
Salut, habrozhiteli! Si, pendant longtemps, il vous semble que tous les développements et déploiements dans votre entreprise se sont ralentis au maximum, passez à l'architecture de microservices. Il assure le développement, la livraison et le déploiement continus d'applications de toute complexité.
Le livre, destiné aux développeurs et architectes de grandes entreprises, explique comment concevoir et écrire des applications dans l'esprit de l'architecture de microservices. Il décrit également comment refactoriser une grande application - et le monolithe se transforme en un ensemble de microservices.
Nous vous proposons de vous familiariser avec le passage "Transaction Management in Microservice Architecture"
Presque toutes les demandes traitées par une application industrielle sont exécutées dans le cadre d'une transaction de base de données. Les développeurs de ces applications utilisent des cadres et des bibliothèques qui simplifient le travail avec les transactions. Certains outils fournissent une API impérative pour démarrer, valider et annuler manuellement les transactions. Et les frameworks comme Spring ont un mécanisme déclaratif. Spring prend en charge l'annotation @Transactional, qui invoque automatiquement une méthode dans une transaction. Grâce à cela, l'écriture de la logique métier transactionnelle devient assez simple.
Pour être plus précis, la gestion des transactions est simple dans les applications monolithiques qui accèdent à une seule base de données. Si l'application utilise plusieurs bases de données et courtiers de messages, ce processus devient plus difficile. Eh bien, dans l'architecture de microservice, les transactions couvrent plusieurs services, chacun ayant sa propre base de données. Dans de telles circonstances, l'application doit utiliser un mécanisme de transaction plus sophistiqué. Comme vous le verrez bientôt, l'approche traditionnelle des transactions distribuées n'est pas viable dans les applications modernes. Les systèmes basés sur les microservices devraient plutôt utiliser la narration.
Mais avant de passer aux récits, voyons pourquoi la gestion des transactions crée autant de complexités dans une architecture de microservices.
4.1.1. Architecture de microservice et besoin de transactions distribuées
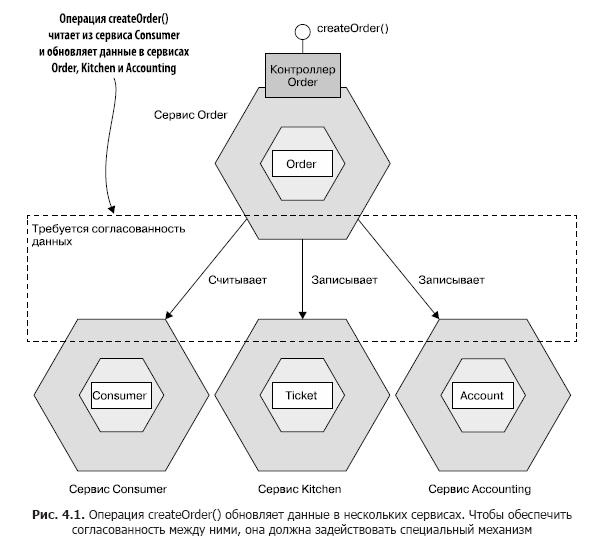
Imaginez que vous êtes développeur chez FTGO et êtes responsable de l'implémentation du fonctionnement du système createOrder (). Comme décrit au chapitre 2, cette opération doit garantir que le client peut passer des commandes, vérifier les détails de la commande, autoriser la carte bancaire du client et créer un enregistrement de commande dans la base de données. La mise en œuvre de ces actions serait relativement simple dans une application monolithique. Toutes les données nécessaires pour vérifier que la commande est prête et disponible. De plus, les transactions ACID pourraient être utilisées pour garantir la cohérence des données. Vous pouvez simplement spécifier l'annotation @Transactional pour la méthode de service createOrder ().
Cependant, effectuer cette opération dans une architecture de microservice est beaucoup plus difficile. Comme on peut le voir sur la fig. 4.1, les données requises par les opérations createOrder () sont dispersées sur plusieurs services. createOrder () lit les informations du service Consommateur et met à jour le contenu des services Commande, Cuisine et Comptabilité.
Étant donné que chaque service possède sa propre base de données, vous devez utiliser un mécanisme pour coordonner les données entre eux.
4.1.2. Problèmes de transaction distribuée
L'approche traditionnelle pour assurer la cohérence des données entre plusieurs services, bases de données ou courtiers de messages est l'utilisation de transactions distribuées. Le standard de facto pour la gestion des transactions distribuées est X / Open XA (voir
en.wikipedia.org/wiki/XA ). Le modèle XA utilise la validation en deux phases (2PC) pour garantir que toutes les modifications apportées à la transaction sont enregistrées ou annulées. Cela nécessite des bases de données, des courtiers de messages, des pilotes de base de données et des API de messagerie pour se conformer à la norme XA, et un mécanisme de communication interprocessus qui distribue les identificateurs de transaction XA globaux est également requis. La plupart des bases de données relationnelles sont compatibles XA, tout comme certains courtiers de messages. Par exemple, une application basée sur Java EE peut effectuer des transactions distribuées à l'aide du JTA.
Malgré leur simplicité, les transactions distribuées présentent un certain nombre de problèmes. De nombreuses technologies modernes, notamment les bases de données NoSQL telles que MongoDB et Cassandra, ne les prennent pas en charge. Les transactions distribuées ne sont pas prises en charge par certains courtiers de messages modernes comme RabbitMQ et Apache Kafka. Donc, si vous décidez d'utiliser des transactions distribuées, de nombreux outils modernes ne seront pas à votre disposition.
Un autre problème avec les transactions distribuées est qu'elles sont une forme d'IPC synchrone, ce qui nuit à la disponibilité. Pour qu'une transaction distribuée soit validée, tous les services impliqués doivent être accessibles. Comme décrit au chapitre 3, l'accessibilité du système est un produit de l'accessibilité de tous les participants aux transactions. Si deux services avec une disponibilité de 99,5% participent à une transaction distribuée, la disponibilité globale sera de 99%, ce qui est beaucoup moins. Chaque service supplémentaire réduit le degré de disponibilité. Eric Brewer a formulé le théorème CAP, qui stipule qu'un système ne peut avoir que deux des trois propriétés suivantes: cohérence, accessibilité et résistance de partition (en.wikipedia.org/wiki/CAP_ Theorem). Aujourd'hui, les architectes privilégient les systèmes abordables, sacrifiant la cohérence.
À première vue, les transactions distribuées peuvent sembler attrayantes. Du point de vue du développeur, ils ont le même modèle logiciel que les transactions locales. Mais en raison des problèmes décrits précédemment, cette technologie n'est pas viable dans les applications modernes. Le chapitre 3 a montré comment envoyer des messages dans le cadre d'une transaction de base de données sans utiliser de transactions distribuées. Pour résoudre le problème plus complexe d'assurer la cohérence des données dans une architecture de microservices, l'application doit utiliser un mécanisme différent basé sur le concept de services asynchrones à couplage lâche. Et ici, les récits sont utiles.
4.1.3. Utilisez le modèle Storytelling pour maintenir la cohérence des données
La narration est un mécanisme qui garantit la cohérence des données dans une architecture de microservice sans utiliser de transactions distribuées. Le récit est créé pour chaque équipe système qui doit mettre à jour les données de plusieurs services. Il s'agit d'une séquence de transactions locales, chacune mettant à jour les données dans un service, en utilisant les cadres et bibliothèques familiers pour les transactions ACID mentionnés précédemment.
Modèle de narration
Garantit la cohérence des données entre les services à l'aide d'une séquence de transactions locales coordonnées avec des messages asynchrones. Voir microservices.io/patterns/data/saga.html .
L'opération du système amorce la première étape de la narration. L'achèvement d'une transaction locale conduit à ce qui suit. Dans la section 4.2, vous verrez comment la coordination de ces étapes est réalisée à l'aide de messages asynchrones. Un avantage important de la messagerie asynchrone est qu'elle garantit que toutes les étapes de la narration sont terminées, même si un ou plusieurs participants sont inaccessibles.
Les narrations présentent plusieurs différences importantes par rapport aux transactions ACID. Tout d'abord, ils manquent d'isolement (pour plus d'informations, voir la section 4.3). De plus, comme chaque transaction locale capture ses modifications, pour revenir en arrière, vous devez utiliser des transactions compensatoires, dont nous parlerons plus loin dans cette section. Prenons un exemple de narration.
Exemple narratif: création d'une commande
Dans ce chapitre, nous utilisons le récit Créer un ordre comme exemple (Fig. 4.2). Il implémente l'opération createOrder (). La première transaction locale est déclenchée par une demande de création de commande externe. Les cinq transactions restantes sont déclenchées l'une après l'autre.
Ce récit comprend les transactions locales suivantes.
1. Commandez le service. Crée une commande avec l'état APPROVAL_PENDING.
2. Consommateur de services. Vérifie si le client peut passer des commandes.
3. Service de cuisine. Vérifie les détails de la commande et crée une demande avec le statut CREATE_PENDING.
4. Service de comptabilité. Autorise la carte bancaire d'un client.
5. Service de cuisine. Modifie le statut d'une application en AWAITING_ACCEPTANCE.
6. Ordre de service. Modifie le statut de la commande en APPROUVÉ.
Dans la section 4.2, je montrerai comment les services impliqués dans l'histoire interagissent les uns avec les autres à l'aide de messages asynchrones. Le service publie un message à la fin d'une transaction locale. Cela amorce la prochaine étape de la narration et permet non seulement d'obtenir une faible cohésion des participants, mais aussi de garantir la pleine mise en œuvre de la narration. Même si le destinataire est temporairement indisponible, le courtier met le message en mémoire tampon jusqu'à ce qu'il puisse être remis.
Les récits semblent simples, mais leur utilisation est associée à certaines difficultés, notamment à un manque d'isolement entre eux. La solution au problème est décrite dans la section 4.3. Un autre aspect non trivial est l'annulation des modifications lorsqu'une erreur se produit. Voyons comment cela se fait.
Les récits utilisent des transactions de compensation pour annuler les modifications
Les transactions ACID traditionnelles ont une grande fonctionnalité: la logique métier peut facilement annuler une transaction si une violation de règle métier est détectée. Il exécute simplement la commande ROLLBACK et la base de données annule toutes les modifications apportées jusqu'à présent. Malheureusement, l'histoire ne peut pas être annulée automatiquement, car à chaque étape, elle capture les modifications dans la base de données locale. Cela signifie, par exemple, qu'en cas d'échec de l'autorisation d'une carte bancaire au cours de la quatrième étape de la narration de l'ordre de création, l'application FTGO doit annuler manuellement les modifications apportées au cours des trois étapes précédentes. Vous devez écrire les transactions dites de compensation.
Supposons que la (n + 1) -ème transaction de l'histoire ait échoué. Il est nécessaire de neutraliser les conséquences des n transactions précédentes. Au niveau conceptuel, chacune de ces étapes Ti a sa propre transaction de compensation Ci, qui annule l'effet de Ti. Pour compenser l'effet des n premières étapes, le récit doit exécuter chaque transaction Ci dans l'ordre inverse. La séquence ressemble à ceci: T1 ... Tn, Cn ... C1 (Fig. 4.3). Dans cet exemple, l'étape Tn + 1 échoue, ce qui nécessite l'annulation des étapes T1 ... Tn.
Le récit effectue des transactions compensatoires dans l'ordre inverse des transactions originales: Cn ... C1. Ici, le même mécanisme d'exécution séquentiel fonctionne que dans le cas de Ti. La résiliation de Ci devrait déclencher Ci - 1.
Prenons, par exemple, le récit de Créer un ordre. Il peut échouer pour diverses raisons.
1. Informations incorrectes sur le client ou le client n'est pas autorisé à créer des commandes.
2. Informations incorrectes sur le restaurant ou le restaurant n'est pas en mesure d'accepter la commande.
3. Impossibilité d'autoriser la carte bancaire d'un client.
En cas d'échec de la transaction locale, le mécanisme de coordination de la narration doit effectuer des étapes compensatoires qui refusent la commande et éventuellement la commande. Dans le tableau. 4.1 Les transactions compensatoires sont collectées pour chaque étape du récit Créer une commande. Il convient de noter que toutes les étapes ne nécessitent pas une transaction compensatoire. Cela s'applique, par exemple, aux opérations de lecture, telles que verifyConsumerDetails (), ou à l'opération authorizeCreditCard (), toutes les étapes après lesquelles elles réussissent toujours.
Dans la section 4.3, vous découvrirez que les trois premières étapes du récit Créer une commande sont appelées transactions disponibles pour compensation, car les étapes qui les suivent peuvent échouer. La quatrième étape est appelée transaction tournante car les étapes suivantes n'échouent jamais. Les deux dernières étapes sont appelées transactions répétables, car elles se terminent toujours avec succès.
Pour comprendre comment les transactions compensatoires sont utilisées, imaginez une situation dans laquelle l'autorisation de la carte bancaire d'un client échoue. Dans ce cas, le récit effectue les transactions locales suivantes.
1. Commandez le service. Crée une commande avec l'état APPROVAL_PENDING.
2. Consommateur de services. Vérifie si le client peut passer des commandes.
3. Service de cuisine. Vérifie les détails de la commande et crée une demande avec le statut CREATE_PENDING.
4. Service de comptabilité. Effectue une tentative infructueuse d'autoriser la carte bancaire d'un client.
5. Service de cuisine. Modifie le statut de l'application en CREATE_REJECTED.
6. Ordre de service. Change le statut de la commande en REJETÉ.
Les cinquième et sixième étapes sont des transactions compensatoires qui annulent les mises à jour effectuées par les services de cuisine et, par conséquent, la commande. La logique narrative de coordination est responsable de la séquence des transactions directes et compensatoires. Voyons comment cela fonctionne.
À propos de l'auteur
Chris Richardson est le développeur, l'architecte et l'auteur de POJOs in Action (Manning, 2006), qui décrit comment créer des applications Java de niveau entreprise à l'aide des frameworks Spring et Hibernate. Il porte les titres honorifiques de Java Champion et JavaOne Rock Star.
Chris a développé la version originale de CloudFoundry.com, une première implémentation de la plate-forme Java PaaS pour Amazon EC2.
Aujourd'hui, il est considéré comme un leader idéologique reconnu dans le monde des microservices et intervient régulièrement lors de conférences internationales. Chris a créé microservices.io, qui contient des modèles de conception de microservices. Il mène également des consultations et des formations dans le monde entier pour les organisations qui passent à l'architecture de microservices. Chris travaille actuellement sur sa troisième startup, Eventuate.io. Il s'agit d'une plateforme logicielle de développement de microservices transactionnels.
»Plus d'informations sur le livre sont disponibles sur
le site Web de l'éditeur»
Contenu»
Extrait25% de réduction sur les colporteurs -
Modèles de microservicesLors du paiement de la version papier du livre, un livre électronique est envoyé par e-mail.