoir comment mettre en œuvre un modèle relationnel sur un modèle de graphe a été examinée même au moment de la formation de ce dernier. Comme l'a dit David McGovern , par exemple:
Il n'y a rien d'inhérent à l'approche graphique qui empêche la création d'une couche (par exemple, par une indexation appropriée) sur une base de données graphique qui permet une vue relationnelle avec (1) la récupération des tuples à partir des paires de valeurs clés habituelles et (2) le regroupement des tuples par type de relation.
Lorsque vous implémentez le modèle de document en haut du graphique, vous devez garder à l'esprit, par exemple, les éléments suivants:
- Les éléments du tableau JSON sont considérés comme ordonnés, venant du haut du bord du graphique - non;
- Les données du modèle de document sont généralement dénormalisées, vous ne souhaitez toujours pas stocker plusieurs copies du même document joint et les sous-documents n'ont généralement pas d'identificateurs;
- D'un autre côté, l'idéologie des SGBD de documents est que les documents sont des «unités» toutes faites qui n'ont pas besoin d'être reconstruites à chaque fois. Il est nécessaire de fournir dans le modèle graphique la possibilité d'obtenir rapidement le sous-graphique correspondant au document fini.
Quelques publicitésL'auteur de l'article est lié au développement du SGBD NitrosBase, dont le modèle interne est graphique, et les modèles externes - relationnels et documentaires - sont ses représentations. Tous les modèles sont égaux: presque toutes les données sont disponibles dans chacun d'eux en utilisant le langage de requête naturel pour cela. De plus, dans toute représentation, les données sont susceptibles de changer. Les changements seront reflétés dans le modèle interne et, par conséquent, dans d'autres représentations.
À quoi ressemble la correspondance de modèles dans NitrosBase - je vais le décrire, je l'espère, dans l'un des articles suivants.
Conclusion
J'espère que les contours généraux de ce qu'on appelle le multimodélisme sont devenus plus ou moins clairs pour le lecteur. Des SGBD assez différents sont appelés multimodèles et la «prise en charge de plusieurs modèles» peut être différente. Pour comprendre ce qu'on appelle «multi-modèle» dans chaque cas, il est utile de répondre aux questions suivantes:
- S'agit-il de la prise en charge de modèles traditionnels ou d'un modèle hybride unique?
- Les modèles sont-ils «égaux» ou l'un d'eux est-il soumis aux autres?
- Les modèles sont-ils "indifférents" les uns aux autres? Les données enregistrées dans un modèle peuvent-elles être lues dans un autre ou même écrasées?
Je pense qu'il est déjà possible de donner une réponse positive à la question de la pertinence des SGBD multimodèles, mais la question intéressante est de savoir lesquelles de leurs variétés seront plus en demande dans un avenir proche. Il semble que les SGBD multimodèles qui prennent en charge les modèles traditionnels, principalement relationnels, seront plus demandés; , , , — .