L'essence de l'histoire du gestionnaire de paquets le plus populaire pour Kubernetes pourrait être représentée à l'aide d'emoji:
- la boîte est Helm (c'est la plus appropriée de la dernière version d'Emoji);
- serrure - sécurité;
- l'homme est la solution au problème.

En fait, tout sera un peu plus compliqué, et l'histoire regorge de détails techniques sur la
façon de rendre Helm sûr .
- En bref, qu'est-ce que Helm si vous ne le saviez pas ou l'oubliez. Quels problèmes résout-il et où se situe-t-il dans l'écosystème?
- Considérez l'architecture de Helm. Pas une seule conversation sur la sécurité et la façon de sécuriser un outil ou une solution ne peut se passer de comprendre l'architecture du composant.
- Parlons des composants de Helm.
- Le problème le plus brûlant est l'avenir - la nouvelle version de Helm 3.
Tout dans cet article concerne Helm 2. Cette version est maintenant en production et c'est probablement vous qui l'utilisez maintenant, et c'est là qu'il y a des risques de sécurité.
À propos du conférencier: Alexander Khayorov (
allexx ) développe depuis 10 ans, contribue à améliorer le contenu de
Moscow Python Conf ++ et a rejoint le comité
Helm Summit . Travaille actuellement chez Chainstack en tant que responsable du développement - il s'agit d'un hybride entre le responsable du développement et la personne responsable de la livraison des versions finales. Autrement dit, il est situé sur le site des hostilités, où tout se passe de la création du produit à son fonctionnement.
Chainstack est une petite start-up en croissance rapide dont la tâche est de fournir aux clients la possibilité d'oublier l'infrastructure et les difficultés de fonctionnement des applications décentralisées, l'équipe de développement est située à Singapour. Ne demandez pas à Chainstack de vendre ou d'acheter de la crypto-monnaie, mais proposez de parler des cadres de la blockchain d'entreprise, et ils seront heureux de vous répondre.
Heaume
Il s'agit du gestionnaire de packages (graphiques) pour Kubernetes. La manière la plus compréhensible et la plus universelle d'apporter des applications au cluster Kubernetes.

Bien entendu, il s'agit d'une approche plus structurelle et industrielle que de créer vos propres manifestes YAML et d'écrire de petits utilitaires.
Helm est le meilleur disponible et le plus populaire en ce moment.
Pourquoi barre? Principalement parce qu'il est pris en charge par la CNCF. Cloud Native - une grande organisation, est la société mère des projets Kubernetes, etcd, Fluentd et autres.
Autre fait important, Helm est un projet très populaire. Quand, en janvier 2019, je prévoyais de parler de la façon de rendre Helm sûr, le projet avait mille étoiles sur GitHub. En mai, il y en avait 12 000.
Beaucoup de gens sont intéressés par Helm, donc, même si vous ne l'utilisez toujours pas, vous aurez besoin de connaître sa sécurité.
La sécurité est importante.L'équipe centrale de Helm est prise en charge par Microsoft Azure, et c'est donc un projet assez stable contrairement à beaucoup d'autres. La sortie de Helm 3 Alpha 2 à la mi-juillet indique que beaucoup de gens travaillent sur le projet et qu'ils ont le désir et la force de développer et d'améliorer Helm.
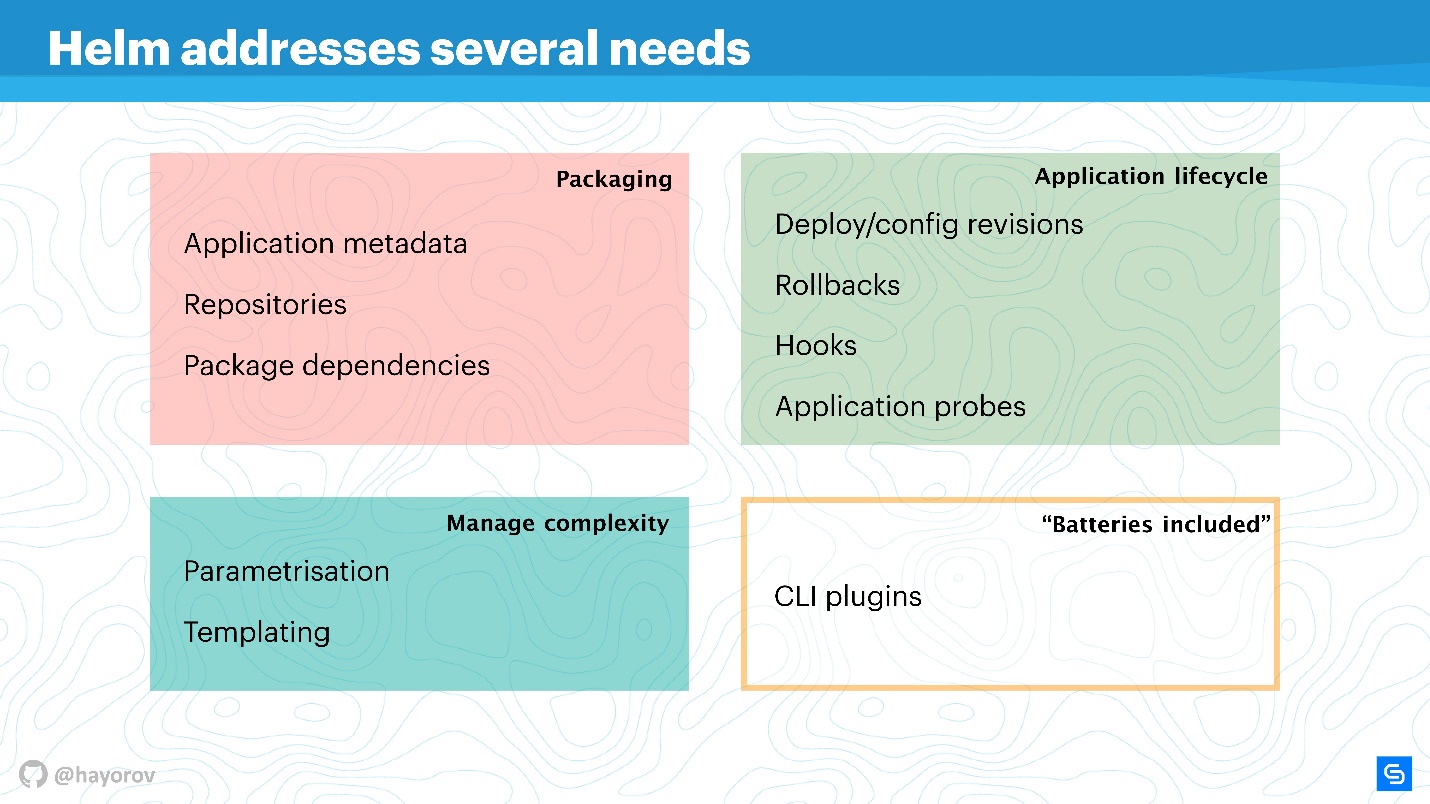
Helm résout plusieurs problèmes de gestion des applications racine dans Kubernetes.
- Emballage d'application. Même une application comme «Hello, World» sur WordPress comprend déjà plusieurs services, et je veux les regrouper.
- Gestion de la complexité qui se pose avec la gestion de ces applications.
- Un cycle de vie qui ne se termine pas après l'installation ou le déploiement de l'application. Il continue de vivre, il doit être mis à jour, et Helm y contribue et essaie d'apporter les bonnes mesures et politiques pour cela.
L'emballage est organisé de manière compréhensible: il y a des métadonnées en totale conformité avec le travail d'un gestionnaire de paquets régulier pour Linux, Windows ou MacOS. Autrement dit, le référentiel, en fonction de divers packages, méta-informations pour les applications, paramètres, fonctionnalités de configuration, indexation des informations, etc. Tout ce Helm vous permet d'obtenir et d'utiliser pour les applications.
Gestion de la complexité . Si vous avez de nombreuses applications similaires, vous avez besoin d'un paramétrage. Les modèles en découlent, mais afin de ne pas trouver votre propre façon de créer des modèles, vous pouvez utiliser ce que Helm propose dès le départ.
Gestion du cycle de vie des applications - à mon avis, c'est le problème le plus intéressant et non résolu. C'est pourquoi je suis venu à Helm en temps voulu. Nous devions surveiller le cycle de vie de l'application, nous voulions transférer notre CI / CD et nos cycles d'application à ce paradigme.
Helm vous permet de:
- gérer le déploiement, introduit le concept de configuration et de révision;
- restauration réussie;
- utiliser des crochets pour différents événements;
- Ajoutez des vérifications d'application supplémentaires et répondez à leurs résultats.
De plus
, Helm a des «batteries» - un grand nombre de choses savoureuses qui peuvent être incluses sous forme de plug-ins, vous simplifiant la vie. Les plugins peuvent être écrits indépendamment, ils sont assez isolés et ne nécessitent pas d'architecture élancée. Si vous voulez implémenter quelque chose, je vous recommande de le faire en tant que plugin, puis il est possible de l'inclure en amont.
Helm est basé sur trois concepts principaux:
- Chart Repo - description et tableau de paramétrage possibles pour votre manifeste.
- Config - c'est-à -dire les valeurs qui seront appliquées (texte, valeurs numériques, etc.).
- Release rassemble les deux premiers composants, et ensemble, ils se transforment en Release. Les versions peuvent être versionnées, réalisant ainsi l'organisation du cycle de vie: petite au moment de l'installation et grande au moment de la mise à niveau, de la rétrogradation ou de la restauration.
Architecture de barre
Le diagramme reflète conceptuellement l'architecture de haut niveau de Helm.
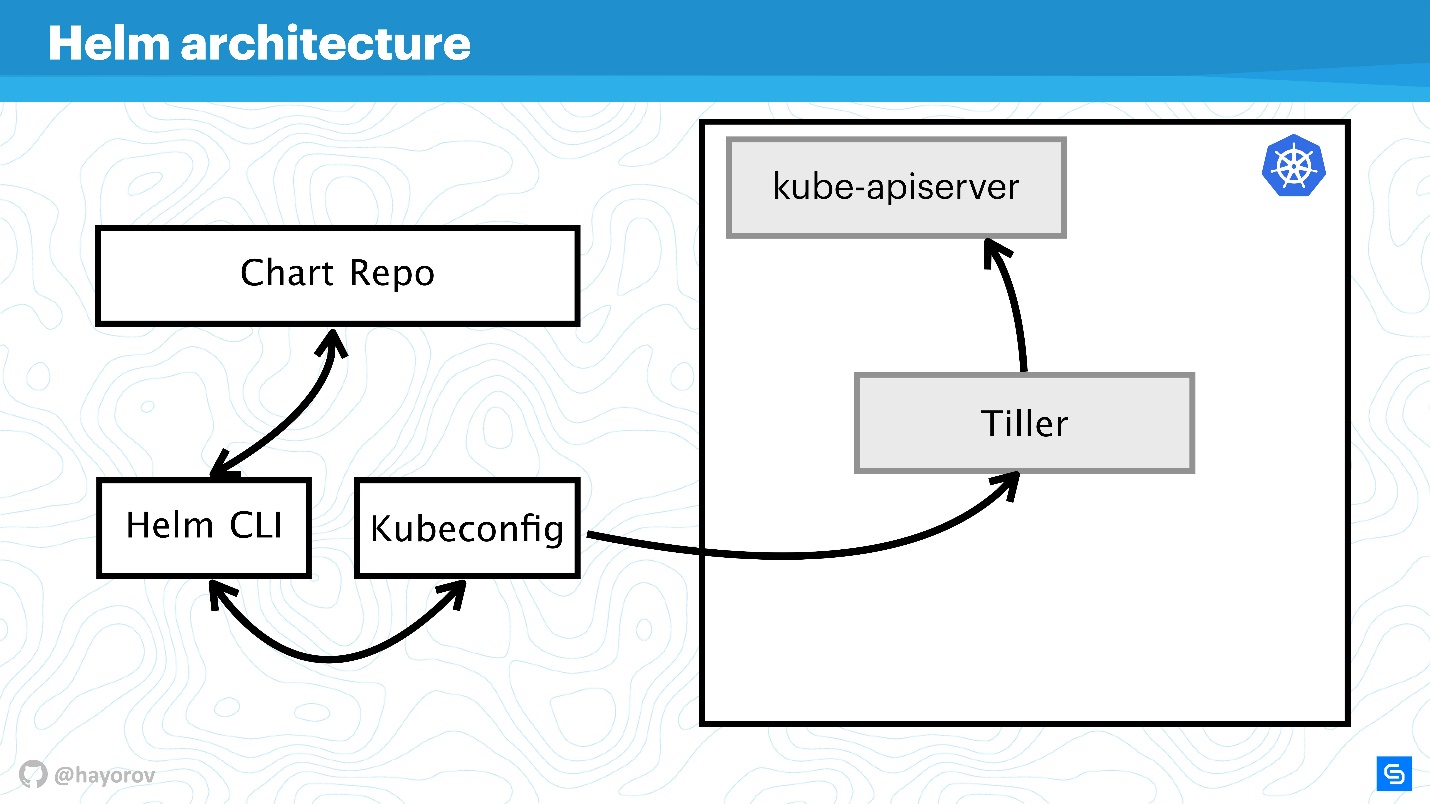
Permettez-moi de vous rappeler que Helm est quelque chose qui est lié à Kubernetes. Par conséquent, nous ne pouvons pas nous passer de cluster Kubernetes (rectangle). Le composant kube-apiserver est sur l'assistant. Sans Helm, nous avons Kubeconfig. Helm apporte un petit binaire, pour ainsi dire, l'utilitaire Helm CLI, qui est installé sur un ordinateur, un ordinateur portable, un ordinateur central - pour tout.
Mais cela ne suffit pas. Helm a un composant serveur Tiller. Il représente les intérêts de Helm au sein d'un cluster, c'est la même application au sein d'un cluster Kubernetes, comme les autres.
Le composant suivant de Chart Repo est le référentiel de graphiques. Il existe un référentiel officiel et il peut exister un référentiel privé d'une entreprise ou d'un projet.
L'interaction
Voyons comment les composants d'architecture interagissent lorsque nous voulons installer une application à l'aide de Helm.
- Nous disons
Helm install , allez dans le référentiel (Chart Repo) et obtenez un graphique Helm.
- L'utilitaire Helm (Helm CLI) interagit avec Kubeconfig pour déterminer le cluster à contacter.
- Après avoir reçu ces informations, l'utilitaire se tourne vers Tiller, qui est dans notre cluster, déjà sous forme d'application.
- Tiller se tourne vers Kube-apiserver pour effectuer des actions dans Kubernetes, pour créer des objets (services, pods, répliques, secrets, etc.).
De plus, nous compliquerons le schéma pour voir le vecteur d'attaques auquel l'ensemble de l'architecture Helm dans son ensemble peut être soumis. Et puis on va essayer de la protéger.
Vecteur d'attaque
Le premier point potentiellement faible est l'
API utilisateur privilégié . Dans le cadre du schéma, il s'agit d'un pirate informatique qui a obtenu un accès administrateur à Helm CLI.
Un utilisateur d'API non privilégié peut également être dangereux s'il se trouve quelque part à proximité. Un tel utilisateur aura un contexte différent, par exemple, il peut être fixé dans un espace de noms du cluster dans les paramètres de Kubeconfig.
Le vecteur d'attaque le plus intéressant peut être le processus situé à l'intérieur du cluster quelque part près de Tiller et auquel il peut accéder. Il peut s'agir d'un serveur Web ou d'un microservice qui voit l'environnement réseau du cluster.
Une option d'attaque exotique, mais qui gagne en popularité, est associée au Chart Repo. Un graphique créé par un auteur sans scrupules peut contenir une ressource non sécurisée, et vous l'exécuterez en le croyant. Ou il peut remplacer le graphique que vous téléchargez à partir du référentiel officiel et, par exemple, créer une ressource sous la forme de politiques et augmenter votre accès.
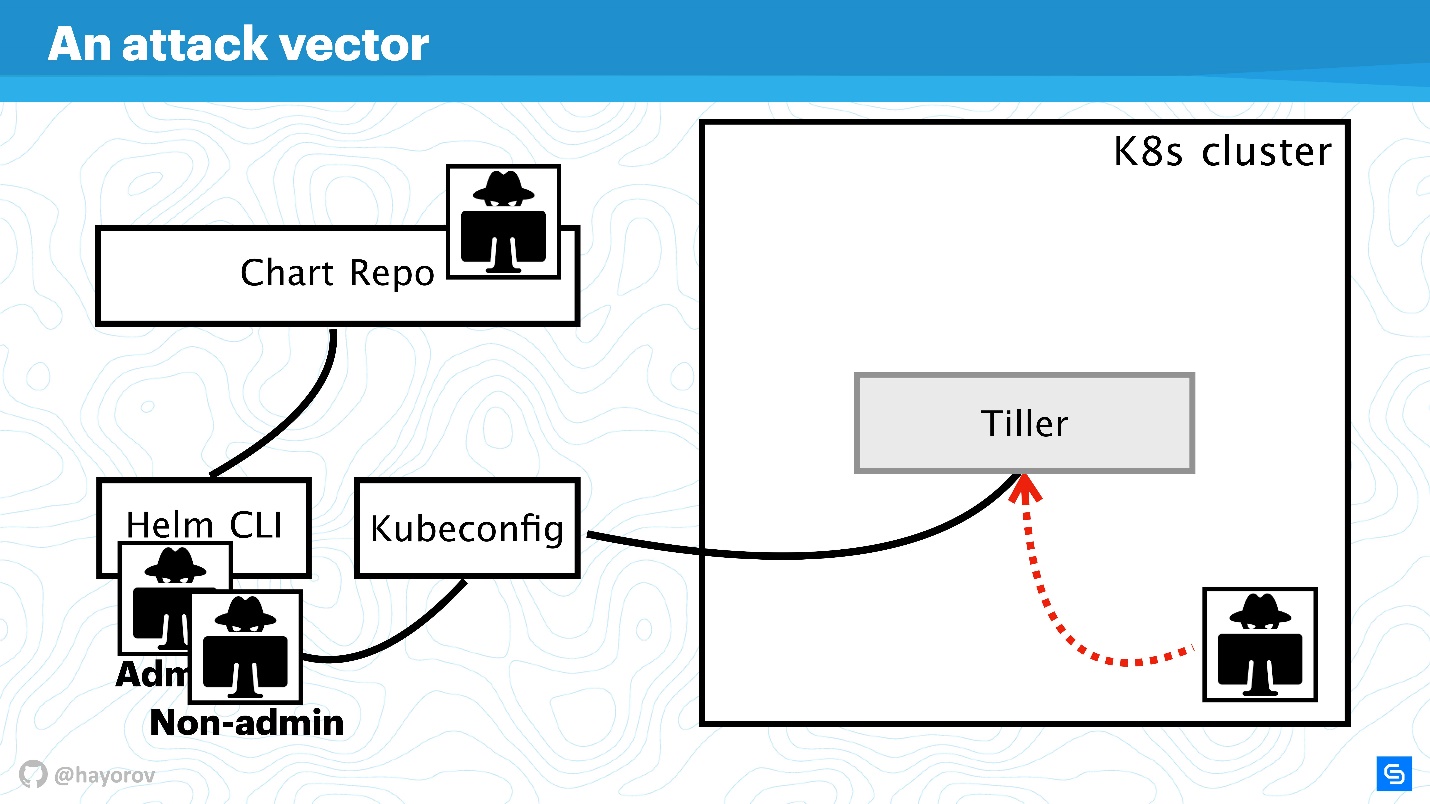
Essayons de repousser les attaques de ces quatre côtés et trouvons où il y a des problèmes dans l'architecture de Helm, et où, éventuellement, ils ne le sont pas.
Agrandissons le schéma, ajoutons plus d'éléments, mais gardons tous les composants de base.
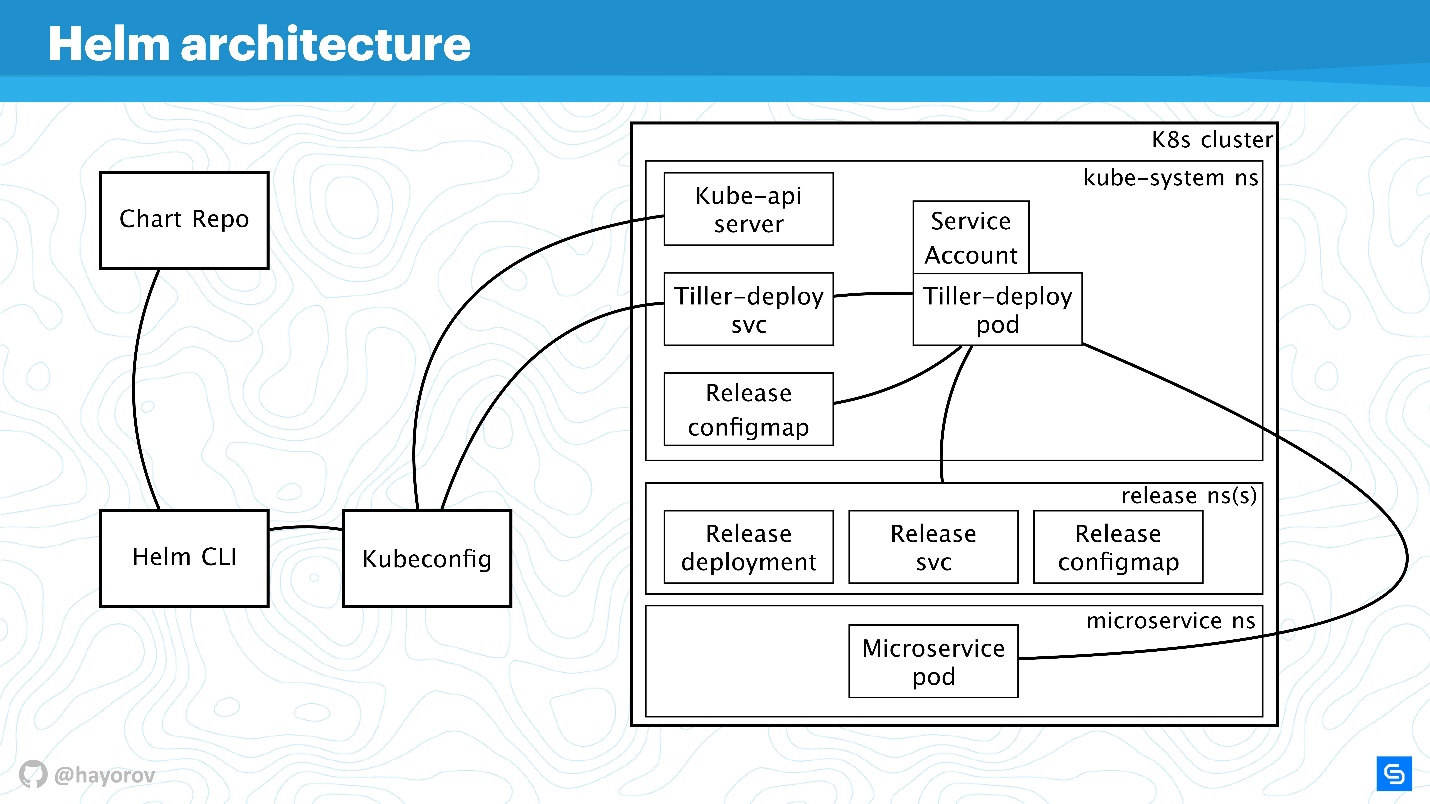
Helm CLI communique avec Chart Repo, interagit avec Kubeconfig, le travail est transféré au cluster dans le composant Tiller.
Tiller est représenté par deux objets:
- Tiller-deploy svc, qui expose un certain service;
- Tiller-deploy pod (sur le diagramme en une seule copie dans une réplique), qui exécute toute la charge qui accède au cluster.
Pour l'interaction, différents protocoles et schémas sont utilisés. Du point de vue de la sécurité, nous sommes surtout intéressés par:
- Le mécanisme par lequel Helm CLI accède au référentiel de graphiques: quel protocole, s'il existe une authentification et ce qui peut être fait à ce sujet.
- Protocole par lequel Helm CLI, à l'aide de kubectl, communique avec Tiller. Il s'agit d'un serveur RPC installé à l'intérieur du cluster.
- Tiller lui-même est disponible pour les microservices qui sont dans un cluster et interagit avec Kube-apiserver.
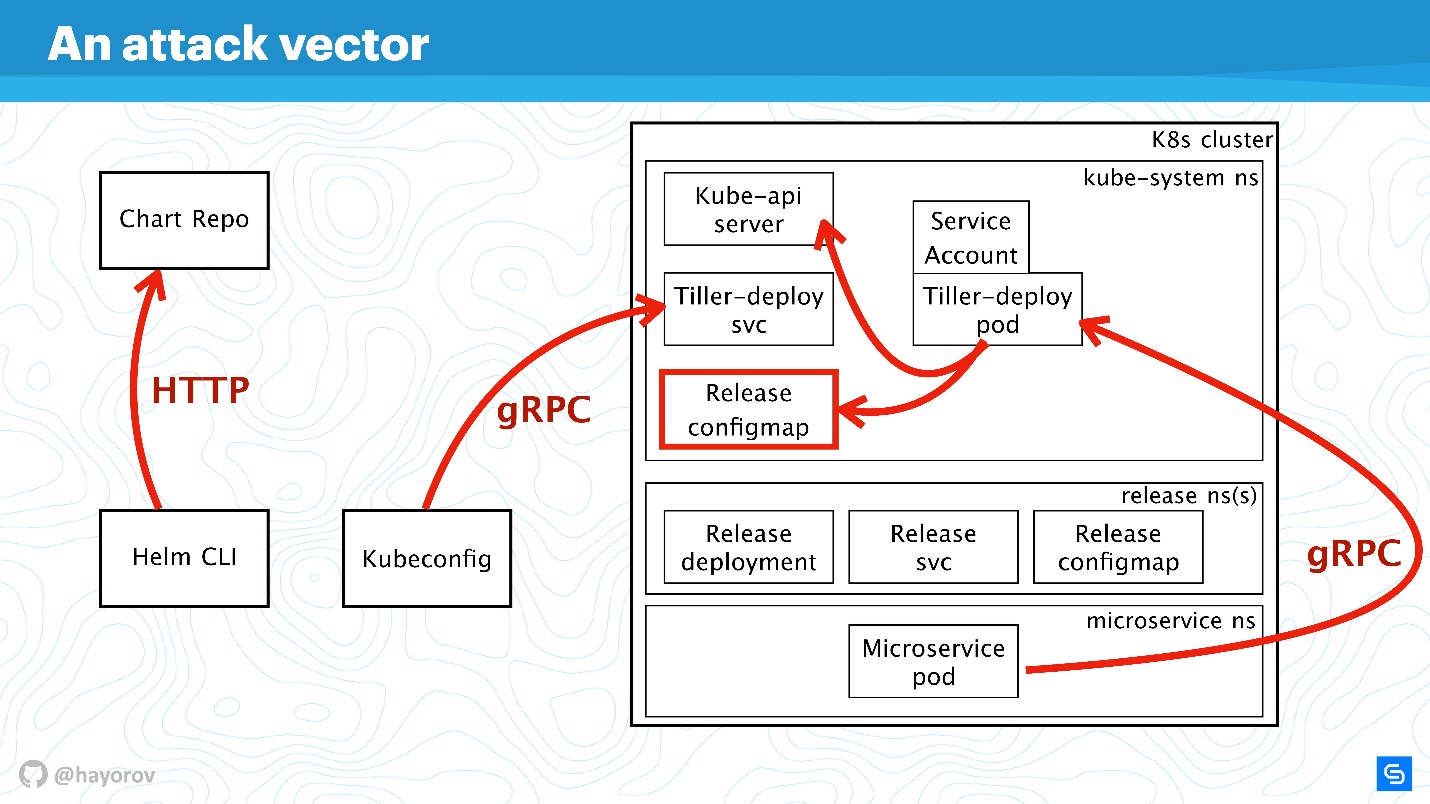
Nous allons discuter de toutes ces directions dans l'ordre.
RBAC
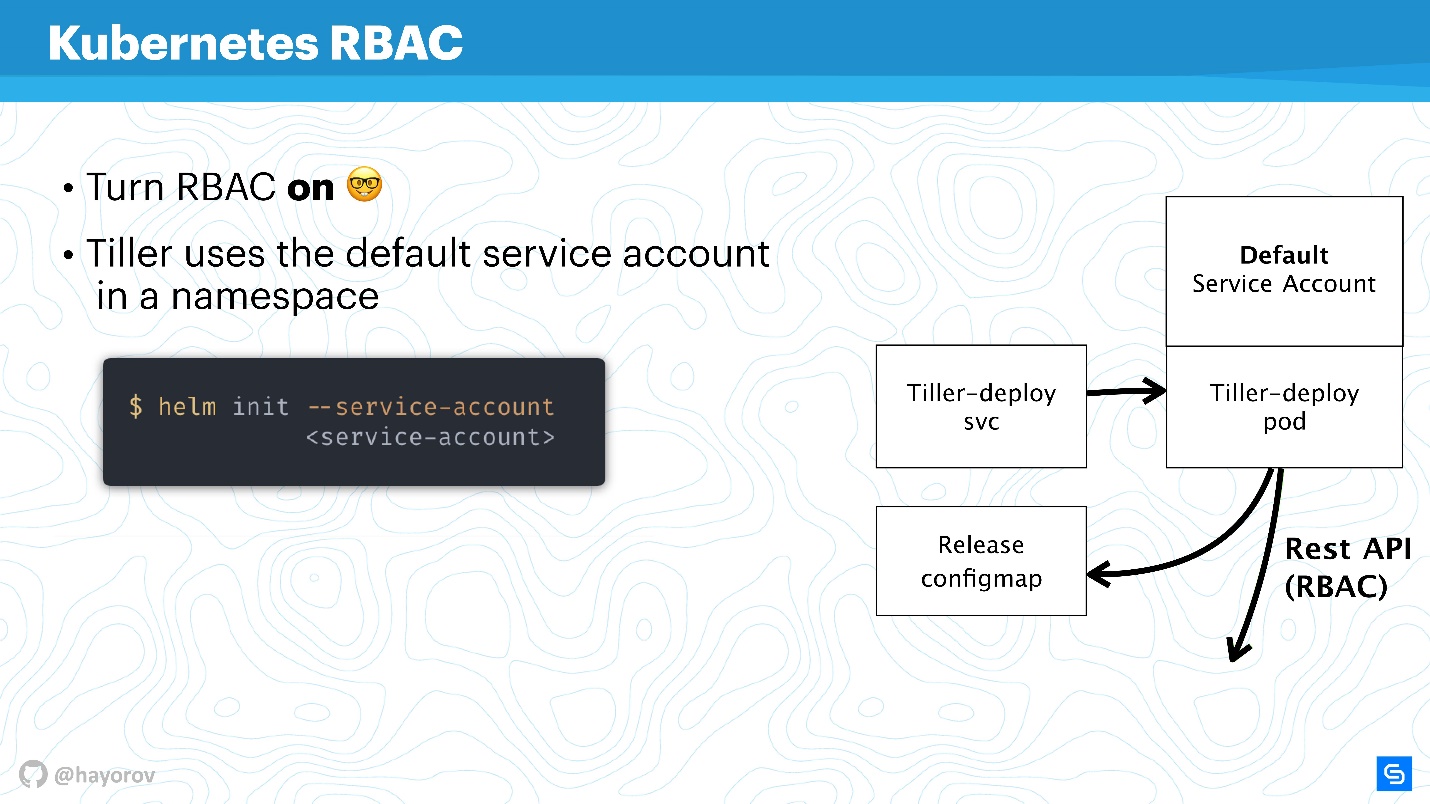
Il est inutile de parler de toute sécurité de Helm ou d'un autre service au sein du cluster si RBAC n'est pas activé.
Il semble que ce ne soit pas une nouvelle recommandation en soi, mais je suis sûr que jusqu'à présent, beaucoup n'ont pas inclus RBAC même en production, car cela fait beaucoup de bruit et vous devez configurer beaucoup de choses. Néanmoins, je demande instamment que cela soit fait.
 https://rbac.dev/
https://rbac.dev/ est un site d'avocats pour RBAC. Il a collecté une énorme quantité de documents intéressants qui aideront à mettre en place RBAC, montrer pourquoi il est bon et comment vivre avec, en principe, en production.
Je vais essayer d'expliquer comment Tiller et RBAC fonctionnent. Tiller fonctionne à l'intérieur d'un cluster sous un certain compte de service. En règle générale, si RBAC n'est pas configuré, ce sera le superutilisateur. Dans la configuration de base, Tiller sera l'administrateur. C'est pourquoi on dit souvent que Tiller est un tunnel SSH vers votre cluster. C'est en fait le cas, vous pouvez donc utiliser un compte de service dédié distinct au lieu du compte de service par défaut dans le diagramme ci-dessus.
Lorsque vous initialisez Helm, installez-le d'abord sur le serveur, vous pouvez définir le compte de service à l'aide de
--service-account . Cela vous permettra d'utiliser l'utilisateur avec le minimum de droits nécessaires. Certes, vous devez créer une telle "guirlande": Role et RoleBinding.
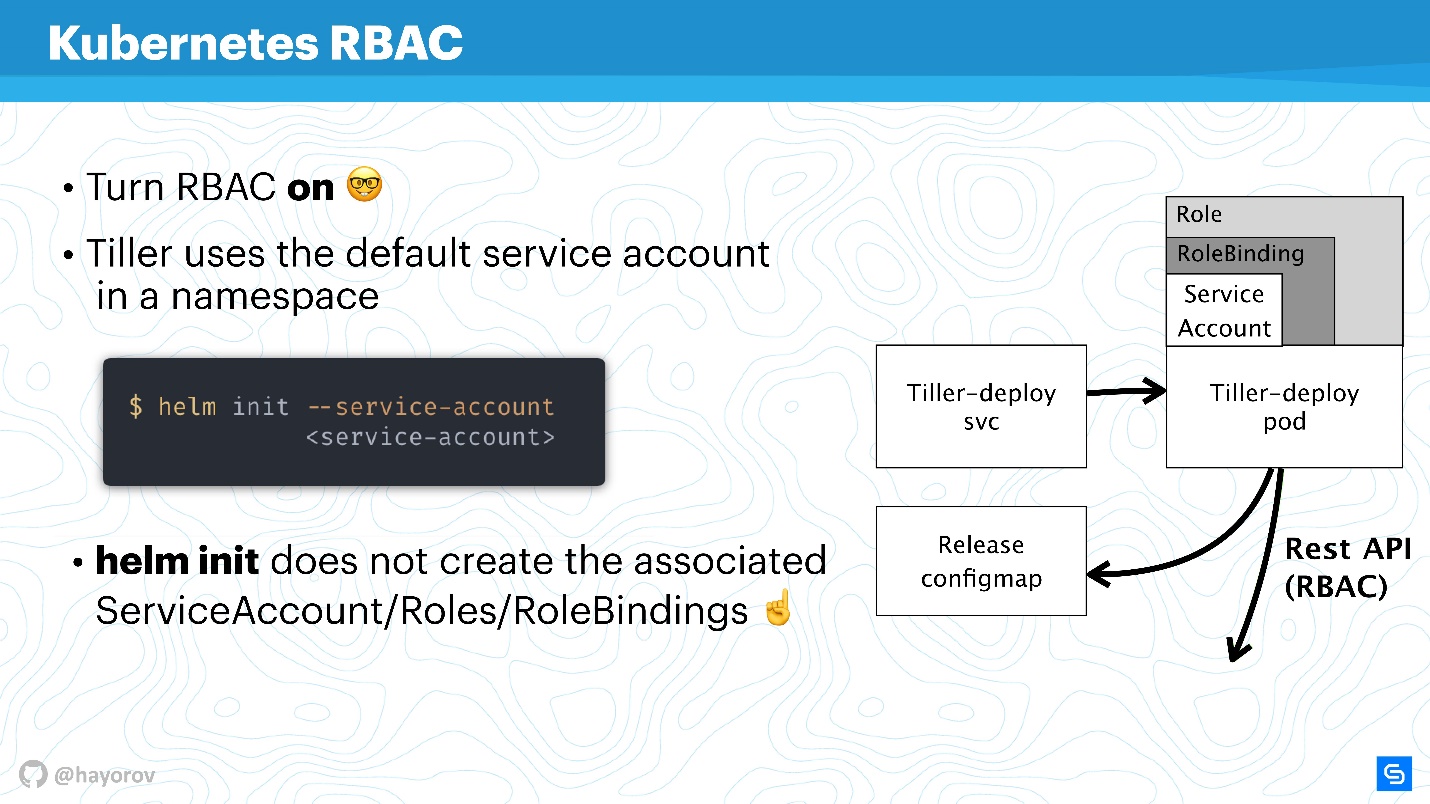
Malheureusement, Helm ne le fera pas pour vous. Vous ou votre administrateur de cluster Kubernetes devez préparer à l'avance un ensemble de rôles, RoleBinding pour le compte de service pour transférer Helm.
La question est - quelle est la différence entre Role et ClusterRole? La différence est que ClusterRole est valide pour tous les espaces de noms, contrairement aux rôles et rôles de liaison classiques, qui ne fonctionnent que pour les espaces de noms spécialisés. Vous pouvez configurer des stratégies pour l'ensemble du cluster et tous les espaces de noms, ainsi que les personnaliser pour chaque espace de noms séparément.
Il convient de mentionner que RBAC résout un autre gros problème. Beaucoup se plaignent du fait que Helm, malheureusement, n'est pas multi-location (ne prend pas en charge la multi-location). Si plusieurs équipes consomment un cluster et utilisent Helm, il est en principe impossible de configurer des stratégies et de différencier leur accès au sein de ce cluster, car il existe un compte de service sous lequel Helm fonctionne, et il crée toutes les ressources du cluster à partir de celui-ci, ce qui parfois très inconfortable. Cela est vrai - en tant que binaire lui-même, en tant que processus,
Helm Tiller n'a aucune idée de la mutualisation .
Cependant, il existe un excellent moyen d'exécuter plusieurs fois Tiller dans un cluster. Il n'y a aucun problème avec cela; Tiller peut être exécuté dans tous les espaces de noms. Ainsi, vous pouvez utiliser RBAC, Kubeconfig comme contexte et restreindre l'accès au Helm spécial.
Il ressemblera à ceci.
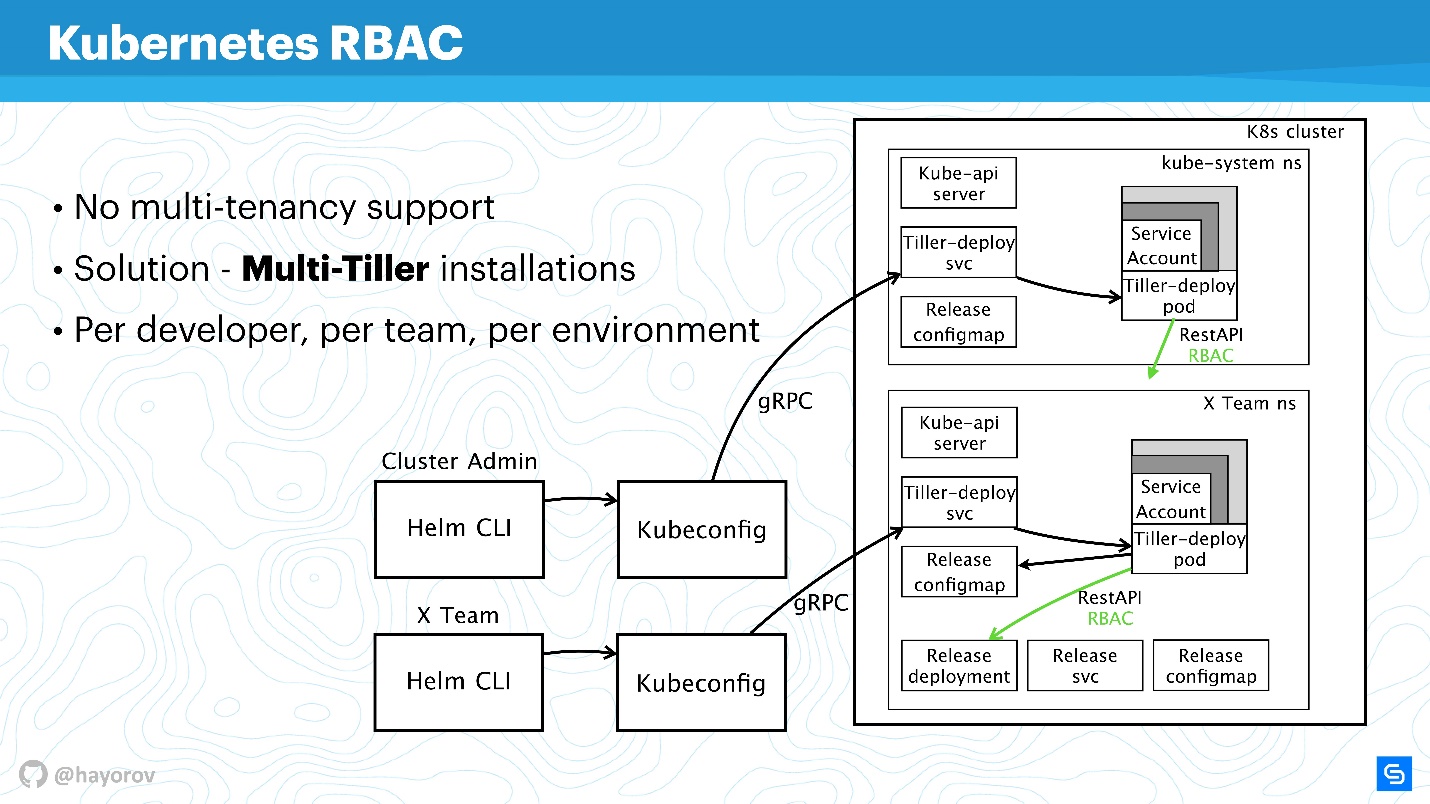
Par exemple, il existe deux Kubeconfig avec contexte pour différentes équipes (deux espaces de noms): X Team pour l'équipe de développement et le cluster d'administration. Le cluster d'administration a son propre large Tiller, qui est situé dans l'espace de noms du système Kube, respectivement un compte de service avancé. Et un espace de noms distinct pour l'équipe de développement, ils pourront déployer leurs services dans un espace de noms spécial.
Il s'agit d'une approche de travail, Tiller n'est pas si gourmand que cela pourrait affecter considérablement votre budget. C'est l'une des solutions rapides.
N'hésitez pas à configurer Tiller séparément et à fournir à Kubeconfig un contexte pour l'équipe, pour un développeur spécifique ou pour l'environnement: Dev, Staging, Production (il est douteux que tout soit sur le même cluster, cependant, cela peut être fait).
Poursuivant notre histoire, passez de RBAC et parlez de ConfigMaps.
Cartes de configuration
Helm utilise ConfigMaps comme entrepôt de données. Lorsque nous avons parlé d'architecture, il n'y avait nulle part une base de données dans laquelle étaient stockées les informations sur les versions, les configurations, les annulations, etc. Pour cela, ConfigMaps est utilisé.
Le principal problème avec ConfigMaps est connu - ils ne sont pas sûrs en principe, il est
impossible d'y stocker des données sensibles . Nous parlons de tout ce qui ne doit pas aller au-delà du service, par exemple les mots de passe. Le moyen le plus natif pour Helm est maintenant de passer de l'utilisation de ConfigMaps aux secrets.
Cela se fait très simplement. Redéfinissez le paramètre Tiller et spécifiez que le stockage sera secret. Ensuite, pour chaque déploiement, vous ne recevrez pas ConfigMap, mais un secret.
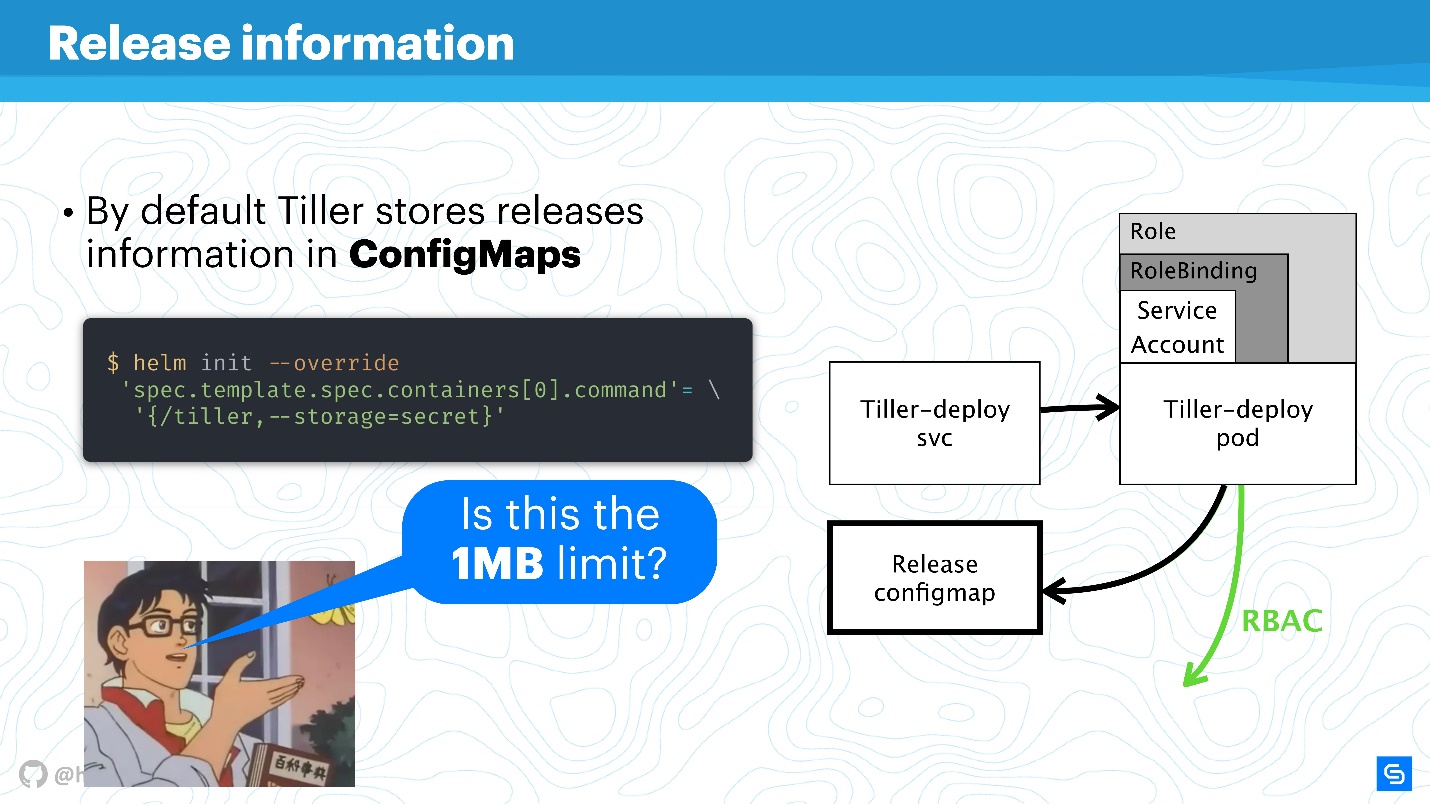
Vous pouvez affirmer que les secrets eux-mêmes sont un concept étrange et qu'il n'est pas très sûr. Cependant, il vaut la peine de comprendre que les développeurs de Kubernetes le font. À partir de la version 1.10, c'est-à-dire il y a assez longtemps, il y a la possibilité, au moins dans les clouds publics, de connecter le stockage correct pour stocker les secrets. Maintenant, l'équipe travaille sur une meilleure distribution de l'accès aux secrets, aux soumissions individuelles ou à d'autres entités.
Il est préférable de traduire Helm de stockage en secrets, et ceux-ci, à leur tour, sont sécurisés de manière centralisée.
Bien sûr, il restera une
limite de stockage de données de 1 Mo. Ici, Helm utilise etcd comme référentiel distribué pour ConfigMaps. Et là, ils pensaient que c'était un bloc de données approprié pour les réplications, etc. Il y a une discussion intéressante sur Reddit à ce sujet, je recommande de trouver ce sujet de lecture amusant pour le week-end ou de lire le squeeze
ici .
Dépôt de graphique
Les graphiques sont les plus vulnérables socialement et peuvent devenir la source de "l'homme au milieu", surtout si vous utilisez la solution de stock. Tout d'abord, nous parlons de référentiels qui sont exposés via HTTP.
Certainement, vous devez exposer Helm Repo via HTTPS - c'est la meilleure option et peu coûteuse.
Faites attention au
mécanisme de signature des graphiques . La technologie est simple à déshonorer. C'est la même chose que vous utilisez sur GitHub, la machine PGP habituelle avec des clés publiques et privées. Installez-vous et assurez-vous d'avoir les clés nécessaires et de tout signer, c'est vraiment votre charte.
De plus, le
client Helm prend en charge TLS (pas dans le sens de HTTP côté serveur, mais TLS mutuel). Vous pouvez utiliser des clés de serveur et de client pour communiquer. Franchement, je n'utilise pas un tel mécanisme en raison de l'aversion pour les certificats mutuels. En principe,
chartmuseum - le principal outil d'exposition Helm Repo pour Helm 2 - prend également en charge l'authentification de base. Vous pouvez utiliser l'authentification de base si elle est plus pratique et plus calme.
Il existe également un
plugin helm-gcs qui vous permet d'héberger des dépôts de graphiques sur Google Cloud Storage. C'est assez pratique, fonctionne très bien et est assez sûr, car tous les mécanismes décrits sont utilisés.
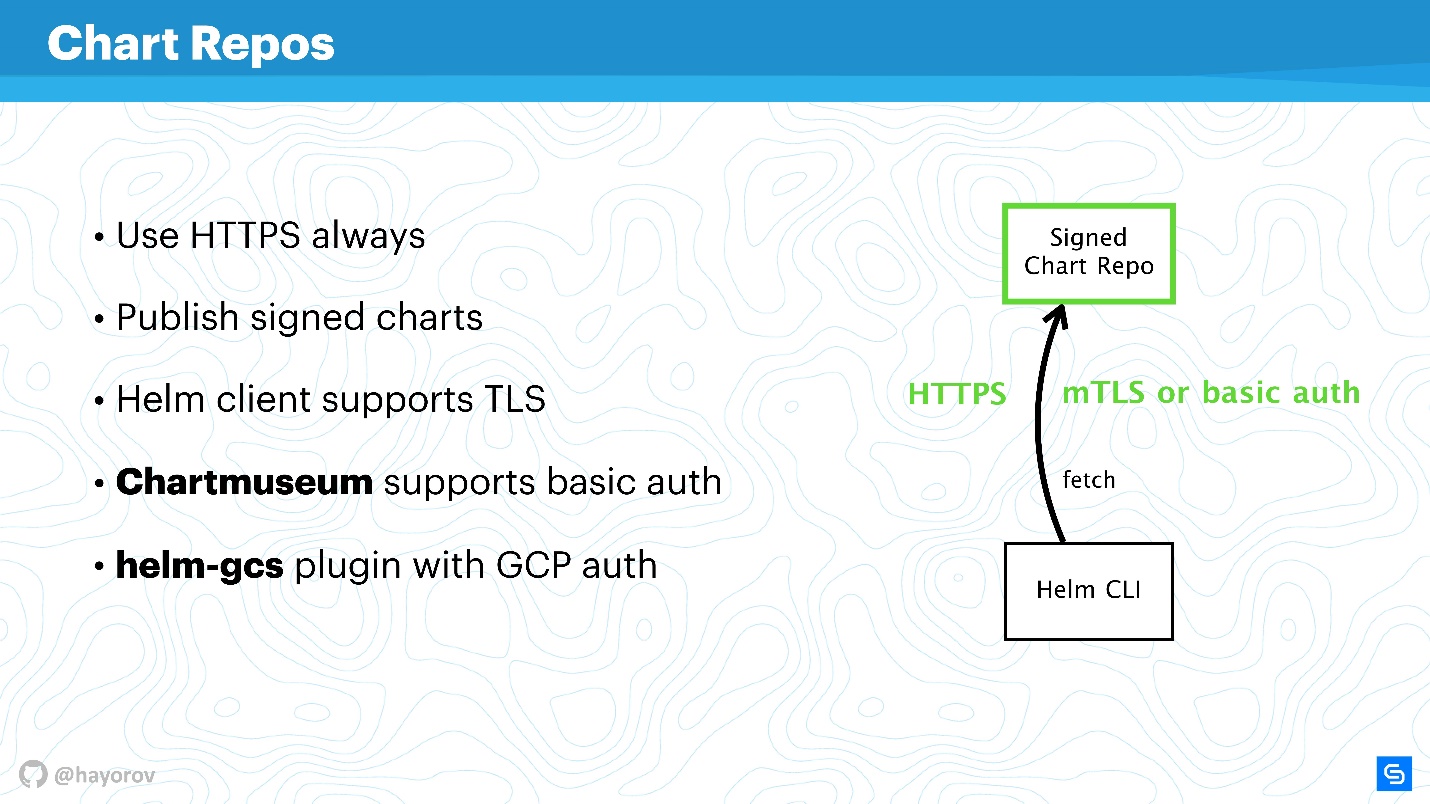
Si vous activez HTTPS ou TLS, utilisez mTLS, connectez l'authentification de base pour réduire davantage les risques, vous obtiendrez un canal de communication sécurisé Helm CLI et Chart Repo.
API gRPC
L'étape suivante est très responsable: sécuriser Tiller, qui est dans le cluster et est, d'une part, le serveur, d'autre part, il accède aux autres composants et essaie de se présenter comme quelqu'un.
Comme je l'ai dit, Tiller est un service qui expose gRPC, un client Helm y arrive via gRPC. Par défaut, bien sûr, TLS est désactivé. Pourquoi cela se fait est une question discutable, il me semble simplifier la configuration au départ.
Pour la production et même pour la mise en scène, je recommande d'activer TLS sur gRPC.
À mon avis, contrairement à mTLS pour les graphiques, cela est approprié ici et se fait très simplement - générer une infrastructure PQI, créer un certificat, lancer Tiller, transférer le certificat lors de l'initialisation. Après cela, vous pouvez exécuter toutes les commandes Helm, apparaissant comme un certificat généré et une clé privée.
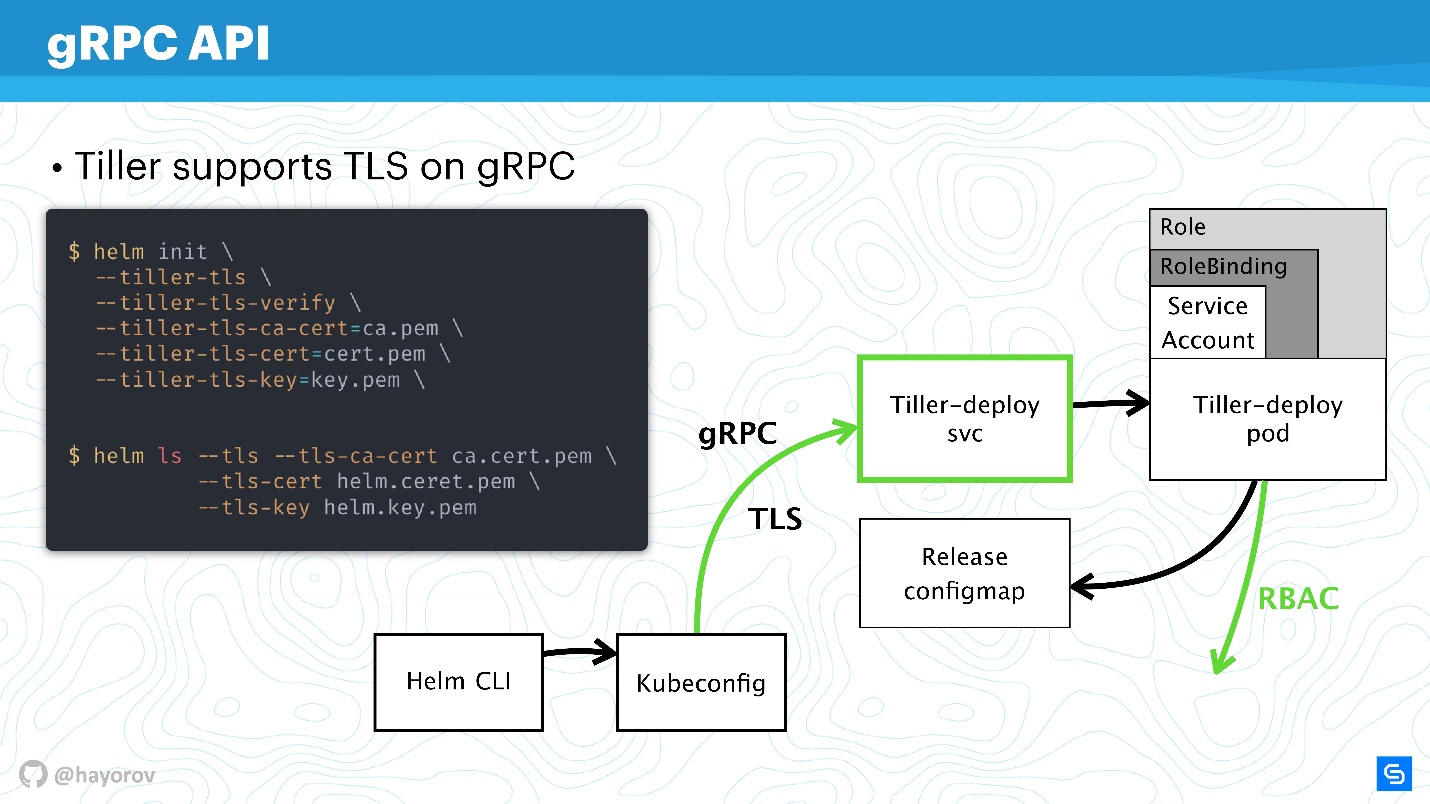
Ainsi, vous vous protégerez de toutes les demandes adressées à Tiller depuis l'extérieur du cluster.
Nous avons donc sécurisé le canal de connexion à Tiller, déjà discuté de RBAC et ajusté les droits de Kubernetes apiserver, réduit le domaine avec lequel il peut interagir.
Heaume protégé
Regardons le diagramme final. Il s'agit de la même architecture avec les mêmes flèches.
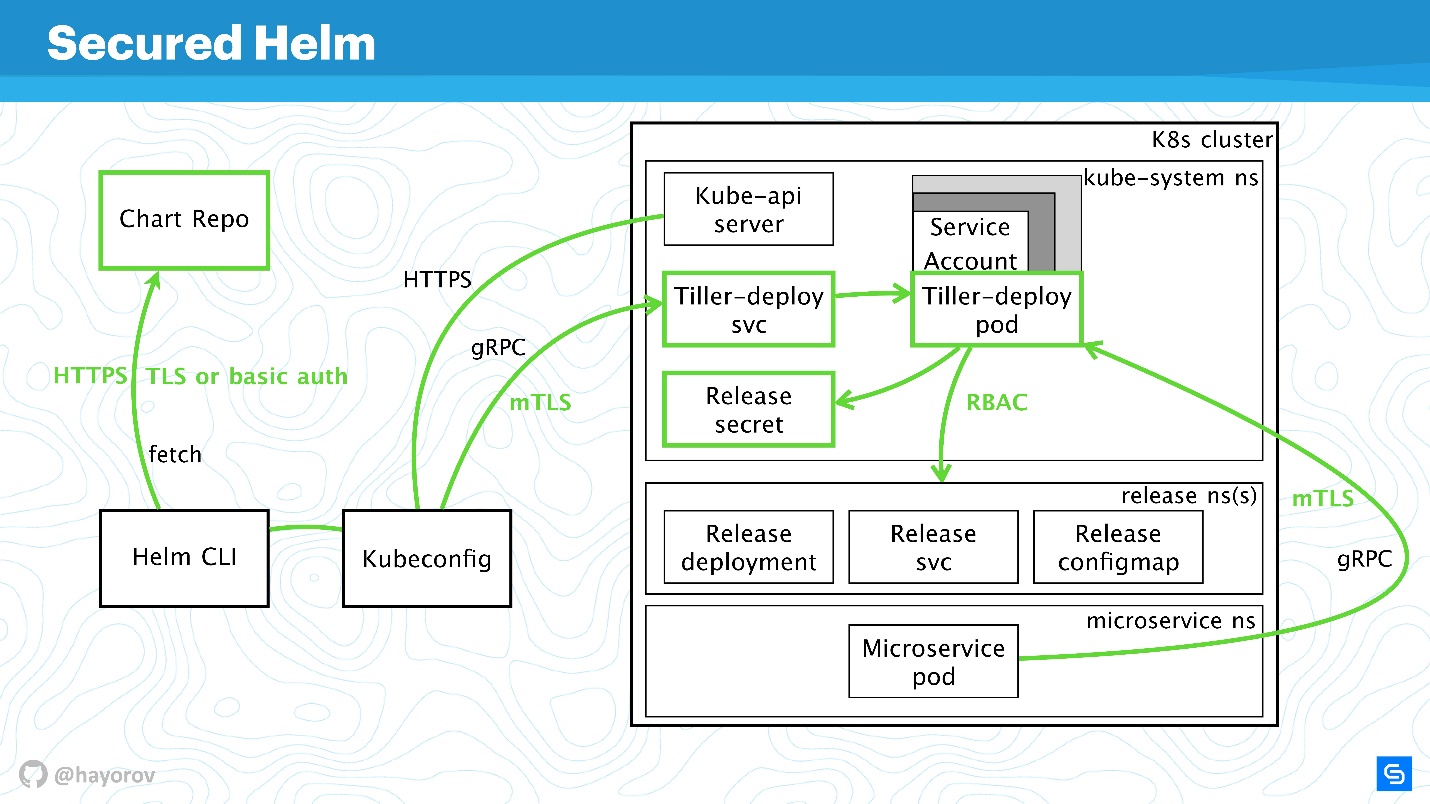
Toutes les connexions peuvent désormais être peintes en vert en toute sécurité:
- pour Chart Repo, nous utilisons TLS ou mTLS et l'authentification de base;
- mTLS pour Tiller, et il est présenté comme un service gRPC avec TLS, nous utilisons des certificats;
- le cluster utilise un compte de service spécial avec Role et RoleBinding.
Nous avons nettement sécurisé le cluster, mais quelqu'un d'intelligent a déclaré:
"Il ne peut y avoir qu'une seule solution absolument sûre - l'ordinateur est éteint, qui est dans une boîte en béton et il est gardé par des soldats."
Il existe différentes façons de manipuler les données et de trouver de nouveaux vecteurs d'attaque. Cependant, je suis convaincu que ces recommandations permettront la mise en œuvre d'une norme de sécurité industrielle de base.
Bonus
Cette partie n'est pas directement liée à la sécurité, mais elle sera également utile. Je vais vous montrer des choses intéressantes que peu de gens connaissent. Par exemple, comment rechercher des graphiques - officiels et non officiels.
Le référentiel
github.com/helm/charts compte désormais environ 300 graphiques et deux flux: stable et incubateur. Le contributeur sait combien il est difficile de passer de l'incubateur à l'écurie et combien il est facile de sortir de l'écurie. Cependant, ce n'est pas le meilleur outil pour rechercher des graphiques pour Prometheus et tout ce que vous aimez pour une raison simple n'est pas un portail où il est pratique de rechercher des packages.
Mais il existe un service
hub.helm.sh avec lequel il est beaucoup plus pratique de trouver des graphiques. Plus important encore, il existe de nombreux autres référentiels externes et près de 800 caractères sont disponibles. De plus, vous pouvez connecter votre référentiel si, pour une raison quelconque, vous ne souhaitez pas envoyer vos graphiques à stable.
Essayez hub.helm.sh et développons-le ensemble. Ce service est dans le cadre du projet Helm, et vous pouvez même contribuer à son interface utilisateur si vous êtes un fournisseur frontal et que vous souhaitez simplement améliorer l'apparence.
Je souhaite également attirer votre attention sur l'
intégration de l'API Open Service Broker . Cela semble lourd et incompréhensible, mais cela résout les problèmes auxquels tout le monde est confronté. Je vais vous expliquer avec un exemple simple.
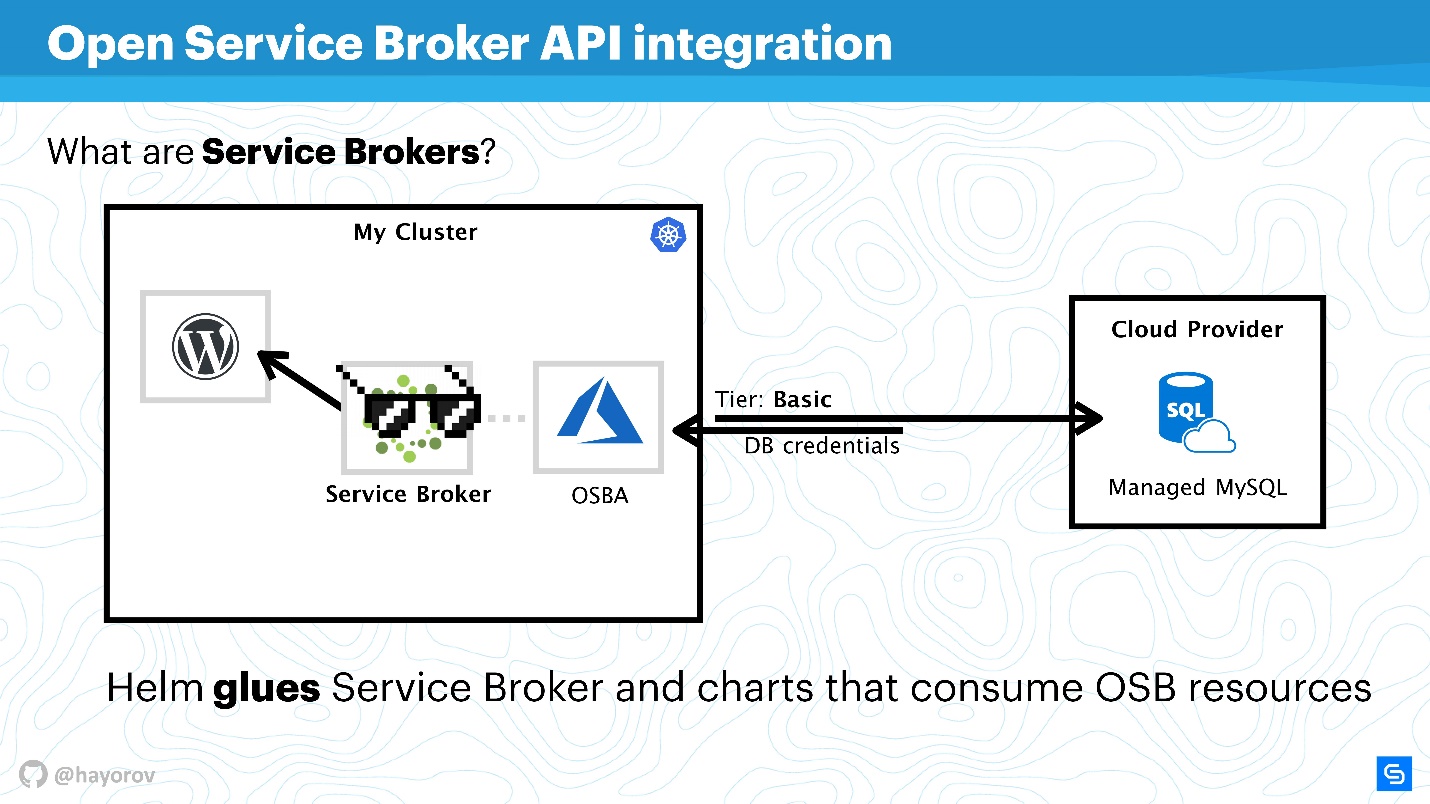
Il existe un cluster Kubernetes dans lequel nous voulons exécuter l'application classique - WordPress. En règle générale, une base de données est nécessaire pour une fonctionnalité complète. Il existe de nombreuses solutions différentes, par exemple, vous pouvez démarrer votre service complet. Ce n'est pas très pratique, mais beaucoup le font.
D'autres, comme nous à Chainstack, utilisent des bases de données gérées, telles que MySQL ou PostgreSQL, pour les serveurs. Par conséquent, nos bases de données sont situées quelque part dans le cloud.
Mais un problème se pose: vous devez connecter notre service à la base de données, créer une base de données de saveurs, transmettre les informations d'identification et les gérer d'une manière ou d'une autre. Tout cela est généralement effectué manuellement par l'administrateur système ou le développeur. Et il n'y a pas de problème quand il y a peu d'applications. Lorsqu'il y en a beaucoup, vous avez besoin d'une moissonneuse-batteuse. Il existe une telle combinaison - c'est Service Broker. Il vous permet d'utiliser un plug-in spécial pour le cluster de cloud public et de commander des ressources auprès du fournisseur via Broker, comme s'il s'agissait d'une API. Pour cela, vous pouvez utiliser les outils natifs de Kubernetes.
C'est très simple. Vous pouvez interroger, par exemple, MySQL géré dans Azure avec un niveau de base (cela peut être personnalisé). À l'aide de l'API Azure, la base sera créée et préparée pour l'utilisation. Vous n'avez pas besoin d'interférer avec cela, le plugin en est responsable. Par exemple, OSBA (plug-in Azure) renverra les informations d'identification au service, les transmettra à Helm. Vous pouvez utiliser WordPress avec MySQL nuageux, ne pas traiter du tout avec les bases de données gérées et ne vous inquiétez pas des services d'État à l'intérieur.
Nous pouvons dire que Helm agit comme une colle, qui d'une part vous permet de déployer des services, et d'autre part, il consomme les ressources des fournisseurs de cloud.
Vous pouvez écrire votre propre plugin et utiliser toute cette histoire sur site. Ensuite, vous avez juste votre propre plugin pour le fournisseur de cloud d'entreprise. Je vous conseille d'essayer cette approche, surtout si vous avez une grande échelle et que vous souhaitez déployer rapidement le développement, la mise en scène ou toute l'infrastructure pour une fonctionnalité. Cela facilitera la vie de vos opérations ou DevOps.
Une autre découverte que j'ai déjà mentionnée est le
plugin helm-gcs , qui vous permet d'utiliser Google-buckets (stockage d'objets) pour stocker des graphiques Helm.

Il ne faut que quatre commandes pour commencer à l'utiliser:
- installez le plugin;
- l'initier;
- définissez le chemin vers bucket, qui se trouve dans gcp;
- publier des graphiques de manière standard.
La beauté est que la méthode native de gcp pour l'autorisation sera utilisée. Vous pouvez utiliser un compte de service, un compte de développeur - n'importe quoi. Il est très pratique et ne coûte rien à utiliser. Si vous, comme moi, défendez la philosophie opsless, cela sera très pratique, surtout pour les petites équipes.
Alternatives
Helm n'est pas la seule solution de gestion de services. Il y a beaucoup de questions à lui poser, c'est probablement pourquoi la troisième version est apparue si rapidement. Bien sûr, il existe des alternatives.
Il peut s'agir de solutions spécialisées, par exemple, Ksonnet ou Metaparticle. Vous pouvez utiliser vos outils de gestion d'infrastructure classiques (Ansible, Terraform, Chef, etc.) aux mêmes fins que celles dont j'ai parlé.
Enfin, la solution
Operator Framework , dont la popularité ne cesse de croître.
L'opérateur Framework est la principale alternative de Helm à laquelle vous devez faire attention.
Il est plus natif pour CNCF et Kubernetes,
mais le seuil d'entrée est beaucoup plus élevé , vous devez programmer plus et décrire moins les manifestes.
Il existe différents addons, tels que Draft, Scaffold. Ils simplifient considérablement la vie, par exemple, les développeurs simplifient le cycle d'envoi et de lancement de Helm pour déployer un environnement de test. Je les appellerais des prolongateurs d'opportunités.
Voici un graphique visuel de l'emplacement de ce qui se trouve.
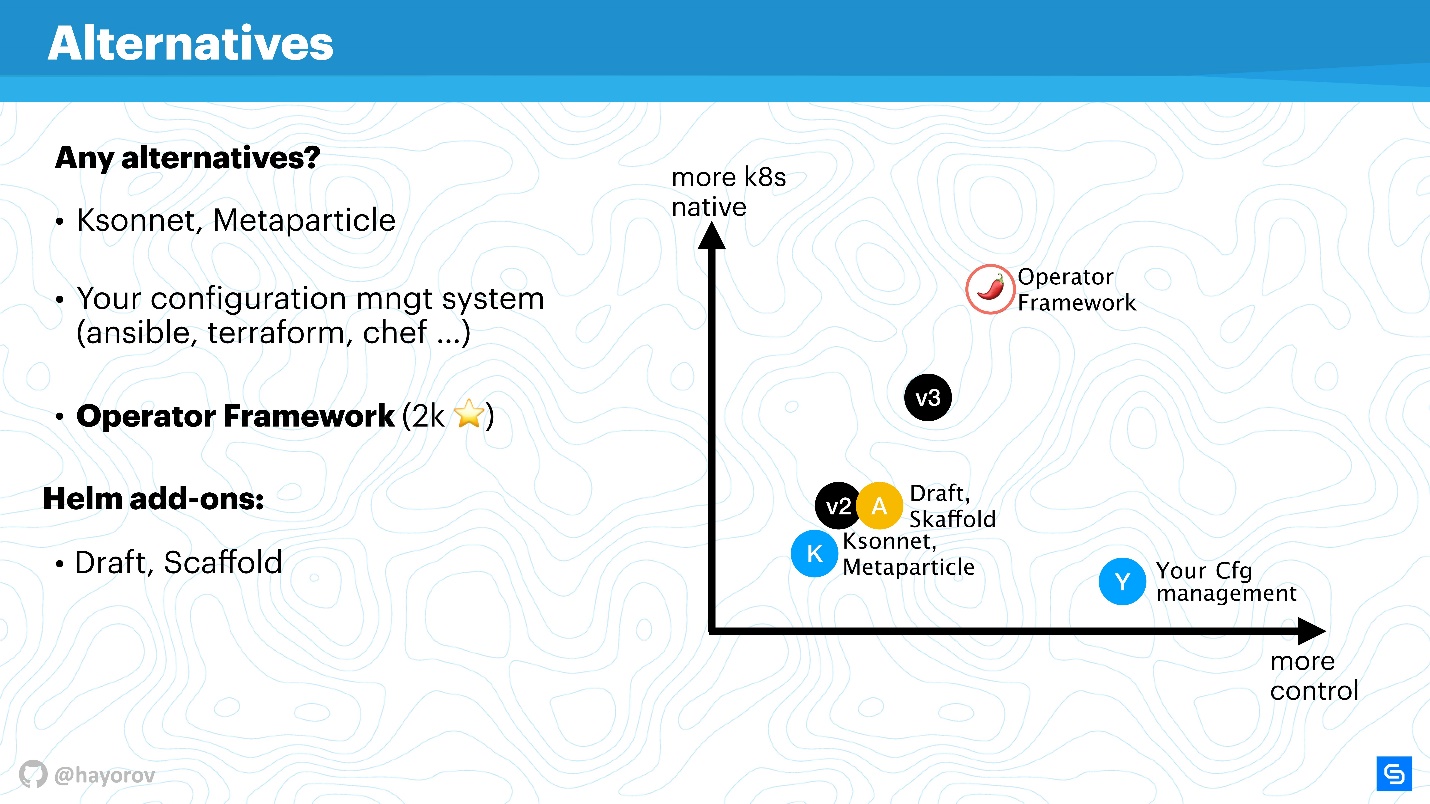
Sur l'axe des x, le niveau de votre contrôle personnel sur ce qui se passe, sur l'axe des y, le niveau de nativité de Kubernetes. La version 2 de Helm se situe quelque part au milieu. Dans la version 3, ce n'est pas colossal, mais le contrôle et le niveau de nativité sont améliorés. Les solutions de niveau Ksonnet sont encore inférieures même à Helm 2. Cependant, elles valent le coup d'œil pour savoir ce qu'il y a d'autre dans ce monde. Bien sûr, votre gestionnaire de configuration sera sous votre contrôle, mais absolument pas natif de Kubernetes.
L'opérateur Framework est absolument natif de Kubernetes et vous permet de le gérer de manière beaucoup plus élégante et méticuleuse (mais n'oubliez pas le niveau d'entrée). Au lieu de cela, il convient à une application spécialisée et à la création d'une gestion, plutôt qu'à une récolteuse de masse pour emballer un grand nombre d'applications à l'aide de Helm.
Les extensions améliorent simplement un peu le contrôle, complètent le flux de travail ou coupent les coins des pipelines CI / CD.
L'avenir de Helm
La bonne nouvelle est que Helm 3 est en train d'apparaître. La version alpha de Helm 3.0.0-alpha.2 est déjà sortie, vous pouvez essayer. Il est assez stable, mais la fonctionnalité est encore limitée.
Pourquoi avez-vous besoin de Helm 3? Tout d'abord, c'est l'histoire de la
disparition de Tiller , en tant que composant. Comme vous le savez déjà, c'est un grand pas en avant, car tout est simplifié du point de vue de la sécurité architecturale.
Lorsque Helm 2 a été créé, ce qui était pendant Kubernetes 1.8 ou même plus tôt, de nombreux concepts étaient immatures. Par exemple, le concept de CRD est activement mis en œuvre et Helm
utilisera CRD pour stocker les structures. Il sera possible d'utiliser uniquement le client et de ne pas garder le côté serveur. Par conséquent, utilisez les commandes natives de Kubernetes pour travailler avec les structures et les ressources. C'est un énorme pas en avant.
La prise en charge des référentiels OCI natifs (Open Container Initiative) apparaîtra. Il s'agit d'une énorme initiative, et Helm est surtout intéressant pour publier ses graphiques. Il arrive au point que, par exemple, le Docker Hub prend en charge de nombreuses normes OCI. Je ne me demande pas, mais peut-être que les fournisseurs classiques de référentiels Docker commenceront à vous donner la possibilité de placer leurs graphiques Helm pour vous.
Une histoire controversée pour moi est
le soutien de Lua en tant que moteur de création de modèles pour l'écriture de scripts. Je ne suis pas un grand fan de Lua, mais ce sera une fonctionnalité complètement facultative. Je l'ai vérifié 3 fois - l'utilisation de Lua ne sera pas nécessaire. Par conséquent, toute personne qui veut pouvoir utiliser Lua, quelqu'un qui aime Go, rejoignez notre immense camp et utilisez go-tmpl pour cela.
, —
. int string, . JSONS-, values.
event-driven model . . Helm 3, , , , , .
Helm 3 , , Helm 2, Kubernetes . , Helm Kubernetes Kubernetes.
Une autre bonne nouvelle est qu'à la DevOpsConf, Alexander Khayorov vous dira si les conteneurs peuvent être sûrs? Rappel, une conférence sur l'intégration des processus de développement, de test et d'exploitation se tiendra à Moscou les 30 septembre et 1er octobre . Jusqu'au 20 août, vous pouvez toujours soumettre un rapport et parler de votre expérience dans la résolution de l' une des nombreuses tâches de l'approche DevOps.
Suivez les points de contrôle et les actualités de la conférence dans la newsletter et la chaîne de télégrammes .