Bonjour à tous. Nous partageons la traduction de la dernière partie de l'article, préparée spécialement pour les étudiants du
cours Data Engineer . La première partie se trouve
ici .
Apache Beam et DataFlow pour les pipelines en temps réel
Configuration de Google Cloud
Remarque: J'ai utilisé Google Cloud Shell pour démarrer le pipeline et publier les données du journal utilisateur, car j'ai rencontré des problèmes lors de l'exécution du pipeline dans Python 3. Google Cloud Shell utilise Python 2, qui est mieux compatible avec Apache Beam.
Pour démarrer le convoyeur, nous devons nous plonger un peu dans les paramètres. Pour ceux d'entre vous qui n'ont pas utilisé GCP auparavant, vous devez suivre les 6 étapes suivantes sur cette
page .
Après cela, nous devrons télécharger nos scripts sur Google Cloud Storage et les copier sur notre Google Cloud Shel. Le téléchargement vers le stockage cloud est assez trivial (une description peut être trouvée
ici ). Pour copier nos fichiers, nous pouvons ouvrir Google Cloud Shel à partir de la barre d'outils en cliquant sur la première icône à gauche dans la figure 2 ci-dessous.
 Figure 2
Figure 2Les commandes dont nous avons besoin pour copier des fichiers et installer les bibliothèques nécessaires sont répertoriées ci-dessous.
Création de notre base de données et table
Après avoir terminé toutes les étapes de configuration, la prochaine chose que nous devons faire est de créer un ensemble de données et une table dans BigQuery. Il existe plusieurs façons de procéder, mais la plus simple consiste à utiliser la console Google Cloud en créant d'abord un ensemble de données. Vous pouvez suivre les étapes du
lien suivant pour créer une table avec un schéma. Notre tableau comportera
7 colonnes correspondant aux composants de chaque journal utilisateur. Pour plus de commodité, nous définirons toutes les colonnes comme des chaînes (tapez chaîne), à l'exception de la variable timelocal, et les nommerons en fonction des variables que nous avons générées précédemment. La disposition de notre table devrait ressembler à la figure 3.
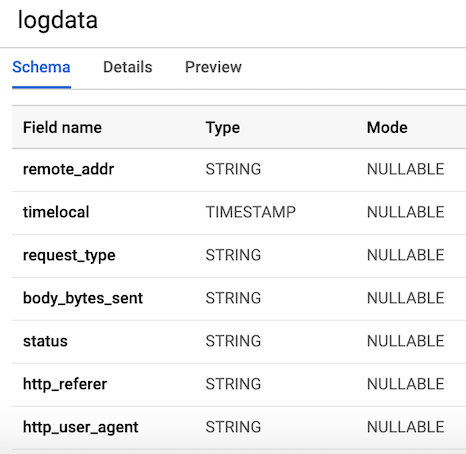 Figure 3. Disposition du tableau
Figure 3. Disposition du tableauPublier les données du journal utilisateur
Pub / Sub est un composant essentiel de notre pipeline car il permet à plusieurs applications indépendantes d'interagir les unes avec les autres. En particulier, il fonctionne comme un intermédiaire qui nous permet d'envoyer et de recevoir des messages entre les applications. La première chose que nous devons faire est de créer un sujet. Accédez simplement à Pub / Sub dans la console et appuyez sur CRÉER UN SUJET.
Le code ci-dessous appelle notre script pour générer les données de journal définies ci-dessus, puis se connecte et envoie les journaux à Pub / Sub. La seule chose que nous devons faire est de créer un objet
PublisherClient , de spécifier le chemin d'accès au sujet à l'aide de la méthode
topic_path et d'appeler la fonction de
publish avec
topic_path et les données. Veuillez noter que nous importons
generate_log_line partir de notre script
stream_logs , alors assurez-vous que ces fichiers se trouvent dans le même dossier, sinon vous obtiendrez une erreur d'importation. Ensuite, nous pouvons exécuter cela via notre console Google en utilisant:
python publish.py
from stream_logs import generate_log_line import logging from google.cloud import pubsub_v1 import random import time PROJECT_ID="user-logs-237110" TOPIC = "userlogs" publisher = pubsub_v1.PublisherClient() topic_path = publisher.topic_path(PROJECT_ID, TOPIC) def publish(publisher, topic, message): data = message.encode('utf-8') return publisher.publish(topic_path, data = data) def callback(message_future):
Dès que le fichier démarre, nous pouvons observer la sortie des données du journal vers la console, comme illustré dans la figure ci-dessous. Ce script fonctionnera jusqu'à ce que nous
utilisions CTRL + C pour le terminer.
 Figure 4. Sortie de
Figure 4. Sortie de publish_logs.py
Écrire du code pour notre pipeline
Maintenant que nous avons tout préparé, nous pouvons passer à la partie la plus intéressante - écrire le code de notre pipeline en utilisant Beam et Python. Pour créer un pipeline Beam, nous devons créer un objet pipeline (p). Après avoir créé l'objet pipeline, nous pouvons appliquer plusieurs fonctions l'une après l'autre à l'aide de l'opérateur
pipe (|) . En général, le flux de travail ressemble à l'image ci-dessous.
[Final Output PCollection] = ([Initial Input PCollection] | [First Transform] | [Second Transform] | [Third Transform])
Dans notre code, nous allons créer deux fonctions définies par l'utilisateur. La fonction
regex_clean , qui analyse les données et récupère la ligne correspondante en fonction de la liste PATTERNS à l'aide de la fonction
re.search . La fonction renvoie une chaîne séparée par des virgules. Si vous n'êtes pas un expert en expression régulière, je vous recommande de lire ce
tutoriel et de vous entraîner dans le bloc-notes pour vérifier le code. Après cela, nous définissons une fonction ParDo personnalisée appelée
Split , qui est une variation de la transformation Beam pour le traitement parallèle. En Python, cela se fait d'une manière spéciale - nous devons créer une classe qui hérite de la classe DoFn Beam. La fonction Split prend une chaîne analysée de la fonction précédente et renvoie une liste de dictionnaires avec des clés correspondant aux noms de colonne dans notre table BigQuery. Il y a quelque chose à noter à propos de cette fonction: j'ai dû importer le
datetime à l'intérieur de la fonction pour la faire fonctionner. J'ai reçu une erreur d'importation au début du fichier, ce qui était étrange. Cette liste est ensuite transmise à la fonction
WriteToBigQuery , qui ajoute simplement nos données à la table. Le code du travail Batch DataFlow et du travail Streaming DataFlow est indiqué ci-dessous. La seule différence entre le code batch et le code stream est que dans le traitement batch, nous lisons CSV à partir de
src_path utilisant la fonction
ReadFromText de Beam.
Travail DataFlow par lots (traitement des paquets)
import apache_beam as beam from apache_beam.options.pipeline_options import PipelineOptions from google.cloud import bigquery import re import logging import sys PROJECT='user-logs-237110' schema = 'remote_addr:STRING, timelocal:STRING, request_type:STRING, status:STRING, body_bytes_sent:STRING, http_referer:STRING, http_user_agent:STRING' src_path = "user_log_fileC.txt" def regex_clean(data): PATTERNS = [r'(^\S+\.[\S+\.]+\S+)\s',r'(?<=\[).+?(?=\])', r'\"(\S+)\s(\S+)\s*(\S*)\"',r'\s(\d+)\s',r"(?<=\[).\d+(?=\])", r'\"[AZ][az]+', r'\"(http|https)://[az]+.[az]+.[az]+'] result = [] for match in PATTERNS: try: reg_match = re.search(match, data).group() if reg_match: result.append(reg_match) else: result.append(" ") except: print("There was an error with the regex search") result = [x.strip() for x in result] result = [x.replace('"', "") for x in result] res = ','.join(result) return res class Split(beam.DoFn): def process(self, element): from datetime import datetime element = element.split(",") d = datetime.strptime(element[1], "%d/%b/%Y:%H:%M:%S") date_string = d.strftime("%Y-%m-%d %H:%M:%S") return [{ 'remote_addr': element[0], 'timelocal': date_string, 'request_type': element[2], 'status': element[3], 'body_bytes_sent': element[4], 'http_referer': element[5], 'http_user_agent': element[6] }] def main(): p = beam.Pipeline(options=PipelineOptions()) (p | 'ReadData' >> beam.io.textio.ReadFromText(src_path) | "clean address" >> beam.Map(regex_clean) | 'ParseCSV' >> beam.ParDo(Split()) | 'WriteToBigQuery' >> beam.io.WriteToBigQuery('{0}:userlogs.logdata'.format(PROJECT), schema=schema, write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND) ) p.run() if __name__ == '__main__': logger = logging.getLogger().setLevel(logging.INFO) main()
Streaming DataFlow Job
from apache_beam.options.pipeline_options import PipelineOptions from google.cloud import pubsub_v1 from google.cloud import bigquery import apache_beam as beam import logging import argparse import sys import re PROJECT="user-logs-237110" schema = 'remote_addr:STRING, timelocal:STRING, request_type:STRING, status:STRING, body_bytes_sent:STRING, http_referer:STRING, http_user_agent:STRING' TOPIC = "projects/user-logs-237110/topics/userlogs" def regex_clean(data): PATTERNS = [r'(^\S+\.[\S+\.]+\S+)\s',r'(?<=\[).+?(?=\])', r'\"(\S+)\s(\S+)\s*(\S*)\"',r'\s(\d+)\s',r"(?<=\[).\d+(?=\])", r'\"[AZ][az]+', r'\"(http|https)://[az]+.[az]+.[az]+'] result = [] for match in PATTERNS: try: reg_match = re.search(match, data).group() if reg_match: result.append(reg_match) else: result.append(" ") except: print("There was an error with the regex search") result = [x.strip() for x in result] result = [x.replace('"', "") for x in result] res = ','.join(result) return res class Split(beam.DoFn): def process(self, element): from datetime import datetime element = element.split(",") d = datetime.strptime(element[1], "%d/%b/%Y:%H:%M:%S") date_string = d.strftime("%Y-%m-%d %H:%M:%S") return [{ 'remote_addr': element[0], 'timelocal': date_string, 'request_type': element[2], 'body_bytes_sent': element[3], 'status': element[4], 'http_referer': element[5], 'http_user_agent': element[6] }] def main(argv=None): parser = argparse.ArgumentParser() parser.add_argument("--input_topic") parser.add_argument("--output") known_args = parser.parse_known_args(argv) p = beam.Pipeline(options=PipelineOptions()) (p | 'ReadData' >> beam.io.ReadFromPubSub(topic=TOPIC).with_output_types(bytes) | "Decode" >> beam.Map(lambda x: x.decode('utf-8')) | "Clean Data" >> beam.Map(regex_clean) | 'ParseCSV' >> beam.ParDo(Split()) | 'WriteToBigQuery' >> beam.io.WriteToBigQuery('{0}:userlogs.logdata'.format(PROJECT), schema=schema, write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND) ) result = p.run() result.wait_until_finish() if __name__ == '__main__': logger = logging.getLogger().setLevel(logging.INFO) main()
Démarrage du convoyeur
Nous pouvons démarrer le pipeline de plusieurs manières différentes. Si nous le voulions, nous pourrions simplement l'exécuter localement à partir du terminal, en nous connectant à distance à GCP.
python -m main_pipeline_stream.py \ --input_topic "projects/user-logs-237110/topics/userlogs" \ --streaming
Cependant, nous allons le lancer à l'aide de DataFlow. Nous pouvons le faire en utilisant la commande ci-dessous en définissant les paramètres requis suivants.
project - L'ID de votre projet GCP.runner est un runner pipeline qui analysera votre programme et construira votre pipeline. Pour s'exécuter dans le cloud, vous devez spécifier un DataflowRunner.staging_location - Chemin d'accès au stockage cloud Cloud Dataflow pour l'indexation des paquets de code requis par les gestionnaires de processus.temp_location - le chemin vers le stockage cloud Cloud Dataflow pour héberger les fichiers de travail temporaires créés pendant le fonctionnement du pipeline.streaming
python main_pipeline_stream.py \ --runner DataFlow \ --project $PROJECT \ --temp_location $BUCKET/tmp \ --staging_location $BUCKET/staging --streaming
Pendant l'exécution de cette commande, nous pouvons accéder à l'onglet DataFlow dans la console Google et afficher notre pipeline. En cliquant sur le pipeline, nous devrions voir quelque chose de similaire à la figure 4. À des fins de débogage, il peut être très utile d'aller dans les journaux puis dans Stackdriver pour afficher les journaux détaillés. Cela m'a aidé à résoudre des problèmes avec le pipeline dans un certain nombre de cas.
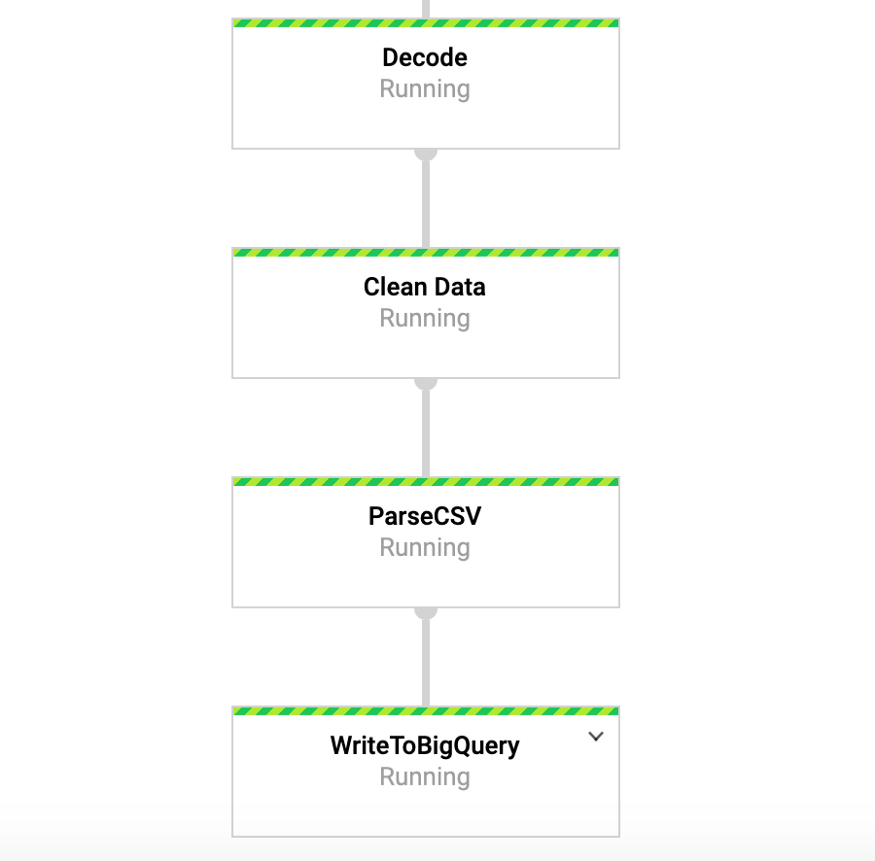 Figure 4: Convoyeur à poutres
Figure 4: Convoyeur à poutresAccédez à nos données dans BigQuery
Donc, nous aurions déjà dû commencer le pipeline avec les données entrant dans notre table. Pour tester cela, nous pouvons aller à BigQuery et afficher les données. Après avoir utilisé la commande ci-dessous, vous devriez voir les premières lignes de l'ensemble de données. Maintenant que nous avons les données stockées dans BigQuery, nous pouvons effectuer une analyse plus approfondie, ainsi que partager des données avec des collègues et commencer à répondre aux questions commerciales.
SELECT * FROM `user-logs-237110.userlogs.logdata` LIMIT 10;
 Figure 5: BigQuery
Figure 5: BigQueryConclusion
Nous espérons que ce message servira d'exemple utile pour créer un pipeline de données en streaming, ainsi que pour trouver des moyens de rendre les données plus accessibles. Le stockage de données dans ce format nous offre de nombreux avantages. Nous pouvons maintenant commencer à répondre à des questions importantes, par exemple, combien de personnes utilisent notre produit? La base d'utilisateurs augmente-t-elle au fil du temps? Avec quels aspects du produit les gens interagissent-ils le plus? Et y a-t-il des erreurs là où elles ne devraient pas être? Ce sont des questions qui intéresseront l'organisation. Sur la base des idées issues des réponses à ces questions, nous pourrons améliorer le produit et accroître l'intérêt des utilisateurs.
Beam est vraiment utile pour ce type d'exercice, et propose également un certain nombre d'autres cas d'utilisation intéressants. Par exemple, vous pouvez analyser les données sur les ticks d'échange en temps réel et effectuer des transactions sur la base de l'analyse, peut-être que vous avez des données de capteur provenant de véhicules et que vous souhaitez calculer le calcul du niveau de trafic. Vous pouvez également, par exemple, être une société de jeux qui collecte des données utilisateur et les utilise pour créer des tableaux de bord pour suivre les mesures clés. D'accord, messieurs, ce sujet est déjà pour un autre post, merci pour la lecture, et pour ceux qui veulent voir le code complet, ci-dessous est un lien vers mon GitHub.
https://github.com/DFoly/User_log_pipeline
C’est tout.
Lisez la première partie .