Bonjour, Habr! Je vous présente la traduction de l'article
"Service mesh data plane vs control plane" par
Matt Klein .

Cette fois, j'ai voulu et traduit la description des deux composants du maillage de service, le plan de données et le plan de contrôle. Cette description m'a semblé la plus compréhensible et la plus intéressante, et surtout menant à la compréhension de "Est-ce même nécessaire?"
Comme l'idée d'un «maillage de service» est devenue de plus en plus populaire au cours des deux dernières années (article original 10 octobre 2017) et que le nombre de participants dans l'espace a augmenté, j'ai constaté une augmentation proportionnelle de la confusion parmi toute la communauté technique concernant la façon de comparer et opposer différentes solutions.
La situation est mieux décrite dans la série de tweets suivante que j'ai écrite en juillet:
Confusion avec le maillage de service (maillage de service) n ° 1: Linkerd ~ = Nginx ~ = Haproxy ~ = Envoy. Aucun d'eux n'est égal à Istio. Istio est quelque chose de complètement différent. 1 /
Les premiers ne sont que des avions de données. Ils ne font rien. Ils doivent être réglés pour quelque chose de plus. 2 /
Istio est un exemple de plan de contrôle qui relie des pièces entre elles. Il s'agit d'un calque différent. / fin
Les tweets précédents mentionnaient plusieurs projets différents (Linkerd, NGINX, HAProxy, Envoy et Istio), mais, plus important encore, présentaient les concepts généraux d'un plan de données, d'un maillage de service et d'un plan de contrôle. Dans ce billet, je prendrai un peu de recul et dirai ce que j'entends par les termes «plan de données» et «plan de contrôle» à un niveau très élevé, puis je dirai comment les termes se rapportent aux projets mentionnés dans les tweets.
Qu'est-ce qu'un maillage de service (vraiment)?
 Figure 1: Présentation du maillage de serviceLa figure 1
Figure 1: Présentation du maillage de serviceLa figure 1 illustre le concept d'un maillage de service au niveau le plus élémentaire. Il existe quatre clusters de services (AD). Chaque instance de service est associée à un serveur proxy local. Tout le trafic réseau (HTTP, REST, gRPC, Redis, etc.) provenant d'une seule instance d'application est transmis via un serveur proxy local aux clusters de services externes correspondants. Ainsi, l'instance d'application ne connaît pas le réseau dans son ensemble et ne connaît que son proxy local. En fait, le réseau du système distribué était éloigné du service.
Plan de données
Dans un maillage de service, un serveur proxy situé localement pour l'application effectue les tâches suivantes:
- Découverte de service Quels services / services / applications sont disponibles pour votre application?
- Contrôle de santé Les instances de service retournées par la découverte de service sont-elles opérationnelles et prêtes à accepter le trafic réseau? Cela peut inclure des contrôles d'intégrité actifs (par exemple, vérification de la réponse / healthcheck) et passifs (par exemple, en utilisant 3 erreurs 5xx consécutives comme indication de l'état malsain du service).
- Acheminement Après avoir reçu une demande à "/ foo" du service REST, vers quel cluster de services la demande doit-elle être envoyée?
- Équilibrage de charge Une fois qu'un cluster de services a été sélectionné pendant le routage, vers quelle instance du service la demande doit-elle être envoyée? Quel délai? Quels paramètres de coupure de circuit? Si la demande échoue, doit-elle être répétée?
- Authentification et autorisation Pour les demandes entrantes, le service appelant peut-il être cryptographiquement reconnu / autorisé à l'aide de mTLS ou d'un autre mécanisme? S'il est identifié / autorisé, est-il autorisé à appeler l'opération demandée (point d'extrémité) dans le service ou doit-on renvoyer une réponse non authentifiée?
- Observabilité Pour chaque demande, des statistiques détaillées, des journaux / journaux et des données de trace distribuées doivent être générées afin que les opérateurs puissent comprendre le flux de trafic distribué et les problèmes de débogage à mesure qu'ils surviennent.
Pour tous les points précédents du réseau de service (maillage de service), le plan de données est responsable. En fait, le proxy local au service (side-car) est un plan de données. En d'autres termes, le plan de données est responsable de la diffusion, de la transmission et de la surveillance conditionnelles de chaque paquet de réseau envoyé au service ou envoyé à partir de celui-ci.
L'avion de contrôle
L'abstraction du réseau fournie par le proxy local dans le plan de données est magique (?). Cependant, comment le proxy connaît-il réellement la route "/ foo" vers le service B? Comment utiliser les données de découverte de service remplies de demandes de proxy? Comment les paramètres d'équilibrage de charge, de temporisation, de coupure de circuit, etc. sont-ils configurés? Comment déployer l'application en utilisant la méthode bleu / vert (bleu / vert) ou la méthode de transfert progressif du trafic? Qui configure les paramètres d'authentification et d'autorisation à l'échelle du système?
Tous les éléments ci-dessus sont gérés par le plan de contrôle du maillage de service.
Le plan de contrôle accepte un ensemble de serveurs proxy isolés sans état et les transforme en un système distribué .
Je pense que la raison pour laquelle de nombreux technologues trouvent confus les concepts séparés du plan de données et du plan de contrôle est que, pour la plupart des gens, le plan de données est familier, tandis que le plan de contrôle est étranger / incompréhensible. Nous travaillons depuis longtemps avec des routeurs et des commutateurs réseau physiques. Nous comprenons que les packages / demandes doivent aller du point A au point B, et que nous pouvons utiliser du matériel et des logiciels pour cela. La nouvelle génération de proxys logiciels est tout simplement les versions tendances des outils que nous utilisons depuis longtemps.
 Figure 2: Plan de contrôle humain
Figure 2: Plan de contrôle humainCependant, nous utilisons depuis longtemps le plan de contrôle, bien que la plupart des opérateurs de réseaux n'associent cette partie du système à aucun composant technologique. La raison en est simple:
La plupart des avions de contrôle utilisés aujourd'hui sont ... nous .
La figure 2 montre ce que j'appelle le «plan de contrôle humain». Dans ce type de déploiement, qui est encore très courant, l'opérateur humain, probablement grincheux, crée des configurations statiques - potentiellement à l'aide de scripts - et les déploie à l'aide d'une sorte de processus spécial sur tous les proxys. Ensuite, les proxys commencent à utiliser cette configuration et commencent à traiter le plan de données à l'aide des paramètres mis à jour.
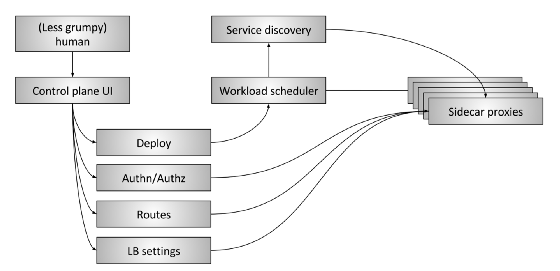 Figure 3: Plan de contrôle de maillage de service avancéLa figure 3
Figure 3: Plan de contrôle de maillage de service avancéLa figure 3 montre le plan de contrôle «étendu» du maillage de service. Il se compose des parties suivantes:
- L'Humain : Il y a encore une personne (espérons-le moins en colère) qui prend des décisions de haut niveau concernant l'ensemble du système.
- Contrôle de l'interface utilisateur du plan : une personne interagit avec un certain type d'interface utilisateur pour contrôler le système. Il peut s'agir d'un portail Web, d'une application de ligne de commande (CLI) ou d'une autre interface. À l'aide de l'interface utilisateur, l'opérateur a accès à des paramètres de configuration globale du système tels que:
- Gestion du déploiement, bleu / vert et / ou avec transfert progressif du trafic
- Paramètres d'authentification et d'autorisation
- Spécifications de la table de routage, par exemple, lorsque l'application A demande des informations sur "/ foo", que se passe-t-il
- Paramètres d'équilibrage de charge, tels que les délais d'attente, les tentatives, les paramètres de coupure de circuit, etc.
- Planificateur de charge de travail : les services sont lancés dans l'infrastructure via un certain type de système de planification / orchestration, tel que Kubernetes ou Nomad. L'ordonnanceur est responsable du chargement du service avec son serveur proxy local.
- Découverte de service Lorsque le planificateur démarre et arrête les instances de service, il signale l'état d'intégrité au système de découverte de service.
- API de configuration de proxy Sidecar : les proxys locaux extraient dynamiquement l'état de divers composants du système selon le modèle «finalement cohérent» sans intervention de l'opérateur. L'ensemble du système, composé de toutes les instances de services en cours d'exécution et des serveurs proxy locaux, converge finalement en un seul écosystème. L'API du plan de données Envoy est un exemple de la façon dont cela fonctionne dans la pratique.
Essentiellement, l'objectif du plan de contrôle est d'établir une politique qui sera finalement adoptée par le plan de données. Des avions de contrôle plus avancés retireront plus de parties de certains systèmes de l'opérateur et nécessiteront moins de contrôle manuel, à condition qu'ils fonctionnent correctement! ..
Plan de données et plan de contrôle. Résumé du plan de données et du plan de contrôle
- Plan de données de maillage de service : affecte chaque paquet / demande dans le système. Responsable de la découverte des applications / services, des contrôles d'intégrité, du routage, de l'équilibrage de charge, de l'authentification / autorisation et de l'observabilité.
- Plan de contrôle du maillage de service : fournit une politique et une configuration pour tous les plans de données de travail au sein du réseau de service. Ne touche aucun paquet / demande dans le système. Le plan de contrôle transforme tous les plans de données en un système distribué.
Paysage actuel du projet
Après avoir compris l'explication ci-dessus, regardons l'état actuel du projet «service mesh».
- Avions de données : Linkerd, NGINX, HAProxy, Envoy, Traefik
- Avions de contrôle : Istio, Nelson, SmartStack
Au lieu de procéder à une analyse approfondie de chacune des solutions ci-dessus, je m'attarderai brièvement sur certains points qui, à mon avis, causent actuellement la plus grande confusion dans l'écosystème.
Au début de 2016, Linkerd a été l'un des premiers serveurs proxy pour le plan de données pour le maillage de service et a fait un travail fantastique de sensibilisation et d'attention au modèle de conception de maillage de service. Environ 6 mois après cela, Envoy a rejoint Linkerd (bien qu'il soit avec Lyft depuis la fin de 2015). Linkerd et Envoy sont deux des projets les plus souvent mentionnés lors des discussions sur les réseaux de services.
Istio a été annoncé en mai 2017. Les objectifs du projet Istio sont très similaires au plan de contrôle étendu illustré à la
figure 3 . Envoy for Istio est le serveur proxy par défaut. Ainsi, Istio est le plan de contrôle et Envoy est le plan de données. En peu de temps, Istio a causé beaucoup d'agitation et d'autres avions de données ont commencé à s'intégrer en remplacement d'Envoy (Linkerd et NGINX ont tous deux démontré leur intégration avec Istio). Le fait que vous puissiez utiliser différents plans de données dans le même plan de contrôle signifie que le plan de contrôle et le plan de données ne sont pas nécessairement étroitement liés. Une API telle que l'API du plan de données universel Envoy peut former un pont entre deux parties du système.
Nelson et SmartStack aident à illustrer davantage la séparation du plan de contrôle et du plan de données. Nelson utilise Envoy comme proxy et construit un plan de contrôle fiable du maillage de service basé sur la pile HashiCorp, c'est-à-dire Nomade etc. SmartStack est peut-être le premier d'une nouvelle vague de réseaux de services. SmartStack forme un plan de contrôle autour d'un HAProxy ou NGINX, démontrant la possibilité de découpler un plan de contrôle d'un maillage de service et d'un plan de données.
Une architecture de microservices avec un maillage de service attire plus l'attention (à droite!), Et de plus en plus de projets et de fournisseurs commencent à travailler dans cette direction. Au cours des prochaines années, nous verrons de nombreuses innovations à la fois dans le plan de données et le plan de contrôle, ainsi que le mélange des divers composants. À terme, l'architecture de microservice devrait devenir plus transparente et magique (?) Pour l'opérateur.
J'espère de moins en moins ennuyé.
Points clés (points clés à retenir)
- Un maillage de service (maillage de service) se compose de deux parties différentes: un plan de données et un plan de contrôle. Les deux composants sont requis et sans eux, le système ne fonctionnera pas.
- Tout le monde connaît le plan de contrôle, et maintenant vous pouvez être le plan de contrôle!
- Tous les avions de données se font concurrence en termes de fonctions, de performances, de configurabilité et d'extensibilité.
- Tous les avions de contrôle rivalisent de fonction, de configurabilité, d'extensibilité et de convivialité.
- Un seul plan de contrôle peut contenir les abstractions et les API correctes afin que plusieurs plans de données puissent être utilisés.