Comment évaluer la qualité des tests? Beaucoup s'appuient sur la mesure la plus populaire connue de tous: la couverture du code. Mais il s'agit d'une métrique quantitative et non qualitative. Il montre combien de votre code est couvert par des tests, mais pas comment ces tests sont bien écrits.
Une façon de comprendre cela est de tester les mutations. Cet outil, apportant des modifications mineures au code source et relançant les tests par la suite, vous permet d'identifier les tests inutiles et la couverture de faible qualité.
Lors du
Meetup Badoo PHP en mars, j'ai parlé de la façon d'organiser les tests mutationnels pour le code PHP et des problèmes que vous pourriez rencontrer. La vidéo est disponible
ici , et pour la version texte, bienvenue à cat.
Qu'est-ce que le test de mutation
Pour expliquer ce que je veux dire, je vais vous montrer quelques exemples. Ils sont simples, exagérés par endroits et peuvent sembler évidents (bien que les exemples réels soient généralement assez complexes et ne peuvent pas être vus avec leurs yeux).
Considérez la situation: nous avons une fonction élémentaire qui prétend être un adulte, et il y a un test qui la teste. Le test a un fournisseur de données, c'est-à-dire qu'il teste deux cas: 17 ans et 19 ans. Je pense qu'il est évident pour beaucoup d'entre vous que isAdult a une couverture à 100%. La seule ligne. Le test est effectué. Tout est magnifique.

Mais un examen plus approfondi révèle que notre fournisseur est mal écrit et ne teste pas les conditions aux limites: l'âge de 18 ans en tant que condition aux limites n'est pas testé. Vous pouvez remplacer le signe> par> =, et le test ne détectera pas une telle modification.
Un autre exemple, un peu plus compliqué. Il existe une fonction qui construit un objet simple contenant des setters et des getters. Nous avons trois champs que nous définissons, et il y a un test qui vérifie que la fonction buildPromoBlock collecte vraiment l'objet que nous attendons.

Si vous regardez attentivement, nous avons également setSomething, qui définit une propriété sur true. Mais dans le test, nous n'avons pas une telle affirmation. Autrement dit, nous pouvons supprimer cette ligne de buildPromoBlock - et notre test ne détectera pas ce changement. Dans le même temps, nous avons une couverture de 100% dans la fonction buildPromoBlock, car les trois lignes ont été exécutées pendant le test.
Ces deux exemples nous conduisent à ce qu'est le test de mutation.
Avant de démonter l'algorithme, je donnerai une courte définition. Le test de mutation est un mécanisme qui nous permet, en apportant des modifications mineures au code, d'imiter les actions du mal Pinocchio ou du junior Vasya, qui est venu et a commencé à le casser délibérément, remplacer les signes> par <, = par! =, Etc. Pour chacune de ces modifications que nous apportons à de bonnes fins, nous exécutons des tests qui doivent couvrir la ligne modifiée.
Si les tests ne nous ont rien montré, s'ils ne sont pas tombés, alors ils ne sont probablement pas assez efficaces. Ils ne testent pas les cas limites, ne contiennent pas d'assertions: ils doivent peut-être être améliorés. Si les tests échouent, alors ils sont cool. Ils protègent vraiment contre de tels changements. Par conséquent, notre code est plus difficile à briser.
Analysons maintenant l'algorithme. C'est assez simple. La première chose que nous faisons pour effectuer des tests de mutation est de prendre le code source. Ensuite, nous obtenons une couverture de code pour savoir quels tests exécuter pour quelle chaîne. Après cela, nous passons en revue le code source et générons les soi-disant mutants.
Un mutant est un changement de code unique. Autrement dit, nous prenons une certaine fonction où il y avait un signe> en comparaison, si, nous changeons ce signe en> = - et nous obtenons un mutant. Après cela, nous exécutons les tests. Voici un exemple de mutation (nous avons remplacé> par> =):

Dans ce cas, les mutations ne sont pas faites au hasard, mais selon certaines règles. La réponse du test de mutation est idempotente. Peu importe le nombre de fois où nous exécutons des tests de mutation sur le même code, ils produisent les mêmes résultats.
La dernière chose que nous faisons est d'exécuter les tests qui couvrent la ligne mutée. Sortez-le de la couverture. Il existe des outils non optimaux qui pilotent tous les tests. Mais un bon outil ne chassera que ceux qui sont nécessaires.
Après cela, nous évaluons le résultat. Les tests ont échoué - alors tout va bien. S'ils ne sont pas tombés, ils ne sont pas très efficaces.
Mesures
Quelles mesures les tests de mutation nous fournissent-ils? Il en ajoute trois autres à la couverture du code, dont nous parlerons maintenant.
Mais d'abord, analysons la terminologie.

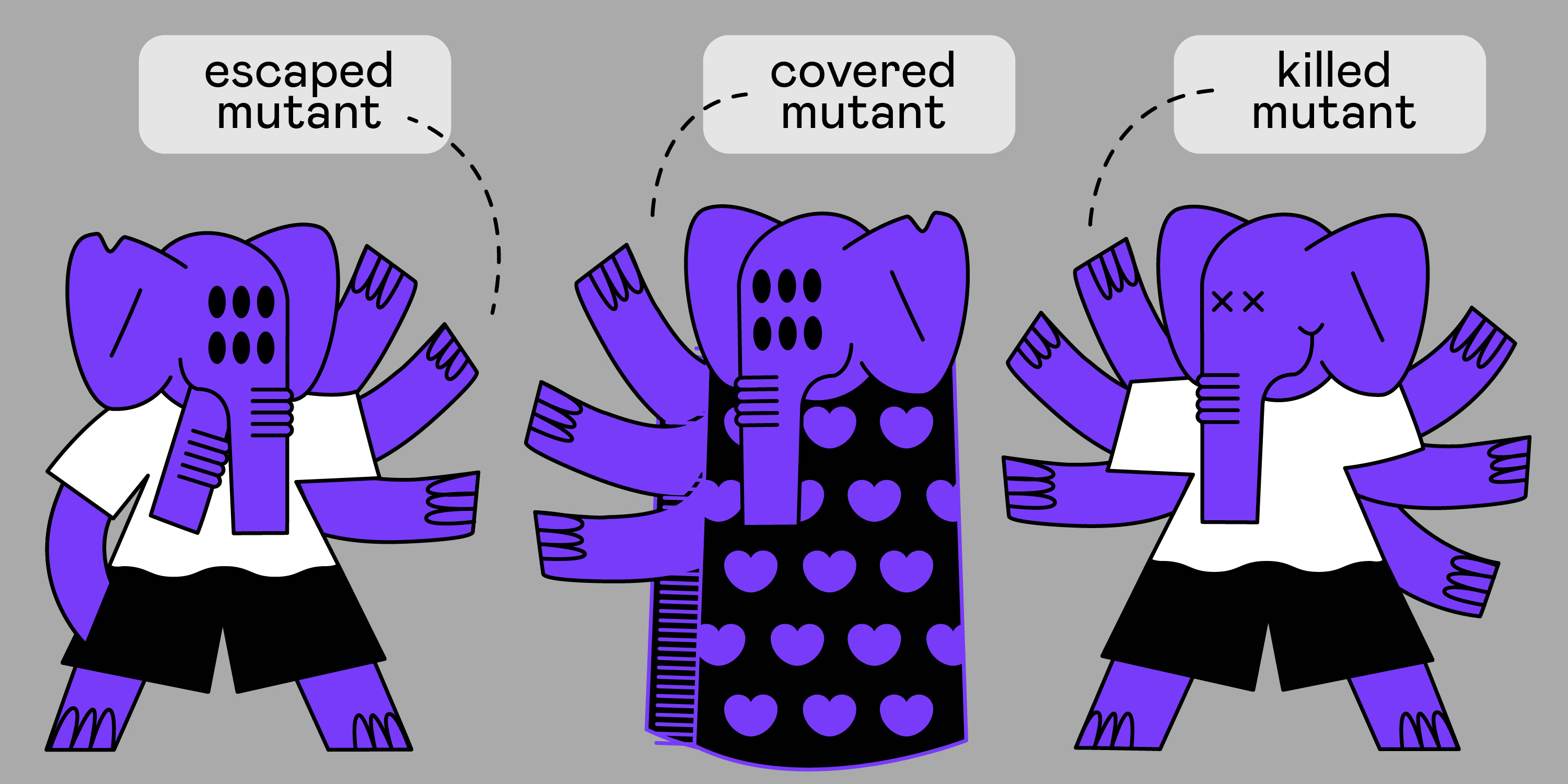
Il y a le concept de mutants tués: ce sont les mutants que nos tests ont «cloués» (c'est-à-dire qu'ils les ont capturés).

Il y a le concept de mutant échappé (mutants survivants). Ce sont les mutants qui ont réussi à éviter la punition (c'est-à-dire que les tests ne les ont pas détectés).

Et il y a des concepts couverts par un mutant - un mutant couvert par des tests et un mutant découvert en face de lui, qui n'est couvert par aucun test (c'est-à-dire que nous avons du code, il a une logique métier, nous pouvons le changer, mais pas un seul test ne vérifie pas les modifications).
Le principal indicateur que le test de mutation nous donne est le MSI (indicateur de score de mutation), le rapport du nombre de mutants tués à leur nombre total.
Le deuxième indicateur est la couverture du code de mutation. C'est juste qualitatif, pas quantitatif, car il montre combien de logique métier vous pouvez briser et le faire régulièrement, nos tests sont pris.
Et la dernière métrique est le MSI couvert, c'est-à-dire un MSI plus doux. Dans ce cas, nous calculons MSI uniquement pour les mutants qui ont été couverts par des tests.
Problèmes de test de mutation
Pourquoi moins de la moitié des programmeurs ont entendu parler de cet outil? Pourquoi n'est-il pas utilisé partout?
Basse vitesse
Le premier problème (l'un des principaux) est la vitesse des tests de mutation. Dans le code, si nous avons des dizaines d'opérateurs de mutation, même pour la classe la plus simple, nous pouvons générer des centaines de mutations. Pour chaque mutation, vous devrez exécuter des tests. Si nous avons, disons, 5 000 tests unitaires qui durent dix minutes, le test mutationnel peut prendre des heures.
Que peut-on faire pour niveler cela? Exécutez des tests en parallèle, dans plusieurs threads. Jetez des flux dans plusieurs voitures. Ça marche.
La deuxième façon est les exécutions incrémentielles. Il n'est pas nécessaire de compter les indicateurs mutationnels pour la branche entière à chaque fois - vous pouvez prendre la différence de branche. Si vous utilisez des brunchs de fonctionnalités, il vous sera facile de le faire: exécutez des tests uniquement sur les fichiers qui ont changé et voyez ce qui se passe dans l'assistant, comparez, analysez.
La prochaine chose que vous pouvez faire est le réglage des mutations. Étant donné que les opérateurs de mutation peuvent être modifiés, vous pouvez définir certaines règles selon lesquelles ils fonctionnent, puis vous pouvez arrêter certaines mutations si elles entraînent sciemment des problèmes.
Un point important: le test mutationnel ne convient qu'aux tests unitaires. Malgré le fait qu'il puisse être exécuté pour des tests d'intégration, c'est évidemment une idée ratée, car les tests d'intégration (comme de bout en bout) s'exécutent beaucoup plus lentement et affectent beaucoup plus de code. Vous n'attendrez tout simplement jamais les résultats. En principe, ce mécanisme a été inventé et développé exclusivement pour les tests unitaires.
Mutants sans fin
Le deuxième problème qui peut survenir avec les tests de mutation est celui des mutants dits sans fin. Par exemple, il y a du code simple, une boucle for simple:

Si vous remplacez i ++ par i--, le cycle se transformera en infini. Votre code restera longtemps. Et les tests mutationnels génèrent assez souvent de telles mutations.
La première chose que vous pouvez faire est de régler la mutation. Évidemment, changer i ++ en i-- dans une boucle for est une très mauvaise idée: dans 99% des cas, nous nous retrouverons avec une boucle infinie. Par conséquent, nous avons interdit de le faire dans notre outil.
La deuxième chose et la plus importante qui vous protège contre de tels problèmes est le délai d'attente pour la course. Par exemple, le même PHPUnit a la possibilité de terminer un test de délai d'expiration quel que soit l'endroit où il est bloqué. PHPUnit via PCNTL raccroche les rappels et calcule le temps lui-même. Si le test échoue pendant une certaine période, il le cloue simplement et un tel cas est considéré comme un mutant tué, car le code qui a généré les mutations est vraiment vérifié par le test, qui détecte vraiment le problème, indiquant que le code est devenu inopérant.
Mutants identiques
Ce problème existe dans la théorie des tests de mutation. En pratique, il n'est pas souvent rencontré, mais vous devez le savoir.
Prenons un exemple classique qui l'illustre. Nous avons une multiplication de la variable A par -1 et une division de A par -1. Dans le cas général, ces opérations conduisent au même résultat. Nous changeons le signe de A. En conséquence, nous avons une mutation qui permet à deux signes de changer entre eux. La logique du programme par une telle mutation n'est pas violée. Les tests et ne doivent pas l'attraper, ne doivent pas tomber. En raison de ces mutants identiques, certaines difficultés surviennent.
Il n'y a pas de solution universelle - chacun résout ce problème à sa manière. Peut-être qu'une sorte de système d'enregistrement mutant pourrait aider. Chez Badoo, nous pensons à quelque chose de similaire maintenant, nous allons les imiter.
Ceci est une théorie. Et PHP?
Il existe deux outils bien connus pour le test mutationnel: Humbug et Infection. Lorsque je préparais l'article, je voulais parler de celui qui est le meilleur et en venir à la conclusion qu'il s'agit d'une infection.
Mais quand je suis allé à la page Humbug, j'ai vu ce qui suit: Humbug s'est déclaré obsolète en faveur de l'infection. Par conséquent, une partie de mon article s'est avérée vide de sens. L'infection est donc un très bon outil. Je dois dire merci à
borNfree de Minsk, qui l'a créé. Il travaille vraiment cool. Vous pouvez le prendre directement dans la boîte, le passer par le compositeur et le démarrer.
Nous avons vraiment aimé Infection. Nous voulions l'utiliser. Mais ils ne le pouvaient pas pour deux raisons. L'infection nécessite une couverture de code pour exécuter des tests pour les mutants correctement et précisément. Ici, nous avons deux façons. Nous pouvons le calculer directement en runtime (mais nous avons 100 000 tests unitaires). Ou nous pouvons le calculer pour le maître actuel (mais construire sur notre nuage de dix machines très puissantes dans plusieurs threads prend une heure et demie). Si nous le faisons à chaque exécution de mutation, l'outil ne fonctionnera probablement pas.
Il existe une option pour alimenter le fichier fini, mais au format PHPUnit, il s'agit d'un tas de fichiers XML. Outre le fait qu'ils contiennent des informations précieuses, ils font glisser un tas de structure, des crochets et d'autres choses. Je me suis dit qu'en général, notre couverture de code pèserait environ 30 Go, et nous devons la faire glisser sur toutes les machines cloud, en lecture constante depuis le disque. En général, l'idée est moyenne.
Le deuxième problème était encore plus important. Nous avons une merveilleuse bibliothèque
SoftMocks . Il nous permet de gérer le code hérité, qui est difficile à tester, et d'écrire avec succès des tests pour celui-ci. Nous l'utilisons activement et n'allons pas le refuser dans un proche avenir, malgré le fait que nous écrivons du nouveau code afin de ne pas avoir besoin de SoftMocks. Donc, cette bibliothèque est incompatible avec Infection, car ils utilisent presque la même approche pour modifier les changements.
Comment fonctionnent les SoftMocks? Ils interceptent les inclusions de fichiers et les remplacent par des modifications, c'est-à-dire qu'au lieu d'exécuter la classe A, SoftMocks crée la classe A à un endroit différent et en connecte une autre au lieu de l'original. L'infection agit exactement de la même manière, seulement elle fonctionne via
stream_wrapper_register () , qui fait la même chose, mais au niveau du système. Par conséquent, SoftMocks ou Infection peuvent fonctionner pour nous. Les SoftMocks étant nécessaires à nos tests, il est très difficile de se faire des amis avec ces deux outils. C'est probablement possible, mais dans ce cas, nous entrons tellement dans l'infection que la signification de ces changements est tout simplement perdue.
Surmontant les difficultés, nous avons écrit notre petit instrument. Nous avons emprunté des opérateurs de mutation à Infection (ils sont bien écrits et très faciles à utiliser). Au lieu de démarrer des mutations via stream_wrapper_register (), nous les exécutons via SoftMocks, c'est-à-dire que nous utilisons notre outil de la boîte. Notre toolza est ami avec notre service de couverture de code interne. Autrement dit, à la demande, il peut recevoir la couverture d'un fichier ou d'une ligne sans exécuter tous les tests, ce qui se produit très rapidement. Mais c'est simple. Si Infection possède un tas d'outils et de fonctionnalités de toutes sortes (par exemple, le lancement dans plusieurs threads), alors le nôtre ne l'est pas. Mais nous utilisons notre infrastructure interne pour compenser cette lacune. Par exemple, nous exécutons la même exécution de test dans plusieurs threads via notre cloud.
Comment utilisons-nous cela?
La première est une exécution manuelle. C'est la première chose à faire. Tous les tests que vous écrivez sont vérifiés manuellement par des tests de mutation. Cela ressemble à ceci:

J'ai exécuté un test de mutation pour un fichier. J'ai obtenu le résultat: 16 mutants. Parmi ceux-ci, 15 ont été tués par des tests, et un est tombé avec une erreur. Je n'ai pas dit que les mutations peuvent générer des décès. Nous pouvons facilement changer quelque chose: rendre le type de retour invalide, ou autre chose. C'est possible, il est considéré comme un mutant tué, car notre test commencera à tomber.
Néanmoins, Infection distingue ces mutants dans une catégorie distincte pour la raison qu'il vaut parfois la peine d'accorder une attention particulière aux erreurs. Il arrive que quelque chose d'étrange se produise - et le mutant n'est pas correctement considéré comme tué.
La deuxième chose que nous utilisons est le rapport sur le maître. Une fois par jour, la nuit, lorsque notre infrastructure de développement est inactive, nous générons un rapport de couverture de code. Après cela, nous faisons le même rapport de test de mutation. Cela ressemble à ceci:

Si vous avez déjà regardé le rapport sur la couverture du code de PHPUnit, vous avez probablement remarqué que l'interface est similaire, car nous avons fait notre outil par analogie. Il a simplement calculé tous les indicateurs clés d'un fichier particulier dans un répertoire. Nous avons également défini certains objectifs (en fait, nous les avons pris du plafond et ne nous conformons pas encore, car nous n'avons pas encore décidé quels objectifs devraient être guidés par chaque métrique, mais ils existent de sorte qu'il est facile de créer des rapports à l'avenir).
Et la dernière chose, la plus importante, qui est une conséquence des deux autres. Les programmeurs sont des gens paresseux. Je suis paresseux: j'aime que tout fonctionne et je n'ai pas à faire de gestes supplémentaires. Nous avons fait en sorte que lorsqu'un développeur pousse sa propre branche, les indicateurs de sa branche et de son maître de brunch soient automatiquement comptés de manière incrémentielle.

Par exemple, j'ai exécuté deux fichiers et obtenu ce résultat. Dans le maître j'avais 548 mutants, 400 ont été tués. Selon un autre dossier - 147 contre 63. Dans ma branche, le nombre de mutants dans les deux cas a augmenté. Mais dans le premier dossier, le mutant a été cloué, et dans le second, il s'est échappé. Naturellement, l'indicateur MSI a chuté. Une telle chose permet même aux personnes qui ne veulent pas perdre de temps d'exécuter des tests mutationnels avec leurs mains, de voir ce qu'elles ont fait de pire et d'y prêter attention (exactement de la même manière que les examinateurs le font dans le processus de révision du code).
Résultats
Il est encore difficile de donner des chiffres: nous n'avions aucun indicateur, maintenant il est apparu, mais il n'y a rien à comparer.
Je peux dire que le test mutationnel donne en termes d'effet psychologique. Si vous commencez à exécuter vos tests par le biais de tests de mutation, vous commencez involontairement à écrire de meilleurs tests, et l'écriture de tests de qualité conduit inévitablement à un changement dans la façon dont vous écrivez du code - vous commencez à penser que vous devez couvrir tous les cas que vous pouvez casser, vous le lancez meilleure structure, le rendre plus testable.
Il s'agit d'une opinion exclusivement subjective. Mais certains de mes collègues ont donné à peu près les mêmes commentaires: lorsqu'ils ont commencé à utiliser constamment les tests mutationnels dans leur travail, ils ont commencé à mieux écrire les tests, et beaucoup ont dit qu'ils ont commencé à mieux écrire le code.
Conclusions
La couverture du code est une mesure importante qui doit être surveillée. Mais cet indicateur ne garantit rien: cela ne signifie pas que vous êtes en sécurité.
Les tests de mutation peuvent aider à améliorer vos tests unitaires, et le suivi de la couverture du code est logique. Il existe déjà un outil pour PHP, donc si vous avez un petit projet sans problèmes, alors saisissez et essayez aujourd'hui.
Commencez au moins en exécutant un test de mutation manuellement. Faites cette simple étape et voyez ce que cela vous apporte. Je suis sûr que vous l'aimerez.