Remarque perev. : Ce que l'on appelle aujourd'hui SRE (Site Reliability Engineering - «assurer la fiabilité des systèmes d'information») comprend un large éventail de mesures pour le fonctionnement des produits logiciels visant à atteindre le niveau de fiabilité requis. La surveillance est l'un des événements clés, et les «signaux d'or» constituent les principales mesures qui devraient y être prises en compte. N'ayant trouvé aucun document à leur sujet sur Habré, nous avons décidé de traduire une courte note des auteurs de la plateforme de gestion des incidents (VictorOps), qui donne une idée de l'idée générale de cette approche.
Une ingénierie de fiabilité de site efficace (
SRE ) repose sur une compréhension approfondie de l'infrastructure et de l'architecture de service sous-jacentes. Accroître la transparence de l'état de l'application et de l'infrastructure n'est que le début d'un travail proactif sur la création de systèmes fiables. Dans le même temps, les soi-disant «quatre signaux d'or» SRE sont considérés comme le meilleur point de départ pour surveiller l'état des systèmes. Une fois ces quatre méthodes de surveillance de base établies, nous pouvons continuer à accroître la transparence du système.
Une transparence accrue, associée à des méthodes de collaboration efficaces, permet aux équipes SRE de surveiller rapidement les systèmes et de prendre des mesures pour éliminer les conséquences des incidents, augmentant ainsi l'efficacité globale des méthodes de
surveillance et d'alerte . Les signaux Gold SRE aident les équipes à identifier les faiblesses potentielles de la fiabilité, leur permettant de se concentrer sur le dépannage des problèmes d'infrastructure. Examinons la relation entre les méthodes de surveillance et les commandes SRE et voyons quel effet les signaux d'or ont sur le processus.
Surveillance et SRE
Dans la partie III de notre
dictionnaire DevOps, nous avons exploré Internet, en essayant de trouver une définition du SRE. Selon un
article de Wikipédia connexe,
«Ben Treynor, le fondateur de l'équipe de fiabilité du site chez Google [dit] que le SRE est« ce qui se passe quand un ingénieur logiciel fait ce qu'on appelait la maintenance » .
» SRE combine les défis et les capacités de l'ingénierie logicielle avec les défis de l'exploitation informatique et vous aide à trouver des solutions aux problèmes de fiabilité. Il est entendu que les équipes SRE doivent surveiller leurs services pour identifier les domaines où la fiabilité peut être améliorée.
C'est précisément la mission de suivi des équipes SRE. Il n'occupe qu'une petite partie de la
création de systèmes hautement transparents , mais c'est un élément important pour comprendre l'état des applications et de l'infrastructure. Quatre signaux de surveillance dorés et SRE offrent un niveau de transparence de base concernant la fiabilité de tout ce que vous créez. Ayant atteint un niveau d'observabilité confortable de l'état des signaux d'or, vous pouvez utiliser ces informations supplémentaires pour une analyse plus approfondie à l'aide d'outils de surveillance.
Maintenant que nous avons décidé de l'importance de surveiller les signaux SRE or, tournons-nous vers les métriques réelles qui les composent.
Quatre signaux de surveillance dorés
Au début du processus d'amélioration des efforts de surveillance, il peut être difficile de comprendre par où commencer. Les quatre signaux d'or SRE et de surveillance ont été cités pour la première fois dans
le livre de Google sur SRE , et sont maintenant activement utilisés par de nombreuses équipes. C'est formidable de commencer avec eux, car ils aident à mettre en évidence les principales statistiques qui doivent toujours être suivies.
Examinons donc les signaux d'or et voyons pourquoi leur surveillance fait partie intégrante de la fiabilité de tout système.
1. Latence
Combien de temps faut-il pour traiter une demande? Définissez un point de référence pour les retards typiques des demandes réussies et comparez-le aux retards pour les demandes infructueuses. Le suivi des retards causés par des erreurs vous permet de résoudre tout problème lié à la vitesse de détection et de réponse aux incidents.
2. Trafic
Ce signal ne nécessite aucune explication particulière. Quel effet le nombre d'utilisateurs ou le nombre de transactions passant par le service a-t-il sur le système? Selon la fonctionnalité du service, la mesure du trafic peut différer considérablement d'une entreprise à l'autre. En suivant les interactions avec les utilisateurs réels et le trafic, vous pouvez mieux comprendre comment les utilisateurs finaux perçoivent le service et avoir une idée du comportement des systèmes en situation de stress.
3. Erreurs
Bien sûr, chaque équipe doit garder une trace des erreurs. Que les erreurs soient déclenchées manuellement ou autonomes (comme une requête HTTP ayant échoué), les commandes SRE doivent les suivre. De nombreuses équipes SRE utilisent un
logiciel spécial de
gestion des incidents pour les alerter des erreurs critiques, trouver leurs causes et prendre des mesures correctives.
4. Saturation
Chaque équipe doit surveiller la charge de son système. Il est important de définir une métrique de saturation, ce qui signifierait que le service a atteint le maximum de ses capacités. La plupart des services commencent à perdre des performances avant même que la charge n'atteigne 100%. Il est donc important de comprendre les fonctionnalités de votre propre système pour déterminer la directive de saturation qui a du sens.
En définissant des règles de surveillance et d'alerte pour les quatre signaux d'or, vous couvrirez la plupart des incidents clés du système. Cependant, pour commencer à créer un système de surveillance proactif et SRE, vous devez creuser encore plus.
Remarque perev. : Pour illustrer un tableau de bord avec des graphiques «signaux d'or», nous présentons le résultat de la configuration de surveillance correspondante pour Kubernetes à partir de cet article de Sysdig :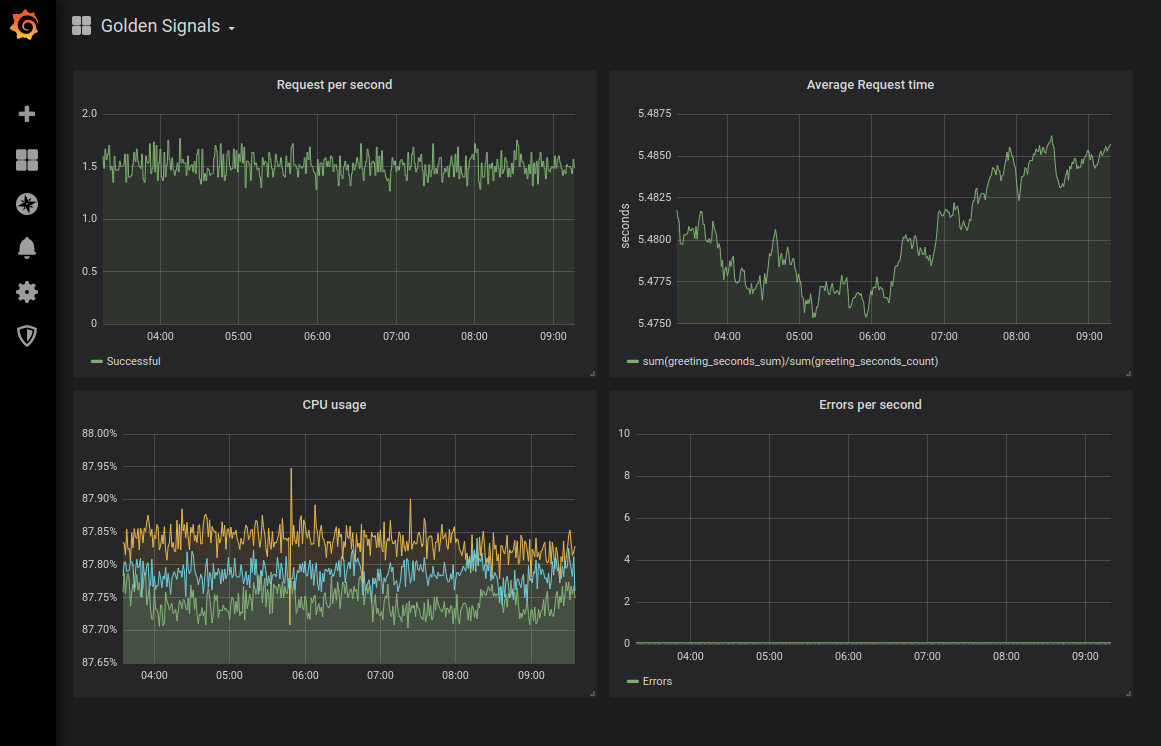 Remarque perev. : Et voici une représentation plus visuelle des signaux d'or de Denise Yu , qui peut être utilisée comme mémo pratique:
Remarque perev. : Et voici une représentation plus visuelle des signaux d'or de Denise Yu , qui peut être utilisée comme mémo pratique:
SRE proactif va au-delà des signaux d'or
La surveillance des signaux d'or est un bon début pour analyser les incidents dans le service, mais ce n'est pas suffisant. Les équipes SRE expérimentées explorent de manière proactive leurs systèmes avec de nombreuses méthodes supplémentaires. Réalisant des tests organisés en phase préparatoire et en production, les équipes SRE étudient activement leurs systèmes et utilisent les informations reçues pour accroître la fiabilité des services.
Ingénierie du chaos
L'ingénierie du chaos est une discipline que les équipes utilisent pour tester leurs systèmes afin de détecter de manière proactive les faiblesses et les vulnérabilités. En introduisant manuellement le chaos dans le service, vous pouvez voir comment le système réagit à diverses circonstances.
Remarque perev. : En savoir plus sur cette approche dans l'article «Chaos Engineering: l'art de la destruction intentionnelle» ( partie 1 et partie 2 ).Jours de jeu
Alors que l'ingénierie du chaos se concentre sur la compréhension du système,
les journées de jeu aident le personnel à comprendre. Ils sont utilisés pour tester la résilience de l'équipe lorsqu'il s'agit de répondre aux incidents et d'éliminer leurs conséquences. Les résultats des journées de jeu peuvent être utilisés pour développer des processus plus efficaces ou pour déterminer le besoin de nouveaux outils qui augmentent l'efficacité du personnel.
Surveillance synthétique
La surveillance synthétique permet aux équipes de créer des utilisateurs artificiels et de simuler leur comportement à l'aide du service. Vous pouvez définir des modèles de comportement spécifiques et observer le comportement du système sous une charge donnée. La surveillance synthétique est une excellente méthode pour effectuer des tests détaillés et déterminer la fiabilité de services spécifiques dans l'ensemble du système.
...
Toute équipe cherchant à surveiller visuellement l'état du système est tenue de surveiller les signaux SRE dorés. Mais l'idée de l'état et de la fiabilité globale du système n'est pas du tout la même chose que de travailler pour augmenter sa fiabilité. Dans un écosystème moderne de systèmes hautement distribués et à déploiement rapide, les équipes SRE sont confrontées à une tâche ardue. Les signaux d'or de la surveillance et du SRE peuvent être le point de départ à partir duquel de nouvelles
améliorations au sein du SRE commenceront.
PS du traducteur
Lisez aussi dans notre blog: