L'autre jour, le Meetup # 66 de Moscou Python a eu lieu - la communauté continue de discuter des outils pertinents qui améliorent le langage et l'adaptent à différents environnements. Y compris à la réunion, mon rapport a été fait. Je m'appelle Nail, je fais Yandex.Connect.

L'histoire que j'ai préparée concernait uWSGI. Il s'agit d'un serveur d'applications Web multifonctionnel, et chaque application moderne est accompagnée de métriques. J'ai essayé de montrer comment les capacités de uWSGI peuvent aider à collecter des métriques.
- Bonjour à tous, je suis heureux de vous accueillir tous sur les murs de Yandex. C'est bien que tant de gens soient venus voir mes rapports et d'autres, que tant de gens soient intéressés et vivent en Python. Quel est mon rapport? Il est appelé "uWSGI pour aider les métriques". Je vais vous parler un peu de moi. Je fais du Python depuis six ans, je travaille dans l'équipe Yandex.Connect, nous écrivons une plateforme commerciale qui fournit des services Yandex développés en interne pour des utilisateurs externes, c'est-à-dire pour tout le monde. Toute personne ou organisation peut utiliser les produits développés par Yandex pour elle-même, à ses propres fins.
Nous parlerons des métriques, comment obtenir ces métriques, comment nous utilisons dans notre équipe uWSGI comme outil pour obtenir des métriques, comment cela nous aide. Ensuite, je vais vous raconter une petite histoire d'optimisation.
Quelques mots sur les métriques. Comme vous le savez, le développement d'une application moderne est impossible sans tests. Il est étrange que quelqu'un développe ses applications sans tests. En même temps, il me semble que le fonctionnement d'une application moderne est impossible sans métriques. Notre application est un organisme vivant. Une personne peut prendre certaines mesures, telles que la pression, la fréquence cardiaque, - l'application a également des indicateurs qui nous intéressent et que nous aimerions observer. Contrairement à une personne qui prend généralement ces mesures vitales lorsqu'elle se sent mal, dans le cas d'une application, nous pouvons toujours les prendre.

Pourquoi prenons-nous des mesures? Au fait, qui utilise les métriques? J'espère qu'après mon rapport, il y aura plus de mains, et que les gens seront intéressés et commenceront à collecter des métriques, ils comprendront que cela est nécessaire et utile.
Alors pourquoi avons-nous besoin de mesures? Tout d'abord, nous voyons ce qui se passe avec le système, nous mettons en évidence certains indicateurs normatifs pour notre système et comprenons si nous allons au-delà de ces indicateurs pendant le processus de candidature ou non. Vous pouvez voir un comportement anormal du système, par exemple, une augmentation du nombre d'erreurs, comprendre ce qui ne va pas avec le système, avant nos utilisateurs et recevoir des messages sur les incidents non pas des utilisateurs, mais du système de surveillance. Sur la base de mesures, nous pouvons configurer des alertes et recevoir des SMS, des lettres, des appels, comme vous le souhaitez.

Quelles sont, en règle générale, les mesures? Ce sont des chiffres, peut-être un compteur qui croît de façon monotone. Par exemple, le nombre de demandes. Certaines valeurs unitaires qui changent dans le temps augmentent ou diminuent. Un exemple est le nombre de tâches dans une file d'attente. Ou des histogrammes - des valeurs qui tombent dans certains intervalles, les soi-disant paniers. En règle générale, il est pratique de lire ces données temporelles et de savoir dans quel intervalle de temps le nombre de valeurs convient.

Quel type de mesures pouvons-nous prendre? Je vais me concentrer sur le développement d'applications web, car il est plus proche de moi. Par exemple, nous pouvons filmer le nombre de demandes, nos points de terminaison, le temps de réponse de nos points de terminaison, les codes de réponse des services associés, si nous y allons et que nous avons une architecture de microservice. Si nous utilisons le cache, nous pouvons comprendre l'efficacité du cache miss ou hit, comprendre la distribution des temps de réponse des deux serveurs tiers et, par exemple, de la base de données. Mais pour voir les métriques, vous devez en quelque sorte les collecter.

Comment pouvons-nous les collecter? Il existe plusieurs options. Je veux vous parler de la première option - un schéma push. En quoi cela consiste-t-il?
Supposons que nous recevions une demande d'un utilisateur. Localement, avec notre application, nous installons une sorte, généralement un agent push. Disons que nous avons un Docker, qu'il contient une application et qu'un agent push se tient toujours en parallèle. L'agent push reçoit localement la valeur des métriques, il les met en mémoire tampon, crée des lots et les envoie au système de stockage des métriques.
Quel est l'avantage d'utiliser des schémas push? Nous pouvons envoyer des métriques directement de l'application au système métrique, mais en même temps, nous obtenons une sorte d'interaction réseau, de latence, de surcharge pour collecter des métriques. Dans le cas d'un client push local, cela est nivelé.
Une autre option est un schéma de tirage. Avec le schéma de traction, nous avons le même scénario. Une demande de l'utilisateur nous parvient, nous la gardons en quelque sorte à la maison. Et puis avec une certaine fréquence - une fois par seconde, une fois par minute, comme cela vous convient - le système de collecte de métriques arrive à un point final spécial de notre application et prend ces indicateurs.

Une autre option est les journaux. Nous écrivons tous des journaux et les envoyons quelque part. Rien ne nous empêche de prendre ces journaux, de les traiter en quelque sorte et d'obtenir des mesures basées sur les journaux.
Par exemple, nous écrivons le fait de la demande d'un utilisateur dans le journal, puis nous prenons les journaux, hop-hop, comptés. Un exemple typique est ELK (Elasticsearch, Logstash, Kibana).

Comment ça marche avec nous? Yandex possède sa propre infrastructure, son propre système de collecte de métriques. Elle attend une réponse standardisée pour une poignée qui implémente un schéma de traction. De plus, nous avons un cloud interne où nous lançons notre application. Et tout cela est intégré dans un seul système. Lors du téléchargement vers le cloud, nous indiquons simplement: "Accédez à ce stylet et obtenez les statistiques."

Voici un exemple de réponse pour le schéma d'extraction que notre système de collecte métrique attend.
Pour nous-mêmes dans l'équipe, nous avons décidé de choisir une manière plus appropriée pour nous, de mettre en évidence plusieurs critères selon lesquels nous choisirons la meilleure option pour nous. L'efficacité est la rapidité avec laquelle nous pouvons obtenir dans le système métrique un affichage du fait de toute action. Dépendance - si nous devons installer des outils supplémentaires ou configurer l'infrastructure d'une manière ou d'une autre pour obtenir la métrique. Et la polyvalence - comment cette méthode est adaptée à différents types d'applications.
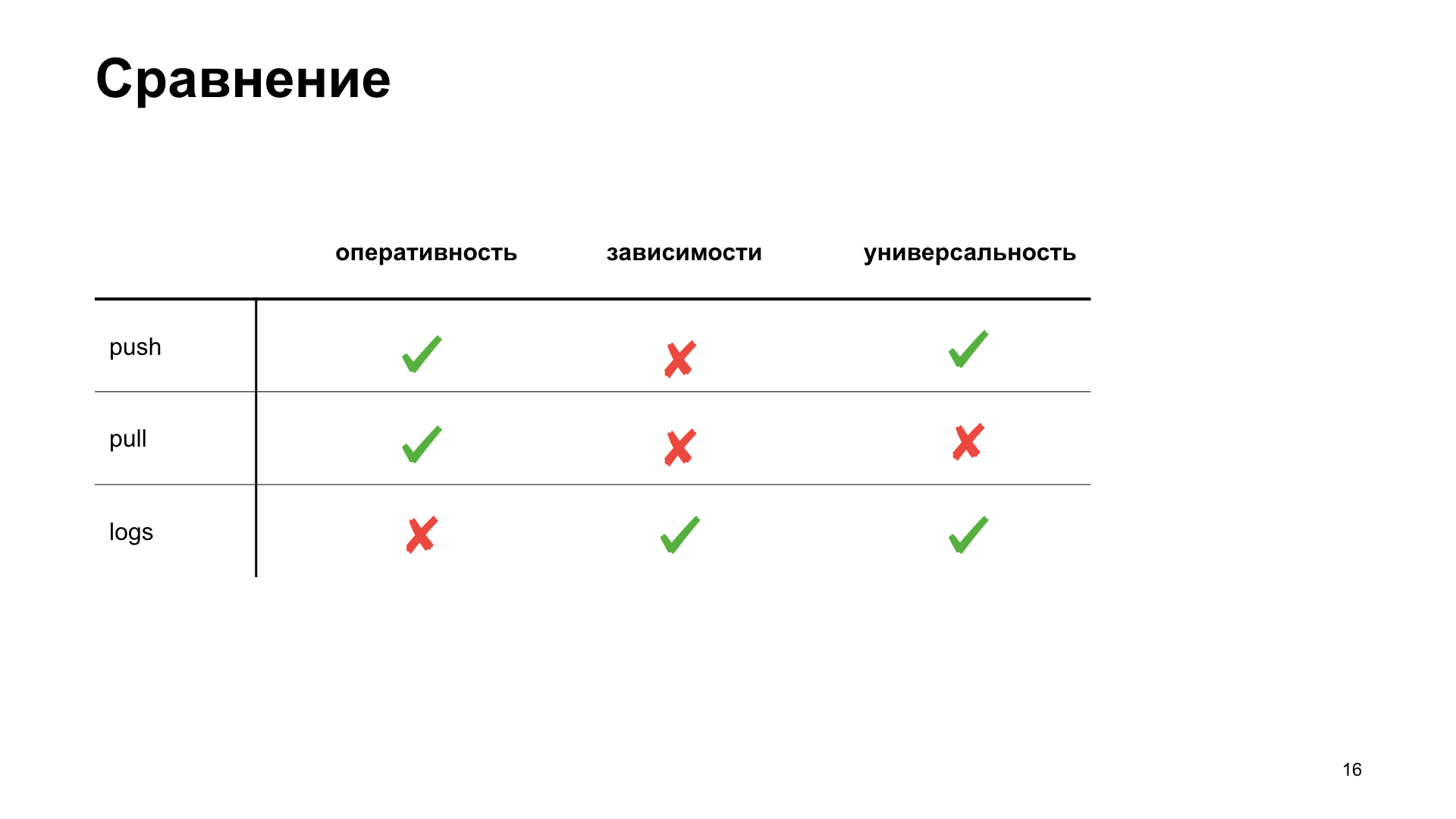
C'est ce que nous avons finalement obtenu. Bien que, selon les critères d'efficacité et de polyvalence, le schéma push gagnera. Mais nous développons une application Web, et notre cloud dispose déjà d'une infrastructure prête à l'emploi pour travailler avec cette tâche, nous avons donc décidé de choisir un schéma d'extraction pour nous-mêmes. Nous allons parler d'elle.
Afin de donner quelque chose au schéma de tirage, nous devons le pré-agréger quelque part, l'enregistrer. Notre système de surveillance entre dans des poignées de traction toutes les cinq secondes. Où pouvons-nous économiser? Localement dans votre mémoire ou dans un stockage tiers.

Si nous enregistrons localement, alors en règle générale, cela convient au cas avec un processus. Et nous, dans notre uWSGI, exécutons plusieurs processus en parallèle. Ou nous pouvons utiliser une sorte de stockage partagé. Qu'est-ce qui nous vient à l'esprit avec le mot «stockage partagé»? Il s'agit d'une sorte de bases de données Redis, Memcached, relationnelles ou non relationnelles, ou même d'un fichier.

À propos d'uWSGI. Permettez-moi de vous rappeler ceux qui l'utilisent peu ou rarement: uWSGI est un serveur Web d'applications qui vous permet d'exécuter des applications Python sous vous. Il implémente l'interface, le protocole uWSGI. Ce protocole est décrit dans PEP 333, qui sont intéressés, vous pouvez lire.

Cela nous aidera également à choisir la meilleure solution Yandex.Tank. Il s'agit d'un outil de test de charge qui vous permet de décortiquer notre application avec différents profils de charge et de créer de superbes graphismes. Ou cela fonctionne dans la console, comme vous le souhaitez.

Les expériences. Nous allons créer une application synthétique pour nos tests synthétiques, nous la bombarderons avec un réservoir. L'application uWSGI aura un conflit simple avec 10 travailleurs.

Voici notre application Flask. La charge utile que notre application effectue, nous émulerons une boucle vide.

Nous tirons et Yandex.Tank nous donne l'un de ces graphiques. Que montre-t-il? Centiles de temps de réponse. La ligne oblique est le RPS qui grandit, et les histogrammes sont les centiles dans lesquels notre serveur Web s'intègre sous une telle charge.
Nous prendrons cette option comme référence et examinerons comment les différentes options de stockage des métriques affectent les performances.

L'option la plus simple consiste à utiliser PostgreSQL. Parce que nous travaillons avec PostgreSQL, nous l'avons. Utilisons ce qui est déjà prêt.
Disons que nous avons une étiquette dans PostgreSQL dans laquelle nous incrémentons simplement le compteur.

Déjà sur de petites quantités de RPS, nous constatons une forte dégradation des performances. On peut dire juste énorme.

L'option suivante est Redis. Mais ici, nous faisons plus intelligemment: nous l'installons localement et nous y accédons non pas via le réseau, mais via le socket Unix. Augmentez également le compteur.
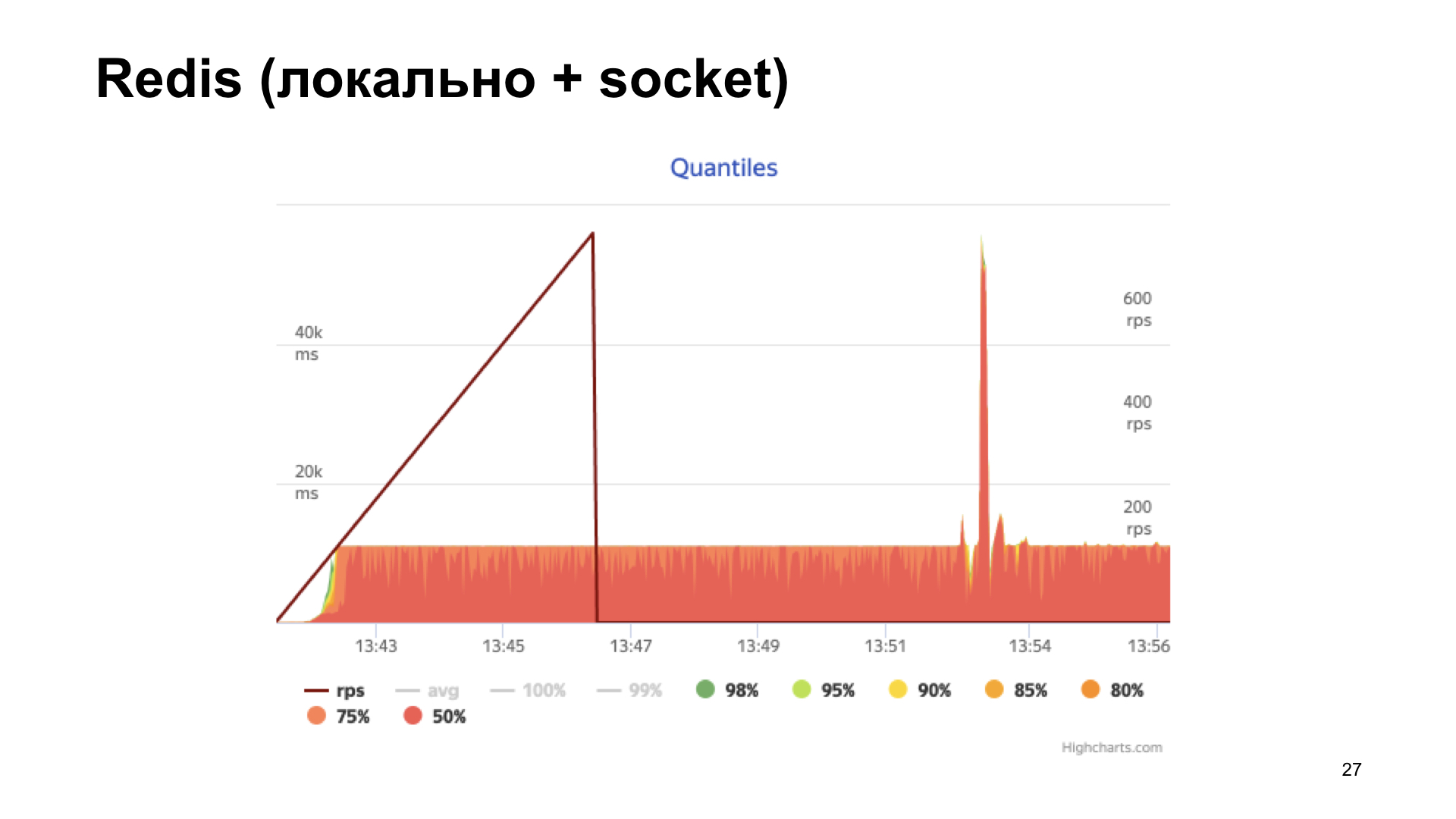
On obtient l'histogramme des temps de réponse en sortie. Nous voyons que les choses vont mieux ici, mais à un moment donné, nous nous heurtons à une étagère, puis la productivité n'augmente plus. Cette option semble plus optimale, mais nous voulons faire encore mieux.

Ici uWSGI, une véritable moissonneuse-batteuse, vient à notre secours. Il existe de nombreux modules différents. Mule pour exécuter les sous-processus, le cadre de mise en cache, le cron, le sous-système de métriques et le système d'alerte. «Système de mesure des sous-systèmes» - semble prometteur.

Elle sait comment ajouter une sorte de métrique, augmenter le compteur, diminuer le compteur, multiplier, diviser - tout ce que votre cœur désire.
Le seul sous-système de métrique n'est pas en mesure de donner exactement les métriques intégrées.
Pourquoi est-ce important pour nous? Comme vous l'avez vu plus tôt, nous avons une poignée pour donner des statistiques dans un format spécifique, et plusieurs travailleurs sont en cours d'exécution. Nous ne savons pas lequel des employés recevra la demande, mais pour renvoyer toutes les mesures, nous devons créer une sorte de registre de noms et le brouiller d'une manière ou d'une autre entre les processus. C'est un gros problème, je veux éviter cela. Qu'avons-nous d'autre?

Bien sûr, sous-système de cache. Et nous voyons ici: il peut faire presque la même chose, et est également capable de donner les noms des clés stockées dans le cache. Voilà ce dont vous avez besoin.

Le sous-système de cache est un cache intégré à uWSGI. Un module rapide et thread-safe, qui est un stockage de valeur-clé ordinaire.

Mais puisqu'il s'agit d'un cache, il y a un deuxième problème bien connu: comment nommer une variable et comment invalider le cache? Dans notre cas, voyons quels sont les paramètres de cache par défaut. Il a des restrictions sur la longueur de la clé. Dans notre cas, il s'agit du nom de la métrique. La valeur par défaut est 2048 octets. Et vous pouvez augmenter la configuration si nécessaire. Le nombre d'éléments qu'il stocke par défaut est de 65 536. Il semble que cette valeur devrait être suffisante pour tout le monde. Il est peu probable que quiconque collecte un tel nombre de métriques à partir de son application.
Et ttl par défaut est 0. Autrement dit, les valeurs des caches stockés ne sont pas invalidées dans le temps. Ainsi, nous pouvons les récupérer dans le cache et les envoyer au système de métriques.

Encore une fois, l'option est une application qui utilise la boîte uWSGI.
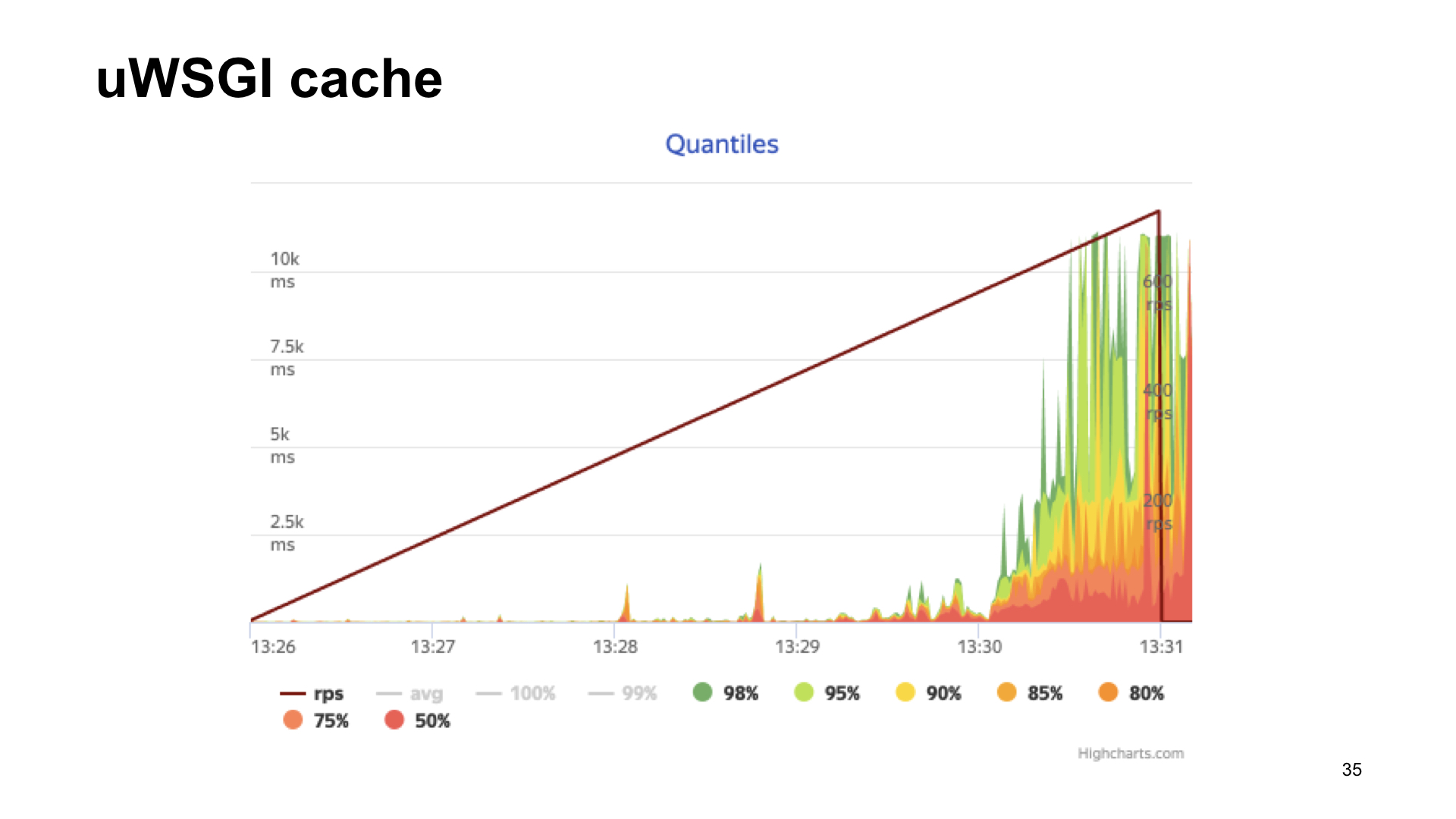
Voici les résultats du décorticage de cette application.

Le résultat sans métriques, si avec uWSGI, avec un étirement, il ressemble presque au même.
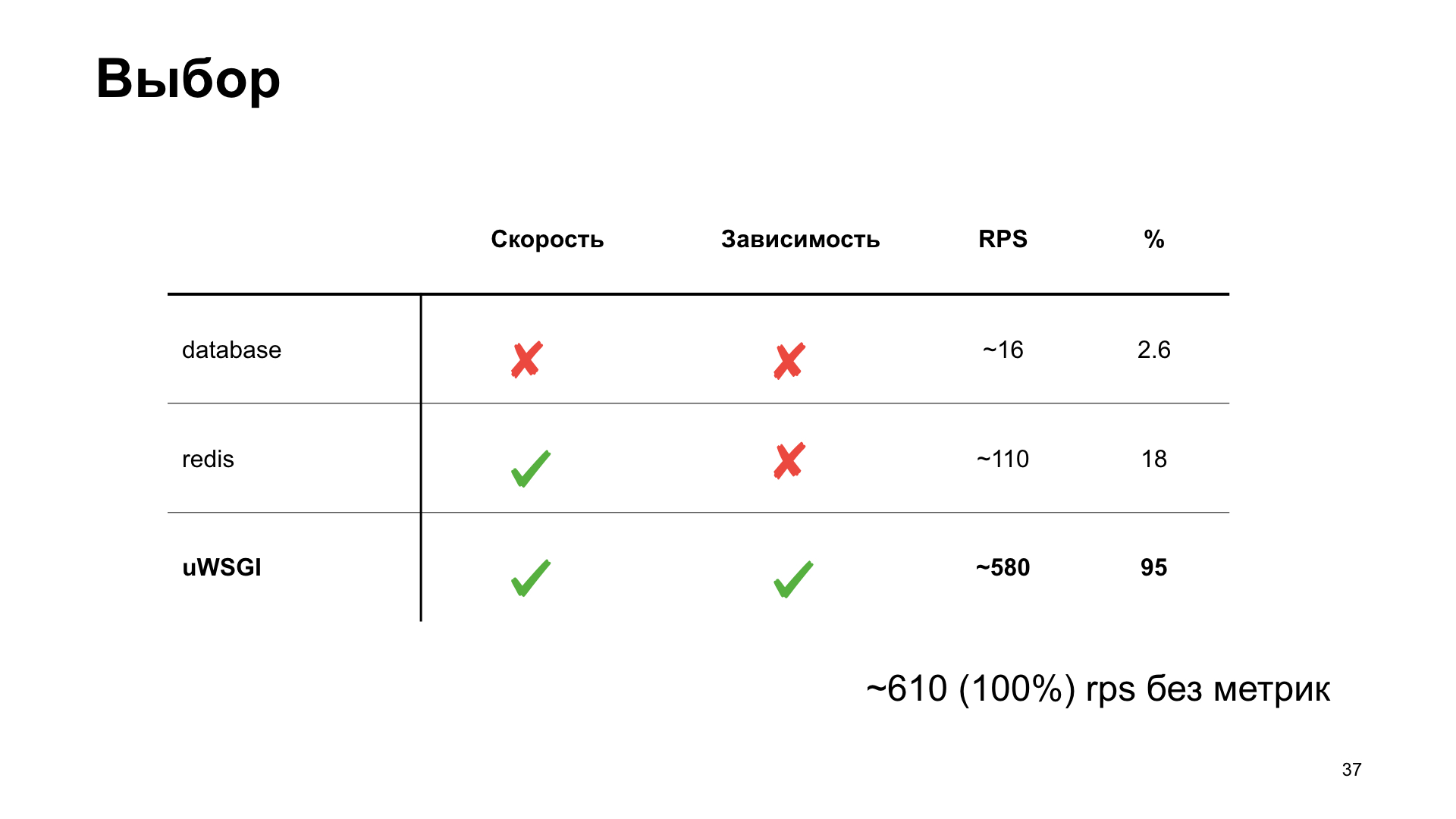
Comme vous pouvez le voir, dans le cas de uWSGI, nous ne perdons que 5% des performances par rapport à la version "vanille" sans métriques. D'autres options ont un tirage assez important et, par conséquent, à la suite du vote des spectateurs, uWSGI gagne.

Comment avons-nous appliqué cela? Nous avons écrit une petite bibliothèque, un wrapper autour de uWSGI. Par exemple, nous installons une instance de notre bibliothèque et ici nous ajoutons la métrique «heure de requête de base de données» comme exemple.

Nous souhaitons également suivre le fonctionnement du cache. Nous redéfinissons simplement les méthodes du client memca, économisons le temps de recevoir des données, le temps de téléchargement et le nombre de cache hit et cache cache miss.

Comment faisons-nous cela à l'intérieur de la bibliothèque? Pour expédier les valeurs, nous obtenons les noms des clés stockées dans le cache, les parcourons et les donnons simplement au format souhaité au point de terminaison.
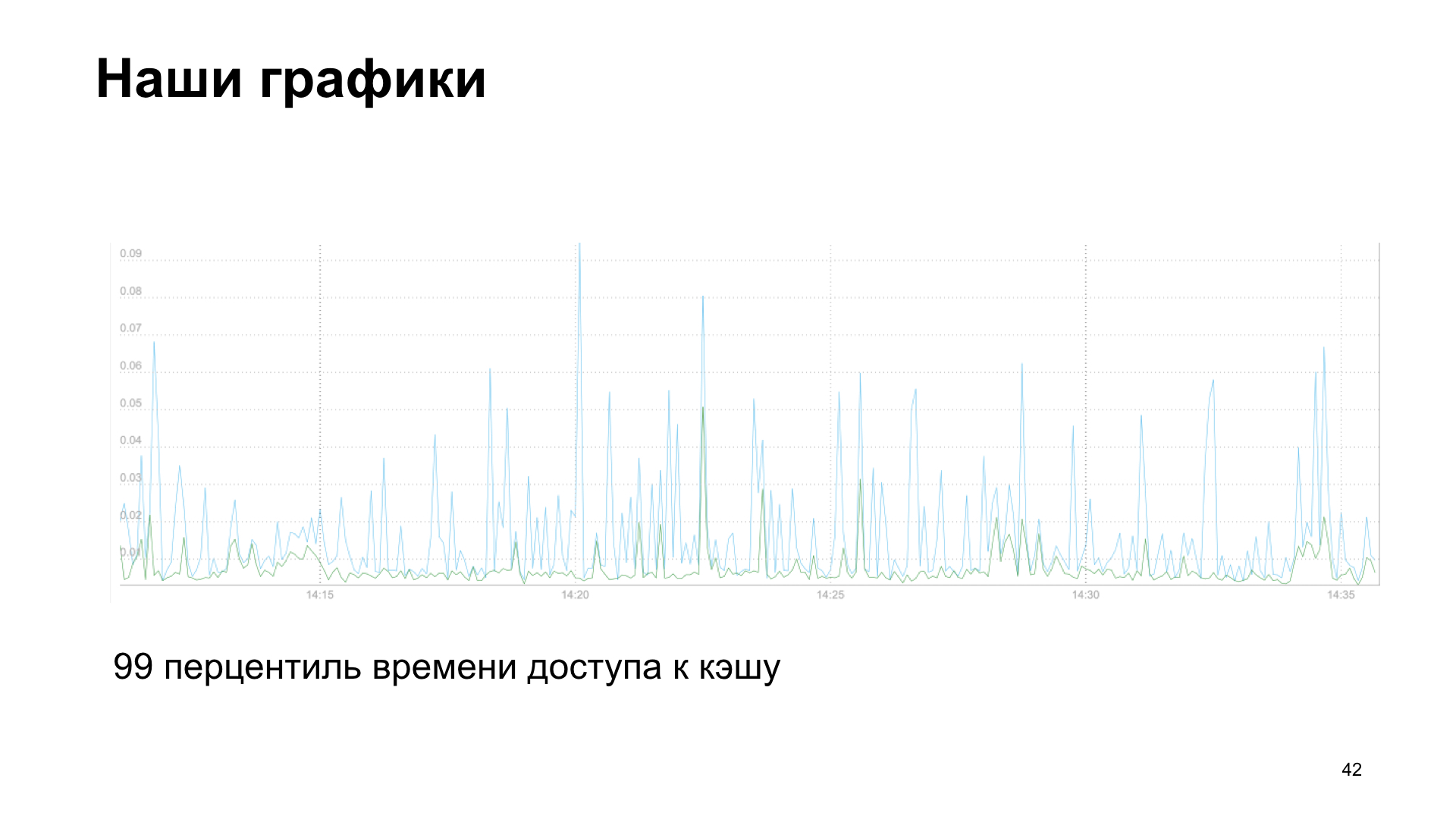
En conséquence, nous obtenons un graphique, dans ce cas, il s'agit du 99e centile du temps d'accès au cache, en lecture et en écriture.

Ou, en option, le nombre de demandes de service tiers à notre API.

Nous avons des histoires d’échec et de succès. Nous avons commencé à ajouter de plus en plus de mesures et nous avons constaté une baisse des performances. Les paramètres eux-mêmes nous ont aidés. Si vous collectez des mesures, vous pouvez voir que quelque chose ne va pas. Par conséquent, je vous recommande également de regarder rétrospectivement les métriques que vous avez accumulées au cours de la semaine, du mois, de six mois. Et voyez quelle tendance votre application montre dans quels indicateurs. Nous avons réalisé que nous avons commencé à nous reposer sur le calcul des métriques.

Le profilage nous a aidés. Ici, vous voyez un graphique de flamme, il nous montre visuellement combien d'appels de différentes fonctions ont pris au cours du processus, lesquels appels ont apporté la plus grande contribution dans le temps. Nous avons réalisé que nous n'avions pas très bien réussi dans la première version à l'aide de cornichons. À l'intérieur de notre bibliothèque, elle a passé beaucoup de temps à décaper.

Nous avons refusé le décapage, transféré à cashe inc, tout mesuré, c'est devenu plus rapide.

Dans la nouvelle implémentation, nous passons la plupart de notre temps à travailler avec le cache, pas à décaper.

Pourquoi je te dis ça? Je vous invite à commencer à collecter des métriques, à les surveiller et à vous concentrer sur les métriques. Lorsque vous choisissez une option de collecte de métriques possible, comparez les options, voyez celle qui vous convient le mieux. Et, bien sûr, le profilage est bon. Si vous voyez que quelque chose ne va pas, quelque chose ralentit - profil.
Merci à tous! Comme je l'ai promis, les références: