
Lorsque vous écoutez toute la journée pour des entretiens techniques, vous commencez à remarquer des tendances. Au contraire, dans notre cas, leur absence. J'ai réussi à trouver seulement deux choses qui restent inchangées. J'ai même imaginé un jeu alcoolique basé sur eux: chaque fois que quelqu'un décide que la réponse à la question est une table de hachage, nous buvons une pile, si la bonne réponse est vraiment une table de hachage, nous en buvons deux. Mais je ne conseille pas d'y jouer, j'ai failli mourir.
Pourquoi j'écoute des interviews toute la journée? Parce qu'il y a quelques années, je suis devenu l'un des créateurs du service
interviewing.io , une plateforme d'
interview où les gens de la sphère informatique peuvent développer des compétences de communication avec l'employeur et trouver un emploi entre les emplois.
En conséquence, j'ai accès à une grande quantité de données sur la façon dont le même utilisateur se montre lors de différentes interviews. Et ils s'avèrent si imprévisibles que vous penserez inévitablement à quel point les résultats d'une seule réunion sont généralement indicatifs.
Comment obtenons-nous les données
Lorsque l'utilisateur qui mène l'entretien et l'utilisateur à la recherche d'un emploi se rencontrent, ils se rencontrent dans un éditeur de code commun. Là, la capacité de communiquer par la voix et par le biais de messages texte est connectée, il y a un analogue d'un tableau de bord pour enregistrer les décisions - vous pouvez immédiatement commencer des problèmes techniques.
Les questions posées lors de nos entretiens sont généralement de la catégorie de celles posées lors de l'entretien téléphonique aux candidats au poste de développeur de logiciels backend. Les utilisateurs effectuant des entretiens sont généralement des employés de grandes entreprises (Google, Facebook, Yelp) ou des représentants de startups à fort biais technique (Asana, Mattermark, KeepSafe et autres). À la fin de chaque réunion, les employeurs évaluent les candidats selon plusieurs critères, dont l'un est la compétence en programmation. Les notes sont mises sur une échelle de un («so-so») à quatre («great!»). Sur notre plateforme, des notes de trois et plus signifient dans la plupart des cas que le candidat est suffisamment fort pour passer à l'étape suivante.
Ici, vous pouvez dire: «Tout cela est merveilleux, mais quelle est la particularité ici? De nombreuses entreprises collectent de telles statistiques lors du processus de sélection. » Nos données diffèrent de ces statistiques sur un point: un même utilisateur peut participer à plusieurs entretiens, chacun avec un nouvel employé de la nouvelle entreprise. Cela ouvre des opportunités pour une analyse comparative très intéressante dans un environnement plus ou moins stable.
Conclusion # 1: Les résultats varient considérablement d'une interview à l'autre
Commençons par quelques photos. Dans le graphique ci-dessous, chaque icône en forme de petit homme montre la note individuelle moyenne de l'un des utilisateurs ayant participé à deux ou plusieurs entretiens. L'un des paramètres qui n'est pas affiché sur ce graphique est la période de temps.
Vous pouvez voir comment les succès des gens changent au fil du temps, ici. Il y a quelque chose dans l'esprit du chaos primitif.
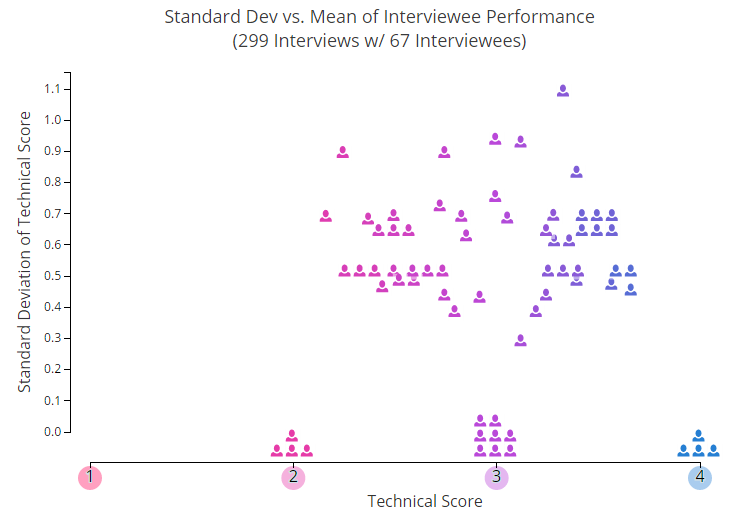
L'axe des Y montre un écart typique des valeurs moyennes - en conséquence, plus nous montons, plus les résultats des entretiens sont imprévisibles. Comme vous pouvez le voir, environ 25% des participants sont maintenus de manière stable au même niveau, tandis que les autres sautent tous de haut en bas.
Après avoir soigneusement étudié ce calendrier, vous, malgré une pile de données, seriez probablement en mesure de déterminer approximativement lequel des utilisateurs vous souhaitez inviter pour une interview. Mais ici, il est important de se rappeler: nous avons pris des valeurs moyennes. Imaginez maintenant que vous devez prendre une décision basée sur une seule évaluation, qui a été utilisée pour le calculer. C'est là que les problèmes commencent.
Pour plus de clarté, vous pouvez ouvrir une
version interactive morte du graphique . Là, chaque icône s'ouvre lorsque vous survolez et vous pouvez voir quelle note l'utilisateur a reçue à chacune des interviews. Les résultats peuvent vous surprendre grandement! Eh bien, par exemple:
- La part du lion de ceux qui en ont au moins un quatre se sont retrouvés au moins une fois dans le «double»
- Même si vous ne sélectionnez que les candidats les plus forts (le score moyen est de 3,3 et plus), les résultats fluctuent toujours de manière significative
- La "moyenne" (score moyen - de 2,6 à 3,3), les résultats sont particulièrement contradictoires
Nous nous sommes demandé s'il y avait une relation entre le niveau du candidat et l'amplitude des vibrations. En d'autres termes, peut-être pour les plus faibles, il y a des sauts pointus caractéristiques, tandis que les programmeurs puissants sont stables? En fait, non. Lorsque nous avons effectué une analyse de régression d'un écart typique par rapport à l'estimation moyenne, nous n'avons pu établir aucune relation significative (R au carré était d'environ 0,03). Et cela signifie que les gens obtiennent des notes différentes, quel que soit leur niveau général.
Je dirais ceci: lorsque vous regardez toutes ces données, puis imaginez que vous devez choisir une personne en fonction des résultats d'une entrevue, vous avez l'impression de regarder une belle pièce luxueusement meublée à travers un trou de serrure. Dans un cas, vous avez la chance de voir une photo sur le mur, dans un autre - une collection de vins, et dans le troisième - vous vous enfouirez dans le mur arrière du canapé.
Dans des situations réelles, lorsque nous essayons de décider d'appeler un candidat pour un entretien au bureau, nous essayons généralement d'éviter les erreurs du premier type (c'est-à-dire, ne pas sélectionner au hasard ceux qui sont en deçà de la barre) et les erreurs du deuxième type (c'est-à-dire, ne pas refuser ceux qui Cela vaut la peine d'être invité). Les leaders du marché élaborent généralement une stratégie basée sur le fait que les erreurs du deuxième type font moins de mal. Cela semble logique, non? S'il y a suffisamment de ressources et que le nombre de candidats est important, même avec un grand nombre d'erreurs du deuxième type, il y aura toujours quelqu'un de approprié.
Mais cette stratégie de commettre des erreurs du second type a un côté caché, et maintenant elle se fait sentir, se répandant dans la crise actuelle des embauches dans le domaine informatique. Les entretiens individuels dans leur forme actuelle fournissent-ils suffisamment d'informations? Sommes-nous en train de rejeter, malgré la demande accrue de développeurs talentueux, des travailleurs compétents simplement parce que nous essayons d'envisager un calendrier complet avec de fortes différences à travers un minuscule judas?
Donc, si nous ignorons les métaphores et la lecture morale: étant donné que les résultats des entretiens sont si imprévisibles, quelle est la probabilité qu'un candidat fort échoue dans un entretien téléphonique?
Conclusion n ° 2: la probabilité d'échec à l'entretien sur la base des résultats des tentatives passées
Vous trouverez ci-dessous la répartition en pourcentage de l'ensemble de la base de nos utilisateurs selon les estimations moyennes.
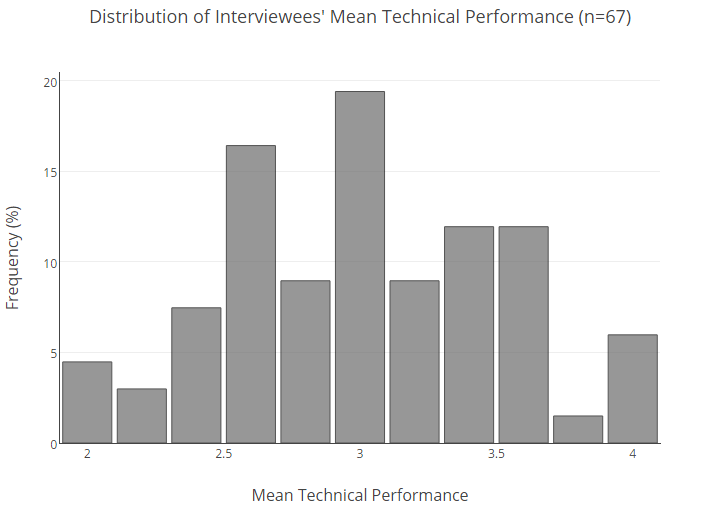
Pour comprendre la probabilité qu'un candidat avec un certain résultat moyen ne se montre pas bien dans une interview, nous avons dû faire des statistiques.
Premièrement, nous avons divisé les personnes interrogées en groupes sur la base des notes moyennes (tandis que les valeurs ont été arrondies à 0,25). Ensuite, pour chaque groupe, la probabilité d'échec a été calculée, c'est-à-dire l'obtention d'un score de 2 ou moins. De plus, pour compenser la quantité modeste de données, nous avons
rééchantillonné .
Lors de la compilation du rééchantillonnage, nous avons considéré le résultat d'une future entrevue comme une distribution multi-nominale. En d'autres termes, nous avons présenté que ses résultats sont déterminés par le lancer d'un dé à quatre faces, et pour chaque groupe, le centre de gravité du cube est décalé d'une certaine manière.
Ensuite, nous avons commencé à lancer ces dés jusqu'à ce que nous ayons créé un nouvel ensemble de données simulées pour chaque groupe. De nouvelles probabilités de défaillance pour les utilisateurs ayant des estimations différentes ont été calculées sur la base de ces données. Ci-dessous, vous pouvez voir le graphique que nous avons reçu après 10 000 lancers.
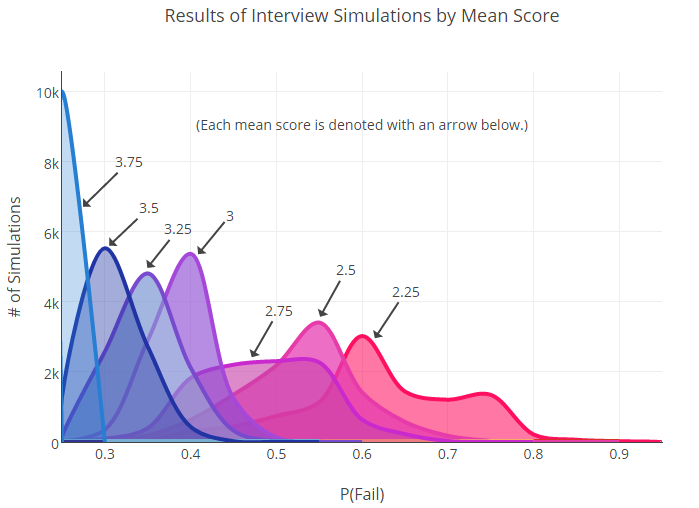
Comme vous pouvez le voir, il existe de nombreuses intersections. Ceci est important: le fait de se chevaucher nous indique qu'il peut n'y avoir aucune différence statistiquement significative entre certains groupes (par exemple, 2,75 et 3).
Bien sûr, lorsque nous aurons plus de données (beaucoup plus), les frontières entre les groupes seront plus claires. D'un autre côté, le fait même qu'un énorme échantillon soit nécessaire pour trouver la différence entre les indicateurs de taux d'échec peut indiquer une variabilité initialement élevée des résultats pour l'utilisateur moyen.
En fin de compte, avec confiance, nous pouvons dire ce qui suit: la différence entre les points extrêmes de l'échelle (2,25 et 3,75) est significative, mais tout le reste est déjà beaucoup moins ambigu.
Néanmoins, sur la base de cette distribution, nous avons tenté de calculer la probabilité en pourcentage qu'un candidat avec l'une ou l'autre note moyenne affiche un mauvais résultat dans une seule entrevue:
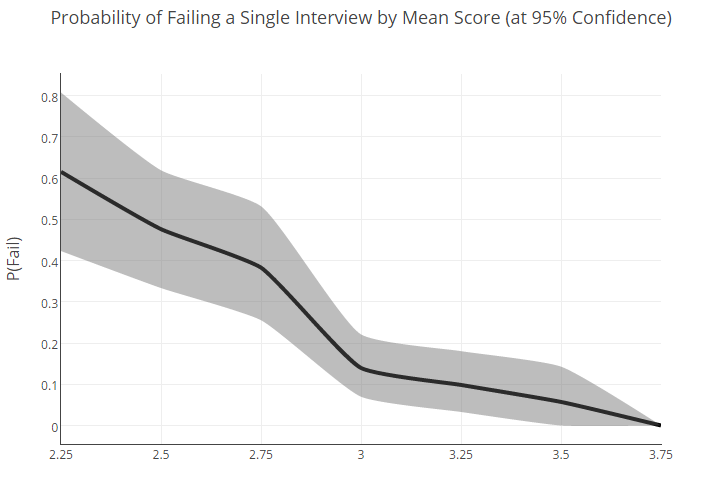
Le fait que les personnes ayant un bon niveau général (c'est-à-dire une note moyenne d'environ 3) puissent échouer avec une probabilité de 22% montre que les schémas de sélection que nous utilisons maintenant peuvent et doivent être améliorés. Des résultats brumeux pour la "moyenne" ne font que confirmer cette conclusion.
Alors, les interviews sont-elles condamnées?
En général, le mot «interviews» évoque dans nos esprits une image de quelque chose d’informatif et donnant des résultats reproductibles. Cependant, les données que nous avons collectées parlent de quelque chose de complètement différent. Et cela a autre chose en commun avec mon expérience personnelle d'embauche d'employés et avec les opinions que j'entends souvent dans la communauté.
L'article de Zack Holman,
Startup Interviewing is F *****, clarifie cet écart entre les motifs de sélection des candidats et le travail qu'ils doivent effectuer. Les honorables messieurs de TripleByte
sont arrivés à des conclusions similaires , après avoir traité leurs propres données. La plate-forme rejetée.us a récemment fourni des preuves éclatantes d'incohérence dans le processus d'entrevue.
On peut affirmer que beaucoup de ceux qui ont été éliminés après un entretien téléphonique avec l'entreprise A ont montré le meilleur résultat lors d'une autre entrevue, se sont retrouvés dans certaines des entreprises considérées comme décentes - et maintenant, six mois plus tard, ils reçoivent des offres pour parler de recruteurs de l'entreprise A. Et malgré tous les efforts des deux parties, ce processus de sélection brusque, imprévisible et, finalement, aléatoire des candidats se poursuit, comme dans un cercle magique.
Alors oui, bien sûr, l'une des conclusions qui peut être tirée est que les entretiens techniques sont dans une impasse; ils ne fournissent pas suffisamment d'informations fiables pour prédire le résultat d'un entretien individuel. Les entretiens avec des problèmes algorithmiques sont un sujet très chaud dans la communauté, et nous aimerions l'analyser en détail à l'avenir.
Il sera particulièrement intéressant de retracer la relation entre la réussite des candidats et le type d'entretien - nous avons de plus en plus d'approches et de variantes apparaissant sur notre plateforme. En fait, c'est l'un de nos objectifs à long terme: comment fouiller dans les données collectées, examiner l'éventail des stratégies de sélection des candidats actuels et tirer des conclusions sérieuses et fondées sur des données sur les formats d'entrevue qui fournissent les informations les plus utiles.
En attendant, je suis enclin à l'idée qu'il vaut mieux regarder à un niveau généralisé que de se laisser guider dans une décision importante par les résultats arbitraires d'une seule réunion. Les données généralisées nous permettent de faire une correction non seulement pour ceux qui dans un cas isolé ont répondu de manière inhabituellement faible, mais aussi pour ceux qui ont laissé une bonne impression purement par hasard ou ont finalement incliné la tête devant ce monstre et mémorisé Cracking the Coding Interview.
Je comprends qu'il n'est pas toujours pratique ni même possible pour une entreprise de recueillir d'autres preuves de compétences de candidats quelque part dans la nature. Mais si, par exemple, un cas limite ou une personne ne se montre pas du tout comme vous vous y attendiez, il est probablement judicieux de lui parler à nouveau et de passer à un autre sujet avant de prendre une décision finale.