Utilisation des données d'un système de gestion des services informatiques (ITSM) à titre d'exemple.
Dans un article précédent sur
SAP Process Mining ou comment comprendre nos processus métier, nous avons parlé de Process Mining et de son application dans un environnement d'entreprise. Aujourd'hui, nous voulons parler davantage du modèle de données et du processus de préparation. Nous examinerons les composants, comment ils sont interconnectés, quel format de données demander aux propriétaires de données et quelle pourrait être l'approche de génération d'une table d'événements pour SAP Process Mining by Celonis.
Modèle de données dans SAP PROCESS MINING by CELONIS
La structure des données dans l'outil SAP Process Mining by Celonis est assez simple:
- "Table d'événements." Il s'agit d'une partie obligatoire du modèle de données. Une telle table ne peut être qu'une seule dans chaque modèle de données individuel. Un graphe de processus y est automatiquement généré. Voir figure 1.
- Les répertoires sont toutes les autres tables qui développent la «table des événements» avec des informations analytiques supplémentaires. Contrairement à elle, les informations de référence ne changent pas avec le temps. Plus précisément, il ne devrait pas changer dans l'intervalle de temps que nous analysons. Par exemple, il peut s'agir d'un tableau avec une description des propriétés des contrats, des articles d'approvisionnement, des demandes de quelque chose, des employés, des règlements, des entrepreneurs et d'autres objets qui sont impliqués d'une manière ou d'une autre dans le processus. Dans ce cas, la référence décrira toutes sortes de propriétés statiques de ces objets (montants, types, noms, noms, tailles, départements, adresses et autres attributs divers). Les répertoires sont facultatifs. Vous pouvez exécuter le modèle de données sans eux. Une simple analyse d'un tel processus sera moins intéressante.
 Figure 1. Modèle de données dans Proces Mining: une table d'événements et une référence aux instances de processus
Figure 1. Modèle de données dans Proces Mining: une table d'événements et une référence aux instances de processusUne table d'événements est une table standard (stockage physique, par opposition aux tables logiques) dans la plate-forme en mémoire de SAP HANA. Les répertoires peuvent être présentés sous forme de tableaux standard (stockage physique) et de tableaux de calcul (vues de calcul). À de rares exceptions près, il peut être nécessaire d'ajouter une petite référence sous forme de CSV ou XLSX au modèle de données existant. Cette fonctionnalité existe directement dans l'interface graphique.
Ci-dessous, nous examinerons de plus près chacune de ces deux composantes du modèle de données.
Une «table des événements» (ou «journal des événements») contient au moins trois colonnes obligatoires:
- Un identificateur de processus est une clé unique pour chaque instance de processus (par exemple, un numéro de référence, d'incident ou de tâche). Dans l'exemple de la figure 2, il s'agit de la colonne "CASE_ID".
- Activité. C'est le nom de l'étape du processus - une sorte d'événement qui nous intéresse. C'est à partir des activités que sera composé le graphe du processus (colonne «ÉVÉNEMENT»).
- Horodatage de l'événement (colonne "TIMESTAMP").
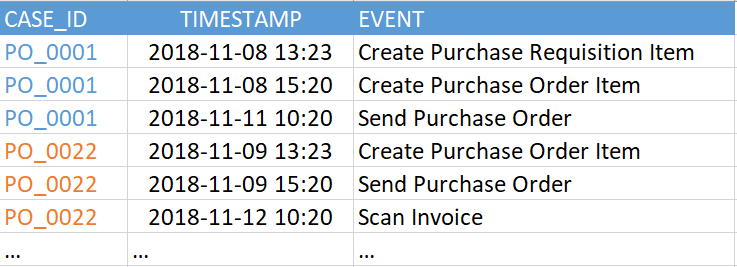 Figure 2. Exemple de table d'événements
Figure 2. Exemple de table d'événementsLa version actuelle de SAP Process Mining by Celonis prend en charge jusqu'à 1 000 événements uniques dans un modèle de données unique. C'est-à-dire que le nombre de valeurs uniques dans la colonne "ÉVÉNEMENT" dans l'exemple ci-dessus (dans votre table d'événements, il peut être appelé différemment) ne doit pas dépasser 1000. Et les événements eux-mêmes (c'est-à-dire les lignes de ce tableau) peuvent être assez nombreux. Nous avons vu des exemples de centaines de millions d'événements dans un modèle de données.
Un horodatage peut être représenté soit par une colonne, puis il vous appartient de déterminer ce qu'il signifie - le début ou la fin d'une étape, ou deux colonnes, comme dans la figure 3, lorsque le début et la fin d'une étape sont explicitement indiqués. La différence fondamentale entre la version à deux colonnes est que le système sera capable de reconnaître automatiquement les étapes exécutées en parallèle. Cela se voit lors de la comparaison des heures de début et de fin des différentes étapes.
 Figure 3. Exemple de table d'événements avec deux horodatages
Figure 3. Exemple de table d'événements avec deux horodatagesToutes les autres colonnes de ce tableau sont facultatives. Le graphique du processus peut également être restauré avec succès à l'aide des trois colonnes requises, mais il sera difficile de se débarrasser du sentiment qu'il manque quelque chose. Par conséquent, il est fortement recommandé de ne pas vous limiter à un ensemble minimal d'enceintes.
Les colonnes supplémentaires sont toutes les informations qui vous intéressent, qui changent au cours du processus ou sont associées à un événement spécifique. Par exemple, le nom de l'employé qui a fait l'événement, le groupe de travail, la priorité actuelle de l'application. L'accent mis sur la dépendance au temps n'est pas accidentel ici. Il est recommandé de ne laisser que des données mutables dans la table des événements. Toutes les autres informations statiques sont mieux placées dans des répertoires séparés. En d'autres termes, le journal des événements doit être normalisé, si possible. Cela est fait non pas tant pour réduire la quantité de données, mais pour faciliter le travail ultérieur avec les expressions PQL au stade de la création de rapports analytiques.
Que tout soit en placeQue se passe-t-il si vous ajoutez une colonne contenant des informations de référence au «tableau des événements»? En général, rien de terrible ne se produira, du moins au début. Et pour tester rapidement n'importe quelle idée, cette option est tout à fait appropriée. Il ne peut y avoir que deux conséquences négatives: reproduction inutile de copies de données et difficultés supplémentaires dans certaines formules analytiques. Ces difficultés auraient pu être évitées si toutes les données supplémentaires avaient été soumises à l'annuaire. En général, il vaut mieux le faire tout de suite.
Un peu sur les licencesLa table d'événements est associée à la licence de SAP Process Mining par Celonis. Un modèle de données = 1 licence = 1 journal des événements. Avec une certaine réserve, nous pouvons dire que 1 journal des événements = 1 processus métier. La mise en garde sera la suivante: des situations peuvent survenir lorsque plusieurs processus s'inscrivent dans un seul journal des événements, et vice versa - plusieurs journaux des événements sont intentionnellement créés pour un processus. En outre, le terme «processus métier» peut être interprété d'un point de vue de données assez largement. Par conséquent, à des fins de licence, pour le critère évident, le nombre de journaux d'événements a été sélectionné. C'est sur ce critère qu'il faut s'appuyer.
RépertoiresLes répertoires sont facultatifs, leur ajout au modèle de données est facultatif. Ils contiennent toute information supplémentaire qui peut être utile pour l'analyse du processus. Mais, contrairement au tableau des événements, les informations dans les répertoires sont statiques, elles ne dépendent pas de l'heure à laquelle l'événement s'est produit.
Un cas particulier doit être mentionné ici. En ce qui concerne les données de l'utilisateur effectuant les étapes du processus métier, la question se pose: cette information est-elle une référence? D'une part, oui - ce sont des données statiques. Il serait intéressant de ne laisser dans la table des événements qu'un certain «USER_ID», selon lequel le nom, le poste et le service de l'utilisateur, l'appartenance au groupe de travail, etc. seront associés à l'activité. Mais d'un autre côté, imaginons que nous analysons un processus métier sur une période de 2 à 3 ans. Pendant ce temps, l'utilisateur pouvait changer plusieurs postes et basculer entre les départements ou les groupes de travail. Il s'avère que ce sont des informations qui changent déjà avec le temps. Et dans ce cas, il doit être laissé dans la table des événements, ce qui entraînera à son tour qu'en plus de "USER_ID" dans le journal des événements, des colonnes telles que "groupe de travail", "position", "département" et même "nom complet" (nom de famille) apparaîtront il pourrait également changer pendant cette période). En général, la question de normaliser ou non les informations utilisateur reste à la discrétion du client.
Les répertoires peuvent être ajoutés à un modèle de données existant à tout moment.
Pour ce faire, c'est assez simple:
- Une table est créée dans SAP HANA.
- Le tableau est ajouté au modèle de données général à l'aide du bouton "Importer les données".
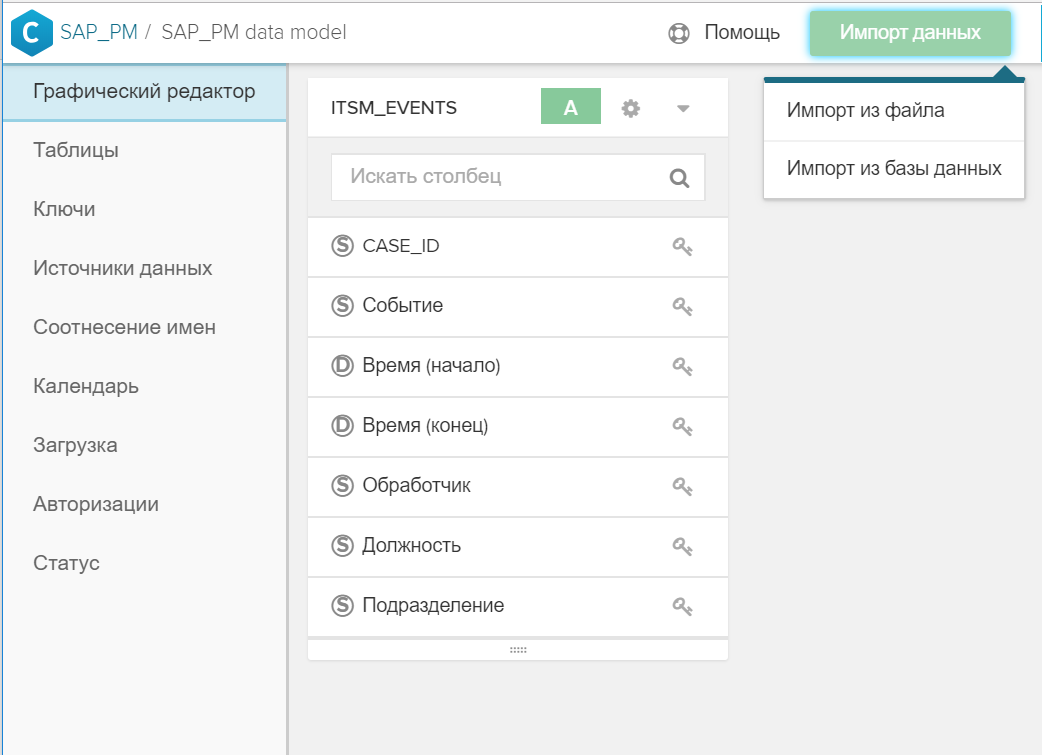
Figure 4. Importez une table ou un fichier dans un modèle de données existant - La clé (ou les clés) est indiquée dans l'interface graphique, par laquelle le nouveau répertoire est associé à la table des événements et / ou à d'autres répertoires. Pour ce faire, cliquez simplement sur l'icône
 dans un tableau, puis sur le correspondant dans une autre table.
dans un tableau, puis sur le correspondant dans une autre table.
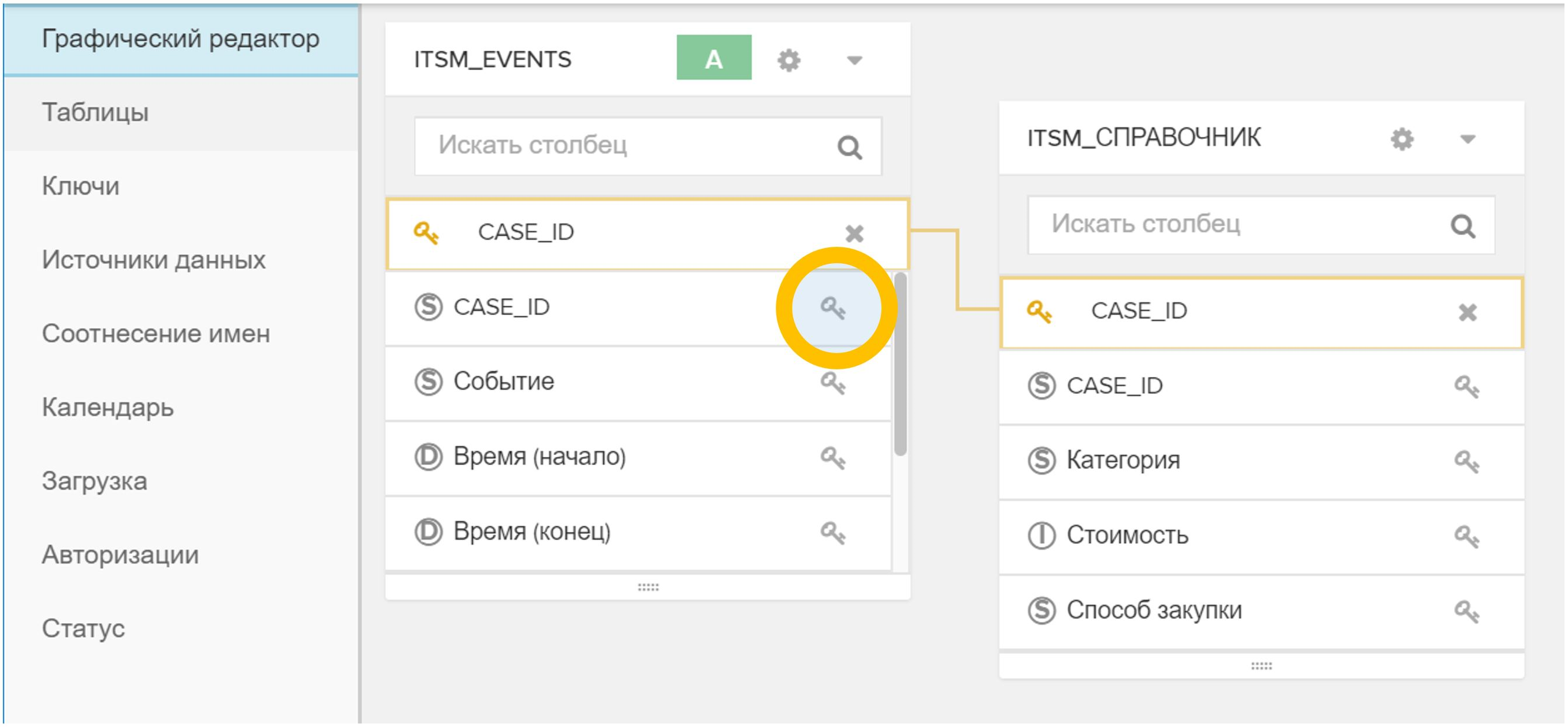
Figure 5. Liaison de tables dans un modèle de données par un champ arbitraire (dans ce cas, CASE_ID) - Dans le menu "Statut", cliquez sur le bouton "Recharger depuis la source". Ce processus prend généralement quelques secondes.
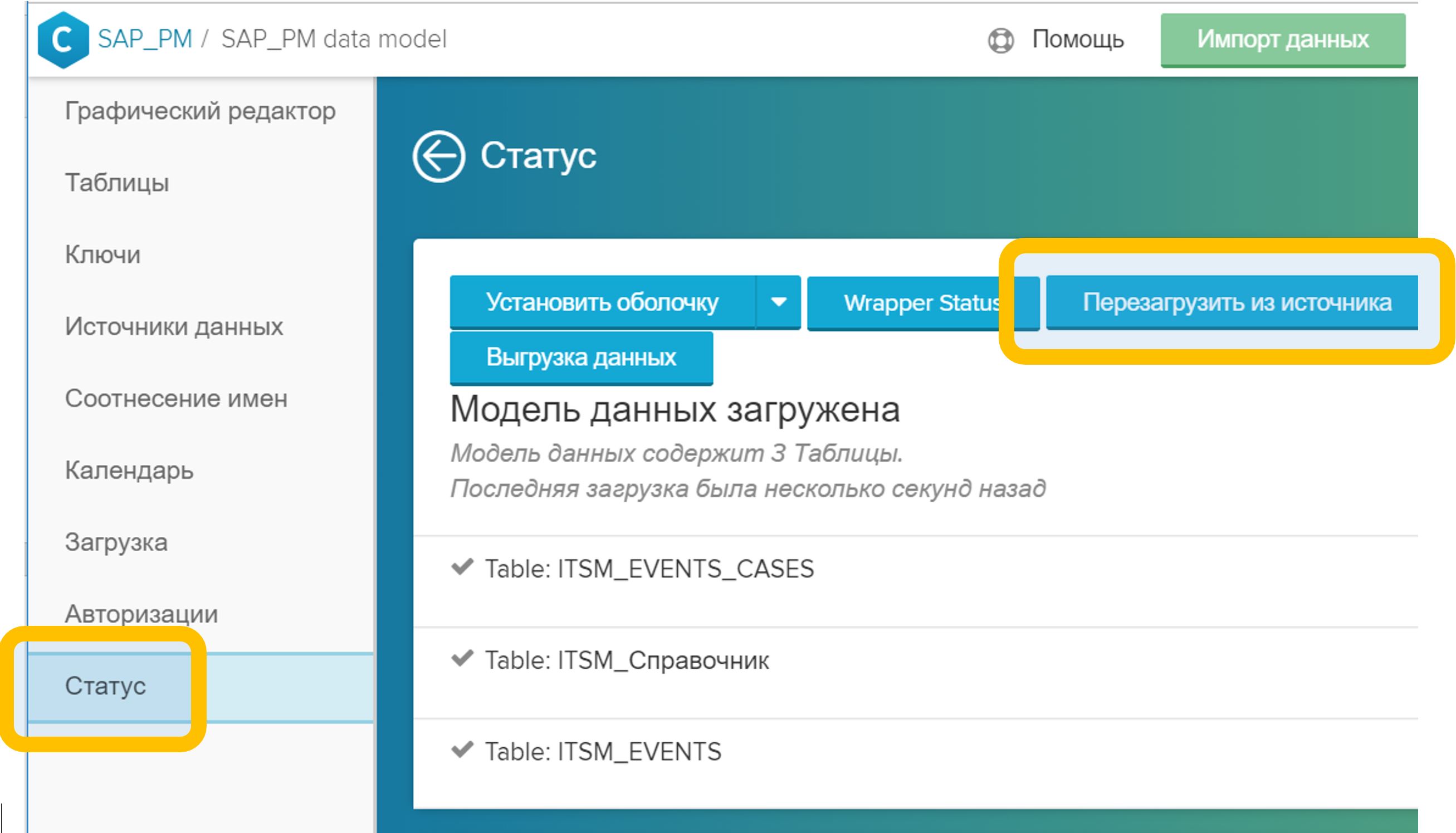 Figure 6. Rechargement du modèle de données à partir de la source
Figure 6. Rechargement du modèle de données à partir de la source
Une fois ces étapes terminées, vous pouvez immédiatement utiliser de nouvelles analyses, à la fois dans les nouveaux rapports et dans les rapports existants. L'enrichissement du modèle de données ne nuit en rien au travail actuel des analystes: tous les rapports créés continuent de fonctionner, vous n'avez pas besoin de les refaire ou de les modifier d'une manière ou d'une autre.
Pour les répertoires relativement petits, il existe une autre possibilité: pas une version complètement industrielle, bien sûr, mais elle peut aussi être utile. Il s'agit de charger des fichiers CSV, XLSX, DBF via une interface graphique directement dans le modèle de données. La procédure reste exactement la même que celle décrite ci-dessus, mais au lieu des tables de base de données, un fichier préparé à l'avance est utilisé, qui est chargé avec le bouton Importer les données.
Table CA: Référence d'instance de processusLa conversation précédente sur les ouvrages de référence a commencé par le fait qu'ils sont facultatifs. Ils peuvent être complètement omis du modèle de données et limités à une table d'événements. C'est presque vrai.
Une référence obligatoire existe. Il doit s'agir d'un tableau marqué avec le statut «CA Table». Les AC sont des chaînes d'événements. Et, vous l'avez deviné, la clé dans ce répertoire sera "CASE_ID" - l'identifiant unique de l'instance de processus. Une telle référence décrit les propriétés statiques des instances de processus individuelles. Un exemple de l'ITSM: l'auteur de l'appel, un service aux entreprises, la date de clôture, ou l'employé qui a réussi à résoudre l'incident, un signe de caractère de masse, etc.
 Figure 7. Exemple de tableau CA
Figure 7. Exemple de tableau CAEt pourtant je ne vous ai pas beaucoup trompé. Si, pour une raison quelconque, vous décidez de ne pas ajouter le répertoire requis au modèle de données, le système le générera lui-même. Le résultat de son travail peut être vu dans l'onglet Statut: si votre table d'événements est appelée, disons "ITSM_EVENTS", alors la table "ITSM_EVENTS_CASES" sera générée conjointement avec elle, comme dans la figure 8.
Figure 8. Table de chaîne d'événements (CA) générée automatiquementUne table CA générée automatiquement sera une description très simple des instances de processus: clé, nombre d'événements, durée du processus (comme si vous groupiez une table d'événements par un identificateur de processus, calculiez le nombre de lignes et la différence entre l'heure de la première et de la dernière étape). Par conséquent, il est logique de créer votre propre version plus intéressante de la table CA. Il peut être ajouté au modèle de données à tout moment. Dans le même temps, dès que vous ajoutez votre table CA au modèle, le répertoire généré par le système (dans notre cas, c'est «ITSM_EVENTS_CASES») sera automatiquement supprimé du modèle de données.
Pourquoi la «table CA» est-elle intéressante? C'est elle qui s'affiche dans l'interface graphique en tant que détail du processus. Si l'analyste, tout en travaillant avec le modèle de données, a trouvé quelque chose d'intéressant dans le processus et a voulu passer à des exemples spécifiques individuels, alors il utilisera le rapport «View CA», c'est-à-dire détaillant. Après avoir ouvert un tel rapport, vous y trouverez un répertoire du processus (combiné avec une table d'événements, bien sûr). Par conséquent, ajoutez à la «table CA» tout ce que l'analyste peut utiliser pour comprendre les propriétés du processus et les conditions de son déroulement.
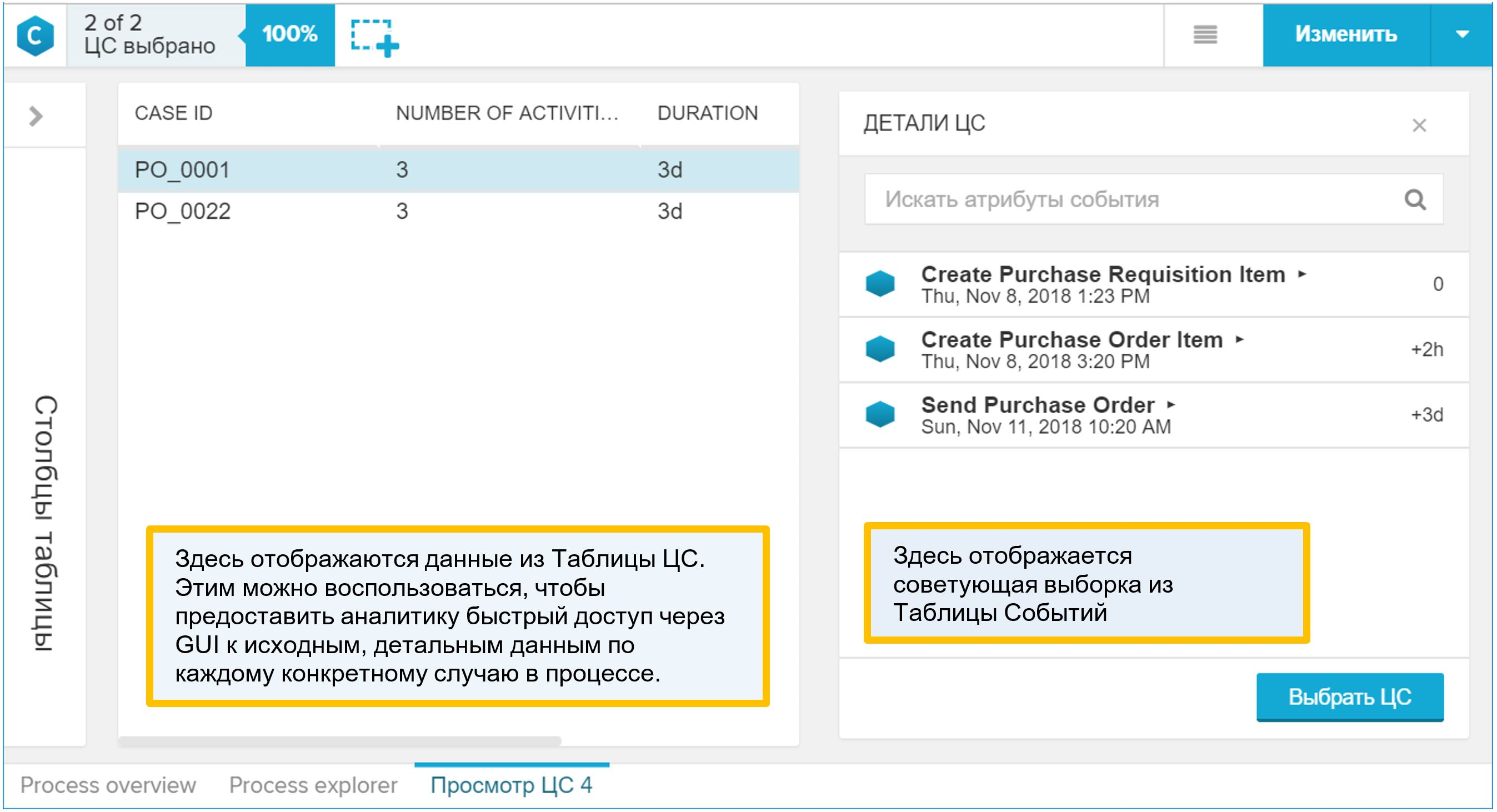 Figure 9. Exemple de rapport synthétique «View CA»
Figure 9. Exemple de rapport synthétique «View CA»Comment ajouter votre référence de processus au modèle de données:
- Une table est créée dans SAP HANA.
- Le tableau est ajouté au modèle de données général à l'aide du bouton "Importer les données".
- Dans l'interface graphique, dans les propriétés de la table, vous devez lui attribuer le rôle "Table avec CA".
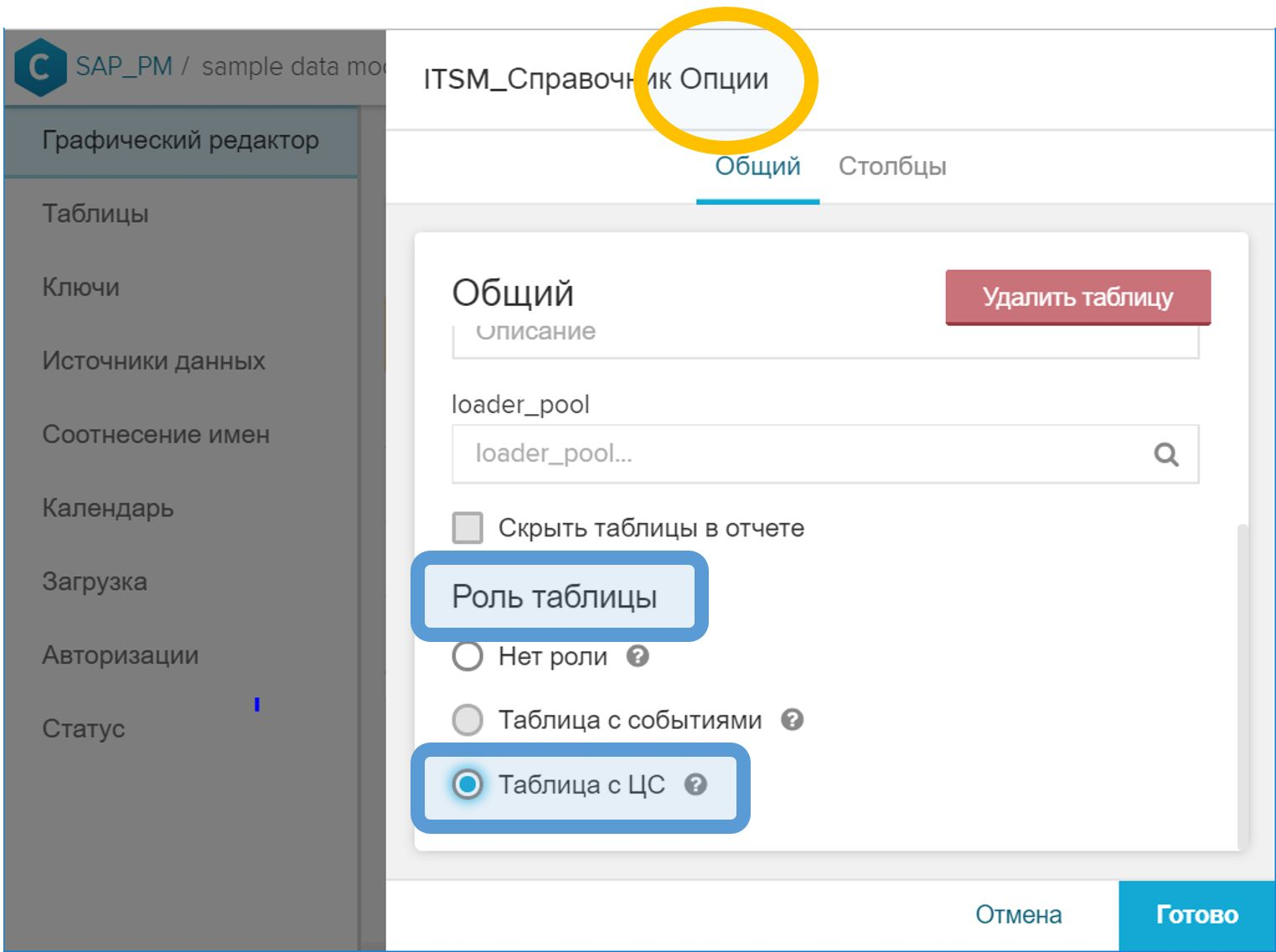
Figure 10. Rôle de "Table with CA" pour indiquer le répertoire des instances de processus - Dans l'interface graphique, associez la table CA à la table d'événements par ID de processus. Cette étape est effectuée de la même manière que dans le cas d'un répertoire normal - avec le symbole clé clé ( ) en face du champ correspondant.
- Dans le menu "Statut", cliquez sur le bouton "Recharger depuis la source".
Remarque importante: la colonne "CASE_ID" (dans chaque cas, elle peut être appelée autrement) dans la table CA, qui contient l'identificateur de processus et est utilisée pour s'associer à la table d'événements, ne doit contenir que des valeurs uniques. C'est tout à fait logique. Et si pour une raison quelconque, ce n'est pas le cas, lors du chargement du modèle de données à l'étape (5), l'erreur correspondante sera générée (sur l'impossibilité d'effectuer l'opération "JOIN" sur la table d'événements et la table CA).
Création d'un modèle de données à partir de l'historique des modifications
En pratique, nous rencontrons des sources de données très différentes pour Process Mining. Leur composition est déterminée par le processus commercial sélectionné et les normes adoptées par le client.
L'un des cas les plus courants est celui des données du système de gestion des services informatiques (ITSM, IT Service Management), nous avons donc décidé d'analyser cet exemple en premier. En fait, il n'y a pas de liaison stricte spécifique à l'ITSM dans cette approche. Il peut être appliqué dans d'autres processus métier, où la source de données est un historique des modifications ou un journal d'audit.
Que demander au service informatique?Si vous n'êtes pas un employé des TI ou le spécialiste qui dessert la base ITSM, préparez-vous au fait qu'il vous sera demandé de formuler une réponse exacte à la question «que déchargez-vous?» ou "que voulez-vous de nous?"
Et cela n'est pas toujours connu - ce qui est exactement nécessaire. L'analyse du processus opérationnel est une étude, une recherche de modèles et la recherche de «connaissances». Si nous savions à l'avance quel type de «vision» nous recherchons, alors ce ne serait plus de la «vision». En fait, je voudrais obtenir "tout": attributs, relations, changements. Mais, comme le montre la pratique, il n'a jamais été possible d'obtenir une bonne réponse précise à une question trop générale.
Il y a deux réponses possibles à la question «que déchargez-vous».
L'option est fausse: demandez à la base de décharger toutes les modifications des statuts de l'application plus un ensemble d'attributs évidents (par exemple, priorité, artiste, groupe de travail, etc.). Tout d'abord, vous disposez d'un ensemble limité d'analystes: vous savez déjà ce que vous mesurerez dans le processus (c'est de là que vient l'ensemble des attributs), donc Process Mining deviendra un outil pour calculer le KPI du processus (très pratique, je dois dire, un outil; mais je veux quand même plus).
Deuxièmement, chaque service informatique individuel interprète différemment la demande pour ajouter des attributs de demande supplémentaires au téléchargement. Par exemple, soyez prioritaire: il peut changer en travaillant sur un appel. L'appel est enregistré avec une priorité, puis le spécialiste du groupe de travail le modifie, et il se termine avec un statut différent. Et maintenant la question est: dans le déchargement demandé par vous, quel moment correspond à la priorité? Dans un premier temps, il semble que la valeur de priorité devrait correspondre à la colonne «Date et heure de l'événement». Mais en réalité, il s'avère souvent que seul l'état de l'application lui-même correspond à la date et à l'heure spécifiées, et toutes les autres colonnes sont les valeurs au moment du déchargement ou au moment de la fermeture de l'application. Et vous ne le saurez pas tout de suite.
Il me semble qu'il y a une meilleure option. Vous pouvez demander des données sous la forme du tableau suivant:
- Le numéro de l'appel, de l'incident, de la tâche (SD *, IM *, RT *, ...) est l'identifiant de l'objet dans le système ITSM (NVARCHAR)
- Horodatage (TIMESTAMP)
- Nom d'attribut (NVARCHAR)
- Ancienne valeur (NVARCHAR)
- Nouvelle valeur (NVARCHAR)
- Qui a changé (NVARCHAR)
En fait, ce n'est rien de plus qu'une histoire de changements dans les attributs. Dans les interfaces des systèmes ITSM, vous pouvez voir un tel tableau sur les onglets avec le nom "Historique" ou "Journal".
Les avantages de cette approche sont évidents:
- Format de téléchargement simple et clair. Il connaît les professionnels de l'informatique dans l'interface graphique du système lui-même. Ne devrait pas poser de questions sur la base.
- Nous obtenons une liste de tous les attributs possibles avec toutes les valeurs possibles. Oui, il y en aura beaucoup, probablement plusieurs centaines. Mais trier les éléments inutiles et inintéressants est très simple, mais à chaque fois, demander des déchargements supplémentaires n'est pas toujours simple et toujours long (surtout lorsque vous ne savez pas du tout quels attributs sont présents dans le système).
- Il s'agit d'un modèle de données fiable. Il est difficile de le gâcher, à moins que vous ne fassiez intentionnellement de fausses informations.
- Nous savons exactement ce que chaque attribut avait à chaque instant. Ceci est important car nous nous testons et nous assurons que le modèle est correct. Et pendant l'analyse, nous pouvons ajouter des étapes intermédiaires au modèle («zoom avant») et déterminer les valeurs d'attribut correctes à tous les points supplémentaires dans le temps.
Les inconvénients de la deuxième option sont également évidents. Et ils, il me semble, peuvent être résolus (par opposition au problème des données incomplètes):
- Le script SQL pour la préparation des données devient un peu plus compliqué - par rapport à l'option lorsque l'équipe informatique fait la préparation partielle des données pour vous (voir la première version de la requête ci-dessus), sans le soupçonner. Oui, il (le script) est plus compliqué, mais il est seul. Je pense que ce serait une mauvaise idée de partager la préparation des données entre l'équipe ITSM et l'équipe Process Mining. Idéalement, toute la transformation devrait être transférée à l'équipe Process Mining afin qu'elle comprenne exactement ce qui se passe avec les données et minimise les interférences avec les données côté source. Un format d'échange de données simple permet d'atteindre cet objectif.
- Le volume de déchargement est important. La commande peut être la suivante: 10-30 Go / an pour une grande entreprise. Mais charger un tel volume dans HANA n'est pas du tout un problème et n'est même pas considéré comme une tâche. De plus, nous ne parlons de «téléchargement» que pendant le projet pilote, tandis que l'intégration ETL / ELT entre la source de données et HANA (par exemple, HANA Smart Data Integration) sera utilisée dans les opérations industrielles, et cet élément cessera d'avoir de l'importance.
Je ne voudrais pas dire que c'est la seule façon correcte d'obtenir des données du système ITSM pour les tâches de Process Mining. Mais à l'heure actuelle, je suis porté à croire que c'est le format le plus pratique pour cette tâche. Il y a probablement beaucoup plus d'approches intéressantes, et je serai très heureux de discuter d'idées alternatives si vous les partagez avec moi.
Génération de table d'événements
Ainsi, à la sortie, nous avons un historique des changements dans les attributs des demandes, des incidents, des appels, des tâches et d'autres objets ITSM. À partir d'une telle table, il est possible de générer les deux composants clés du modèle de données Process Mining: une table d'événements et une table CA.
Pour générer des événements en fonction de l'historique des modifications, procédez comme suit:
- Dans l'historique des modifications, collectez toutes les valeurs uniques de la colonne (conditionnellement) «nom d'attribut».
- Déterminez le changement dans lequel les attributs que vous souhaitez voir sur le graphique du processus. Qu'est-ce qu'un «événement» pour nous?
- Créez une vue de calcul appropriée ou écrivez un script SQL qui filtre les lignes sélectionnées à partir de l'historique des modifications et génère une table d'événements.
Supposons que la table de modification soit la suivante:
CREATE COLUMN TABLE "SAP_PM"."ITSM_HISTORY" ( "CASE_ID" NVARCHAR(256), "ATTRIBUTE" NVARCHAR(256), "VALUE_OLD" NVARCHAR(1024), "VALUE_NEW" NVARCHAR(1024), "TS" TIMESTAMP, "USER" NVARCHAR(256) );
Tout d'abord, regardez la liste de tous les attributs présents. Cela peut être fait dans le menu "Open Data Preview" ou avec une simple requête SQL comme celle-ci:
SELECT DISTINCT "ATTRIBUTE" FROM "SAP_PM"."ITSM_HISTORY";
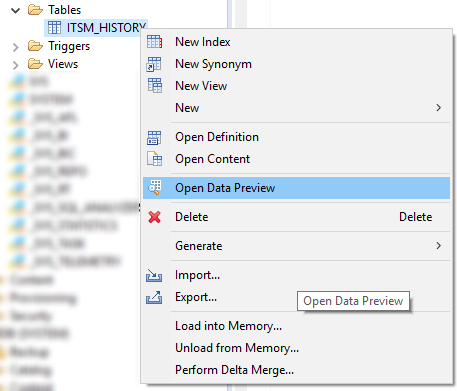 Figure 11. Menu contextuel avec la commande Open Data Preview dans SAP HANA Studio
Figure 11. Menu contextuel avec la commande Open Data Preview dans SAP HANA StudioEnsuite, nous déterminons la composition des attributs, dont le changement est pour nous un événement dans le processus. Voici une liste de candidats évidents pour une telle liste:
- Statut
- A été amené au travail
- La catégorie a été modifiée
- Délai dépassé
- Le temps de réaction est violé
- La demande a été renvoyée pour révision.
- Erreur de 1ère ligne
- Groupe de travail
- Priorité
Les principaux événements ici, bien sûr, sont les transitions entre les statuts de la tâche appel / incident \ application \. La valeur de l'attribut "Statut" (VALUE_NEW) lui-même sera le nom de l'étape de processus pour nous. Par conséquent, la création d'une table d'événements en première approximation pourrait ressembler à ceci:
CREATE COLUMN TABLE "SAP_PM"."ITSM_EVENTS" ( "CASE_ID" NVARCHAR(256) ,"EVENT" NVARCHAR(1024) ,"TS" TIMESTAMP ,"USER" NVARCHAR(256) ,"VALUE_OLD" NVARCHAR(1024) ,"VALUE_NEW" NVARCHAR(1024) ); INSERT INTO "SAP_PM"."ITSM_EVENTS" SELECT "CASE_ID" ,"VALUE_NEW" AS "EVENT" ,"TS" ,"USER" ,"VALUE_OLD" ,"VALUE_NEW" FROM "SAP_PM"."ITSM_HISTORY" WHERE "ATTRIBUTE" = '' ;
La modification du reste des attributs constitue nos étapes supplémentaires qui rendent la recherche du processus encore plus intéressante. Leur composition est déterminée par la demande d'un analyste commercial et peut évoluer au fur et à mesure de l'évolution de la pratique du Process Mining dans l'entreprise.
INSERT INTO "SAP_PM"."ITSM_EVENTS" SELECT "CASE_ID" ,"ATTRIBUTE" AS "EVENT" ,"TS" ,"USER" ,"VALUE_OLD" ,"VALUE_NEW" FROM "SAP_PM"."ITSM_HISTORY" WHERE "VALUE_OLD" IS NOT NULL AND "ATTRIBUTE" IN ( ' ' ,' ' ,' ' ,' ' ,' ' ,' 1- ' ,' ' ,'') );
En étendant la liste des attributs dans le filtre OERE "ATTRIBUER" DANS (.....), vous augmentez la variété des étapes affichées sur le graphique du processus. Il convient de noter qu'une grande variété d'étapes n'est pas toujours une bénédiction. Parfois, des détails trop détaillés rendent difficile la compréhension du processus. Je pense qu'après la première itération, vous déterminerez quelles étapes sont nécessaires et lesquelles devraient être exclues du modèle de données (et la liberté de prendre de telles décisions et de s'y adapter rapidement est un autre argument en faveur du transfert du travail de transformation des données du côté de l'équipe Process Mining) .
Le filtre "VALUE_OLD" N'EST PAS NUL, vous le remplacerez probablement par quelque chose de plus adapté à vos conditions et aux attributs sélectionnés. Je vais essayer d'expliquer la signification de ce filtre. Dans certaines implémentations populaires de systèmes ITSM, au moment de l'enregistrement (ouverture) d'un appel, des informations sur l'initialisation de tous les attributs de l'objet sont entrées dans le journal. Autrement dit, tous les champs sont marqués avec des valeurs par défaut. À ce moment, VALUE_NEW contiendra la même valeur d'initialisation et VALUE_OLD ne contiendra rien - après tout, il n'y avait pas d'historique jusqu'à ce moment. Nous n'avons absolument pas besoin de ces enregistrements dans le processus. Ils doivent être retirés avec un filtre adapté à vos conditions spécifiques. Un tel filtre peut être:
- "VALUE_OLD" N'EST PAS NUL
- "VALUE_NEW" = 'oui'
- Vous pouvez vous concentrer sur l'horodatage (prendre uniquement les événements qui se sont produits après l'enregistrement de l'objet).
- Vous pouvez vous concentrer sur le champ "UTILISATEUR" si le compte système est en cours d'initialisation.
- Toute autre condition que vous avez trouvée.
Génération de table CA
Le même historique des modifications qui nous a servi de source d'événements sera également utile pour créer un répertoire d'instances de processus (tables CA). Algorithme similaire:
1. Définissez une liste d'attributs qui:
a. Ne changez pas pendant le travail sur la demande, par exemple, l'auteur de l'appel et son département, l'évaluation de l'utilisateur des résultats du travail, le drapeau de violation du délai.
b. Ils peuvent changer, mais nous ne nous intéressons qu'aux valeurs à certains moments: au moment de l'inscription, de la fermeture, lors de l'embauche, du transfert de la 2ème ligne à la 1ère, etc.
c. Ils peuvent changer, mais nous ne nous intéressons qu'aux valeurs agrégées (maximum, minimum, quantité, etc.)
2. Créez un tableau diagonal avec l'ensemble de colonnes souhaité. Chaque attribut qui nous intéresse générera son propre ensemble de lignes (en fonction du nombre d'instances de processus), dans lequel une seule colonne aura une valeur et tout le reste sera vide (NULL).
3. Nous réduisons la table diagonale dans le répertoire final en utilisant le regroupement par identifiant de processus.
Exemples d'attributs qu'il est judicieux de mettre dans la table CA (en pratique, cette liste peut être beaucoup plus longue):
- Le service
- Système informatique
- L'auteur
- Organisation auteur
- Note des utilisateurs sur la qualité de la solution
- Nombre de retours au travail
- Quand a été emmené au travail
- Créé par
- Qui a fermé
- Résolu par la ligne 1
- Classification / routage non valide
- Date limite
- Violation des délais
Un même attribut peut être soit une source d'un événement dans un processus, soit une propriété d'une instance de processus. Par exemple, l'attribut "Priority". D'une part, nous nous intéressons à sa signification au moment de l'enregistrement de l'appel, et d'autre part, tous les faits de modification de cet attribut peuvent être soumis au graphique de processus en tant qu'étapes indépendantes.
Un autre exemple est Deadline. Il s'agit d'une propriété de référence évidente du processus, mais vous pouvez en faire une étape virtuelle dans le graphique du processus: une opération telle que la «date limite» n'existe pas dans le processus, mais si nous ajoutons l'entrée correspondante à la table des événements, nous la créerons artificiellement et nous pourrons visualiser l'emplacement par rapport à temps d'exécution des autres étapes directement sur le graphique du processus. C'est pratique pour une analyse rapide.
En général, lorsque nous créons des propriétés de processus basées sur l'historique des changements d'attributs, la source d'informations utiles pour nous peut être:
- Valeur d'attribut elle-même (exemple: "Note des utilisateurs")
- Utilisateur qui l'a changé
- Changer le temps
- Le moment où l'attribut a pris une certaine valeur (exemple: l'attribut «Date limite violée» ne s'intéresse pas à la valeur d'attribut elle-même, mais au moment où il passe à l'équivalent du drapeau levé - par exemple, «oui» ou 1)
- Le fait que l'attribut soit présent dans l'histoire (exemple: «Incident de masse» avec la valeur «oui»)
Cette liste, bien sûr, peut être complétée par d'autres idées d'utilisation des attributs et tout ce qui y est lié.
Maintenant que nous avons déjà décidé de la liste des propriétés d'intérêt, examinons l'un des scénarios possibles pour générer la table CA. Tout d'abord, créez le tableau lui-même avec l'ensemble de colonnes que nous avons défini ci-dessus pour nous-mêmes:
CREATE COLUMN TABLE "SAP_PM"."ITSM_CASES" ( "CASE_ID" NVARCHAR(256) NOT NULL ,"CATEGORY" NVARCHAR(256) DEFAULT NULL ,"AUTHOR" NVARCHAR(256) DEFAULT NULL ,"RESOLVER" NVARCHAR(256) DEFAULT NULL ,"RAITING" INTEGER DEFAULT NULL ,"OPEN_TIME" TIMESTAMP DEFAULT NULL ,"START_TIME" TIMESTAMP DEFAULT NULL ,"DEADLINE" TIMESTAMP DEFAULT NULL );
Nous aurons également besoin d'une table temporaire "ITSM_CASES_STAGING", qui nous permettra de trier une liste plate d'attributs pour les colonnes de propriétés requises dans le répertoire des instances de processus:
CREATE COLUMN TABLE "SAP_PM"."ITSM_CASES_STAGING" LIKE "SAP_PM"."ITSM_CASES" WITH NO DATA;
Ce sera un tableau diagonal - dans chaque ligne, seuls deux champs ont une valeur: "CASE_ID", c'est-à-dire identificateur de processus et un seul champ avec une propriété de processus. Les champs restants de la ligne seront vides (NULL). Au stade final, nous réduisons facilement les diagonales en lignes par simple agrégation et obtenons ainsi le tableau des CA dont nous avons besoin.
Un exemple pour une catégorie de traitement:
INSERT INTO "SAP_PM"."ITSM_CASES_STAGING" ("CASE_ID", "CATEGORY") SELECT "CASE_ID", LAST_VALUE("VALUE_NEW" ORDER BY "TS") FROM "SAP_PM"."ITSM_HISTORY" WHERE "ATTRIBUTE" = '' GROUP BY "CASE_ID" ;
Supposons que l'auteur soit le premier utilisateur non système de l'histoire de l'appel qui enregistre les appels (dans votre cas particulier, le critère peut être plus précis):
INSERT INTO "SAP_PM"."ITSM_CASES_STAGING" ("CASE_ID", "AUTHOR") SELECT "CASE_ID", FIRST_VALUE("USER" ORDER BY "TS") FROM "SAP_PM"."ITSM_HISTORY" WHERE "USER" != 'SYSTEM' GROUP BY "CASE_ID" ;
Si nous pensons que le gestionnaire qui a mis le dernier statut «Solution proposée» (et la solution pourrait être proposée à plusieurs reprises, mais que le dernier est résolu), a réussi à résoudre le problème, alors cette propriété de l'instance de processus peut être formulée comme suit:
INSERT INTO "SAP_PM"."ITSM_CASES_STAGING" ("CASE_ID", "RESOLVER") SELECT "CASE_ID", LAST_VALUE("USER" ORDER BY "TS") FROM "SAP_PM"."ITSM_HISTORY" WHERE "ATTRIBUTE" = '' AND "VALUE_NEW" = ' ' GROUP BY "CASE_ID" ;
Note des utilisateurs (sa satisfaction de la décision):
INSERT INTO "SAP_PM"."ITSM_CASES_STAGING" ("CASE_ID", "RAITING") SELECT "CASE_ID", TO_INTEGER(LAST_VALUE("VALUE_NEW" ORDER BY "TS")) FROM "SAP_PM"."ITSM_HISTORY" WHERE "ATTRIBUTE" = ' ' AND "VALUE_NEW" IS NOT NULL GROUP BY "CASE_ID" ;
Le moment de l'enregistrement (création) est tout simplement le premier record de l'histoire de la circulation:
INSERT INTO "SAP_PM"."ITSM_CASES_STAGING" ("CASE_ID", "OPEN_TIME") SELECT "CASE_ID", MIN("TS") FROM "SAP_PM"."ITSM_HISTORY" GROUP BY "CASE_ID" ;
Le temps de réaction est une caractéristique importante de la qualité des services. Pour le calculer, vous devez savoir quand le drapeau «A été mis au travail» a été levé pour la première fois:
INSERT INTO "SAP_PM"."ITSM_CASES_STAGING" ("CASE_ID", "START_TIME") SELECT "CASE_ID", MIN("TS") FROM "SAP_PM"."ITSM_HISTORY" WHERE "ATTRIBUTE" = ' ' AND 'VALUE_NEW' = '' GROUP BY "CASE_ID" ;
Le délai est utilisé pour calculer les KPI pour des réponses rapides aux appels ou pour résoudre les incidents. Dans le processus, le délai peut changer à plusieurs reprises. Pour calculer les KPI, nous devons connaître la dernière version de cet attribut. Si nous voulons suivre explicitement comment la date limite a changé, c'est-à-dire pour afficher de tels cas sur le graphique du processus, nous devons également utiliser cet attribut pour générer une entrée dans la table des événements. Il s'agit d'un exemple d'attribut qui sert à la fois de propriété du processus et de source de l'événement.
INSERT INTO "SAP_PM"."ITSM_CASES_STAGING" ("CASE_ID", "DEADLINE") SELECT "CASE_ID", MAX(TO_DATE("VALUE_NEW")) FROM "SAP_PM"."ITSM_HISTORY" WHERE "ATTRIBUTE" = ' ' AND 'VALUE_NEW' IS NOT NULL GROUP BY "CASE_ID" ;
Tous les exemples ci-dessus sont du même type. Par analogie avec eux, la table CA peut être développée avec tous les attributs qui vous intéressent. De plus, cela peut être fait déjà après le début du projet, le système vous permet d'étendre le modèle de données pendant son fonctionnement.
Lorsque notre table diagonale temporaire est remplie avec les propriétés des instances de processus, il ne reste plus qu'à faire l'agrégation et à obtenir la table CA finale:
INSERT INTO "SAP_PM"."ITSM_CASES" SELECT "CASE_ID" ,MAX("CATEGORY") ,MAX("AUTHOR") ,MAX("RESOLVER") ,MAX("RAITING") ,MAX("OPEN_TIME") ,MAX("START_TIME") ,MAX("DEADLINE") FROM "SAP_PM"."ITSM_CASES_STAGING" GROUP BY "CASE_ID" ;
Après cela, nous n'avons plus besoin des données de la table temporaire. Le tableau lui-même peut être laissé pour continuer à répéter le processus ci-dessus régulièrement pour mettre à jour le modèle de données dans Process Mining:
DELETE FROM "SAP_PM"."ITSM_CASES_STAGING";
Conseils pour préparer et nettoyer les fichiers CSV pour un projet pilote
Vous commencerez probablement votre connaissance de la discipline Process Mining avec un projet pilote. Dans ce cas, l'accès direct à la source de données ne peut pas être obtenu; les employés des TI et les responsables de la sécurité de l'information y résisteront. Cela signifie que dans le cadre du projet pilote, nous devrons travailler avec l'exportation de données des systèmes d'entreprise vers des fichiers CSV, puis les importer dans SAP HANA pour créer un modèle de données.
Dans une installation industrielle, il n'y aura pas d'export vers CSV. À la place, des outils d'intégration SAP HANA seront utilisés, en particulier: Smart Data Integration (SDI), Smart Data Access (SDA) ou SAP Landscape Transformation Replication Server (SLT). Mais pour tester et se familiariser avec la technologie, l'exportation vers des fichiers texte CSV est une méthode plus simple sur le plan organisationnel. Par conséquent, il sera utile de partager avec vous quelques conseils pour préparer des données dans CSV pour une importation rapide et réussie dans la base de données.
Exigences de format recommandées pour le fichier lui-même lors de l'exportation:
- Format de fichier: CSV
- Encodage: UTF8
- Séparateur de champs: n'importe quel caractère qui vous convient. Par exemple, "|" ou "^" ou "~". La logique du choix est simple - nous devons essayer d'éviter la situation où la «division» est contenue dans les données elles-mêmes.
- Il est nécessaire de supprimer le séparateur de la valeur des champs. Oui, vous pourriez dire que pour cela, en fait, il y a des guillemets. Mais, comme le montre l'expérience, avec les guillemets également, de nombreux problèmes se posent. En général, supprimons (ou remplaçons) le caractère séparateur des valeurs de champ. Votre projet pilote ne souffrira pas beaucoup de cette imprécision, mais le temps de préparation des données est sensiblement économisé.
- Guillemets: supprimez tous les guillemets de la valeur du champ. Les guillemets se trouvent souvent dans les noms de sociétés - par exemple, Kalinka LLC. Mais il existe de telles options: MPZ Kalinka LLC. Et maintenant, c'est une grande difficulté. Les guillemets dans les valeurs de champ doivent être accompagnés du symbole «\», ou supprimés, remplacés par autre chose. Il est plus fiable de le supprimer simplement. La valeur du champ n'en souffrira pas beaucoup.
- Transferts de transport: supprimez tous les caractères CHAR (10) et CHAR (13) des valeurs de champ. Sinon, l'importation à partir de CSV sera impossible.
Si nous prenons en compte les points (4) + (5) + (6), alors il est logique d'utiliser la construction suivante dans la sélection:
REPLACE(REPLACE(REPLACE(REPLACE("COLUMN", '|', ';'), '"', ''), CHAR(13), ' '), CHAR(10), ' ') as "COLUMN"
De plus, lorsque les fichiers CSV seront prêts, ils devront être copiés sur le serveur HANA dans un dossier déclaré sûr pour l'importation de fichiers (par exemple, / usr / sap / HDB / import). L'importation de données dans HANA à partir d'un fichier CSV local est une procédure assez rapide, à condition que le fichier soit «propre»:
- chaque ligne de la future table est sur une et une seule ligne du fichier;
- le nombre de colonnes dans toutes les lignes est le même;
- les guillemets sont associés ou manquants;
- les guillemets dans les valeurs de champ accompagnent le symbole "escape" "\", ou sont complètement absents;
- Encodage UTF-8 (et non UTF8-BOM, comme cela se produit lors de l'exportation vers des systèmes Windows).
Pour vérifier les fichiers CSV avant de les importer et trouver les zones problématiques si elles existent (et avec une probabilité de 99% elles le seront), vous pouvez utiliser les commandes suivantes:
1. Vérifiez le caractère de nomenclature au début du fichier:
fichier data.csv
Si le résultat de la commande est comme ceci: «Texte UTF-8 Unicode (avec BOM)», cela signifie que l'encodage est UTF8-BOM et vous devez supprimer le caractère BOM du fichier. Vous pouvez le supprimer comme suit:
sed -i '1s / ^ \ xEF \ xBB \ xBF //' data.csv
2. Le nombre de colonnes doit être le même pour chaque ligne du fichier:
cat data.csv
| awk -F »;" '{print NF}' | sort | uniqou comme ça:
pour i en $ (ls * .csv); faire écho $ i; chat $ i | awk -F ';' '{print NF}' | trier | uniq -c; écho; fait;Changer ';' dans le paramètre F à quel est le séparateur de champ dans votre cas.
Grâce à ces commandes, vous obtenez la distribution des lignes par le nombre de colonnes de chaque ligne. Idéalement, vous devriez obtenir quelque chose comme ceci:
EKKO.csv
79536 200
Ici, le fichier contient 79536 lignes et toutes contiennent 200 colonnes. Il n'y a pas de lignes avec un nombre différent de colonnes. Il devrait en être ainsi.
Et voici un exemple de résultat incorrect:
LFA1.csv
73636 180
7 181
Ici, nous voyons que la plupart des lignes contiennent 180 colonnes (et, probablement, c'est le nombre de colonnes qui est correct), mais il y a des lignes avec la 181e colonne. Autrement dit, l'un des champs contient un signe séparateur dans sa valeur. Nous avons eu de la chance et il n'y a que 7 morceaux de ces lignes - ils peuvent facilement être consultés manuellement et corrigés d'une manière ou d'une autre. Vous pouvez voir les lignes dans lesquelles le nombre de colonnes n'est pas égal à 180, comme ceci:
cat data.csv
| awk -F ";" '{if (NF! = 180) {print $ 0}}'Une note sur l'utilisation des commandes ci-dessus. Ces commandes ne prêteront pas attention aux guillemets. Si le signe séparateur est contenu dans le champ entre guillemets (et cela signifie que tout va bien ici du point de vue de l'importation dans la base de données), la vérification avec cette méthode montrera un faux problème (colonnes supplémentaires) - cela devrait également être pris en compte lors de l'analyse des résultats.
3. Si les guillemets ne sont pas appariés et ne peuvent pas résoudre ce problème, vous pouvez supprimer tous les guillemets du fichier:
sed -i 's / "// g' data.csv
Le danger de cette approche est que si les valeurs de champ contiennent un caractère séparateur, le nombre de colonnes de la ligne changera. Par conséquent, les caractères de séparation doivent être supprimés des valeurs de champ au stade de l'exportation (supprimer ou remplacer par un autre caractère).
4. Champs vides
Face à une situation où l'importation réussie de données a été empêchée par des valeurs de champ vides sous cette forme:
; ""
Où «;» Est le signe du séparateur de champ dans ce cas. Autrement dit, le champ est composé de deux guillemets doubles (chaîne vide simple). Si vous ne pouvez soudainement pas importer les données et que vous pensez que le problème peut être dû à des champs vides, essayez de remplacer «» par NULL
sed -i 's /; ”” /; NULL / g' data.csv
(remplacez «;» par votre option de séparateur)
5. Il peut être utile de rechercher des formats numériques «sales» dans les données:
; "0" (le nombre contient un espace)
; "100.10-" (le signe "-" après le numéro)
La grue Bugatti 3/4 "300 - une dimension en pouces est indiquée par un double guillemet - et cela entraîne automatiquement le problème des guillemets non appariés lors de l'exportation.
Malheureusement, il ne s'agit pas d'une liste exhaustive des problèmes possibles avec des formats de données peu pratiques pour l'importation dans la base de données. Ce serait formidable de connaître vos options de la pratique: quelles erreurs curieuses avez-vous rencontrées? Comment vous les avez détectés et éliminés. Partagez dans les commentaires.
Conclusion
En général, le modèle de données pour Process Mining est très simple: une table d'événements plus, éventuellement, des livres de référence supplémentaires. Mais comme cela se produit généralement, cela ne semble simple que lorsqu'au moins un cycle complet de tâches est terminé - l'ensemble du processus est visible dans son intégralité et le plan de travail est clair. J'espère que cet article vous aidera à comprendre la préparation des données pour votre premier projet Process Mining. En général, le processus de préparation ressemble à ceci:
- Demander un historique des modifications au propriétaire des données
- Vérification et nettoyage du téléchargement (préparation des fichiers CSV)
- Importer vers SAP HANA
- Construction de tables d'événements
- Création d'une table CA (référence de processus)
Et, en fait, c'est là que commence la préparation du modèle de données et que commence la partie la plus intéressante - Process Mining. Si vous avez des questions lors de la mise en œuvre du projet Process Mining, n'hésitez pas à écrire dans les commentaires, je serai heureux de vous aider. Bonne chance!
Fedor Pavlov, expert de la plateforme SAP CIS