Il y a un an, nous avons pensé à construire l'infrastructure de tests de charge importants, lorsque nous avons atteint le cap des 12 000 utilisateurs en ligne travaillant dans
notre service en même temps. Pendant 3 mois nous avons réalisé la première version du test, qui montrait les limites du service.
L'ironie du sort est qu'en même temps que le test a été lancé, nous avons atteint les limites de la prod, ce qui a fait chuter le service de 2 heures. Cela nous a en outre encouragés à passer de la réalisation de tests au cas par cas à la création d'une infrastructure porteuse efficace. Par infrastructure, je veux dire tous les outils pour travailler avec la charge: outils pour le lancement et le démarrage, un cluster pour charger la charge, un cluster, un produit similaire, des services pour collecter des métriques et pour préparer des rapports, du code pour gérer tout cela et des services pour évoluer.
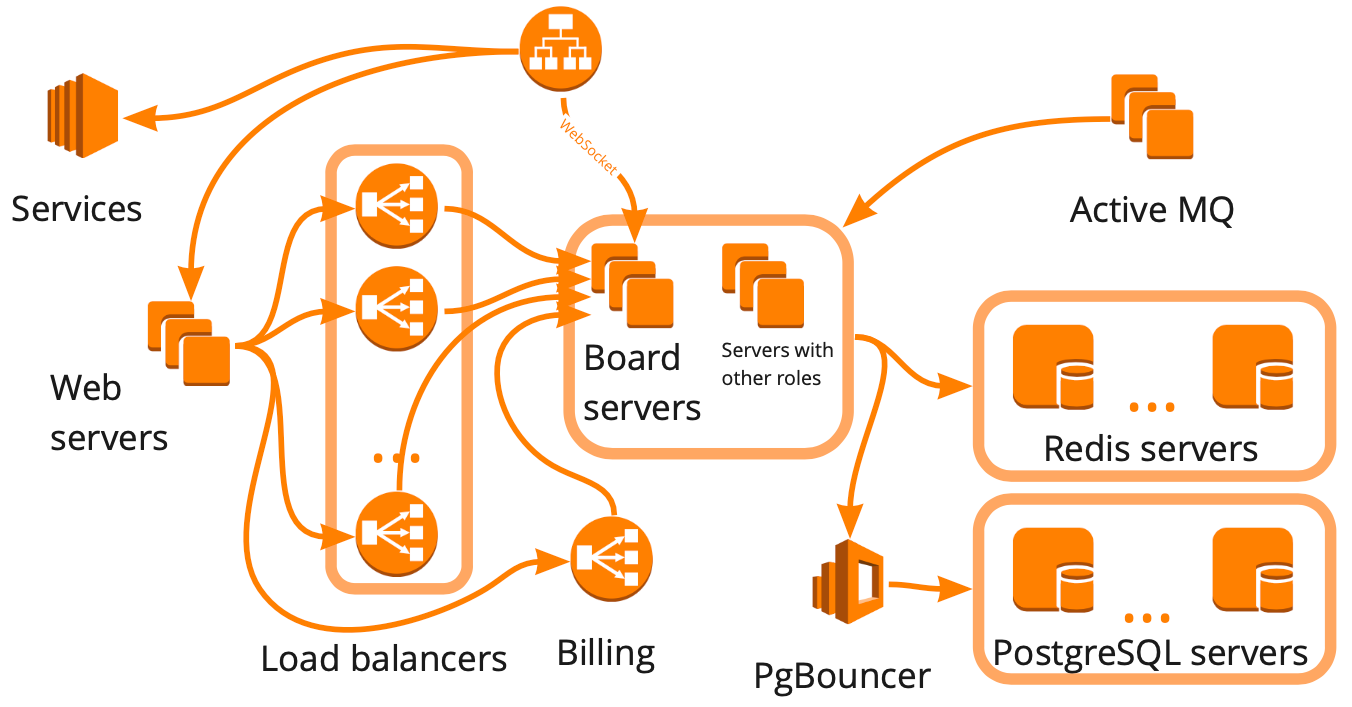
Voici à quoi ressemble le schéma miro.com: il existe de nombreux serveurs différents qui interagissent d'une manière ou d'une autre, et chacun effectue des tâches spécifiques. Il semble que pour construire l'infrastructure des tests de charge, il nous a suffi de dessiner un tel schéma, de prendre en compte toutes les relations et de commencer à couvrir chaque bloc séquentiellement avec des scripts. Cette approche est bonne, mais elle prendrait de nombreux mois, ce qui ne nous convenait pas en raison de la croissance rapide - au cours des six derniers mois, nous sommes passés de 12K à 20K utilisateurs en ligne travaillant dans le service en même temps. De plus, nous ne savions pas comment l'infrastructure de notre service répondra à une augmentation de la charge: lequel des blocs deviendra un goulot d'étranglement et que nous pouvons évoluer de manière linéaire.
En conséquence, nous avons décidé de tester le service en utilisant des utilisateurs virtuels, en simulant leur travail réaliste, c'est-à-dire en construisant un clone de production et en faisant un gros test, qui:
- charger un cluster identique à la production en structure, mais en avance sur lui en puissance;
- donnez-nous toutes les données pour prendre des décisions;
- montrera que l'ensemble de l'infrastructure est capable de supporter la bonne charge;
- sera la base des tests de résistance dont nous aurons peut-être besoin à l'avenir.
Le seul inconvénient d'un tel test est son prix de revient, car pour cela nous avons besoin d'un environnement qui sera plus grand que l'environnement de production.
Dans cet article, je vais vous expliquer comment créer un scénario réaliste, des plugins - WS, Stress-client, Taurus, - charger un cluster, vendre un cluster et montrer des exemples d'utilisation de tests.
Le prochain article explique comment nous gérons des centaines de serveurs pour un test de charge.
Créez un scénario réaliste
Pour créer un scénario réaliste, nous avons besoin de:
- analyser le travail des utilisateurs sur la prod, et pour cela, déterminer les métriques qui sont importantes pour nous, commencer à les collecter régulièrement et analyser les sauts;
- créer des blocs personnalisés pratiques avec lesquels nous pouvons charger efficacement la partie nécessaire de la logique métier;
- Vérifiez le réalisme du script avec les métriques du serveur.
Maintenant, plus sur chaque article.
Analyse du travail des utilisateurs sur prodDans notre service, les utilisateurs peuvent créer des tableaux et y travailler avec différents contenus: photos, textes, mocapas, autocollants, diagrammes, etc. La première mesure que nous devons collecter est le nombre de tableaux et la distribution de contenu sur eux.
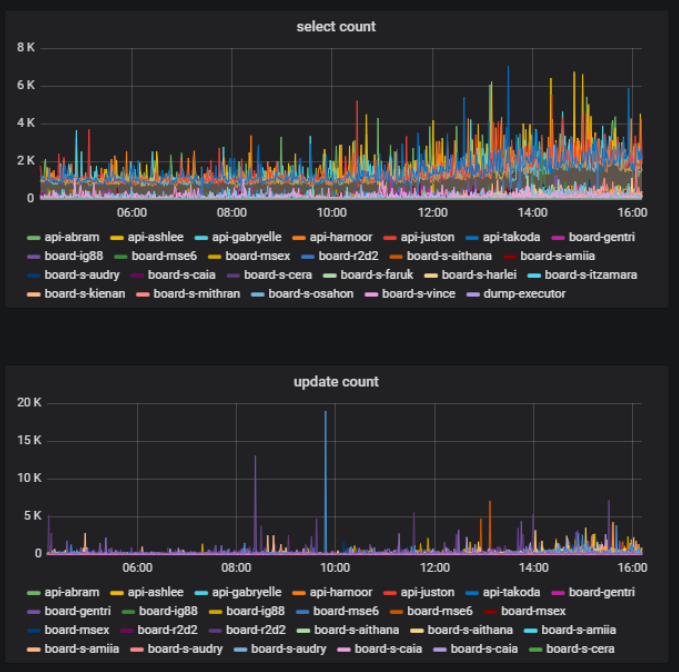
Sur la même carte au même moment, certains utilisateurs peuvent activement faire quelque chose - créer, supprimer, modifier - et certains simplement afficher le matériel créé. Il s'agit également d'une mesure importante - le rapport entre le nombre d'utilisateurs modifiant le contenu du tableau et le nombre total d'utilisateurs d'un tableau. Nous pouvons l'obtenir sur la base de statistiques sur l'utilisation de la base de données.
Dans notre backend, nous utilisons l'approche par composants. Composants que nous appelons modèles. Nous divisons notre code en modèles afin que pour chaque partie de la logique métier, un certain modèle soit responsable. Nous pouvons calculer le nombre d'appels de base de données qui se produisent à travers chaque modèle et comprendre quelle partie de la logique charge le plus la base de données.
 Blocs personnalisés pratiques
Blocs personnalisés pratiquesPar exemple, nous devons ajouter un bloc au script qui charge notre service de manière identique à la façon dont cela se produit lorsque vous ouvrez une page de tableau de bord avec une liste de tableaux de bord. Lors du chargement de cette page, des requêtes http avec un grand ensemble de données sont envoyées: le nombre de tableaux, les comptes auxquels l'utilisateur a accès, tous les utilisateurs du compte, etc.

Comment charger efficacement un tableau de bord? Lors de l'analyse du comportement de production, nous avons constaté des pics de charge dans la base de données lors de l'ouverture du tableau de bord d'un grand compte. Nous pouvons recréer un compte identique et changer l'intensité d'utilisation de ses données dans le script, en chargeant efficacement un tableau de bord avec un petit nombre de hits. Nous pouvons également créer une charge inégale pour plus de réalisme.
Dans le même temps, il est important pour nous que le nombre d'utilisateurs virtuels et la charge créée par eux soient aussi similaires que possible aux utilisateurs et à la charge de production. Pour ce faire, nous recréons également dans le test la charge de fond sur le tableau de bord moyen. Ainsi, la plupart des utilisateurs virtuels travaillent sur de petits tableaux de bord moyens, et seuls quelques utilisateurs créent une charge désastreuse, comme cela se produit en production.
Au départ, nous ne voulions pas couvrir chaque rôle de serveur et chaque relation avec un script distinct. Cela peut être vu dans l'exemple avec le tableau de bord - nous répétons simplement pendant le test ce qui se passe lorsque le tableau de bord est ouvert sur le prod lorsque l'utilisateur l'ouvre, et nous ne couvrons pas ce qu'il affecte avec des scripts synthétiques. Cela vous permet par défaut de tester des nuances que nous n'avions même pas anticipées. Ainsi, nous approchons de la création d'un test d'infrastructure du côté de la logique métier.
Nous avons utilisé cette logique pour charger efficacement tous les autres blocs du service. En même temps, chaque bloc individuel du point de vue de la logique d'utilisation du fonctionnel peut ne pas être réaliste; il est important qu'il donne une charge métrique réaliste sur les serveurs. Et puis nous pouvons créer un script à partir de ces blocs qui imite le vrai travail des utilisateurs.

Les données font partie du script.
N'oubliez pas que les données font également partie du script et que la logique du code lui-même dépend beaucoup des données. Lors de la construction d'une grande base de données pour le test - et elle devrait évidemment être volumineuse pour un test d'infrastructure de grande taille - nous devons apprendre à créer des données qui ne donneront pas de résultat lors de l'exécution du script. Si vous accumulez des données indésirables, le script peut s'avérer irréaliste et une grande base de données sera difficile à réparer. Par conséquent, nous avons commencé à utiliser l'API Rest pour créer des données de la même manière que nos utilisateurs le font.
Par exemple, pour créer des cartes avec les données disponibles, nous exécutons des requêtes API pour charger des cartes à partir de la sauvegarde. En conséquence, nous obtenons des données réelles honnêtes - différentes cartes de différentes tailles. Dans le même temps, la base de données se remplit assez rapidement en raison du fait que nous tirons des demandes dans le script de manière multithread. En vitesse, cela est comparable à la génération de données d'ordures.
Résultats pour cette partie
- Utilisez des scénarios réalistes si vous souhaitez tout vérifier en même temps;
- Analyser le comportement réel des utilisateurs pour concevoir la structure du script;
- Créez immédiatement des blocs pratiques pour la personnalisation;
- Configurer par de vraies métriques de serveur, pas par des analyses d'utilisation;
- N'oubliez pas que les données font partie du script.
Charger un cluster
Schéma d'outils pour appliquer la charge:
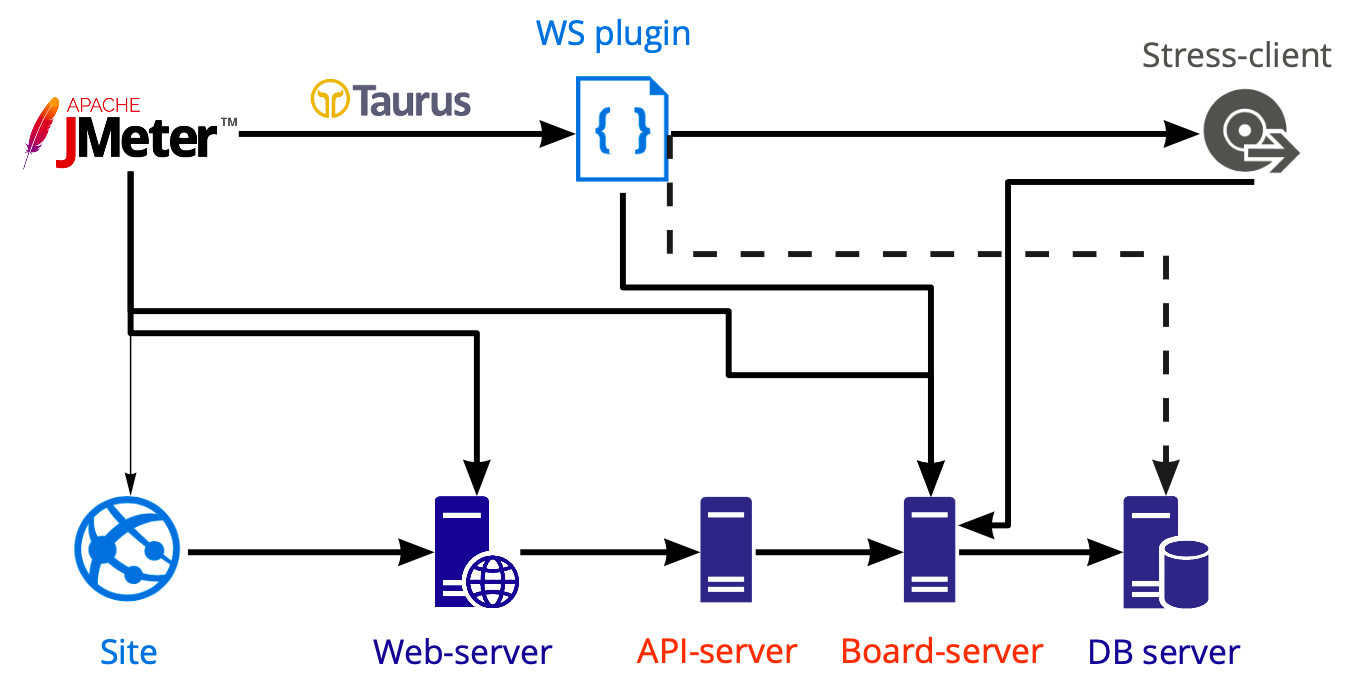
Dans Jmeter, nous créons un script que nous lançons à l'aide de Taurus et chargeons différents serveurs avec lui: web, api, serveurs de carte. Nous effectuons des tests de base de données séparément en utilisant Postgresql, pas Jmeter, donc le diagramme montre une ligne pointillée.
Travail personnalisé à l'intérieur de la prise Web
Le travail sur la carte s'effectue à l'intérieur de la connexion WS, et c'est sur la carte que le travail multi-utilisateur est possible. Maintenant, dans la boîte Jmeter à l'intérieur du gestionnaire de plug-ins, il existe plusieurs plug-ins pour travailler avec le socket Web. La logique est la même partout - les plugins ouvrent simplement une connexion socket Web, mais toutes les actions qui se produisent à l'intérieur, dans tous les cas, vous devez vous écrire. Pourquoi? Parce que nous ne pouvons pas travailler de la même manière qu'avec les requêtes http, c'est-à-dire que nous ne pouvons pas écrire un script, extraire des valeurs dynamiques avec des extracteurs et les ignorer davantage.
Le travail à l'intérieur du socket Web est généralement très personnalisé: vous invoquez certaines méthodes avec certaines données personnalisées et, par conséquent, vous devez vous-même comprendre si la demande a été exécutée correctement et combien de temps il a fallu pour l'exécuter. L'écouteur à l'intérieur de ce plugin est également écrit indépendamment; nous n'avons pas trouvé de bonne solution prête à l'emploi.
Client stressé
Nous voulons répéter le plus simplement possible ce que font les vrais utilisateurs. Mais nous ne savons pas comment enregistrer et lire ce qui se passe dans le navigateur à l'intérieur de WS. Si nous écrivons tout à l'intérieur de WS à partir de zéro, nous obtiendrons un nouveau client, et non celui que les vrais utilisateurs utilisent. Je n'ai pas envie d'écrire un nouveau client si nous en avons déjà un qui fonctionne.
Par conséquent, nous avons décidé de placer notre client à l'intérieur de Jmeter. Et face à un certain nombre de difficultés. Par exemple, exécuter js dans Jmeter est une histoire distincte, comme Il s'agit d'une
version absolument
spécifique des fonctionnalités prises en charge. Et si vous souhaitez utiliser votre code client existant, vous ne réussirez probablement pas, car les nouvelles constructions ne peuvent pas être lancées ici, elles devront être réécrites.
La deuxième difficulté est que nous ne voulons pas prendre en charge l'intégralité du code client pour les tests de charge. Par conséquent, nous avons supprimé tout ce qui était superflu du client et laissé uniquement l'interaction client-serveur. Cela nous a permis d'utiliser des méthodes client-serveur et de faire tout ce que notre client peut faire. Le plus est que l'interaction client-serveur change extrêmement rarement, ce qui signifie que la prise en charge du code à l'intérieur du script est rarement requise. Par exemple, au cours des six derniers mois, je n'ai jamais apporté de modifications au code, car il fonctionne très bien.
La troisième difficulté - l'apparition de gros scripts complique considérablement le script. Premièrement, cela peut devenir un goulot d'étranglement dans le test. Deuxièmement, nous ne pourrons probablement pas démarrer un grand nombre de threads à partir d'une seule machine. Maintenant, nous ne pouvons lancer que 730 threads.
Notre exemple d'instance Amazon Jmeter server AWS: m5.large ($0.06 per Hour) vCPU: 2 Mem (GiB): 8 Dedicated EBS Bandwidth (Mbps): Up to 3,500 Network Performance (Gbps): Up to 10 → ~730
Où trouver des centaines de serveurs et comment économiser
Ensuite, la question se pose: 730 threads d'une seule machine, mais nous voulons 50K. Où élever autant de serveurs? Nous créons une solution cloud, donc acheter des serveurs pour tester une solution cloud semble étrange. De plus, c'est toujours une certaine lenteur dans les processus d'achat de fer neuf. Par conséquent, nous devons les augmenter également dans le cloud, nous avons donc finalement choisi entre les fournisseurs de cloud et les outils de chargement dans le cloud.
Nous n'avons pas utilisé d'outils de chargement dans le cloud comme Blazemeter et RedLine13, car ils ont des restrictions d'utilisation qui ne nous convenaient pas. Nous avons différents sites de test, nous voulions donc trouver une solution universelle qui permettrait d'utiliser 90% des développements, y compris dans les tests locaux.
En conséquence, nous avons choisi entre les fournisseurs de cloud.
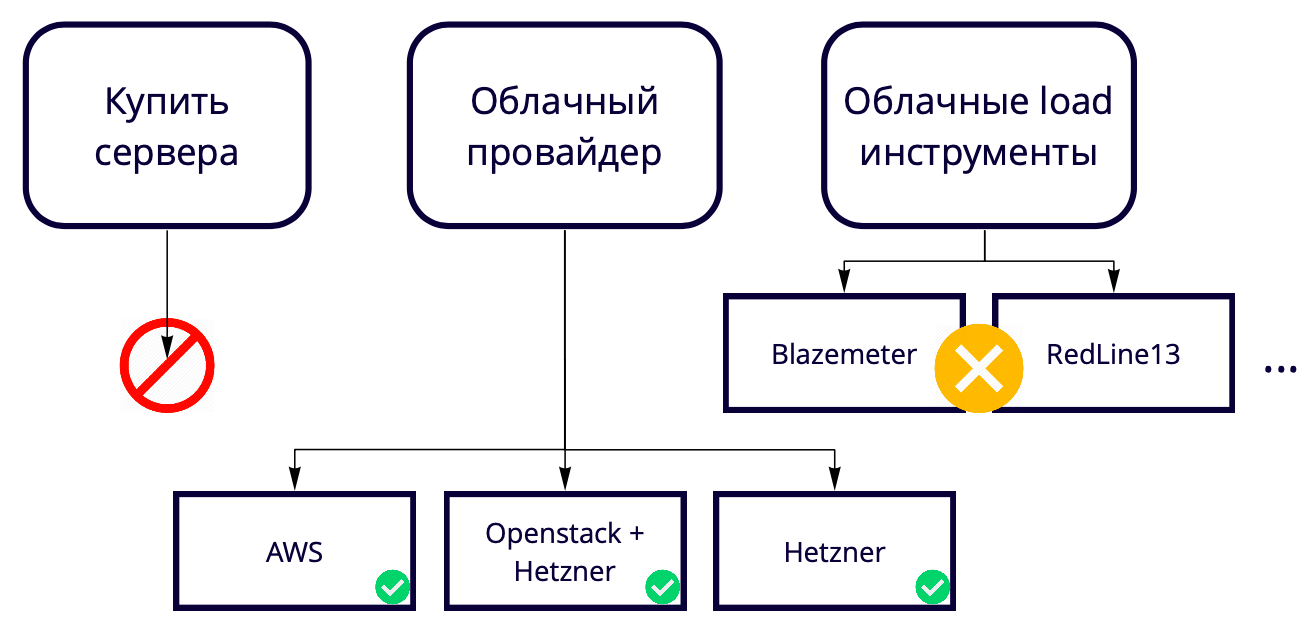
Notre production est sur AWS, nous testons donc principalement là-bas et nous voulons que le banc d'essai soit aussi similaire que possible à la production. Amazon a de nombreuses fonctionnalités payantes, dont certaines que nous utilisons dans le produit, par exemple, des équilibreurs. Si ces fonctionnalités ne sont pas nécessaires dans AWS, vous pouvez les utiliser 17 fois moins cher dans Hetzner. Ou vous pouvez conserver le serveur dans Hetzner, utiliser Openstack et écrire des équilibreurs et d'autres fonctionnalités vous-même, car en utilisant Openstack, vous pouvez répéter toute l'infrastructure. Nous avons réussi.
Tester 50 000 utilisateurs avec 69 instances dans AWS nous coûte environ 3 000 $ par mois. Comment économiser? Par exemple, AWS a des instances temporaires - des instances ponctuelles. Leur fraîcheur est que nous ne les gardons pas constamment, nous ne les élevons que pour la durée des tests et ils coûtent beaucoup moins cher. La nuance est que quelqu'un d'autre peut les acheter à un prix plus élevé au moment de notre test. Heureusement, cela ne s'est jamais produit auparavant, mais nous économisons déjà au moins 60% du coût à leurs dépens.
Charger un cluster
Nous utilisons le cluster de boîtes Jmeter. Cela fonctionne très bien, il n'a pas besoin d'être modifié en aucune façon. Il a plusieurs options de lancement. Nous utilisons le plus simple lorsqu'un assistant démarre N instances, et il peut y en avoir des centaines.
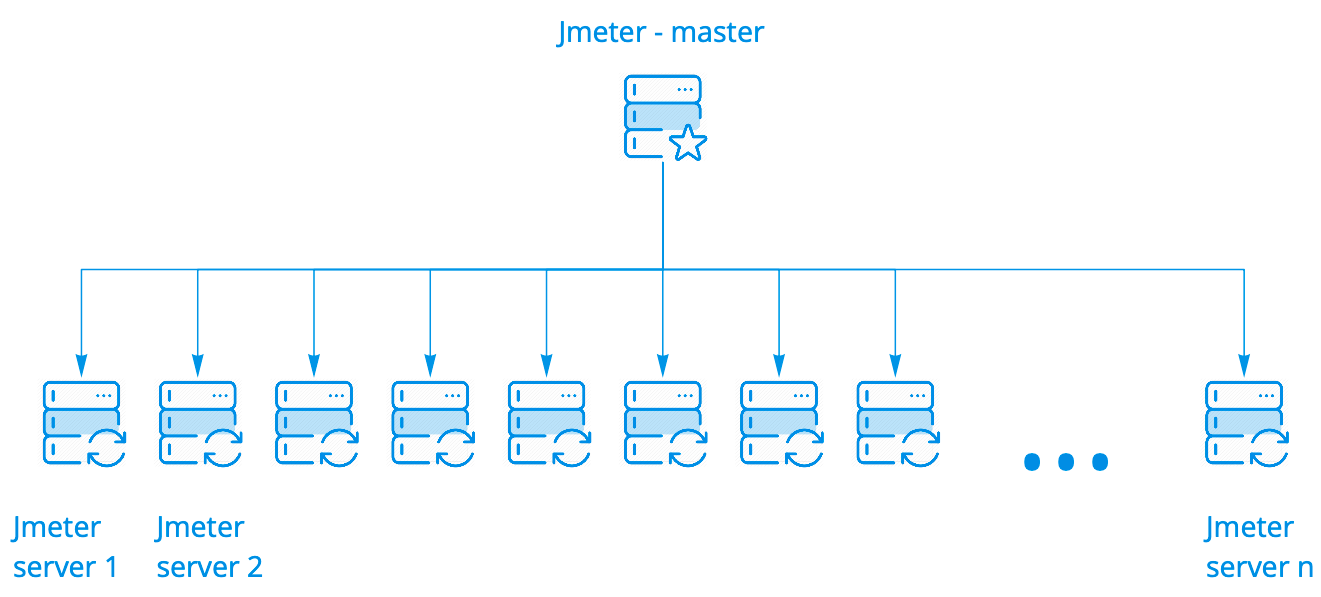
L'assistant exécute le script sur les serveurs Jmeter, tout en restant en contact avec eux, collecte des statistiques générales de toutes les instances en temps réel et les affiche dans la console. Tout cela ressemble exactement à l'exécution du script sur un serveur, bien que nous voyions les résultats du lancement sur une centaine de serveurs.
Pour une analyse détaillée des résultats de l'exécution du script sur toutes les instances, nous utilisons Kibana. Journaux Parsim à l'aide de Filebeat.

Un écouteur Prometheus pour Apache JMeter
Jmeter a un
plugin pour travailler avec Prometheus , qui fournit toutes les statistiques sur l'utilisation de la JVM et des threads à l'intérieur du test. Cela vous permet de voir à quelle fréquence les utilisateurs se connectent, se déconnectent, etc. Le plugin peut être personnalisé pour envoyer des données sur le script à Prometheus et les voir en temps réel dans Grafana.
Taureau
Nous voulons résoudre un certain nombre de problèmes actuels avec Taurus, mais nous ne l'avons pas encore résolu:
- Configure au lieu des clones de script. Si vous avez testé sur Jmeter, vous avez probablement dû faire face à la nécessité d'exécuter des scripts avec différents ensembles de paramètres source, pour lesquels vous deviez créer leurs clones. Dans Taurus, il est possible d'avoir un scénario et à l'aide de configurations de contrôler les paramètres de lancement;
- Configurer la gestion des serveurs Jmeter lors de l'utilisation d'un cluster;
- Un analyseur de résultats en ligne qui vous permet de collecter les résultats séparément des threads Jmeter et de ne pas surcharger le script lui-même;
- Intégration pratique avec CI;
- La possibilité de tester un système distribué.
Les résultats de cette partie
- Si nous utilisons le code à l'intérieur de Jmeter, alors il est préférable de penser immédiatement à ses performances, car sinon nous pouvons tester Jmeter, pas notre produit;
- Le cluster Jmeter est une chose merveilleuse: il est facile à configurer, la surveillance y est facilement vissée;
- Un grand cluster peut être conservé sur place, ce sera beaucoup moins cher;
- Soyez prudent avec les écouteurs à l'intérieur du Jmeter afin que le script ne ralentisse pas le travail sur un grand nombre de serveurs.
Exemples d'utilisation de tests d'infrastructure
Toute l'histoire ci-dessus concerne en grande partie la création d'un scénario réaliste pour un test de limite de service. Les exemples ci-dessous montrent comment vous pouvez réutiliser l'infrastructure des tests de charge pour résoudre des problèmes locaux. Je vais parler en détail de deux tests, mais en général, nous effectuons périodiquement environ 10 types de tests de charge.
Test de base de données
Que pouvons-nous charger de test dans la base de données? Les requêtes lourdes sont peu probables, car nous pouvons les tester en mode monothread, si nous regardons simplement les plans de requête.
Une situation intéressante est lorsque nous exécutons le test et voyons la charge sur le disque. Le graphique montre la progression de l'iowait.
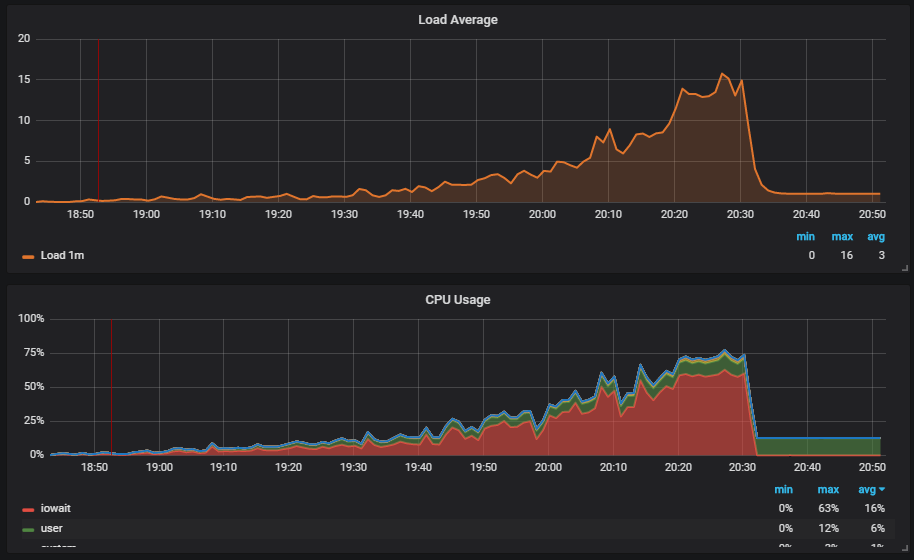
De plus, nous voyons que cela affecte les utilisateurs.
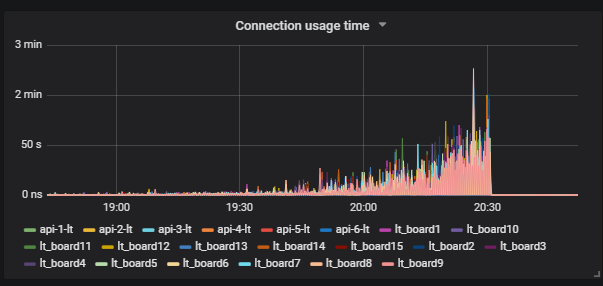
Nous comprenons la raison: le vide n'a pas fonctionné et n'a pas supprimé les données de déchets de la base de données. Si vous n'avez pas travaillé avec Postgresql, Vacuum est comme le garbage collector en Java.

De plus, nous voyons que
Checkpoint a commencé à fonctionner hors du calendrier. Pour nous, c'est un signal que les configurations Postgresql ne correspondent pas à l'intensité du travail avec la base de données.
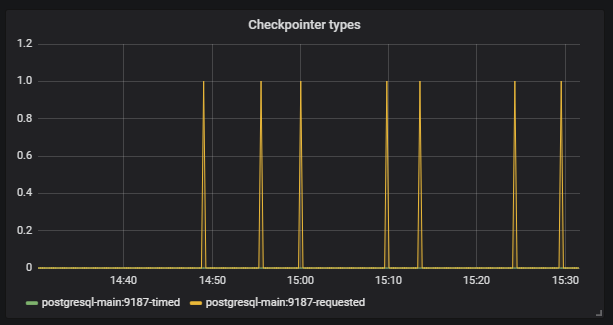
Notre tâche consiste à configurer correctement la base de données afin que de telles situations ne se reproduisent pas. Le même Postgresql a de nombreux paramètres. Pour un réglage fin, vous devez travailler en courtes itérations: correction de la configuration, lancement, vérification, correction de la configuration, lancement, vérification. Bien sûr, pour cela, vous devez appliquer une bonne charge à la base, mais pour cela, vous avez juste besoin de grands tests d'infrastructure.
La particularité est que pour que le test accélère normalement et ne tombe pas là où il n'est pas nécessaire, l'overclocking doit être long. Il nous faut environ trois heures pour tester, et cela ne ressemble plus à de courtes itérations.
Nous recherchons une solution. Nous trouvons l'un des outils Postgresql -
Pg_replay . Il peut reproduire en plusieurs fils exactement ce qui est écrit dans les journaux et exactement comme cela s'est produit au moment de leur enregistrement. Comment pouvons-nous l'utiliser efficacement? Nous réduisons le vidage de la base de données, puis enregistrons tout ce qui se passe dans la base de données après l'enregistrement dans les journaux, puis nous avons la possibilité de déployer le vidage et de lire tout ce qui s'est passé avec la base de données multithread.
Où écrire des journaux? Une solution populaire pour l'enregistrement des journaux est de les collecter sur le prod, car cela donne le script reproductible le plus réaliste. Mais il y a un certain nombre de problèmes:
- Pour le test, vous devez utiliser les données de vente, ce qui n'est pas toujours possible;
- Le processus utilise une opération syslog coûteuse;
- Le disque est en cours de chargement.
Notre approche des grands tests nous aide ici. Nous effectuons un vidage sur un environnement de test, exécutons un grand test et enregistrons les journaux de tout ce qui se passe au moment où le script réaliste est exécuté. Ensuite, nous utilisons notre propre outil
marucy pour tester la base de données:
- Une instance est créée dans AWS;
- Le dépotoir dont nous avons besoin est déployé;
- Pg_replay est lancé et lit les journaux nécessaires;
- Nous utilisons notre surveillance pour analyser le résultat de Prometheus + Grafana. Il existe des exemples de tableaux de bord dans le référentiel.
Au démarrage de marucy, on peut passer un petit nombre de paramètres qui peuvent être modifiés, par exemple l'intensité du script.
Par conséquent, nous utilisons notre script réaliste pour créer un test, puis jouer le test sans utiliser un grand cluster. Il est important de considérer que pour tester une base de données SQL, le script doit être inégal, sinon la base de données elle-même se comportera différemment du prod.
Surveillance de la dégradation
Pour les tests de dégradation, nous utilisons notre scénario réaliste. L'idée est que nous devons nous assurer que le service ne fonctionne pas plus lentement après la prochaine version. Si nos développeurs changent dans le code ce qui entraîne une augmentation du temps d'exécution des requêtes, nous pouvons comparer les nouvelles valeurs avec les références et signaler s'il y a une erreur dans la construction. Pour les valeurs de référence, nous prenons les valeurs actuelles qui nous conviennent.
Le contrôle du temps d'exécution des requêtes est utile, mais nous sommes allés plus loin. Nous voulions voir que le temps de réponse pendant le travail des vrais utilisateurs après la sortie ne devenait pas plus long. Nous pensions qu'au moment des tests de résistance, nous pouvons probablement aller vérifier quelque chose, mais ce ne seront que des dizaines de cas. Il est plus efficace d'exécuter des tests fonctionnels existants et de voir un millier de cas en même temps.

Comment ça marche pour nous? Il y a un maître qui, après assemblage, est déployé sur un banc d'essai. Ensuite, les tests fonctionnels sont exécutés automatiquement en parallèle avec les tests de charge. Ensuite, nous obtenons un rapport dans Allure sur la façon dont les tests fonctionnels se sont déroulés sous charge.
Dans ce rapport, par exemple, nous voyons qu'un test de comparaison a chuté avec une valeur de référence.
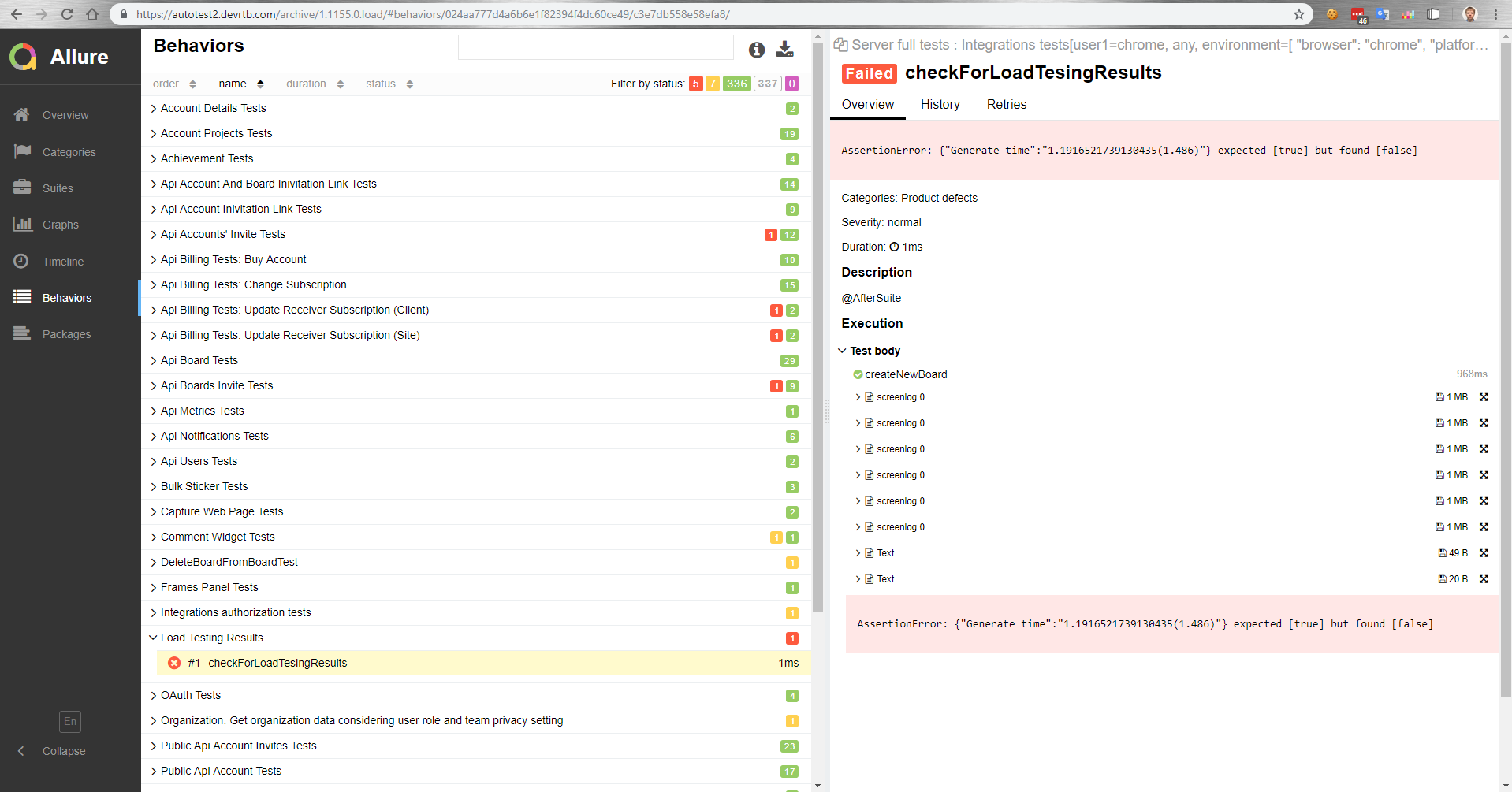
Dans les tests fonctionnels, nous pouvons également mesurer le temps d'exécution d'une opération dans un navigateur. Ou, un test fonctionnel échoue simplement en raison d'une augmentation du temps d'exécution de l'opération sous charge, car le délai d'attente sur le client fonctionnera.
Résultats pour cette partie
- Un test réaliste vous permet de tester la base de données à moindre coût et de la configurer facilement;
- Des tests fonctionnels sous charge sont possibles.
Le
prochain article explique comment nous gérons des centaines de serveurs pour un test de charge.